モデルの調整は、検証データセットで可能な限り最良の望ましい結果をもたらす、機械学習 (ML) モデルの最適なパラメーターと構成を見つける実験的プロセスです。 パフォーマンス メトリクスを使用した単一目的の最適化は、ML モデルを調整するための最も一般的なアプローチです。 ただし、予測パフォーマンスに加えて、特定のアプリケーションについて考慮する必要がある複数の目的が存在する場合があります。 例えば、
- 公平性 - ここでの目的は、特に人間がアルゴリズムの決定の対象となる場合に、データ内の特定のサブグループ間のモデル結果の偏りを軽減するようモデルを奨励することです。 たとえば、信用貸付アプリケーションは、正確であるだけでなく、さまざまな人口サブグループに偏りがないようにする必要があります。
- 推論時間 – ここでの目的は、モデル呼び出し中の推論時間を短縮することです。 たとえば、音声認識システムは、同じ言語のさまざまな方言を正確に理解するだけでなく、ビジネス プロセスで許容される指定された時間制限内で動作する必要があります。
- エネルギー効率 – ここでの目的は、より小さなエネルギー効率の高いモデルをトレーニングすることです。 たとえば、ニューラル ネットワーク モデルはモバイル デバイスで使用するために圧縮されているため、ネットワークのパスに必要な FLOPS の数を減らすことで、エネルギー消費を自然に削減します。
多目的最適化手法は、目的の指標間のさまざまなトレードオフを表しています。 これには、同時に満たされるさまざまなメトリックに対する一連の制約に従う目的関数のグローバルな最小値を見つけることが含まれます。
Amazon SageMaker 自動モデルチューニング (AMT) アルゴリズムとハイパーパラメータの範囲を使用して、データセットで多くの SageMaker トレーニングジョブを実行することにより、モデルの最適なバージョンを見つけます。 次に、ユーザーが定義したメトリクス (例: 精度、auc、再現率) によって測定されるように、最高のパフォーマンスを発揮するモデルをもたらすハイパーパラメーター値を選択します。 Amazon SageMaker の自動モデル チューニングを使用すると、データセットでトレーニング ジョブを実行することにより、モデルの最適なバージョンを見つけることができます。 いくつかの検索戦略、 ベイジアン、ランダム検索、グリッド検索、ハイパーバンドなど。
Amazon SageMaker の明確化 データの準備中、モデルのトレーニング後、デプロイされたモデルで潜在的なバイアスを検出できます。 現在、21 の異なるメトリックから選択できます。 これらの指標は、 はっきりさせる python パッケージと github リポジトリ こちら. Amazon SageMaker Clarify のメトリクスを使用してバイアスを測定する方法について詳しくは、次の URL をご覧ください。 Amazon SageMaker Clarify がバイアスの検出にどのように役立つかを学ぶ.
このブログでは、Amazon SageMaker AMT を使用して ML モデルを自動的に調整し、単一の組み合わせメトリクスを作成して、精度と公平性の両方の目標を達成する方法を紹介します。 信用リスク予測の金融サービスのユースケースを示します。精度指標は次のとおりです。 曲線下面積 (AUC) パフォーマンスとバイアス指標を測定する 予測されたラベル (DPPL) の正の割合の違い SageMaker Clarify から、さまざまな人口統計グループのモデル予測の不均衡を測定します。 この例のコードは、 GitHubの.
