データ統合は、堅牢なデータ分析の基礎です。 これには、さまざまなソースからのデータの発見、準備、構成が含まれます。 現代のデータ環境では、さまざまなソースからのデータへのアクセス、統合、変換は、データ主導の意思決定にとって重要なプロセスです。 AWSグルーサーバーレス データ統合および抽出、変換、ロード (ETL) サービスである は、このプロセスに革命をもたらし、よりアクセスしやすく効率的になりました。 AWS Glue により複雑さとコストが排除され、組織はデータ統合タスクを数分で実行できるようになり、効率が向上します。
このブログ投稿では、 新たに発表 Google BigQuery のマネージドコネクタを使用し、コードを書かずに AWS Glue Studio を使用して最新の ETL パイプラインを構築する方法を示します。
AWS Glue の概要
AWSグルー は、分析、機械学習 (ML)、アプリケーション開発のためのデータの検出、準備、結合を容易にするサーバーレス データ統合サービスです。 AWS Glue はデータ統合に必要なすべての機能を提供するため、数か月ではなく数分でデータの分析と使用を開始できます。 AWS Glue は、データ統合を容易にするために、ビジュアルとコードベースの両方のインターフェイスを提供します。 ユーザーは、 AWSGlueデータカタログ。 データ エンジニアと ETL (抽出、変換、ロード) 開発者は、ETL ワークフローをいくつかの手順で視覚的に作成、実行、監視できます。 AWS グルースタジオ。 データアナリストとデータサイエンティストが使用できるのは、 AWS グルー DataBrew コードを書かずにデータを視覚的に強化、クリーンアップ、正規化します。
Google BigQuery Spark コネクタの紹介
多様なデータ統合ユースケースの需要を満たすために、AWS Glue は Google BigQuery 用のネイティブ Spark コネクタを提供するようになりました。 お客様は、AWS Glue 4.0 for Spark を使用して、Google BigQuery のテーブルの読み取りと書き込みができるようになりました。 さらに、テーブル全体を読み取ることも、カスタム クエリを実行して、直接および間接的な書き込み方法を使用してデータを書き込むこともできます。 BigQuery に安全に保存されているサービス アカウント認証情報を使用して BigQuery に接続します。 AWSシークレットマネージャー.
Google BigQuery Spark コネクタの利点
- シームレス統合: ネイティブ コネクタは、データ統合のための直感的で合理化されたインターフェイスを提供し、学習曲線を短縮します。
- コスト効率: カスタム コネクタの構築と維持には費用がかかる場合があります。 AWS Glue が提供するネイティブコネクタは、コスト効率の高い代替手段です。
- 効率化: 以前は数週間から数か月かかっていたデータ変換タスクが数分以内に完了できるようになり、効率が最適化されます。
ソリューションの概要
この例では、AWS Glue とネイティブ Google BigQuery コネクタを使用して XNUMX つの ETL ジョブを作成します。
- BigQuery テーブルにクエリを実行し、データを保存します Amazon Simple Storage Service(Amazon S3) 寄木細工の形式で。
- 最初のジョブから抽出されたデータを使用して、Google BigQuery に保存される集計結果を変換および作成します。

前提条件
このソリューションで使用されるデータセットは、 NCEI/WDS 世界重大地震データベース、紀元前 5,700 年から現在までの 2150 以上の地震の世界的なリストが含まれています。 この公開データを Google BigQuery プロジェクトにコピーするか、既存のデータセットを使用します。
BigQuery 接続を構成する
AWS Glue から Google BigQuery に接続するには、を参照してください。 BigQuery 接続の構成。 Google Cloud Platform の認証情報を作成して Secrets Manager シークレットに保存し、そのシークレットを Google BigQuery AWS Glue 接続に関連付ける必要があります。
Amazon S3 をセットアップする
Amazon S3 内のすべてのオブジェクトはバケットに保存されます。 データを Amazon S3 に保存する前に、次のことを行う必要があります。 S3バケットを作成する 結果を保存します。
S3 バケットを作成するには:
- AWS マネジメントコンソールで アマゾンS3、選択する バケットを作成する.
- グローバルに一意の値を入力してください 名前 あなたのバケツのために。 例えば、
awsglue-demo. - 選択する バケットを作成します。
AWS Glue ETL ジョブの IAM ロールを作成する
AWS Glue ETL ジョブを作成するときは、 AWS Identity and Access Management(IAM) ジョブが使用するロール。 ロールは、Amazon S3 (ソース、ターゲット、スクリプト、ドライバー ファイル、一時ディレクトリ用) および Secrets Manager を含む、ジョブで使用されるすべてのリソースへのアクセスを許可する必要があります。
手順については、 ETL ジョブの IAM ロールを構成する.
