デジタル フットプリントが拡大し、デジタル資産がビジネスに与える影響が増大するにつれて、顧客はインフラストラクチャとアプリケーション リソース全体にわたるセキュリティ上の脅威と脆弱性の増大に直面しています。一般的なサイバーセキュリティの課題は XNUMX つあります。
- さまざまな形式やスキーマのデジタル リソースからログを利用し、それらのログに基づいて脅威発見の分析を自動化します。
- ログがアマゾン ウェブ サービス (AWS)、他のクラウド プロバイダー、オンプレミス、またはエッジ デバイスから取得されたものであっても、顧客はセキュリティ データを一元化して標準化する必要があります。
さらに、セキュリティの脅威を特定するための分析は、脅威アクター、セキュリティベクトル、デジタル資産の変化する状況に合わせて拡張および進化できなければなりません。
この複雑なセキュリティ分析シナリオを解決するための新しいアプローチでは、次を使用してセキュリティ データの取り込みと保存を組み合わせます。 アマゾン セキュリティ レイク を使用して機械学習 (ML) でセキュリティ データを分析します。 アマゾンセージメーカー。 Amazon Security Lake は、クラウドおよびオンプレミスのソースから組織のセキュリティ データを、AWS アカウントに保存されている専用のデータレイクに自動的に一元化する専用のサービスです。 Amazon Security Lake は、セキュリティ データの一元管理を自動化し、統合された AWS サービスとサードパーティ サービスからのログを正規化し、カスタマイズ可能な保持期間でデータのライフサイクルを管理し、ストレージ階層化も自動化します。 Amazon Security Lake はログ ファイルを次の場所に取り込みます。 オープン サイバーセキュリティ スキーマ フレームワーク (OCSF) 形式。Cisco Security、CrowdStrike、Palo Alto Networks などのパートナーをサポートし、AWS 環境外のリソースからの OCSF ログもサポートします。データは標準化されたスキーマに従い、最小限のデータ パイプラインの変更で新しいソースを追加できるため、この統合スキーマにより下流の消費と分析が合理化されます。セキュリティ ログ データが Amazon Security Lake に保存された後、問題はそれをどのように分析するかになります。セキュリティ ログ データを分析するための効果的なアプローチは、ML を使用することです。具体的には、アクティビティとトラフィックのデータを検査し、ベースラインと比較する異常検出です。ベースラインは、その環境においてどのようなアクティビティが統計的に正常であるかを定義します。異常検出は個々のイベント シグネチャを超えて拡張され、定期的な再トレーニングによって進化する可能性があります。異常または異常として分類されたトラフィックには、優先順位を付けて緊急性を持って対処できます。 Amazon SageMaker は、ビジネスアナリスト向けのノーコード製品を含む、フルマネージド型のインフラストラクチャ、ツール、ワークフローを使用して、顧客がデータを準備し、あらゆるユースケースに合わせて ML モデルを構築、トレーニング、デプロイできるようにするフルマネージド型のサービスです。 SageMaker は、XNUMX つの組み込み異常検出アルゴリズムをサポートしています。 IPの洞察 および ランダムカットフォレスト。 SageMaker を使用して、独自のカスタム外れ値検出モデルを作成することもできます。 アルゴリズム 複数の ML フレームワークをソースとしています。
