アマゾンEMRスタジオ は、データ サイエンティストやデータ エンジニアが R、Python、Scala、PySpark で記述されたデータ エンジニアリングおよびデータ サイエンス アプリケーションを簡単に開発、視覚化、デバッグできるようにする統合開発環境 (IDE) です。 EMR Studio は、EMR Studio ワークスペースを介して、フルマネージドの Jupyter ノートブックと、Spark UI や YARN Timeline Server などのツールを提供します。 EMR Studio ワークスペースを EMR クラスターに接続し、EMR クラスターのコンピューティング能力を使用して、クラスター上でデータ サイエンス ジョブを実行できます。 データは多くの場合、管理されるデータ レイクに保存されます。 AWSレイクフォーメーションを使用すると、単純な付与または取り消しメカニズムを通じて、きめ細かいアクセス制御を適用できます。
喜んでご紹介します ランタイムの役割 EMR Studio ワークスペースの場合。 EMR Studio ワークスペースをアタッチするときに、ランタイム ロールを定義して EMR クラスターに割り当てることができるようになりました。 EMR クラスター上のジョブは、このランタイム ロールを使用して AWS リソースにアクセスします。 ランタイム ロールを構成した後、Lake Formation を使用して、EMR Studio ワークスペースによって送信されたジョブに対してきめ細かいデータ アクセス制御を適用することもできます。
以前は、EMR Studio ワークスペースを EMR クラスターに接続する場合、すべてのワークスペースで同じものを使用する必要がありました。 AWS IDおよびアクセス管理 (IAM) ロール - つまり、クラスターの アマゾン エラスティック コンピューティング クラウド (Amazon EC2) インスタンス プロファイル。 したがって、同じ EMR クラスターに接続されているすべてのワークスペースは同じデータ アクセス権を持っていました。 データ ソースへのアクセスを制御するには、各 EMR Studio ワークスペースで異なる EMR クラスターを使用する必要があり、複数の EMR インスタンス プロファイルが必要でした。
Amazon EMR 6.11 のリリース以降、EMR Studio ワークスペースを EMR クラスターにアタッチするときにランタイムロールを選択できるようになりました。 このランタイム ロールは、アクセスをワークスペース レベルに限定します。 EMR Studio ワークスペースから実行される Apache Livy ジョブと Apache Spark ジョブには、ランタイム ロールにアタッチされたポリシーによって許可されたデータとリソースのみにアクセスする権限が与えられます。 また、Lake Formation で管理されるデータ レイクからデータにアクセスする場合、Lake Formation のアクセス許可を使用して、きめ細かいデータ アクセス制御を適用できます。 これは、運用上のオーバーヘッドを削減するのに役立ちます。
この投稿では、EMR Studio ワークスペースのランタイム ロールを構成し、ランタイム ロールを使用して EMR クラスターにワークスペースをアタッチする方法を示します。 大企業は通常、複数の AWS アカウントを使用しており、それらのアカウントの多くは XNUMX つの AWS アカウントによって管理されるデータレイクにアクセスする必要がある可能性があるため、この例では XNUMX つの AWS アカウントを使用しています。 EMR Studio ランタイム ロールへのアクセスを制御し、Lake Formation を介してデータ レイク内のアカウント間でデータ アクセスを管理し、EMR ランタイム ロールにテーブル レベルと列レベルの権限を強制する方法について説明します。
ソリューションの概要
きめ細かいアクセス制御を実証するために、サンプルを作成します。 AWSグルー company という名前のデータベースを作成し、Lake Formation でデータベース権限を管理します。 データベースは XNUMX つの個別のテーブルで構成されます。
- 社員 – このテーブルには、従業員 ID、名前、部門、給与などの会社の従業員に関する情報が保存されます。
- 商品 – このテーブルには、製品 ID、名前、カテゴリ、価格など、会社が販売する製品に関する情報が保存されます。
データ アクセス制御を実証するために、次のデータ ユーザーを考慮します。
- アリス、営業チームのデータサイエンティスト – 彼女は、
productsテーブルと選択された列(uID、名前、部門など)employeesテーブル - ボブ、人事チームのデータ サイエンティスト – 彼は、次のすべての列への読み取り専用アクセス権を持っている必要があります。
employeesテーブルにアクセスする必要はありません。productsテーブル
クロスアカウントのデータ共有を実証するために、次の XNUMX つのアカウントを検討します。
- データプロデューサーアカウント – このアカウントを次のように呼びます
123456789012この投稿で。 このアカウントは生データを管理します Amazon シンプル ストレージ サービス (Amazon S3) そしてデータをデータレイクに書き込みます。 のcompanyデータベースとテーブルはこのアカウントにある必要があります。 - データ消費者アカウント – このアカウントを次のように呼びます
111122223333この投稿で。 このアカウントはデータ分析のためにユーザーによって直接アクセスされますが、データへの書き込みアクセス権はありません。 このアカウントには、アリスとボブがアクセスできる必要があります。
アーキテクチャは次のように実装されています。
- データ プロデューサー アカウントはデータ レイクを管理します。 生データは S3 バケットに保存され、AWS Glue データ カタログにカタログ化されます。
- データ プロデューサー アカウントの Lake Formation は、データ カタログを介したデータ アクセスを管理し、データ コンシューマー アカウントとのクロスアカウント データ共有を提供します。
- データ コンシューマー アカウントの Lake Formation は、テーブル レベルでのデータ レイクへのクロスアカウント アクセスと、きめ細かい Lake Formation 権限を制御します。 詳細については、以下を参照してください。 きめ細かいアクセス制御の方法.
- データ コンシューマー アカウントの EMR Studio ワークスペースは、EMR クラスターでジョブを実行するときにランタイム ロールを使用します。
- EMR クラスターは、データ コンシューマー アカウントの Glue データ カタログに接続し、アカウント間のデータ共有を通じてデータ レイクからデータをクエリします。
次の図は、このアーキテクチャを示しています。

次のセクションでは、Lake Formation を介してアカウント間でデータを共有し、ランタイム ロールを使用して EMR Studio ワークスペースを実行し、きめ細かいアクセス制御を実証する手順を説明します。
前提条件
次の前提条件が必要です。
データ プロデューサー アカウントでインフラストラクチャを作成する
インフラストラクチャ リソースを作成するには、次の手順を実行します。
- データ作成者の AWS アカウントにログインします (
123456789012). - 選択する 発射スタック CloudFormation テンプレートをデプロイして必要なリソースを作成します。

- データレイクバケットサフィックス、データレイクで使用される S3 バケットのサフィックスを入力します。 作成される S3 バケット全体の名前は次のようになります。
{AwsAccoundId}-{AwsRegion}-{DataLakeBucketSuffix}. - CloudFormation スタックが作成されたら、 出力 スタックのタブをクリックして値を取得します
DataLakeS3Bucket次のステップで使用します。
データ ファイルを作成し、データ プロデューサー アカウントの Amazon S3 にアップロードします。
データプロデューサー AWS アカウントの DataLakeS3BucketName にアップロードする権限を持つ IAM ID を使用するように AWS CLI を設定します (123456789012)、または、を使用して CloudShell にサインインできます。 AWSマネジメントコンソール。 次の手順を実行します。
- ローカル マシンで、cd コマンドを使用して選択したディレクトリに移動します。たとえば、次のようになります。
cd ~. - 実行する スクリプト
chmod 744 create_sample_data.sh && ./create_sample_data.sh <DataLakeS3BucketName>.
