ビジネスが拡大するにつれて、企業ネットワーク内の IP アドレスの需要が供給を超えることがよくあります。組織のネットワークは多くの場合、将来の要件をある程度予測して設計されていますが、企業が進化するにつれて、情報技術 (IT) のニーズは以前に設計されたネットワークを超えています。企業は、限られた IP アドレスのプールを管理することが困難になる可能性があります。
データ エンジニアリング ワークロードの場合 AWSグルー このような制約のあるネットワーク構成で使用すると、チームは多くのジョブを同時に実行するというハードルに直面することがあります。これは、データベースへの必要な接続をサポートするのに十分な IP アドレスがないために発生します。この不足を克服するために、チームは企業ネットワーク プールからさらに多くの IP アドレスを取得する場合があります。これらの取得された IP アドレスは、企業ネットワークで再利用される場合、一意 (重複しない) になることも、重複することもあります。
重複する IP アドレスを使用する場合、接続を確立するために追加のネットワーク管理が必要になります。ネットワーキング ソリューションには次のようなオプションが含まれます。 プライベート ネットワーク アドレス変換 (NAT) ゲートウェイ, AWS プライベートリンク、または自己管理型 NAT アプライアンスを使用して IP アドレスを変換します。
この投稿では、AWS Glue ジョブをスケーリングするための 2 つの戦略について説明します。
- データ処理ユニット (DPU) の適切なサイズ設定、AWS Glue の Auto Scaling 機能の使用、およびジョブの微調整によって、IP アドレスの消費を最適化します。
- プライベート NAT ゲートウェイを備えた追加のルーティング不可能なクラスレス ドメイン間ルーティング (CIDR) 範囲を使用して、ネットワーク容量を拡張します。
これらのソリューションについて詳しく説明する前に、AWS Glue がどのように使用するかを理解しましょう。 エラスティックネットワークインターフェース (ENI) 接続を確立します。 VPC 内のデータストアへのアクセスを有効にするには、VPC にアタッチされる AWS Glue 接続を作成する必要があります。 AWS Glue ジョブが VPC で実行されると、ジョブはデータ接続ごとに設定された VPC 内に ENI を作成し、その ENI は指定された VPC 内の IP アドレスを使用します。これらの ENI の有効期間は短く、ジョブが完了するまでアクティブになります。
次に、AWS Glue IP アドレス消費の最適化を説明する最初のソリューションを見てみましょう。
IP アドレスを効率的に使用するための戦略
AWS Glue では、ジョブが使用するワーカーの数によって、VPC サブネットから使用される IP アドレスの数が決まります。これは、各ワーカーに 1 つの ENI にマップされる 1 つの IP アドレスが必要であるためです。 AWS Glue サブネットに十分な CIDR 範囲が割り当てられていない場合、IP アドレス枯渇エラーが発生する可能性があります。以下は、AWS Glue IP アドレスの消費を最適化するためのいくつかのベストプラクティスです。
- ジョブの DPU の適切なサイズ設定 – AWS Glue は分散処理エンジンです。タスクを並行して実行できる場合、効率的に動作します。ジョブに必要な DPU よりも多くの DPU がある場合、ジョブの実行が常に速くなるとは限りません。したがって、適切な数の DPU を見つけることで、IP アドレスを最適に使用できるようになります。システムに可観測性を構築し、ジョブのパフォーマンスを分析することで、ENI の消費傾向を把握し、適切なサイズのジョブに適切な容量を構成できます。詳細については、を参照してください。 DPU キャパシティ プランニングのモニタリング。 Spark UI は、AWS Glue ジョブのワーカーの使用状況を監視するのに役立つツールです。詳細については、を参照してください。 Apache Spark Web UIを使用したジョブの監視.
- AWS Glue Auto Scaling – 多くの場合、ジョブのキャパシティ要件を事前に予測するのは困難です。 AWS Glue の Auto Scaling 機能を有効にすると、この責任の一部が AWS にオフロードされます。実行時に、ワークロード要件に基づいて、ジョブはワーカー ノードを定義された最大構成まで自動的にスケールします。追加の必要がない場合、AWS Glue はワーカーをオーバープロビジョニングしないため、リソースが節約され、コストが削減されます。 Auto Scaling 機能は、AWS Glue 3.0 以降で利用できます。詳細については、以下を参照してください。 AWS Glue Auto Scalingの紹介:最適化されたApache Sparkを使用して、サーバーレスコンピューティングリソースのサイズを自動的に変更し、コストを削減します.
