企業は、機械学習 (ML) を使用して、広告の掲載、ドライバーの割り当て、製品の推奨、さらには製品やサービスの動的な価格設定など、ほぼリアルタイムの意思決定を行うようになっています。 ML モデルは、次のような一連の入力データを指定して予測を行います。 機能を使用、およびデータ サイエンティストは、これらの機能の設計と構築に時間の 60% 以上を簡単に費やしています。 さらに、非常に正確な予測は、時間の経過とともに急速に変化する特徴値へのタイムリーなアクセスに依存するため、可用性が高く正確なソリューションを構築する作業はさらに複雑になります。 たとえば、配車アプリのモデルは、空港からの配車に最適な料金を選択できますが、それは、過去 10 分間に受信した配車リクエストの数と、次の時間に着陸すると予測される乗客の数がわかっている場合に限られます。 10分。 コール センター アプリのルーティング モデルは、着信通話に対応できる最適なエージェントを選択できますが、顧客の最新の Web セッション クリックを認識している場合にのみ有効です。
ほぼリアルタイムの ML 予測のビジネス価値は計り知れませんが、それらを確実かつ安全に、優れたパフォーマンスで提供するために必要なアーキテクチャは複雑です。 ソリューションには、高スループットの更新とミリ秒単位での最新の特徴値の低レイテンシーの取得が必要ですが、これはほとんどのデータ サイエンティストが提供する準備ができていません。 その結果、一部の企業は数百万ドルを費やして、機能管理用の独自のインフラストラクチャを発明しています。 他の企業は、ML ベンダーがオンライン機能ストア向けのより包括的な既製のソリューションを提供するまで、ML アプリケーションをバッチ スコアリングなどのより単純なパターンに限定しています。
これらの課題に対処するために、 Amazon SageMaker フィーチャーストア ML 機能の完全に管理された中央リポジトリを提供し、独自のインフラストラクチャを構築および維持することなく、機能を安全に保存および取得することを容易にします。 Feature Store を使用すると、機能のグループを定義し、バッチ インジェストとストリーミング インジェストを使用し、XNUMX 桁のミリ秒のレイテンシで最新の機能値を取得して、非常に正確なオンライン予測を実現し、トレーニング用のポイント イン タイムの正しいデータセットを抽出できます。 これらのインフラストラクチャ機能を構築して維持する代わりに、データの増加に合わせてスケーリングし、チーム間で機能を共有できるフル マネージド サービスを利用して、データ サイエンティストが革新的なビジネス ユース ケースを目的とした優れた ML モデルの構築に専念できるようにします。 チームは堅牢な機能を一度提供すれば、さまざまなチームが構築する可能性のあるさまざまなモデルで何度も再利用できるようになりました。
この投稿では、ストリーミング機能エンジニアリングと Feature Store を組み合わせて、機械学習に基づく意思決定をほぼリアルタイムで行う方法の完全な例について説明します。 トランザクションのライブ ストリームから集計機能を更新し、低レイテンシの機能取得を使用して不正なトランザクションを検出するクレジット カード詐欺検出のユース ケースを示します。 私たちにアクセスして、自分で試してみてください GitHubレポ.
