アマゾンオーロラ ゼロETL統合 Amazonレッドシフト で発表された AWS re:Invent 2022 現在、パブリック プレビューで利用可能です Amazon Aurora MySQL 互換エディション 3 (MySQL 8.0 と互換性あり) リージョン内 us-east-1, us-east-2, us-west-2, ap-northeast-1 & eu-west-1。 詳細については、 新着情報の投稿。
この投稿では、この機能を使用してほぼリアルタイムの運用分析を開始する方法について段階的なガイダンスを提供します。

課題
現在、さまざまな業界の顧客が、パーソナライゼーション戦略、不正行為検出、在庫監視などのほぼリアルタイムの分析ユースケースを実装することで、収益と顧客エンゲージメントの向上を目指しています。 これらのユースケースの運用データを分析するには、大きく XNUMX つのアプローチがあります。
- 運用データベース内のデータをインプレースで分析します (リードレプリカ、フェデレーテッド クエリ、分析アクセラレータなど)。
- データ ウェアハウスなどの分析クエリの実行に最適化されたデータ ストアにデータを移動します。
ゼロ ETL 統合は、後者のアプローチを簡素化することに重点を置いています。
運用データベースから分析データ ウェアハウスにデータを移動する一般的なパターンは、抽出、変換、読み込み (ETL) を介して行われます。これは、複数のソースからのデータを大規模な中央リポジトリ (データ ウェアハウス) に結合するプロセスです。 ETL パイプラインは構築に費用がかかり、管理が複雑になる場合があります。 複数のタッチポイントがある場合、ETL パイプラインで断続的なエラーが発生すると長い遅延が発生する可能性があり、このデータに依存するアプリケーションが古いデータまたは欠落したデータのままデータ ウェアハウスで利用できる状態になり、さらにビジネス チャンスの損失につながります。
複数の運用データベースのデータにわたって統合分析を実行する必要がある顧客の場合、インプレースでデータを分析するソリューションは、単一のデータベースに対するクエリを高速化するのに最適ですが、そのようなシステムには複数の運用データベースからのデータを集約できないという制限があります。 。
ゼロETL
AWS では、 ゼロETLビジョン 命に。 Aurora のゼロ ETL と Amazon Redshift の統合により、Aurora のトランザクション データと Amazon Redshift の分析機能を統合できます。 これにより、Aurora と Amazon Redshift の間のカスタム ETL パイプラインを構築および管理する作業が最小限に抑えられます。 データエンジニアは、複数の Aurora データベースクラスターから同じまたは新しい Amazon Redshift インスタンスにデータをレプリケートして、多くのアプリケーションまたはパーティションにわたる全体的な洞察を導き出すことができるようになりました。 Aurora の更新は自動的かつ継続的に Amazon Redshift に伝達されるため、データ エンジニアはほぼリアルタイムで最新の情報を入手できます。 さらに、システム全体をサーバーレスにすることができ、データ量に基づいて動的にスケールアップおよびスケールダウンできるため、管理するインフラストラクチャが必要ありません。
Aurora と Amazon Redshift のゼロ ETL 統合を作成すると、既存の料金設定 (データ転送を含む) で Aurora と Amazon Redshift の使用料金を引き続き支払います。 Aurora のゼロ ETL と Amazon Redshift の統合機能は追加料金なしで利用できます。
Aurora のゼロ ETL と Amazon Redshift の統合により、統合によってソース データベースからターゲット データ ウェアハウスにデータがレプリケートされます。 データは数秒以内に Amazon Redshift で利用可能になり、ユーザーは Amazon Redshift の分析機能や、データ共有、ワークロード最適化オートノミクス、同時実行スケーリング、機械学習などの機能を使用できるようになります。 Aurora のデータに対してリアルタイムのトランザクション処理を実行しながら、同時にレポートやダッシュボードなどの分析ワークロードに Amazon Redshift を使用できます。
次の図は、このアーキテクチャを示しています。