スクリプトはサブディレクトリを作成します tmp 現在の作業ディレクトリに、CSV ファイルでテスト データを作成し、ファイルを DataLakeS3BucketName S3バケット。
データ プロデューサー アカウントで Lake Formation をセットアップする
このセクションでは、データ プロデューサー アカウントで Lake Formation をセットアップする手順を説明します。
Lake Formation のクロスアカウント データ共有バージョン設定をセットアップする
Lake Formation は複数のデータ共有バージョンをサポートしています。 この投稿では、バージョン 3 を使用します。データ共有バージョン間の違いの詳細については、「」を参照してください。 クロスアカウント データ共有のバージョン設定の更新。 データ共有バージョンを変更するには、次を参照してください。 新しいバージョンを有効にするには.
Amazon S3 の場所をデータレイクの場所として登録する
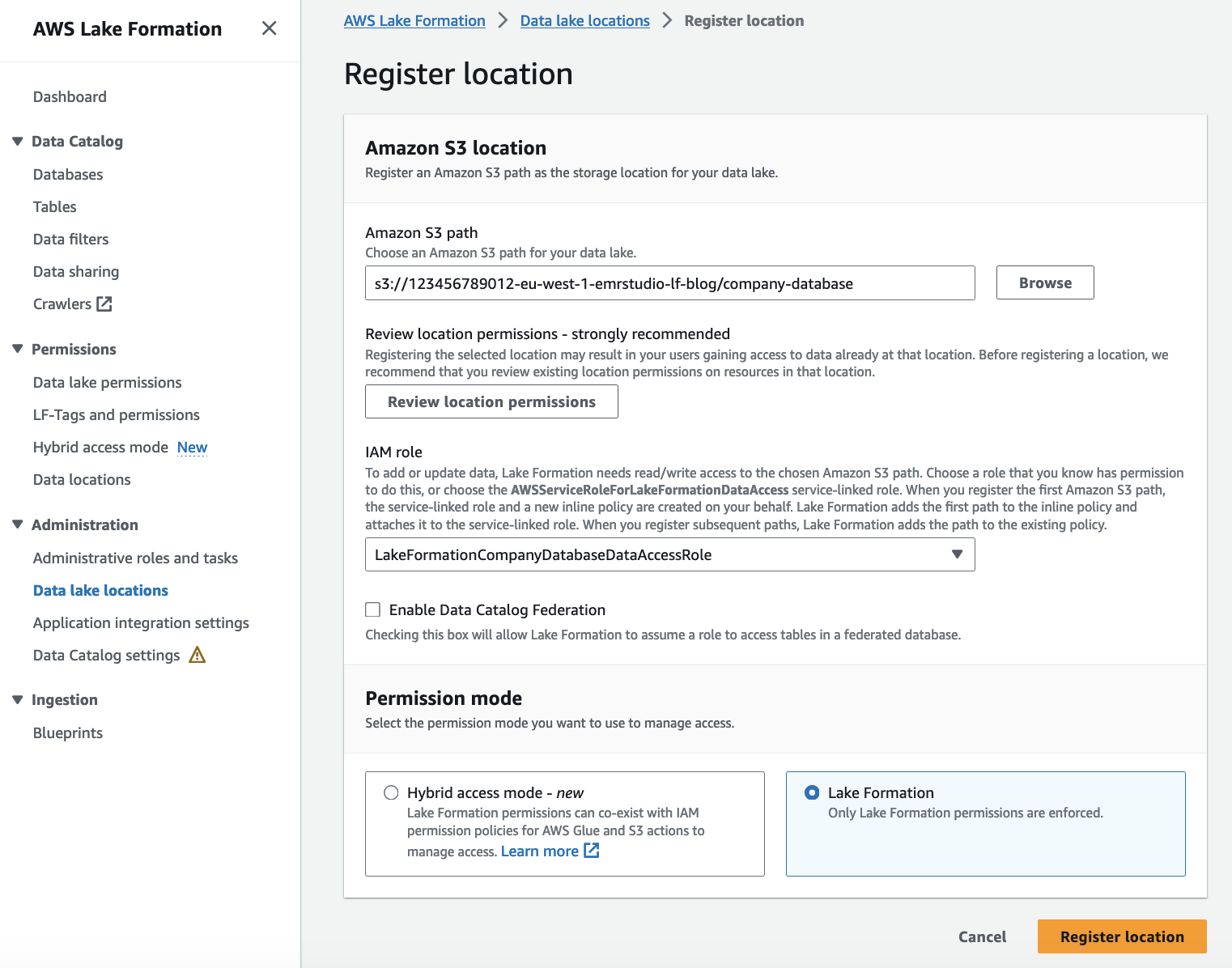
ときにあなたを Amazon S3 の場所を登録する Lake Formation では、その場所に対する読み取り/書き込み権限を持つ IAM ロールを指定します。 登録後、EMR クラスターがこの Amazon S3 ロケーションへのアクセスをリクエストすると、Lake Formation はデータにアクセスするために指定されたロールの一時的な認証情報を提供します。 すでにロールを作成しました LakeFormationCompanyDatabaseDataAccessRole この目的のために、前のステップで説明したとおりです。 Amazon S3 の場所をデータレイクの場所として登録するには、次の手順を実行します。
- データ プロデューサー アカウントの Lake Formation データ レイク管理者で Lake Formation コンソールを開きます (
123456789012). - ナビゲーションペインで、 データレイクの場所 下 管理部門.
- 選択する 登録場所.
- AmazonS3パス、 入る
s3://<DataLakeS3BucketName>/company-database. - IAMの役割、 入る
LakeFormationCompanyDatabaseDataAccessRole. - 許可モード選択 湖の形成.
