MySQL用のAmazonリレーショナルデータベースサービス(Amazon RDS) ゼロETL統合 Amazonレッドシフト ました 発表の Amazon RDS for MySQL バージョン 2023 以降は、AWS re:Invent 8.0.28 でプレビュー中です。この投稿では、この機能を使用してほぼリアルタイムの運用分析を開始する方法について段階的なガイダンスを提供します。この投稿は、 から始まったゼロ ETL シリーズの継続です。 Amazon Aurora と Amazon Redshift のゼロ ETL 統合を使用した、ほぼリアルタイムの運用分析のためのスタートガイド.
課題
現在、さまざまな業界の顧客が、パーソナライゼーション戦略、不正行為検出、在庫監視などのほぼリアルタイムの分析ユースケースを実装することで、データを競争上の優位性のために活用し、収益と顧客エンゲージメントを向上させることを目指しています。これらのユースケースの運用データを分析するには、大きく 2 つのアプローチがあります。
- 運用データベース内のデータをインプレースで分析します (リードレプリカ、フェデレーテッド クエリ、分析アクセラレータなど)。
- データ ウェアハウスなどのユースケース固有のクエリを実行するために最適化されたデータ ストアにデータを移動します。
ゼロ ETL 統合は、後者のアプローチを簡素化することに重点を置いています。
抽出、変換、ロード (ETL) プロセスは、運用データベースから分析データ ウェアハウスにデータを移動する一般的なパターンです。 ELT では、抽出されたデータが最初にターゲットにそのままロードされ、その後変換されます。 ETL および ELT パイプラインは構築に費用がかかり、管理が複雑になる場合があります。複数のタッチポイントがある場合、ETL および ELT パイプラインで断続的なエラーが発生すると長い遅延が発生し、データ ウェアハウス アプリケーションに古いデータまたは欠落したデータが残り、さらにビジネス チャンスの損失につながる可能性があります。
あるいは、データをインプレースで分析するソリューションは、単一データベースでのクエリを高速化する場合には効果的かもしれませんが、そのようなソリューションでは、統合分析を実行する必要がある顧客のために複数の運用データベースからデータを集約することができません。
ゼロETL
データが 1 つのデータベースにサイロ化され、ユーザーが統合分析とパフォーマンスの間でトレードオフを行う必要がある従来のシステムとは異なり、データ エンジニアは複数の RDS for MySQL データベースから単一の Redshift データ ウェアハウスにデータを複製して、全体的な洞察を得ることができるようになりました。多くのアプリケーションまたはパーティション。トランザクションデータベースの更新は自動的かつ継続的に Amazon Redshift に伝達されるため、データエンジニアはほぼリアルタイムで最新の情報を入手できます。管理するインフラストラクチャはなく、統合はデータ量に基づいて自動的にスケールアップおよびスケールダウンできます。
AWS では、 ゼロETLビジョン 命に。現在、ゼロ ETL 統合では次のソースがサポートされています。
Amazon Redshift のゼロ ETL 統合を作成する場合、基盤となるソース データベースとターゲット Redshift データベースの使用料を引き続き支払います。参照する ETL 統合コストゼロ (プレビュー) 詳細については、。
Amazon Redshift とのゼロ ETL 統合により、統合によってソース データベースからターゲット データ ウェアハウスにデータがレプリケートされます。データは数秒以内に Amazon Redshift で利用可能になり、Amazon Redshift の分析機能や、データ共有、ワークロード最適化オートノミクス、同時実行スケーリング、機械学習などの機能を使用できるようになります。 Amazon RDS でトランザクション処理を続行することも、または アマゾンオーロラ 同時に、レポートやダッシュボードなどの分析ワークロードに Amazon Redshift を使用します。
次の図は、このアーキテクチャを示しています。
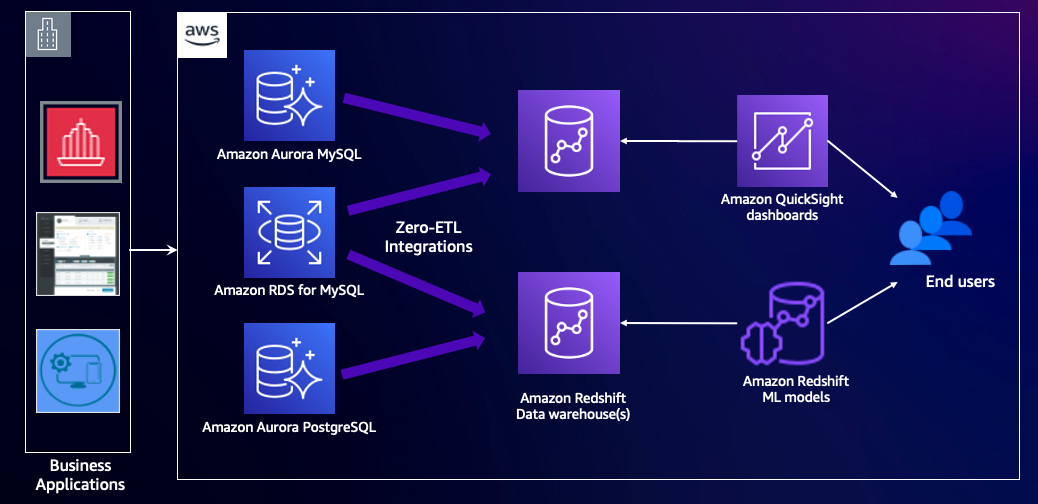
ソリューションの概要
のは、考えてみましょう チケット、ユーザーがスポーツ イベント、ショー、コンサートのチケットをオンラインで売買する架空の Web サイト。このウェブサイトのトランザクションデータは、Amazon RDS for MySQL 8.0.28 (またはそれ以降のバージョン) データベースにロードされます。同社のビジネス アナリストは、時間の経過に伴うチケットの動き、販売者の成功率、最も売れているイベント、会場、シーズンを特定するための指標を生成したいと考えています。彼らは、ゼロ ETL 統合を使用して、これらのメトリクスをほぼリアルタイムで取得したいと考えています。
統合は、Amazon RDS for MySQL (ソース) と Amazon Redshift (宛先) の間でセットアップされます。ソースからのトランザクション データは、分析クエリを処理する宛先でほぼリアルタイムで更新されます。
Amazon Redshift には、サーバーレス オプションまたは暗号化された RA3 クラスターのいずれかを使用できます。この投稿では、プロビジョニングされた RDS データベースと Redshift プロビジョニングされたデータ ウェアハウスを使用します。
次の図は、アーキテクチャの概要を示しています。
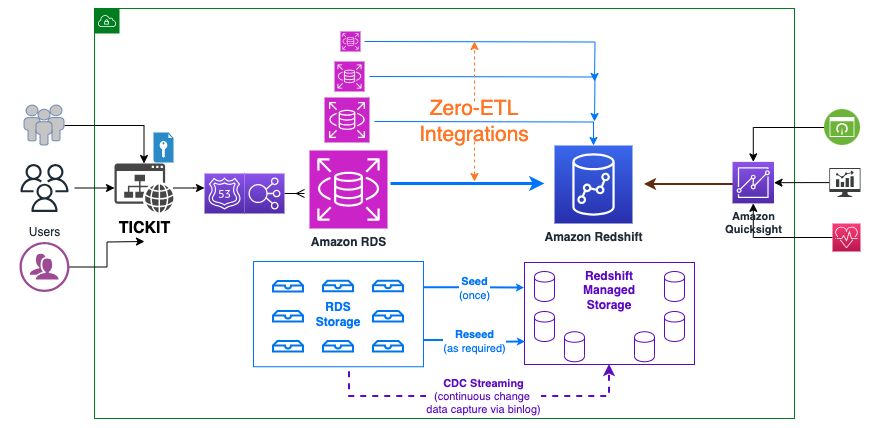
ゼロ ETL 統合を設定するために必要な手順は次のとおりです。これらの手順はゼロ ETL ウィザードによって自動的に実行できますが、ウィザードで Amazon RDS または Amazon Redshift の設定を変更した場合は再起動が必要になります。まだ構成されていない場合は、これらの手順を手動で実行し、都合の良いときに再起動を実行できます。完全なスタートガイドについては、以下を参照してください。 Amazon Redshift との Amazon RDS ゼロ ETL 統合の使用 (プレビュー) & ゼロ ETL 統合の使用.
