このブログ投稿は、Veoneer の Caroline Chung との共同執筆です。
Veoneer は世界的な自動車エレクトロニクス企業であり、自動車電子安全システムの世界的リーダーです。同社はクラス最高の拘束制御システムを提供し、世界中の自動車メーカーに 1 億個を超える電子制御ユニットと衝突センサーを納入してきました。同社は、自動車の安全開発の 70 年の歴史を基礎に、交通事故を防止し、事故を軽減する最先端のハードウェアとシステムに特化し続けています。
自動車の車室内センシング (ICS) は、カメラやレーダーなどの数種類のセンサーと、人工知能 (AI) および機械学習 (ML) ベースのアルゴリズムを組み合わせて使用し、安全性を強化し、ライディング エクスペリエンスを向上させる新興分野です。このようなシステムの構築は複雑な作業となる場合があります。開発者は、トレーニングやテストの目的で、大量の画像に手動で注釈を付ける必要があります。これは非常に時間とリソースを大量に消費します。このようなタスクの所要時間は数週間です。さらに、企業は人的ミスによる一貫性のないラベルなどの問題にも対処しなければなりません。
AWS は、ML などの高度な分析を通じて、開発速度の向上とそのようなシステムの構築コストの削減を支援することに重点を置いています。私たちのビジョンは、自動化されたアノテーションに ML を使用して、安全モデルの再トレーニングを可能にし、一貫性と信頼性の高いパフォーマンス指標を確保することです。この投稿では、Amazon の Worldwide Specialist Organization および ジェネレーティブAIイノベーションセンターでは、キャビン内の画像の頭部境界ボックスとキー ポイントの注釈のためのアクティブ ラーニング パイプラインを開発しました。このソリューションにより、コストが 90% 以上削減され、アノテーション プロセスが数週間から数時間に短縮され、同様の ML データのラベル付けタスクでの再利用が可能になります。
ソリューションの概要
アクティブ ラーニングは、モデルをトレーニングするために最も有益なデータを選択して注釈を付ける反復プロセスを含む ML アプローチです。少数のラベル付きデータ セットと大規模なラベルなしデータ セットが与えられた場合、アクティブ ラーニングはモデルのパフォーマンスを向上させ、ラベル付けの労力を軽減し、人間の専門知識を統合して堅牢な結果を実現します。この投稿では、AWS サービスを使用して画像アノテーション用のアクティブ ラーニング パイプラインを構築します。
次の図は、アクティブ ラーニング パイプラインの全体的なフレームワークを示しています。ラベル付けパイプラインは、 Amazon シンプル ストレージ サービス (Amazon S3) をバケット化し、ML モデルと人間の専門知識の協力を得て、注釈付き画像を出力します。トレーニング パイプラインはデータを前処理し、それを使用して ML モデルをトレーニングします。初期モデルは手動でラベル付けされた小規模なデータセットでセットアップおよびトレーニングされ、ラベル付けパイプラインで使用されます。ラベル付けパイプラインとトレーニング パイプラインは、より多くのラベル付きデータを使用して徐々に反復して、モデルのパフォーマンスを向上させることができます。
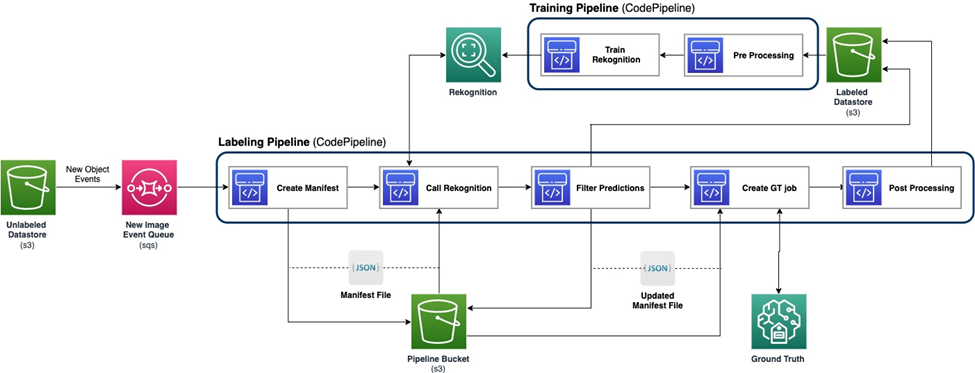
ラベル付けパイプラインでは、 AmazonS3イベント通知 画像の新しいバッチがラベルなしデータストア S3 バケットに入るときに呼び出され、ラベル付けパイプラインがアクティブになります。モデルは新しい画像に関する推論結果を生成します。カスタマイズされた判断関数は、推論信頼度スコアまたはその他のユーザー定義関数に基づいてデータの一部を選択します。このデータとその推論結果は、人間によるラベル付けジョブのために送信されます。 Amazon SageMakerグラウンドトゥルース パイプラインによって作成されます。人間によるラベル付けプロセスはデータへの注釈付けに役立ち、変更された結果は残りの自動注釈付きデータと結合され、後でトレーニング パイプラインで使用できます。
