進化する製造業の状況において、AI と機械学習 (ML) の変革力は明らかであり、業務を合理化し、生産性を向上させるデジタル革命を推進しています。ただし、この進歩により、データ駆動型ソリューションを活用する企業には特有の課題が生じます。産業施設は、生産ライン全体に分散されたセンサー、遠隔測定システム、機器から得られる膨大な量の非構造化データに取り組んでいます。リアルタイム データは、予知保全や異常検出などのアプリケーションにとって重要ですが、そのような時系列データを使用して産業ユース ケースごとにカスタム ML モデルを開発するには、データ サイエンティストに多大な時間とリソースが必要であり、広範な導入の妨げとなっています。
生成AI などの大規模な事前トレーニング済み基礎モデル (FM) を使用します。 クロード として知られる単純なテキスト プロンプトに基づいて、会話テキストからコンピュータ コードまで、さまざまなコンテンツを迅速に生成できます。 ゼロショットプロンプト。これにより、データ サイエンティストがユースケースごとに特定の ML モデルを手動で開発する必要がなくなり、AI へのアクセスが民主化され、小規模なメーカーにもメリットがもたらされます。労働者は AI によって生成された洞察を通じて生産性を向上し、エンジニアは異常を積極的に検出でき、サプライ チェーン マネージャーは在庫を最適化し、工場のリーダーは情報に基づいたデータ主導の意思決定を行うことができます。
それにもかかわらず、スタンドアロン FM は、コンテキスト サイズの制約 (通常は、 200,000トークン未満)、課題が生じます。これに対処するには、自然言語クエリ (NLQ) に応答してコードを生成する FM の機能を使用できます。エージェントの好み パンダAI 高解像度の時系列データに対してこのコードを実行し、FM を使用してエラーを処理します。 PandasAI は、人気のあるデータ分析および操作ツールである pandas に生成 AI 機能を追加する Python ライブラリです。
ただし、時系列データ処理、マルチレベル集計、ピボットまたはジョイント テーブル操作などの複雑な NLQ では、ゼロショット プロンプトで Python スクリプトの精度が一貫しない可能性があります。
コード生成の精度を高めるために、動的に構築することを提案します。 マルチショットプロンプト NLQの場合。マルチショット プロンプトは、同様のプロンプトに対して必要な出力のいくつかの例を FM に表示することで追加のコンテキストを FM に提供し、精度と一貫性を高めます。この投稿では、同様のデータ型 (モノのインターネット デバイスからの高解像度時系列データなど) で実行された成功した Python コードを含む埋め込みからマルチショット プロンプトを取得します。動的に構築されたマルチショット プロンプトは、FM に最も関連性の高いコンテキストを提供し、高度な数学計算、時系列データ処理、およびデータ頭字語の理解における FM の能力を強化します。この改善された対応により、企業の従業員や運用チームがデータに取り組むことが容易になり、広範なデータ サイエンス スキルを必要とせずに洞察を導き出すことができます。
時系列データ分析を超えて、FM はさまざまな産業用途で価値があることが証明されています。メンテナンス チームは資産の健全性を評価し、画像をキャプチャします。 Amazonの再認識ベースの機能概要、およびインテリジェントな検索を使用した異常の根本原因分析 検索拡張生成 (ラグ)。これらのワークフローを簡素化するために、AWS は アマゾンの岩盤、次のような最先端の事前トレーニング済み FM を使用して生成 AI アプリケーションを構築および拡張できるようになります。 クロード v2 Amazon Bedrock のナレッジベースを使用すると、RAG 開発プロセスを簡素化し、プラント作業員により正確な異常の根本原因分析を提供できます。私たちの投稿では、Amazon Bedrock を活用した産業ユースケース向けのインテリジェントアシスタントを紹介し、NLQ の課題に対処し、画像から部品概要を生成し、RAG アプローチを通じて機器診断のための FM 応答を強化します。
ソリューションの概要
次の図は、ソリューションのアーキテクチャを示しています。

ワークフローには、次の 3 つの異なる使用例が含まれています。
使用例 1: 時系列データを使用した NLQ
時系列データを使用した NLQ のワークフローは、次の手順で構成されます。
- 当社では、異常検出のための ML 機能を備えた状態監視システムを使用しています。 アマゾンモニトロン、産業機器の健全性を監視します。 Amazon Monitron は、機器の振動と温度の測定から潜在的な機器の故障を検出できます。