- ジョブ レベルの最適化 – 次を使用してジョブ レベルの最適化を特定します。 AWS Glue ジョブメトリクス 、からのベスト プラクティスを適用します。 AWS Glue for Apache Spark ジョブのパフォーマンス調整のベストプラクティス.
次に、ネットワーク容量の拡張を詳しく説明する 2 番目のソリューションを見てみましょう。
ネットワーク規模(IPアドレス)拡張のソリューション
このセクションでは、ネットワーク サイズを拡大するために考えられる 2 つのソリューションについて詳しく説明します。
ルーティング可能なアドレスを使用して VPC CIDR 範囲を拡張する
4 つの解決策は、プライベート IPvXNUMX CIDR 範囲をさらに追加することです。 RFC 1918 VPC に。理論的には、各 AWS アカウントをこれらの IP アドレス CIDR の一部またはすべてに割り当てることができます。 IP アドレス管理 (IPAM) チームは、複数の AWS アカウントまたはビジネス ユニット間で IP アドレスが重複するのを避けるために、各ビジネス ユニットが RFC1918 に基づいて使用できる IP アドレスの割り当てを管理することがよくあります。 IPAM チームによって割り当てられた現在のルーティング可能な IP アドレス割り当てが十分でない場合は、追加をリクエストできます。
IPAM チームが重複しない追加の CIDR 範囲を発行した場合は、それをセカンダリ CIDR として既存の VPC に追加するか、それを使用して新しい VPC を作成できます。新しい VPC を作成する予定がある場合は、次の方法で VPC を相互接続できます。 VPCピアリング or AWSトランジットゲートウェイ.
この追加容量が、定義された期間内にすべてのジョブを実行するのに十分な場合、それはシンプルでコスト効率の高いソリューションとなります。それ以外の場合は、次のセクションで説明するように、プライベート NAT ゲートウェイを使用して重複する IP アドレスを採用することを検討できます。次のソリューションでは、2 つの VPC で CIDR 範囲が重複している場合は VPC ピアリングができないため、Transit Gateway を使用して VPC を接続する必要があります。
