これは、GoDaddy の Brandon Abear、Dinesh Sharma、John Bush、Ozcan IIikhan との共同執筆によるゲスト投稿です。
GoDaddyは オンラインで成功するためのあらゆるヘルプとツールを提供することで、日常の起業家を支援します。 世界中に 20 万人以上の顧客を抱える GoDaddy は、人々が自分のアイデアに名前を付け、専門的な Web サイトを構築し、顧客を引き付け、仕事を管理する場所です。
GoDaddy では、データドリブンな企業であることに誇りを持っています。データから貴重な洞察を絶え間なく追求することで、ビジネス上の意思決定が促進され、顧客満足度が保証されます。効率性に対する当社の取り組みは揺るぎないものであり、バッチ処理ジョブを最適化するためのエキサイティングな取り組みに着手しました。この取り組みの中で、私たちは改善機会の 7 層と呼ぶ構造化されたアプローチを特定しました。この方法論は、効率を追求する際の指針となっています。
この投稿では、どのようにして業務効率を向上させたかについて説明します。 Amazon EMR サーバーレス。ベンチマーク結果と方法論、および EMR サーバーレスと固定容量の費用対効果に関する洞察を共有します。 EC2 上の Amazon EMR を使用してオーケストレーションされたデータ ワークフロー上の一時クラスター ApacheAirflowのAmazonマネージドワークフロー (アマゾンMWAA)。 EMR サーバーレスが得意とする分野での導入戦略を共有します。私たちの調査結果では、60% 以上のコスト削減、Spark ワークロードの 50% 高速化、開発およびテスト速度の XNUMX 倍の顕著な向上、二酸化炭素排出量の大幅な削減など、大きなメリットがあることが明らかになりました。
経歴
2020 年後半、GoDaddy のデータ プラットフォームは AWS クラウドへの移行を開始し、800 PB のデータを含む 2.5 ノードの Hadoop クラスターをデータセンターから EC2 上の EMR に移行しました。このリフトアンドシフト アプローチにより、オンプレミス環境とクラウド環境の直接比較が容易になり、AWS パイプラインへのスムーズな移行が保証され、データ検証の問題と移行の遅延が最小限に抑えられます。
2022 年初めまでに、ビッグ データ ワークロードを EC2 上の EMR に移行することに成功しました。 AWS FinHack プログラムから学んだベストプラクティスを使用して、リソースを大量に消費するジョブを微調整し、Pig および Hive ジョブを Spark に変換し、22.75 年にバッチ ワークロードの支出を 2022% 削減しました。しかし、ジョブの数が多いため、スケーラビリティの課題が浮上しました。 。これにより、GoDaddy は体系的な最適化の取り組みに着手し、より持続可能で効率的なビッグデータ処理の基盤を確立しました。
改善の機会の 7 つの層
運用効率を追求する中で、次の図に示すように、バッチ処理ジョブ内で最適化の機会を 7 つの異なる層に分けて特定しました。これらのレイヤーは、正確なコードレベルの機能強化から、より包括的なプラットフォームの改善まで多岐にわたります。この多層アプローチは、より優れたパフォーマンスとより高い効率を継続的に追求する際の戦略的な青写真となっています。

レイヤーは次のとおりです。
- コードの最適化 – コード ロジックを改良し、パフォーマンスを向上させるためにコード ロジックを最適化する方法に焦点を当てます。これには、選択的キャッシュ、パーティションとプロジェクションのプルーニング、結合の最適化、その他のジョブ固有のチューニングによるパフォーマンスの強化が含まれます。 AI コーディング ソリューションの使用も、このプロセスの不可欠な部分です。
- ソフトウェアの更新 - オープンソース ソフトウェア (OSS) の最新バージョンに更新して、新機能や改善点を活用します。たとえば、Spark 3 のアダプティブ クエリ実行は、パフォーマンスとコストの大幅な向上をもたらします。
- カスタム Spark 構成 – リソース使用率、メモリ、並列処理を最大化するためのカスタム Spark 構成のチューニング。タスクの規模を適切に設定することで、大幅な改善を達成できます。
