ダン・ユー、ハリー・フォスター、トム・フィッツパトリック著
EDA 4.0 の時代へようこそ。そこで私たちは、人工知能の力による電子設計の自動化における革命的な変革を目の当たりにしています。 EDA の歴史は、設計の反復の高速化、生産性の向上、複雑な電子システムの開発の促進など、重要な技術進歩を特徴とする個別の時期に分けることができます。
特に、EDA 1.0 の出現は、1970 年代初頭にカリフォルニア大学バークレー校で SPICE (集積回路に重点を置いたシミュレーション プログラム) が導入されたことによって始まり、回路設計に革命をもたらしました。
1980 年代から 1990 年代初頭にかけて、効率的な配置配線アルゴリズムの開発の結果として EDA 2.0 が登場しました。 RTL 時代としても知られるこの時期は、ゲート レベルの設計からより高いレベルの抽象化への移行を目撃し、RTL 設計によりレジスタ転送レベルでの回路記述が可能になり、それによってシミュレーションのパフォーマンスが向上しました。 この時期は、論理合成の導入という重要なマイルストーンを迎えました。
1990 年代後半から 2000 年代初頭にかけてのシステムオンチップ (SoC) 設計の台頭は、EDA 3.0 につながる極めて重要な瞬間となりました。 この時代には、デザインの再利用手法と組み合わせた IP 開発経済の出現が見られました。 EDA ツールと標準は、SoC の設計、検証、および検証をサポートするために開発され、エンジニアが SoC クラスの設計のますます複雑化を管理できるようになりました。
EDA 4.0 は、多くの点で、製造部門のデジタル化を一因として、企業の製品の製造、改良、流通の方法を急速に変えている産業革命 4.0 の広範なトレンドと一致しています。 EDA 4.0 は、クラウド コンピューティングと人工知能 (AI) および機械学習 (ML) 機能の可能性を活用し、インテリジェントで接続されたデバイスの設計を容易にするために進化しました。


現在、EDA ツールには機械学習、仮想プロトタイピング、デジタル ツイン、システム レベルの設計手法が組み込まれており、EDA 製品の検証の高速化、検証ワークフローの自動化、検証精度の向上が実現しています。 EDA 4.0 時代は、製品パフォーマンスの最適化、市場投入までの時間の短縮、開発および製造プロセスの合理化を約束します。
この記事では、機能検証に特化した ML ソリューションの最先端の実装について詳しく説明します。 私たちは ML によって対処可能な課題を調査し、この分野に関連する新しい技術とアルゴリズムを紹介します。
機能検証における ML のトピック
表 1 は、プログラミング コード検証の一般的な観点にすべての機能検証トピックを含めた場合に、機能検証に適用できるトピックとサブトピックをまとめたものです。 斜体のテキストは、他の一般的な調査出版物では調査されていないサブトピックを示します。
表 1: 機能検証における ML アプリケーションのトピック。

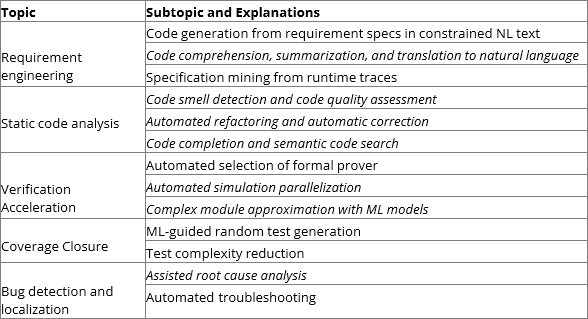
要求エンジニアリング
機能検証における要件エンジニアリングは、検証要件を定義、文書化、維持するプロセスであり、基礎となる IC 設計の優れた品質を確保するために重要です。
要件定義には、曖昧な自然言語 (NL) 検証目標を形式的かつ正確に検証仕様に変換することが含まれます。 翻訳の品質は検証の正確さに直接影響します。 従来、このプロセスは手間がかかり、品質を確保するために手作業で校正を数回繰り返すなど、かなりの設計サイクルを要します。
翻訳を自動化するために、XNUMX つのグループの古典的なアプローチが提案されています。 アプローチのグループの XNUMX つは、制約付き自然言語 (CNL) を導入して仕様の草案を形式化し、その後にテンプレート ベースの翻訳エンジンを導入することです。 このアプローチでは、機能検証で発生する要件のほとんどに対処できる強力な CNL 構文と包括的なコンパイラ/テンプレート システムの開発に多大な先行投資が必要です。 さらに、開発者には追加の言語を学習するという負担がかかり、このアイデアが広く受け入れられるのを妨げています。
もう XNUMX つのグループは、古典的な自然言語プロセス (NLP) を活用して NL 仕様を解析し、関連する重要な要素を抽出して正式な仕様を策定します。