- 選択する 登録場所.
IAMAllowedPrincipals に付与されたアクセス許可を取り消す
IAMAllowedPrincipals グループには、IAM ポリシーによって Data Catalog リソースへのアクセスが許可されている IAM ユーザーとロールが含まれます。 に 湖層形成モデルを強制する、 必要がある IAMAllowedPrincipals からの許可を取り消します 次の手順を使用します。
- データ プロデューサー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 「権限」の下のデータレイク権限.
- 権限をフィルタリングする
Database = company&Principle=IAMAllowedPrinciples. - プリンシパルに与えられたすべての権限を選択します
IAMAllowedPrincipals選択して 取り消す.

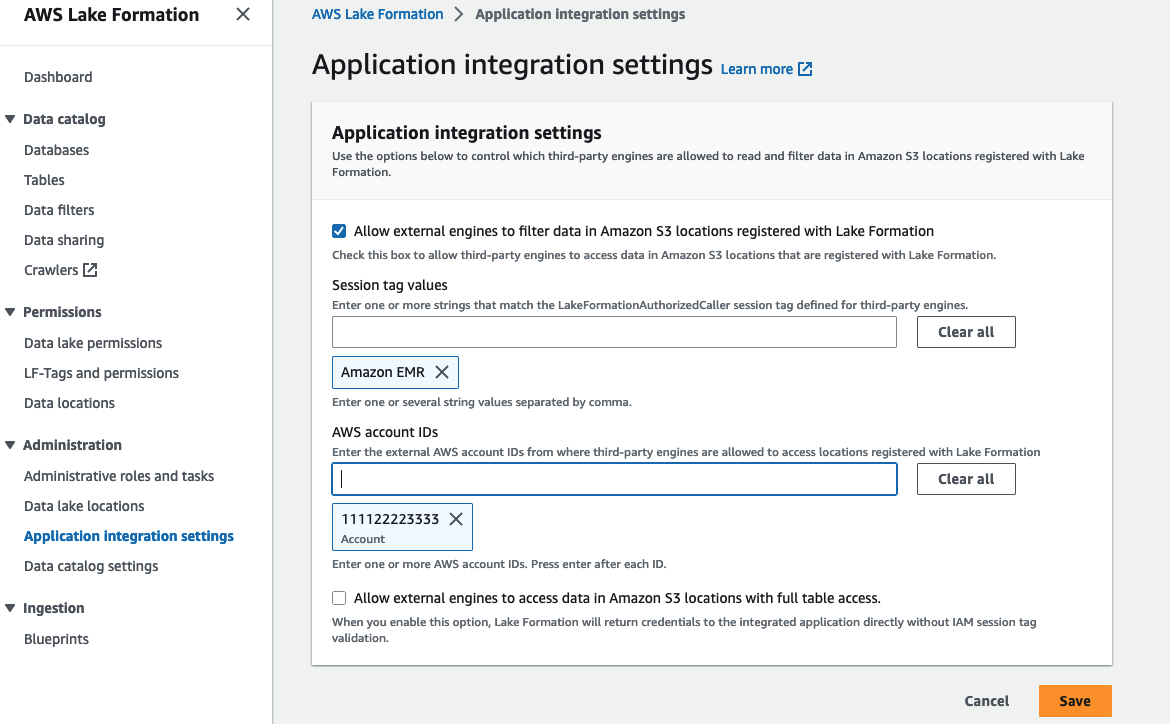
アプリケーション統合設定をセットアップする
EMR クラスターのアクセス許可を強制するには、Lake Formation にセッション タグ値を登録する必要があります。 Lake Formation は、このセッション タグを使用して呼び出し元を承認し、データ レイクへのアクセスを提供します。 登録します Amazon EMR セッションタグ値として。 この値は、 セキュリティ構成 EMR クラスターを作成するとき。
次の手順を使用してセッション タグを設定します。
- データ プロデューサー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- 選択する アプリケーション統合設定 下 管理部門 ナビゲーションペインに表示されます。
- 選択 外部エンジンが Lake Formation に登録された Amazon S3 ロケーションのデータをフィルタリングできるようにする.
- セッションタグの値、 入る
Amazon EMR. - AWS アカウント ID、データコンシューマーの AWS アカウント ID (
111122223333). - 選択する Save.
データベースとテーブルをデータ コンシューマー アカウントと共有する
ここで、付与可能なアクセス許可を含むアクセス許可をデータ コンシューマー AWS アカウントに付与します。 これにより、データ コンシューマー アカウントの Lake Formation データ レイク管理者は、アカウント内のデータへのアクセスを制御できるようになります。
データ コンシューマ アカウントにデータベース権限を付与します。
次の手順を完了します。
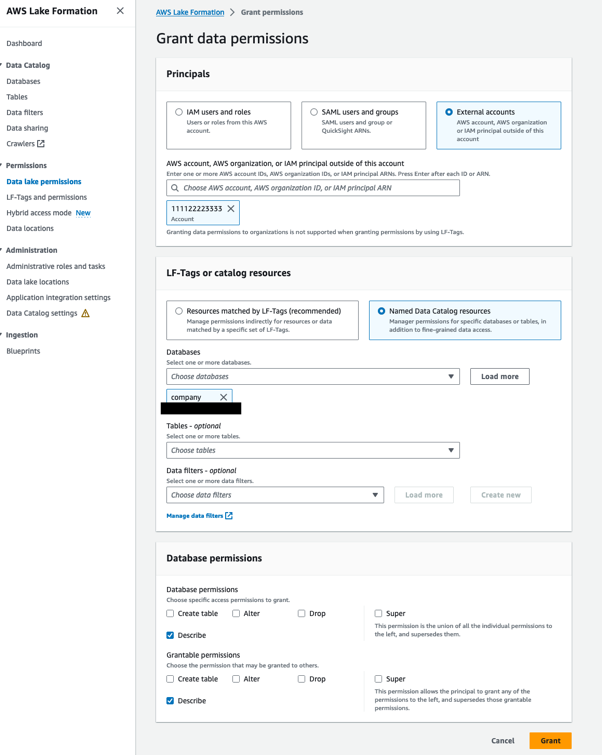
- データ プロデューサー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 データベース.
- データベースを選択します
company、そして メニュー、下 権限、選択する グラント. - 原則 セクション、選択 外部アカウント データ コンシューマの AWS アカウントを入力します (
111122223333). - LF-タグまたはカタログリソース セクションでは、選択
companyfor データベース. - データベースのアクセス許可 セクション、選択 説明する 両方のための データベースのアクセス許可 & 付与可能な権限.