spark.sql.shuffle.partitions,spark.sql.files.maxPartitionBytes,spark.executor.cores,spark.executor.memory。ただし、これらのカスタム構成は、特定の Spark バージョンと互換性がない場合、逆効果になる可能性があります。 - リソースのプロビジョニング時間 – 一時的な EMR クラスターなどのリソースを起動するのにかかる時間 アマゾン エラスティック コンピューティング クラウド (アマゾンEC2)。この時間に影響を与える一部の要因はエンジニアの制御の範囲外ですが、最適化できる要因を特定して対処することは、全体的なプロビジョニング時間の短縮に役立ちます。
- タスクレベルでのきめ細かいスケーリング – タスク内の各段階のニーズに基づいて、CPU、メモリ、ディスク、ネットワーク帯域幅などのリソースを動的に調整します。ここでの目的は、リソースの浪費につながる可能性のある固定クラスター サイズを回避することです。
- ワークフロー内の複数のタスクにわたるきめ細かいスケーリング – 各タスクに固有のリソース要件があることを考慮すると、固定リソース サイズを維持すると、同じワークフロー内の特定のタスクのプロビジョニングが不足または過剰になる可能性があります。従来、マルチタスク ワークフローのクラスター サイズは最大のタスクのサイズによって決まります。ただし、ワークフロー内の複数のタスクやステップにわたってリソースを動的に調整すると、よりコスト効率の高い実装が可能になります。
- プラットフォームレベルの機能強化 – 先行層での機能強化は、特定のジョブまたはワークフローのみを最適化できます。プラットフォームの改善は、企業レベルでの効率化を目指します。これは、コア インフラストラクチャの更新またはアップグレード、新しいフレームワークの導入、各ジョブ プロファイルに適切なリソースの割り当て、サービス利用のバランス調整、Savings Plan とスポット インスタンスの使用の最適化、または効果を高めるためのその他の包括的な変更の実装など、さまざまな手段を通じて実現できます。すべてのタスクとワークフロー全体の効率を高めます。
レイヤ 1 ~ 3: 以前のコスト削減
オンプレミスから AWS クラウドに移行した後、私たちは主に、図に示す最初の 3 つのレイヤーにコスト最適化の取り組みを集中しました。最もコストのかかるレガシー Pig および Hive パイプラインを Spark に移行し、Amazon EMR 用に Spark 構成を最適化することで、大幅なコスト削減を達成しました。
たとえば、従来の Pig ジョブは完了までに 10 時間かかり、最も高価な EMR ジョブのトップ 10 にランクされました。 TEZ ログとクラスター メトリックを確認したところ、クラスターが処理中のデータ量に対して大幅に過剰にプロビジョニングされており、ランタイムのほとんどで十分に活用されていないことがわかりました。 Pig から Spark への移行はより効率的でした。変換に使用できる自動ツールはありませんでしたが、次のような手動の最適化が行われました。
- 不必要なディスク書き込みを削減し、シリアル化と逆シリアル化の時間を節約します (レイヤー 1)
- Airflow タスクの並列化を Spark に置き換え、Airflow DAG (レイヤー 1) を簡素化しました。
- 冗長な Spark 変換を排除しました (レイヤー 1)
- アダプティブ クエリ実行 (レイヤー 2) を使用して、Spark 3 から 2 にアップグレードされました。
- 歪んだ結合に対処し、より小さいディメンション テーブルを最適化しました (レイヤー 3)
その結果、作業コストは 95% 削減され、作業完了時間は 1 時間に短縮されました。ただし、このアプローチは労働集約的であり、多くのジョブに拡張可能ではありませんでした。
レイヤ 4 ~ 6: 適切なコンピューティング ソリューションを見つけて採用する
2022 年後半、以前のレベルでの最適化における重要な成果に続き、残りのレイヤーの強化に注意が移りました。
バッチ処理の状態を理解する