NL ドメインにおける ML 翻訳の進歩により、完全に自動化された機械翻訳が商業的に実現可能になり、場合によっては平均的な人間の翻訳者のパフォーマンスを超えます。 これにより、最大数十億のパラメータを備えた大規模なトレーニング済み NL モデルを活用して、NL 仕様を SystemVerilog Assertions (SVA)、Property Specific Language (PSL)、またはその他の言語の検証仕様に直接変換するという期待が燃え上がりました。 エンドツーエンドの変換を成功させようとする試みがいくつか観察されていますが、本番環境に対応したものはありません。 このアプローチの主な障害は、NL 仕様とその正式な翻訳を組み合わせた利用可能なトレーニング データセットが不足していることです。 最も広範なデータセットはわずか約 100 文のペアです. この数は、日常的に数百万、場合によっては数十億の文のペアが存在する NL の同等の言語と比較すると見劣りします。
要件定義とは逆に、要約ではコードを調べて、人間が理解できる NL 要約に変換します。 これは、開発者があまり理想的に維持されていないコードを読んだり、複雑なロジックを理解したりするのに役立ちます。 理想的に実装されたコード要約では、コード ブロックにインライン ドキュメントを挿入したり、別のドキュメントを生成したりできます。 これを利用すると、コードの保守性と文書化が大幅に改善されます。
コード要約への ML の適用は、Python や JavaScript などのより一般的なコンピュータ言語で実験されています。 いくつかのグループのアプローチが実験され、さまざまな程度の成功が収められています。 情報検索 (IR) ベースのアプローチは、NLP をソース コードに適用し、既存の要約を備えた類似のコードを探すことに重点を置いています。 このグループのアプローチは、概要を含む既存のコードの品質に大きく依存します。 その使用は、多くの既存のコード リポジトリがすぐに利用できる緊密な組織内でのみ可能です。 代わりに、ヒューリスティックベースのアプローチでは、モジュールの定義で特定されたヒューリスティックに基づいて特定のルールを定義しようとします。たとえば、基本的な読み取り/書き込みコマンドラインのサブモジュールが多数あるモジュールはメモリモジュールとみなされる可能性があります。 したがって、メモリモジュールの事前定義されたパターンから概要を構築できます。
この記事の執筆時点では、IC 設計検証におけるコード要約はまだどの文献にも報告されていません。 他の言語の成功が IC の設計と検証でも実現できると楽観的になるのは当然ですが、研究コミュニティによってまだ確認されていません。 特に、言語間モデルに関する最近の進歩は、学習した知識を他のプログラミング言語から IC 設計に移すのに役立つ可能性があります。 ただし、コードの要約に関する ML に一般的な課題に加えて、IC 設計および検証コードにおける固有の時間並列性により、他のプログラミング言語では珍しい課題が生じる可能性があります。
仕様マイニングは、ソフトウェア エンジニアリングの長期的なトピックです。 手動で仕様を作成する代わりに、テスト対象のデザイン (DUT) の実行から間接的に仕様を抽出します。 ML を適用すると、シミュレーション トレースから繰り返しパターンをマイニングできます。 これは、シミュレーションベースのカバレッジクロージャまたは正式な検証の自動化に役立ちます。 一般的に繰り返されるパターンは、DUT の予期される動作である可能性があると想定されます。 あるいは、トレース内でめったに発生しないイベント パターンを異常とみなすこともできます。 したがって、診断やデバッグの目的で使用できます。
ML は、複雑なシステムの時間データが利用可能な多くのドメインにわたるパターン発見と異常検出に適用されています。 アジームら。 ML を使用してプロトコル トレースを観察し、問題のある可能性のあるプロトコルの実装を発見して正式な仕様を発見する、一般的なソフトウェア エンジニアリング アプローチを提案しています。 成功した実験は、ML を使用した仕様マイニングにおける興味深い追跡研究プロジェクトに影響を与えました。
静的コード分析
バグ修正のコストは IC 開発の段階に応じて指数関数的に増加するため、静的コード解析は、設計開発の初期段階でコードの品質と保守性を向上させる魅力的なオプションを提供します。
コード臭とは、ソース コード内の最適ではない設計パターンを指します。これは、構文的にも意味的にも正しいかもしれませんが、ベスト プラクティスに違反しており、コードの保守性の低下につながる可能性があります。 特定の例は、プロジェクトまたはコード ベース全体にわたって同じ関数が複数回実装されるコードの重複です。 一部のコピーでは特定のバグが比較的短期間で修正される可能性がありますが、他のコピーでは同じバグが気付かれないままになります。