クレジットカード詐欺の使用例
盗まれたクレジットカード番号は、この機密データを保存している組織の以前のリークやハッキングからダークウェブでまとめて購入できます。 詐欺師はこれらのカードリストを購入し、カードがブロックされるまで、盗まれた番号で可能な限り多くの取引を行おうとします。 これらの詐欺攻撃は通常、短期間で発生します。攻撃中のトランザクションの速度はカード所有者の通常の支出パターンとは大幅に異なるため、これは過去のトランザクションで簡単に見つけることができます。
次の表は、4 つのクレジット カードからの一連のトランザクションを示しています。この場合、カード所有者は最初に本物の支出パターンを持ち、次に XNUMX 月 XNUMX 日から詐欺攻撃を受けます。
| cc_num | トランスタイム | 量 | 詐欺ラベル |
| ... 1248 | 01月14日50:01:XNUMX | 10.15 | 0 |
| ... 1248 | 02月12日14:31:XNUMX | 32.45 | 0 |
| ... 1248 | 02月16日23:12:XNUMX | 3.12 | 0 |
| ... 1248 | 04月02日12:10:XNUMX | 1.01 | 1 |
| ... 1248 | 04月02日13:34:XNUMX | 22.55 | 1 |
| ... 1248 | 04月02日14:05:XNUMX | 90.55 | 1 |
| ... 1248 | 04月02日15:10:XNUMX | 60.75 | 1 |
| ... 1248 | 04月13日30:55:XNUMX | 12.75 | 0 |
この投稿では、ML モデルをトレーニングして、特定の時間枠におけるそのカードからのトランザクション数や平均トランザクション額など、個々のカードの支出パターンを記述する機能をエンジニアリングすることにより、この種の動作を特定します。 このモデルは、支払いが完了する前に疑わしい取引を検出してブロックすることにより、POS での詐欺からカード所有者を保護します。 このモデルは、低レイテンシのリアルタイム コンテキストで予測を行い、進行中の不正攻撃に対応できるように、最新の特徴計算の受信に依存しています。 実際のシナリオでは、カード所有者の支出パターンに関連する機能は、モデルの機能セットの一部を形成するだけであり、加盟店、カード所有者、支払いに使用されたデバイス、およびその他の可能性のあるデータに関する情報を含めることができます。詐欺の検出に関連します。
私たちのユースケースは個々のカードの支出パターンのプロファイリングに依存しているため、トランザクションストリームでクレジットカードを識別できることが重要です。 公開されているほとんどの不正検出データセットはこの情報を提供しないため、Pythonを使用します ファーカー ライブラリを使用して、5 か月間の一連のトランザクションを生成します。 このデータセットには、5.4 の一意の (および偽の) クレジット カード番号にまたがる 10,000 万件のトランザクションが含まれており、実際のクレジット カード詐欺に合わせて意図的に不均衡になっています (トランザクションの 0.25% のみが不正です)。 カードごとに XNUMX 日あたりの取引回数と取引金額が異なります。 私たちを参照してください GitHubレポ のガイドをご参照ください。
ソリューションの概要
カード所有者の通常の支出パターンとは大幅に異なる最近のトランザクションのバーストに気付くことにより、不正検出モデルでクレジットカードトランザクションを分類する必要があります。 簡単そうに聞こえますが、どのように構築すればよいでしょうか。
次の図は、全体的なソリューション アーキテクチャを示しています。 これと同じパターンが、さまざまなストリーミング アグリゲーションのユース ケースでうまく機能すると考えています。 大まかに言うと、パターンには次の XNUMX つの部分が含まれます。
- フィーチャーストア – Feature Store を使用して、複数の機能グループに編成された機能値を使用して、高スループットの書き込みと安全な低レイテンシの読み取りを備えた機能のリポジトリを提供します。