ソリューションウォークスルー
AWS Glue Studio でビジュアル ETL ジョブを作成して、Google BigQuery から Amazon S3 にデータを転送する
- Video Cloud Studioで AWSグルー コンソール。
- AWS Glue で、次の場所に移動します。 ビジュアルETL 下 ETL ジョブ セクションを作成し、次を使用して新しい ETL ジョブを作成します ビジュアル 真っ白なキャンバスで。
- 入力します 名前 たとえば、AWS Glue ジョブの場合、
bq-s3-dataflow. - 選択 Google ビッグクエリ データソースとして。
- 入力します 名 たとえば、Google BigQuery ソースノードの場合
noaa_significant_earthquakes. - ドロップダウンリストから Google ビッグクエリ たとえば、接続
bq-connection. - 入力します 親 たとえば、プロジェクト
bigquery-public-datasources. - 選択 単一のテーブルを選択してください BigQuery ソース.
- 入力する テーブル たとえば、[データセット].[テーブル] の形式で移行したいとします。
noaa_significant_earthquakes.earthquakes.
- 入力します 名 たとえば、Google BigQuery ソースノードの場合
- 次に、データターゲットを次のように選択します アマゾンS3.
- 入力します 名前 ターゲットの Amazon S3 ノードの場合、地震など。
- 出力データの選択 フォーマット as 寄せ木細工の床.
- 現在地に最も近い 圧縮タイプ as 粋な.
- S3ターゲットの場所、前提条件で作成したバケットを入力します。たとえば、
s3://<YourBucketName>/noaa_significant_earthquakes/earthquakes/. - 交換する必要があります
<YourBucketName>バケットの名前を付けます。
- 次に、 仕事の詳細。 の中に IAMの役割、前提条件から IAM ロールを選択します。例:
AWSGlueRole.
- 選択する Save.
ジョブの実行と監視
- ETL ジョブを構成したら、ジョブを実行できます。 AWS Glue は ETL プロセスを実行し、Google BigQuery からデータを抽出して、指定した S3 の場所にロードします。
- AWS Glue コンソールでジョブの進行状況を監視します。 ログとジョブの実行履歴を確認して、すべてがスムーズに実行されていることを確認できます。

データ検証
- ジョブが正常に実行されたら、S3 バケット内のデータを検証して、期待どおりであることを確認します。 を使用して結果を確認できます Amazon S3 セレクト.

自動化とスケジュール設定
- 必要に応じて、ETL プロセスを定期的に実行するようにジョブのスケジュールを設定します。 AWS を使用して ETL ジョブを自動化し、S3 バケットが Google BigQuery からの最新データで常に最新の状態になるようにできます。
Google BigQuery から Amazon S3 にデータを転送するための AWS Glue ETL ジョブが正常に設定されました。 次に、このデータを集約して Google BigQuery に転送する ETL ジョブを作成します。
AWS Glue Studio Visual ETL を使用して地震ホットスポットを見つける。
- Open AWSグルー コンソール。
- AWS Glue で、次の場所に移動します。 ビジュアルETL 下 ETL ジョブ セクションを作成し、次を使用して新しい ETL ジョブを作成します ビジュアル 真っ白なキャンバスで。
- AWS Glue ジョブの名前を指定します。例:
s3-bq-dataflow. - 選択する アマゾンS3 データソースとして。
- 入力します 名前 ソース Amazon S3 ノードの場合 (地震など)。
- 選択 S3の場所 として S3ソースタイプ.
- 前提条件で作成した S3 バケットを S3 URL例えば、
s3://<YourBucketName>/noaa_significant_earthquakes/earthquakes/. - 交換する必要があります
<YourBucketName>バケットの名前を付けます。 - 現在地に最も近い データフォーマット as 寄せ木細工の床.
- 選択 スキーマを推測する.

- 次に、 フィールドを選択 変換。
- 選択
earthquakesas ノードの親. - フィールドを選択します:
id, eq_primary, and country.
- 選択
- 次に、 集計変換.
- 入力します 名前 例えば、
Aggregate. - 選択する
Select Fieldsas ノードの親. - 選択する
eq_primary and countryとして group by 列。 - Add
idとして 集計 列とcountとして 集計関数.
- 入力します 名前 例えば、
- 次に、 フィールド名の変更 変換。
- ソース Amazon S3 ノードの名前を入力します。例:
Rename eq_primary. - 選択する
Aggregateas ノードの親. - 選択する
eq_primaryとして 現在のフィールド名 入力してくださいearthquake_magnitudeとして 新しいフィールド名.
- ソース Amazon S3 ノードの名前を入力します。例:
- 次に、 フィールド名の変更
- ソース Amazon S3 ノードの名前を入力します。例:
Rename count(id). - 選択する
Rename eq_primaryas ノードの親. - 選択する
count(id)として 現在のフィールド名 入力してくださいnumber_of_earthquakesとして 新しいフィールド名.
