これは、Gramener の Shravan Kumar と Avirat S が共著したゲスト投稿です。
グラメナー ストライブ は、農業、林業、水管理、再生可能エネルギーに重点を置くことで、持続可能な開発に貢献しています。グラメナー氏は、環境や社会への影響について十分な情報に基づいた意思決定を行うために必要なツールと洞察を当局に提供することで、より持続可能な未来を構築する上で重要な役割を果たしています。
都市ヒートアイランド (UHI) は、周囲の農村地域よりも著しく高い気温を経験する都市内のエリアです。 UHI はさまざまな環境問題や健康問題を引き起こす可能性があるため、懸念が高まっています。この課題に対処するために、Gramener は空間データと高度なモデリング技術を使用して、次の UHI 効果を理解し、軽減するソリューションを開発しました。
- 温度の不一致 – UHI により、都市部が周囲の農村部よりも暑くなる可能性があります。
- 健康への影響 – UHI 内の温度が高いと、熱関連の病気や死亡者数が 10 ~ 20% 増加します。
- エネルギー消費 – UHI は空調需要を増大させ、その結果、エネルギー消費量が最大 20% 増加します。
- 大気質 – UHI は大気の質を悪化させ、スモッグや粒子状物質のレベルの上昇を引き起こし、呼吸器疾患を増加させる可能性があります。
- 経済的影響 – UHI により、追加のエネルギーコスト、インフラストラクチャの損傷、医療費が数十億ドル発生する可能性があります。
Gramener の GeoBox ソリューションを使用すると、ユーザーは強力な API を通じて公共の地理空間データを簡単に利用して分析できるようになり、既存のワークフローへのシームレスな統合が可能になります。これにより、探索が合理化され、貴重な時間とリソースが節約され、コミュニティが UHI ホットスポットを迅速に特定できるようになります。その後、GeoBox は生データを、ラスター、GeoJSON、Excel などの使いやすい形式で提示される実用的な洞察に変換し、UHI 緩和戦略を明確に理解し、即時実装できるようにします。これにより、コミュニティは情報に基づいた意思決定を行い、持続可能な都市開発の取り組みを実行できるようになり、最終的には大気質の改善、エネルギー消費の削減、より涼しく健康的な環境を通じて市民をサポートできるようになります。
この投稿では、Gramener の GeoBox ソリューションがどのように機能するかを示します。 Amazon SageMaker 地理空間機能を使用します 地球観測分析を実行し、衛星画像から UHI の洞察を解き明かします。 SageMaker の地理空間機能により、データ サイエンティストや機械学習 (ML) エンジニアは、地理空間データを使用してモデルを構築、トレーニング、デプロイすることが簡単になります。 SageMaker 地理空間機能を使用すると、大規模な地理空間データセットを効率的に変換して強化し、事前トレーニングされた ML モデルを使用して製品開発と洞察を得るまでの時間を短縮できます。