当社は Amazon MWAA を使用して、クラウド内のデータ ワークフローを大規模に調整します。 ApacheAirflow と呼ばれるプロセスとタスクのシーケンスをプログラムで作成、スケジュール、監視するために使用されるオープンソース ツールです。 ワークフロー。この投稿での用語は、 ワークフロー & ジョブ は同じ意味で使用され、Amazon MWAA によって調整されたタスクで構成される有向非巡回グラフ (DAG) を指します。各ワークフローには、順次タスクまたは並列タスクがあり、さらには、間の DAG 内で両方の組み合わせも存在します。 create_emr & terminate_emr タスクは、ワークフローの実行全体を通じて固定のコンピューティング能力を備えた一時的な EMR クラスター上で実行されます。次の図に示すように、ワークロードの一部を最適化した後でも、ワークフロー内で最もリソースを消費するタスクに基づいたコンピューティング リソースの過剰プロビジョニングにより、十分に活用されていない最適化されていないワークフローが多数残っていました。
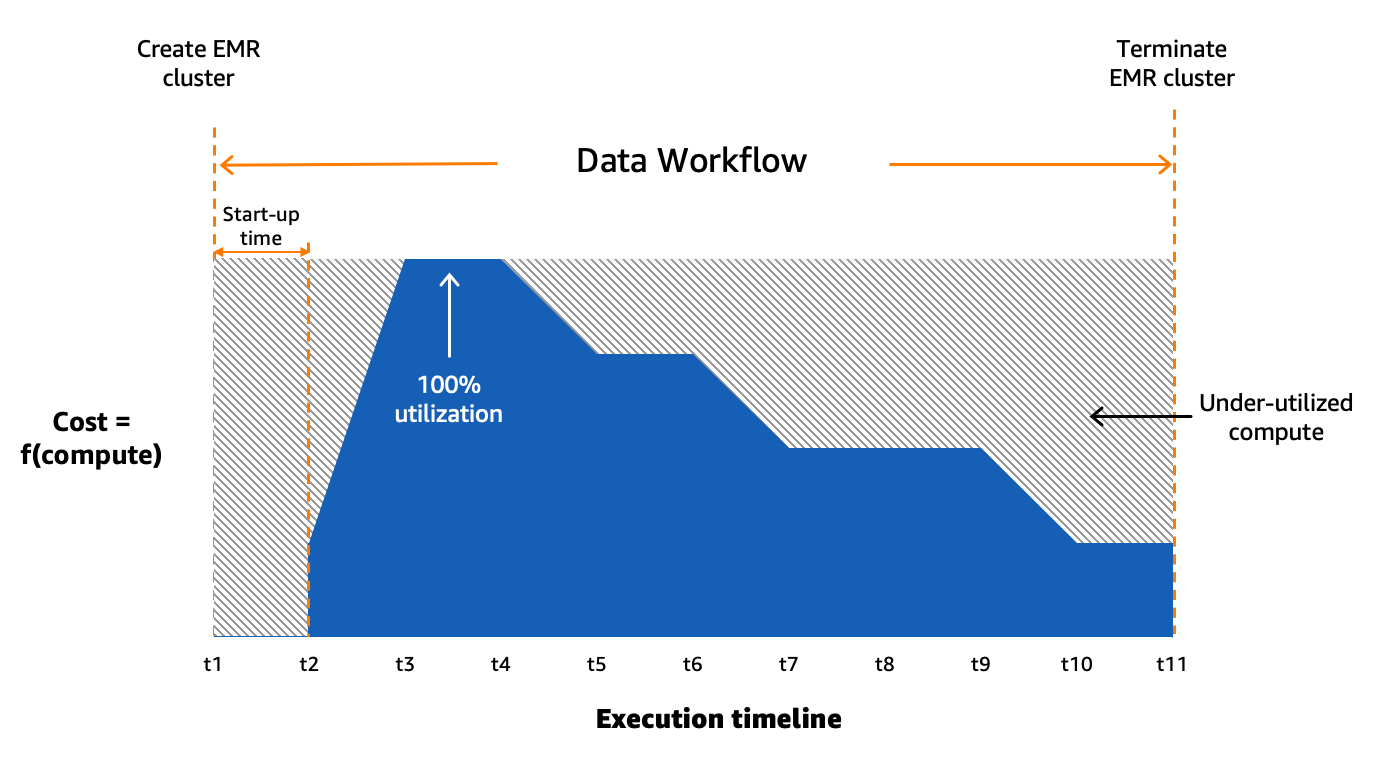
これにより、静的なリソース割り当ての非現実性が浮き彫りになり、動的リソース割り当て (DRA) システムの必要性が認識されるようになりました。ソリューションを提案する前に、バッチ処理を徹底的に理解するために広範なデータを収集しました。プロビジョニング時間とアイドル時間を除いたクラスターのステップ時間を分析すると、ワークフローの半分以上が 20 分以内に完了し、10 分以上かかっているのはわずか 60% という右に偏った分布であるという重要な洞察が明らかになりました。この分散により、高速プロビジョニング コンピューティング ソリューションが選択され、ワークフローの実行時間が大幅に短縮されました。次の図は、バッチ処理アカウントの 2 つにおける ECXNUMX 一時クラスター上の EMR のステップ時間 (プロビジョニングとアイドル時間を除く) を示しています。
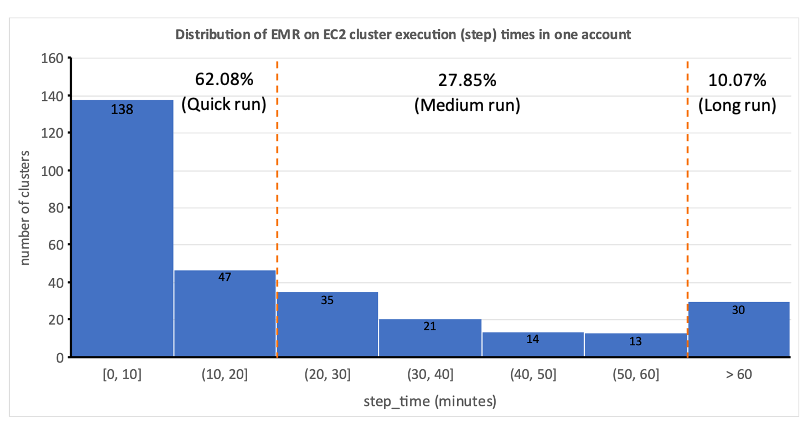
さらに、ワークフローのステップ時間 (プロビジョニング時間とアイドル時間を除く) の分布に基づいて、ワークフローを 3 つのグループに分類しました。
- クイックラン – 持続時間は 20 分以内
- 中程度の実行 – 20 ~ 60 分間続きます
- ロングラン – 60 分を超え、多くの場合は数時間以上にわたる
考慮する必要があったもう 1 つの要素は、セキュリティ、ジョブとコストの分離、専用クラスターなどの理由から、一時クラスターを広範囲に使用することでした。さらに、ピーク時と使用率が低い時間帯では、リソースの必要量に大きな変化がありました。
固定サイズのクラスターの代わりに、EC2 上の EMR でマネージド スケーリングを使用して、コスト上の利点を実現できる可能性があります。ただし、EMR サーバーレスへの移行は、当社のデータ プラットフォームにとってより戦略的な方向性であると思われます。 EMR サーバーレスは、潜在的なコスト上の利点に加えて、最新の Amazon EMR バージョンへのワンクリックアップグレード、簡素化された操作およびデバッグエクスペリエンス、ロールアウト時の最新世代への自動アップグレードなどの追加の利点を提供します。これらの機能を組み合わせることで、大規模なプラットフォームの運用プロセスが簡素化されます。
EMR サーバーレスの評価: GoDaddy でのケーススタディ
EMR サーバーレスは、Apache Spark や Apache Hive などのビッグデータ フレームワークを実行する際のクラスターの構成、管理、スケーリングの複雑さを解消する Amazon EMR のサーバーレス オプションです。 EMR サーバーレスを使用すると、企業は、費用対効果、迅速なプロビジョニング、簡素化された開発者エクスペリエンス、アベイラビリティーゾーンの障害に対する回復力の向上など、数多くのメリットを享受できます。
EMR サーバーレスの可能性を認識し、実際の運用ワークフローを使用して詳細なベンチマーク調査を実施しました。この調査は、EMR サーバーレスのパフォーマンスと効率を評価すると同時に、大規模な実装のための導入計画を作成することを目的としていました。この調査結果は非常に心強いもので、EMR サーバーレスがワークロードを効果的に処理できることを示しています。
ベンチマーク方法論
