膨大な量のテキストから正確で洞察力に富んだ回答を導き出すことは、大規模言語モデル (LLM) によって可能になる素晴らしい機能です。 LLM アプリケーションを構築する場合、多くの場合、外部データ ソースに接続してクエリを実行して、関連するコンテキストをモデルに提供することが必要になります。一般的なアプローチの 1 つは、検索拡張生成 (RAG) を使用して、複雑な情報を理解し、クエリに対して自然な応答を提供する Q&A システムを作成することです。 RAG を使用すると、モデルが膨大な知識ベースを活用し、チャットボットやエンタープライズ検索アシスタントなどのアプリケーションに人間のような対話を提供できるようになります。
この投稿では、その力を活用する方法を探ります。 ラマインデックス, ラマ 2-70B-チャット, ラングチェーン 強力な Q&A アプリケーションを構築します。これらの最先端のテクノロジーを使用すると、テキスト コーパスを取り込み、重要な知識のインデックスを作成し、ユーザーの質問に正確かつ明確に答えるテキストを生成できます。
ラマ 2-70B-チャット
Llama 2-70B-Chat は、主要モデルと競合する強力な LLM です。これは 2022 兆のテキスト トークンで事前トレーニングされており、Meta はユーザーへのチャット アシスタンスに使用することを目的としています。事前トレーニング データは公開データから取得されており、2023 年 XNUMX 月に終了し、微調整データは XNUMX 年 XNUMX 月に終了します。モデルのトレーニング プロセス、安全性に関する考慮事項、学習、および使用目的の詳細については、論文を参照してください。 Llama 2: オープンな基盤と微調整されたチャット モデル。 Llama 2 モデルは以下で入手可能です Amazon SageMaker ジャンプスタート 迅速かつ簡単な導入を可能にします。
ラマインデックス
ラマインデックス は、LLM アプリケーションの構築を可能にするデータ フレームワークです。さまざまなソースや形式 (PDF、ドキュメント、API、SQL など) で既存のデータを取り込むためのデータ コネクタを提供するツールが提供されます。データがデータベースに保存されているか、PDF に保存されているかに関係なく、LlamaIndex を使用すると、そのデータを LLM で簡単に使用できるようになります。この投稿で説明したように、LlamaIndex API を使用するとデータ アクセスが簡単になり、強力なカスタム LLM アプリケーションとワークフローを作成できるようになります。
LLM を試したり構築したりしている場合は、LLM を利用したアプリケーションの開発と展開を簡素化する堅牢なフレームワークを提供する LangChain に精通しているはずです。 LangChain と同様に、LlamaIndex は、データ コネクタ、データ インデックス、エンジン、データ エージェントを含む多数のツールと、ツールと可観測性、トレース、評価などのアプリケーション統合を提供します。 LlamaIndex は、データと強力な LLM の間のギャップを埋めることに重点を置き、使いやすい機能でデータ タスクを合理化します。 LlamaIndex は、LLM のクエリと関連ドキュメントの取得のためのシンプルなインターフェイスを提供するため、RAG などの検索および取得アプリケーションを構築するために特別に設計および最適化されています。
