Amazon Titan 画像ジェネレーター G1 最先端のテキストから画像への変換モデルであり、以下から入手できます。 アマゾンの岩盤、さまざまなコンテキストで複数のオブジェクトを説明するプロンプトを理解し、生成する画像にこれらの関連する詳細をキャプチャできます。これは、米国東部 (バージニア北部) と米国西部 (オレゴン) の AWS リージョンで利用でき、スマート トリミング、インペイント、背景の変更などの高度な画像編集タスクを実行できます。ただし、ユーザーは、モデルがまだトレーニングされていないカスタム データセット内の固有の特性にモデルを適応させたいと考えています。カスタム データセットには、ブランド ガイドラインや以前のキャンペーンなどの特定のスタイルと一致する、独自性の高いデータを含めることができます。これらのユースケースに対処し、完全にパーソナライズされたイメージを生成するには、次を使用して独自のデータを使用して Amazon Titan Image Generator を微調整できます。 Amazon Bedrock のカスタム モデル.
画像の生成から編集に至るまで、テキストから画像へのモデルは業界全体に幅広く応用できます。従業員の創造性を高め、文字による説明だけで新しい可能性を想像できるようになります。たとえば、手動で作成するプロセスを必要とせずにさまざまなデザインを視覚化する機能を提供することで、建築家の設計やフロアプランニングを支援し、より迅速なイノベーションを可能にします。同様に、グラフィックスやイラストの生成を効率化することで、製造、小売業のファッション デザイン、ゲーム デザインなど、さまざまな業界のデザインを支援できます。 Text-to-Image モデルは、パーソナライズされた広告や、メディアやエンターテイメントのユースケースにおけるインタラクティブで没入型のビジュアル チャットボットを可能にすることで、顧客エクスペリエンスも向上させます。
この投稿では、私たちのお気に入りのペットである犬のロンと猫のスミラという 2 つの新しいカテゴリを学習するために、Amazon Titan Image Generator モデルを微調整するプロセスを説明します。モデルの微調整タスク用にデータを準備する方法と、Amazon Bedrock でモデルのカスタマイズ ジョブを作成する方法について説明します。最後に、微調整されたモデルをテストしてデプロイする方法を示します。 プロビジョニングされたスループット.