- カスタム DB パラメータ グループを使用して RDS for MySQL ソースを構成します。
- 大文字と小文字を区別する識別子を有効にするように Redshift クラスターを構成します。
- 必要な権限を設定します。
- ゼロ ETL 統合を作成します。
- Amazon Redshift の統合からデータベースを作成します。
カスタマイズされた DB パラメータ グループを使用して RDS for MySQL ソースを構成する
RDS for MySQL データベースを作成するには、次の手順を実行します。
- Amazon RDS コンソールで、という名前の DB パラメータ グループを作成します。
zero-etl-custom-pg.
Zero-ETL 統合は、MySQL データベースによって生成されたバイナリ ログ (binlog) を使用して機能します。 Amazon RDS for MySQL でバイナリログを有効にするには、特定のパラメータのセットを有効にする必要があります。
- 次の binlog クラスター パラメーター設定を設定します。
binlog_format = ROWbinlog_row_image = FULLbinlog_checksum = NONE
さらに、次のことを確認してください。 binlog_row_value_options パラメータが設定されていません PARTIAL_JSON。デフォルトでは、このパラメータは設定されていません。
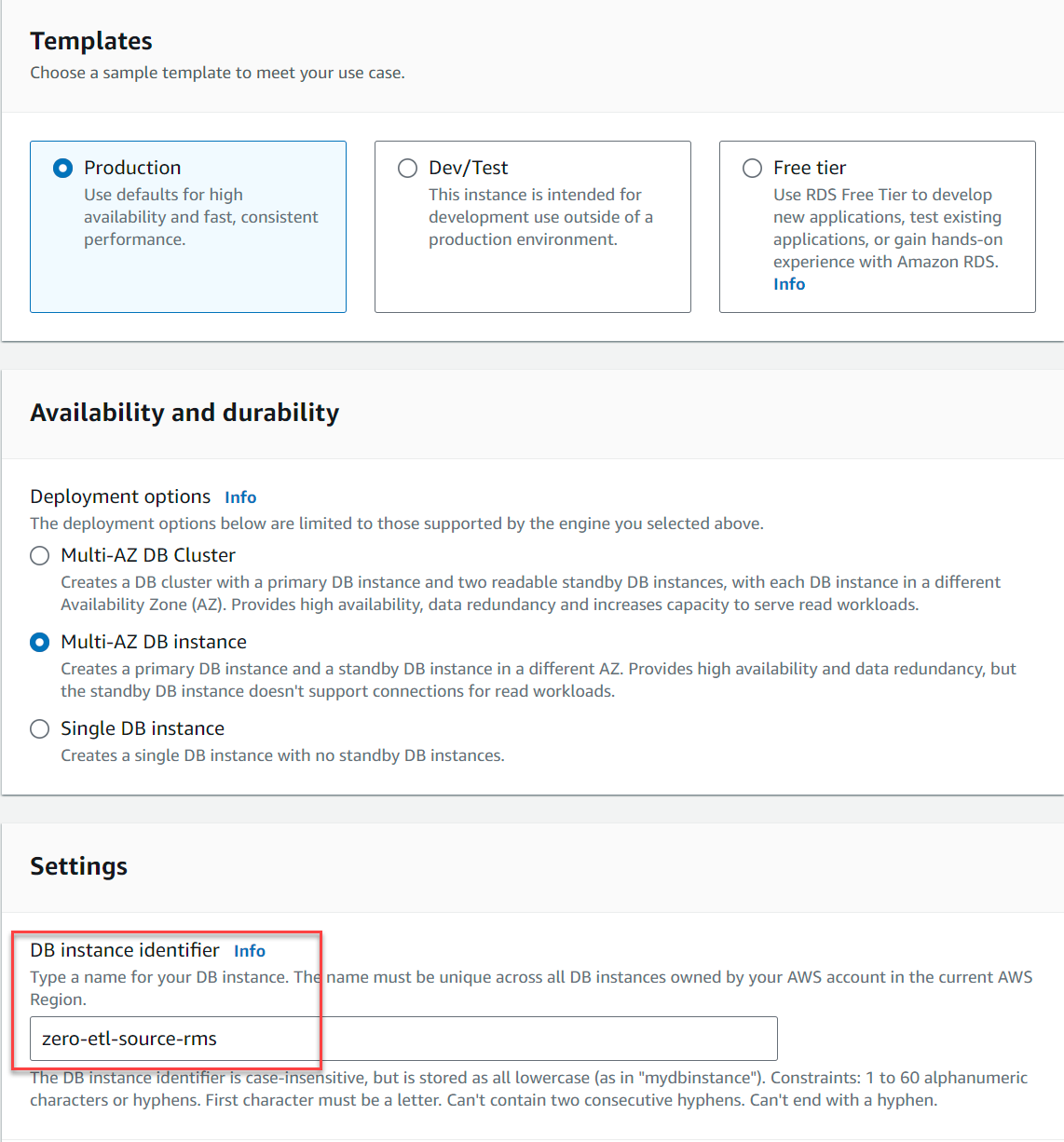
- 選択する データベース ナビゲーションペインで、を選択します データベースを作成する.
- エンジンバージョン、選択する MySQLの8.0.28 (以上)。

- テンプレート選択 生産.
- 可用性と耐久性、いずれかを選択する マルチ AZ DB インスタンス or 単一の DB インスタンス (この記事の執筆時点では、Multi-AZ DB クラスターはサポートされていません)。
- DBインスタンス識別子、 入る
zero-etl-source-rms.
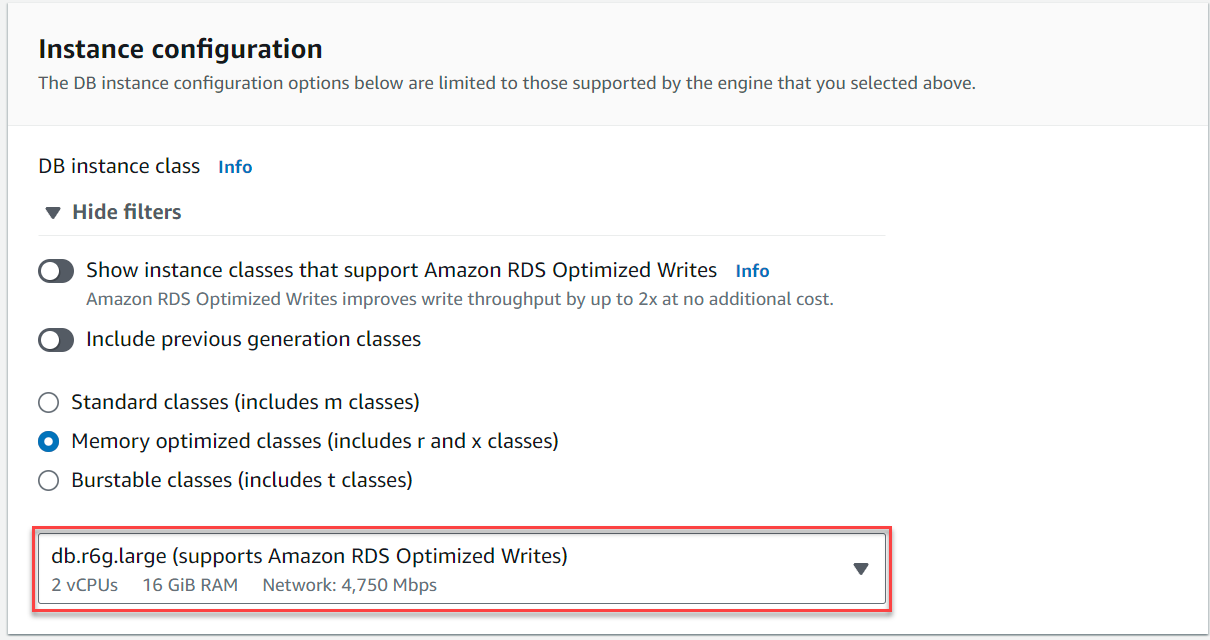
- インスタンス構成選択 メモリ最適化クラス インスタンスを選択します
db.r6g.largeTICKIT の使用例にはこれで十分です。
- 追加の構成、用 DB クラスターパラメータグループ、前に作成したパラメータ グループを選択します (
zero-etl-custom-pg).
