2022の終わりに向かって、 AWS はリアルタイム ストリーミング インジェストの一般提供を発表しました 〜へ Amazonレッドシフト for Amazon Kinesisデータストリーム & Apache KafkaのAmazonマネージドストリーミング(Amazon MSK)ストリーミング データをステージングする必要がなくなります。 Amazon Simple Storage Service(Amazon S3) Amazon Redshift に取り込む前に。
ストリーミング取り込み Amazon MSK から Amazon Redshift への移行は、リアルタイムのデータ処理と分析に対する最先端のアプローチを表します。 Amazon MSK は、Apache Kafka 用の拡張性の高いフルマネージド サービスとして機能し、膨大なデータ ストリームのシームレスな収集と処理を可能にします。ストリーミング データを Amazon Redshift に統合すると、組織がリアルタイム分析とデータ主導の意思決定の可能性を活用できるようになり、計り知れない価値がもたらされます。
この統合により、秒単位で測定される低レイテンシを実現しながら、3 秒あたり数百メガバイトのストリーミング データを Amazon Redshift に取り込むことができます。同時に、この統合により、最新の情報を分析にすぐに利用できるようになります。統合では Amazon SXNUMX にデータをステージングする必要がないため、Amazon Redshift はより低いレイテンシーで、中間のストレージコストなしでストリーミング データを取り込むことができます。
SQL ステートメントを使用して Redshift クラスター上で Amazon Redshift ストリーミング インジェストを設定し、MSK トピックを認証して接続できます。このソリューションは、データ パイプラインを簡素化し、運用コストを削減したいと考えているデータ エンジニアにとって優れたオプションです。
この投稿では、設定方法の完全な概要を提供します。 Amazon Redshift ストリーミング インジェスト アマゾンMSKから。
ソリューションの概要
次のアーキテクチャ図は、使用する AWS のサービスと機能を説明しています。

ワークフローには次の手順が含まれます。
- まず、 アマゾンMSKコネクト ソース コネクタを使用して、MSK トピックを作成し、モック データを生成して、それを MSK トピックに書き込みます。この投稿では、模擬顧客データを使用します。
- 次のステップでは、 クエリエディタv2.
- 最後に、外部スキーマを設定し、Amazon Redshift でマテリアライズド ビューを作成して、MSK トピックからのデータを使用します。このソリューションは、Amazon MSK から Amazon Redshift にデータをエクスポートするために MSK Connect シンクコネクタに依存しません。
次のソリューション アーキテクチャ図では、使用する AWS サービスの構成と統合について詳しく説明します。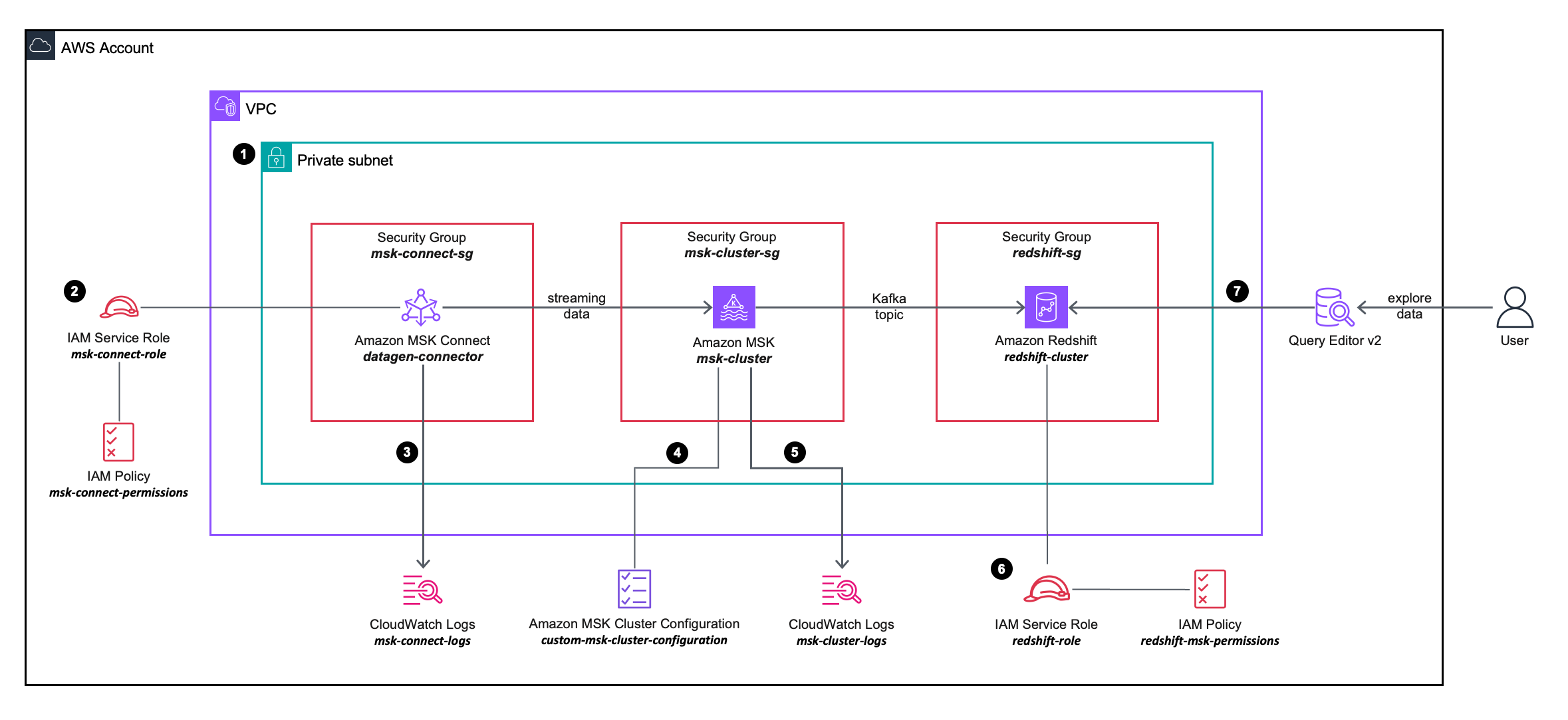