 |
 |
| 犬のロン | 猫のスミラ |
ジョブを微調整する前にモデルの機能を評価する
基礎モデルは大量のデータでトレーニングされるため、モデルがそのまま使用しても十分に機能する可能性があります。そのため、実際にユースケースに合わせてモデルを微調整する必要があるかどうか、または迅速なエンジニアリングで十分であるかどうかを確認することをお勧めします。次のスクリーンショットに示すように、Amazon Titan Image Generator の基本モデルを使用して犬の Ron と猫の Smila の画像を生成してみましょう。
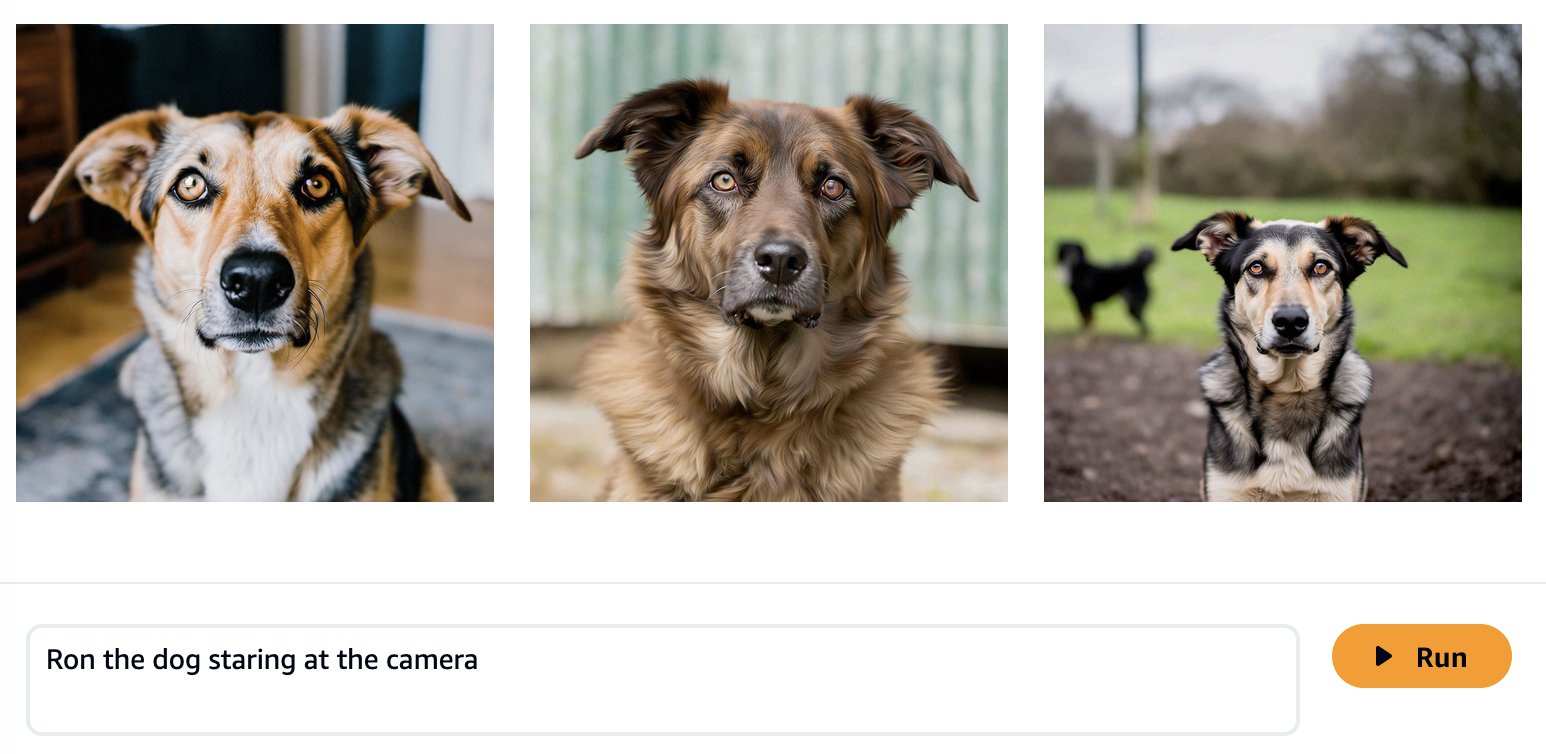

予想通り、すぐに使えるモデルはまだ Ron と Smila を認識しておらず、生成された出力には異なる犬と猫が表示されます。迅速なエンジニアリングにより、より詳細な情報を提供して、お気に入りのペットの外観に近づけることができます。


生成された画像はロンとスミラにより似ていますが、モデルが彼らの完全な類似性を再現できないことがわかります。ここで、Ron と Smila からの写真を使用して微調整ジョブを開始して、一貫性のあるパーソナライズされた出力を取得しましょう。
Amazon Titan Image Generator の微調整
Amazon Bedrock は、Amazon Titan Image Generator モデルを微調整するためのサーバーレス エクスペリエンスを提供します。データを準備してハイパーパラメータを選択するだけで、面倒な作業は AWS が処理します。
Amazon Titan Image Generator モデルを使用して微調整すると、このモデルのコピーが AWS モデル開発アカウントに作成され、AWS によって所有および管理され、モデルのカスタマイズ ジョブが作成されます。次に、このジョブは VPC から微調整データにアクセスし、Amazon Titan モデルの重みが更新されます。新しいモデルは次の場所に保存されます。 Amazon シンプル ストレージ サービス (Amazon S3) 事前トレーニングされたモデルと同じモデル開発アカウントにあります。これで、自分のアカウントのみが推論に使用できるようになり、他の AWS アカウントと共有されることはなくなりました。推論を実行するときは、次の方法でこのモデルにアクセスします。 