従来のコード匂い検出は、定義されたヒューリスティック ルールに基づいてソース コード内のパターンを識別します。 静的コード分析ツールでこれらのルールとメトリクスを手動で開発する代わりに、利用可能な大量のソース コードで ML ベースのアプローチをトレーニングして、コードの臭いを特定できます。 研究によると、ML を使用した匂いの検出により、普遍的なコードの匂いの検出が可能になり、パターン実装の労力が大幅に削減されることが証明されています。 結果として得られる匂いスコアはコードの品質評価に使用でき、開発者が製品の品質を一貫して向上させるのに役立ちます。 さらに、ML ベースのコード リファクタリングは、コードの匂いを改善したり、候補となる変更をさらに改善したりするための役立つヒントを提供する可能性があります。
機能検証における ML の応用はまだ明らかではなく、大規模なトレーニング データセットが利用できないため、既存の研究ではこのソリューションの可能性を十分に活用できません。
IC 設計に取り組む開発者は、適切なツールが提供されている場合に最も生産性を高めることができます。 シンプルなコード補完は、最新の統合開発環境 (IDE) の標準機能です。 ただし、ディープラーニングを伴うより高度な技術が提案され、急速に成熟しつつあります。 多くの大規模なオープンソース コード リポジトリからの数十億のパラメーターを使用して ANN をトレーニングし、開発者の実装意図やコンテキストからコード スニペットの合理的な推奨事項を提供することが可能になりました。
ML は、NL クエリによって関連するコードを取得できるセマンティック コード検索により、IC 開発者の生産性を維持するのにも役立ちます。 コードには通常、さまざまな略語や専門用語が含まれているため、重要な変数、関数、またはモジュール名のスペルを正しく指定しなくても、関連するコード スニペットを見つけるにはセマンティック検索の方が効果的です。 多くの既存の検索エンジンのセマンティック検索に似ていますが、セマンティック コード検索は、概念が曖昧で、短縮された高度に技術的なコードを見つけるのに役立ちます。 最良のモデルの平均逆数ランクは、すでに 70% の使用可能なスコアを達成できます。
理論的には、他のプログラミング言語に適用されているのと同じ ML テクニックを IC 設計に適用できますが、コーディング支援に関する研究はまだ発表されていません。
検証の高速化
最近の調査によると、機能検証は依然として IC 設計において最も時間のかかるステップであり、機能エラーと論理エラーが依然としてリスピンの最も重要な原因であることが示されています。 機能検証の速度が向上すると、IC 設計の品質と生産性に大きな影響を与えます。 ML は、高速化のための正式な検証とシミュレーション ベースの検証の両方で使用されています。
形式検証では、形式数学アルゴリズムを使用して設計の正しさを証明します。 最新のフォーマル検証オーケストレーションでは、フォーマル アルゴリズムを採用して、さまざまなサイズ、タイプ、複雑さの設計を対象としています。 経験とヒューリスティックは、開発者が特定の問題に対してライブラリから最適なアルゴリズムを選択するのに役立ちます。
統計手法として、ML は形式的な検証の問題に直接対処することはできません。 ただし、正式なオーケストレーションでは非常に役立つことが証明されています。 コンピューティング リソースと問題解決の確率を予測することで、コンピューティング リソースの消費量がより少ない最も有望なソルバーを最初にスケジュールすることで、これらのリソースを最大限に活用して検証時間を短縮するようにフォーマル ソルバーをスケジュールすることができます。 Ada-boost デシジョン ツリー ベースの分類子は、ベースライン オーケストレーションから解決されたインスタンスの比率を 95% から 97% に改善し、平均 1.85 の速度向上を実現します。 別の実験では、形式的検証のリソース要件を平均 32% の誤差で予測できました。 特徴エンジニアリングを繰り返し適用して、DUT、プロパティ、形式的制約から特徴を慎重に選択します。その後、これらの特徴を使用して、リソース要件を予測するための重線形回帰モデルをトレーニングします。
正式な検証とは対照的に、シミュレーションベースの検証では通常、設計が完全に正しいことを保証できません。 代わりに、デザインは、特定のランダムまたは固定パターンの入力刺激が適用されたテストベンチの下に置かれ、その出力がリファレンス出力と比較されて、デザインの動作が予期されるかどうかが検証されます。 シミュレーションは機能検証の基本ですが、シミュレーションベースの検証でも検証時間が長くなる可能性があります。 複雑な設計の検証が完了するまでに数週間かかることも珍しくありません。