プライベート NAT ゲートウェイを使用してルーティング不可能な CIDR を構成する
AWS ホワイトペーパーに記載されているとおり スケーラブルで安全なマルチ VPC AWS ネットワーク インフラストラクチャの構築では、ルーティング不可能な IP アドレス サブネットを作成し、ルーティング可能な IP アドレス空間 (重複しない) に配置されたプライベート NAT ゲートウェイを使用してトラフィックをルーティングすることで、ネットワーク容量を拡張できます。プライベート NAT ゲートウェイは、ルーティング不可能な IP アドレスとルーティング可能な IP アドレスの間でトラフィックを変換し、ルーティングします。次の図は、AWS Glue を参照したソリューションを示しています。
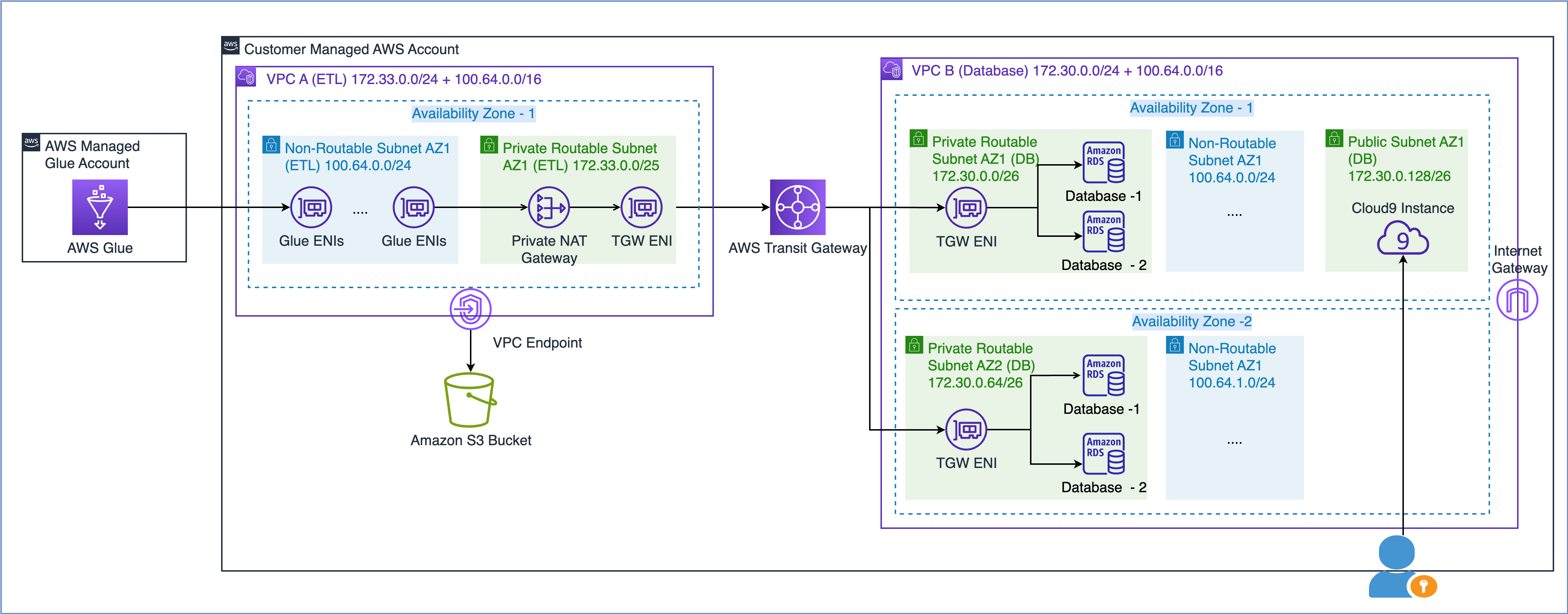
上の図からわかるように、VPC A (ETL) には 172.33.0.0 つの CIDR 範囲が接続されています。小さい CIDR 範囲 24/100.64.0.0 はどこでも再利用されないためルーティング可能ですが、大きい CIDR 範囲 16/XNUMX はデータベース VPC で再利用されるためルーティングできません。
VPC B (データベース) では、ルーティング可能なサブネット 172.30.0.0/26 および 172.30.0.64/26 で 100.64.0.0 つのデータベースをホストしました。これら 24 つのサブネットは、高可用性を実現するために 100.64.1.0 つの別個のアベイラビリティーゾーンにあります。また、ルーティング不可能なセットアップをシミュレートするために、24 つの未使用のサブネット XNUMX/XNUMX および XNUMX/XNUMX も追加しています。
容量要件に基づいて、ルーティング不可能な CIDR 範囲のサイズを選択できます。 IP アドレスを再利用できるため、必要に応じて非常に大規模なサブネットを作成できます。たとえば、/16 の CIDR マスクでは、約 65,000 の IPv4 アドレスが得られます。ネットワーク エンジニアリング チームと協力して、サブネットのサイズを調整できます。