モデルの再トレーニングはトレーニング パイプラインで行われ、人間がラベル付けしたデータを含むデータセットを使用してモデルを再トレーニングします。ファイルの保存場所を記述するマニフェスト ファイルが生成され、同じ初期モデルが新しいデータで再トレーニングされます。再トレーニング後、新しいモデルが初期モデルを置き換え、アクティブ ラーニング パイプラインの次の反復が開始されます。
モデルの展開
ラベル付けパイプラインとトレーニング パイプラインの両方がデプロイされます。 AWS コードパイプライン. AWS コードビルド 実装にはインスタンスが使用され、少量のデータに対して柔軟かつ高速です。スピードが必要な場合は、 アマゾンセージメーカー GPU インスタンスに基づいてエンドポイントを割り当て、プロセスをサポートおよび加速するためにより多くのリソースを割り当てます。
モデルの再トレーニング パイプラインは、新しいデータセットがある場合、またはモデルのパフォーマンスの改善が必要な場合に呼び出すことができます。再トレーニング パイプラインにおける重要なタスクの 1 つは、トレーニング データとモデルの両方のバージョン管理システムを用意することです。などの AWS のサービスですが、 Amazonの再認識 統合されたバージョン管理機能を備えているため、パイプラインの実装が簡単になります。カスタマイズされたモデルにはメタデータのログ記録や追加のバージョン管理ツールが必要です。
ワークフロー全体は、 AWSクラウド開発キット (AWS CDK) を使用して、以下を含む必要な AWS コンポーネントを作成します。
- CodePipeline ジョブと SageMaker ジョブの 2 つの役割
- ワークフローを調整する 2 つの CodePipeline ジョブ
- パイプラインのコードアーティファクト用の 3 つの SXNUMX バケット
- ジョブマニフェスト、データセット、モデルにラベルを付けるための 3 つの SXNUMX バケット
- 前処理と後処理 AWSラムダ SageMaker Ground Truth ラベル付けジョブの関数
AWS CDK スタックは高度にモジュール化されており、さまざまなタスク間で再利用可能です。トレーニング、推論コード、および SageMaker Ground Truth テンプレートは、同様のアクティブ ラーニング シナリオに置き換えることができます。
モデルトレーニング
モデルのトレーニングには、頭部境界ボックスの注釈と人間のキー ポイントの注釈という 2 つのタスクが含まれます。このセクションでは両方を紹介します。
頭の境界ボックスの注釈
頭部境界ボックス アノテーションは、画像内の人間の頭部の境界ボックスの位置を予測するタスクです。私たちは、 Amazon Rekognitionカスタムラベル 頭の境界ボックスの注釈のモデル。次の サンプルノート SageMaker を介して Rekognition Custom Labels モデルをトレーニングする方法に関するステップバイステップのチュートリアルを提供します。
トレーニングを開始するには、まずデータを準備する必要があります。トレーニング用のマニフェスト ファイルとテスト データセット用のマニフェスト ファイルを生成します。マニフェスト ファイルには複数のアイテムが含まれており、それぞれがイメージ用です。以下は、イメージのパス、サイズ、および注釈情報を含むマニフェスト ファイルの例です。
マニフェスト ファイルを使用すると、トレーニングとテストのためにデータセットを Rekognition Custom Labels モデルにロードできます。さまざまな量のトレーニング データを使用してモデルを反復し、同じ 239 枚の未確認の画像でテストしました。このテストでは、 mAP_50 スコアは 0.33 枚のトレーニング画像の 114 から 0.95 枚のトレーニング画像の 957 に増加しました。次のスクリーンショットは、最終的な Rekognition Custom Labels モデルのパフォーマンス メトリックを示しています。F1 スコア、精度、再現率の点で優れたパフォーマンスが得られます。