ワークフローには次の手順が含まれます。
- VPC 上のプライベート サブネット内に MSK Connect ソース コネクタ、MSK クラスター、および Redshift クラスターをデプロイします。
- MSK Connect ソース コネクタは、 AWS Identity and Access Management(IAM) インラインポリシー に付属 IAMの役割これにより、ソース コネクタが MSK クラスター上でアクションを実行できるようになります。
- MSK Connect ソース コネクタのログがキャプチャされ、 アマゾンクラウドウォッチ ロググループ.
- MSK クラスターは カスタム MSK クラスター構成これにより、MSK Connect コネクタが MSK クラスター上にトピックを作成できるようになります。
- MSK クラスターのログがキャプチャされ、Amazon CloudWatch ログ グループに送信されます。
- Redshift クラスターは、IAM ロールにアタッチされた IAM インライン ポリシーで定義された詳細な権限を使用します。これにより、Redshift クラスターは MSK クラスター上でアクションを実行できます。
- Query Editor v2 を使用して Redshift クラスターに接続できます。
前提条件
前提条件リソースのプロビジョニングと構成を簡素化するには、次を使用できます。 AWS CloudFormation テンプレート:
![]()
スタックを起動するときは、次の手順を実行します。
- スタック名、スタックの意味のある名前を入力します。たとえば、
prerequisites. - 選択する 次へ。
- 選択する 次へ。
- 選択 AWS CloudFormationがカスタム名でIAMリソースを作成する可能性があることを認めます。
- 選択する 送信します。
CloudFormation スタックは、次のリソースを作成します。
- VPC
custom-vpc、3 つのアベイラビリティーゾーンにわたって作成され、3 つの パブリックサブネット 3つ プライベートサブネット:- パブリック サブネットはパブリック ルート テーブルに関連付けられ、送信トラフィックはインターネット ゲートウェイに送信されます。
- プライベート サブネットはプライベート ルート テーブルに関連付けられ、送信トラフィックは NAT ゲートウェイに送信されます。
- An インターネットゲートウェイ Amazon VPC に接続されています。
- A NATゲートウェイ に関連付けられている エラスティックIP また、パブリック サブネットの 1 つにデプロイされます。
- スリー セキュリティグループ:
msk-connect-sg、これは後で MSK Connect コネクタに関連付けられます。redshift-sg、これは後で Redshift クラスターに関連付けられます。msk-cluster-sg、これは後で MSK クラスターに関連付けられます。からの受信トラフィックを許可します。msk-connect-sg,redshift-sg.