つまり、VPC 内のルーティング可能なサブネットとルーティング不可能なサブネットの両方を使用するように AWS Glue ジョブを設定して、利用可能な IP アドレス プールを最大化できます。
ここで、ルーティング不可能なサブネットにある Glue ENI が別の VPC 内のデータ ソースとどのように通信するかを理解しましょう。
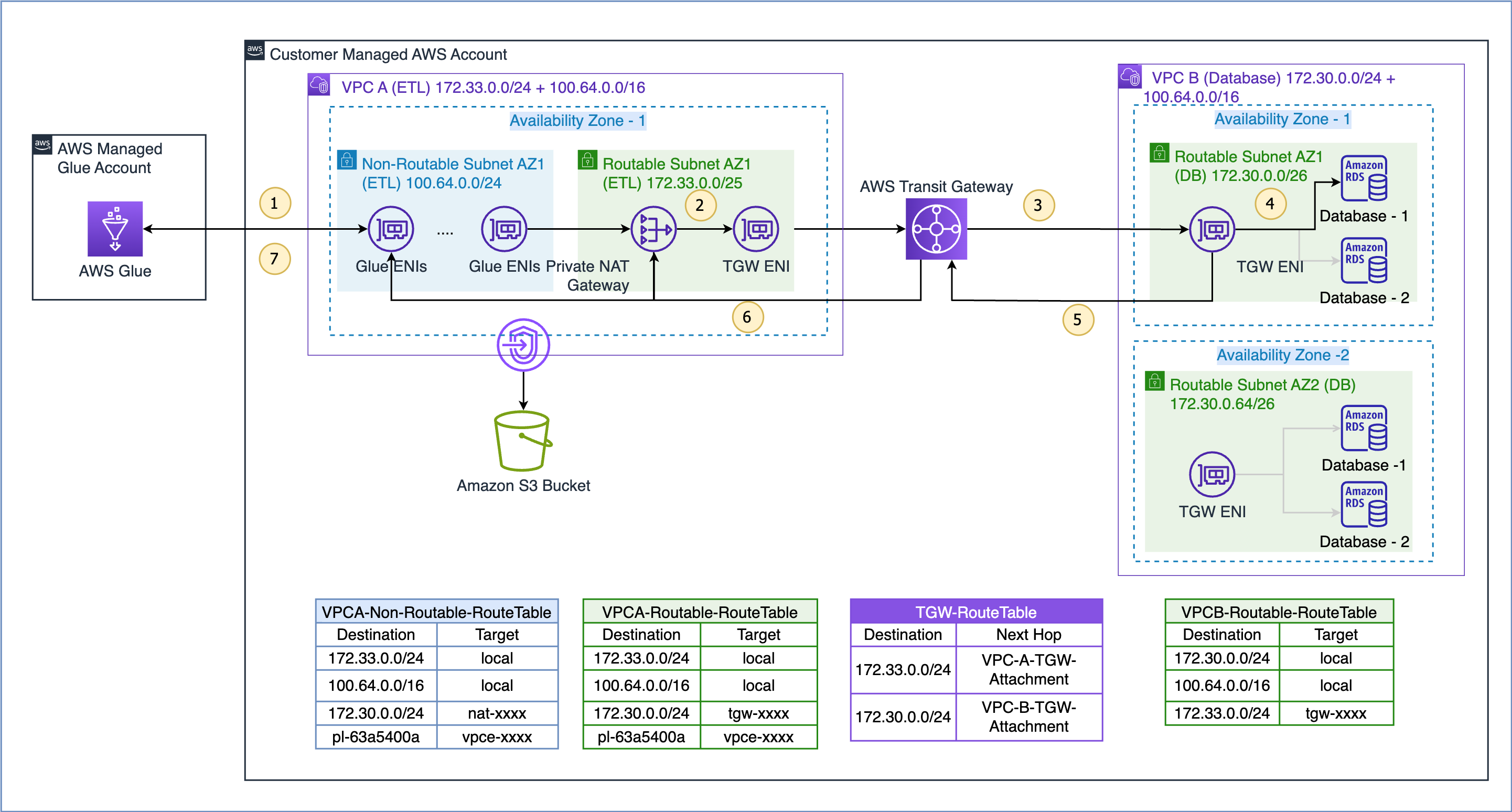
ここで示すユースケースのデータ フローは次のとおりです (上図の番号付きステップを参照)。
- AWS Glue ジョブがデータソースにアクセスする必要がある場合、まずジョブで AWS Glue 接続を使用し、VPC A のルーティング不可能なサブネット 100.64.0.0/24 に ENI を作成します。その後、AWS Glue はデータベース接続設定を使用し、 VPC B 172.30.0.0/24 のデータベースへの接続を試行します。
- ルートテーブルによると
VPCA-Non-Routable-RouteTable宛先 172.30.0.0/24 はプライベート NAT ゲートウェイ用に構成されています。要求は NAT ゲートウェイに送信され、送信元 IP アドレスがルーティング不可能な IP アドレスからルーティング可能な IP アドレスに変換されます。その後、トラフィックは VPC A のトランジット ゲートウェイ アタッチメントに送信されます。これは、トラフィックが VPC A に関連付けられているためです。VPCA-Routable-RouteTableVPC A のルート テーブル。 - トランジット ゲートウェイは 172.30.0.0/24 ルートを使用し、トラフィックを VPC B トランジット ゲートウェイ アタッチメントに送信します。
- VPC B のトランジット ゲートウェイ ENI は、VPC B のローカル ルートを使用してデータベース エンドポイントに接続し、データをクエリします。