- 時系列データを加工して収集します アマゾンモニトロン データスルー Amazon Kinesisデータストリーム & Amazon データ ファイアホース、表形式の CSV 形式に変換し、 Amazon シンプル ストレージ サービス (Amazon S3)バケット。
- エンドユーザーは、自然言語クエリを Streamlit アプリに送信することで、Amazon S3 の時系列データとのチャットを開始できます。
- Streamlit アプリはユーザーのクエリを Amazon Bedrock Titan テキスト埋め込みモデル このクエリを埋め込み、クエリ内で類似性検索を実行します。 AmazonOpenSearchサービス インデックスには、以前の NLQ とコード例が含まれています。
- 類似性検索の後、NLQ の質問、データ スキーマ、Python コードなどの類似した上位の例がカスタム プロンプトに挿入されます。
- PandasAI は、このカスタム プロンプトを Amazon Bedrock Claude v2 モデルに送信します。
- このアプリは、PandasAI エージェントを使用して Amazon Bedrock Claude v2 モデルと対話し、Amazon Monitron データ分析および NLQ 応答用の Python コードを生成します。
- Amazon Bedrock Claude v2 モデルが Python コードを返した後、PandasAI はアプリからアップロードされた Amazon Monitron データに対して Python クエリを実行し、コード出力を収集し、失敗した実行に必要な再試行に対処します。
- Streamlit アプリは PandasAI 経由で応答を収集し、出力をユーザーに提供します。出力が満足のいくものである場合、ユーザーはそれを役立つものとしてマークし、NLQ および Claude が生成した Python コードを OpenSearch サービスに保存できます。
ユースケース 2: 故障部品の要約生成
概要生成のユースケースは次の手順で構成されます。
- ユーザーは、どの産業資産が異常な動作を示しているかを把握した後、故障した部品の画像をアップロードし、技術仕様と動作条件に従ってその部品に物理的な問題があるかどうかを特定できます。
- ユーザーは Amazon 認識 DetectText API これらの画像からテキスト データを抽出します。
- 抽出されたテキスト データは Amazon Bedrock Claude v2 モデルのプロンプトに含まれており、モデルが誤動作部分の 200 ワードの概要を生成できるようになります。ユーザーはこの情報を使用して、部品のさらなる検査を実行できます。
使用例 3: 根本原因の診断
根本原因診断のユースケースは次の手順で構成されます。
- ユーザーは、故障した資産に関連するさまざまなドキュメント形式 (PDF、TXT など) でエンタープライズ データを取得し、S3 バケットにアップロードします。
- これらのファイルのナレッジベースは、Titan テキスト埋め込みモデルとデフォルトの OpenSearch Service ベクター ストアを使用して Amazon Bedrock で生成されます。
- ユーザーは、故障した機器の根本原因の診断に関連する質問をします。回答は、RAG アプローチを使用した Amazon Bedrock ナレッジベースを通じて生成されます。
前提条件
この投稿を進めるには、次の前提条件を満たす必要があります。
ソリューション インフラストラクチャをデプロイする
ソリューション リソースを設定するには、次の手順を実行します。
- を展開します AWS CloudFormation template opensearchsagemaker.yml、OpenSearch Service コレクションとインデックスを作成します。 アマゾンセージメーカー ノートブック インスタンスと S3 バケット。この AWS CloudFormation スタックには次のような名前を付けることができます。
genai-sagemaker. - JupyterLab で SageMaker ノートブック インスタンスを開きます。以下の内容が見つかります GitHubレポ このインスタンスにはすでにダウンロードされています: 産業運営における生成型 AI の可能性を解き放つ.
- このリポジトリ内の次のディレクトリからノートブックを実行します。 産業運営における生成 AI の可能性のロック解除/SagemakerNotebook/nlq-vector-rag-embedding.ipynb。このノートブックは、SageMaker ノートブックを使用して OpenSearch Service インデックスをロードし、 既存の 23 の NLQ の例.