- バッチ摂取 – バッチ取り込みは、ラベル付けされた過去のクレジット カード トランザクションを取得し、不正検出モデルのトレーニングに必要な集計機能と比率を作成します。 私たちは Amazon SageMaker処理 仕事と 組み込みのSparkコンテナー 週ごとの合計カウントとトランザクション量の平均を計算し、オンライン推論で使用するためにそれらを機能ストアに取り込みます。
- モデルのトレーニングと展開 – 私たちのソリューションのこの側面は簡単です。 を使用しております アマゾンセージメーカー を使用してモデルをトレーニングするには 組み込みのXGBoostアルゴリズム 履歴トランザクションから作成された集約された機能について。 モデルはSageMakerエンドポイントにデプロイされ、ライブトランザクションでの不正検出リクエストを処理します。
- ストリーミング取り込み - あん Amazon Kinesis データ分析 Apache Kafka トピックに基づく Apache Flink アプリケーション用 Apache Kafka (MSK) の Amazon マネージド ストリーミング (Amazon MSK) は、トランザクション ストリームから集約された特徴を計算し、 AWSラムダ 関数は、オンライン フィーチャ ストアを更新します。 ApacheFlink は、データ ストリームを処理するための一般的なフレームワークおよびエンジンです。
- ストリーミング予測 – 最後に、Lambda を使用してオンライン機能ストアから集計機能をプルし、一連のトランザクションに対して不正行為の予測を行います。 最新の特徴データを使用してトランザクション率を計算し、不正検出エンドポイントを呼び出します。
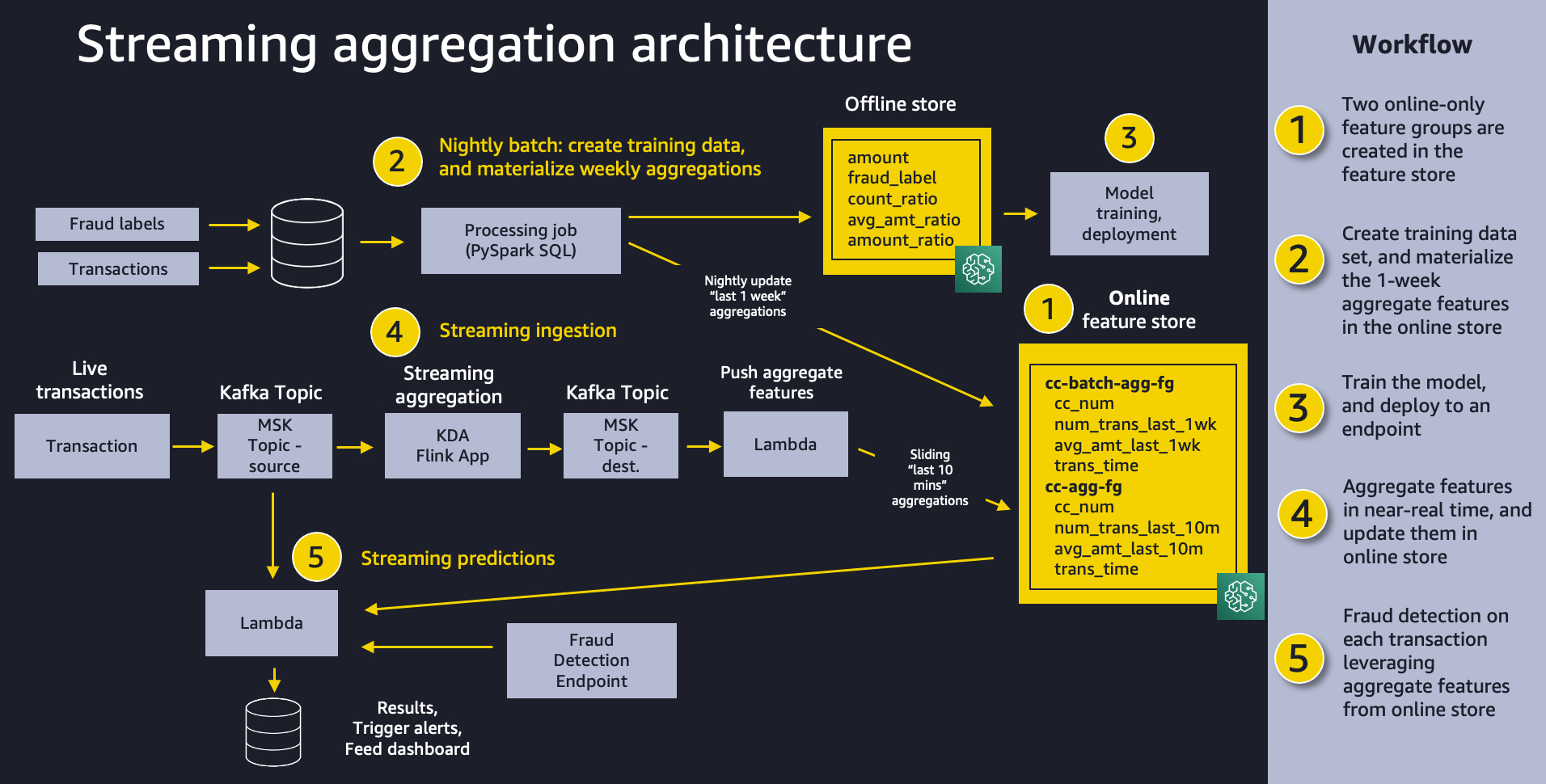
前提条件
私たちは提供します AWS CloudFormation テンプレートを使用して、このソリューションの前提条件となるリソースを作成します。 次の表に、さまざまなリージョンで使用できるスタックを示します。
次のセクションでは、ソリューションの各コンポーネントについて詳しく説明します。
フィーチャーストア
ML モデルは、計算のように単純な変換から、何時間もの計算時間と複雑なコーディングを必要とするマルチステップ パイプラインのように複雑な変換まで、さまざまなデータ ソースから得られる適切に設計された機能に依存しています。 Feature Store を使用すると、チームやモデル全体でこれらの機能を再利用できるため、データ サイエンティストの生産性が向上し、市場投入までの時間が短縮され、モデル入力の一貫性が保証されます。
Feature Store 内の各機能は、 機能グループ。 モデルに必要な機能グループを決定します。 それぞれが数十、数百、さらには数千の機能を持つことができます。 機能グループは個別に管理およびスケーリングされますが、多くの独立したMLモデルとユースケースを担当するデータサイエンティストのチーム全体で検索と発見に利用できます。
MLモデルでは、多くの場合、複数の機能グループの機能が必要です。 機能グループの重要な側面は、ダウンストリームのトレーニングまたは推論のために、その機能値を更新または具体化する必要がある頻度です。 一部の機能は毎時、毎晩、または毎週更新し、機能のサブセットをほぼリアルタイムで機能ストアにストリーミングする必要があります。 すべての機能の更新をストリーミングすると、不必要に複雑になり、外れ値を削除する機会が与えられないため、データ配信の品質がさらに低下する可能性があります。
このユースケースでは、という機能グループを作成します cc-agg-batch-fg バッチで更新された集約されたクレジットカード機能の場合、 cc-agg-fg ストリーミング機能用。
cc-agg-batch-fg 機能グループは毎晩更新され、1 週間の時間枠を振り返る集計機能を提供します。 ストリーミング トランザクションで 1 週間の集計を再計算しても意味のあるシグナルは得られず、リソースの無駄遣いになります。
逆に、私たちの cc-agg-fg 機能グループは、最新のトランザクション数と平均トランザクション額を 10 分間のウィンドウで振り返って提供するため、ストリーミング方式で更新する必要があります。 ストリーミング アグリゲーションがなければ、一連の急速な購入という典型的な詐欺攻撃パターンを特定できませんでした。