信用リスク予測の公平性
信用貸付業界は、融資申請の処理を信用スコアに大きく依存しています。 一般に、信用スコアは申請者のお金の借り入れと返済の履歴を反映しており、貸し手は個人の信用力を判断する際にそれらを参照します。 決済会社や銀行は、特定のアプリケーションに関連するリスクを特定し、競争力のあるクレジット商品を提供するのに役立つシステムを構築することに関心を持っています。 機械学習 (ML) モデルを使用して、過去の応募者データを処理し、信用リスク プロファイルを予測するシステムを構築できます。 データには、申請者の財務および雇用履歴、人口統計、および新しいクレジット/ローンのコンテキストを含めることができます。 特定の申請者が将来債務不履行になるかどうかを予測するモデルには、統計的な不確実性が常に存在します。 システムは、時間の経過とともにデフォルトになる可能性のあるアプリケーションを拒否することと、最終的に信用できるアプリケーションを受け入れることとの間のトレードオフを提供する必要があります。
このようなシステムのビジネス オーナーは、既存および今後の規制コンプライアンス要件に従って、モデルの有効性と品質を確保する必要があります。 彼らは、顧客を公正に扱い、意思決定において透明性を提供する義務があります。 彼らは、肯定的なモデル予測がさまざまなグループ (たとえば、性別、人種、民族性、移民ステータスなど) 間で不均衡にならないようにしたいと考えるかもしれません。 必要なデータが収集されると、ML モデルのトレーニングは通常、分類精度や AUC スコアなどのメトリックを使用して、予測パフォーマンスを主な目的として最適化します。 あるいは、特定の要件が確実に維持されるように、特定のパフォーマンス目標を持つモデルを公平性メトリックで制約することができます。 モデルを制約するそのような手法の XNUMX つは、公平性を意識したハイパーパラメーター調整です。 これらの戦略を適用することにより、最良の候補モデルは、高い予測性能を維持しながら、制約のないモデルよりも低いバイアスを持つことができます。
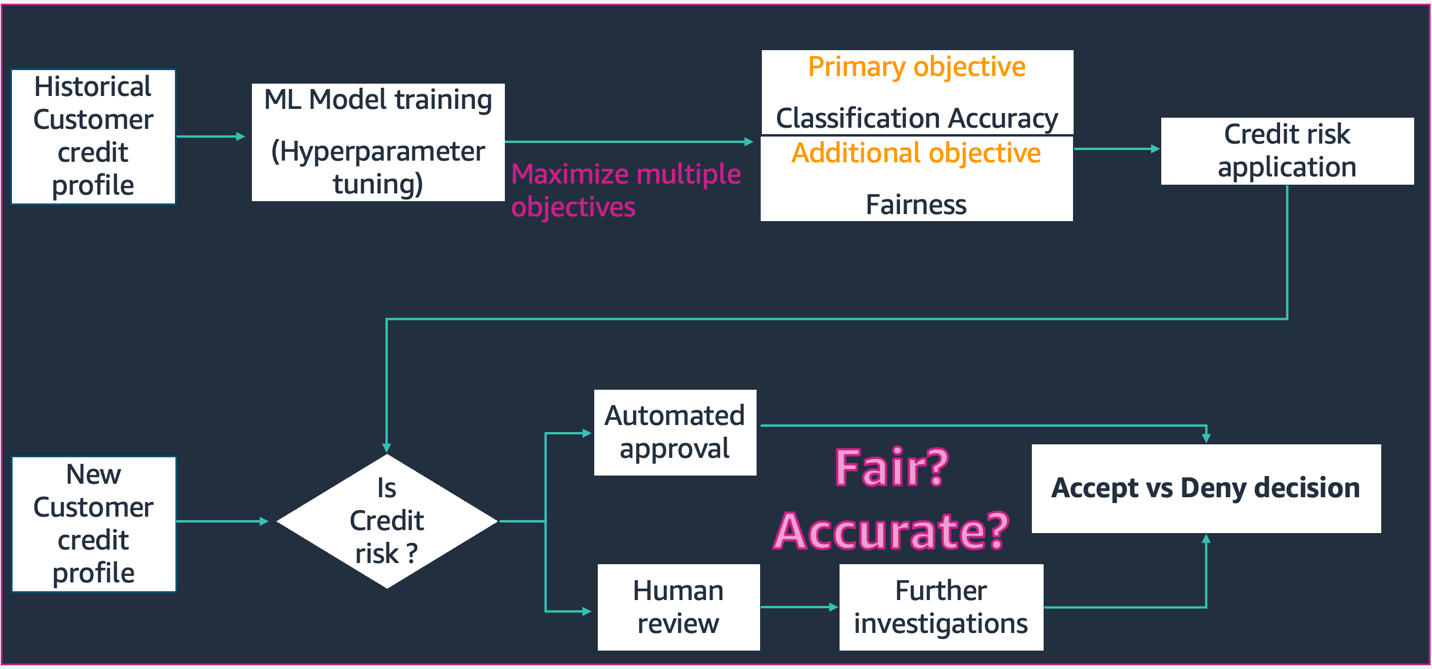