ソリューションの概要
Geobox は、空間特性を利用して UHI 効果を分析および予測することを目的としています。これは、提案されているインフラストラクチャと土地利用の変更が UHI パターンにどのような影響を与えるかを理解し、UHI に影響を与える主要な要因を特定するのに役立ちます。この分析モデルは、地表面温度 (LST) の粒度レベルでの正確な推定値を提供し、グラメナーがパラメーター (使用された指数とデータの名前) に基づいて UHI 効果の変化を定量化できるようにします。
Geobox を使用すると、市の部門は次のことを行うことができます。
- 気候適応の改善 計画 – 情報に基づいた決定により、猛暑の影響が軽減されます。
- 緑地拡張の支援 – より多くの緑地が空気の質と生活の質を向上させます。
- 部門間のコラボレーションの強化 – 連携した取り組みにより公共の安全が向上します。
- 戦略的な緊急事態への備え – 的を絞った計画により、緊急事態の可能性が軽減されます。
- 医療サービスの連携 – 協力はより効果的な健康介入につながります。
ソリューションワークフロー
このセクションでは、UHI ソリューションの中核として機能する、データ収集から空間モデリング、予測まで、さまざまなコンポーネントがどのように連携するかについて説明します。このソリューションは構造化されたワークフローに従い、カナダの都市における UHI への対応に主に焦点を当てています。
フェーズ 1: データ パイプライン
Landsat 8 衛星は、15 日ごとの午前 11 時 30 分に対象地域の詳細な画像を撮影し、都市の景観と環境の包括的なビューを提供します。 Mapbox の Supermercado Python ライブラリをズーム レベル 48 で使用して、19 メートルのグリッド サイズでグリッド システムが確立され、正確な空間分析が可能になります。

フェーズ 2: 探索的分析
インフラストラクチャと人口データ レイヤーを統合する Geobox により、ユーザーは都市の変動分布を視覚化し、都市の形態学的洞察を導き出すことができ、都市の構造と発展の包括的な分析が可能になります。
また、フェーズ 1 の Landsat 画像は、一貫性と精度を確保するために 48 メートルのグリッドに細心の注意を払ってスケーリングされたデータを使用して、正規化差分植生指数 (NDVI) や正規化差分構築指数 (NDBI) などの洞察を得るために使用されます。