現在議論され、実験されている有望なアイデアは、ML を使用して複雑なシステムの動作をモデル化し、予測することです。 普遍近似定理は、少なくとも XNUMX つの隠れ層を持つフィードフォワード ANN である多層パーセプトロン (MLP) が、任意の精度で任意の連続関数を近似できることを証明します。 一方、ANN の特殊な形式である正規化リカレント ニューラル ネットワーク (RNN) は、メモリを備えたあらゆる動的システムに近似することが証明されています。 高度な ML アクセラレータ ハードウェアにより、ANN が一部の IC 設計モジュールの動作をモデル化し、シミュレーションを高速化できるようになりました。 AI アクセラレータの能力と ML モデルの複雑さに応じて、大幅な高速化が達成される可能性があります。
テストの生成とカバレッジの終了
手動で定義されたテスト パターンのほかに、シミュレーション ベースの検証で採用される標準的な手法には、ランダム テスト生成やグラフ ベースのインテリジェント テストベンチ自動化などがあります。 カバレッジ クロージャの「ロング テール」の性質により、効率がわずかに改善されただけでも、シミュレーション時間が大幅に短縮される可能性があります。 機能検証への ML の適用に関する多くの研究は、この分野に焦点を当ててきました。
広範な ML 研究により、ランダムなテスト生成よりも優れた結果が得られることが実証されています。 ほとんどの研究では、DUT がその入力を制御し、出力を監視できるブラック ボックスであると仮定した「ブラック ボックス モデル」が採用されています。 オプションで、いくつかのテスト ポイントを観察できます。 この研究は、DUT の動作を理解しようとするものではありません。 代わりに、不必要なテストを減らすことに重点が置かれています。 彼らは、さまざまな ML 技術を採用して、過去の入力/出力/観測データから学習し、ランダム テスト ジェネレーターを調整したり、役に立ちそうにないテストを削除したりします。 最近の開発では、強化学習 (RL) ベースのモデルを使用して DUT の出力から学習し、キャッシュ コントローラーの最も可能性の高いテストを予測しました。 ML モデルに与えられる報酬が FIFO の深さである場合、実験は過去の結果から学習し、数回の反復で目標の FIFO の深さ全体に達することができますが、ランダム テスト生成ベースのアプローチでは依然として 1 を超えるのに苦労しています。より細かい粒度の ML アーキテクチャでは、カバー ポイントごとに ML モデルをトレーニングする必要があります。 100 値分類子は、テストをシミュレートするか、破棄するか、モデルをさらに再トレーニングするために使用するかを決定するためにも使用されます。 サポート ベクター マシン (SVM)、ランダム フォレスト、ディープ ニューラル ネットワークはすべて CPU 設計で実験されています。 3 分の 5 から 69 分の 72 のテストで XNUMX% のカバレッジを達成できます。 FSM および非 FSM 設計に関するさらなる実験では、有向シーケンス生成と比較して XNUMX% および XNUMX% の削減が実証されました。 ただし、これらの結果のほとんどは、ML の統計的性質の制限に依然として悩まされています。 ML ベースのカバレッジ指向テスト生成 (CDG) のより包括的なレビューでは、いくつかの ML モデルとその実験結果の概要を示します。 ベイジアン ネットワークの遺伝的アルゴリズムと遺伝的プログラミングのアプローチ、マルコフ モデル、データ マイニング、および帰納的論理プログラミングはすべて、さまざまな程度の成功を収めた実験です。
ここで説明したすべてのアプローチにおいて、ML モデルは収集した履歴データからの学習に基づいて予測を行うことができますが、将来を予測する最小限の機能、つまり未カバーのテスト ターゲットを達成するためにどのテストがより有望なオプションであるかを予測する機能は最小限に抑えられています。 この種の情報はまだ入手できないため、彼らができる最善のことは、過去のテストと最も無関係なテストを選択することです。 別の有望な実験では、DUT をホワイト ボックスとみなし、コードを分析してコントロール / データ フロー グラフ (CDFG) に変換する、別のアプローチを検討しました。 トレーニングされたグラフ ニューラル ネットワーク (GNN) での勾配ベースの検索を使用して、事前定義されたテスト ターゲットのテストが生成されます。 IBEX v1、v2、および TPU での実験では、74% のカバー ポイントでトレーニングした場合、カバレッジ予測の精度が 73%、90%、および 50% に達しました。 いくつかの追加の実験により、使用された勾配探索法が GNN アーキテクチャの影響を受けないことも確認されています。