ソリューションの概要
のは、考えてみましょう チケット、ユーザーがスポーツ イベント、ショー、コンサートのチケットをオンラインで売買する架空の Web サイト。 この Web サイトのトランザクション データは、Aurora MySQL 3.03.1 (またはそれ以降のバージョン) データベースにロードされます。 同社のビジネス アナリストは、時間の経過に伴うチケットの動き、販売者の成功率、最も売れているイベント、会場、シーズンを特定するための指標を生成したいと考えています。 彼らは、ゼロ ETL 統合を使用して、これらのメトリクスをほぼリアルタイムで取得したいと考えています。
統合は、Amazon Aurora MySQL 互換エディション 3.03.1 (ソース) と Amazon Redshift (宛先) の間でセットアップされます。 ソースからのトランザクション データは、分析クエリを処理する宛先でほぼリアルタイムで更新されます。
Amazon Aurora MySQL 互換エディションと Amazon Redshift の両方で、プロビジョニングされたオプションまたはサーバーレス オプションを使用できます。 この図では、プロビジョニングされた Aurora データベースと AmazonRedshiftサーバーレス データウェアハウス。 パブリック プレビューに関する考慮事項の完全なリストについては、機能を参照してください。 AWS ドキュメント.
次の図は、アーキテクチャの概要を示しています。

ゼロ ETL 統合を設定するために必要な手順は次のとおりです。 完全な入門ガイドについては、次のドキュメントのリンクを参照してください。 オーロラ & アマゾンの赤方偏移。
- カスタマイズされた DB クラスターパラメーターグループを使用して Aurora MySQL ソースを構成します。
- 名前空間に必要なリソース ポリシーを使用して、Amazon Redshift サーバーレスの宛先を設定します。
- Redshift Serverless ワークグループを更新して、大文字と小文字を区別する識別子を有効にします。
- 必要な権限を設定します。
- ゼロ ETL 統合を作成します。
- Amazon Redshift の統合からデータベースを作成します。
カスタマイズされた DB クラスターパラメーターグループを使用して Aurora MySQL ソースを構成する
Aurora MySQL データベースを作成するには、次の手順を実行します。
- Amazon RDS コンソールで、DB クラスターパラメータグループを作成します。
zero-etl-custom-pg.
Zero-ETL 統合には、バイナリログ (binlog) を制御する Aurora DB クラスターパラメーターの特定の値が必要です。 たとえば、拡張バイナリ モードをオンにする必要があります (aurora_enhanced_binlog=1).
- 次の binlog クラスター パラメーター設定を設定します。
binlog_backup=0binlog_replication_globaldb=0binlog_format=行aurora_enhanced_binlog=1binlog_row_metadata=フルbinlog_row_image=フル
- 選択する 変更を保存します.

- 選択する データベース ナビゲーションペインで、を選択します データベースを作成する.

- 利用可能なバージョン、選択する オーロラ MySQL 3.03.1 (以上)。

- テンプレート選択 生産.
- DBクラスター識別子、 入る
zero-etl-source-ams.
- インスタンス構成選択 メモリ最適化クラス 適切なインスタンス サイズを選択します (デフォルトは
db.r6g.2xlarge).
- 追加の構成、用 DB クラスターパラメータグループ、前に作成したパラメータ グループを選択します (
zero-etl-custom-pg).
- 選択する データベースを作成する.
数分以内に、ゼロ ETL 統合のソースとして Aurora MySQL データベースが起動されます。

Redshiftサーバーレス宛先の構成
このユースケースでは、次の手順を実行して Redshift サーバーレス データ ウェアハウスを作成します。
- Amazon Redshiftコンソールで、 サーバーレスダッシュボード ナビゲーションペインに表示されます。
- 選択する プレビューワークグループの作成.

- ワークグループ名、 入る
zero-etl-target-rs-wg.
- 名前空間選択 新しい名前空間を作成する 入力してください
zero-etl-target-rs-ns.
- ネームスペースに移動します
zero-etl-target-rs-nsを選択して リソースポリシー タブには何も表示されないことに注意してください。 - 選択する 承認されたプリンシパルを追加する.
- この名前空間で統合を作成できる AWS ユーザーまたはロールの Amazon リソースネーム (ARN)、または AWS アカウント ID (IAM プリンシパル) のいずれかを入力します。
アカウント ID は、root ユーザーの ARN として保存されます。

- 承認された統合ソースを名前空間に追加し、ゼロ ETL 統合のデータ ソースである Aurora MySQL DB クラスターの ARN を指定します。
- 選択する 変更を保存します.