- データフォルダーからドキュメントをアップロードする アセットパートドキュメント GitHub リポジトリ内から、CloudFormation スタック出力にリストされている S3 バケットにコピーします。

次に、Amazon S3 にドキュメントのナレッジベースを作成します。
- Amazon Bedrock コンソールで、 知識ベース ナビゲーションペインに表示されます。
- 選択する 知識ベースを作成する.
- ナレッジベース名、名前を入力します。
- ランタイムの役割選択 新しいサービスロールを作成して使用する.
- データソース名、データ ソースの名前を入力します。
- S3 URI、根本原因ドキュメントをアップロードしたバケットの S3 パスを入力します。
- 選択する Next.
 Titan 埋め込みモデルが自動的に選択されます。
Titan 埋め込みモデルが自動的に選択されます。 - 選択 新しいベクター ストアを簡単に作成する.
- 設定を確認し、選択してナレッジ ベースを作成します。 知識ベースを作成する.
- ナレッジ ベースが正常に作成されたら、次を選択します。 同期 S3 バケットをナレッジ ベースと同期します。

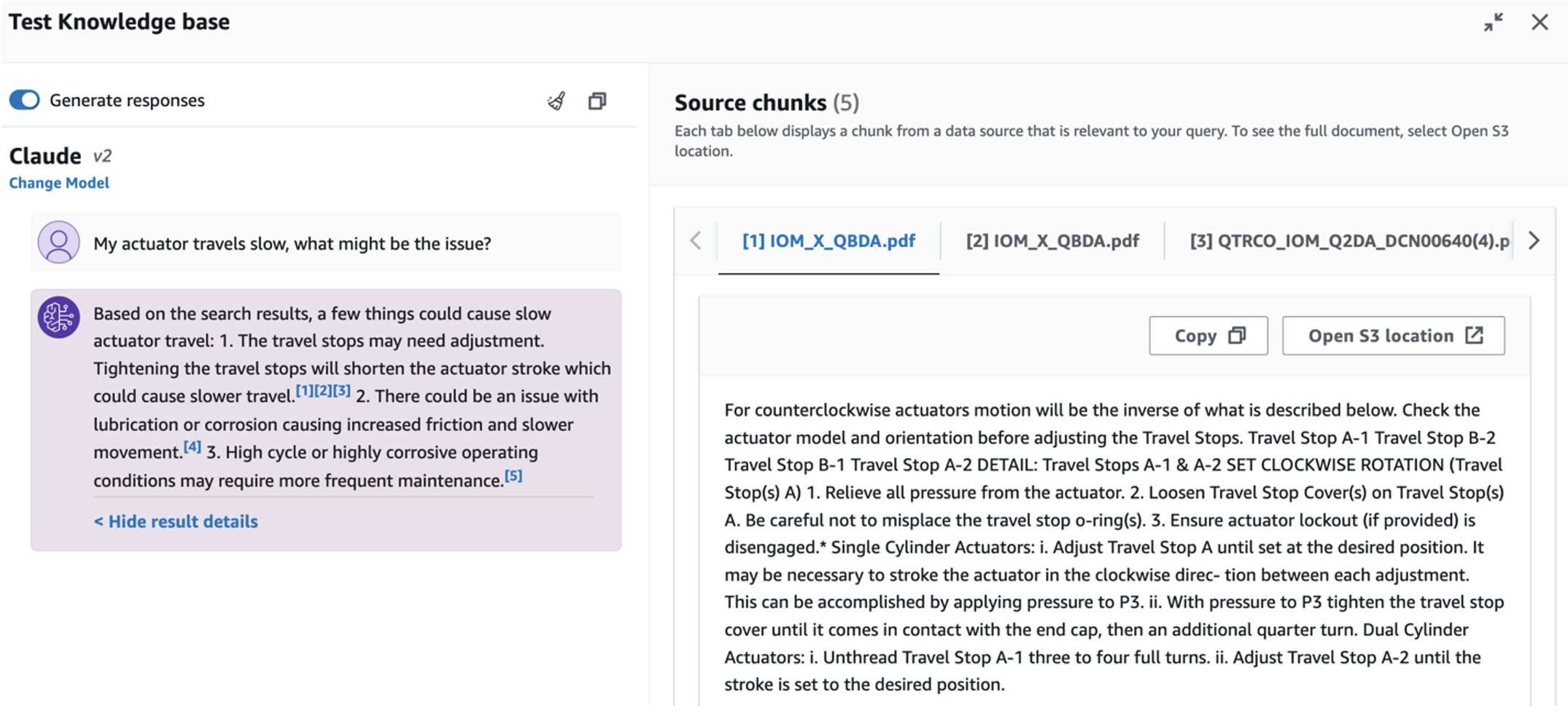
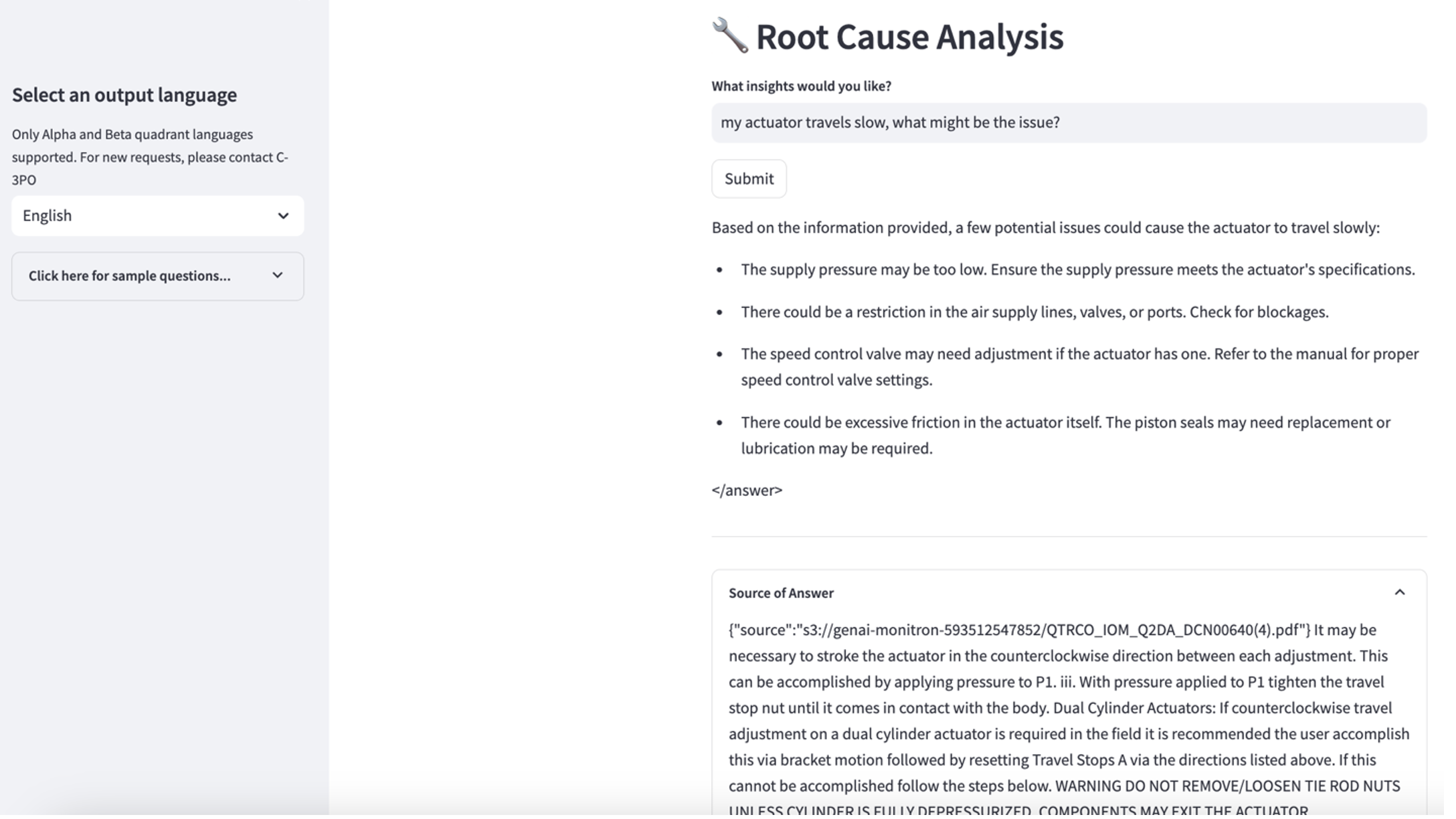
- ナレッジ ベースをセットアップした後、「アクチュエータの動作が遅いのですが、何が問題でしょうか?」などの質問をして、根本原因を診断するための RAG アプローチをテストできます。
次のステップでは、必要なライブラリ パッケージを含むアプリを PC または EC2 インスタンス (Ubuntu Server 22.04 LTS) にデプロイします。