- 2 つの CloudWatch ログ グループ:
msk-connect-logs、MSK Connect ログに使用されます。msk-cluster-logs、MSK クラスター ログに使用されます。
- 2 つの IAM ロール:
msk-connect-roleこれには、MSK Connect の詳細な IAM 権限が含まれます。redshift-roleこれには、Amazon Redshift に対する詳細な IAM 権限が含まれます。
- A カスタム MSK クラスター構成これにより、MSK Connect コネクタが MSK クラスター上にトピックを作成できるようになります。
- MSK クラスター。 3 つのプライベート サブネット全体に 3 つのブローカーがデプロイされています。
custom-vpc.msk-cluster-sgセキュリティグループとcustom-msk-cluster-configuration構成は MSK クラスターに適用されます。ブローカーのログは、msk-cluster-logsCloudWatch ログ グループ。 - A Redshiftクラスターのサブネットグループ、 の 3 つのプライベート サブネットを使用しています。
custom-vpc. - Redshift クラスターのサブネット グループ内のプライベート サブネットにデプロイされた 1 つの単一ノードを持つ Redshift クラスター。の
redshift-sgセキュリティグループとredshift-roleIAM ロールは Redshift クラスターに適用されます。
MSK Connect カスタム プラグインを作成する
この投稿では、 Amazon MSK データジェネレーター MSK Connect にデプロイされ、疑似顧客データが生成され、MSK トピックに書き込まれます。
次の手順を完了します。
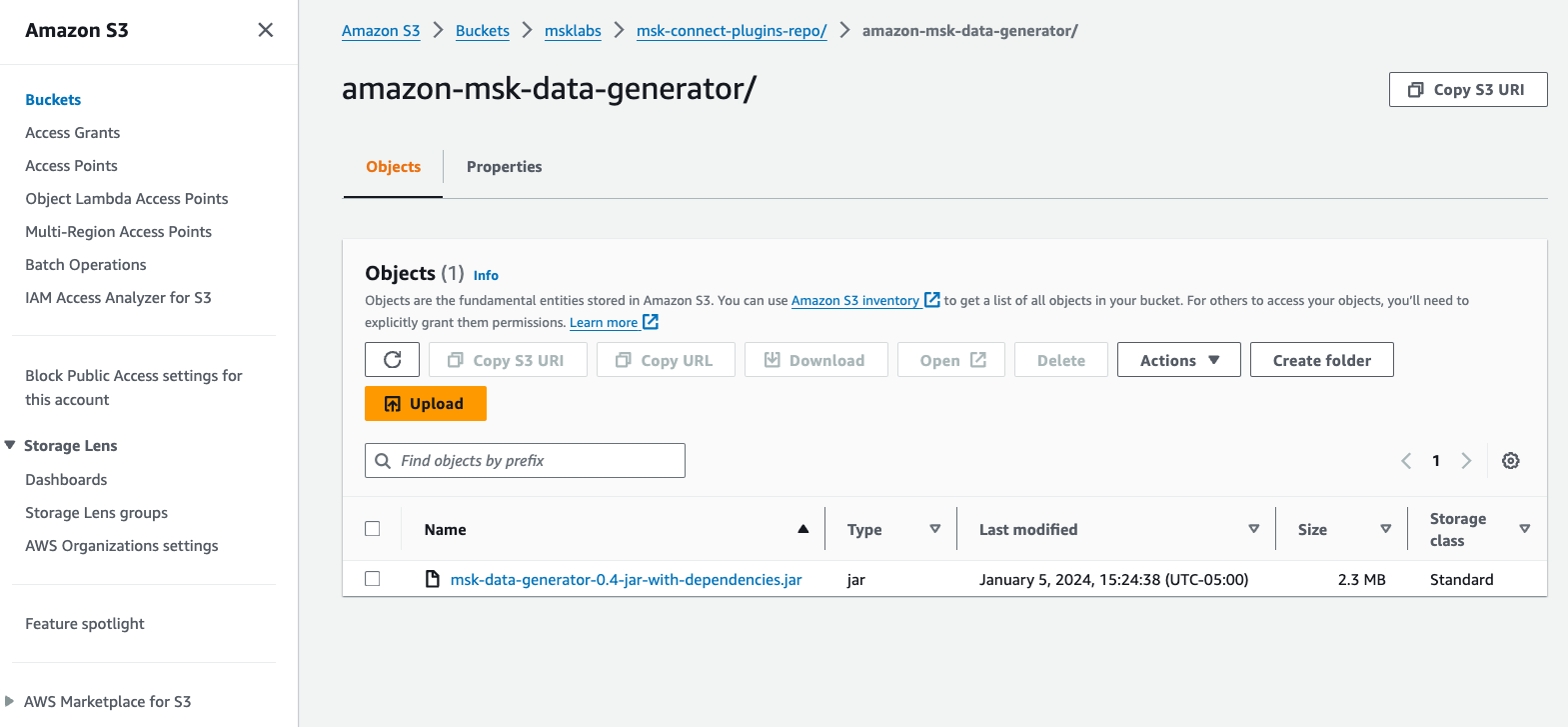
- ダウンロード Amazon MSK データジェネレーター GitHub からの依存関係を含む JAR ファイル。

- JAR ファイルを AWS アカウントの S3 バケットにアップロードします。
- Amazon MSKコンソールで、 カスタムプラグイン 下 MSKコネクト ナビゲーションペインに表示されます。
- 選択する カスタムプラグインを作成します。
- 選択する S3を参照、Amazon S3 にアップロードした Amazon MSK データ ジェネレーター JAR ファイルを検索し、選択します 選択する.