Aurora MySQL ソースの ARN は、 次のスクリーンショットに示すように、タブ。

Redshift Serverless ワークグループを更新して、大文字と小文字を区別する識別子を有効にする
AWSコマンドラインインターフェイス (AWS CLI) を実行するには、 アップデートワークグループ アクション:
あなたが使用することができます AWS クラウドシェル または次のような別のインターフェイス アマゾン エラスティック コンピューティング クラウド (Amazon EC2) Redshift Serverless パラメータグループを更新できる AWS ユーザー設定を使用します。 次のスクリーンショットは、これを CloudShell で実行する方法を示しています。

次のスクリーンショットは、 update-workgroup Amazon EC2 のコマンド。

必要な権限を構成する
ゼロ ETL 統合を作成するには、ユーザーまたはロールにアタッチされた アイデンティティベースのポリシー 適切な AWS IDおよびアクセス管理 (IAM) 権限。 次のサンプル ポリシーでは、関連付けられたプリンシパルが次のアクションを実行できるようになります。
- ソース Aurora DB クラスターのゼロ ETL 統合を作成します。
- すべてのゼロ ETL 統合を表示および削除します。
- ターゲット データ ウェアハウスへのインバウンド統合を作成します。 同じアカウントが Amazon Redshift データ ウェアハウスを所有しており、このアカウントがそのデータ ウェアハウスの承認されたプリンシパルである場合、このアクセス許可は必要ありません。 また、Amazon Redshift には、プロビジョニングされたものとサーバーレスのもので異なる ARN 形式があることにも注意してください。
- プロビジョニングされたクラスター –
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - サーバレス –
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- プロビジョニングされたクラスター –
権限を構成するには、次の手順を実行します。
- IAMコンソールで、 Policies ナビゲーションペインに表示されます。
- 選択する ポリシーを作成する.
- という新しいポリシーを作成します。
rds-integrations次の JSON を使用します。
ポリシーのプレビュー:

RDS ポリシー アクションに対する IAM ポリシー警告が表示される場合、この機能はパブリック プレビュー段階にあるため、これは想定内のことです。 これらのアクションは、機能が一般公開されると、IAM ポリシーの一部になります。 安全に続行できます。
- 作成したポリシーを IAM ユーザーまたはロールの権限にアタッチします。
ゼロETL統合を作成する
ゼロ ETL 統合を作成するには、次の手順を実行します。
- Amazon RDS コンソールで、 ゼロETL統合 ナビゲーションペインに表示されます。
- 選択する ゼロETL統合の作成.