毎晩再計算される機能を分離することで、ストリーミング機能の取り込みスループットを向上させることができます。 分離により、各グループの取り込みを個別に最適化できます。 ユース ケースを設計するときは、多数の機能グループからの機能を必要とするモデルでは、リアルタイム予測ワークフローに過度の遅延が追加されないように、機能ストアから複数の取得を並行して行う必要がある場合があることに注意してください。
このユース ケースの機能グループを次の表に示します。
| cc-agg-fg | cc-agg-バッチ-fg |
| cc_num (レコード ID) | cc_num (レコード ID) |
| トランスタイム | トランスタイム |
| num_trans_last_10m | num_trans_last_1w |
| avg_amt_last_10m | avg_amt_last_1w |
各機能グループには、レコード識別子(この投稿ではクレジットカード番号)として使用されるXNUMXつの機能が必要です。 レコード識別子は機能グループの主キーとして機能し、機能グループ間の高速ルックアップと結合を可能にします。 イベント時間機能も必要です。これにより、機能ストアは時間の経過に伴う機能値の履歴を追跡できます。 これは、特定の時点での機能の状態を振り返るときに重要になります。
各機能グループでは、一意のクレジットカードごとのトランザクション数とその平均トランザクション量を追跡します。 10つのグループの唯一の違いは、集計に使用される時間枠です。 ストリーミング集約には1分のウィンドウを使用し、バッチ集約にはXNUMX週間のウィンドウを使用します。
Feature Store を使用すると、オフラインのみ、オンラインのみ、またはオンラインとオフラインの両方の機能グループを柔軟に作成できます。 オンライン ストアは、高スループットの書き込みと特徴値の低レイテンシーの取得を提供します。これは、オンライン推論に最適です。 を利用したオフラインストアを提供 Amazon シンプル ストレージ サービス (Amazon S3) により、機能グループごとに分割された機能値の完全な履歴を備えた高度にスケーラブルなリポジトリが企業に提供されます。 オフライン ストアは、トレーニングおよびバッチ スコアリングのユース ケースに最適です。
機能グループがオンライン ストアとオフライン ストアの両方を提供できるようにすると、SageMaker は自動的に機能値をオフライン ストアに同期し、最新の値を継続的に追加して、時間の経過に伴う値の完全な履歴を提供します。 オンラインとオフラインの両方の機能グループのもう XNUMX つの利点は、トレーニングと推論の偏りの問題を回避できることです。 SageMaker を使用すると、トレーニングと推論の両方に同じ変換された特徴値をフィードできるため、一貫性を確保してより正確な予測を推進できます。 私たちの投稿では、オンライン機能ストリーミングのデモを行うことに重点を置いているため、オンラインのみの機能グループを実装しました。
バッチ摂取
バッチ機能を具体化するために、毎晩 SageMaker Processing ジョブとして実行される機能パイプラインを作成します。 次の図に示すように、このジョブには 1 つの責任があります。モデルをトレーニングするためのデータセットを作成することと、XNUMX 週間のフィーチャを集約するための最新の値をバッチ フィーチャ グループに入力することです。

トレーニングセットで使用される各履歴トランザクションは、トランザクションに関係する特定のクレジットカードの集約された機能で強化されています。 1つの別々のスライド時間ウィンドウを振り返ります。10週間前とその前のXNUMX分です。 モデルのトレーニングに使用される実際の機能には、これらの集計値の次の比率が含まれます。
- amt_ratio1 =
avg_amt_last_10m / avg_amt_last_1w - amt_ratio2 =
transaction_amount / avg_amt_last_1w - count_ratio =
num_trans_last_10m / num_trans_last_1w
たとえば、 count_ratio 過去 10 分間のトランザクション数を先週のトランザクション数で割った値です。