これにより、データ コンシューマ アカウントのデータ レイク管理者はデータベースを記述し、データ コンシューマ アカウントの他のプリンシパルに記述権限を付与できるようになります。
- 選択する グラント.
データ コンシューマ アカウントにテーブル権限を付与します。
次の手順を完了します。
- データ プロデューサー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 テーブル類.
- 現在地に最も近い
productsに属するテーブルcompanyデータベース、および メニュー、下 権限、選択する グラント. - 原則 セクション、選択 外部アカウント データ コンシューマの AWS アカウントを入力します (
111122223333). - LF-タグまたはカタログリソース セクション、選択 名前付きデータカタログリソース 次のように指定します。
- データベース、選択する
company. - テーブル類、選択する
products&employees.
- データベース、選択する
- テーブルのアクセス許可 セクションでは、選択 選択 & 説明する 両方のための テーブルのアクセス許可 & 付与可能な権限.
これにより、データ コンシューマー アカウントのデータ レイク管理者はテーブルを選択して記述し、データ コンシューマー アカウントの他のプリンシパルにテーブルの選択と記述のアクセス許可を付与できるようになります。
- データ権限 セクション、選択 すべてのデータアクセス.
- 選択する グラント.

これでデータ プロデューサー アカウントの設定が完了しました。
データ コンシューマー アカウントでインフラストラクチャをセットアップする
インフラストラクチャ リソースを作成するには、次の手順を実行します。
- データ コンシューマ アカウントにログインします (
111122223333). - 選択する スタックを起動 CloudFormation テンプレートをデプロイして必要なリソースを作成します。

- リリース ラベル、使用する Amazon EMR リリース ラベルを入力します。これは emr-6.11 以降のみです。
- インスタンスタイプでは、EMR クラスターのインスタンス タイプ (r4.4xlarge など) を選択します。
- EMRS3バケット名サフィックス、EMR クラスター ログと EMR ノートブック ファイルを保存するための S3 バケット サフィックスを入力します。 作成される完全な S3 バケット名は次のようになります。
{AWSAccoundId}-{AWSRegion}-{EMRS3BucketNameSuffix}. - S3PathToInTransitCertificate、転送中の暗号化に使用される .pem ファイルを含む .zip ファイルの S3 パスを入力します。
.pem ファイルを含む .zip ファイルを作成し、S3 バケットにアップロードする手順については、を参照してください。 Amazon EMR 暗号化を使用して転送中のデータを暗号化するための証明書の提供.
- CloudFormation スタックが作成されたら、 出力 スタックのタブ。
- の価値を捉える
EMRStudioLinkEMR Studio へのサインインに使用します。
データ コンシューマー アカウントでのリソース共有を受け入れる
共有リソースにアクセスするには、まず招待を受け入れる必要があります。
- AWS RAM アクセス権を持つ IAM ID を使用して、データ コンシューマー アカウントの AWS RAM コンソールを開きます。
- ナビゲーションペインで、 リソース共有 下 私と共有.
データ プロデューサー アカウントからの XNUMX つの保留中のリソース共有が表示されるはずです。
- 両方のリソース共有を受け入れます。
あなたは company データベース、 employees テーブルと products データカタログのテーブル。
データ コンシューマー アカウントで Lake Formation をセットアップする
このセクションでは、データ コンシューマー アカウントで Lake Formation をセットアップする手順を説明します。
アプリケーション統合設定をセットアップする
データプロデューサーアカウントの設定と同様に、Amazon EMR をセッションタグとして登録する必要があります。 この値は、 セキュリティ構成 CloudFormation スタックで EMR クラスターを作成するとき。
これを行うには、次の手順を実行します。
- データ コンシューマー アカウントで Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます (
111122223333). - 選択する アプリケーション統合設定 下 管理部門 ナビゲーションペインに表示されます。
- 選択 外部エンジンが Lake Formation に登録された Amazon S3 ロケーションのデータをフィルタリングできるようにする.
- セッションタグの値、 入る
Amazon EMR. - AWS アカウント ID、データコンシューマーの AWS アカウント ID (
111122223333). - 選択する Save.
デフォルトデータベースのランタイムロールに説明権限を付与します。
Lake Formation にデフォルトのデータベースがない場合、またはデフォルトのデータベースに付与するアクセス許可がすでにある場合 IAMAllowedPrinciples、この手順は省略できます。
Amazon EMR は、デフォルトでデフォルトのデータベースをチェックします。 Lake Formation にデフォルトのデータベースがすでにある場合は、次の手順を実行して、デフォルトのデータベースのランタイム ロールに記述アクセス許可を付与します。
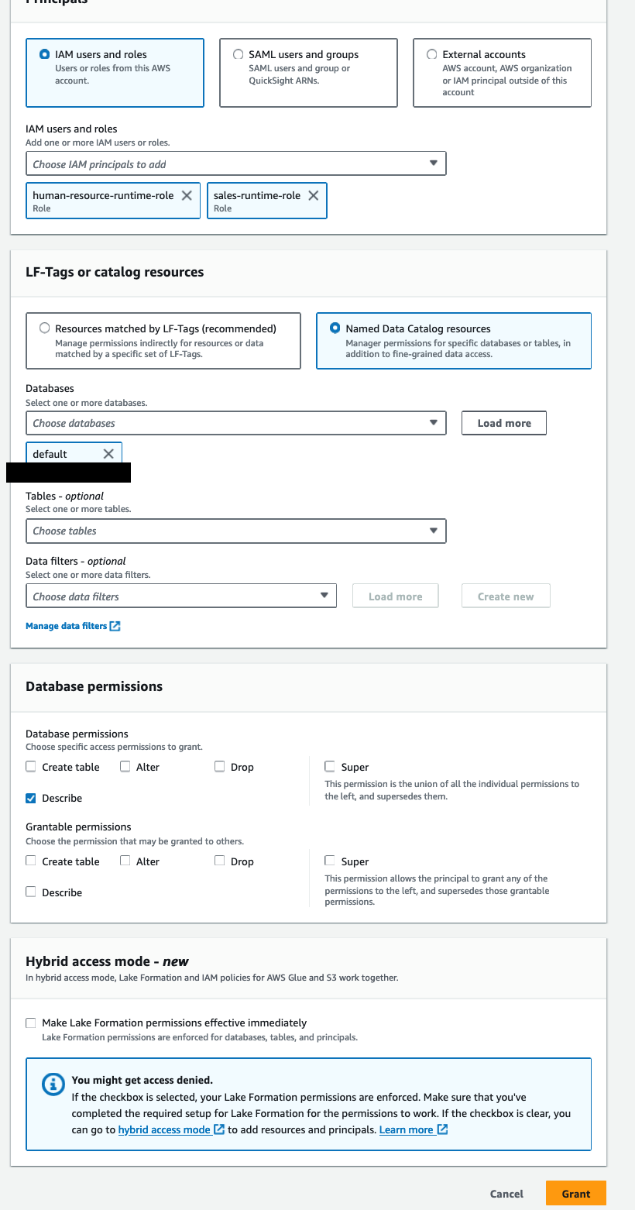
- データ コンシューマー アカウントの Lake Formation データ レイク管理者ユーザーを使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 データベース.