この投稿では、Amazon Security Lake からソースされたデータを準備し、SageMaker の IP Insights アルゴリズムを使用して ML モデルをトレーニングしてデプロイする方法を学びます。このモデルは、異常なネットワーク トラフィックや動作を特定し、より大規模なエンドツーエンドのセキュリティ ソリューションの一部として構成できます。このようなソリューションでは、ユーザーが通常とは異なるサーバーから、または通常とは異なる時間にサインインしているかどうかの多要素認証 (MFA) チェックを呼び出し、新しい IP アドレスからの不審なネットワーク スキャンがある場合はスタッフに通知し、通常とは異なるネットワークの場合は管理者に警告することができます。プロトコルまたはポートが使用されるか、IP インサイトの分類結果を次のような他のデータ ソースで強化します。 アマゾンガードデューティ 脅威の検出結果をランク付けするための IP レピュテーション スコア。
ソリューションの概要
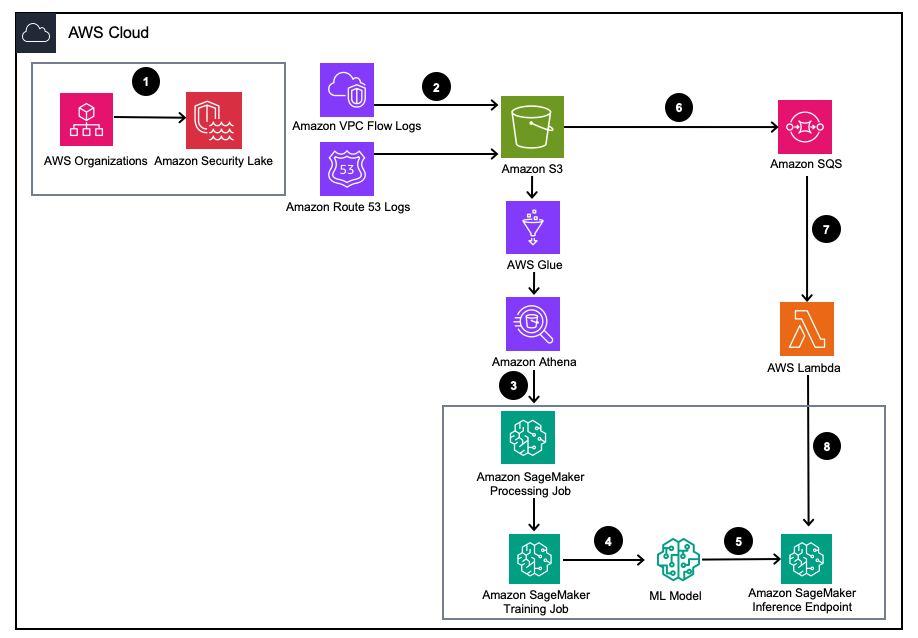
図 1 – ソリューション アーキテクチャ
- Amazon Security Lake を有効にする AWS組織 AWS アカウント、AWS リージョン、外部 IT 環境用。
- Security Lake ソースをセットアップする Amazon Virtual Private Cloud(Amazon VPC) フローログと アマゾンルート53 DNS ログは Amazon Security Lake S3 バケットに記録されます。
- SageMaker 処理ジョブを使用して Amazon Security Lake ログデータを処理し、機能を設計します。使用 アマゾンアテナ 構造化された OCSF ログ データをクエリする Amazon Simple Storage Service(Amazon S3) AWSグルー テーブルは AWS LakeFormation によって管理されます。
- 処理された Amazon Security Lake ログを使用する SageMaker Training ジョブを使用して、SageMaker ML モデルをトレーニングします。
- トレーニングされた ML モデルを SageMaker 推論エンドポイントにデプロイします。
- 新しいセキュリティ ログを S3 バケットに保存し、イベントをキューに保存します。 Amazon Simple Queue Service(Amazon SQS).
- 購読する AWSラムダ SQS キューへの関数。
- Lambda 関数を使用して SageMaker 推論エンドポイントを呼び出し、セキュリティ ログを異常としてリアルタイムで分類します。
前提条件
ソリューションを展開するには、まず次の前提条件を満たしている必要があります。
- Amazon Security Lake を有効にする 組織内、または VPC フロー ログと Route 53 リゾルバー ログの両方が有効になっている単一アカウント。
- その AWS Identity and Access Management(IAM) SageMaker の処理ジョブとノートブックによって使用されるロールには、以下を含む IAM ポリシーが付与されています。 Amazon Security Lake サブスクライバーのアクセス許可のクエリ AWS Lake Formation によって管理されるマネージド Amazon Security Lake データベースとテーブル用。この処理ジョブは、準拠を維持するために、分析またはセキュリティ ツール アカウント内から実行する必要があります。 AWS セキュリティリファレンスアーキテクチャ (AWS SRA).
- Lambda 関数で使用される IAM ロールに、以下を含む IAM ポリシーが付与されていることを確認します。 Amazon Security Lake サブスクライバーのデータアクセス許可.