私たちの ML モデルは、生のカウントやトランザクションの金額に頼るのではなく、これらの比率から通常のアクティビティと不正なアクティビティのパターンを学習できます。 異なるカードの支出パターンは大きく異なるため、正規化された比率は、集計された金額自体よりも優れたシグナルをモデルに提供します。
バッチ ジョブがなぜ 10 分間のルックバックで特徴量を計算しているのか疑問に思われるかもしれません。 それはオンライン推論にのみ関連するものではありませんか? 正確なトレーニング データセットを作成するには、履歴トランザクションの 10 分間のウィンドウが必要です。 これは、オンライン推論をサポートするためにほぼリアルタイムで使用される 10 分間のストリーミング ウィンドウとの一貫性を確保するために重要です。
処理ジョブから得られたトレーニングデータセットは、モデルトレーニング用のCSVとして直接保存することも、他のモデルや他のデータサイエンスチームが他のさまざまな問題に対処するために使用できるオフライン機能グループに一括取り込みすることもできます。ユースケース。 たとえば、次のような機能グループを作成して設定できます。 cc-transactions-fg。 次に、トレーニングジョブは、特定のモデルのニーズに基づいて特定のトレーニングデータセットを取得し、特定の日付範囲と対象の機能のサブセットを選択できます。 このアプローチにより、複数のチームが機能グループを再利用し、維持する機能パイプラインを減らすことができるため、時間の経過とともに大幅なコスト削減と生産性の向上につながります。 このサンプルノートブック データ サイエンティストがトレーニング データセットを抽出できる中央リポジトリとして Feature Store を使用するパターンを示します。
トレーニング データセットの作成に加えて、 PutRecord 1 週間のフィーチャ アグリゲーションを毎晩オンライン フィーチャ ストアに配置する API。 次のコードは、レコード識別子やイベント時間などの特定の機能値を指定して、オンライン機能グループにレコードを配置する方法を示しています。
ML エンジニアは、モデル トレーニング用にデータ サイエンティストが作成した元のコードに基づいて、オンライン機能用の別バージョンの機能エンジニアリング コードを構築することがよくあります。 これにより、目的のパフォーマンスを実現できますが、追加の開発ステップであり、トレーニングと推論の偏りが発生する可能性が高くなります。 このユース ケースでは、集計に SQL を使用することで、データ サイエンティストがバッチとストリーミングの両方に同じコードを提供できるようにする方法を示します。
ストリーミング取り込み
Feature Store は、事前に計算された機能を 10 桁のミリ秒で取得できるほか、ストリーミング インジェストを必要とするソリューションでも効果的な役割を果たすことができます。 私たちのユースケースは両方を示しています。 週ごとのルックバックは、事前に計算された機能グループとして処理され、前に示したように夜間に具体化されます。 次に、XNUMX 分間のウィンドウでオンザフライで集約された機能を計算し、後でオンラインで推論するためにそれらを機能ストアに取り込む方法について詳しく見ていきましょう。
このユース ケースでは、ソース MSK トピックにライブ クレジット カード トランザクションを取り込み、Kinesis Data Analytics for Apache Flink アプリケーションを使用して宛先 MSK トピックに集約機能を作成します。 アプリケーションは、 アパッチ フリンク SQL. Flink SQL を使用すると、標準 SQL を使用してストリーミング アプリケーションを簡単に開発できます。 ANSI-SQL 2011 に準拠したままデータベースや SQL に似たシステムを使用したことがあれば、Flink を学ぶのは簡単です。 SQL とは別に、Java および Scala アプリケーションを構築できます。 Amazon Kinesis データ分析 Apache Flink に基づくオープンソース ライブラリを使用します。 次に、Lambda 関数を使用して送信先の MSK トピックを読み取り、集約機能を SageMaker 機能グループに取り込み、推論します。 Flink の SQL API を使用して Apache Flink アプリケーションを作成するのは簡単です。 Flink SQL を使用して、ストリーミング データをソース MSK トピックに集約し、それを宛先 MSK トピックに保存します。