- カスタムプラグイン名、 入る
msk-datagen-plugin. - 選択する カスタムプラグインを作成します。
カスタム プラグインが作成されると、そのステータスが次のようになります。 アクティブをクリックすると、次のステップに進むことができます。
MSK Connect コネクタを作成する
コネクタを作成するには、次の手順を実行します。
- Amazon MSKコンソールで、 コネクタ 下 MSKコネクト ナビゲーションペインに表示されます。
- 選択する コネクタを作成します。
- カスタムプラグインタイプ、選択する 既存のプラグインを使用します。
- 選択
msk-datagen-plugin、を選択します 次へ。 - コネクタ名、 入る
msk-datagen-connector. - クラスタータイプ、選択する 自己管理型の Apache Kafka クラスター。
- VPC、選択する
custom-vpc. - サブネット1、最初のアベイラビリティーゾーン内のプライベートサブネットを選択します。
custom-vpc CloudFormation テンプレートによって作成された場合、パブリック サブネットには奇数の CIDR 範囲を使用し、プライベート サブネットには偶数の CIDR 範囲を使用しています。
-
- パブリック サブネットの CIDR は 10.10.1.0/24、10.10.3.0/24、および 10.10.5.0/24 です。
- プライベート サブネットの CIDR は 10.10.2.0/24、10.10.4.0/24、および 10.10.6.0/24 です。
- サブネット2、2 番目のアベイラビリティーゾーン内のプライベートサブネットを選択します。
- サブネット3、3 番目のアベイラビリティーゾーン内のプライベートサブネットを選択します。
- ブートストラップ サーバー、MSK クラスターの TLS 認証用のブートストラップ サーバーのリストを入力します。