さらに、1,128 枚の画像を含む非公開データセットでモデルをテストしました。このモデルは、目に見えないデータに対して正確な境界ボックス予測を一貫して予測し、高いパフォーマンスをもたらします。 mAP_50 94.9%。次の例は、頭の境界ボックスを含む自動アノテーションが付けられた画像を示しています。

重要なポイントの注釈
キー ポイントの注釈は、目、耳、鼻、口、首、肩、肘、手首、腰、足首などのキー ポイントの位置を生成します。この特定のタスクを予測するには、位置の予測に加えて、各ポイントの可視性が必要であり、そのために新しい方法を設計します。
重要なポイントの注釈には、 Yolo 8 ポーズモデル SageMaker を初期モデルとして使用します。まず、Yolo の要件に従ってラベル ファイルと構成 .yaml ファイルを生成するなど、トレーニング用のデータを準備します。データを準備した後、モデルをトレーニングし、モデルの重みファイルを含むアーティファクトを保存します。トレーニングされたモデルの重みファイルを使用して、新しい画像に注釈を付けることができます。
トレーニング段階では、可視ポイントと遮蔽ポイントを含む、位置がラベル付けされたすべてのポイントがトレーニングに使用されます。したがって、このモデルはデフォルトで予測の位置と信頼度を提供します。次の図では、0.6 に近い大きな信頼しきい値 (主しきい値) により、可視または遮蔽された点とカメラの視点の外側の点を分割できます。ただし、遮蔽されたポイントと可視ポイントは信頼度によって分離されません。これは、予測された信頼度が可視性の予測には役に立たないことを意味します。

可視性の予測を取得するために、遮蔽されたポイントとカメラの視点の外側の両方を除外し、可視ポイントのみを含むデータセットでトレーニングされた追加のモデルを導入します。次の図は、可視性が異なるポイントの分布を示しています。追加モデルでは可視点とそれ以外の点を分離することができます。 0.6 付近のしきい値 (追加のしきい値) を使用して、可視ポイントを取得できます。これら XNUMX つのモデルを組み合わせて、位置と可視性を予測する方法を設計します。

キー ポイントは、最初に位置と主信頼度を使用してメイン モデルによって予測され、次に追加モデルから追加の信頼度予測が取得されます。その可視性は次のように分類されます。
- 主信頼度が主しきい値より大きく、追加信頼度が追加しきい値より大きい場合に表示されます。
- 主信頼度が主しきい値より大きく、追加信頼度が追加しきい値以下の場合、オクルージョンされます。
- カメラのレビュー外(そうでない場合)
キー ポイントの注釈の例を次の図に示します。実線のマークは可視ポイント、中空のマークは隠れたポイントです。カメラの外側のレビューポイントは表示されません。

基準に基づいて OKS MS-COCO データセットの定義に基づいて、私たちの方法は、未確認のテスト データセットで 50% の mAP_98.4 を達成できます。可視性の点では、この方法では同じデータセットで 79.2% の分類精度が得られます。
人間のラベル付けと再トレーニング
モデルはテスト データでは優れたパフォーマンスを達成しますが、新しい実世界のデータでは間違いを犯す可能性がまだあります。人間によるラベル付けは、再トレーニングを使用してモデルのパフォーマンスを向上させるためにこれらの間違いを修正するプロセスです。すべての頭部境界ボックスまたはキーポイントの出力に対して、ML モデルから出力される信頼値を組み合わせた判定関数を設計しました。最終スコアを使用して、これらの間違いと、その結果生じた不適切なラベル付けされた画像を特定します。これらの画像は、人間によるラベル付けプロセスに送信する必要があります。