プロビジョニングされたキャパシティのコンピューティング または直接使用して、 Amazon Bedrock のバッチ推論。選択した推論方式とは関係なく、データはアカウント内に残り、AWS が所有するアカウントにコピーされたり、Amazon Titan Image Generator モデルを改善するために使用されたりすることはありません。
次の図は、このワークフローを示しています。
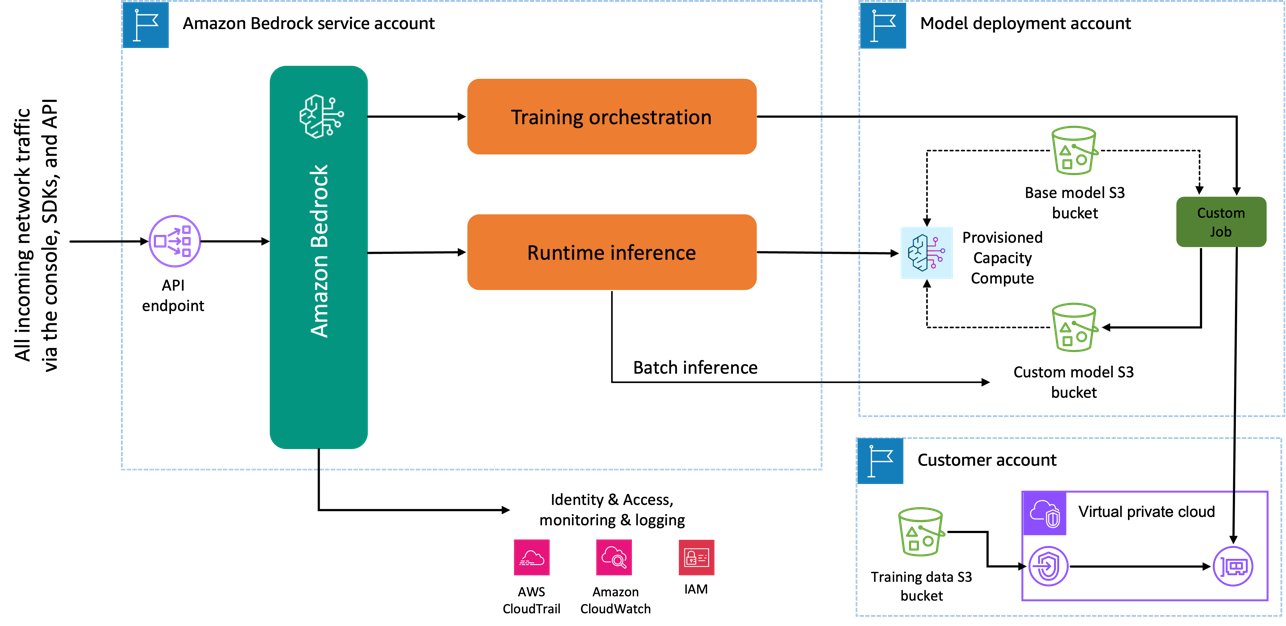
データプライバシーとネットワークセキュリティ
プロンプトやカスタム モデルなどの微調整に使用されるデータは、AWS アカウント内で非公開のままです。これらは、モデルのトレーニングやサービスの改善のために共有または使用されることはなく、サードパーティのモデル プロバイダーと共有されることもありません。微調整に使用されるすべてのデータは、転送中も保存中も暗号化されます。データは、API 呼び出しが処理されるのと同じリージョンに残ります。も使用できます AWS プライベートリンク データが存在する AWS アカウントと VPC の間にプライベート接続を作成します。
データの準備
モデルのカスタマイズ ジョブを作成する前に、次のことを行う必要があります。 トレーニング データセットを準備する。トレーニング データセットの形式は、作成しているカスタマイズ ジョブのタイプ (微調整または継続的な事前トレーニング) とデータのモダリティ (テキストからテキスト、テキストから画像、または画像から埋め込み)。 Amazon Titan Image Generator モデルの場合、微調整に使用する画像と各画像のキャプションを提供する必要があります。 Amazon Bedrock は、画像が Amazon S3 に保存され、画像とキャプションのペアが複数の JSON 行を含む JSONL 形式で提供されることを想定しています。
各 JSON 行は、image-ref、画像の S3 URI、および画像のテキスト プロンプトを含むキャプションを含むサンプルです。画像は JPEG または PNG 形式である必要があります。次のコードは、形式の例を示しています。
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