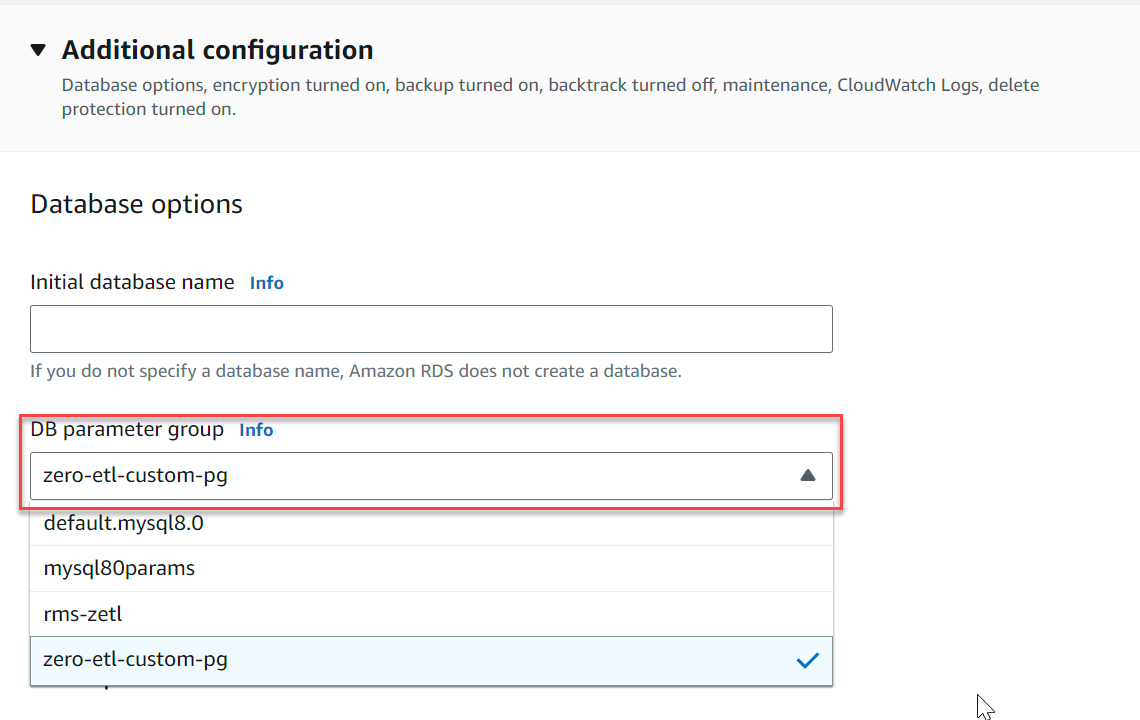
- 選択する データベースを作成する.
数分以内に、ゼロ ETL 統合のソースとして RDS for MySQL データベースが起動されるはずです。
Redshift の宛先を構成する
ソース DB クラスターを作成した後、Amazon Redshift でターゲット データ ウェアハウスを作成して設定する必要があります。データ ウェアハウスは次の要件を満たす必要があります。
- RA3 ノード タイプの使用 (
ra3.16xlarge,ra3.4xlargeまたはra3.xlplus)または AmazonRedshiftサーバーレス - 暗号化 (プロビジョニングされたクラスターを使用している場合)
このユースケースでは、次の手順を実行して Redshift クラスターを作成します。
- Amazon Redshiftコンソールで、 構成 それから、 ワークロード管理.
- パラメータグループセクションで、 創造する.
- という名前の新しいパラメータ グループを作成します。
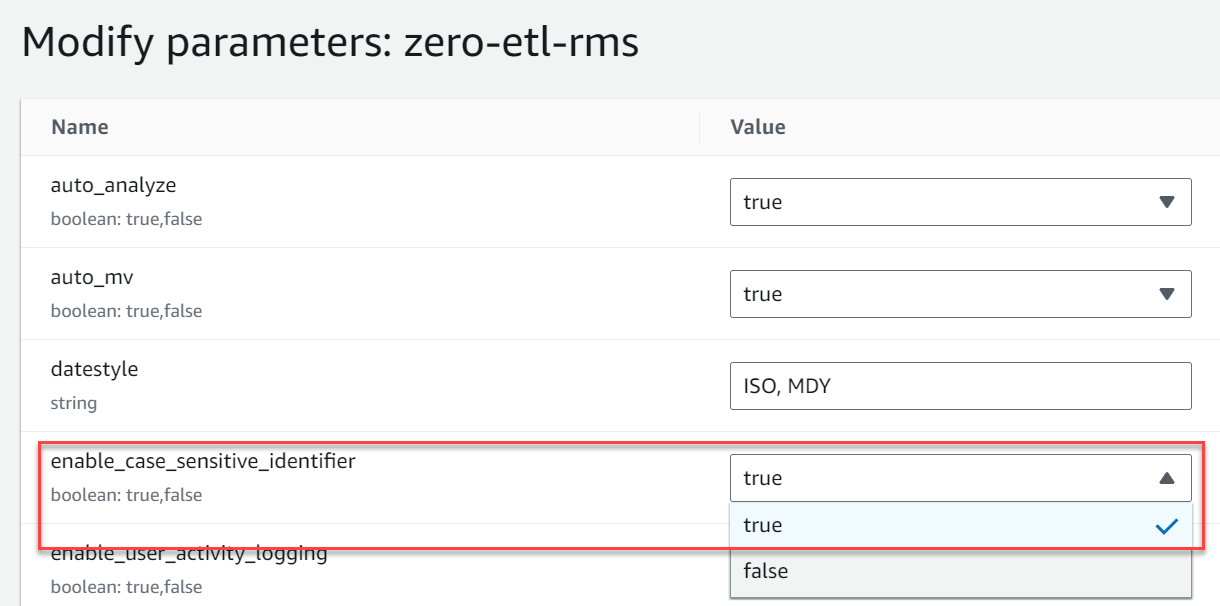
zero-etl-rms. - 選択する パラメータを編集する の値を変更します
enable_case_sensitive_identifier〜へTrue. - 選択する Save.
使用することもできます AWSコマンドラインインターフェイス (AWS CLI) コマンド アップデートワークグループ Redshiftサーバーレスの場合:
- 選択する プロビジョニング済みクラスター ダッシュボード.
コンソール ウィンドウの上部に、 新しい Amazon Redshift 機能をプレビューで試す バナー。
- 選択する プレビュー クラスターの作成.

- プレビュー トラック、選びました
preview_2023. - ノードタイプ、サポートされているノード タイプのいずれかを選択します (この投稿では、
ra3.xlplus).