- AWS 認証情報を設定する ローカル PC 上の AWS CLI を使用して。簡単にするために、CloudFormation スタックのデプロイに使用したものと同じ管理者ロールを使用できます。 Amazon EC2を使用している場合は、 適切な IAM ロールをインスタンスにアタッチします.
- クローン GitHubレポ:
- ディレクトリをに変更します
unlocking-the-potential-of-generative-ai-in-industrial-operations/src実行してsetup.shこのフォルダー内のスクリプトを実行して、LangChain や PandasAI などの必要なパッケージをインストールします。cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - 次のコマンドを使用して Streamlit アプリを実行します。
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
前のステップで Amazon Bedrock に作成した OpenSearch Service コレクション ARN を指定します。
資産健全性アシスタントとチャットする
エンドツーエンドの展開が完了すると、ポート 8501 のローカルホスト経由でアプリにアクセスできるようになり、Web インターフェイスを備えたブラウザ ウィンドウが開きます。アプリを EC2 インスタンスにデプロイした場合、 セキュリティグループの受信ルールを介してポート 8501 へのアクセスを許可する。さまざまな使用例に応じて、さまざまなタブに移動できます。
ユースケース 1 を検討する
最初のユースケースを検討するには、次を選択します。 データの洞察とグラフ。まず、時系列データをアップロードします。使用する既存の時系列データ ファイルがない場合は、次のファイルをアップロードできます。 サンプルCSVファイル 匿名の Amazon Monitron プロジェクト データを使用します。