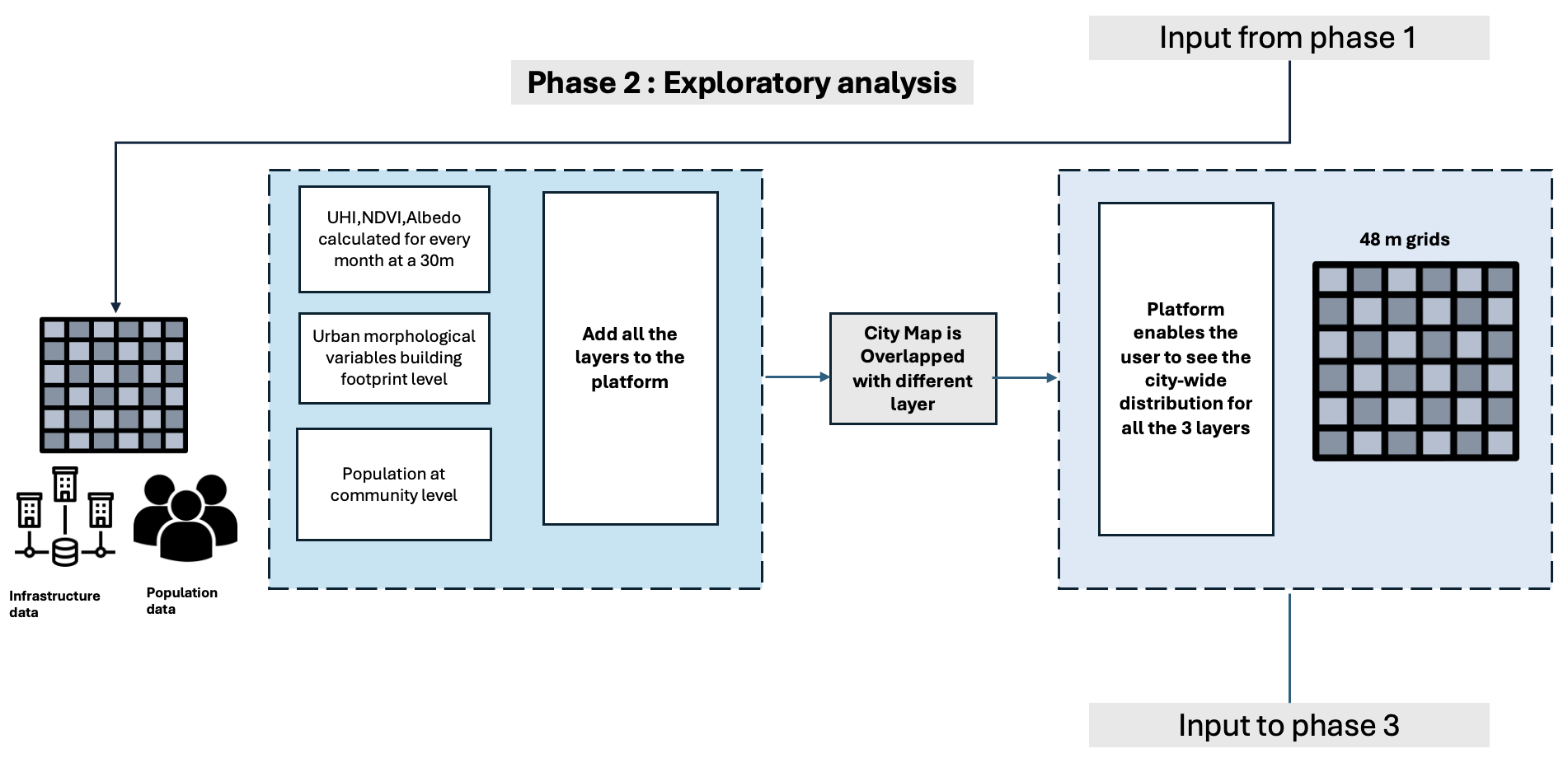
次の変数が使用されます。
- 地表温度
- 建築現場の範囲
- NDVI
- ビルディングブロックの範囲
- NDBI
- 建築面積
- アルベド
- 建物数
- 修正正規化差水指数 (MNDWI)
- 建物の高さ
- 階数と床面積
- 容積率
フェーズ 3: 分析モデル
このフェーズは 3 つのモジュールで構成されており、データに ML モデルを使用して、LST と他の影響力のある要因との関係についての洞察を得ることができます。
- モジュール 1: ゾーン統計と集計 – ゾーン統計は、値ラスターの値を使用して統計を計算する際に重要な役割を果たします。これには、ゾーン ラスターに基づいて各ゾーンの統計データを抽出することが含まれます。集計は 100 メートルの解像度で実行され、データの包括的な分析が可能になります。
- モジュール 2: 空間モデリング – Gramener は、地表面温度 (LST) と他の変数の間の相関関係を解明するために、2014 つの回帰モデル (線形効果、空間効果、および空間固定効果) を評価しました。これらのモデルの中で、空間固定効果モデルは、特に 2020 年から XNUMX 年にわたる時間枠で最も高い平均 R 二乗値をもたらしました。
- モジュール 3: 変数の予測 – 短期的に変数を予測するために、グラメナーは指数平滑法手法を採用しました。これらの予測は、将来の LST 値とその傾向を理解するのに役立ちました。さらに、代表濃度経路 (RCP8.5) データを使用して長期間にわたる LST 値を予測することにより、長期スケール分析を掘り下げました。
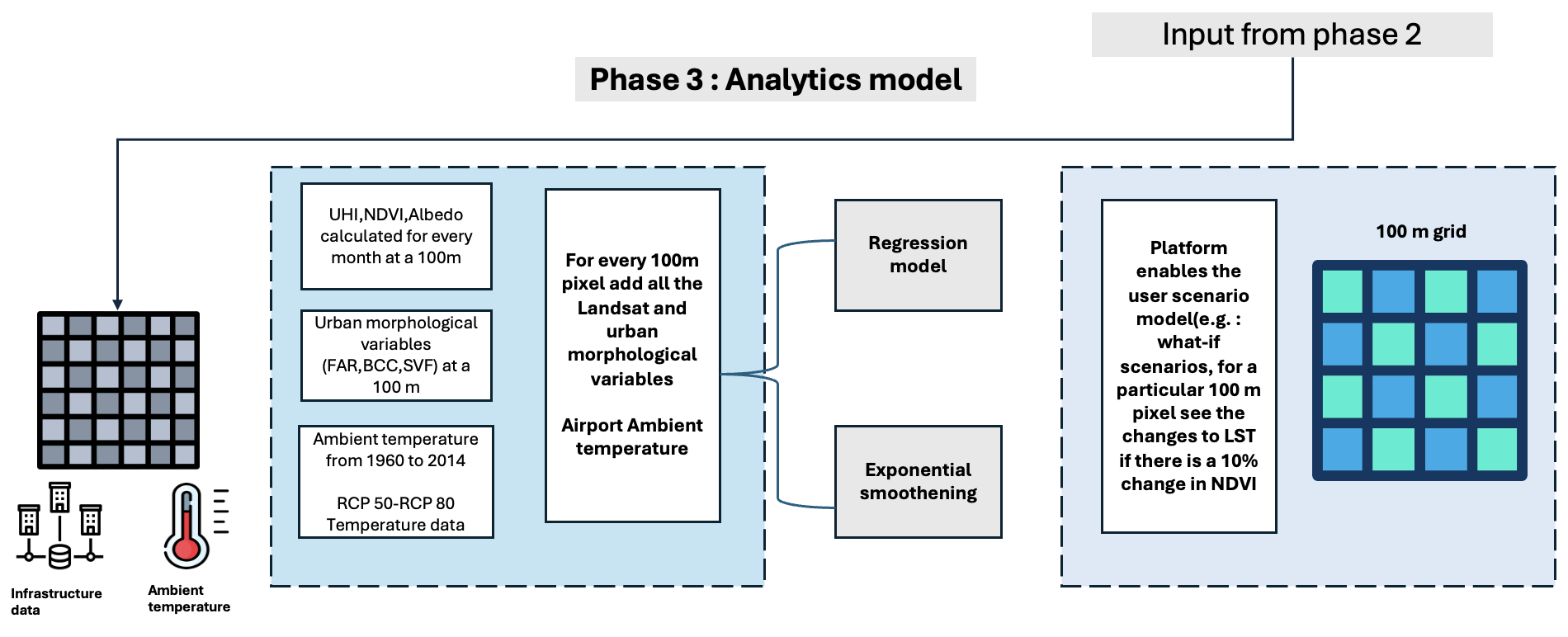
データの取得と前処理
モジュールを実装するために、Gramener は SageMaker 地理空間ノートブックを使用しました。 Amazon SageMakerスタジオ。地理空間ノートブック カーネルには、一般的に使用される地理空間ライブラリがプリインストールされており、Python ノートブック環境内で地理空間データを直接視覚化し、処理できるようになります。
Gramener は、建物の評価や温度データ、衛星画像などのさまざまなデータセットを使用して LST の傾向を予測しました。 UHI ソリューションの鍵は、Landsat 8 衛星からのデータを使用することでした。 USGS と NASA の共同事業であるこの地球画像衛星は、このプロジェクトの基本的なコンポーネントとして機能しました。
SearchRasterDataCollection API、SageMaker は、衛星画像の取得を容易にする専用の機能を提供します。 Gramener は、この API を使用して、UHI ソリューション用の Landsat 8 衛星データを取得しました。