ソリューションの概要
この投稿では、LlamaIndex と LLM を使用して RAG ベースのアプリケーションを作成する方法を示します。次の図は、以降のセクションで概要を説明するこのソリューションの段階的なアーキテクチャを示しています。
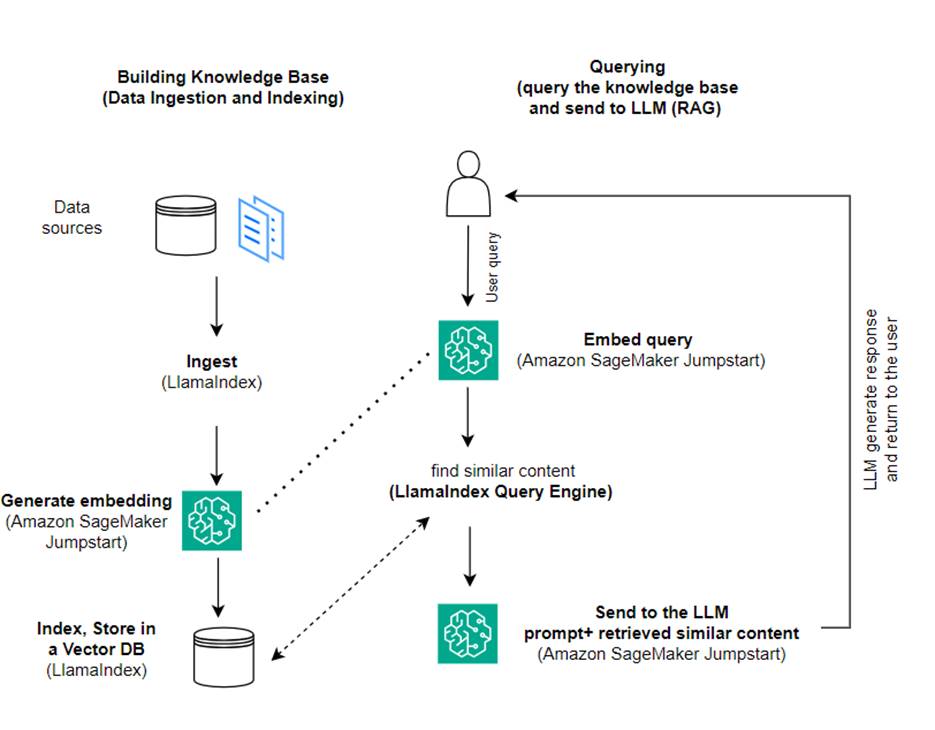
RAG は、情報検索と自然言語生成を組み合わせて、より洞察力に富んだ応答を生成します。プロンプトが表示されると、RAG はまずテキスト コーパスを検索して、入力に最も関連性の高い例を取得します。応答の生成中に、モデルは機能を強化するためにこれらの例を考慮します。関連する検索された一節を組み込むことにより、RAG 応答は、基本的な生成モデルと比較して、より事実に即し、一貫性があり、コンテキストと一致する傾向があります。この取得と生成のフレームワークは、取得と生成の両方の長所を活用し、純粋な自己回帰会話モデルから発生する可能性のある繰り返しやコンテキストの欠如などの問題に対処するのに役立ちます。 RAG は、コンテキストに応じた高品質な応答を備えた会話型エージェントと AI アシスタントを構築するための効果的なアプローチを導入します。
ソリューションの構築は次の手順で構成されます。
- セットアップ Amazon SageMakerスタジオ を開発環境として使用し、必要な依存関係をインストールします。
- Amazon SageMaker JumpStart ハブから埋め込みモデルをデプロイします。
- プレスリリースをダウンロードして、外部ナレッジベースとして使用してください。
- プレス リリースからインデックスを作成して、クエリを実行し、追加のコンテキストとしてプロンプトに追加できるようにします。
- ナレッジ ベースにクエリを実行します。
- LlamaIndex エージェントと LangChain エージェントを使用して Q&A アプリケーションを構築します。
この投稿のすべてのコードは、次の場所から入手できます。 GitHubレポ.
前提条件
この例では、SageMaker ドメインと適切な AWS アカウントが必要です。 AWS IDおよびアクセス管理 (IAM) 権限。アカウント設定手順については、次を参照してください。 AWS アカウントを作成する。 SageMaker ドメインをまだお持ちでない場合は、以下を参照してください。 Amazon SageMaker ドメイン 作成するための概要。この投稿では、 AmazonSageMakerFullAccess 役割。この資格情報を運用環境で使用することはお勧めできません。代わりに、最小限の権限を持つロールを作成して使用する必要があります。使用方法を調べることもできます Amazon SageMaker ロールマネージャー SageMaker コンソールを介して直接、一般的な機械学習のニーズに対応するペルソナベースの IAM ロールを構築および管理します。
さらに、少なくとも次のインスタンス サイズにアクセスする必要があります。
- ml.g5.2xラージ デプロイ時のエンドポイントの使用については、 ハグフェイス GPT-J テキスト埋め込みモデル
- ml.g5.48xラージ Llama 2-Chat モデルのエンドポイントをデプロイする際のエンドポイントの使用について
割り当てを増やすには、を参照してください。 割り当て増加のリクエスト.