トレーニング データが利用できないため、これらの ML アプローチのほとんどは、他の同様の設計からの事前知識を活用することなく、各設計からのみ学習することに注意してください。
バグ分析
バグ分析の目的は、潜在的なバグを特定し、それらを含むコード ブロックを特定し、修正の提案を提供することです。 最近の調査では、IC の検証には設計にかかる時間とほぼ同じ時間がかかり、機能的なバグが ASIC 設計のやり直しの約 50% に寄与していることが判明しました。 したがって、これらのバグを機能検証の初期段階で特定して修正できることが非常に重要です。 ML は、開発者が設計内のバグを検出し、バグをより迅速に発見できるようにするために採用されています。
機能検証におけるバグハンティングを迅速化するには、根本原因によるバグのクラスタリング、根本原因の分類、修正の提案という XNUMX つの進歩的な問題を解決する必要があります。 ほとんどの研究は最初の XNUMX つに焦点を当てており、XNUMX 番目についてはまだ研究結果が得られていません。
半構造化シミュレーション ログ ファイルはバグ分析に使用できます。 未公開の設計のログ ファイルのメタデータとメッセージ行から 616 の異なる特徴を抽出します。 クラスタリングの実験では、特徴の次元削減後でも、調整済み相互情報量 (AMI) が K 平均法と凝集クラスタリングで 0.543、DBSCAN で 0.593 を達成しました。これは、AMI が 1.0 に達する理想的なクラスタリングとは程遠いものです。 問題 2 を解決する際の精度を決定するために、さまざまな分類アルゴリズムもテストされました。ランダム フォレスト、サポート ベクター分類 (SVC)、デシジョン ツリー、ロジスティック回帰、K 近傍法、およびナイーブ ベイズを含むすべてのアルゴリズムの検出力が比較されます。根本原因を予測します。 最高のスコアはランダム フォレストによって達成され、予測精度は 90.7%、F0.913 スコアは 1 でした。 別のアプローチでは、コードコミットからのラベル付きデータセットを使用して勾配ブースティングモデルをトレーニングすることを提案しています。このモデルでは、アルゴリズムに 100 個が選択されるまで、作成者、リビジョン、コード、プロジェクトに関する 36 を超える特徴がテストされました。 この実験では、どのコミットにバグのあるコードが含まれる可能性が最も高いかを予測することが可能であり、手動によるバグ探索時間を大幅に削減できる可能性があることが示されています。
ただし、採用されている ML 技術は比較的単純であるため、コード内で豊富なセマンティクスを考慮したり、過去のバグ修正から学習したりできる ML モデルをトレーニングすることはできません。 したがって、バグが発生する理由と方法を説明することはできず、バグを自動的または半自動的に排除するためにコードを修正することを提案することもできません。
機能検証に適用できる新しい ML 手法とモデル
近年、ML 技術、モデル、アルゴリズムにおける大きな進歩が見られています。 私たちの調査では、これらの新しい技術のうち、機能検証の研究で採用されている技術はほとんどないことがわかりました。機能検証の困難な問題に取り組むためにこれらの技術が使用されれば、大きな成功が可能であると楽観的に信じています。
膨大な量のテキスト コーパスでトレーニングされた数十億のパラメータを備えたトランスフォーマー ベースの大規模 NL モデルは、質問応答、機械翻訳、テキスト分類、抽象的要約などのさまざまな NL タスクで人間に近い、または人間を超えるレベルのパフォーマンスを達成しました。その他。 これらの研究結果をコード分析に適用すると、これらのモデルの大きな可能性と汎用性が実証されました。 これらのモデルがトレーニング データの大規模なコーパスを実際に取り込み、学習した知識を構造化し、簡単にアクセスできることが実証されています。 この機能は、静的コード分析、要件エンジニアリング、およびいくつかの一般的なプログラミング言語のコーディング支援に役立ちます。 十分なトレーニング データがあれば、これらの手法でさまざまな機能検証タスクの ML モデルをトレーニングできると考えるのが合理的です。