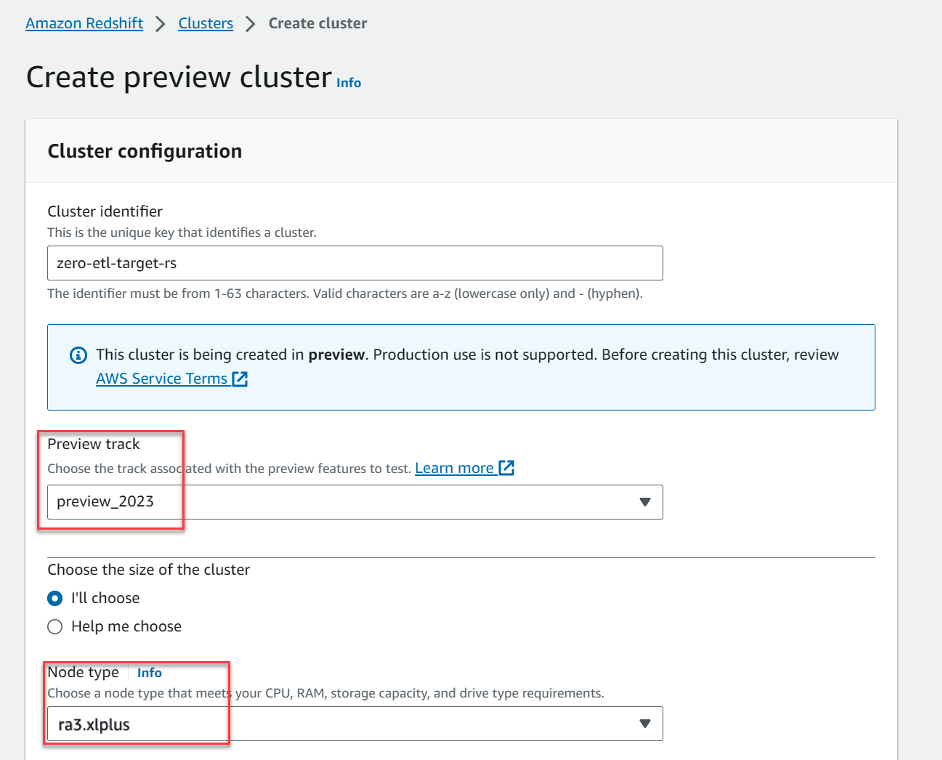
- 追加の構成、展開する データベース構成.
- パラメータグループ、選択する
zero-etl-rms. - Encryption選択 AWS キー管理サービスを使用する.
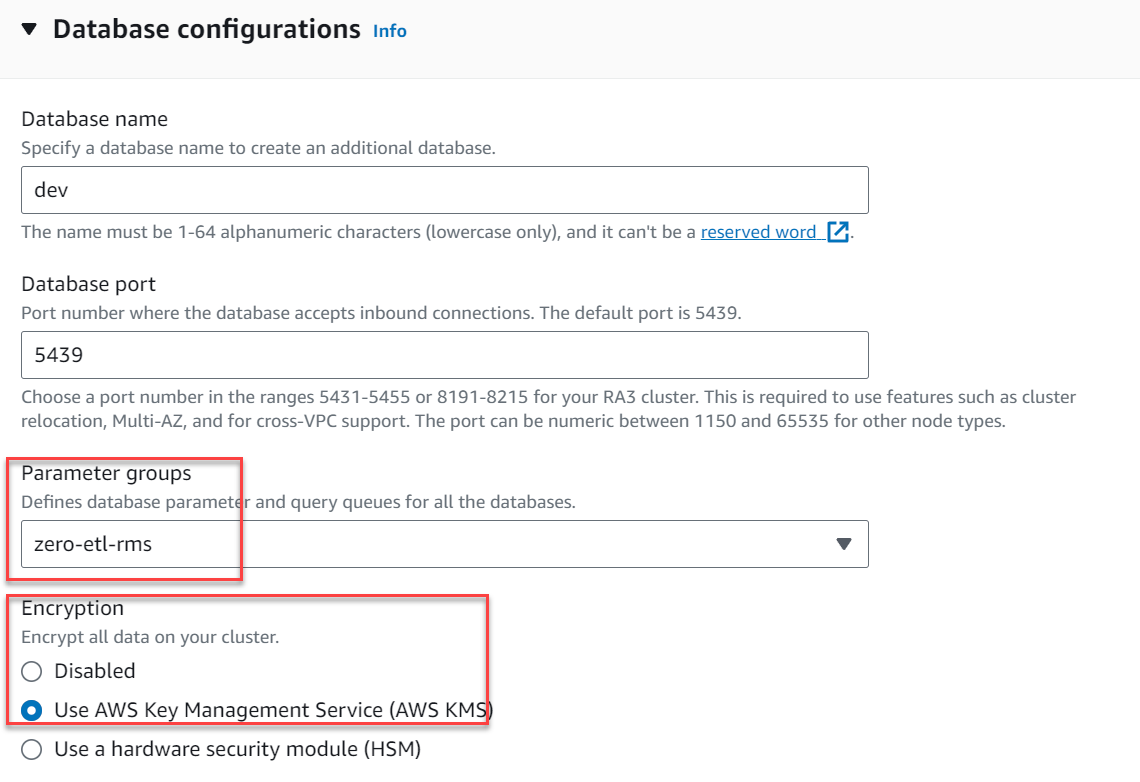
- 選択する クラスターを作成する.
クラスターは次のようになります。 利用できます 数分で。

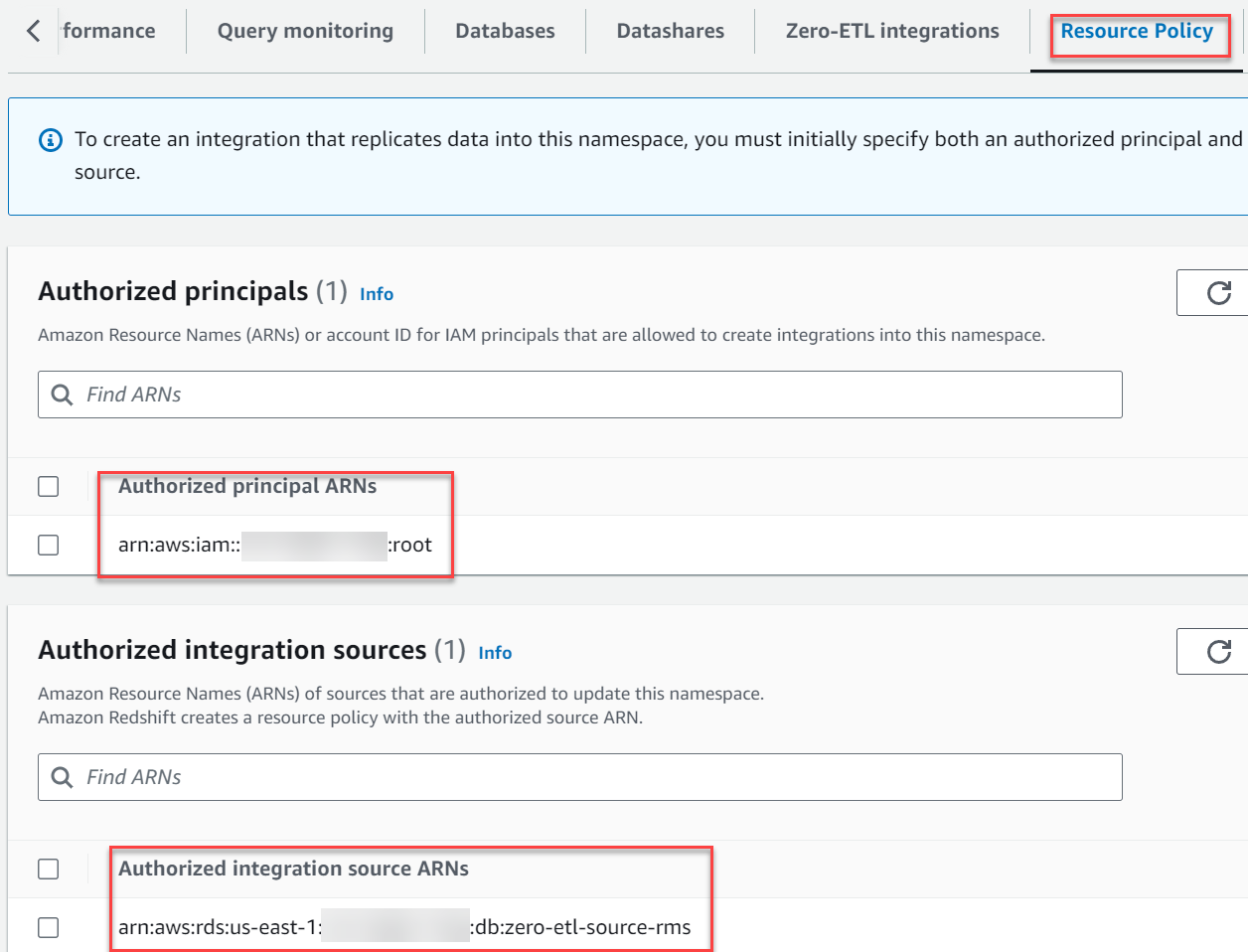
- ネームスペースに移動します
zero-etl-target-rs-nsを選択して リソースポリシー タブには何も表示されないことに注意してください。 - 選択する 承認されたプリンシパルを追加する.