SageMaker JumpStart を使用して GPT-J 埋め込みモデルをデプロイする
このセクションでは、SageMaker JumpStart モデルをデプロイする際の 2 つのオプションを提供します。提供されたコードを使用してコードベースのデプロイメントを使用することも、SageMaker JumpStart ユーザー インターフェイス (UI) を使用することもできます。
SageMaker Python SDK を使用してデプロイする
に示すように、SageMaker Python SDK を使用して LLM をデプロイできます。 コード リポジトリで利用可能です。次の手順を実行します。
- 次を使用して、エンベディング モデルのデプロイに使用されるインスタンス サイズを設定します。
instance_type = "ml.g5.2xlarge" - モデルが埋め込みに使用する ID を見つけます。 SageMaker JumpStart では、次のように識別されます。
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - 事前トレーニングされたモデル コンテナーを取得し、推論のためにデプロイします。
エンベディング モデルが正常にデプロイされると、SageMaker はモデル エンドポイントの名前と次のメッセージを返します。
SageMaker Studio で SageMaker JumpStart を使用してデプロイする
Studio で SageMaker JumpStart を使用してモデルをデプロイするには、次の手順を実行します。
- SageMaker Studio コンソールのナビゲーションペインで JumpStart を選択します。

- GPT-J 6B Embedding FP16 モデルを検索して選択します。
- [展開] を選択し、展開構成をカスタマイズします。

- この例では、ml.g5.2xlarge インスタンスが必要です。これは、SageMaker JumpStart によって提案されるデフォルトのインスタンスです。
- もう一度 [Deploy] を選択してエンドポイントを作成します。
エンドポイントが使用可能になるまでに約 5 ~ 10 分かかります。

エンベディング モデルをデプロイした後、SageMaker API との LangChain 統合を使用するには、入力 (生のテキスト) を処理する関数を作成し、モデルを使用して入力をエンベディングに変換する必要があります。これを行うには、というクラスを作成します。 ContentHandler、入力データの JSON を受け取り、テキスト埋め込みの JSON を返します。 class ContentHandler(EmbeddingsContentHandler).
モデルのエンドポイント名を ContentHandler テキストを変換して埋め込みを返す関数:
エンドポイント名は、SDK の出力または SageMaker JumpStart UI のデプロイメント詳細で見つけることができます。
それをテストできます ContentHandler 関数とエンドポイントは、生のテキストを入力して実行することで期待どおりに動作します。 embeddings.embed_query(text) 関数。提供された例を使用できます text = "Hi! It's time for the beach" または独自のテキストを試してください。
SageMaker JumpStart を使用した Llama 2-Chat のデプロイとテスト
これで、ユーザーと対話型の会話ができるモデルをデプロイできるようになりました。この例では、Llama 2 チャット モデルの XNUMX つを選択します。
モデルは、次を使用してリアルタイム エンドポイントにデプロイする必要があります。 predictor = my_model.deploy()。 SageMaker はモデルのエンドポイント名を返します。これは、 endpoint_name 後で参照する変数。
あなたが定義するのは、 print_dialogue 入力をチャット モデルに送信し、その出力応答を受信する関数。ペイロードには、次のようなモデルのハイパーパラメータが含まれています。
- max_new_tokens – モデルが出力で生成できるトークンの最大数を指します。
- トップ_p – 出力を生成するときにモデルが保持できるトークンの累積確率を指します。
- 温度 – モデルによって生成される出力のランダム性を指します。温度が 0 より大きいか 1 に等しいとランダム性のレベルが上がりますが、温度が 0 の場合は最も可能性の高いトークンが生成されます。
ユースケースに基づいてハイパーパラメータを選択し、適切にテストする必要があります。 Llama ファミリなどのモデルでは、エンド ユーザー使用許諾契約 (EULA) を読んで同意したことを示す追加パラメータを含める必要があります。
モデルをテストするには、入力ペイロードのコンテンツ セクションを置き換えます。 "content": "what is the recipe of mayonnaise?"。独自のテキスト値を使用し、ハイパーパラメータを更新して、それらをより深く理解することができます。
エンベディング モデルのデプロイと同様に、SageMaker JumpStart UI を使用して Llama-70B-Chat をデプロイできます。
- SageMaker Studio コンソールで、次を選択します。 ジャンプスタート ナビゲーションペインで
- を検索して選択します。
Llama-2-70b-Chat model - EULA に同意して選択します 配備します、デフォルトのインスタンスを再度使用します