ソリューションを展開する
環境をセットアップするには、次の手順を実行します。
- 起動する SageMaker スタジオ または SageMaker Jupyter ノートブック
ml.m5.largeインスタンス。 注: インスタンスのサイズは、使用するデータセットによって異なります。 - GitHub のクローンを作成する 倉庫.
- ノートブックを開く
01_ipinsights/01-01.amazon-securitylake-sagemaker-ipinsights.ipy. - 実装する 提供された IAM ポリシー および 対応する IAM 信頼ポリシー SageMaker Studio Notebook インスタンスが S3、Lake Formation、Athena 内のすべての必要なデータにアクセスできるようにします。
このブログでは、環境にデプロイされた後のノートブック内のコードの関連部分について説明します。
依存関係をインストールし、必要なライブラリをインポートする
次のコードを使用して、依存関係をインストールし、必要なライブラリをインポートし、データ処理とモデルのトレーニングに必要な SageMaker S3 バケットを作成します。必要なライブラリの XNUMX つ、 awswrangler、 パンダデータフレーム用の AWS SDK これは、AWS Glue データカタログ内の関連テーブルをクエリし、結果をデータフレームにローカルに保存するために使用されます。
Amazon Security Lake VPC フロー ログ テーブルをクエリする
コードのこの部分では、AWS SDK for pandas を使用して、VPC フロー ログに関連する AWS Glue テーブルにクエリを実行します。前提条件で述べたように、Amazon Security Lake テーブルは次によって管理されます。 AWSレイクフォーメーションしたがって、SageMaker ノートブックで使用されるロールにはすべての適切な権限を付与する必要があります。このクエリは、複数日間の VPC フロー ログ トラフィックを取得します。このブログの開発中に使用されたデータセットは小規模でした。ユースケースの規模に応じて、AWS SDK for pandas の制限に注意する必要があります。テラバイト規模を検討する場合は、AWS SDK for pandas のサポートを考慮する必要があります。 モディン.
データ フレームを表示すると、共通フィールドを含む単一列の出力が表示されます。 ネットワークアクティビティ (4001) OCSFのクラス。
Amazon Security Lake VPC フロー ログ データを IP Insights に必要なトレーニング形式に正規化します。
IP Insights アルゴリズムでは、トレーニング データが CSV 形式であり、4 つの列が含まれている必要があります。最初の列は、エンティティの一意の識別子に対応する不透明な文字列である必要があります。 2 番目の列は、エンティティのアクセス イベントの IPvXNUMX アドレスを XNUMX 進ドット表記で表す必要があります。このブログのサンプル データセットでは、一意の識別子は、 instance_id 内の値 dataframe。 IPv4 アドレスは次から導出されます。 src_endpoint。 Amazon Athena クエリの作成方法に基づいて、インポートされたデータは IP Insights モデルをトレーニングするための正しい形式になっているため、追加の機能エンジニアリングは必要ありません。別の方法でクエリを変更する場合は、追加の特徴エンジニアリングを組み込む必要がある場合があります。
Amazon Security Lake Route 53 リゾルバー ログ テーブルのクエリと正規化
上記と同様に、ノートブックの次のステップでは、Amazon Security Lake Route 53 リゾルバー テーブルに対して同様のクエリを実行します。このノートブック内ではすべての OCSF 準拠のデータを使用するため、Route 53 リゾルバー ログでも機能エンジニアリング タスクは VPC フロー ログの場合と同じままになります。次に、XNUMX つのデータ フレームをトレーニングに使用する XNUMX つのデータ フレームに結合します。 Amazon Athena クエリはデータを正しい形式でローカルにロードするため、それ以上の特徴エンジニアリングは必要ありません。
IP Insights トレーニング イメージを取得し、OCSF データを使用してモデルをトレーニングします。