データ ワークフローは、合計ステップ時間 (プロビジョニングとアイドル時間を除く) に基づいて、クイック実行 (0 ~ 20 分)、中程度の実行 (20 ~ 60 分)、および長時間実行 (60 分以上) の 2 つのカテゴリに分割されています。私たちは、全体的な評価基準として機能する、コスト効率と総実行時間の高速化という XNUMX つの主要な指標に対する EMR 導入タイプ (Amazon ECXNUMX 対 EMR サーバーレス) の影響を分析しました。使いやすさと復元力を正式に測定したわけではありませんが、評価プロセス全体を通じてこれらの要素が考慮されました。
環境を評価するための高レベルの手順は次のとおりです。
- データと環境を準備します。
- 各ジョブ カテゴリから 3 ~ 5 つのランダムな生産ジョブを選択します。
- 生産への干渉を防ぐために必要な調整を実施します。
- テストを実行します。
- スクリプトを数日間または複数回繰り返し実行して、正確で一貫したデータ ポイントを収集します。
- EC2 および EMR サーバーレスで EMR を使用してテストを実行します。
- データを検証し、テストを実行します。
- 入力および出力のデータセット、パーティション、行数を検証して、同一のデータ処理を保証します。
- メトリクスを収集し、結果を分析します。
- テストから関連する指標を収集します。
- 結果を分析して洞察と結論を引き出します。
ベンチマーク結果
ベンチマークの結果では、20 つのジョブ カテゴリすべてにおいて、実行時間の高速化とコスト効率の両方において大幅な強化が見られました。改善は素早いジョブで最も顕著であり、起動時間の短縮が直接の結果でした。たとえば、固定コンピューティング容量の EC2 一時クラスター上の EMR で実行される 10 分間のデータ ワークフロー (クラスターのプロビジョニングとシャットダウンを含む) は、EMR サーバーレスでは XNUMX 分で終了し、実行時間が短縮され、コスト面でのメリットが得られます。全体として、EMR サーバーレスへの移行により、次の図に示すように、ジョブ ブラケット全体にわたって大幅なパフォーマンスの向上とコスト削減が実現しました。
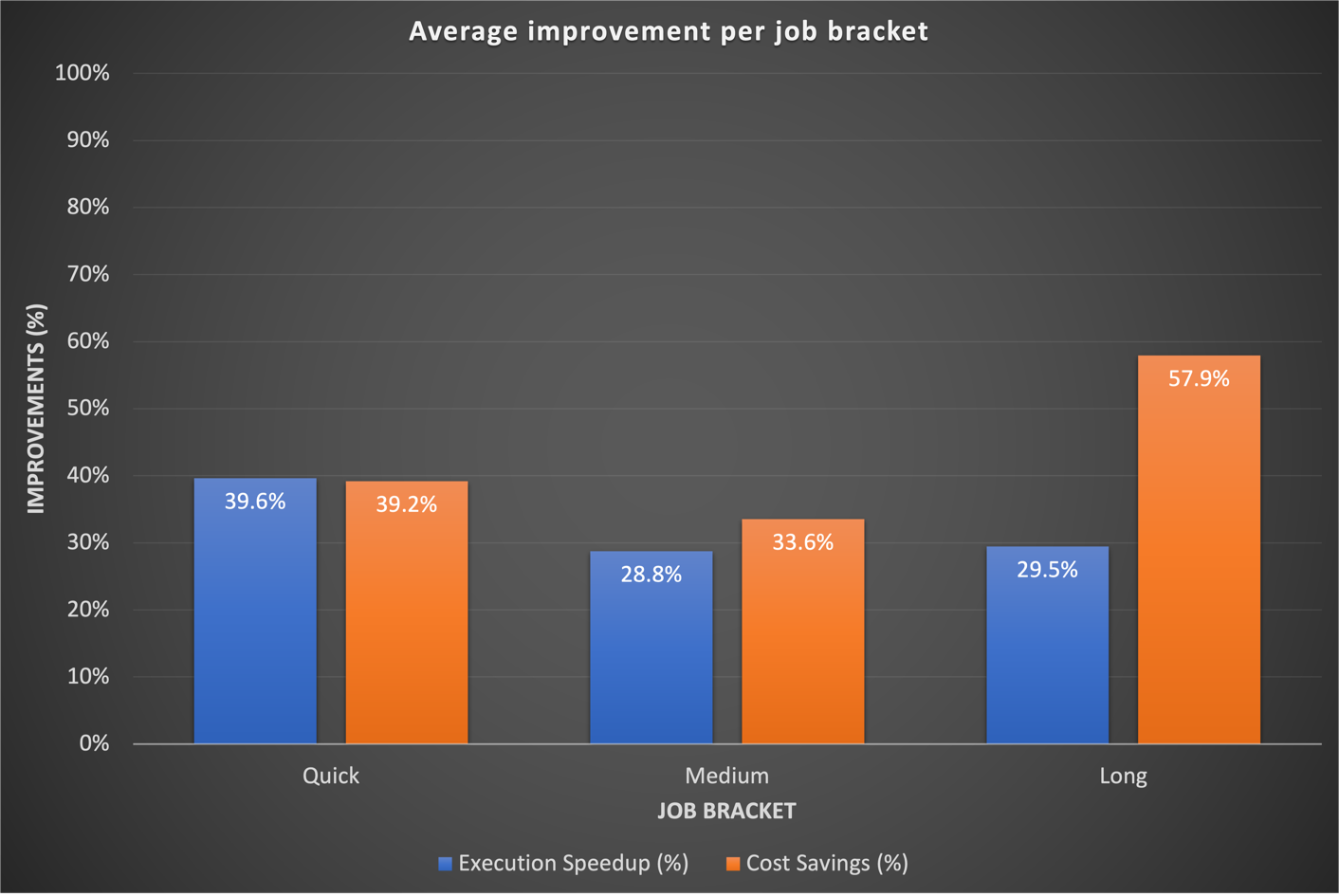
これまで、私たちは長期的なワークフローの調整により多くの時間を費やしてきました。興味深いことに、これらのジョブの既存のカスタム Spark 構成が EMR サーバーレスに必ずしも適切に変換されるわけではないことがわかりました。結果が重要ではない場合、一般的なアプローチは、executor コアに関連する以前の Spark 構成を破棄することでした。 EMR サーバーレスがこれらの Spark 構成を自律的に管理できるようにすることで、多くの場合、結果の向上が観察されました。次のグラフは、EMR サーバーレスと EC2 上の EMR を比較した場合の、ジョブあたりの平均実行時間とコストの改善を示しています。
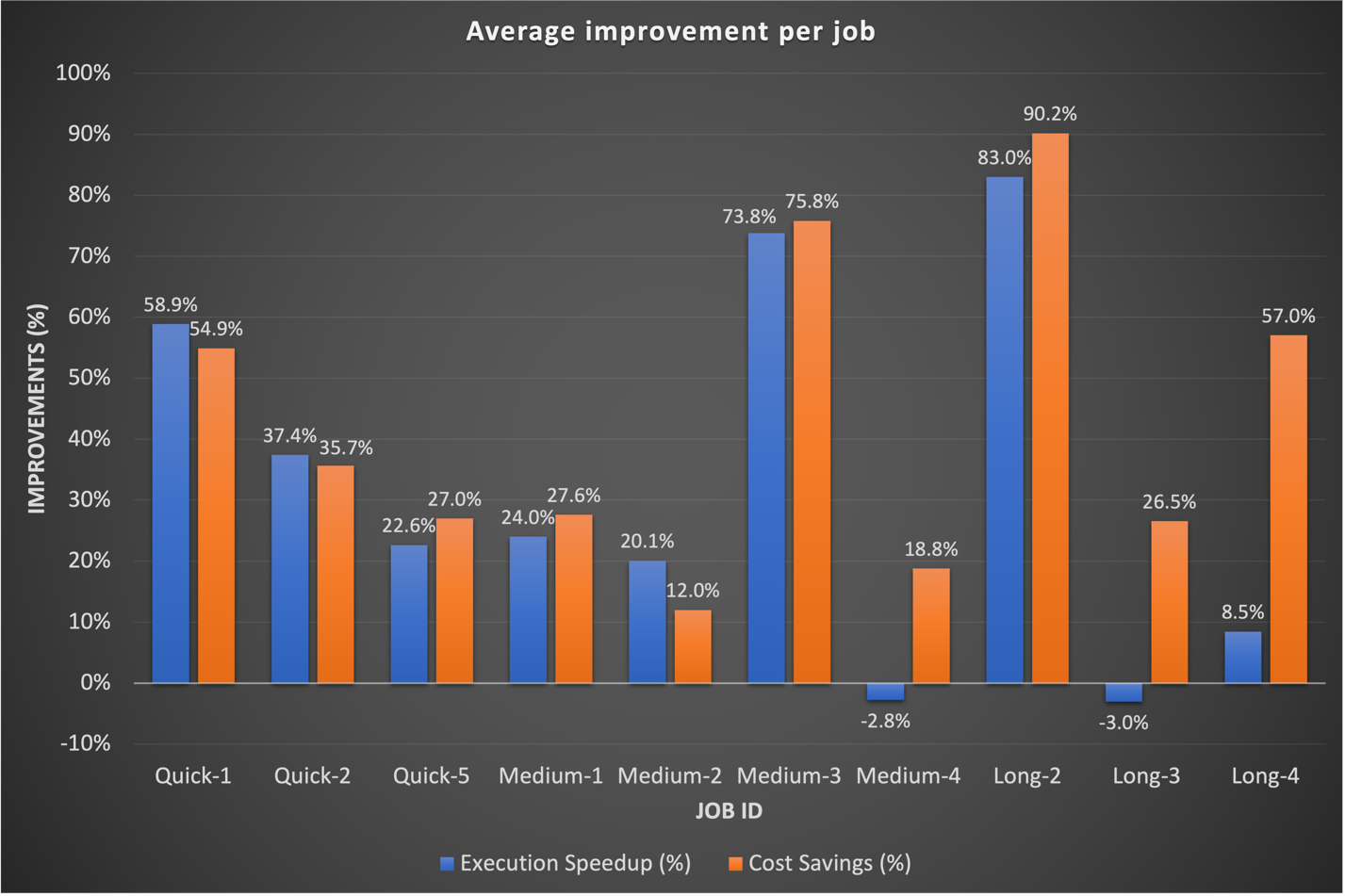
次の表は、Amazon EMR のさまざまなデプロイメント オプション (EC2 上の EMR および EMR サーバーレス) で実行された同じワークフローの結果のサンプル比較を示しています。
| メトリック | EC2 の EMR (平均) |
EMR サーバーレス (平均) |
EC2 の EMR と比較 EMR サーバーレス |
| 総実行コスト ($) | 5.82ドル | 2.60ドル | 視聴者の38%が |
| 合計実行時間 (分) | 53.40 | 39.40 | 視聴者の38%が |
| プロビジョニング時間 (分) | 10.20 | 0.05 | . |
| プロビジョニングコスト ($) | $ 1.19 | . | . |
| 歩数時間 (分) | 38.20 | 39.16 | -3% |
| ステップコスト ($) | $ 4.30 | . | . |
| アイドル時間 (分) | 4.80 | . | . |
| EMRリリースラベル | emr-6.9.0 | . | |
| Hadoop ディストリビューション | Amazon 3.3.3 | . | |
| スパークバージョン | スパーク3.3.0 | . | |