- AWS ユーザーまたはロールの Amazon リソースネーム (ARN)、または統合の作成が許可されている AWS アカウント ID (IAM プリンシパル) のいずれかを入力します。
アカウント ID は、root ユーザーの ARN として保存されます。
![[クラスター リソース ポリシー] タブで承認されたプリンシパルを追加します。](https://zephyrnet.com/wp-content/uploads/2024/03/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift-amazon-web-services-12.png)
- 認定された統合ソース セクションでは、選択 承認された統合ソースを追加する ゼロ ETL 統合のデータ ソースである RDS for MySQL DB インスタンスの ARN を追加します。
この値は、Amazon RDS コンソールに移動して、 タブ zero-etl-source-rms DBインスタンス。
![承認された統合ソースを zero-etl-source-rms DB インスタンスの [構成] タブに追加します。](https://zephyrnet.com/wp-content/uploads/2024/03/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift-amazon-web-services-13.png)
リソース ポリシーは次のスクリーンショットのようになります。
必要な権限を構成する
ゼロ ETL 統合を作成するには、ユーザーまたはロールにアタッチされた アイデンティティベースのポリシー 適切な AWS IDおよびアクセス管理 (IAM) 権限。 AWS アカウント所有者は次のことができます 必要な権限を構成する ゼロ ETL 統合を作成する可能性のあるユーザーまたはロール向け。サンプル ポリシーでは、関連付けられたプリンシパルが次のアクションを実行できるようになります。
- ソース RDS for MySQL DB インスタンスのゼロ ETL 統合を作成します。
- すべてのゼロ ETL 統合を表示および削除します。
- ターゲット データ ウェアハウスへのインバウンド統合を作成します。同じアカウントが Redshift データ ウェアハウスを所有しており、このアカウントがそのデータ ウェアハウスの承認されたプリンシパルである場合、この権限は必要ありません。また、Amazon Redshift では、プロビジョニングされたクラスターとサーバーレスクラスターに対して異なる ARN 形式があることにも注意してください。
- Provisioned –
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - サーバレス –
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Provisioned –
権限を構成するには、次の手順を実行します。
- IAMコンソールで、 Policies ナビゲーションペインに表示されます。
- 選択する ポリシーを作成する.
- という新しいポリシーを作成します。
rds-integrations次の JSON を使用します (置き換えます)region&account-idあなたの実際の値で):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:db:source-instancename",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}
- 作成したポリシーを IAM ユーザーまたはロールの権限にアタッチします。
ゼロETL統合を作成する
ゼロ ETL 統合を作成するには、次の手順を実行します。
- Amazon RDS コンソールで、 ゼロETL統合 ナビゲーションペインに表示されます。
- 選択する ゼロETL統合の作成.

- 統合識別子、たとえば名前を入力します。
zero-etl-demo.
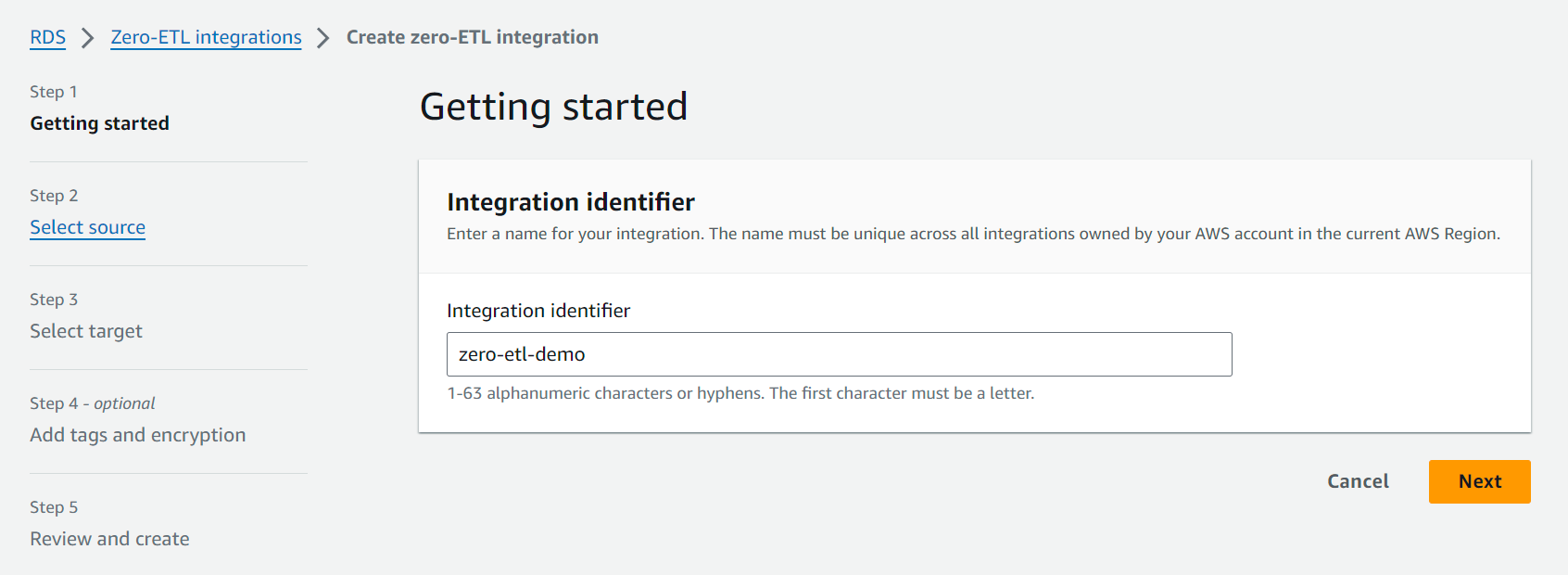
- ソースデータベース、選択する RDS データベースを参照する ソースクラスターを選択します
zero-etl-source-rms. - 選択する Next.

- ターゲット、用 Amazon Redshift データ ウェアハウス、選択する Redshift データ ウェアハウスを参照する Redshift データ ウェアハウスを選択します (
zero-etl-target-rs). - 選択する Next.