ノートブックの次の部分では、IP Insights アルゴリズムに基づいて ML モデルをトレーニングし、統合された dataframe さまざまな種類のログからの OCSF の情報。 IP Insights のハイパーパラメータのリストは次のとおりです。 こちら。以下の例では、最高のパフォーマンスのモデルを出力するハイパーパラメーターを選択しました (たとえば、epoch には 5、vector_dim には 128)。私たちのサンプルのトレーニング データセットは比較的小さかったので、 ml.m5.large 実例。ハイパーパラメータと、インスタンス数やインスタンス タイプなどのトレーニング構成は、目的のメトリクスとトレーニング データ サイズに基づいて選択する必要があります。 Amazon SageMaker 内でモデルの最適なバージョンを見つけるために利用できる機能の XNUMX つは、Amazon SageMaker です。 自動モデルチューニング ハイパーパラメータ値の範囲全体で最適なモデルを検索します。
トレーニングされたモデルをデプロイし、有効なトラフィックと異常なトラフィックでテストします。
モデルのトレーニングが完了したら、モデルを SageMaker エンドポイントにデプロイし、一連の一意の識別子と IPv4 アドレスの組み合わせを送信してモデルをテストします。コードのこの部分は、S3 バケットにテスト データが保存されていることを前提としています。テスト データは .csv ファイルで、最初の列はインスタンス ID、XNUMX 番目の列は IP です。有効なデータと無効なデータをテストしてモデルの結果を確認することをお勧めします。次のコードはエンドポイントをデプロイします。
エンドポイントがデプロイされたので、推論リクエストを送信して、トラフィックが異常である可能性があるかどうかを特定できるようになりました。以下は、フォーマットされたデータがどのようになるかのサンプルです。この場合、次に示すように、最初の列の識別子はインスタンス ID で、XNUMX 番目の列は関連付けられた IP アドレスです。
データを CSV 形式で取得したら、S3 バケットから .csv ファイルを読み取ることで、コードを使用して推論のためにデータを送信できます。
IP Insights モデルの出力は、IP アドレスとオンライン リソースが統計的にどの程度期待されるかを示す尺度を提供します。ただし、このアドレスとリソースの範囲には制限がないため、インスタンス ID と IP アドレスの組み合わせが異常であると見なすべきかどうかを判断する方法について考慮する必要があります。
前の例では、XNUMX つの異なる識別子と IP の組み合わせがモデルに送信されました。最初の XNUMX つの組み合わせは、トレーニング セットに基づいて予期される有効なインスタンス ID と IP アドレスの組み合わせでした。 XNUMX 番目の組み合わせには、正しい一意の識別子がありますが、同じサブネット内の IP アドレスが異なります。埋め込みがトレーニング データとわずかに異なるため、モデルは軽度の異常があると判断する必要があります。 XNUMX 番目の組み合わせには有効な一意の識別子がありますが、環境内の VPC 内に存在しないサブネットの IP アドレスが含まれています。
注: 正常および異常なトラフィック データは、特定のユースケースに基づいて変化します。たとえば、外部トラフィックと内部トラフィックを監視する場合は、各 IP アドレスに対応する一意の識別子と、外部識別子を生成するスキームが必要になります。
トラフィックが異常であるかどうかを判断するためのしきい値を決定するには、既知の正常なトラフィックと異常なトラフィックを使用して行うことができます。で説明されている手順は、 このサンプルノート 以下の通り:
- 通常のトラフィックを表すテスト セットを構築します。
- 異常なトラフィックをデータセットに追加します。
- の分布をプロットする
dot_product通常のトラフィックと異常なトラフィックに関するモデルのスコア。 - 正常なサブセットと異常なサブセットを区別するしきい値を選択します。この値は、誤検知の許容範囲に基づいています。
新しい VPC フロー ログ トラフィックの継続的な監視を設定します。
この新しい ML モデルを Amazon Security Lake でプロアクティブな方法でどのように使用できるかを示すために、各モデルで呼び出される Lambda 関数を設定します。 PutObject Amazon Security Lake で管理されるバケット内のイベント、特に VPC フロー ログ データ。 Amazon Security Lake 内には、Amazon Security Lake からのログとイベントを消費するサブスクライバーの概念があります。新しいイベントに応答する Lambda 関数には、データ アクセス サブスクリプションが付与されている必要があります。オブジェクトが Security Lake バケットに書き込まれると、データ アクセス サブスクライバーには、ソースの新しい Amazon S3 オブジェクトが通知されます。サブスクライバーは、S3 オブジェクトに直接アクセスし、サブスクリプションエンドポイントを通じて、または Amazon SQS キューをポーリングすることによって、新しいオブジェクトの通知を受け取ることができます。
- Video Cloud Studioで Security Lake コンソール.