| Hive/HCatalog のバージョン | Hive 3.1.3、HCatalog 3.1.3 | . | |
| Basic | スパーク | . | |
AWS Graviton2 on EMR サーバーレスのパフォーマンス評価
EMR サーバーレスのワークロードに対する説得力のある結果を確認した後、私たちは、サーバーレスのパフォーマンスをさらに分析することにしました。 AWS グラビトン 2 EMR サーバーレス内の (arm64) アーキテクチャ。 AWS には ベンチマークされた TPC-DS 2TB スケールを使用して Graviton3 EMR サーバーレスでワークロードをスパークし、全体的な価格パフォーマンスの 27% の向上を示します。
統合のメリットをより深く理解するために、GoDaddy の実稼働ワークロードを毎日のスケジュールで使用して独自の調査を実行したところ、Graviton23.8 を使用すると、さまざまなジョブにわたって 2% という驚異的な価格パフォーマンスの向上が観察されました。この研究の詳細については、以下を参照してください。 GoDaddy ベンチマークの結果、Amazon EMR サーバーレス上の AWS Graviton24 を使用した Spark ワークロードの価格パフォーマンスが最大 2% 向上しました.
EMRサーバーレスの導入戦略
デプロイメント リングを介して EMR サーバーレスの段階的なロールアウトを戦略的に実装し、体系的な統合を可能にしました。この段階的なアプローチにより、改善点を検証し、必要に応じて EMR サーバーレスのさらなる採用を中止することができます。これは、問題を早期に発見するためのセーフティ ネットとして、またインフラストラクチャを改善する手段として機能しました。このプロセスでは、データ エンジニアリング チームと DevOps チームの専門知識を構築しながら、スムーズな運用を通じて変更の影響を軽減しました。さらに、緊密なフィードバック ループが促進され、迅速な調整が可能になり、効率的な EMR サーバーレス統合が保証されます。
次の図に示すように、ワークフローを 3 つの主要な導入グループに分割しました。
- カナリア諸島 – このグループは、展開段階の早い段階で潜在的な問題を検出して解決するのに役立ちます。
- 早期導入者 – これは、Canaries グループによって最初の問題が特定され修正された後、新しいコンピューティング ソリューションを採用するワークフローの 2 番目のバッチです。
- 幅広い展開リング – リングの最大のグループであるこのグループは、ソリューションの大規模な展開を表します。これらは、前の 2 つのグループでのテストと実装が成功した後に展開されます。
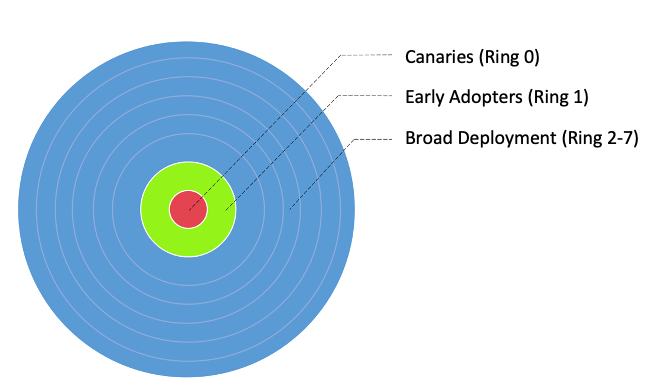
次の表に示すように、EMR サーバーレスを採用するために、これらのワークフローをさらに細分化した導入リングに分割しました。
| 指輪 # | 名前 | 詳細 |
| リング0 | カナリア | 導入リスクが低く、コスト削減効果が期待できるジョブ。 |
| リング1 | 初期採用者 | 高い利益が期待できる低リスクのクイック実行 Spark ジョブ。 |
| リング2 | クイックラン | クイックランの残りの部分 (step_time <= 20 分) Spark ジョブ |
| リング3 | LargerJobs_EZ | 高い潜在利益、簡単な移動、中期および長期の Spark ジョブ |
| リング4 | より大きなジョブ | 利益が期待できる残りの中期および長期の Spark ジョブ |
| リング5 | ハイブ | より高いコスト削減の可能性がある Hive ジョブ |
| リング6 | Redshift_EZ | EMR サーバーレスに適した簡単な移行 Redshift ジョブ |
| リング7 | グルー_EZ | 簡単な移行 EMR サーバーレスに適した Glue ジョブ |
本番導入実績概要
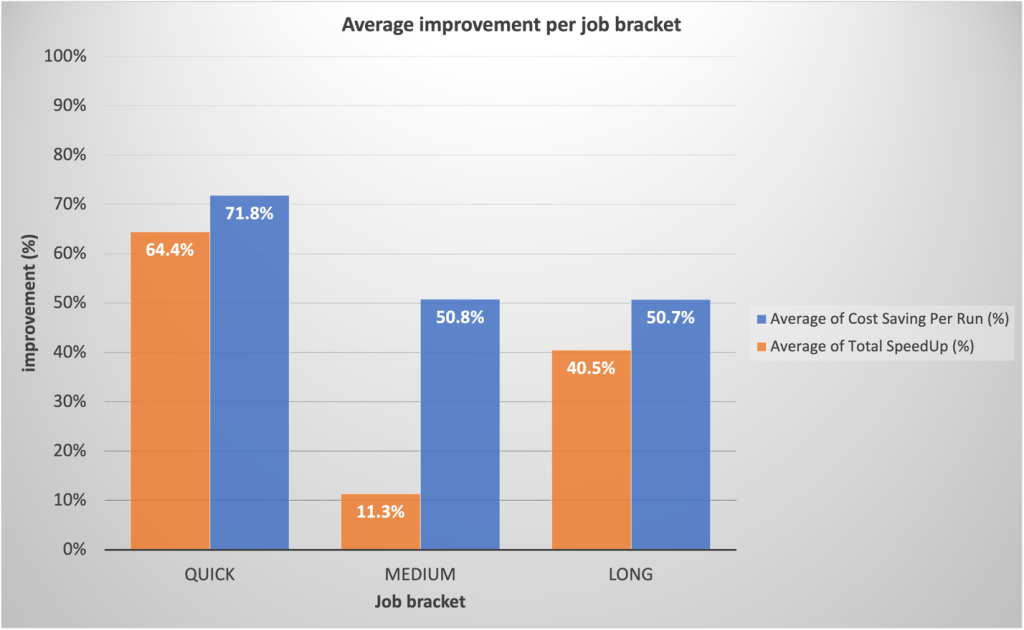
ベンチマークとカナリア導入の有望な結果により、GoDaddy でのより広範な EMR サーバーレス導入に対する大きな関心が高まりました。現在まで、EMR サーバーレスの展開は進行中です。これまでのところ、コストを 62.5% 削減し、バッチ ワークフローの完了全体を 50.4% 短縮しました。