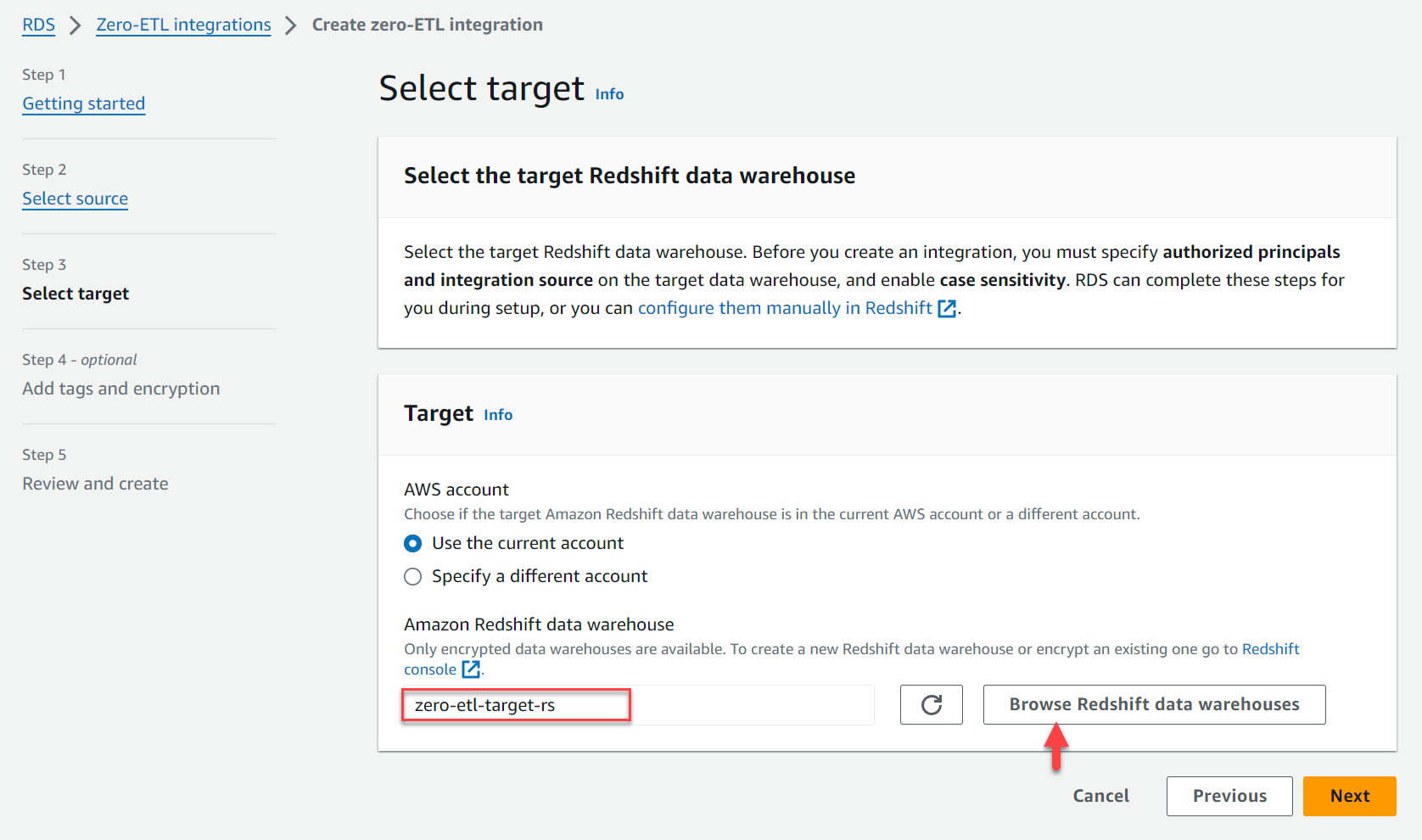
- 必要に応じて、タグと暗号化を追加します。
- 選択する Next.
- 統合名、ソース、ターゲット、その他の設定を確認します。
- 選択する ゼロETL統合の作成.
統合を選択して詳細を表示し、その進行状況を監視できます。ステータスが から変わるまでに約 30 分かかりました。 作成 〜へ アクティブ.

時間は、ソース内のデータセットのサイズによって異なります。
Amazon Redshift の統合からデータベースを作成する
ゼロ ETL 統合からデータベースを作成するには、次の手順を実行します。
- Amazon Redshiftコンソールで、 クラスター ナビゲーションペインに表示されます。
- Video Cloud Studioで
zero-etl-target-rsクラスタ。 - 選択する クエリデータ クエリ エディター v2 を開きます。
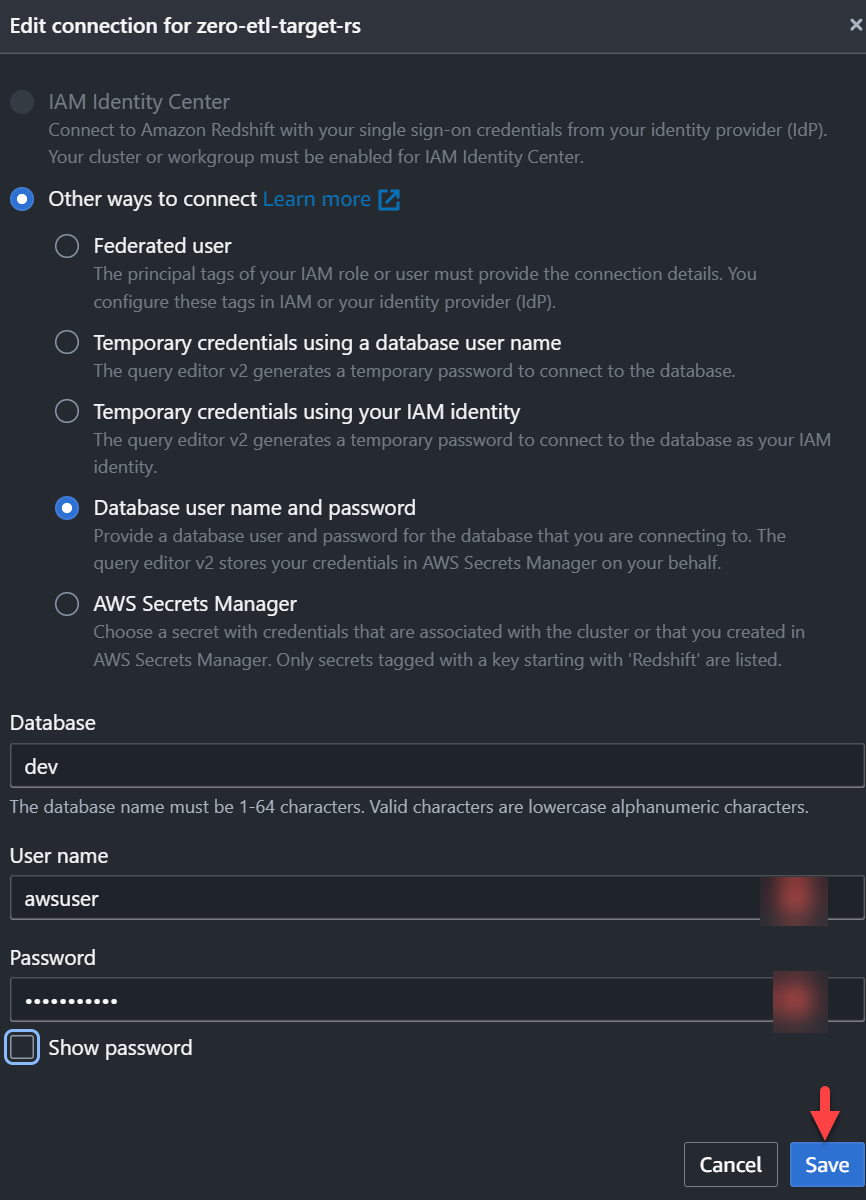
- を選択して Redshift データ ウェアハウスに接続します。 Save.