- デフォルトのデータベースを選択し、所有者アカウント ID がデータ コンシューマ アカウント (
111122223333)、および メニュー、選択 グラント. - 原則セクション選択 IAMユーザーとロール.
- IAMユーザーとロール、選択する
sales-runtime-role&human-resource-runtime-role. - LF-タグまたはカタログリソース選択 名前付きデータカタログリソース そしてデフォルトを選択します データベース.
- データベースのアクセス許可 セクション、 データベースのアクセス許可、選択する 説明する.
- 選択する グラント.
共有データベースのリソース リンクを作成する
データプロデューサーの AWS アカウントによって共有されたデータベースとテーブルのリソースにアクセスするには、 リソースリンク データコンシューマの AWS アカウント内。 リソース リンクは、ローカルまたは共有データベースまたはテーブルへのリンクである Data Catalog オブジェクトです。 データベースまたはテーブルへのリソース リンクを作成した後は、データベース名またはテーブル名を使用する場所に常にリソース リンク名を使用できます。 この手順では、リソース リンクに対するアクセス許可をランタイム ロールの原則に付与します。 ランタイム ロールは、リソース リンクを介して共有データベースと基になるテーブルのデータにアクセスします。
リソースリンクを作成するには、次の手順を実行します。
- データ コンシューマー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 データベース.
- 現在地に最も近い
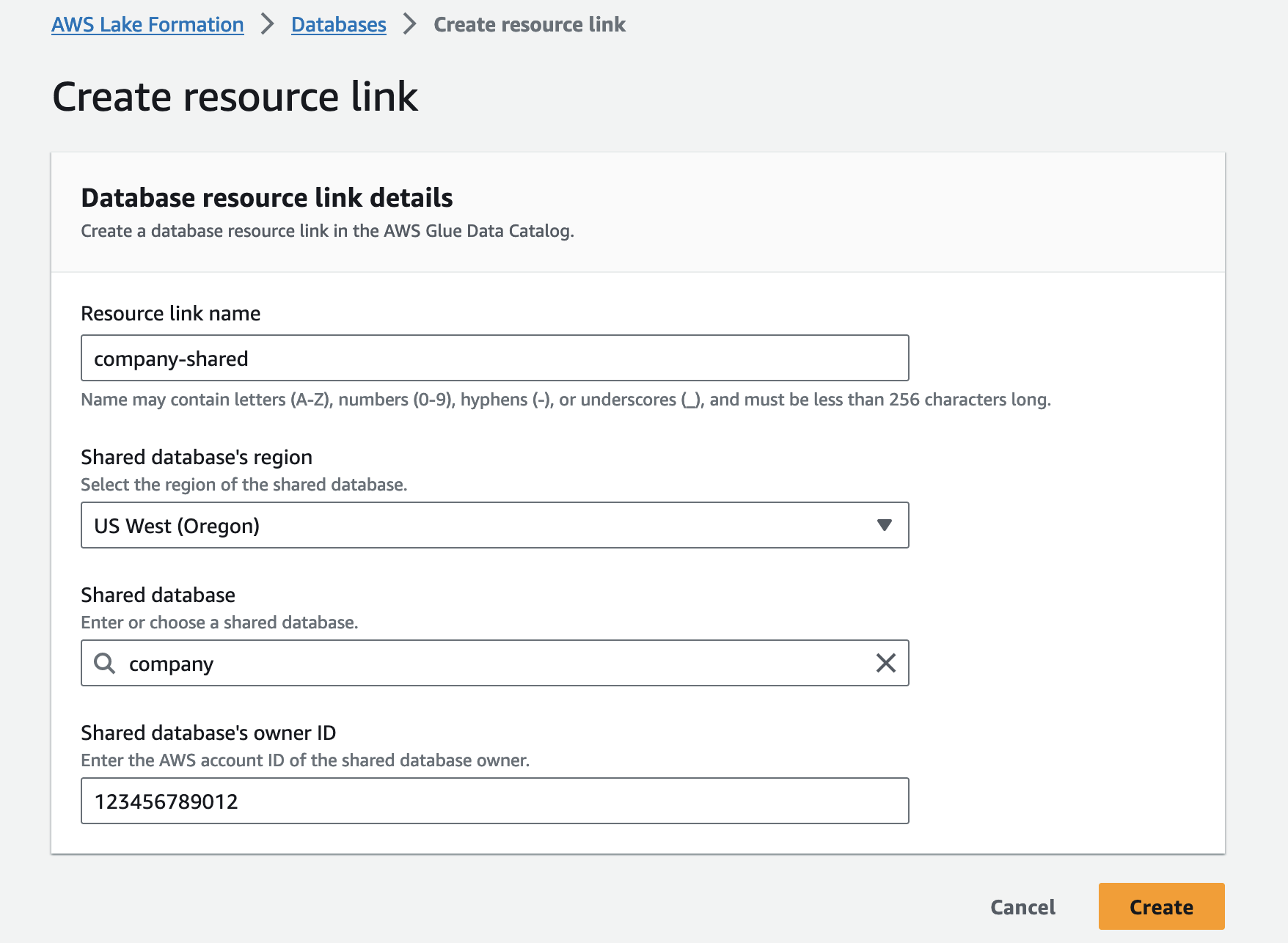
companyデータベースで、所有者のアカウント ID がデータ プロデューサー アカウント (123456789012)、および メニュー、選択 リソースリンクの作成. - リソースリンク名、リソース リンクの名前を入力します (例:
company-shared). - 共有データベースのリージョン、地域を選択します。
companyデータベース。 - 共有データベース、会社データベースを選択します。
- 共有データベースの所有者ID、データ プロデューサー アカウントのアカウント ID を入力します (
123456789012). - 選択する 創造する.