「Ron」と「Smila」は人の名前など、他のコンテキストでも使用できる名前であるため、モデルを微調整するためのプロンプトを作成するときに「犬のロン」と猫の「スミラ」という識別子を追加します。 。これは微調整ワークフローの要件ではありませんが、この追加情報により、新しいクラス向けにカスタマイズする際にモデルのコンテキストがより明確になり、「犬のロン」と「犬のロン」と「犬のロン」の混同を避けることができます。猫のスミラ」とウクライナの都市スミラを組み合わせたもの。このロジックを使用した次の画像は、トレーニング データセットのサンプルを示しています。
 |
 |
 |
| 白い犬用ベッドに横たわる犬のロン | タイルの床に座る犬のロン | 車のシートに横たわる犬のロン |
 |
 |
 |
| ソファに横たわる猫のスミラ | ソファに寝そべってカメラを見つめる猫のスミラ | ペットキャリーに横たわる猫のスミラ |
データをカスタマイズ ジョブで想定される形式に変換すると、次のサンプル構造が得られます。
{"画像参照": "/ron_01.jpg", "caption": "白い犬用ベッドに横たわる犬のロン"} {"image-ref": "/ron_02.jpg", "caption": "タイルの床に座っている犬のロン"} {"image-ref": "/ron_03.jpg", "caption": "車のシートに横たわる犬のロン"} {"image-ref": "/smila_01.jpg", "caption": "ソファに横たわる猫のスミラ"} {"image-ref": "/smila_02.jpg", "caption": "猫像の隣の窓際に座る猫のスミラ"} {"image-ref": "/smila_03.jpg", "caption": "ペットキャリアに横たわる猫のスミラ"}
JSONL ファイルを作成したら、カスタマイズ ジョブを開始するためにそれを S3 バケットに保存する必要があります。 Amazon Titan Image Generator G1 微調整ジョブは、5 ~ 10,000 個の画像で機能します。この投稿で説明する例では、犬のロンの 60 枚と猫のスミラの 30 枚の合計 30 枚の画像を使用します。一般に、学習しようとしているスタイルやクラスの種類を増やすと、微調整されたモデルの精度が向上します。ただし、微調整に使用する画像の数が増えるほど、微調整ジョブが完了するまでに必要な時間も長くなります。使用される画像の数も、微調整されたジョブの価格に影響します。参照する Amazon の岩盤価格 。