不適切なラベルが付けられた画像に加えて、画像のごく一部が人間によるラベル付けのためにランダムに選択されます。これらの人間がラベル付けした画像は、再トレーニングのために現在のバージョンのトレーニング セットに追加され、モデルのパフォーマンスと全体的なアノテーションの精度が向上します。
実装では、SageMaker Ground Truth を使用します。 人間のラベル付け プロセス。 SageMaker Ground Truth は、データラベル付けのためのユーザーフレンドリーで直感的な UI を提供します。次のスクリーンショットは、頭の境界ボックスの注釈に対する SageMaker Ground Truth のラベル付けジョブを示しています。

次のスクリーンショットは、キー ポイント アノテーションの SageMaker Ground Truth ラベル付けジョブを示しています。

コスト、スピード、再利用性
次の表に示すように、人間によるラベル付けと比較した場合の当社のソリューションを使用する主な利点は、コストと速度です。これらの表を使用して、コスト削減と速度の向上を表します。高速化された GPU SageMaker インスタンス ml.g4dn.xlarge を使用すると、100,000 枚の画像に対する全期間のトレーニングと推論のコストが人間によるラベル付けのコストより 99% 削減され、速度は人間によるラベル付けより 10 ~ 10,000 倍高速になります (環境に応じて異なります)。タスク。
最初の表は、コストパフォーマンスの指標をまとめたものです。
| モデル | mAP_50 は 1,128 枚のテスト画像に基づいています | 100,000枚の画像に基づくトレーニングコスト | 100,000枚の画像に基づく推論コスト | 人間によるアノテーションと比較してコスト削減 | 100,000 枚の画像に基づく推論時間 | 人間によるアノテーションと比較した時間の加速 |
| 認識頭境界ボックス | 0.949 | $4 | $22 | 99%以下 | 5.5午後 | 日 |
| ヨロのキーポイント | 0.984 | $27.20 | * 10ドル | 99.9%以下 | 分 | ウィークス |
次の表は、パフォーマンス指標をまとめたものです。
| 注釈タスク | mAP_50 (%) | トレーニング費用 ($) | 推論コスト ($) | 推論時間 |
| 頭の境界ボックス | 94.9 | 4 | 22 | 5.5時間 |
| キーポイント | 98.4 | 27 | 10 | 5 minutes |
さらに、当社のソリューションは同様のタスクでの再利用性を提供します。先進運転支援システム (ADAS) や車室内システムなどの他のシステム向けのカメラ認識開発にも、当社のソリューションを採用できます。
まとめ
この投稿では、AWS サービスを利用して車内画像に自動アノテーションを付けるためのアクティブ ラーニング パイプラインを構築する方法を説明しました。アノテーションプロセスの自動化と迅速化を可能にする ML の力と、AWS のサービスでサポートされているモデルまたは SageMaker でカスタマイズされたモデルを使用するフレームワークの柔軟性を実証します。 Amazon S3、SageMaker、Lambda、および SageMaker Ground Truth を使用すると、データのストレージ、アノテーション、トレーニング、デプロイメントを合理化し、コストを大幅に削減しながら再利用性を実現できます。このソリューションを実装することで、自動車会社は自動画像アノテーションなどの ML ベースの高度な分析を使用して、より俊敏性とコスト効率を高めることができます。
今すぐ始めて、次の機能を解き放ちましょう AWSサービス 自動車の車内センシングのユースケースのための機械学習も可能です。
著者について