- ソース Amazon S3 ノードの名前を入力します。例:
- 次に、データターゲットを次のように選択します Google ビッグクエリ.
- たとえば、Google BigQuery ソース ノードの名前を指定します。
most_powerful_earthquakes. - ドロップダウンリストから Google BigQuery接続例えば、
bq-connection. - 選択 親プロジェクト例えば、
bigquery-public-datasources. - の名前を入力してください 表 たとえば、[データセット].[テーブル] の形式で作成したいとします。
noaa_significant_earthquakes.most_powerful_earthquakes. - 選択する 直接 として 書き込みメソッド.

- たとえば、Google BigQuery ソース ノードの名前を指定します。
- 次に、 仕事の詳細 タブと IAMの役割、前提条件から IAM ロールを選択します。例:
AWSGlueRole.
- 選択する Save.
ジョブの実行と監視
- ETL ジョブを構成したら、ジョブを実行できます。 AWS Glue は ETL プロセスを実行し、Google BigQuery からデータを抽出して、指定された S3 の場所にロードします。
- AWS Glue コンソールでジョブの進行状況を監視します。 ログとジョブの実行履歴を確認して、すべてがスムーズに実行されていることを確認できます。
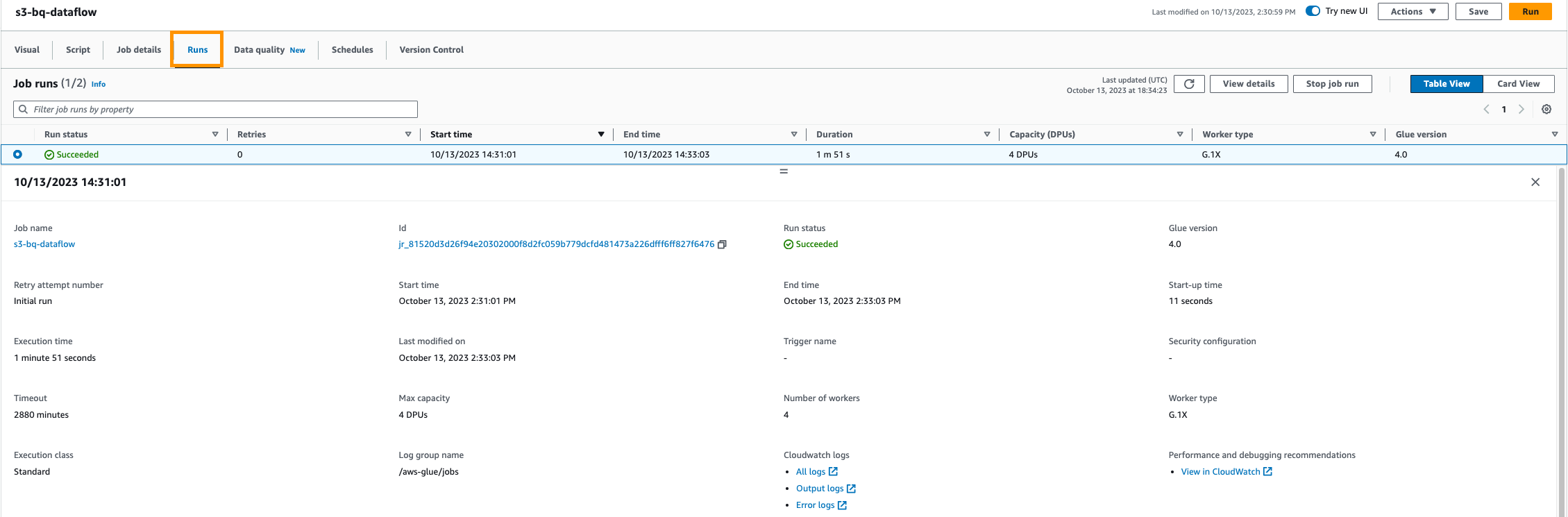
データ検証
- ジョブが正常に実行されたら、Google BigQuery データセット内のデータを検証します。 この ETL ジョブは、最も強力な地震が発生した国のリストを返します。 これは、国ごとに特定のマグニチュードの地震の数をカウントすることによってこれらを提供します。

自動化とスケジュール設定
- ETL プロセスを定期的に実行するようにジョブのスケジュールを設定できます。 AWS Glue を使用すると、ETL ジョブを自動化し、S3 バケットが Google BigQuery からの最新データで常に最新の状態に保たれます。
それでおしまい! Amazon S3 から Google BigQuery にデータを転送するための AWS Glue ETL ジョブが正常に設定されました。 この統合を使用すると、これら XNUMX つのプラットフォーム間でのデータの抽出、変換、読み込みのプロセスを自動化し、データを分析や他のアプリケーションにすぐに利用できるようになります。
クリーンアップ
料金の発生を避けるには、次の手順を実行して、このブログ投稿で使用されているリソースを AWS アカウントからクリーンアップしてください。
- AWS Glue コンソールで、選択します ビジュアルETL ナビゲーションペインに表示されます。
- ジョブのリストからジョブを選択します
bq-s3-data-flow削除してください。 - ジョブのリストからジョブを選択します
s3-bq-data-flow削除してください。 - AWS Glue コンソールで、選択します Connections 下のナビゲーションペインで データカタログ.