10 分間のウィンドウを振り返って集計カウントと平均金額を生成するために、入力トピックで次の Flink SQL クエリを使用し、結果を宛先トピックにパイプします。
| cc_num | 量 | 日付時刻 | num_trans_last_10m | avg_amt_last_10m |
| ... 1248 | 50.00 | 01,22月01日00時XNUMX分XNUMX秒 | 1 | 74.99 |
| ... 9843 | 99.50 | 01,22月02日30時XNUMX分XNUMX秒 | 1 | 99.50 |
| ... 7403 | 100.00 | 01,22月03日48時XNUMX分XNUMX秒 | 1 | 100.00 |
| ... 1248 | 200.00 | 01,22月03日59時XNUMX分XNUMX秒 | 2 | 125.00 |
| ... 0732 | 26.99 | Nov01、22:04:15 | 1 | 26.99 |
| ... 1248 | 50.00 | 01,22月04日28時XNUMX分XNUMX秒 | 3 | 100.00 |
| ... 1248 | 500.00 | 01,22月05日05時XNUMX分XNUMX秒 | 4 | 200.00 |
この例では、最後の行に、10で終わるクレジットカードからの過去1248分間の200.00つのトランザクションのカウントがあり、対応する平均トランザクション量が$ XNUMXであることに注意してください。 SQLクエリは、トレーニングデータセットの作成を促進するために使用されるクエリと一致しており、トレーニングと推論の偏りを回避するのに役立ちます。
次の図に示すように、トランザクションが Kinesis Data Analytics for Apache Flink 集計アプリにストリーミングされると、アプリは集計結果を Lambda 関数に送信します。 Lambda 関数はこれらの機能を取得し、 cc-agg-fg 機能グループ。

PutRecord API への単純な呼び出しを使用して、最新の機能値を Lambda から機能ストアに送信します。 以下は、集約機能を格納するための Python コードのコア部分です。
イベント時間として現在の時間を含む、名前付きの値のペアのリストとしてレコードを準備します。 Feature Store API により、この新しいレコードは、機能グループの作成時に特定したスキーマに従っていることが保証されます。 この主キーのレコードが既に存在する場合は、オンライン ストアで上書きされます。
ストリーミング予測
ストリーミングインジェストにより、機能ストアを最新の機能値で最新の状態に保つことができたので、不正予測を行う方法を見てみましょう。
ソース MSK トピックをトリガーとして使用する 1 つ目の Lambda 関数を作成します。 新しいトランザクション イベントごとに、Lambda 関数は最初に Feature Store からバッチおよびストリーミング機能を取得します。 クレジット カードの動作の異常を検出するために、モデルは最近の購入金額または購入頻度のスパイクを探します。 Lambda 関数は、10 週間の集計と XNUMX 分の集計の間の単純な比率を計算します。 次に、次の図に示すように、これらの比率を使用して SageMaker モデルエンドポイントを呼び出し、不正予測を行います。

次のコードを使用して、SageMakerモデルエンドポイントを呼び出す前に、フィーチャーストアからオンデマンドでフィーチャー値を取得します。
SageMaker は、複数の特徴レコードの取得もサポートしています シングルコール、それらが異なる機能グループのものであっても。
最後に、モデル入力特徴ベクトルを組み立てて、モデル エンドポイントを呼び出して、特定のクレジット カード トランザクションが不正かどうかを予測します。 SageMaker は、異なる機能グループからのものであっても、XNUMX 回の呼び出しで複数の機能レコードを取得することもサポートしています。
sagemaker_runtime = boto3.client(service_name='runtime.sagemaker')