に MSK クラスターのブートストラップ サーバーを取得します、Amazon MSK コンソールに移動し、選択します クラスター、選択する msk-cluster、を選択します クライアント情報を見る。ブートストラップ サーバーの TLS 値をコピーします。
- セキュリティグループ、選択する このクラスターへのアクセス権を持つ特定のセキュリティ グループを使用する、選択して
msk-connect-sg. - コネクタ構成、デフォルト設定を次のように置き換えます。
- コネクタ容量については、選択します プロビジョニング済み。
- ワーカーあたりの MCU 数、選択する 1.
- 労働者の数、選択する 1.
- ワーカー構成、選択する MSK のデフォルト構成を使用する.
- アクセス許可、選択する
msk-connect-role. - 選択する 次へ。
- 暗号化については、選択します TLS 暗号化トラフィック。
- 選択する 次へ。
- ログ配信、選択する Amazon CloudWatch Logs に配信する.
- 選択する ブラウズ選択
msk-connect-logs、選択して 選択する. - 選択する 次へ。
- 確認して選択 コネクタを作成します。
カスタム コネクタが作成されると、そのステータスが次のようになります。 Running:をクリックすると、次のステップに進むことができます。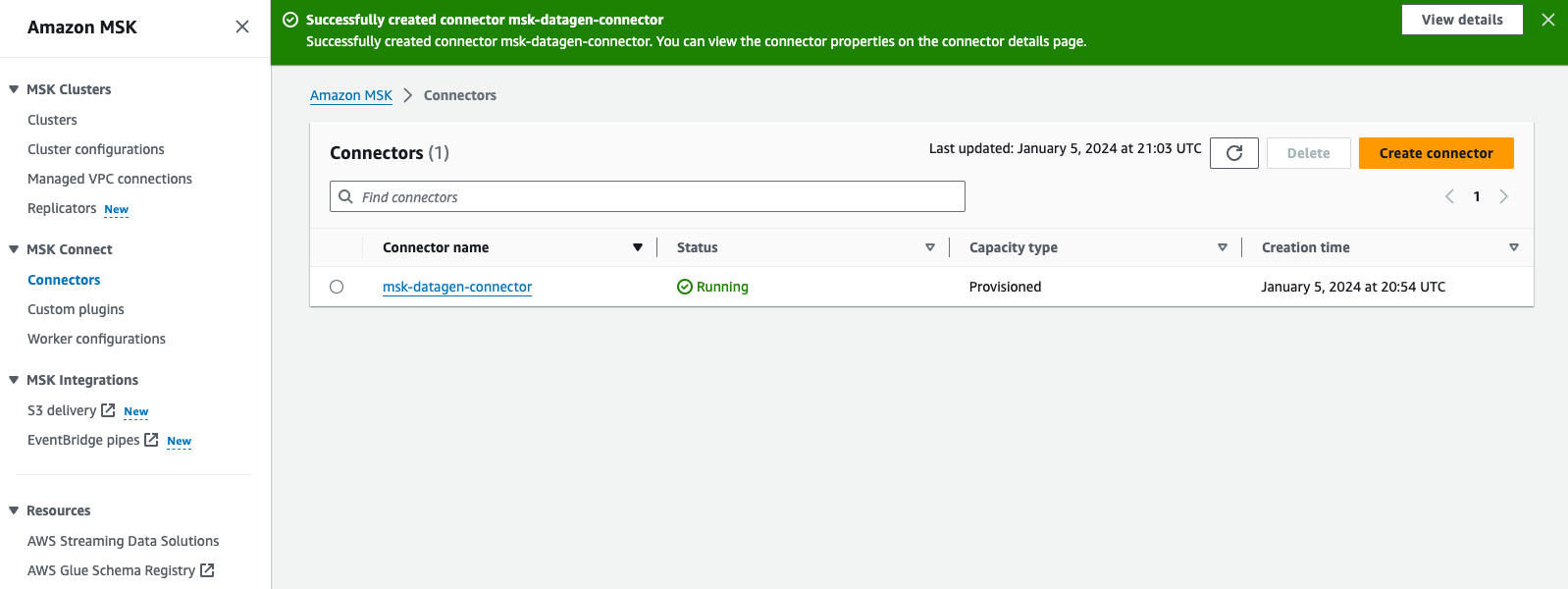
Amazon MSK の Amazon Redshift ストリーミング取り込みを設定する
ストリーミング取り込みを設定するには、次の手順を実行します。
- Query Editor v2 を使用して Redshift クラスターに接続し、データベース ユーザー名で認証します。
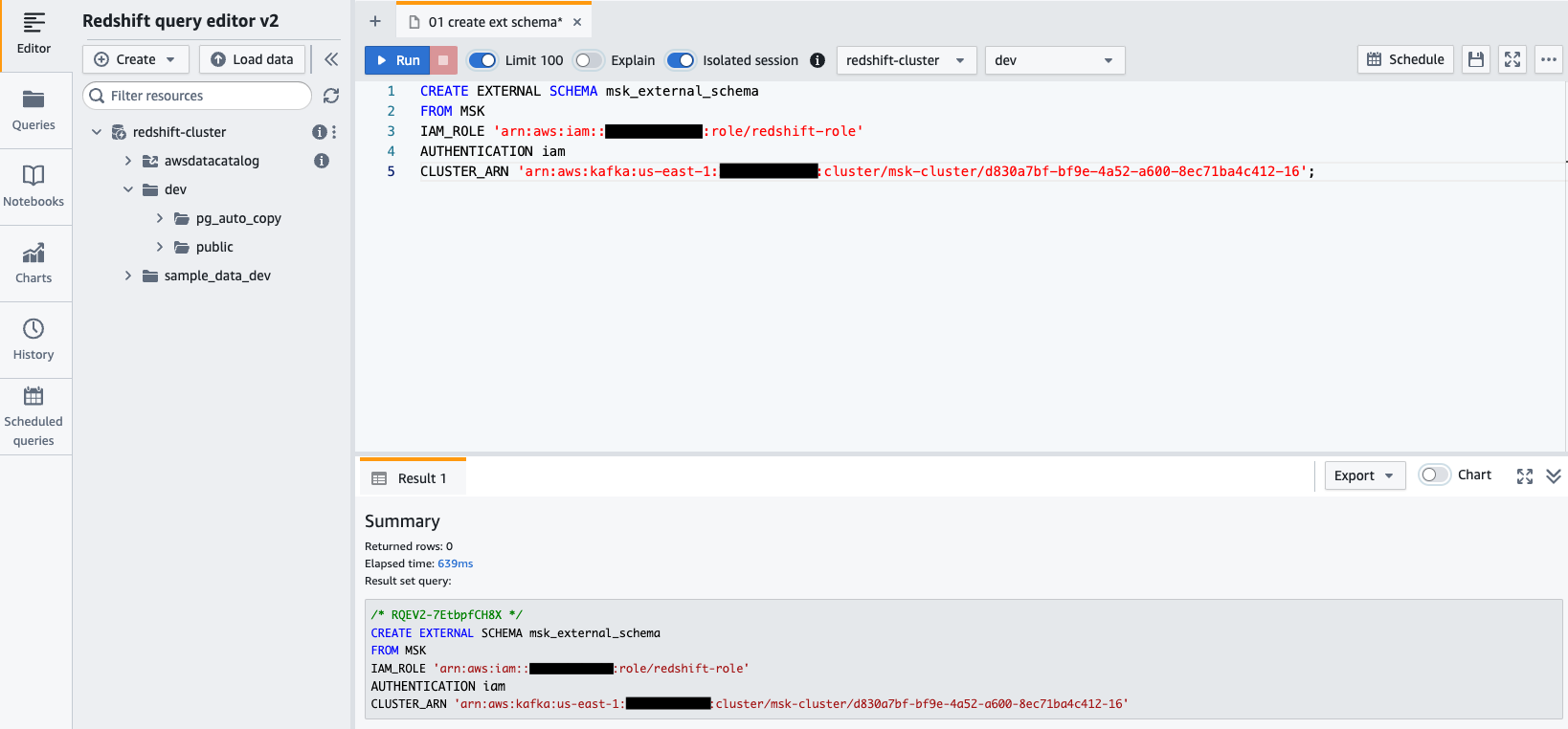
awsuser、パスワードAwsuser123. - 次の SQL ステートメントを使用して、Amazon MSK から外部スキーマを作成します。
次のコードに、 redshift-role IAM の役割と msk-cluster クラスター ARN.