- 統合名、たとえば名前を入力します。
zero-etl-demo. - Aurora MySQL ソースクラスター、ソースクラスターを参照して選択します
zero-etl-source-ams.
- 開催場所、用 Amazon Redshift データ ウェアハウス、Redshift Serverless 宛先名前空間 (
zero-etl-target-rs-ns). - 選択する ゼロETL統合の作成.
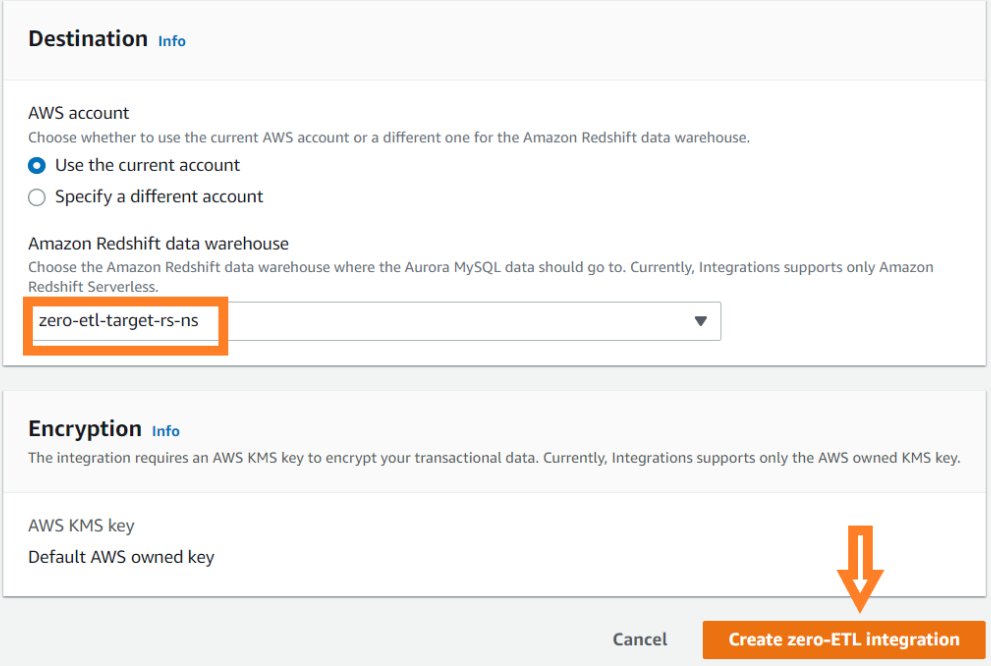
別の AWS アカウントにあるターゲット Amazon Redshift データ ウェアハウスを指定するには、現在のアカウントのユーザーがターゲット アカウントのリソースにアクセスできるようにするロールを作成する必要があります。 詳細については、以下を参照してください。 所有する別の AWS アカウントの IAM ユーザーにアクセスを提供する.
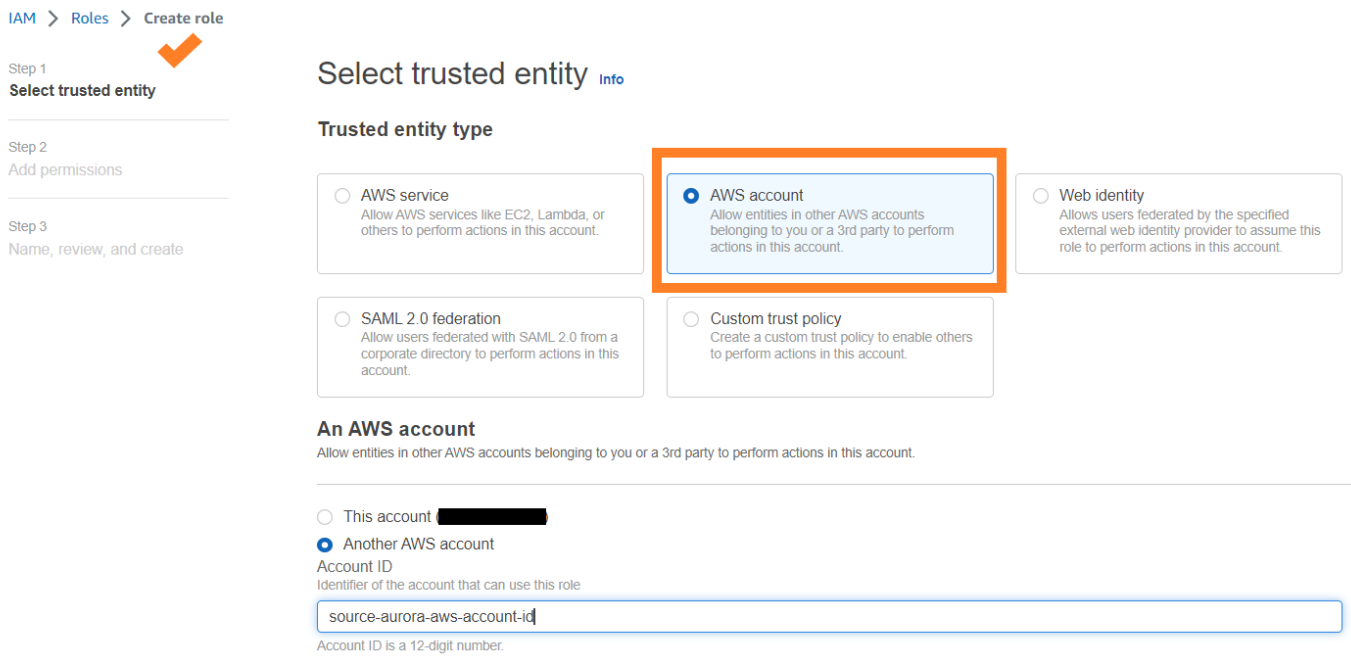
次の権限を持つターゲット アカウントにロールを作成します。
ロールには、ターゲット アカウント ID を指定する次の信頼ポリシーが必要です。 これを行うには、別のアカウントの AWS アカウント ID として信頼できるエンティティを使用してロールを作成します。
次のスクリーンショットは、IAM コンソールでこれを作成する方法を示しています。
次に、ゼロ ETL 統合の作成中に、宛先アカウント ID と作成したロールの名前を選択して、さらに続行します。 別のアカウントを指定してください オプションを選択します。
統合を選択して詳細を表示し、その進行状況を監視できます。 ステータスが から変更されるまでに数分かかります。 作成 〜へ アクティブ. 時間は、ソースですでに利用可能なデータセットのサイズによって異なります。