- クエリが完了すると、応答は VPC A に返されます。応答トラフィックは VPC B のトランジット ゲートウェイ アタッチメントにルーティングされ、トランジット ゲートウェイは 172.33.0.0/24 ルートを使用して、トラフィックを VPC A トランジット ゲートウェイ アタッチメントに送信します。 。
- VPC A のトランジット ゲートウェイ ENI は、ローカル ルートを使用してトラフィックをプライベート NAT ゲートウェイに転送し、宛先 IP アドレスをルーティング不可能なサブネット内の ENI の IP アドレスに変換します。
- 最後に、AWS Glue ジョブがデータを受信し、処理を続行します。
プライベート NAT ゲートウェイ ソリューションは、組織内のルーティング可能なネットワークから追加の IP アドレスを取得できない場合に追加の IP アドレスが必要な場合のオプションです。場合によっては、サービスを追加するたびに追加コストが発生し、目標を達成するにはこのトレードオフが必要になります。 NAT ゲートウェイの料金セクションを参照してください。 Amazon VPC の料金ページ 。
前提条件
プライベート NAT ゲートウェイ ソリューションのウォークスルーを完了するには、次のものが必要です。
ソリューションを展開する
ソリューションを実装するには、次の手順を実行します。
- AWS 管理コンソールにサインインします。
- をクリックしてソリューションをデプロイします。
 。このスタックのデフォルトは、
。このスタックのデフォルトは、 us-east-1、希望の地域を選択できます。 - クリック 次の 次に、スタックの詳細を指定します。入力パラメータを事前設定されたデフォルト値のままにすることも、必要に応じて変更することもできます。
-
DatabaseUserPassword、選択した英数字のパスワードを入力し、後で使用できるように必ず書き留めてください。 -
S3BucketName、一意の値を入力します Amazon シンプル ストレージ サービス (Amazon S3) バケット名。このバケットには、AWS パブリック コード リポジトリからコピーされる AWS Glue ジョブ スクリプトが保存されます。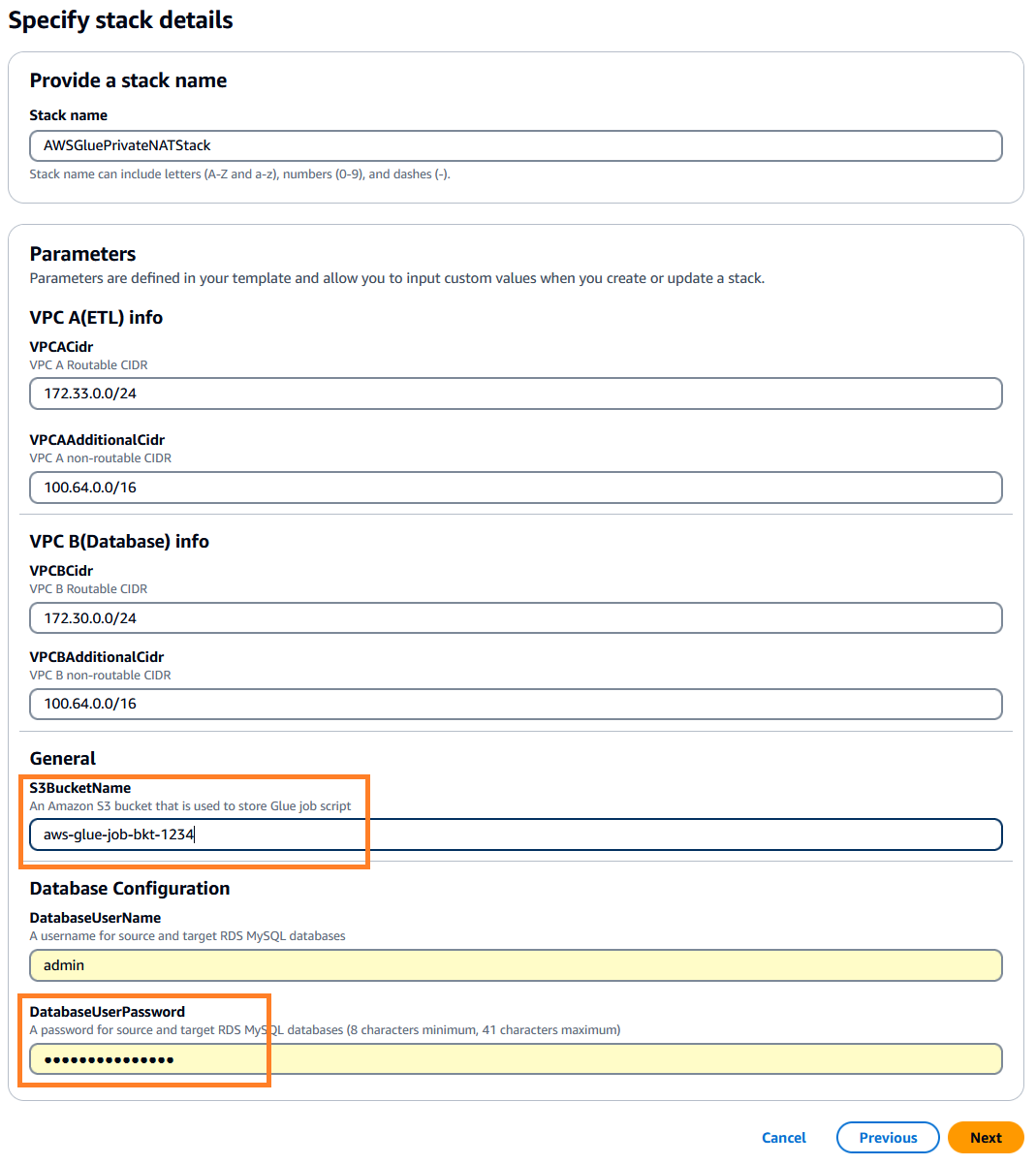
- クリック 次の.