最近まで、グラフ データの構造が複雑なため、ML をグラフ データに適用するのは困難でした。 グラフ ニューラル ネットワーク (GNN) の進歩により、機能検証の新たな機会が約束されました。 そのようなアプローチの XNUMX つは、設計をコード/データ フロー グラフに変換し、その後、これをさらに GNN のトレーニングに使用して、テストのカバレッジ クロージャの予測に役立てます。 この種のホワイト ボックス アプローチにより、これまでは得られなかった設計内の制御とデータ フローに関する洞察が得られ、潜在的なカバレッジ ホールを埋めるための有向テストを生成できるようになります。 グラフは、検証中に発生する豊富な関係情報、構造情報、および意味情報を表現できます。 グラフ上で ML モデルをトレーニングすることで得られる豊富な情報により、バグハンティングやカバレッジのクロージャなど、多くの新しい機能検証タスクを実行できるようになります。
まとめ
EDA 4.0 は、人工知能の力を通じて電子設計の自動化を変革し、エンジニアがインダストリー 4.0 の革命的な変化を実現するのに役立ついくつかの主要テクノロジーを提供します。 この記事では、機能検証のさまざまな側面に対処する際の機械学習の潜在的な貢献についての包括的な調査を提供します。 この記事では、機能検証における ML の典型的なアプリケーションに焦点を当て、この分野における最先端の成果を要約します。
ただし、さまざまな ML 手法が適用されているにもかかわらず、現在の研究は主に基本的な ML 手法に依存しており、トレーニング データの利用可能性によって制限されています。 この状況は、他の高度なドメインにおける ML アプリケーションの初期段階を彷彿とさせ、機能検証における ML アプリケーションがまだ初期段階にあることを示しています。 高度な技術とモデルを活用して ML の機能を最大限に活用するには、未開発の大きな可能性がまだ残っています。 さらに、今日の ML アプリケーションにおけるセマンティック情報、リレーショナル情報、構造情報の利用はまだ完全には実現されていません。
この主題の詳細については、次のタイトルのホワイト ペーパーを参照してください。 機能検証における機械学習アプリケーションの調査。 このホワイトペーパーでは、このトピックをさらに深く掘り下げ、業界の観点から洞察を提供し、利用可能なデータの制限によってもたらされる差し迫った課題について説明します。 論文全文には、この記事の多くの情報を提供する魅力的な研究と著作への徹底的な参照も含まれています。
Harry Foster は、Siemens Digital Industries Software の検証主任研究員です。 Verification Academy の共同創設者兼編集長でもあります。 フォスターは、2021 年のデザイン オートメーション カンファレンスのゼネラルチェアを務め、現在は前チェアマンを務めています。 彼は検証に関する複数の特許を取得しており、検証に関する書籍を 2022 冊共著しています。 Foster 氏は、業界標準の開発への貢献が評価され、Accellera Technical Excellence Award を受賞しており、Accellera Open Verification Library (OVL) 標準の最初の作成者でもあります。 さらに、フォスターは 2022 年 ACM Distinguished Service Award と XNUMX IEEE CEDA Outstanding Service Award を受賞しています。
Tom Fitzpatrick は、Siemens Digital Industries Software (Siemens EDA) の戦略的検証アーキテクトであり、高度な検証手法、言語、標準の開発に取り組んでいます。 彼は、Verilog 25、SystemVerilog 1364、UVM 1800 など、過去 1800.2 年間に機能検証環境を劇的に改善したいくつかの業界標準に大きく貢献してきました。 彼は Accellera ポータブル スティミュラス ワーキング グループの創設メンバーであり、現在は副議長を務めており、現在 IEEE 1800 および Accellera UVM-AMS ワーキング グループの議長を務めています。 Fitzpatrick は、DVCon US 運営委員会の長年のメンバーであり、DVConUS 2024 の総合議長を務めています。また、デザイン オートメーション カンファレンス実行委員会のメンバーでもあります。 Fitzpatrick は、MIT で電気工学とコンピュータ サイエンスの修士号と学士号を取得しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://semiengineering.com/welcome-to-eda-4-0-and-the-ai-driven-revolution/