この図に示されているシナリオでは、
- ML モデルは、過去の顧客の信用プロファイル データを使用して構築されます。 モデルのトレーニングとハイパーパラメーターの調整プロセスは、分類の精度と公平性を含む複数の目的を最大化します。 モデルは、実稼働システムの既存のビジネス プロセスにデプロイされます。
- 新しい顧客の信用プロファイルの信用リスクが評価されます。 リスクが低い場合は、自動化されたプロセスを通過できます。 リスクの高いアプリケーションには、最終的な承認または却下の決定の前に人間によるレビューが含まれる場合があります。
設計と開発、展開、および運用中に収集された決定事項と指標は、次の方法で文書化できます。 SageMaker モデルカード 関係者と共有します。
このユースケースでは、SageMaker の自動モデルチューニングを使用して、精度と公平性の両方の客観的メトリクスを組み合わせてハイパーパラメータを微調整することにより、特定のグループに対するモデルの偏りを減らす方法を示します。 南ドイツ信用データセット (南ドイツのクレジット データ セット)。
申請者データは、次のカテゴリに分類できます。
- 人口統計
- 財務データ
- 職歴
- ローンの目的
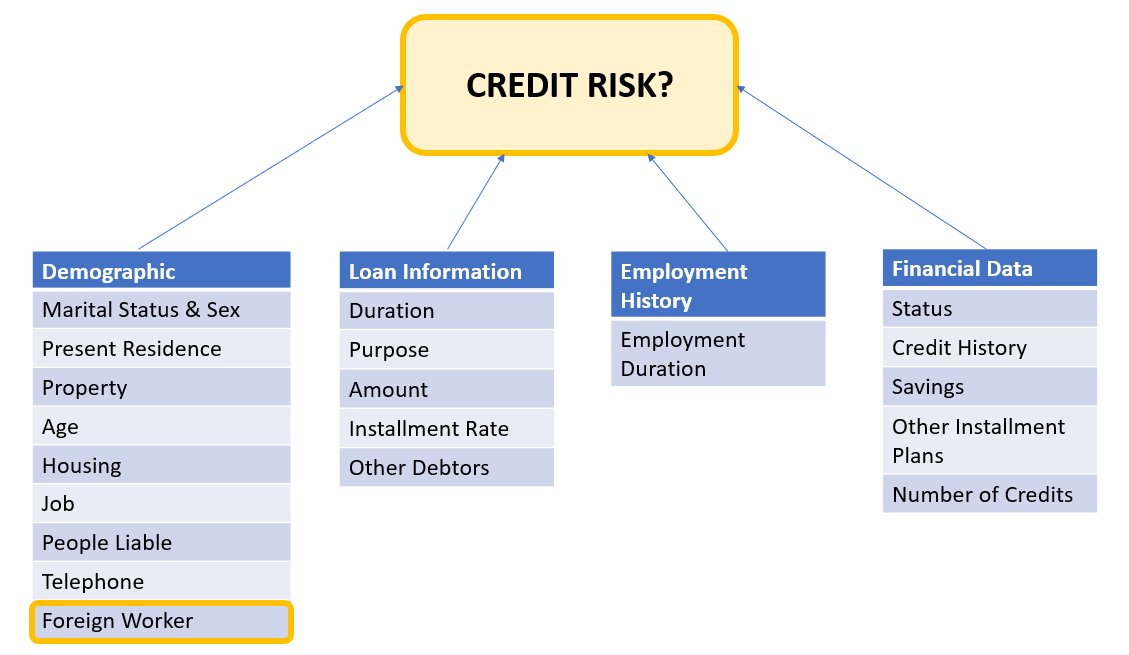
この例では、特に「外国人労働者」の人口統計を調べ、その特定のサブグループに対して高精度かつ低バイアスで与信申請の決定を予測するモデルを調整します。
様々な バイアス指標 これは、データ内の特定のサブグループに関してシステムの公平性を評価するために使用できます。 ここでは、予測されたラベルの正の割合の差の絶対値を使用します (DPPL) SageMaker Clarify から。 簡単に言えば、DPPL は、非外国人労働者と外国人労働者との間の肯定的なクラス (信用度の高い) 割り当ての違いを測定します。
たとえば、すべての外国人労働者の 4.5% がモデルによって肯定的なラベルを割り当てられ、すべての非外国人労働者の 13.7% が肯定的なラベルを割り当てられている場合、 DPPL = 0.137 – 0.045 = 0.092.