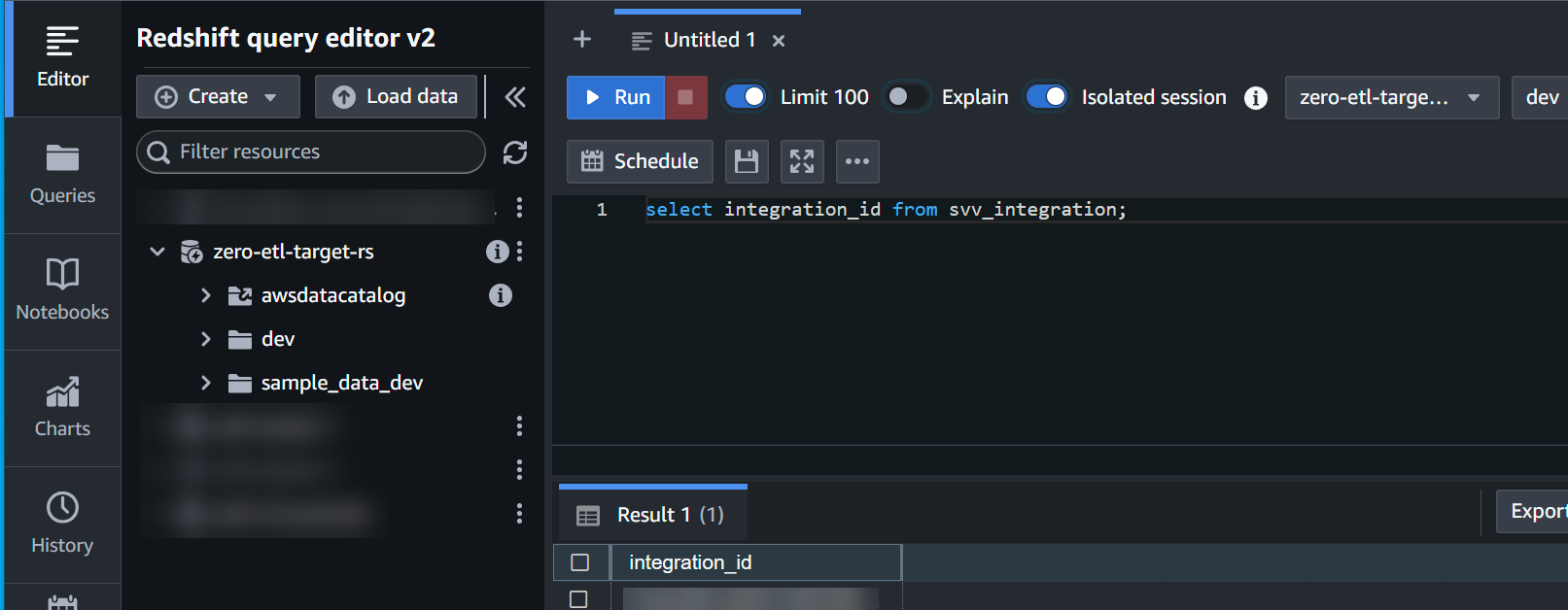
- を取得します
integration_idsvv_integrationシステムテーブル:
select integration_id from svv_integration; -- copy this result, use in the next sql
-
integration_id前のステップから、統合から新しいデータベースを作成します。
CREATE DATABASE zetl_source FROM INTEGRATION '<result from above>';
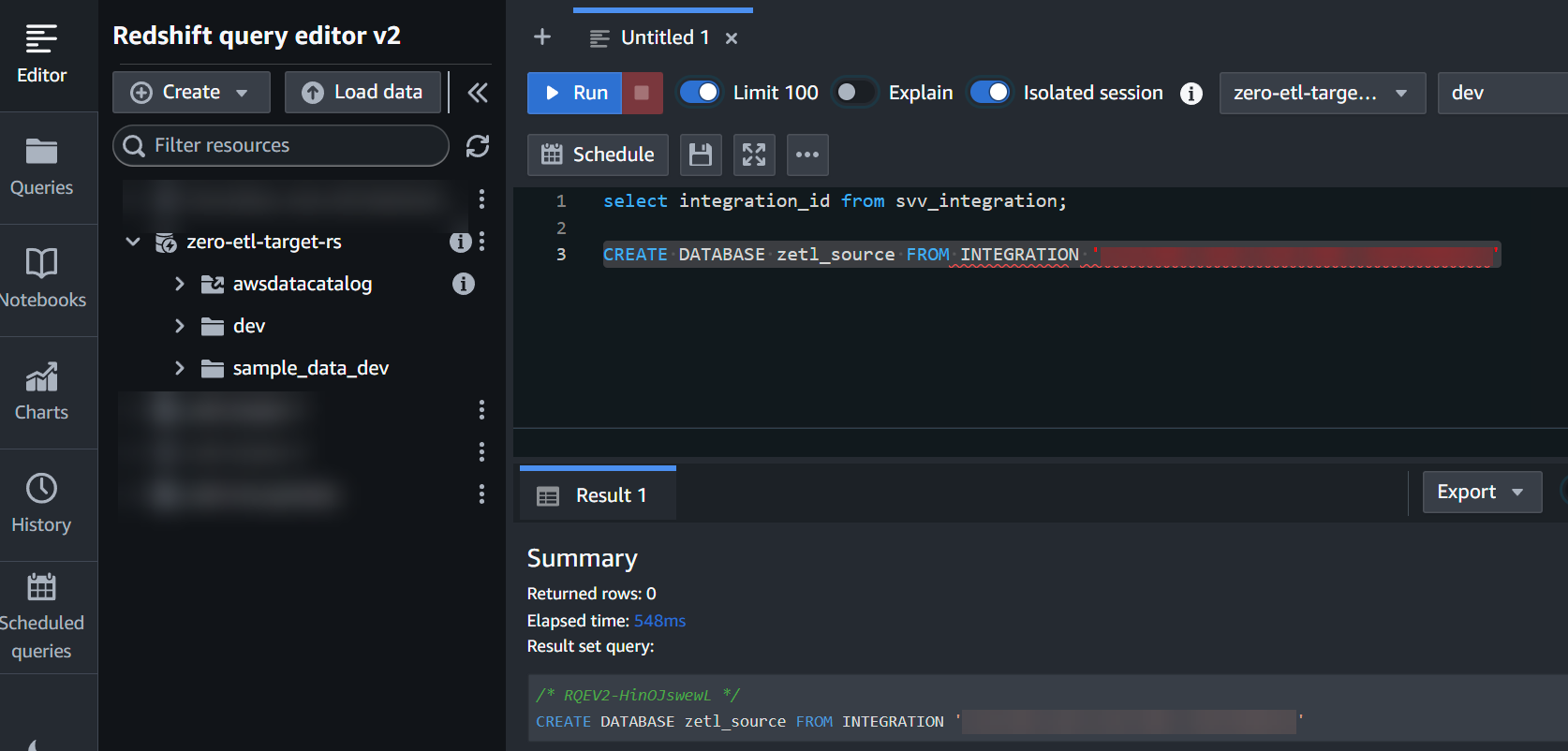
これで統合が完了し、ソースのスナップショット全体がデスティネーションにそのまま反映されます。進行中の変更はほぼリアルタイムで同期されます。
ほぼリアルタイムのトランザクション データを分析する
これで、TICKIT の運用データに対して分析を実行できるようになりました。
ソースTICKITデータを入力します。
ソース データを入力するには、次の手順を実行します。
- CSV 入力データ ファイルをローカル ディレクトリにコピーします。以下はコマンドの例です。
aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit' . --recursive
- RDS for MySQL クラスターに接続し、TICKIT データ モデルのデータベースまたはスキーマを作成し、そのスキーマ内のテーブルに主キーがあることを確認して、ロード プロセスを開始します。
mysql -h <rds_db_instance_endpoint> -u admin -p password --local-infile=1
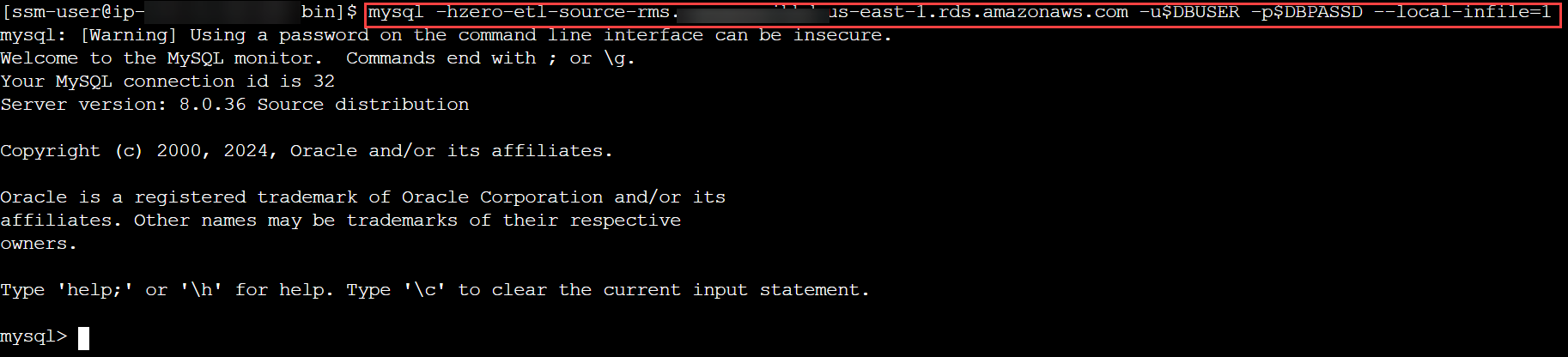
- 以下を使用してください CREATE TABLE コマンド.