 ヤンシャン・ユー Amazon Generative AI Innovation Center の応用科学者です。産業アプリケーション向けの AI および機械学習ソリューションの構築に 9 年以上の経験があり、生成 AI、コンピューター ビジョン、時系列モデリングを専門としています。
ヤンシャン・ユー Amazon Generative AI Innovation Center の応用科学者です。産業アプリケーション向けの AI および機械学習ソリューションの構築に 9 年以上の経験があり、生成 AI、コンピューター ビジョン、時系列モデリングを専門としています。
 天一毛 は、シカゴ地域を拠点とする AWS の応用科学者です。 彼は機械学習および深層学習ソリューションの構築に 5 年以上の経験があり、人間のフィードバックによるコンピューター ビジョンと強化学習に重点を置いています。 彼は、顧客と協力して顧客の課題を理解し、AWS のサービスを使用して革新的なソリューションを作成することでそれらを解決することに喜びを感じています。
天一毛 は、シカゴ地域を拠点とする AWS の応用科学者です。 彼は機械学習および深層学習ソリューションの構築に 5 年以上の経験があり、人間のフィードバックによるコンピューター ビジョンと強化学習に重点を置いています。 彼は、顧客と協力して顧客の課題を理解し、AWS のサービスを使用して革新的なソリューションを作成することでそれらを解決することに喜びを感じています。
 ヤンルー・シャオ Amazon Generative AI Innovation Center の応用科学者であり、顧客の現実世界のビジネス問題に対する AI/ML ソリューションを構築しています。彼は、製造、エネルギー、農業などのさまざまな分野で働いてきました。ヤンルーは博士号を取得しました。オールド・ドミニオン大学でコンピューターサイエンスの博士号を取得。
ヤンルー・シャオ Amazon Generative AI Innovation Center の応用科学者であり、顧客の現実世界のビジネス問題に対する AI/ML ソリューションを構築しています。彼は、製造、エネルギー、農業などのさまざまな分野で働いてきました。ヤンルーは博士号を取得しました。オールド・ドミニオン大学でコンピューターサイエンスの博士号を取得。
 ポール・ジョージ は、自動車技術において 15 年以上の経験を持つ、熟練した製品リーダーです。彼は、製品管理、戦略、市場開拓、およびシステム エンジニアリング チームを率いることに熟達しています。彼は、いくつかの新しいセンシングおよび知覚製品を世界中で開発し、発売してきました。 AWS では、自動運転車ワークロードの戦略と市場投入を主導しています。
ポール・ジョージ は、自動車技術において 15 年以上の経験を持つ、熟練した製品リーダーです。彼は、製品管理、戦略、市場開拓、およびシステム エンジニアリング チームを率いることに熟達しています。彼は、いくつかの新しいセンシングおよび知覚製品を世界中で開発し、発売してきました。 AWS では、自動運転車ワークロードの戦略と市場投入を主導しています。
 キャロライン・チャン Veoneer (Magna International が買収) のエンジニアリング マネージャーであり、センシングおよび知覚システムの開発に 14 年以上の経験があります。彼女は現在、マグナ インターナショナルでインテリア センシングの事前開発プログラムを指揮し、コンピューティング ビジョン エンジニアとデータ サイエンティストのチームを管理しています。
キャロライン・チャン Veoneer (Magna International が買収) のエンジニアリング マネージャーであり、センシングおよび知覚システムの開発に 14 年以上の経験があります。彼女は現在、マグナ インターナショナルでインテリア センシングの事前開発プログラムを指揮し、コンピューティング ビジョン エンジニアとデータ サイエンティストのチームを管理しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