ソリューションアーキテクチャ
以下の図は、Amazon SageMaker で XGBoost を使用した自動モデル チューニング ジョブのアーキテクチャの概要を示しています。

このソリューションでは、SageMaker Processing が Amazon S3 からのトレーニング データセットを前処理します。 Amazon SageMaker 自動チューニングは、関連付けられた EC2 インスタンスと EBS ボリュームを使用して、複数の SageMaker トレーニング ジョブをインスタンス化します。 アルゴリズム (XGBoost) のコンテナは、各ジョブで Amazon ECR からロードされます。 SageMaker AMT は、指定されたアルゴリズム スクリプトとハイパーパラメータの範囲を使用して、前処理されたデータセットで多くのトレーニング ジョブを実行することにより、モデルの最適なバージョンを見つけます。 出力メトリクスは、モニタリングのために Amazon CloudWatch に記録されます。
このユース ケースで調整するハイパーパラメータは次のとおりです。
- イータ – オーバーフィッティングを防ぐために更新で使用されるステップ サイズの縮小。
- min_child_weight – 子に必要なインスタンスの重み (ヘシアン) の最小合計。
- ガンマ – ツリーのリーフ ノードでさらにパーティションを作成するために必要な最小損失削減。
- max_depth – ツリーの最大深度。
これらのハイパーパラメータの定義と、SageMaker AMT で利用可能な他のものを見つけることができます こちら.
まず、自動モデル調整を使用してハイパーパラメーターを調整するための単一のパフォーマンス目標メトリックのベースライン シナリオを示します。 次に、パフォーマンス メトリックと公平性メトリックの組み合わせとして指定された多目的メトリックの最適化されたシナリオを示します。
単一メトリック ハイパーパラメータ チューニング (ベースライン)
個々のトレーニング ジョブを評価するためのチューニング ジョブには、複数のメトリックを選択できます。 以下のコード スニペットに従って、単一の目標メトリックを次のように指定します。 objective_metric_name. ハイパーパラメータ チューニング ジョブは、選択された目標指標に最適な値を与えるトレーニング ジョブを返します。
このベースライン シナリオでは、以下に示すように曲線下面積 (AUC) を調整しています。 AUC のみを最適化しており、公平性などの他の指標については最適化していないことに注意することが重要です。
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner hyperparameter_ranges = {'eta': ContinuousParameter(0, 1), 'min_child_weight': IntegerParameter(1, 10), 'gamma': IntegerParameter(1, 5), 'max_depth': IntegerParameter(1, 10)} objective_metric_name = 'validation:auc' tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10,
) tuning_job_name = "xgb-tuner-{}".format(strftime("%d-%H-%M-%S", gmtime()))
inputs = {'train': train_data_path, 'validation': val_data_path}
tuner.fit(inputs, job_name=tuning_job_name)
tuner.wait()
tuner_metrics = sagemaker.HyperparameterTuningJobAnalytics(tuning_job_name)この文脈で max jobs XNUMX つのトレーニング ジョブを調整する回数を指定し、そこから最適なトレーニング ジョブを見つけることができます。
多目的ハイパーパラメータ調整 (公平性最適化)
これで説明されているように、ハイパーパラメータ調整を使用して複数の客観的指標を最適化したい 紙. ただし、SageMaker AMT は依然として入力として XNUMX つのメトリクスのみを受け入れます。
この課題に対処するために、複数のメトリックを単一のメトリック関数として表現し、このメトリックを最適化します。