Amazon Titan Image Generator の微調整
トレーニング データの準備ができたので、新しいカスタマイズ ジョブを開始できます。このプロセスは、Amazon Bedrock コンソールまたは API の両方を介して実行できます。 Amazon Bedrock コンソールを使用するには、次の手順を実行します。
- Amazon Bedrock コンソールで、 カスタムモデル ナビゲーションペインに表示されます。
- ソフトウェア設定ページで、下図のように モデルのカスタマイズ メニュー、選択 微調整ジョブの作成.
- モデル名の微調整、新しいモデルの名前を入力します。
- ジョブ構成、トレーニング ジョブの名前を入力します。
- 入力データ、入力データの S3 パスを入力します。
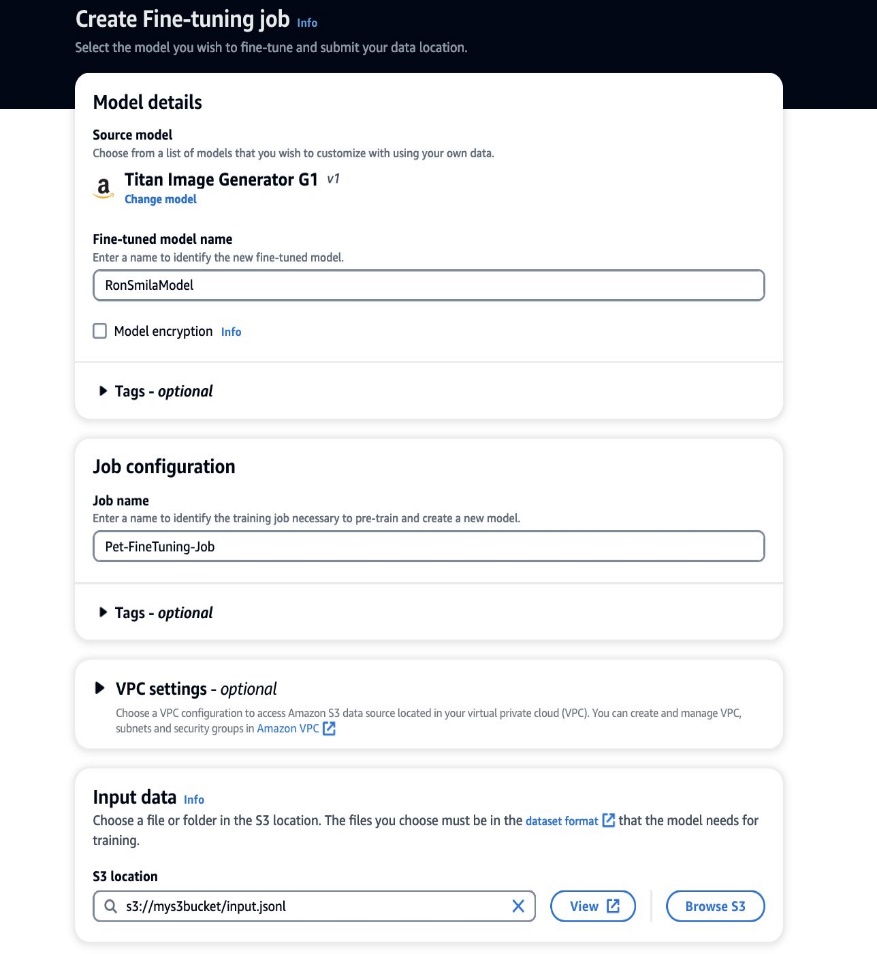
- ハイパーパラメータ セクションでは、次の値を指定します。
- ステップ数 – モデルが各バッチに公開される回数。
- バッチサイズ – モデルパラメータを更新する前に処理されたサンプルの数。
- 学習率 – 各バッチ後にモデル パラメーターが更新される速度。これらのパラメーターの選択は、特定のデータセットによって異なります。一般的なガイドラインとして、次の表に詳しく示すように、バッチ サイズを 8、学習率を 1e-5 に固定することから始め、使用する画像の数に応じてステップ数を設定することをお勧めします。
| 提供される画像の数 | 8 | 32 | 64 | 1,000 | 10,000 |
| 推奨されるステップ数 | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
微調整ジョブの結果が満足のいくものでない場合は、生成された画像にスタイルの兆候が観察されない場合はステップ数を増やすことを検討し、生成された画像にスタイルが観察されるが、スタイルが観察される場合はステップ数を減らすことを検討してください。アーチファクトやぼやけがある。 40,000 ステップを実行しても、微調整されたモデルがデータセット内の固有のスタイルを学習できない場合は、バッチ サイズまたは学習率を増やすことを検討してください。
- 出力データ セクションで、定期的に記録される検証損失と精度メトリクスを含む検証出力が保存される S3 出力パスを入力します。