Amazon Redshift の統合からデータベースを作成する
データベースを作成するには、次の手順を実行します。
- Redshift Serverless ダッシュボードで、
zero-etl-target-rs-ns namespace. - 選択する クエリデータ クエリ エディター v2 を開きます。

- を選択して、プレビュー Redshift サーバーレス データ ウェアハウスに接続します。 接続を作成する.

- を取得します
integration_idsvv_integrationシステムテーブル: -
integration_id前のステップから、統合から新しいデータベースを作成します。

これで統合が完了し、ソースのスナップショット全体がデスティネーションにそのまま反映されます。 進行中の変更はほぼリアルタイムで同期されます。
ほぼリアルタイムのトランザクション データを分析する
これで、TICKIT の運用データに対して分析を実行できるようになりました。
ソースTICKITデータを入力します。
ソース データを入力するには、次の手順を実行します。
- Aurora MySQL クラスターに接続し、TICKIT データモデルのデータベース/スキーマを作成し、そのスキーマ内のテーブルに主キーがあることを確認して、読み込みプロセスを開始します。

スクリプトは以下から利用できます HTMLファイル サンプルデータベースを作成するには demodb (を使用して ティックト.db Amazon Aurora MySQL 互換エディションのモデル)。
- スクリプトを実行して、 ティックト.db のモデルテーブル
demodbデータベース/スキーマ:
- からデータをロード Amazon シンプル ストレージ サービス (Amazon S3)、宛先での変更データ キャプチャ (CDC) 検証の終了時間を記録し、統合がどの程度アクティブであったかを観察します。

以下は 一般的なエラー Amazon S3 からの負荷に関連する:
- Aurora MySQL クラスターの現在のバージョンでは、
aws_default_s3_roleDB クラスターパラメータグループのパラメータを、必要な Amazon S3 アクセス権限を持つロール ARN に追加します。
- 資格情報が欠落していることによるエラーが発生した場合 (たとえば、
Error 63985 (HY000): S3 API returned error: Missing Credentials: Cannot instantiate S3 Client)の場合は、IAM ロールをクラスターに関連付けていない可能性があります。 この場合、目的の IAM ロールをソース Aurora MySQL クラスターに追加します。
宛先のソース TICKIT データを分析する
Redshift Serverless ダッシュボードで、統合セットアップの一部として作成したデータベースを使用してクエリ エディター v2 を開きます。 次のコードを使用して、シードまたは CDC アクティビティを検証します。

ドロップダウン メニューで統合から作成されたクラスターまたはワークグループとデータベースを選択し、実行します ticit.db サンプル分析クエリ.

監視
Amazon Redshift で次のシステムビューとテーブルをクエリして、Aurora のゼロ ETL と Amazon Redshift の統合に関する情報を取得できます。
Amazon CloudWatch に公開された統合関連のメトリクスを表示するには、Amazon Redshift コンソールに移動します。 左側のナビゲーション ペインから Zero-ETL 統合を選択し、統合リンクをクリックしてアクティビティ メトリックを表示します。

Redshift コンソールで利用可能なメトリクスは統合メトリクスとテーブル統計で、テーブル統計は Aurora MySQL から Amazon Redshift にレプリケートされた各テーブルの詳細を提供します。

統合メトリクスには、テーブル レプリケーションの成功/失敗数とラグの詳細が含まれます。
クリーンアップ
ゼロ ETL 統合を削除すると、Aurora はその統合を Aurora クラスターから削除します。 トランザクションデータは Aurora または Amazon Redshift から削除されませんが、Aurora は新しいデータを Amazon Redshift に送信しません。
ゼロ ETL 統合を削除するには、次の手順を実行します。
- Amazon RDS コンソールで、 ゼロETL統合 ナビゲーションペインに表示されます。
- 削除するゼロ ETL 統合を選択し、 削除.
- 削除を確認するには、 削除.