- maxM(y1 ,y2 ,θ)
- y1 、y2 は異なるメトリックです。 たとえば、AUC スコアと DPPL です。
- M(⋅,⋅,θ) はスカラー化関数であり、固定パラメーターによってパラメーター化されます
重みが高いほど、モデルの調整における特定の目的に有利に働きます。 重みはケースバイケースで注意が必要な場合があり、ユース ケースに応じてさまざまな重みを試す必要がある場合があります。 この例では、AUC と DPPL の重みがヒューリスティックに設定されています。 これがコードでどのように見えるか見てみましょう。 パフォーマンスの AUC スコアと公平性の DPPL の組み合わせ関数に基づいて、トレーニング ジョブが単一のメトリックを返すことがわかります。 複数の目的のハイパーパラメーター最適化範囲は、単一の目的と同じです。 検証メトリックを「auc」として渡していますが、バックグラウンドでは、以下の関数のリストの最後に説明されているように、結合されたメトリック関数の結果を返しています。
多目的最適化関数は次のとおりです。
objective_metric_name = 'validation:auc'
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10
)AUC スコアを計算する関数は次のとおりです。
def eval_auc_score(predt, dtrain):
fY = [1 if p > 0.5 else 0 for p in predt]
y = dtrain.get_label()
auc_score = roc_auc_score(y, fY)
return auc_scoreDPPL スコアを計算する関数は次のとおりです。
def eval_dppl(predt, dtrain):
dtrain_np = dmatrix_to_numpy(dtrain)
# groups: an np array containing 1 or 2
groups = dtrain_np[:, -1]
# sensitive_facet_index: boolean column indicating sensitive group
sensitive_facet_index = pd.Series(groups - 1, dtype=bool)
# positive_predicted_label_index: boolean column indicating positive predicted labels
positive_label_index = pd.Series(predt > 0.5)
return abs(DPPL(predt, sensitive_facet_index, positive_label_index))結合メトリックの関数は次のとおりです。
def eval_combined_metric(predt, dtrain):
auc_score = eval_auc_score(predt, dtrain)
DPPL = eval_dppl(predt, dtrain)
# Assign weight of 3 to AUC and 1 to DPPL
# Maximize (1-DPPL) for the purpose of minimizing DPPL combined_metric = ((3*auc_score)+(1-DPPL))/4 print("DPPL, AUC Score, Combined Metric: ", DPPL, auc_score, combined_metric)
return "auc", combined_metric実験と結果
バイアス データセットの合成データ生成
元の南ドイツ信用データセットには 1000 レコードが含まれていましたが、さらに 100 レコードを総合的に生成して、モデル予測の偏りが外国人労働者を不利にするデータセットを作成しました。 これは、現実の世界で現れる可能性のあるバイアスをシミュレートするために行われます。 「信用不良者」の申請者としてラベル付けされた外国人労働者の新しい記録は、同じラベルが付いた既存の外国人労働者から推定されました。
合成データを作成するための多くのライブラリ/手法があり、私たちはそれらを使用しています 合成データボールト (DPPLV)。
次のコード スニペットから、南ドイツのクレジット データ セットを使用して DPPLV で合成データがどのように生成されるかを確認できます。