- 選択する ラン SQL ステートメントを実行します。
- 作る マテリアライズドビュー 次の SQL ステートメントを使用します。
- 選択する ラン SQL ステートメントを実行します。
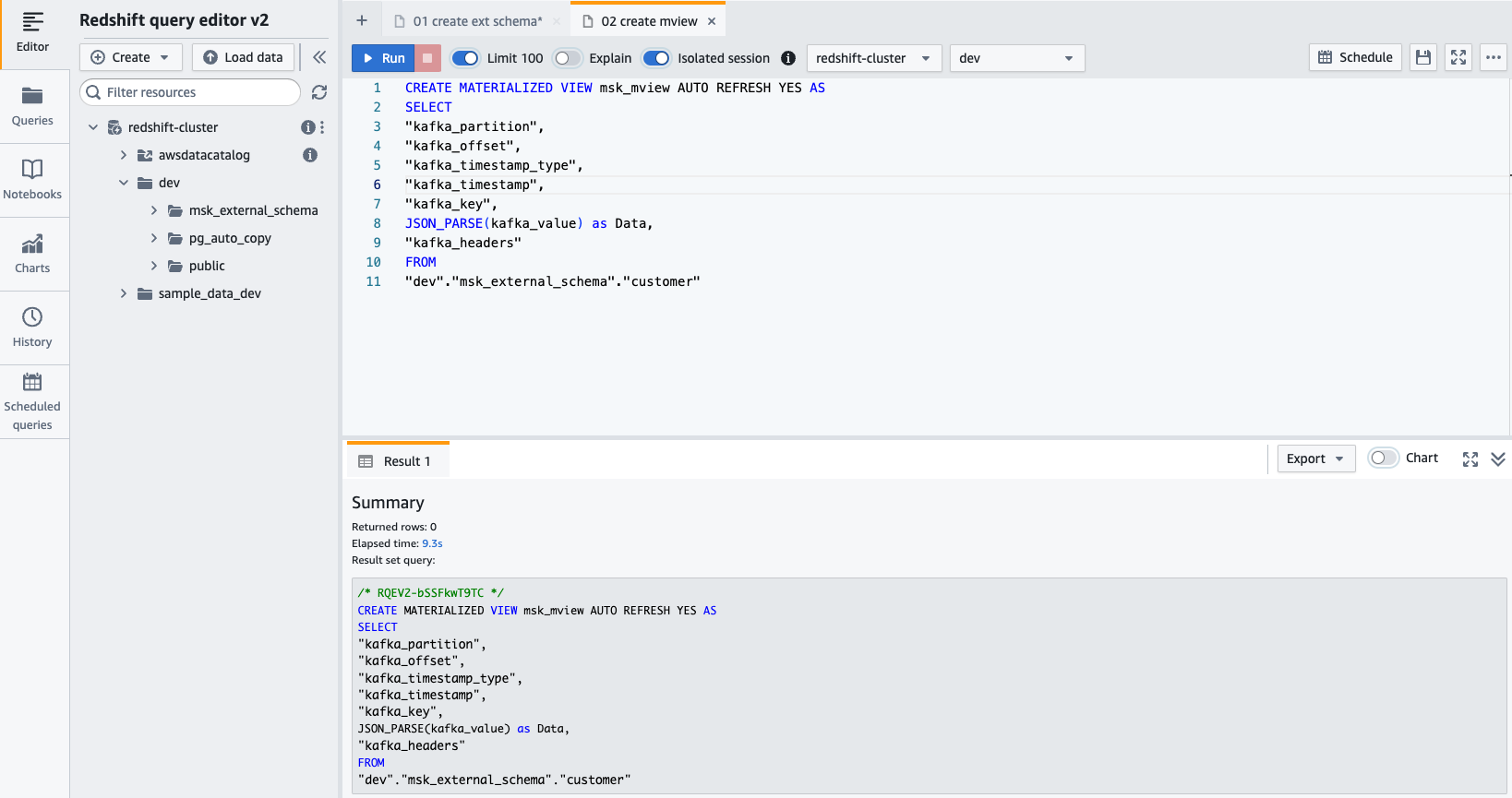
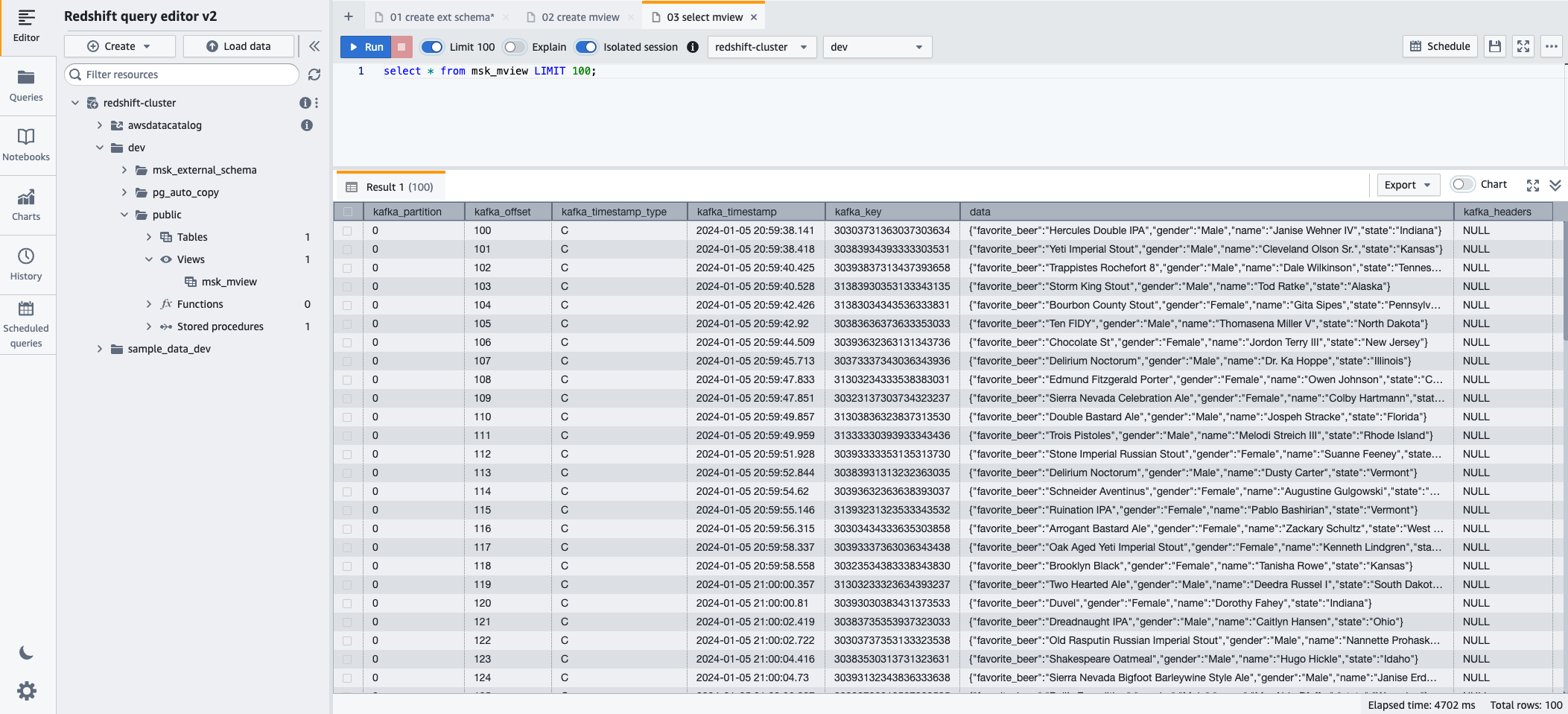
- これで、次の SQL ステートメントを使用してマテリアライズド ビューにクエリを実行できるようになります。
- 選択する ラン SQL ステートメントを実行します。
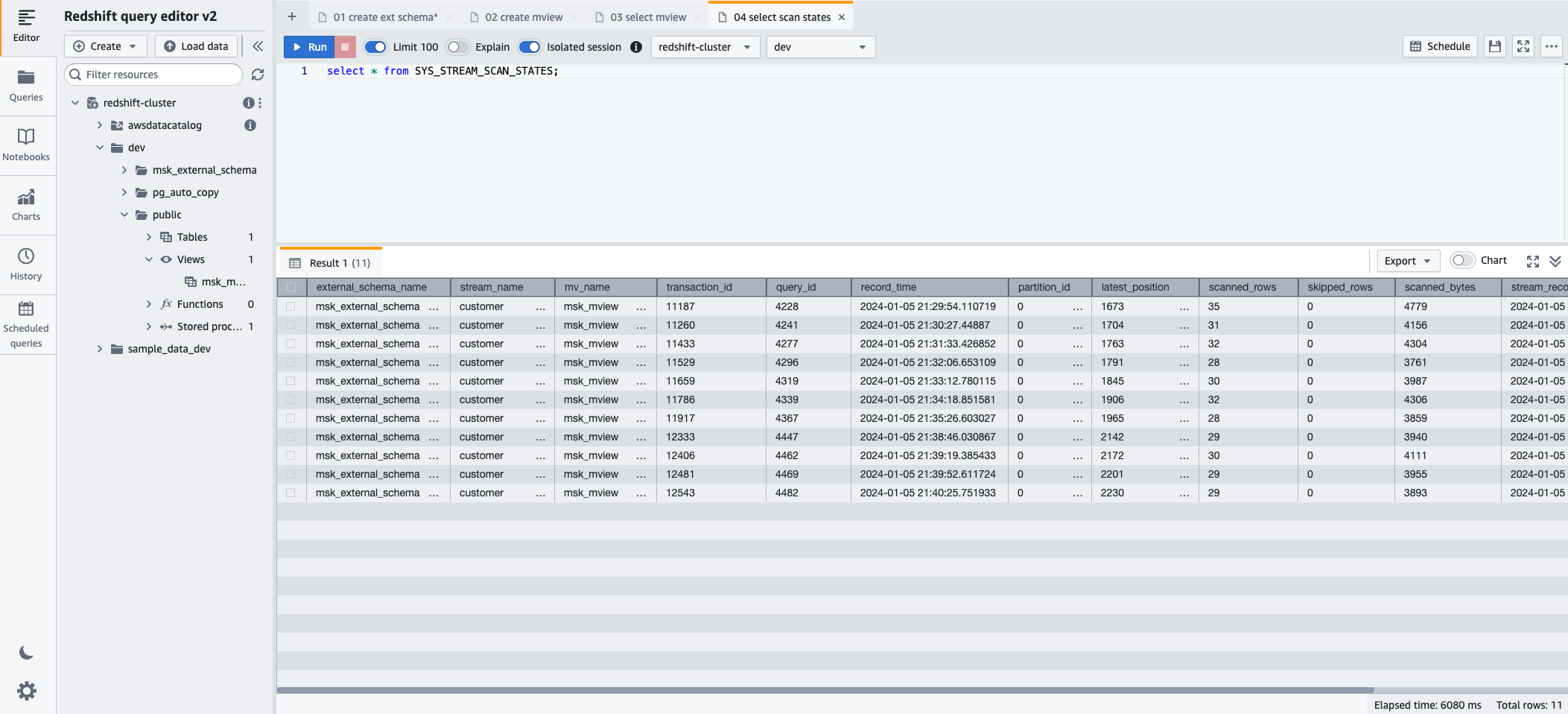
- ストリーミング取り込み経由でロードされたレコードの進行状況を監視するには、 SYS_STREAM_SCAN_STATES 次の SQL ステートメントを使用してビューを監視します。
- 選択する ラン SQL ステートメントを実行します。
- ストリーミング取り込み経由でロードされたレコードで発生したエラーを監視するには、 SYS_STREAM_SCAN_ERRORS 次の SQL ステートメントを使用してビューを監視します。
- 選択する ラン SQL ステートメントを実行します。
クリーンアップ
手順を進めた後、作成したリソースが不要になった場合は、追加料金が発生しないように、次の順序でリソースを削除してください。
- MSK Connectコネクタを削除する
msk-datagen-connector. - MSK Connectプラグインを削除する
msk-datagen-plugin. - ダウンロードした Amazon MSK データ ジェネレーター JAR ファイルを削除し、作成した S3 バケットを削除します。