SearchRasterDataCollection API は次の入力パラメータを使用します。
- アーン – クエリで使用されるラスター データ コレクションの Amazon リソース ネーム (ARN)
- 対象地域 – 対象地域を表す GeoJSON ポリゴン
- 時間範囲フィルター – 対象となる時間範囲。次のように示されます。
{StartTime: <string>, EndTime: <string>} - プロパティフィルター – 許容可能な最大雲量の仕様など、補足的なプロパティフィルターを組み込むこともできます
次の例は、API を介して Landsat 8 データをクエリする方法を示しています。
大規模な衛星データを処理するために、Gramener は以下を使用しました。 Amazon SageMaker処理 地理空間コンテナを使用します。 SageMaker Processing は、単一の都市ブロックの処理から地球規模のワークロードの管理まで、さまざまなサイズのタスクに対応するコンピューティング クラスターの柔軟なスケーリングを可能にします。従来、このようなタスク用のコンピューティング クラスターを手動で作成および管理することは、特に地理空間データの処理に適した環境の標準化に伴う複雑さのため、コストと時間がかかりました。
SageMaker の特殊な地理空間コンテナにより、地理空間処理用のクラスターの管理と実行がより簡単になりました。このプロセスに必要なコーディング作業は最小限です。ワークロードを定義し、地理空間データの場所を指定するだけです。 Amazon シンプル ストレージ サービス (Amazon S3) を選択し、適切な地理空間コンテナを選択します。その後、SageMaker Processing は必要なクラスター リソースを自動的にプロビジョニングし、都市レベルから大陸レベルまでのスケールで地理空間タスクの効率的な実行を促進します。
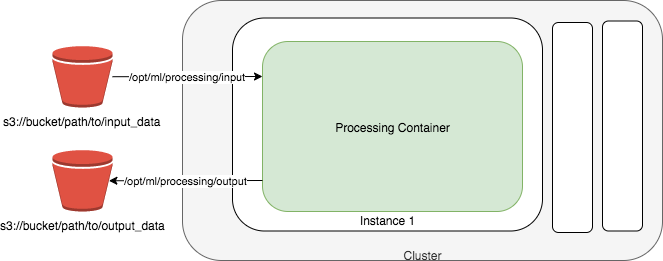
SageMaker は、処理ジョブに必要な基盤となるインフラストラクチャを完全に管理します。ジョブの実行中にクラスター リソースを割り当て、ジョブの完了時にそれらのリソースを削除します。最後に、処理ジョブの結果は、指定された S3 バケットに保存されます。
地理空間画像を使用する SageMaker 処理ジョブは、地理空間ノートブック内から次のように構成できます。
instance_count パラメータは、処理ジョブが使用するインスタンスの数を定義し、instance_type は、使用するインスタンスのタイプを定義します。