ランタイム ロールの原則へのリソース リンクに対するアクセス許可を付与します。
次の手順を使用して、リソース リンクに対する権限を sales-runtime-role および human-resource-runtime-role に付与します。
- データ コンシューマー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 データベース.
- リソースのリンク (
company-shared)と メニュー、選択 グラント. - 原則 セクション、選択 IAMユーザーとロール、選択して
sales-runtime-role&human-resource-runtime-role. - LF-タグまたはカタログリソース セクション、 データベース、選択する
company-shared. - リソースリンクのアクセス許可 セクション、選択 説明する.
これにより、ランタイム ロールでリソース リンクを記述できるようになります。 ランタイム ロールは他の原則にアクセス許可を付与できないようにする必要があるため、付与可能なアクセス許可の選択は行いません。
- 選択する グラント.
テーブルに対するアクセス許可をランタイム ロールの原則に付与する
テーブルに対する権限を付与する必要があります。 sales-runtime-role & human-resource-runtime-role データアクセスを許可するには:
Human-resource-runtime-roleのすべての列に対する説明と選択の権限が必要です。employeesテーブル、およびそのテーブルに対する権限がないproducts列で番号の横にあるXをクリックします。Sales-runtime-role列に対する選択権限が必要ですuid,name,departmentセクションにemployees表を作成し、その内のすべての列に対する権限を説明および選択します。products列で番号の横にあるXをクリックします。
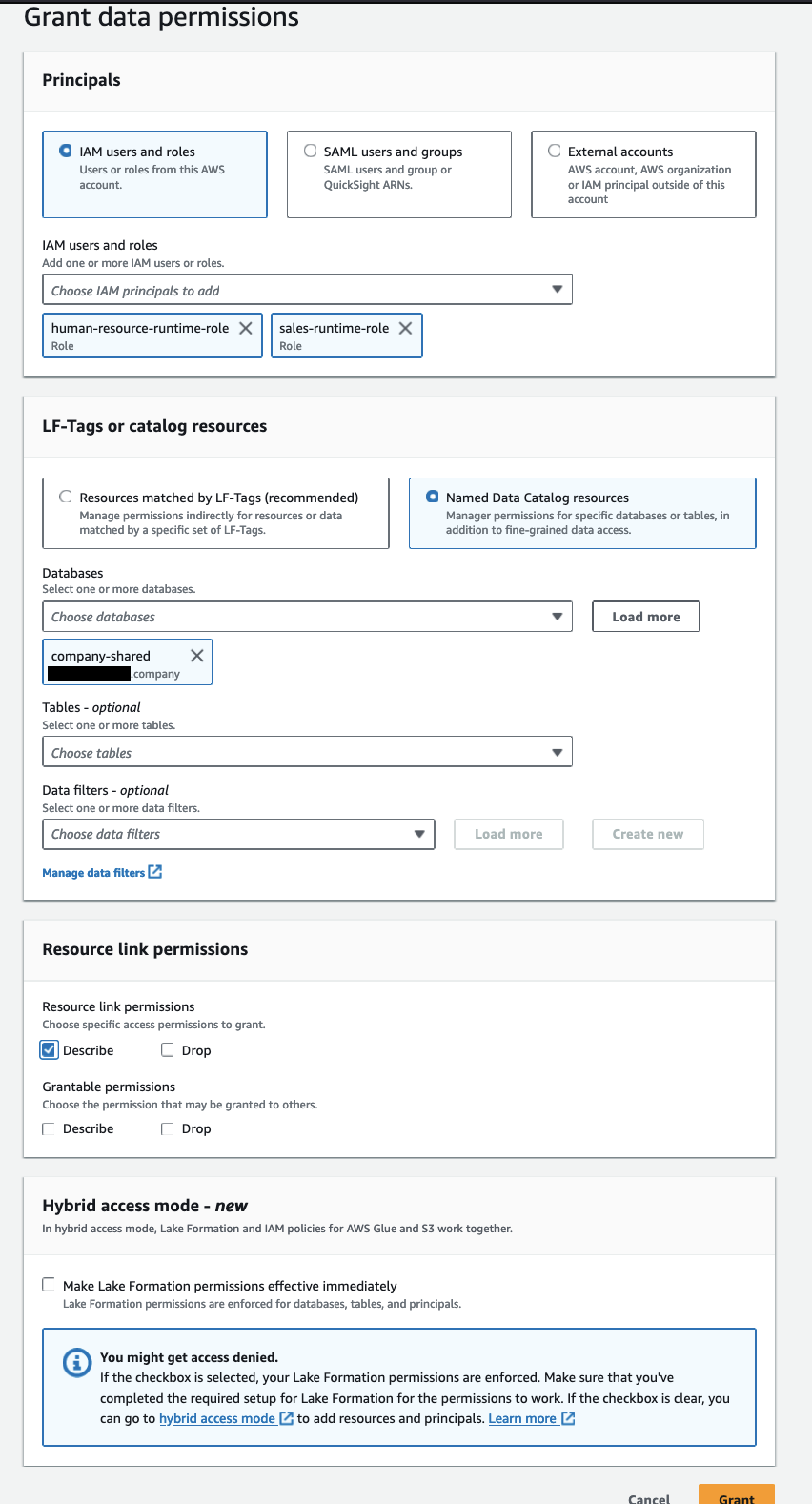
従業員テーブルに対する権限を human-resource-runtime-role に付与します。
次の手順を完了します。
- データ コンシューマー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 データベース.
- リソースのリンク (
company-shared)と メニュー、選択 目標に応じた助成金. - 原則セクション選択 IAMユーザーとロール、を選択します
human-resource-runtime-role. - LF-タグまたはカタログリソース セクション、選択 名前付きデータカタログリソース 次のように指定します。
- データベース、選択する
company. - テーブル類¸選ぶ
employees.
- データベース、選択する
- テーブルのアクセス許可 セクション、 テーブルのアクセス許可選択 説明する & 選択.
- データ権限 セクション、選択 すべてのデータアクセス.
- 選択する グラント.