予備的なベンチマークに基づいて、私たちのチームは迅速なジョブで大幅な利益が得られると予想していました。驚いたことに、実際の運用導入は予測を上回っており、予測の 64.4% に対して平均 42% 高速化され、予測の 71.8% に対して 40% 低コストでした。
驚くべきことに、EMR サーバーレスの迅速なプロビジョニングと動的なリソース割り当てによって可能になる積極的なスケーリングにより、長時間実行されるジョブでも大幅なパフォーマンスの向上が見られました。高リソースのセグメント中に大幅な並列化が行われ、その結果、従来のアプローチと比較して合計実行時間が 40.5% 高速化することが観察されました。次のグラフは、職種ごとの平均強化を示しています。
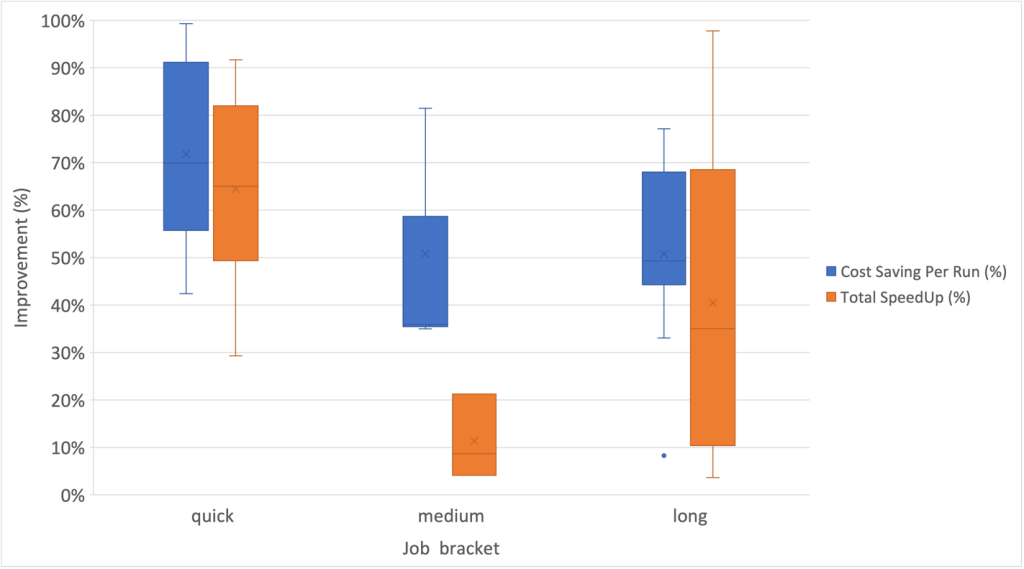
さらに、次の箱ひげ図に示すように、長期実行ジョブ カテゴリ内で速度向上のばらつきが最も高いことが観察されました。
EMRサーバーレスを採用したサンプルワークフロー
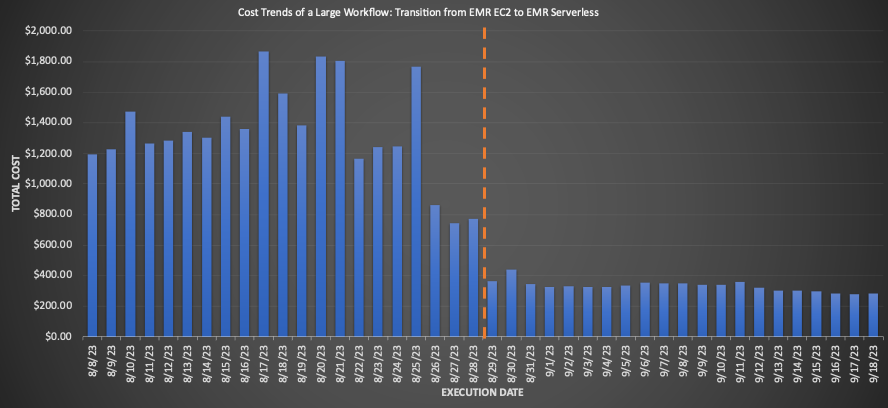
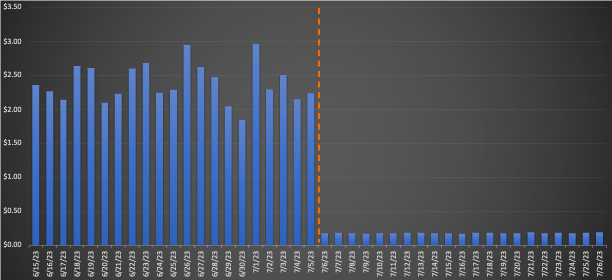
EMR サーバーレスに移行された大規模なワークフローについて、移行前と移行後の 3 週間の平均を比較すると、小売価格に基づいて 75.30% 削減され、総実行時間が 10% 改善され、運用効率が向上するという驚異的なコスト削減が明らかになりました。次のグラフはコストの傾向を示しています。
クイック実行ジョブは 2 ドルあたりのコスト削減を最小限に抑えましたが、最も大幅なコスト削減率を実現しました。これらのワークフローが毎日何千も実行されるため、蓄積されたコストは大幅に節約されます。次のグラフは、EC3 上の EMR から EMR サーバーレスに移行された小規模なワークロードのコスト傾向を示しています。移行前と移行後の 92.43 週間の平均を比較すると、小売店のオンデマンド価格設定で 80.6% という驚くべきコスト削減が行われ、合計実行時間が XNUMX% 短縮されたことがわかりました。
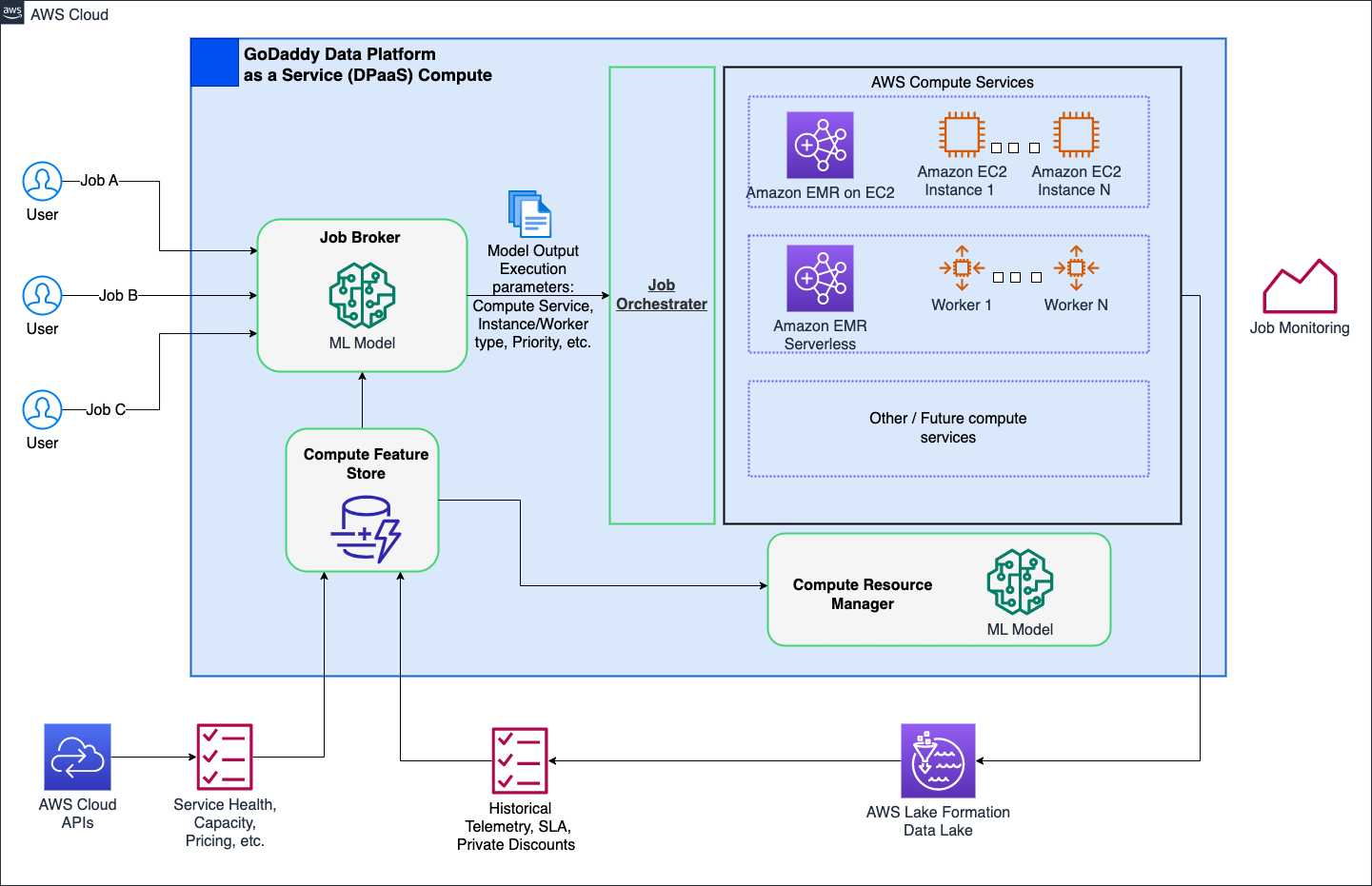
レイヤ 7: プラットフォーム全体の改善
私たちは、GoDaddy のコンピューティング運用に革命を起こし、インテリジェント コンピューティング プラットフォームを使用してすべてのユーザーにシンプルかつ強力なソリューションを提供することを目指しています。 EMR サーバーレスや EMR on EC2 などの AWS コンピューティング ソリューションを使用して、データ処理と機械学習 (ML) ワークロードの最適化された実行を提供しました。 ML を活用したジョブ ブローカーは、さまざまなパラメータに基づいてジョブを実行する時期と方法をインテリジェントに決定し、パワー ユーザーがカスタマイズできるようにします。さらに、ML を活用したコンピューティング リソース マネージャーは、負荷と履歴データに基づいてリソースを事前にプロビジョニングし、最適なコストで効率的かつ高速なプロビジョニングを提供します。インテリジェント コンピューティングは、すぐに使える最適化機能をユーザーに提供し、パワー ユーザーに妥協することなく、多様なペルソナに対応します。
次の図は、インテリジェント コンピューティング アーキテクチャの概要を示しています。
洞察と推奨されるベストプラクティス
次のセクションでは、私たちが収集した洞察と、予備段階および広範な導入段階で開発した推奨されるベスト プラクティスについて説明します。
インフラの準備
EMR サーバーレスは EMR 内の展開方法ですが、その可能性を最適化するにはインフラストラクチャの準備が必要です。次の要件と実装に関する実践的なガイダンスを考慮してください。
- 複数のアベイラビリティーゾーンにわたって大規模なサブネットを使用する – VPC 内で EMR サーバーレス ワークロードを実行する場合は、サブネットが複数のアベイラビリティーゾーンにまたがっており、IP アドレスによって制限されていないことを確認してください。参照する VPC アクセスの構成 & サブネット計画のベスト プラクティス 詳細については。
- 最大同時 vCPU クォータを変更する – 広範なコンピューティング要件の場合は、 アカウントあたりの最大同時 vCPU 数 サービス割り当て。