- 選択する BiqQuery 接続 作成して削除します。
- Secrets Manager コンソールで、作成したシークレットを選択して削除します。
- IAMコンソールで、 役割 ナビゲーションペインで、AWS Glue ETL ジョブ用に作成したロールを選択して削除します。
- Amazon S3 コンソールで、作成した S3 バケットを検索し、選択します 空の オブジェクトを削除してから、バケットを削除します。
- Google BigQuery リソースを含むプロジェクトを削除して、Google アカウント内のリソースをクリーンアップします。 ドキュメントに従って、 Google リソースをクリーンアップする.
まとめ
AWS Glue と Google BigQuery の統合により、分析パイプラインが簡素化され、洞察が得られるまでの時間が短縮され、データ主導型の意思決定が促進されます。 これにより、組織はデータの統合と分析を合理化できます。 AWS Glue のサーバーレスの性質により、インフラストラクチャ管理が不要になり、ジョブの実行中に消費されたリソースに対してのみ料金が発生します。 組織が意思決定のためにデータにますます依存するようになっているため、このネイティブ Spark コネクタは、データ分析のニーズに迅速に対応する、効率的でコスト効率の高い俊敏なソリューションを提供します。
AWS Glue で Google BigQuery のテーブルの読み取りと書き込みを行う方法に興味がある場合は、ステップバイステップの説明をご覧ください。 ビデオチュートリアル。 このチュートリアルでは、接続の設定からデータ転送フローの実行までのプロセス全体を説明します。 AWS Glue の詳細については、次のサイトをご覧ください。 AWSグルー.
付録
AWS Glue コンソールの代わりにコードを使用してこの例を実装する場合は、次のコード スニペットを使用します。
Google BigQuery からのデータの読み取りと Amazon S3 へのデータの書き込み
Amazon S3 からのデータの読み取りと集約、および Google BigQuery への書き込み
著者について
 カルティカイ・カトール アマゾン ウェブ サービス (AWS) のグローバル ライフ サイエンスのソリューション アーキテクトです。 彼は、AWS Analytics サービスに重点を置き、顧客のニーズを満たす革新的でスケーラブルなソリューションを構築することに情熱を注いでいます。 テクノロジーの世界を超えて、彼は熱心なランナーであり、ハイキングを楽しんでいます。
カルティカイ・カトール アマゾン ウェブ サービス (AWS) のグローバル ライフ サイエンスのソリューション アーキテクトです。 彼は、AWS Analytics サービスに重点を置き、顧客のニーズを満たす革新的でスケーラブルなソリューションを構築することに情熱を注いでいます。 テクノロジーの世界を超えて、彼は熱心なランナーであり、ハイキングを楽しんでいます。
 カメン・シャルランドジエフ は、シニア ビッグ データおよび ETL ソリューション アーキテクトであり、Amazon AppFlow の専門家です。 彼は、複雑なデータ統合の課題に直面している顧客の生活を楽にするという使命を担っています。 彼の秘密兵器? フルマネージドのローコード AWS サービスにより、コーディングなしで最小限の労力でジョブを実行できます。
カメン・シャルランドジエフ は、シニア ビッグ データおよび ETL ソリューション アーキテクトであり、Amazon AppFlow の専門家です。 彼は、複雑なデータ統合の課題に直面している顧客の生活を楽にするという使命を担っています。 彼の秘密兵器? フルマネージドのローコード AWS サービスにより、コーディングなしで最小限の労力でジョブを実行できます。
 アンシュル・シャルマ は、AWS Glue チームのソフトウェア開発エンジニアです。 彼は、あらゆるデータ ソース (データ ウェアハウス、データ レイク、NoSQL など) を Glue ETL ジョブに接続する Glue 顧客ネイティブの方法を提供する接続憲章を推進しています。 テクノロジーの世界を超えて、彼はクリケットとサッカーの愛好家です。
アンシュル・シャルマ は、AWS Glue チームのソフトウェア開発エンジニアです。 彼は、あらゆるデータ ソース (データ ウェアハウス、データ レイク、NoSQL など) を Glue ETL ジョブに接続する Glue 顧客ネイティブの方法を提供する接続憲章を推進しています。 テクノロジーの世界を超えて、彼はクリケットとサッカーの愛好家です。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/unlock-scalable-analytics-with-aws-glue-and-google-bigquery/