# Parameters for generated data
# How many rows of synthetic data
num_rows = 100 # Select all foreign workers who were accepted (foreign_worker value 1 credit_risk 1)
ForeignWorkerData = training_data.loc[(training_data['foreign_worker'] == 1) & (training_data['credit_risk'] == 1)] # Fit Foreign Worker data to SDV model
model = GaussianCopula()
model.fit(ForeignWorkerData) # Generate Synthetic foreign worker data based on rows stated
SynthForeignWorkers = model.sample(Rows)元のデータセットで受け入れられた外国人労働者に基づいて、外国人労働者の 100 の新しい合成レコードを生成しました。 これらのレコードを取得して、「credit_risk」ラベルを 0 (信用不良者) に変換します。 これにより、これらの外国人労働者が信用不良者として不当にマークされ、データセットにバイアスが挿入されます
SynthForeignWorkers.loc[SynthForeignWorkers['credit_risk'] == 1, 'credit_risk'] = 0以下のグラフを通じて、データセットの偏りを調べます。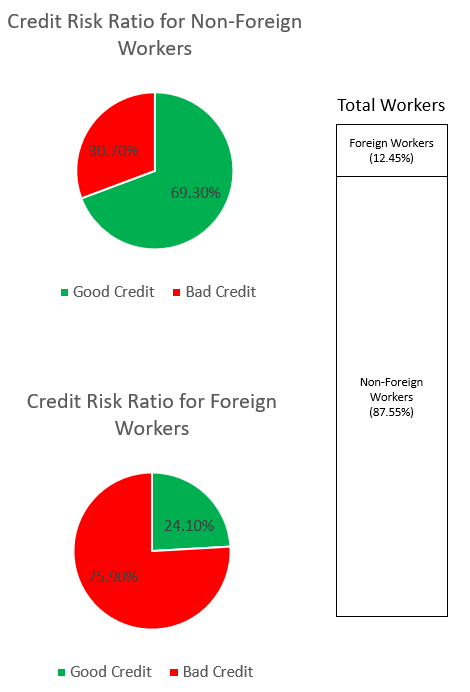
上の円グラフは、信用度が高いまたは信用度が低いと分類された非外国人労働者の割合を示し、下の円グラフは、外国人労働者について同じことを示しています。 「信用不良者」と分類された外国人労働者の割合は 75.90% で、同じ分類の非外国人労働者の 30.70% をはるかに上回っています。 スタック バーには、外国人労働者と非外国人労働者のカテゴリ全体の労働者総数のほぼ同様の割合の内訳が表示されます。
ML モデルが、データ内の明示的な機能または暗黙的なプロキシ機能を通じて、外国人労働者に対する強い偏見を学習することを回避したいと考えています。 追加の公平性の目的により、外国人労働者に対する信用力の低下の偏りを軽減するように ML モデルを導きます。
パフォーマンスと公平性の両方を調整した後のモデル パフォーマンス
このグラフは、SageMaker AMT によって実行された最大 100 個のチューニングジョブの密度プロットと、それに対応する結合された客観的なメトリクス値を示しています。 設定しておりますが max jobs 100まで、ユーザーの判断で変更可能です。 結合されたメトリックは、AUC と DPPL の組み合わせであり、次の機能があります。 (3*AUC + (1-DPPL)) / 4. (DPPL) の代わりに (1-DPPL) を使用する理由は、可能な限り低い DPPL の組み合わせ目標を最大化したいためです (DPPL が低いということは、外国人労働者に対するバイアスが低いことを意味します)。 このプロットは、AMT が XGBoost モデルの最適なハイパーパラメータを特定するのにどのように役立つかを示しています。このハイパーパラメータは、0.68 という最高の組み合わせ評価メトリック値を返します。
指標を組み合わせたモデルのパフォーマンス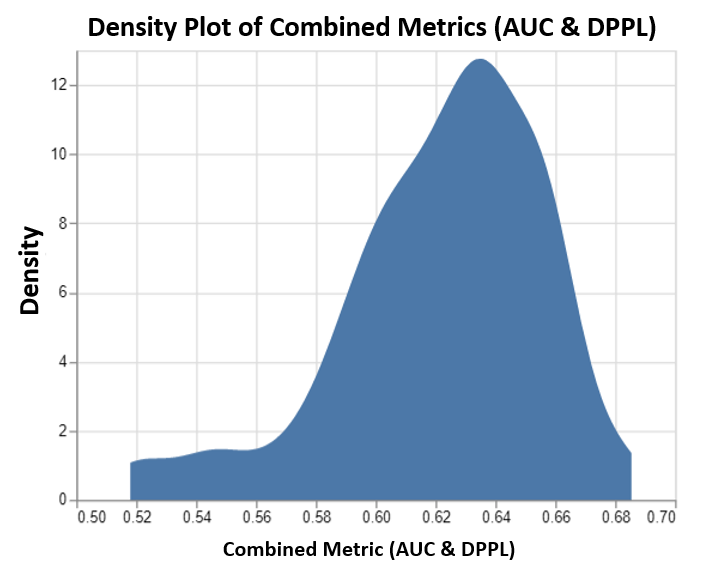
以下では、AUC と DPPL の個々の指標のパレート フロント チャートを見ていきます。 ここでは、パレート フロント チャートを使用して、複数の目的の間のトレードオフを視覚的に表しています。この場合は、XNUMX つのメトリック値 (AUC と DPPL) です。 カーブ フロントのポイントは同等に優れていると見なされ、一方のメトリックを改善するには、もう一方のメトリックを低下させる必要があります。 パレート図を使用すると、両方のメトリックに関して、ベースライン (赤い円) に対してさまざまなジョブがどのように実行されたかを確認できます。 また、最適なジョブ (緑色の三角形) も示しています。 赤い円と緑の三角形の位置は重要です。なぜなら、組み合わせたメトリックが実際に期待どおりに機能しているかどうか、両方のメトリックに対して真に最適化されているかどうかを理解できるからです。 パレート フロント チャートを生成するコードは、次のノートブックに含まれています。 GitHubの.