- サービスアクセス セクションで、新しいを生成します AWS IDおよびアクセス管理 (IAM) ロールを選択するか、S3 バケットにアクセスするために必要な権限を持つ既存の IAM ロールを選択します。
この承認により、Amazon Bedrock は指定されたバケットから入力データセットと検証データセットを取得し、検証出力を S3 バケットにシームレスに保存できるようになります。
- 選択する ファインチューンモデル.
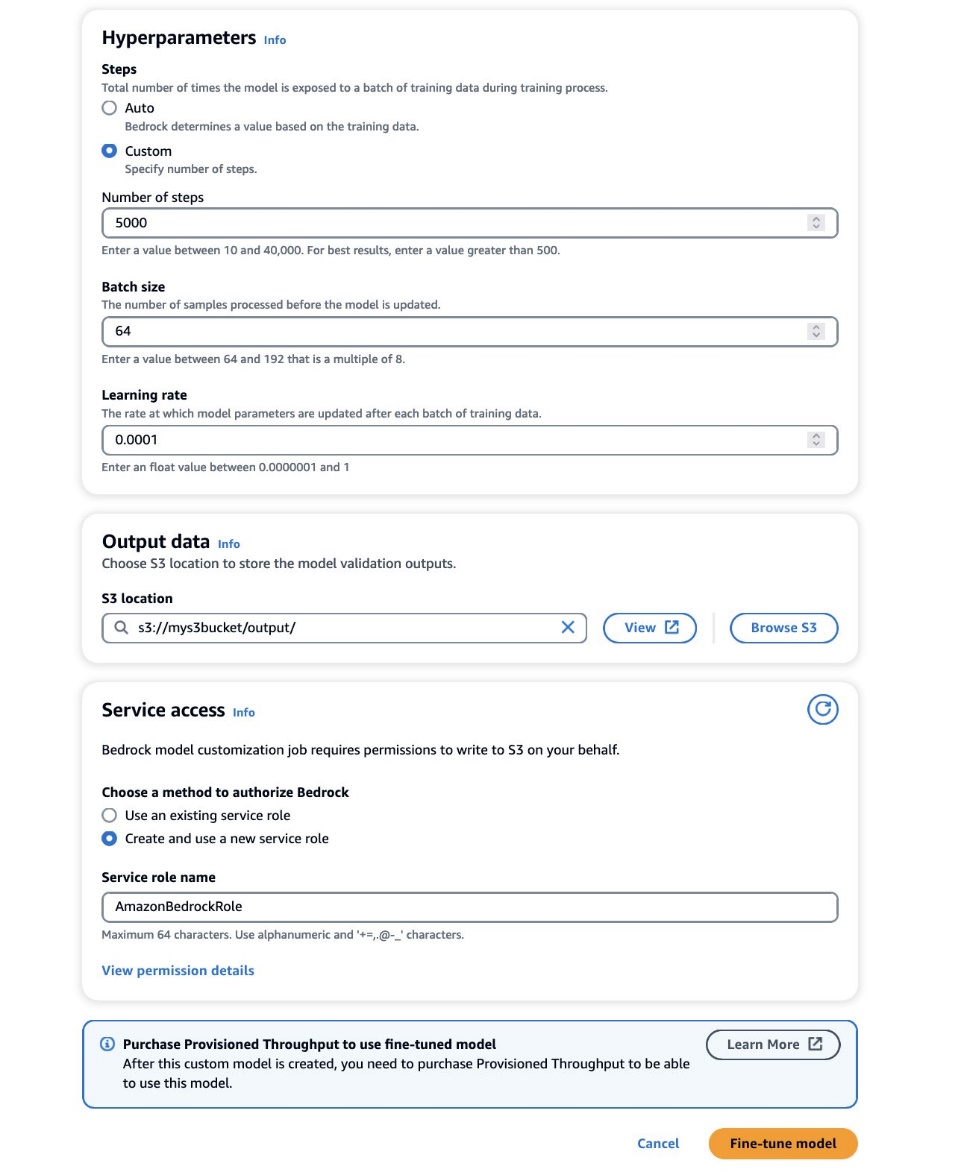
正しい設定が設定されていると、Amazon Bedrock がカスタム モデルをトレーニングします。
プロビジョニングされたスループットを備えた、微調整された Amazon Titan Image Generator をデプロイします
カスタム モデルを作成した後、プロビジョンド スループットを使用すると、事前に決定された固定率の処理能力をカスタム モデルに割り当てることができます。この割り当てにより、ワークロードを処理するための一貫したレベルのパフォーマンスと容量が提供され、実稼働ワークロードのパフォーマンスが向上します。プロビジョンド スループットの 2 番目の利点はコスト管理です。これは、オンデマンド推論モードを使用した標準のトークンベースの価格設定は大規模では予測が難しいためです。
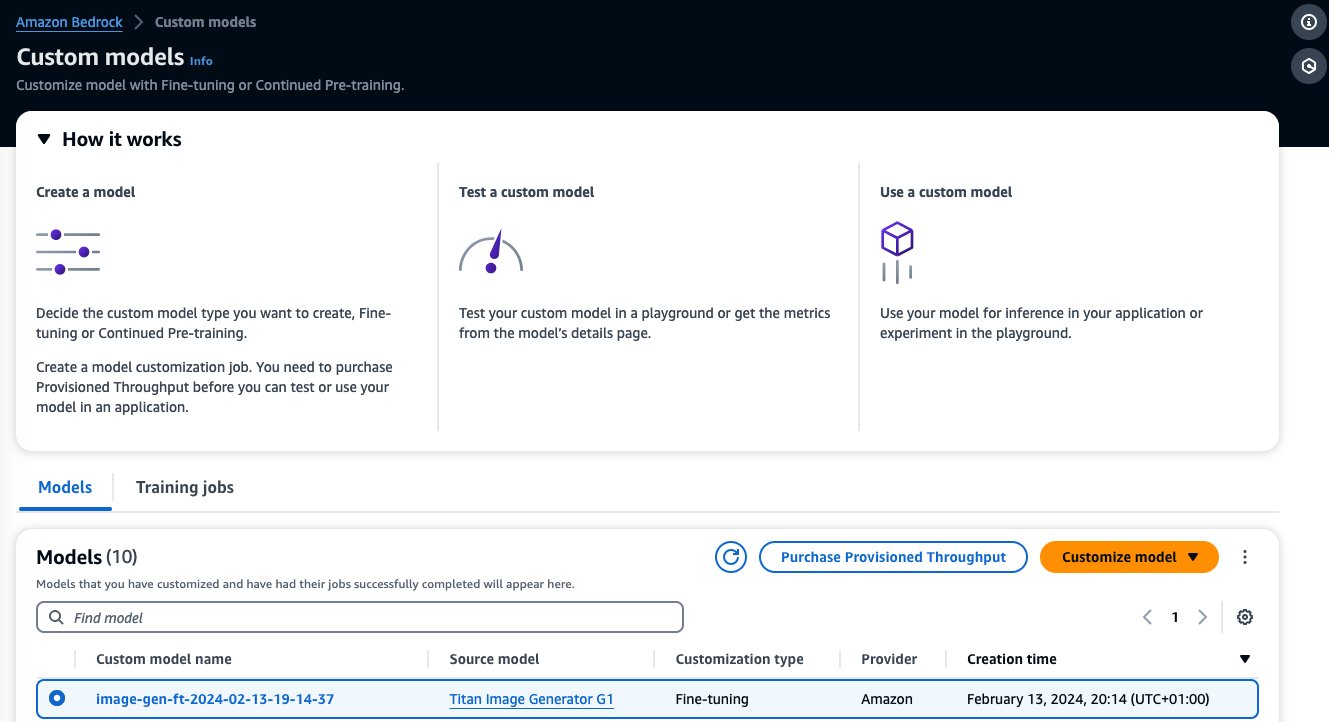
モデルの微調整が完了すると、このモデルが カスタムモデル Amazon Bedrock コンソールのページ。
プロビジョンド スループットを購入するには、微調整したカスタム モデルを選択し、 プロビジョニングされたスループットを購入する.
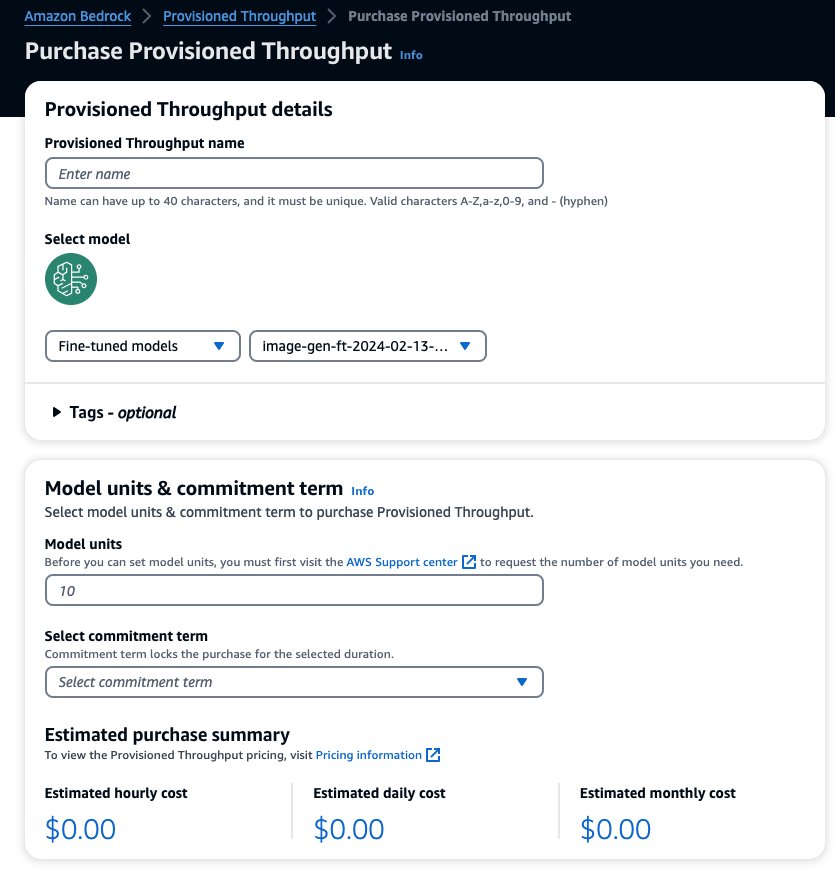
これにより、プロビジョンド スループットを購入する選択したモデルが事前に設定されます。デプロイ前に微調整されたモデルをテストするには、モデル単位の値を 1 に設定し、コミットメント期間を に設定します。 義務はありません。これにより、カスタム プロンプトを使用してモデルのテストをすぐに開始し、トレーニングが適切かどうかを確認できます。さらに、新しい微調整モデルと新しいバージョンが利用可能になった場合、同じモデルの他のバージョンで更新する限り、プロビジョンド スループットを更新できます。