- デフォルト値をそのままにして、 をクリックします。 次の 再び。
- 詳細を確認し、IAM リソースの作成を承認して、 提出する 展開を開始します。
イベントをモニタリングして、AWS CloudFormation コンソールで作成されているリソースを確認できます。スタック リソースが作成されるまでに 20 分程度かかる場合があります。
スタックの作成が完了したら、AWS CloudFormation コンソールの [出力] タブに移動し、後で使用するために次の値をメモします。
DBSourceDBTargetSourceCrawlerTargetCrawler
AWS Cloud9 インスタンスに接続する
次に、ソースとターゲットの Amazon RDS for MySQL テーブルを準備する必要があります。 AWS クラウド9 実例。次の手順を実行します。
- AWS Cloud9 コンソール ページで、
aws-glue-cloud9環境。 - Cloud9 IDE 列で、 をクリックします。 Open 新しいウェブブラウザで AWS Cloud9 インスタンスを起動します。
ソースMySQLテーブルを準備する
ソーステーブルを準備するには、次の手順を実行します。
- AWS Cloud9 ターミナルから、次のコマンドを使用して MySQL クライアントをインストールします。
sudo yum update -y && sudo yum install -y mysql - 次のコマンドを使用してソース データベースに接続します。ソースのホスト名を、前に取得した DBSource 値に置き換えます。プロンプトが表示されたら、スタックの作成時に指定したデータベースのパスワードを入力します。
mysql -h <Source Hostname> -P 3306 -u admin -p - 次のスクリプトを実行してソースを作成します
empテーブルを作成し、テスト データをロードします。-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - ソースを確認してください
emp以下の SQL クエリを使用してテーブルの数を確認します (これは後のステップで検証のために必要になります)。select count(*) from emp; - 次のコマンドを実行して MySQL クライアント ユーティリティを終了し、AWS Cloud9 インスタンスのターミナルに戻ります。
quit;
ターゲットのMySQLテーブルを準備する
ターゲットテーブルを準備するには、次の手順を実行します。