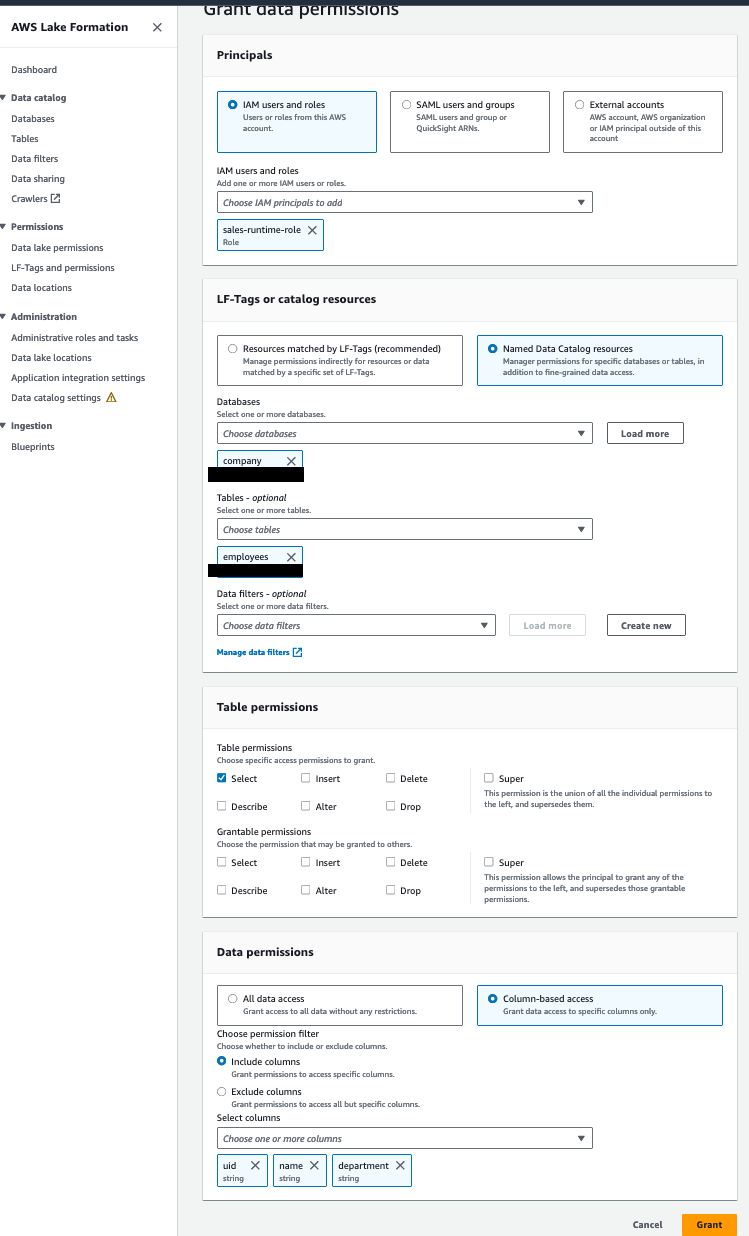
従業員テーブルに対する権限を sales-runtime-role に付与します。
次の手順を完了します。
- データ コンシューマー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 データベース.
- リソースのリンク (
company-shared)と メニュー、選択 目標に応じた助成金. - 原則セクション選択 IAMユーザーとロール、を選択します
sales-runtime-role. - LF-タグまたはカタログリソース セクション、選択 名前付きデータカタログリソース 次のように指定します。
- データベース、選択する
company. - テーブル類、選択する
employees.
- データベース、選択する
- テーブルのアクセス許可 セクション、 テーブルのアクセス許可選択 選択.
- データ権限 セクション、選択 列ベースのアクセス.
- 選択 列を含める を選択して
uid,name,department列。 - 選択する グラント.
products テーブルに対する権限を sales-runtime-role に付与します。
次の手順を完了します。
- データ コンシューマー アカウントの Lake Formation データ レイク管理者を使用して、Lake Formation コンソールを開きます。
- ナビゲーションペインで、 データベース.
- リソースのリンク (
company-shared)と メニュー、選択 目標に応じた助成金. - 原則セクション選択 IAMユーザーとロール、を選択します
sales-runtime-role. - LF-タグまたはカタログリソース セクション、選択 名前付きデータカタログリソース 次のように指定します。
- データベース、選択する
company. - テーブル類、選択する
products.
- データベース、選択する
- テーブルのアクセス許可 セクション、 テーブルのアクセス許可選択 選択 & 説明する.
- データ権限 セクション、選択 すべてのデータアクセス.
- 選択する グラント.

EMR Studio にログインし、EMR Studio ワークスペースを使用します
役割を切り替えます 〜へ alice-role or bob-role コンソールでさまざまな Web ブラウザを使用してアクセスをテストします。 を開きます。 EMRStudioLink CloudFormation スタック出力の URL を使用して各ロールで EMR Studio にサインインし、次の手順を実行します。
- 選択する ワークスペース ナビゲーションペインで、 ワークスペースを作成する.
- ワークスペースの名前と説明を入力します。
- 選択する ワークスペースを作成する.
ワークスペースの準備が完了すると、JupyterLab を含む新しいタブが自動的に開きます。 必要に応じてブラウザのポップアップを有効にします。
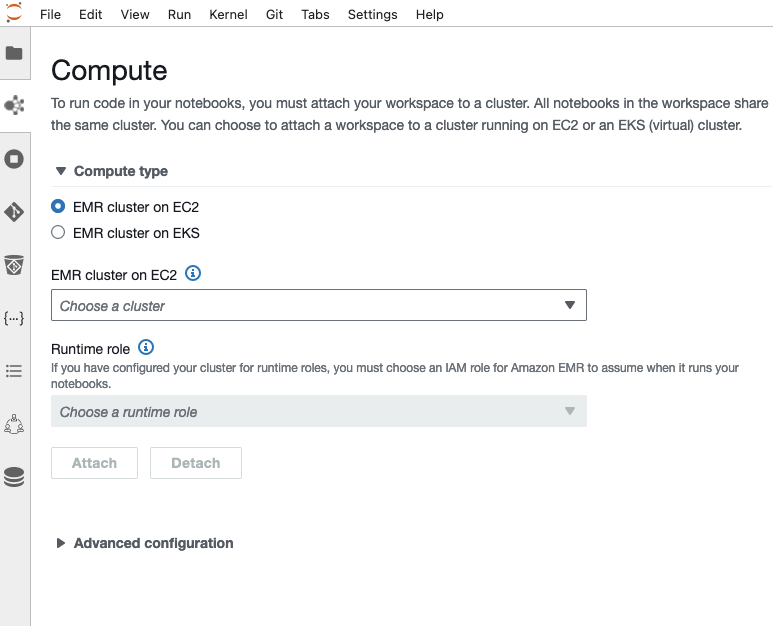
- を選択しました 計算 ナビゲーション ペインの アイコンをクリックして、EMR Studio ワークスペースをコンピューティング エンジンに接続します。
- 選択 EC2 上の EMR クラスター for 計算タイプ.