- MSK Connect コネクタを削除した後、CloudFormation テンプレートを削除できます。 CloudFormation テンプレートによって作成されたすべてのリソースは、AWS アカウントから自動的に削除されます。
まとめ
この投稿では、プライバシーとセキュリティに焦点を当てて、Amazon MSK からの Amazon Redshift ストリーミング取り込みを設定する方法を説明しました。
高スループットのデータストリームを処理する Amazon MSK の機能と Amazon Redshift の堅牢な分析機能を組み合わせることで、ビジネスはすぐに実用的な洞察を得ることができます。このリアルタイムのデータ統合により、変化するデータの傾向、顧客の行動、運用パターンを理解する際の組織の機敏性と応答性が向上します。これにより、情報に基づいたタイムリーな意思決定が可能になり、今日のダイナミックなビジネス環境において競争力を獲得できます。
このソリューションは、次のことを検討しているお客様にも適用できます。 Amazon MSK サーバーレス & AmazonRedshiftサーバーレス.
この投稿が AWS のサービスの統合と構成について詳しく学ぶ良い機会になれば幸いです。コメントセクションでフィードバックをお聞かせください。
著者について
 セバスチャン・ヴラド アマゾン ウェブ サービスのシニア パートナー ソリューション アーキテクトであり、データおよび分析ソリューションと顧客の成功に情熱を持っています。 Sebastian は企業顧客と協力して、ビジネス成果を達成するための最新で安全かつスケーラブルなソリューションの設計と構築を支援します。
セバスチャン・ヴラド アマゾン ウェブ サービスのシニア パートナー ソリューション アーキテクトであり、データおよび分析ソリューションと顧客の成功に情熱を持っています。 Sebastian は企業顧客と協力して、ビジネス成果を達成するための最新で安全かつスケーラブルなソリューションの設計と構築を支援します。