- Amazon MWAA バージョンの互換性 – EMR サーバーレスを採用する際、データ パイプライン オーケストレーションのための GoDaddy の分散型 Amazon MWAA エコシステムにより、異なる AWS プロバイダーのバージョンからの互換性の問題が発生しました。 Amazon MWAA を直接アップグレードする方が、多数の DAG を更新するより効率的でした。 Amazon MWAA インスタンスを自分たちでアップグレードし、問題を文書化し、正確なアップグレード計画のために調査結果と労力の見積もりを共有することで、導入を促進しました。
- GoDaddy EMR オペレーター – 多数の Airflow DAG を EC2 上の EMR から EMR サーバーレスへの移行を効率化するために、既存のインターフェイスに適応するカスタム オペレーターを開発しました。これにより、使い慣れたチューニング オプションを維持しながら、シームレスな移行が可能になりました。データ エンジニアは、単純な検索置換インポートでパイプラインを簡単に移行し、すぐに EMR サーバーレスを使用できます。
予期せぬ動作の軽減
以下は、私たちが遭遇した予期せぬ動作と、それらを軽減するために行った行動です。
- Spark DRA の積極的なスケーリング – 一部のジョブ (初期ベンチマークの 8.33%、本番環境の 13.6%) では、EMR サーバーレスへの移行後にコストが増加しました。これは、Spark DRA がコストよりもパフォーマンスを優先し、新しいワーカーを過度に短期間割り当てたためでした。これに対処するために、エグゼキュータの最大しきい値を調整して設定します。
spark.dynamicAllocation.maxExecutor、EMR サーバーレス スケーリングの攻撃性を効果的に制限します。 EC2 上の EMR から移行する場合は、Spark History UI で最大コア数を確認し、EMR サーバーレスで同様のコンピューティング制限を再現することをお勧めします。--conf spark.executor.cores&--conf spark.dynamicAllocation.maxExecutors. - 大規模なジョブのディスク容量の管理 – 大量のシャッフルと大量のディスク要件を伴う大量のデータを処理するジョブを EMR サーバーレスに移行する場合は、次の構成をお勧めします。
spark.emr-serverless.executor.disk既存の Spark ジョブ メトリクスを参照することによって。さらに、次のような構成spark.executor.coresと組み合わせることspark.emr-serverless.executor.disk&spark.dynamicAllocation.maxExecutors有利な場合は、基礎となるワーカーのサイズと接続されたストレージの合計を制御できるようになります。たとえば、ディスク使用量が比較的少なく、シャッフルが多いジョブでは、より大きなワーカーを使用してローカル シャッフル フェッチの可能性を高めるとメリットが得られる場合があります。
まとめ
この投稿で説明したように、arm64 での EMR サーバーレスの導入に関する私たちの経験は圧倒的に良好でした。コストの 60% 削減、バッチ Spark ワークロードの実行の 50% 高速化、開発およびテスト速度の 2 倍という驚異的な向上など、私たちが達成した目覚ましい成果は、このテクノロジーの可能性を雄弁に物語っています。さらに、現在の結果は、EMR サーバーレスで Graviton60 を広く採用することで、バッチ処理で二酸化炭素排出量を最大 XNUMX% 削減できる可能性があることを示唆しています。
ただし、これらの結果は画一的なシナリオではないことを理解することが重要です。期待できる機能強化は、ワークフローの特定の性質、クラスター構成、リソース使用率レベル、計算能力の変動などの要因によって異なりますが、これらに限定されません。したがって、EMR サーバーレスの統合を検討する際には、その利点を最大限に最適化するのに役立つデータ駆動型のリングベースの導入戦略を強く推奨します。