- 次のコマンドを使用してターゲット データベースに接続します。ターゲットのホスト名を、前に取得した DBTarget 値に置き換えます。プロンプトが表示されたら、スタックの作成時に指定したデータベースのパスワードを入力します。
mysql -h <Target Hostname> -P 3306 -u admin -p - 次のスクリプトを実行してターゲットを作成します
empテーブル。このテーブルは、後続のステップで AWS Glue ジョブによってロードされます。-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
ネットワーク設定を確認します (オプション)
次の手順は、NAT ゲートウェイ、ルート テーブル、プライベート NAT ゲートウェイ ソリューションのトランジット ゲートウェイ構成を理解するのに役立ちます。これらのコンポーネントは、CloudFormation スタックの作成中に作成されました。
- Amazon VPC コンソール ページで、[仮想プライベート クラウド] セクションに移動し、NAT ゲートウェイを見つけます。
- NAT ゲートウェイを名前で検索します
Glue-OverlappingCIDR-NATGWそしてそれをさらに探索してください。次のスクリーンショットでわかるように、NAT ゲートウェイはルーティング可能なサブネット上の VPC A (ETL) に作成されました。
- 左側のナビゲーション ペインで、「仮想プライベート クラウド」セクションの「ルート テーブル」に移動します。
- 検索する
VPCA-Non-Routable-RouteTableそしてそれをさらに探索してください。ルート テーブルが、NAT ゲートウェイを使用して重複する CIDR からのトラフィックを変換するように構成されていることがわかります。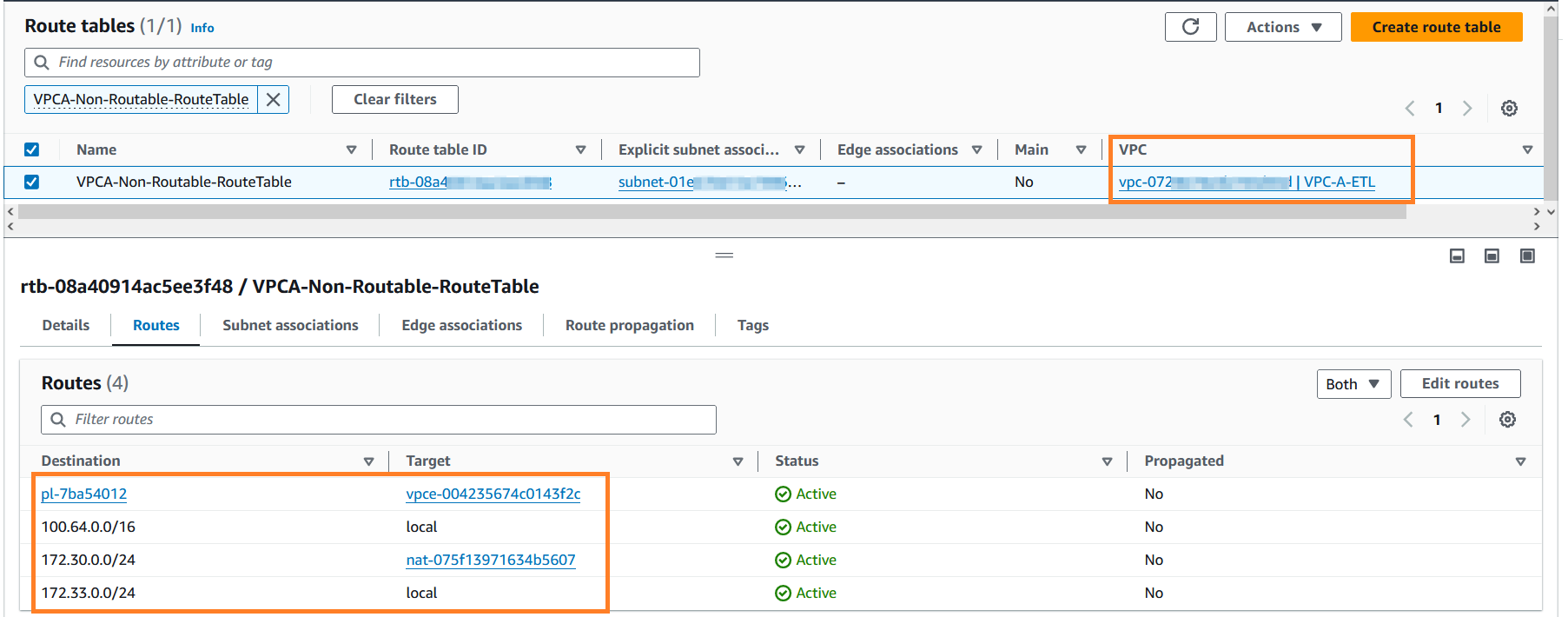
- 左側のナビゲーション ウィンドウで、[トランジット ゲートウェイ] セクションに移動し、[トランジット ゲートウェイの添付ファイル] をクリックします。入力
VPC-検索ボックスで、新しく作成された 2 つのトランジット ゲートウェイの添付ファイルを見つけます。 - これらのアタッチメントをさらに調査して、その構成を学習できます。
AWS Glue クローラーを実行する
ソースとターゲットをカタログ化するために必要な AWS Glue クローラーを実行するには、次の手順を実行します。 emp テーブル。これは、AWS Glue ジョブを実行するための前提条件のステップです。
- AWS Glue コンソール ページのナビゲーション ペインの [データ カタログ] セクションで、 Crawlers.