request_body = ','.join(features)
response = sagemaker_runtime.invoke_endpoint( EndpointName=ENDPOINT_NAME, ContentType='text/csv', Body=request_body)
probability = json.loads(response['Body'].read().decode('utf-8'))この例では、特定のトランザクションが不正である確率が 98% でモデルが返され、そのクレジット カードでの最新の 10 分間のトランザクションに基づいて、ほぼリアルタイムで集計された入力機能を使用することができました。
エンドツーエンドのソリューションをテストする
ソリューションの完全なエンド ツー エンド ワークフローを示すために、クレジット カード トランザクションを MSK ソース トピックに送信するだけです。 自動化された Apache Flink アグリゲーション用の Kinesis Data Analytics がそこから引き継ぎ、Feature Store のトランザクション数と金額のほぼリアルタイムのビューを維持し、スライドする 10 分間のルックバック ウィンドウを使用します。 これらの機能は、機能ストアに既にバッチで取り込まれた 1 週間の集計機能と組み合わされ、各トランザクションで不正行為の予測を行うことができます。
XNUMX つの異なるクレジット カードから XNUMX つのトランザクションを送信します。 次に、多くの連続したトランザクションを数秒で送信することにより、XNUMX 番目のクレジット カードに対する詐欺攻撃をシミュレートします。 次のスクリーンショットは、Lambda 関数からの出力を示しています。 予想通り、最初の XNUMX つの XNUMX 回限りのトランザクションは次のように予測されます。 NOT FRAUD. 10 件の不正取引のうち、最初の取引は次のように予測されます。 NOT FRAUD、残りはすべて正しく次のように識別されます FRAUD. 集計機能が最新に保たれ、より正確な予測を促進する方法に注目してください。

まとめ
ストリーミング アグリゲーションと低レイテンシの推論を必要とする重要な運用ワークフローのソリューション アーキテクチャにおいて、Feature Store が重要な役割を果たす方法を示しました。 エンタープライズ対応のフィーチャ ストアが配置されているため、バッチ インジェストとストリーミング インジェストの両方を使用してフィーチャ グループにフィードし、オンデマンドでフィーチャ値にアクセスして、オンライン予測を実行して重要なビジネス価値を得ることができます。 ML 機能は、データ サイエンティストの多くのチームと数千の ML モデルで大規模に共有できるようになり、データの一貫性、モデルの精度、およびデータ サイエンティストの生産性が向上します。 Feature Store は現在利用可能で、これを試すことができます 例全体。 ご意見をお聞かせください。
に貢献してくれたすべての人に感謝します 前のブログ投稿 同様のアーキテクチャを持つ: Paul Hargis、James Leoni、Arunprasath Shankar。
著者について
 マークロイ AWS のプリンシパル機械学習アーキテクトであり、顧客が AI/ML ソリューションを設計および構築するのを支援しています。 Mark の仕事は幅広い ML ユース ケースをカバーしており、主な関心は機能ストア、コンピューター ビジョン、ディープ ラーニング、および企業全体での ML のスケーリングです。 彼は、保険、金融サービス、メディアとエンターテイメント、ヘルスケア、公益事業、製造など、多くの業界の企業を支援してきました。 Mark は、ML Specialty Certification を含む 25 つの AWS 認定を保持しています。 AWS に入社する前は、Mark は 19 年以上にわたってアーキテクト、開発者、テクノロジー リーダーを務めており、そのうち XNUMX 年間は金融サービスに携わっていました。