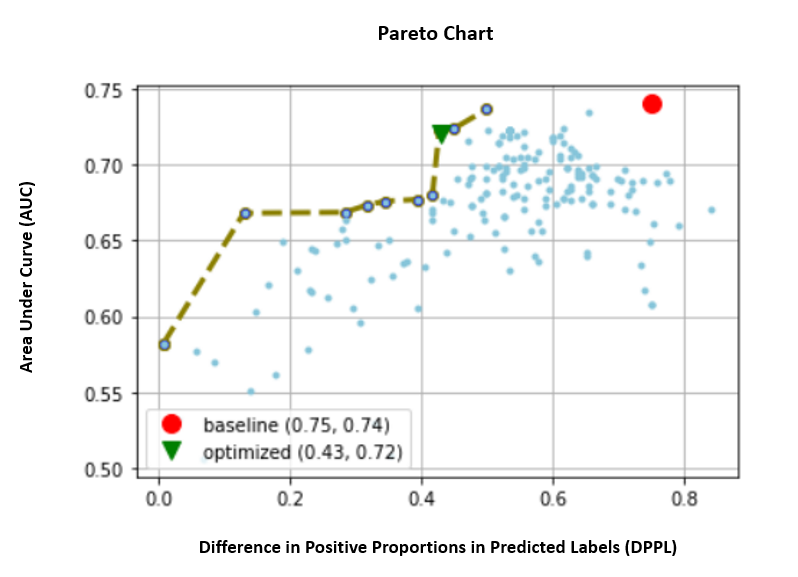
このシナリオでは、DPPL 値が低いほど望ましい (バイアスが少ない) のに対して、AUC が高いほど優れています (パフォーマンスが向上します)。
ここで、ベースライン (赤い円) は、客観的なメトリックが AUC のみであるシナリオを表します。 つまり、ベースラインは DPPL をまったく考慮せず、AUC のみを最適化します (公平性のための微調整は行いません)。 ベースラインの AUC スコアは 0.74 と良好ですが、DPPL スコアが 0.75 であり、公平性についてはうまく機能していません。
最適化されたモデル (緑色の三角形) は、AUC:DPPL の重み比が 3:1 の組み合わせメトリックに対して微調整された場合の最適な候補モデルを表します。 最適化されたモデルの AUC スコアは 0.72 と良好で、DPPL スコアは 0.43 と低くなっています (低バイアス)。 このチューニング ジョブは、AUC を大幅に低下させることなく、DPPL をベースラインよりも大幅に低くできるモデル コンフィギュレーションを検出しました。 DPPL スコアがさらに低いモデルは、緑色の三角形をパレート フロントに沿ってさらに左に移動することで識別できます。 このようにして、外国人労働者のサブグループの公平性を備えたパフォーマンスの高いモデルという複合的な目的を達成しました。
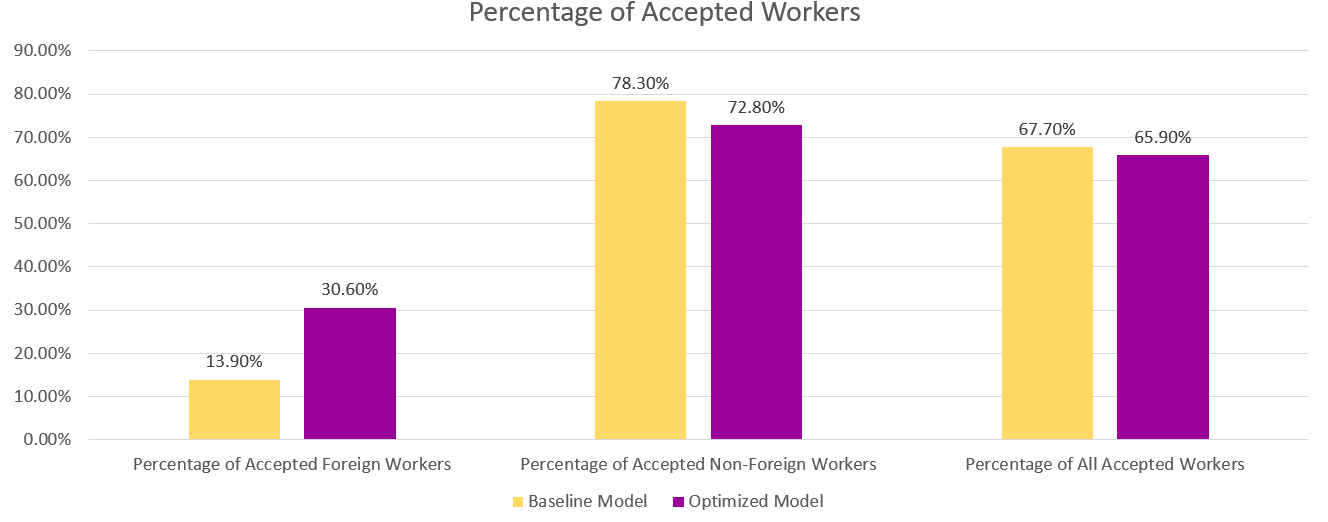
下のグラフでは、ベースライン モデルと最適化されたモデルからの予測結果を確認できます。 パフォーマンスと公平性を組み合わせた目的を持つ最適化されたモデルは、ベースライン モデルの 30.6% とは対照的に、13.9% の外国人労働者に肯定的な結果を予測します。 したがって、最適化されたモデルは、このサブグループに対するモデルの偏りを減らします。
まとめ
このブログでは、実世界のアプリケーション向けに SageMaker 自動モデル調整を使用して多目的最適化を実装する方法を紹介しています。 多くの場合、現実世界で収集されたデータは、特定のサブグループに対して偏っている可能性があります。 自動モデル チューニングを使用した多目的最適化により、顧客は精度に加えて公平性を最適化する ML モデルを簡単に構築できます。 信用リスク予測の例を示し、特に外国人労働者の公平性を調べます。 高いパフォーマンスでモデルをトレーニングし続けながら、公平性などの別のメトリックを最大化できることを示します。 読んだ内容に興味をそそられた場合は、Github でホストされているコード例を試してみてください。 こちら.