- ナビゲーションペインで、 登録者.
- [購読者] ページで、選択します 購読者の作成.
- 購読者の詳細については、次のように入力します。
inferencelambdafor 加入者名 とオプション Description. - 地域 は、現在選択されている AWS リージョンとして自動的に設定され、変更することはできません。
- ログとイベントのソース、選択する 特定のログおよびイベント ソース 選択して VPC フロー ログと Route 53 ログ
- データアクセス方法、選択する S3.
- 加入者の資格情報、Lambda 関数が存在するアカウントの AWS アカウント ID とユーザー指定の 外部ID.
注: これをアカウント内でローカルに行う場合は、外部 ID は必要ありません。 - 選択する 創造する.
Lambda関数を作成する
Lambda 関数を作成してデプロイするには、次の手順を実行するか、事前に構築された SAM テンプレートをデプロイします。 01_ipinsights/01.02-ipcheck.yaml GitHub リポジトリ内。 SAM テンプレートでは、SQS ARN と SageMaker エンドポイント名を指定する必要があります。
- Lambdaコンソールで、 関数を作成する.
- 選択する 最初から作成者.
- 関数名、 入る
ipcheck. - ランタイム、選択する Pythonの3.10.
- アーキテクチャ選択 x86_64.
- 実行の役割選択 Lambda アクセス許可を持つ新しいロールを作成する.
- 関数を作成したら、関数の内容を入力します。 ipcheck.py GitHub リポジトリからのファイル。
- ナビゲーションペインで、 環境変数.
- 選択する 編集.
- 選択する 環境変数を追加.
- 新しい環境変数として次のように入力します。
ENDPOINT_NAME値には、SageMaker エンドポイントのデプロイ中に出力されたエンドポイント ARN を入力します。 - 選択 Save.
- 選択する 配備します.
- ナビゲーションペインで、 .
- 選択 トリガ.
- 選択 トリガーを追加.
- ソースを選択、選択する SQS.
- SQSキュー、Security Lakeによって作成されたメインSQSキューのARNを入力します。
- のチェックボックスを選択します トリガーをアクティブにする.
- 選択 Add.
Lambda の結果を検証する
- Video Cloud Studioで Amazon CloudWatch コンソール.
- 左側のペインで、 ロググループ.
- 検索バーに「ipcheck」と入力し、次の名前のログ グループを選択します。
/aws/lambda/ipcheck. - 以下の最新のログ ストリームを選択します。 ログストリーム.
- ログ内には、新しい Amazon Security Lake ログごとに次のような結果が表示されます。
{'predictions': [{'dot_product': 0.018832731992006302}, {'dot_product': 0.018832731992006302}]}
この Lambda 関数は、Amazon Security Lake によって取り込まれているネットワーク トラフィックを継続的に分析します。これにより、環境内の異常なトラフィックを示す、指定されたしきい値に違反したときにセキュリティ チームに通知するメカニズムを構築できます。
掃除
このソリューションの実験が終了したら、アカウントへの請求を避けるために、S3 バケット、SageMaker エンドポイントを削除し、SageMaker Jupyter ノートブックに接続されているコンピューティングをシャットダウンし、Lambda 関数を削除し、Amazon Security を無効にしてリソースをクリーンアップします。あなたのアカウントに湖があります。
まとめ