特別な感謝へ ムクル・シャルマ & ボリス・ベルリン ベンチマークへの貢献に対して。どうもありがとうございました トラヴィス・ミュールスタイン (CDO)、 アビジット・クンドゥ (エンジニアリング担当副社長)、 ヴィンセント・ヨン (シニアディレクターエンジニア)、および ワイキンラウ (シニア ディレクター データ エンジニア) の継続的なサポートに感謝します。
著者について
 ブランドン・アベア GoDaddy のデータ & アナリティクス (DnA) 組織のプリンシパル データ エンジニアです。彼はビッグデータ全般を楽しんでいます。余暇には、旅行、映画鑑賞、リズム ゲームを楽しんでいます。
ブランドン・アベア GoDaddy のデータ & アナリティクス (DnA) 組織のプリンシパル データ エンジニアです。彼はビッグデータ全般を楽しんでいます。余暇には、旅行、映画鑑賞、リズム ゲームを楽しんでいます。
 ディネッシュ・シャルマ GoDaddy のデータ & アナリティクス (DnA) 組織のプリンシパル データ エンジニアです。彼はユーザー エクスペリエンスと開発者の生産性を重視し、エンジニアリング プロセスを最適化しコストを節約する方法を常に模索しています。余暇には読書が大好きで、熱心なマンガファンです。
ディネッシュ・シャルマ GoDaddy のデータ & アナリティクス (DnA) 組織のプリンシパル データ エンジニアです。彼はユーザー エクスペリエンスと開発者の生産性を重視し、エンジニアリング プロセスを最適化しコストを節約する方法を常に模索しています。余暇には読書が大好きで、熱心なマンガファンです。
 ジョン・ブッシュ GoDaddy のデータ & アナリティクス (DnA) 組織の主任ソフトウェア エンジニアです。彼は、組織がデータを管理し、それを使用してビジネスを前進させることを容易にすることに情熱を持っています。余暇には、ハイキング、キャンプ、電動自転車に乗るのが大好きです。
ジョン・ブッシュ GoDaddy のデータ & アナリティクス (DnA) 組織の主任ソフトウェア エンジニアです。彼は、組織がデータを管理し、それを使用してビジネスを前進させることを容易にすることに情熱を持っています。余暇には、ハイキング、キャンプ、電動自転車に乗るのが大好きです。
 オズカン・イリハン GoDaddy のデータおよび ML プラットフォームのエンジニアリング ディレクターです。彼は、新興企業から世界的企業まで、20 年以上にわたり学際的なリーダーシップの経験を持っています。彼は、顧客を喜ばせ、より多くのことを達成できるようにし、業務効率を高めるソリューションを作成する際にデータと AI を活用することに情熱を持っています。仕事以外では、読書、ハイキング、ガーデニング、ボランティア活動、DIY プロジェクトに取り組むことを楽しんでいます。
オズカン・イリハン GoDaddy のデータおよび ML プラットフォームのエンジニアリング ディレクターです。彼は、新興企業から世界的企業まで、20 年以上にわたり学際的なリーダーシップの経験を持っています。彼は、顧客を喜ばせ、より多くのことを達成できるようにし、業務効率を高めるソリューションを作成する際にデータと AI を活用することに情熱を持っています。仕事以外では、読書、ハイキング、ガーデニング、ボランティア活動、DIY プロジェクトに取り組むことを楽しんでいます。
 Harsh Vardhan は、ビッグデータと分析を専門とする AWS ソリューションアーキテクトです。彼はビッグデータとデータサイエンスの分野で 8 年以上の経験があります。彼は、顧客がベスト プラクティスを採用し、データから洞察を発見できるよう支援することに情熱を注いでいます。
Harsh Vardhan は、ビッグデータと分析を専門とする AWS ソリューションアーキテクトです。彼はビッグデータとデータサイエンスの分野で 8 年以上の経験があります。彼は、顧客がベスト プラクティスを採用し、データから洞察を発見できるよう支援することに情熱を注いでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/how-the-godaddy-data-platform-achieved-over-60-cost-reduction-and-50-performance-boost-by-adopting-amazon-emr-serverless/