結果の微調整
犬のロンと猫のスミラのモデルをカスタマイズするというタスクでは、実験の結果、最適なハイパーパラメーターはバッチ サイズ 5,000、学習率 8e-1 で 5 ステップであることがわかりました。
以下は、カスタマイズされたモデルによって生成される画像の例です。
 |
 |
 |
| スーパーヒーローのマントをかぶった犬のロン | 月の犬ロン | サングラスをかけたプールにいる犬のロン |
 |
 |
 |
| 雪の上の猫のスミラ | カメラを見つめる白黒の猫のスミラ | クリスマス帽子をかぶった猫のスミラ |
まとめ
この投稿では、より高品質の画像を生成するためにプロンプトを設計するのではなく、いつ微調整を使用するべきかについて説明しました。 Amazon Titan Image Generator モデルを微調整し、カスタム モデルを Amazon Bedrock にデプロイする方法を説明しました。また、微調整用にデータを準備し、より正確なモデルをカスタマイズするために最適なハイパーパラメーターを設定する方法に関する一般的なガイドラインも提供しました。
次のステップとして、以下を適応させることができます 例 ユースケースに合わせて、Amazon Titan Image Generator を使用してハイパーパーソナライズされたイメージを生成します。
著者について
 マイラ・ラデイラ・タンケ AWS のシニア ジェネレーティブ AI データ サイエンティストです。機械学習のバックグラウンドを持つ彼女は、さまざまな業界の顧客とともに AI アプリケーションの設計と構築に 10 年以上の経験を持っています。彼女は技術リーダーとして、Amazon Bedrock の生成 AI ソリューションを通じてお客様がビジネス価値の達成を加速できるよう支援しています。自由時間には、マイラは旅行したり、猫のスミラと遊んだり、暖かい場所で家族と時間を過ごしたりすることを楽しんでいます。
マイラ・ラデイラ・タンケ AWS のシニア ジェネレーティブ AI データ サイエンティストです。機械学習のバックグラウンドを持つ彼女は、さまざまな業界の顧客とともに AI アプリケーションの設計と構築に 10 年以上の経験を持っています。彼女は技術リーダーとして、Amazon Bedrock の生成 AI ソリューションを通じてお客様がビジネス価値の達成を加速できるよう支援しています。自由時間には、マイラは旅行したり、猫のスミラと遊んだり、暖かい場所で家族と時間を過ごしたりすることを楽しんでいます。