著者について
 ムニッシュ ダブラ アマゾン ウェブ サービス (AWS) のシニア ソリューション アーキテクトです。 彼が現在注力している分野は、AI/ML、データ分析、オブザーバビリティです。 彼は、スケーラブルな分散システムの設計と構築に強いバックグラウンドを持っています。 彼は、AWS でお客様のビジネスの革新と変革を支援することを楽しんでいます。 リンクトイン: /ムダブラ
ムニッシュ ダブラ アマゾン ウェブ サービス (AWS) のシニア ソリューション アーキテクトです。 彼が現在注力している分野は、AI/ML、データ分析、オブザーバビリティです。 彼は、スケーラブルな分散システムの設計と構築に強いバックグラウンドを持っています。 彼は、AWS でお客様のビジネスの革新と変革を支援することを楽しんでいます。 リンクトイン: /ムダブラ
 ハサン・プーナワラ AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトである Hasan は、顧客が AWS の本番環境で機械学習アプリケーションを設計およびデプロイするのを支援しています。 彼は、データ サイエンティスト、機械学習の実践者、およびソフトウェア開発者として 12 年以上の実務経験があります。 余暇には、Hasan は自然を探索し、友人や家族と過ごすのが大好きです。
ハサン・プーナワラ AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトである Hasan は、顧客が AWS の本番環境で機械学習アプリケーションを設計およびデプロイするのを支援しています。 彼は、データ サイエンティスト、機械学習の実践者、およびソフトウェア開発者として 12 年以上の実務経験があります。 余暇には、Hasan は自然を探索し、友人や家族と過ごすのが大好きです。
 モハマド (モー) ターシン AWS のアソシエイト AI/ML スペシャリスト ソリューション アーキテクトです。 Moh は、責任ある AI の概念について学生に教えた経験があり、クラウドベースのアーキテクチャを通じてこれらの概念を伝えることに情熱を注いでいます。 余暇には、ウェイトを持ち上げたり、ゲームをしたり、自然を探索したりするのが大好きです。
モハマド (モー) ターシン AWS のアソシエイト AI/ML スペシャリスト ソリューション アーキテクトです。 Moh は、責任ある AI の概念について学生に教えた経験があり、クラウドベースのアーキテクチャを通じてこれらの概念を伝えることに情熱を注いでいます。 余暇には、ウェイトを持ち上げたり、ゲームをしたり、自然を探索したりするのが大好きです。
 シンチェン・マ AWS の応用科学者です。 彼は SageMaker Automatic Model Tuning のサービスチームで働いています。
シンチェン・マ AWS の応用科学者です。 彼は SageMaker Automatic Model Tuning のサービスチームで働いています。
 ラフル・スレカ インドを拠点とする AWS のエンタープライズ ソリューション アーキテクトです。 Rahul は、複数の業界セグメントにわたる大規模なビジネス変革プログラムの設計と主導において 22 年以上の経験があります。 彼の関心分野は、データと分析、ストリーミング、および AI/ML アプリケーションです。
ラフル・スレカ インドを拠点とする AWS のエンタープライズ ソリューション アーキテクトです。 Rahul は、複数の業界セグメントにわたる大規模なビジネス変革プログラムの設計と主導において 22 年以上の経験があります。 彼の関心分野は、データと分析、ストリーミング、および AI/ML アプリケーションです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/tune-ml-models-for-additional-objectives-like-fairness-with-sagemaker-automatic-model-tuning/