この投稿では、Amazon Security Lake から取得したネットワーク トラフィック データを機械学習用に準備する方法を学び、Amazon SageMaker の IP Insights アルゴリズムを使用して ML モデルをトレーニングしてデプロイしました。 Jupyter ノートブックで説明されているすべての手順は、エンドツーエンドの ML パイプラインで複製できます。また、新しい Amazon Security Lake ログを消費し、トレーニングされた異常検出モデルに基づいて推論を送信する AWS Lambda 関数も実装しました。 AWS Lambda が受信した ML モデルの応答は、特定のしきい値が満たされたときに、異常なトラフィックをセキュリティ チームに事前に通知できます。モデルの継続的な改善は、異常として識別されたトラフィックが誤検知であったかどうかをラベル付けするループ レビューにセキュリティ チームを含めることによって可能になります。これをトレーニング セットに追加したり、 通常の 経験的なしきい値を決定するときに交通データセットを使用します。このモデルは、異常な可能性のあるネットワーク トラフィックや動作を識別できるため、大規模なセキュリティ ソリューションの一部として組み込むことができ、ユーザーが異常なサーバーからサインインしている場合や異常な時間にサインインしている場合に MFA チェックを開始し、疑わしいものがあればスタッフに警告します。新しい IP アドレスからのネットワーク スキャン、または IP インサイト スコアを Amazon Guard Duty などの他のソースと組み合わせて、脅威の検出結果をランク付けします。このモデルには、Amazon Security Lake のデプロイにカスタム ソースを追加することで、Azure Flow Logs やオンプレミス ログなどのカスタム ログ ソースを含めることができます。
このブログ投稿シリーズのパート 2 では、 ランダムカットフォレスト ネットワークとホストのセキュリティログデータを統合し、自動化された包括的なセキュリティ監視ソリューションの一部としてセキュリティ異常分類を適用する追加の Amazon Security Lake ソースを使用してトレーニングされたアルゴリズム。
著者について
 ジョー・モロッティ アマゾン ウェブ サービス (AWS) のソリューション アーキテクトであり、米国中西部のエンタープライズ顧客を支援しています。 彼は幅広い技術的役割を果たし、顧客の可能性の芸術を示すことを楽しんでいます。 余暇には、家族と一緒に新しい場所を探索したり、スポーツ チームのパフォーマンスを分析したりして充実した時間を過ごしています。
ジョー・モロッティ アマゾン ウェブ サービス (AWS) のソリューション アーキテクトであり、米国中西部のエンタープライズ顧客を支援しています。 彼は幅広い技術的役割を果たし、顧客の可能性の芸術を示すことを楽しんでいます。 余暇には、家族と一緒に新しい場所を探索したり、スポーツ チームのパフォーマンスを分析したりして充実した時間を過ごしています。
 ビシュル・タバア アマゾン ウェブ サービスのソリューション アーキテクトです。 Bishr は、機械学習、セキュリティ、可観測性アプリケーションで顧客を支援することを専門としています。 仕事以外では、テニスをしたり、料理をしたり、家族と時間を過ごすことを楽しんでいます。
ビシュル・タバア アマゾン ウェブ サービスのソリューション アーキテクトです。 Bishr は、機械学習、セキュリティ、可観測性アプリケーションで顧客を支援することを専門としています。 仕事以外では、テニスをしたり、料理をしたり、家族と時間を過ごすことを楽しんでいます。
 スリハーシュアダリ アマゾン ウェブ サービス (AWS) のシニア ソリューション アーキテクトであり、顧客がビジネスの成果からさかのぼって AWS で革新的なソリューションを開発するのを支援しています。 長年にわたり、彼はさまざまな業界のデータ プラットフォームの変革に関して複数の顧客を支援してきました。 彼の主な専門分野には、テクノロジー戦略、データ分析、およびデータ サイエンスが含まれます。 余暇には、テニスをしたり、テレビ番組をどんちゃん騒ぎしたり、タブラを楽しんだりしています。
スリハーシュアダリ アマゾン ウェブ サービス (AWS) のシニア ソリューション アーキテクトであり、顧客がビジネスの成果からさかのぼって AWS で革新的なソリューションを開発するのを支援しています。 長年にわたり、彼はさまざまな業界のデータ プラットフォームの変革に関して複数の顧客を支援してきました。 彼の主な専門分野には、テクノロジー戦略、データ分析、およびデータ サイエンスが含まれます。 余暇には、テニスをしたり、テレビ番組をどんちゃん騒ぎしたり、タブラを楽しんだりしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/identify-cybersecurity-anomalies-in-your-amazon-security-lake-data-using-amazon-sagemaker/