マークロイ AWS のプリンシパル機械学習アーキテクトであり、顧客が AI/ML ソリューションを設計および構築するのを支援しています。 Mark の仕事は幅広い ML ユース ケースをカバーしており、主な関心は機能ストア、コンピューター ビジョン、ディープ ラーニング、および企業全体での ML のスケーリングです。 彼は、保険、金融サービス、メディアとエンターテイメント、ヘルスケア、公益事業、製造など、多くの業界の企業を支援してきました。 Mark は、ML Specialty Certification を含む 25 つの AWS 認定を保持しています。 AWS に入社する前は、Mark は 19 年以上にわたってアーキテクト、開発者、テクノロジー リーダーを務めており、そのうち XNUMX 年間は金融サービスに携わっていました。
 ラジ・ラマスブ シニア アナリティクス スペシャリスト ソリューション アーキテクトであり、アマゾン ウェブ サービスを使用したビッグデータとアナリティクス、および AI/ML に焦点を当てています。 彼は、顧客が AWS で高度にスケーラブルでパフォーマンスが高く、安全なクラウドベースのソリューションを設計および構築するのを支援しています。 Raj は、AWS に参加する前の 18 年以上にわたり、データ エンジニアリング、ビッグ データ分析、ビジネス インテリジェンス、およびデータ サイエンス ソリューションの構築において、技術的な専門知識とリーダーシップを提供してきました。 彼は、ヘルスケア、医療機器、ライフ サイエンス、小売、資産管理、自動車保険、住宅用 REIT、農業、権原保険、サプライ チェーン、ドキュメント管理、不動産など、さまざまな業種の顧客を支援してきました。
ラジ・ラマスブ シニア アナリティクス スペシャリスト ソリューション アーキテクトであり、アマゾン ウェブ サービスを使用したビッグデータとアナリティクス、および AI/ML に焦点を当てています。 彼は、顧客が AWS で高度にスケーラブルでパフォーマンスが高く、安全なクラウドベースのソリューションを設計および構築するのを支援しています。 Raj は、AWS に参加する前の 18 年以上にわたり、データ エンジニアリング、ビッグ データ分析、ビジネス インテリジェンス、およびデータ サイエンス ソリューションの構築において、技術的な専門知識とリーダーシップを提供してきました。 彼は、ヘルスケア、医療機器、ライフ サイエンス、小売、資産管理、自動車保険、住宅用 REIT、農業、権原保険、サプライ チェーン、ドキュメント管理、不動産など、さまざまな業種の顧客を支援してきました。
 プラバカール チャンドラセカラン AWS エンタープライズ サポートのシニア テクニカル アカウント マネージャーです。 Prabhakar は、顧客がクラウド上で最先端の AI/ML ソリューションを構築するのを楽しんでいます。 また、企業のお客様と協力して積極的なガイダンスと運用支援を提供し、AWS を使用する際のソリューションの価値を向上させます。 Prabhakar は 20 つの AWS とその他の XNUMX つのプロフェッショナル認定を取得しています。 XNUMX 年以上の専門的経験を持つ Prabhakar は、AWS に参加する前は金融サービス分野のデータ エンジニアおよびプログラム リーダーでした。
プラバカール チャンドラセカラン AWS エンタープライズ サポートのシニア テクニカル アカウント マネージャーです。 Prabhakar は、顧客がクラウド上で最先端の AI/ML ソリューションを構築するのを楽しんでいます。 また、企業のお客様と協力して積極的なガイダンスと運用支援を提供し、AWS を使用する際のソリューションの価値を向上させます。 Prabhakar は 20 つの AWS とその他の XNUMX つのプロフェッショナル認定を取得しています。 XNUMX 年以上の専門的経験を持つ Prabhakar は、AWS に参加する前は金融サービス分野のデータ エンジニアおよびプログラム リーダーでした。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/use-streaming-ingestion-with-amazon-sagemaker-feature-store-and-amazon-msk-to-make-ml-backed-decisions-in-near-real-time/