次の例は、処理ジョブ クラスターで Python スクリプトがどのように実行されるかを示しています。 run コマンドが呼び出されると、クラスターが起動し、必要なクラスター リソースが自動的にプロビジョニングされます。
空間モデリングと LST 予測
処理ジョブでは、大気圏最上部の分光放射輝度、輝度温度、Landsat 8 からの反射率などのさまざまな変数が計算されます。さらに、容積率 (FAR)、建築敷地の被覆率、建築ブロックの被覆率、シャノンのエントロピー値などの形態学的変数が計算されます。
次のコードは、このバンド演算をどのように実行できるかを示しています。
変数が計算された後、ゾーン統計が実行され、グリッドごとにデータが集計されます。これには、各ゾーン内の対象の値に基づいて統計を計算することが含まれます。これらの計算では、約 100 メートルのグリッド サイズが使用されています。
データを集約した後、空間モデリングが実行されます。グラメナーは、線形回帰や空間固定効果などの空間回帰手法を使用して、観測値の空間依存性を説明しました。このアプローチにより、変数と LST の間の関係をミクロ レベルでモデル化することが容易になります。
次のコードは、このような空間モデリングを実行する方法を示しています。
Gramener は指数平滑法を使用して LST 値を予測しました。指数平滑化は、時間の経過とともに指数関数的に減少する加重平均を過去のデータに適用する時系列予測の効果的な方法です。この方法は、データを平滑化して傾向やパターンを特定する場合に特に効果的です。指数平滑法を使用すると、LST の傾向をより正確に視覚化して予測できるようになり、過去のパターンに基づいて将来の値をより正確に予測できるようになります。
予測を視覚化するために、Gramener 氏は、オープンソースの地理空間ライブラリを備えた SageMaker 地理空間ノートブックを使用して、ベース マップ上にモデル予測をオーバーレイし、ノートブック内で直接階層化された視覚化地理空間データセットを提供しました。
まとめ
この投稿では、グラメナーがクライアントに持続可能な都市環境のためにデータに基づいた意思決定をどのように支援しているかを示しました。 SageMaker を使用することで、Gramener は UHI 分析の大幅な時間を節約し、処理時間を数週間から数時間に短縮しました。この迅速な洞察の生成により、グラメナーのクライアントは、UHI 緩和戦略が必要な領域を正確に特定し、UHI を最小限に抑えるための都市開発とインフラストラクチャ プロジェクトを積極的に計画し、包括的なリスク評価のための環境要因の全体的な理解を得ることができます。
SageMaker を使用して、地球観測データを持続可能性プロジェクトに統合する可能性を発見してください。詳細については、以下を参照してください。 Amazon SageMaker 地理空間機能を使ってみる.