- AWS CloudFormation で作成した EMR クラスター ID を選択します。
- ランタイムの役割、選択する
sales-runtime-roleとしてサインインしている場合alice-role。 選択してくださいhuman-resource-runtime-roleとしてサインインしている場合bob-role. - 選択する 添付する.
EMR Studio ワークスペースでコードを実行し、データ アクセスを確認する
alice-role または bob-role でサインインした後、PySpark カーネルを使用して EMR Studio ワークスペースで次のコードを実行します。
異なるロールを使用すると、異なる結果が表示されるはずです。
Lake Formation のデータ アクセス構成によれば、Alice は、 products テーブル。 彼女は、給与を除くすべての列を表示できます。 employees 列で番号の横にあるXをクリックします。
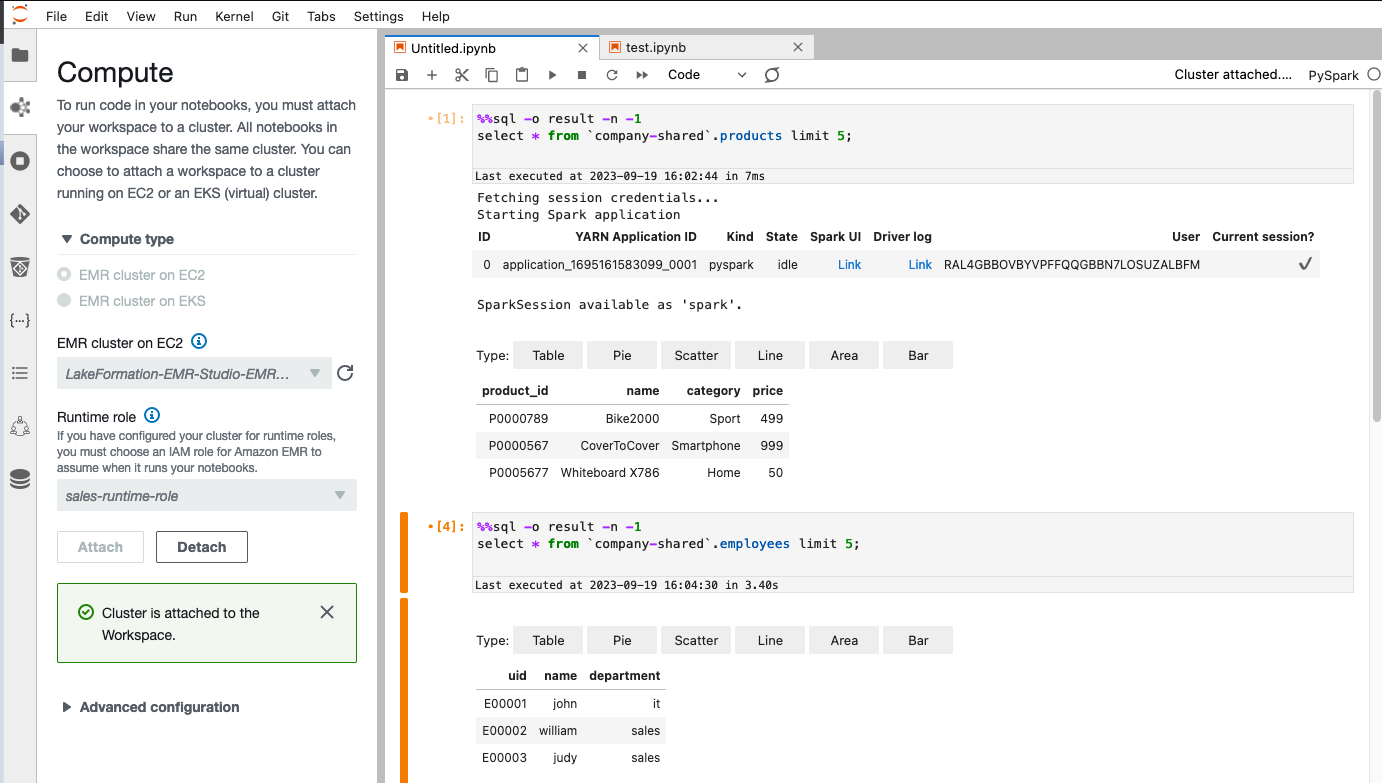
ボブの場合、Lake Formation のデータ アクセス構成に従って、彼は employees テーブルにアクセスできませんが、 products 列で番号の横にあるXをクリックします。

クリーンアップ
このソリューションの実験が終了したら、リソースをクリーンアップします。
- データ コンシューマー AWS アカウントで作成された EMR Studio ワークスペースを停止して削除します。
- S3バケット内のすべてのコンテンツを削除します
EMRS3Bucketデータコンシューマの AWS アカウント内。 - データ コンシューマー AWS アカウントの CloudFormation スタックを削除します。
- S3バケット内のすべてのコンテンツを削除します
DataLakeS3Bucketデータプロデューサーの AWS アカウント内。 - データプロデューサー AWS アカウントの CloudFormation スタックを削除します。
まとめ
この投稿では、ランタイムロールを使用して Amazon EMR で EMR Studio ワークスペースに接続し、Lake Formation でクロスアカウントのきめ細かいデータアクセス制御を適用する方法を説明しました。 また、複数の EMR Studio ユーザーが、データへの個別のアクセス レベルに一致する権限を範囲とするランタイム ロールを使用して、同じ EMR クラスターに接続する方法も実証しました。
Lake Formation での EMR Studio ワークスペースの使用の詳細については、次を参照してください。 ランタイム ロールを使用して EMR Studio ワークスペースを実行する。 ぜひこの新機能を試してみて、ご質問やフィードバックがございましたらお問い合わせください。
著者について
 アシュリー・チョウ AWS のソフトウェア開発エンジニアです。 彼女はデータ分析と分散システムに興味があります。
アシュリー・チョウ AWS のソフトウェア開発エンジニアです。 彼女はデータ分析と分散システムに興味があります。
 シュリヴィディヤ・パルタサラティ AWS Lake Formation チームのシニア ビッグデータ アーキテクトです。 彼女は、AWS で分析およびデータ メッシュ ソリューションを構築し、それらをコミュニティと共有することを楽しんでいます。
シュリヴィディヤ・パルタサラティ AWS Lake Formation チームのシニア ビッグデータ アーキテクトです。 彼女は、AWS で分析およびデータ メッシュ ソリューションを構築し、それらをコミュニティと共有することを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/use-iam-runtime-roles-with-amazon-emr-studio-workspaces-and-aws-lake-formation-for-cross-account-fine-grained-access-control/