 ダニ・ミッチェル アマゾン ウェブ サービスの AI/ML スペシャリスト ソリューション アーキテクトです。彼はコンピューター ビジョンのユースケースに焦点を当てており、EMEA 全体の顧客が ML への移行を加速できるよう支援しています。
ダニ・ミッチェル アマゾン ウェブ サービスの AI/ML スペシャリスト ソリューション アーキテクトです。彼はコンピューター ビジョンのユースケースに焦点を当てており、EMEA 全体の顧客が ML への移行を加速できるよう支援しています。
 バーラティ スリニバサン 彼女は AWS プロフェッショナル サービスのデータ サイエンティストであり、Amazon Bedrock 上にクールなものを構築するのが大好きです。彼女は、責任ある AI に重点を置き、機械学習アプリケーションからビジネス価値を高めることに情熱を注いでいます。顧客向けに新しい AI エクスペリエンスを構築する以外にも、Bharathi は SF を書いたり、持久力スポーツに挑戦したりすることが大好きです。
バーラティ スリニバサン 彼女は AWS プロフェッショナル サービスのデータ サイエンティストであり、Amazon Bedrock 上にクールなものを構築するのが大好きです。彼女は、責任ある AI に重点を置き、機械学習アプリケーションからビジネス価値を高めることに情熱を注いでいます。顧客向けに新しい AI エクスペリエンスを構築する以外にも、Bharathi は SF を書いたり、持久力スポーツに挑戦したりすることが大好きです。
 アチン・ジェイン Amazon Artificial General Intelligence (AGI) チームの応用科学者です。彼はテキストから画像へのモデルに関する専門知識を持っており、Amazon Titan Image Generator の構築に重点を置いています。
アチン・ジェイン Amazon Artificial General Intelligence (AGI) チームの応用科学者です。彼はテキストから画像へのモデルに関する専門知識を持っており、Amazon Titan Image Generator の構築に重点を置いています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