著者について
 アビシェーク・ミタル アマゾン ウェブ サービス (AWS) の世界的な公共部門チームのソリューション アーキテクトであり、主に業界全体の ISV パートナーと協力して、スケーラブルなアーキテクチャを構築し、AWS サービスの導入を促進する戦略を実装するためのアーキテクチャ ガイダンスを提供しています。彼は、クラウドにおける従来のプラットフォームとセキュリティの最新化に情熱を注いでいます。仕事以外では、彼は旅行愛好家です。
アビシェーク・ミタル アマゾン ウェブ サービス (AWS) の世界的な公共部門チームのソリューション アーキテクトであり、主に業界全体の ISV パートナーと協力して、スケーラブルなアーキテクチャを構築し、AWS サービスの導入を促進する戦略を実装するためのアーキテクチャ ガイダンスを提供しています。彼は、クラウドにおける従来のプラットフォームとセキュリティの最新化に情熱を注いでいます。仕事以外では、彼は旅行愛好家です。
 ヤノシュ・ヴォシッツ AWS のシニア ソリューション アーキテクトであり、AI/ML を専門としています。 15 年以上の経験を持つ彼は、AI と ML を活用して革新的なソリューションを実現し、AWS で ML プラットフォームを構築する際に世界中の顧客をサポートしています。彼の専門知識は機械学習、データ エンジニアリング、スケーラブルな分散システムに及び、ソフトウェア エンジニアリングの強力な背景と自動運転などの分野の業界専門知識によって強化されています。
ヤノシュ・ヴォシッツ AWS のシニア ソリューション アーキテクトであり、AI/ML を専門としています。 15 年以上の経験を持つ彼は、AI と ML を活用して革新的なソリューションを実現し、AWS で ML プラットフォームを構築する際に世界中の顧客をサポートしています。彼の専門知識は機械学習、データ エンジニアリング、スケーラブルな分散システムに及び、ソフトウェア エンジニアリングの強力な背景と自動運転などの分野の業界専門知識によって強化されています。
 シュラバンクマール Gramener の顧客成功担当シニア ディレクターであり、ビジネス分析、データ エバンジェリズム、顧客との深い関係構築に 10 年の経験があります。彼は、データ分析、AI および ML の領域におけるクライアント管理、アカウント管理において強固な基礎を築いています。
シュラバンクマール Gramener の顧客成功担当シニア ディレクターであり、ビジネス分析、データ エバンジェリズム、顧客との深い関係構築に 10 年の経験があります。彼は、データ分析、AI および ML の領域におけるクライアント管理、アカウント管理において強固な基礎を築いています。
 アビラットS Gramener の地理空間データ サイエンティストは、AI/ML を活用して地理データから洞察を引き出します。彼の専門知識は災害管理、農業、都市計画であり、その分析は意思決定プロセスに情報を提供します。
アビラットS Gramener の地理空間データ サイエンティストは、AI/ML を活用して地理データから洞察を引き出します。彼の専門知識は災害管理、農業、都市計画であり、その分析は意思決定プロセスに情報を提供します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/understanding-and-predicting-urban-heat-islands-at-gramener-using-amazon-sagemaker-geospatial-capabilities/