埋め込みモデルと同様に、チャット モデルの入力と出力用のコンテンツ ハンドラー テンプレートを作成することで、LangChain 統合を使用できます。この場合、入力をユーザーからのものとして定義し、それらが制御されることを示します。 system promptを選択します。 system prompt 特定のユースケースでユーザーを支援する際の役割をモデルに通知します。
このコンテンツ ハンドラーは、モデルを呼び出すときに、前述のハイパーパラメーターとカスタム属性 (EULA への同意) に加えて渡されます。次のコードを使用して、これらすべての属性を解析します。
エンドポイントが利用可能になったら、それが期待どおりに動作していることをテストできます。更新できます llm("what is amazon sagemaker?") あなた自身のテキストで。特定の ContentHandler に示すように、LangChain を使用して LLM を呼び出します。 コード そして次のコードスニペット:
LlamaIndex を使用して RAG を構築する
続行するには、LlamaIndex をインストールして RAG アプリケーションを作成します。 pip を使用して LlamaIndex をインストールできます。 pip install llama_index
まず、インデックス作成のためにデータ (知識ベース) を LlamaIndex にロードする必要があります。これにはいくつかの手順が含まれます。
- データローダーを選択します。
LlamaIndex は、以下で利用可能な多数のデータ コネクタを提供します。 ラマハブ JSON、CSV、テキスト ファイルなどの一般的なデータ タイプやその他のデータ ソースに対応し、さまざまなデータセットを取り込むことができます。この投稿では、 SimpleDirectoryReader コードに示すように、いくつかの PDF ファイルを取り込みます。私たちのデータサンプルは、PDF 版の 2 つの Amazon プレスリリースです。 プレスリリース コードリポジトリ内のフォルダー。 PDF をロードすると、PDF が 11 個の要素のリストに変換されたことがわかります。
ドキュメントを直接ロードする代わりに、 Document オブジェクトに Node オブジェクトをインデックスに送信する前に。全体を送るかの選択 Document オブジェクトをインデックスに追加するか、ドキュメントを次のように変換します。 Node インデックス作成前のオブジェクトは、特定の使用例とデータの構造によって異なります。ノードのアプローチは通常、文書全体ではなく文書の特定の部分を分割して取得する必要がある長い文書に適した選択です。詳細については、以下を参照してください。 ドキュメント/ノード.
- ローダーをインスタンス化してドキュメントをロードします。
このステップでは、ローダー クラスと必要な設定 (隠しファイルを無視するかどうかなど) を初期化します。詳細については、を参照してください。 シンプルディレクトリリーダー.
- ローダーに電話してください
load_dataメソッドを使用して、ソース ファイルとデータを解析し、それらを LlamaIndex Document オブジェクトに変換し、インデックス作成とクエリの準備が整います。次のコードを使用すると、LlamaIndex のインデックス作成および取得機能を使用したデータの取り込みと全文検索の準備を完了できます。
- インデックスを構築します。
LlamaIndex の主な機能は、ドキュメントまたはノードとして表されるデータに対して組織化されたインデックスを構築できることです。インデックス付けにより、データに対する効率的なクエリが容易になります。デフォルトのメモリ内ベクトル ストアと定義された設定構成を使用してインデックスを作成します。ラマインデックス 設定 は、LlamaIndex アプリケーションでのインデックス作成とクエリ操作に一般的に使用されるリソースと設定を提供する構成オブジェクトです。これはシングルトン オブジェクトとして機能するため、グローバル構成を設定できると同時に、特定のコンポーネントを使用するインターフェイス (LLM、埋め込みモデルなど) に直接渡すことによって、特定のコンポーネントをローカルでオーバーライドすることもできます。特定のコンポーネントが明示的に提供されていない場合、LlamaIndex フレームワークは、 Settings オブジェクトをグローバルデフォルトとして設定します。 LangChain で埋め込みモデルと LLM モデルを使用し、 Settings インストールする必要があります llama_index.embeddings.langchain & llama_index.llms.langchain。設定できるのは、 Settings 次のコードのようにオブジェクトを作成します。
デフォルトでは、 VectorStoreIndex インメモリを使用します SimpleVectorStore これは、デフォルトのストレージ コンテキストの一部として初期化されます。実際のユースケースでは、多くの場合、次のような外部ベクトル ストアに接続する必要があります。 AmazonOpenSearchサービス。 詳細については、を参照してください。 Amazon OpenSearch サーバーレス用のベクトル エンジン.
これで、 クエリエンジン ラマインデックスより。これを行うには、以前に作成したクエリ用のインデックスを渡して質問します。クエリ エンジンは、データをクエリするための汎用インターフェイスです。自然言語クエリを入力として受け取り、豊富な応答を返します。クエリ エンジンは通常、1 つ以上のクエリ エンジンの上に構築されます。 インデックス レトリバー.