- 前にメモしたソース クローラーとターゲット クローラーを見つけます。
- これらのクローラを選択して、 ラン それぞれの AWS Glue データ カタログ テーブルを作成します。
- AWS Glue クローラーが正常に完了したかどうかを監視できます。両方のクローラーが完了するまでに約 3 ~ 4 分かかる場合があります。完了すると、ジョブの最後の実行ステータスが「成功」に変わり、この実行から作成された XNUMX つの AWS Glue カタログテーブルがあることもわかります。

AWS Glue ETL ジョブを実行する
テーブルを設定し、前提条件のステップを完了すると、CloudFormation テンプレートを使用して作成した AWS Glue ジョブを実行する準備が整います。このジョブは、ソース RDS for MySQL データベースに接続し、データを抽出して、ターゲット RDS for MySQL データベースにデータをロードします。このジョブは、ソース MySQL テーブルからデータを読み取り、プライベート NAT ゲートウェイ ソリューションを使用してターゲット MySQL テーブルにデータをロードします。 AWS Glue ジョブを実行するには、次の手順を実行します。
- AWS Glue コンソールで、 をクリックします。 ETL ジョブ ナビゲーションペインに表示されます。
- ジョブをクリックします
glue-private-nat-job. - クリック ラン それを開始する。
この ETL ジョブの PySpark スクリプトは次のとおりです。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
ジョブの DPU 設定に基づいて、AWS Glue は AWS Glue 接続上に設定されたルーティング不可能なサブネットに ENI のセットを作成します。これらの ENI は、 アマゾン エラスティック コンピューティング クラウド (Amazon EC2) コンソール。
以下のスクリーンショットは、ジョブ パラメータで構成された要求されたワーカー数と一致するようにジョブ実行用に作成された 10 個の ENI を示しています。予想どおり、ENI は VPC A のルーティング不可能なサブネットに作成され、IP アドレスのスケーラビリティが可能になりました。ジョブが完了すると、これらの ENI は AWS Glue によって自動的にリリースされます。
AWS Glue ジョブの実行中、そのステータスを監視できます。正常に完了すると、ジョブのステータスは次のように変わります。 成功した.
結果を確認する
AWS Glue ジョブが完了したら、ターゲットの MySQL データベースに接続します。ターゲットのレコード数がソースと一致するかどうかを確認します。 AWS Cloud9 ターミナルでは以下の SQL クエリを使用できます。
USE targetdb;
SELECT count(*) from emp;最後に、次のコマンドを使用して MySQL クライアント ユーティリティを終了し、AWS Cloud9 ターミナルに戻ります。 quit;
これで、AWS Glue がルーティング不可能なサブネットの IP アドレスを使用してターゲットデータベースにデータをロードするジョブを正常に完了したことを確認できます。これで、プライベート NAT ゲートウェイ ソリューションのエンドツーエンドのテストは終了です。
クリーンアップ
今後の料金発生を回避するには、次の手順を実行して、CloudFormation スタック経由で作成されたリソースを削除します。
- AWS CloudFormation コンソールのナビゲーションペインで [スタック] をクリックします。
- スタックを選択します
AWSGluePrivateNATStack. - スタックを削除するには、「削除」をクリックします。プロンプトが表示されたら、スタックの削除を確認します。
まとめ
この投稿では、プライベート NAT ゲートウェイ ソリューションを使用して IP アドレスの消費を最適化し、ネットワーク容量を拡張することで、AWS Glue ジョブをスケールする方法を説明しました。この 2 つのアプローチは、IP アドレス容量の制約がある環境でブロックを解除するのに役立ちます。 AWS Glue IP アドレスの最適化セクションで説明されているオプションは、IP アドレス拡張ソリューションを補完するものであり、反復的に構築してデータ プラットフォームを成熟させることができます。
AWS Glue ジョブ最適化テクニックの詳細については、以下をご覧ください。 AWS Glue for Apache Spark のコストをモニタリングして最適化する & AWS Glue を使用して Apache Spark ジョブをスケーリングし、データをパーティション分割するためのベストプラクティス.
著者について
 スシャンス・コタパリ 自動車および製造業の顧客をサポートするアマゾン ウェブ サービスのソリューション アーキテクトです。彼はビジネス目標を達成するためのテクノロジー ソリューションの設計に情熱を持っており、サーバーレスおよびイベント駆動型のアーキテクチャに強い関心を持っています。
スシャンス・コタパリ 自動車および製造業の顧客をサポートするアマゾン ウェブ サービスのソリューション アーキテクトです。彼はビジネス目標を達成するためのテクノロジー ソリューションの設計に情熱を持っており、サーバーレスおよびイベント駆動型のアーキテクチャに強い関心を持っています。
 センティル・カマラ・ラティナム データと分析を専門とするアマゾン ウェブ サービスのソリューション アーキテクトです。彼は、顧客が最新のデータ プラットフォームを設計および構築できるよう支援することに情熱を注いでいます。自由時間には、センティルは家族と時間を過ごしたり、バドミントンをしたりするのが大好きです。
センティル・カマラ・ラティナム データと分析を専門とするアマゾン ウェブ サービスのソリューション アーキテクトです。彼は、顧客が最新のデータ プラットフォームを設計および構築できるよう支援することに情熱を注いでいます。自由時間には、センティルは家族と時間を過ごしたり、バドミントンをしたりするのが大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