まとめ
この投稿では、Amazon Aurora MySQL 互換エディションから Amazon Redshift への Aurora ゼロ ETL 統合をセットアップする方法を説明しました。 これにより、複雑なデータ パイプラインを維持する必要性が最小限に抑えられ、トランザクション データと運用データのほぼリアルタイムの分析が可能になります。
Aurora のゼロ ETL と Amazon Redshift の統合の詳細については、次のドキュメントを参照してください。 オーロラ & Amazonレッドシフト.
著者について
 ロヒト・ヴァシシュタ テキサス州ダラスを拠点とする AWS のシニア分析スペシャリスト ソリューション アーキテクトです。 彼は、ビッグ データ プラットフォームの設計、構築、主導、保守に 17 年の経験があります。 Rohit は、AWS の幅広いサービスを使用して顧客が分析ワークロードを最新化するのを支援し、最高のセキュリティとデータ ガバナンスを備えた最高の価格/パフォーマンスを顧客が確実に得られるようにします。
ロヒト・ヴァシシュタ テキサス州ダラスを拠点とする AWS のシニア分析スペシャリスト ソリューション アーキテクトです。 彼は、ビッグ データ プラットフォームの設計、構築、主導、保守に 17 年の経験があります。 Rohit は、AWS の幅広いサービスを使用して顧客が分析ワークロードを最新化するのを支援し、最高のセキュリティとデータ ガバナンスを備えた最高の価格/パフォーマンスを顧客が確実に得られるようにします。
 ビジェイ・カルマジ アマゾン ウェブ サービスのデータベース ソリューション アーキテクトです。 彼は AWS の顧客と協力してデータベース プロジェクトに関するガイダンスと技術支援を提供し、AWS を使用する際のソリューションの価値を向上させるのを支援しています。
ビジェイ・カルマジ アマゾン ウェブ サービスのデータベース ソリューション アーキテクトです。 彼は AWS の顧客と協力してデータベース プロジェクトに関するガイダンスと技術支援を提供し、AWS を使用する際のソリューションの価値を向上させるのを支援しています。
 BPヤウ AWS のシニア パートナー ソリューション アーキテクトです。 彼は、顧客が大規模にデータを処理するためのビッグデータ ソリューションを構築できるよう支援することに情熱を注いでいます。 AWS に入社する前は、Amazon.com Supply Chain Optimization Technologies が Oracle データ ウェアハウスを Amazon Redshift に移行し、AWS テクノロジーを使用して次世代のビッグデータ分析プラットフォームを構築するのを支援しました。
BPヤウ AWS のシニア パートナー ソリューション アーキテクトです。 彼は、顧客が大規模にデータを処理するためのビッグデータ ソリューションを構築できるよう支援することに情熱を注いでいます。 AWS に入社する前は、Amazon.com Supply Chain Optimization Technologies が Oracle データ ウェアハウスを Amazon Redshift に移行し、AWS テクノロジーを使用して次世代のビッグデータ分析プラットフォームを構築するのを支援しました。
 ジョティ・アガルワル シアトルを拠点とする Amazon Redshift チームのプロダクト マネージャーです。 彼女は過去 10 年間、データ ウェアハウス業界の複数の製品に取り組んできました。
ジョティ・アガルワル シアトルを拠点とする Amazon Redshift チームのプロダクト マネージャーです。 彼女は過去 10 年間、データ ウェアハウス業界の複数の製品に取り組んできました。
 アダム・レビン は、カリフォルニアを拠点とする Amazon Aurora チームのプロダクトマネージャーです。 彼は過去 10 年間、さまざまなクラウド データベース サービスに取り組んできました。
アダム・レビン は、カリフォルニアを拠点とする Amazon Aurora チームのプロダクトマネージャーです。 彼は過去 10 年間、さまざまなクラウド データベース サービスに取り組んできました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/getting-started-guide-for-near-real-time-operational-analytics-using-amazon-aurora-zero-etl-integration-with-amazon-redshift/