- LOAD DATA コマンドを使用して、ローカル ファイルからデータをロードします。
以下は一例です。入力 CSV ファイルは複数のファイルに分割されていることに注意してください。すべてのデータをロードしたい場合は、すべてのファイルに対してこのコマンドを実行する必要があります。デモの目的では、部分的なデータのロードも同様に機能するはずです。

宛先のソース TICKIT データを分析する
Amazon Redshift コンソールで、統合セットアップの一部として作成したデータベースを使用してクエリエディター v2 を開きます。次のコードを使用して、シードまたは CDC アクティビティを検証します。

データ ウェアハウスにレプリケートされたデータに、ビジネス ロジックを直接適用して変換できるようになりました。また、レプリケートされたテーブルと他のローカル テーブルを結合する Redshift マテリアライズド ビューの作成などのパフォーマンス最適化手法を使用して、分析クエリのクエリ パフォーマンスを向上させることもできます。
監視
Amazon Redshift の次のシステムビューとテーブルをクエリして、Amazon Redshift とのゼロ ETL 統合に関する情報を取得できます。
に公開された統合関連のメトリクスを表示するには アマゾンクラウドウォッチ、Amazon Redshift コンソールを開きます。選ぶ ゼロETL統合 ナビゲーションペインで統合を選択し、アクティビティメトリクスを表示します。
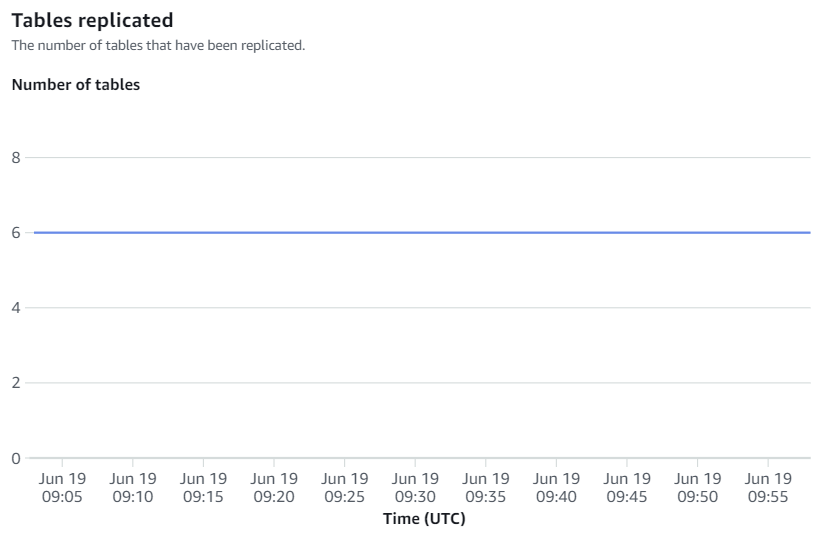
Amazon Redshift コンソールで利用可能なメトリクスは、統合メトリクスとテーブル統計であり、テーブル統計は、Amazon RDS for MySQL から Amazon Redshift にレプリケートされた各テーブルの詳細を提供します。

統合メトリクスには、テーブル レプリケーションの成功数と失敗数、ラグの詳細が含まれます。
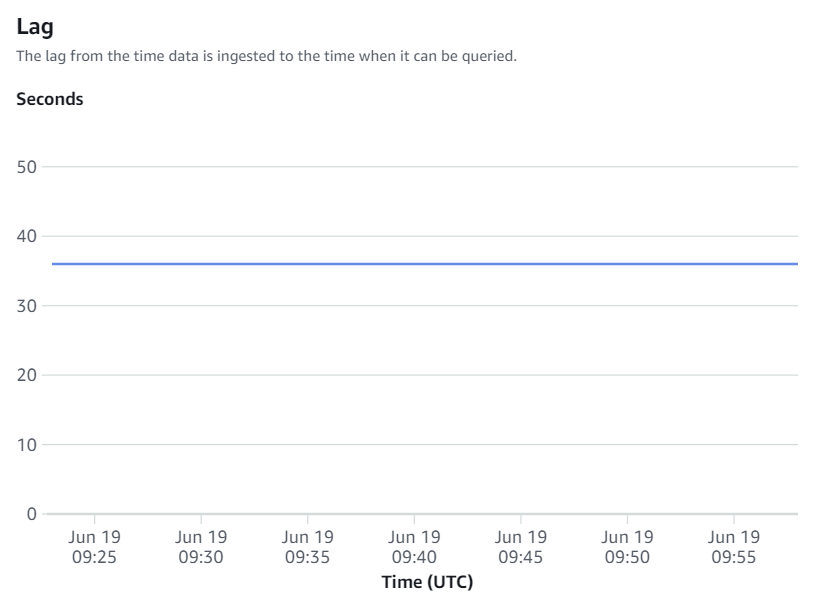
手動再同期
ゼロ ETL 統合は、テーブルの同期状態が失敗または再同期が必要であると表示される場合、自動的に再同期を開始します。ただし、自動再同期が失敗した場合は、テーブルレベルの粒度で再同期を開始できます。
ALTER DATABASE zetl_source INTEGRATION REFRESH TABLES tbl1, tbl2;
テーブルは、次のようなさまざまな理由で失敗状態になる可能性があります。
- 主キーがテーブルから削除されました。このような場合は、主キーを再度追加し、前述の ALTER コマンドを実行する必要があります。
- レプリケーション中に無効な値が検出されたか、サポートされていないデータ型で新しい列がテーブルに追加されました。このような場合は、サポートされていないデータ型の列を削除し、前述の ALTER コマンドを実行する必要があります。
- まれに、内部エラーによりテーブル障害が発生することがあります。 ALTER コマンドで修正できるはずです。
クリーンアップ
ゼロ ETL 統合を削除しても、トランザクション データはソース RDS またはターゲット Redshift データベースから削除されませんが、Amazon RDS は新しい変更を Amazon Redshift に送信しません。
ゼロ ETL 統合を削除するには、次の手順を実行します。
- Amazon RDS コンソールで、 ゼロETL統合 ナビゲーションペインに表示されます。
- 削除するゼロ ETL 統合を選択し、 削除.
- 削除を確認するには、 削除.

まとめ
この投稿では、Amazon RDS for MySQL から Amazon Redshift へのゼロ ETL 統合をセットアップする方法を説明しました。これにより、複雑なデータ パイプラインを維持する必要性が最小限に抑えられ、トランザクション データと運用データのほぼリアルタイムの分析が可能になります。
Amazon RDS ゼロ ETL と Amazon Redshift の統合の詳細については、以下を参照してください。 Amazon Redshift との Amazon RDS ゼロ ETL 統合の使用 (プレビュー).
著者について
 ミリンドオーク は、Amazon Web Services で 3 年間勤務した、Redshift スペシャリストのシニア ソリューション アーキテクトです。彼は、ニューヨーク州クイーンズを拠点とする AWS 認定 SA アソシエイト、セキュリティ スペシャリティ、および分析スペシャリティの認定保持者です。
ミリンドオーク は、Amazon Web Services で 3 年間勤務した、Redshift スペシャリストのシニア ソリューション アーキテクトです。彼は、ニューヨーク州クイーンズを拠点とする AWS 認定 SA アソシエイト、セキュリティ スペシャリティ、および分析スペシャリティの認定保持者です。
 アディティア・サマント はリレーショナル データベース業界のベテランで、商用データベースとオープンソース データベースを扱った経験が 2 年以上あります。彼は現在、アマゾン ウェブ サービスでプリンシパル データベース スペシャリスト ソリューション アーキテクトとして働いています。彼の役割では、スケーラブルで安全かつ堅牢なクラウド ネイティブ アーキテクチャを設計する顧客と協力することに時間を費やしています。 Aditya はサービス チームと緊密に連携し、Amazon が管理するデータベースの新機能の設計と提供に協力しています。
アディティア・サマント はリレーショナル データベース業界のベテランで、商用データベースとオープンソース データベースを扱った経験が 2 年以上あります。彼は現在、アマゾン ウェブ サービスでプリンシパル データベース スペシャリスト ソリューション アーキテクトとして働いています。彼の役割では、スケーラブルで安全かつ堅牢なクラウド ネイティブ アーキテクチャを設計する顧客と協力することに時間を費やしています。 Aditya はサービス チームと緊密に連携し、Amazon が管理するデータベースの新機能の設計と提供に協力しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift/