 シャラド・パイ AWS の主任テクニカル コンサルタントです。彼はストリーミング分析を専門としており、お客様が Amazon MSK と Amazon Kinesis を使用してスケーラブルなソリューションを構築するのを支援しています。彼は業界で 16 年以上の経験があり、現在 AWS でライブ ストリーミング プラットフォームをホストしているメディア顧客と協力して、50 万を超えるピーク時の同時実行数を管理しています。 AWS に入社する前、Sharad の主任ソフトウェア開発者としてのキャリアには、JavaScript、Python、PHP などのオープンソース テクノロジーを使用した 9 年間のコーディング業務が含まれていました。
シャラド・パイ AWS の主任テクニカル コンサルタントです。彼はストリーミング分析を専門としており、お客様が Amazon MSK と Amazon Kinesis を使用してスケーラブルなソリューションを構築するのを支援しています。彼は業界で 16 年以上の経験があり、現在 AWS でライブ ストリーミング プラットフォームをホストしているメディア顧客と協力して、50 万を超えるピーク時の同時実行数を管理しています。 AWS に入社する前、Sharad の主任ソフトウェア開発者としてのキャリアには、JavaScript、Python、PHP などのオープンソース テクノロジーを使用した 9 年間のコーディング業務が含まれていました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/simplify-data-streaming-ingestion-for-analytics-using-amazon-msk-and-amazon-redshift/