RAG ソリューションが提供されたドキュメントから正しい答えを取得できることがわかります。
LangChain ツールとエージェントを使用する
Loader クラス。ローダーは、データを LlamaIndex にロードするか、その後ツールとしてロードするように設計されています。 ラングチェーンエージェント。これにより、これをアプリケーションの一部として使用するための機能と柔軟性がさらに高まります。まずは自分のことを定義することから始めます ツール LangChain エージェント クラスから。ツールに渡す関数は、LlamaIndex を使用してドキュメントに対して構築したインデックスをクエリします。
次に、RAG 実装に使用する適切なタイプのエージェントを選択します。この場合、使用するのは、 chat-zero-shot-react-description エージェント。このエージェントを使用すると、LLM は利用可能なツール (このシナリオではナレッジ ベース上の RAG) を使用して応答を提供します。次に、ツール、LLM、エージェント タイプを渡してエージェントを初期化します。
エージェントが通過しているのがわかります thoughts, actions, observation 、ツールを使用します (このシナリオでは、インデックス付きドキュメントをクエリします)。そして結果を返します:
エンドツーエンドの実装コードは、付属のファイルにあります。 GitHubレポ.
クリーンアップ
不必要なコストを避けるために、次のコードスニペットまたは Amazon JumpStart UI を使用してリソースをクリーンアップできます。
Boto3 SDK を使用するには、次のコードを使用して、テキスト埋め込みモデル エンドポイントとテキスト生成モデル エンドポイント、およびエンドポイント構成を削除します。
SageMaker コンソールを使用するには、次の手順を実行します。
- SageMaker コンソールのナビゲーションペインの [推論] で、[エンドポイント] を選択します。
- 埋め込みエンドポイントとテキスト生成エンドポイントを検索します。
- エンドポイントの詳細ページで、[削除] を選択します。
- もう一度 [削除] を選択して確認します。
まとめ
検索と取得に重点を置いたユースケースの場合、LlamaIndex は柔軟な機能を提供します。 LLM のインデックス作成と取得に優れており、データを深く探索するための強力なツールになります。 LlamaIndex を使用すると、整理されたデータ インデックスの作成、多様な LLM の使用、LLM パフォーマンスを向上させるためのデータの増強、自然言語によるデータのクエリが可能になります。
この投稿では、LlamaIndex の重要な概念と機能をいくつか紹介しました。 RAG アプリケーションの構築には、埋め込みに GPT-J を使用し、LLM として Llama 2-Chat を使用しましたが、代わりに任意の適切なモデルを使用することもできます。 SageMaker JumpStart で利用可能なモデルの包括的な範囲を探索できます。
また、LlamaIndex が、LangChain などの他のフレームワークとデータを接続、インデックス付け、取得、統合するための強力で柔軟なツールをどのように提供できるかについても説明しました。 LlamaIndex の統合と LangChain を使用すると、より強力で多用途で洞察力に富んだ LLM アプリケーションを構築できます。
著者について
 ロミナ・シャリフプール博士 アマゾン ウェブ サービス (AWS) のシニア機械学習および人工知能ソリューション アーキテクトです。彼女は 10 年以上、ML と AI の進歩によって可能になる革新的なエンドツーエンド ソリューションの設計と実装を主導してきました。 Romina の関心分野は、自然言語処理、大規模言語モデル、および MLOps です。
ロミナ・シャリフプール博士 アマゾン ウェブ サービス (AWS) のシニア機械学習および人工知能ソリューション アーキテクトです。彼女は 10 年以上、ML と AI の進歩によって可能になる革新的なエンドツーエンド ソリューションの設計と実装を主導してきました。 Romina の関心分野は、自然言語処理、大規模言語モデル、および MLOps です。
 ニコール・ピント は、オーストラリアのシドニーを拠点とする AI/ML スペシャリスト ソリューション アーキテクトです。ヘルスケアと金融サービスにおける彼女の経歴は、顧客の問題を解決する上で独自の視点を与えてくれます。彼女は、機械学習を通じて顧客をサポートし、STEM 分野で次世代の女性に力を与えることに情熱を注いでいます。
ニコール・ピント は、オーストラリアのシドニーを拠点とする AI/ML スペシャリスト ソリューション アーキテクトです。ヘルスケアと金融サービスにおける彼女の経歴は、顧客の問題を解決する上で独自の視点を与えてくれます。彼女は、機械学習を通じて顧客をサポートし、STEM 分野で次世代の女性に力を与えることに情熱を注いでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