すでに Amazon Monitron プロジェクトがある場合は、以下を参照してください。 Amazon Monitron と Amazon Kinesis を使用して、予測メンテナンス管理のための実用的な洞察を生成します Amazon Monitron データを Amazon S3 にストリーミングし、このアプリケーションでデータを使用します。
アップロードが完了したら、クエリを入力してデータとの会話を開始します。左側のサイドバーには、便宜のためにさまざまな質問例が表示されます。次のスクリーンショットは、「それぞれ警告またはアラームとして表示される各サイトのセンサーの固有の数を教えてください。」などの質問を入力したときに FM によって生成される応答と Python コードを示しています。 (難しいレベルの質問) または「温度信号が異常と表示されたセンサーについて、異常な振動信号が表示された各センサーの持続時間を日数で計算できますか?」 (チャレンジレベルの質問)。アプリはあなたの質問に答え、そのような結果を生成するために実行したデータ分析の Python スクリプトも表示します。


答えに満足したら、次のようにマークできます。 役立ちます、NLQ および Claude で生成された Python コードを OpenSearch サービス インデックスに保存します。

ユースケース 2 を検討する
2 番目の使用例を検討するには、 キャプチャ画像の概要 Streamlit アプリのタブ。産業資産の画像をアップロードすると、アプリケーションは画像情報に基づいて技術仕様と動作条件の 200 ワードの概要を生成します。次のスクリーンショットは、ベルト モーター ドライブのイメージから生成された概要を示しています。この機能をテストするには、適切な画像がない場合は、次のコマンドを使用できます。 サンプル画像.
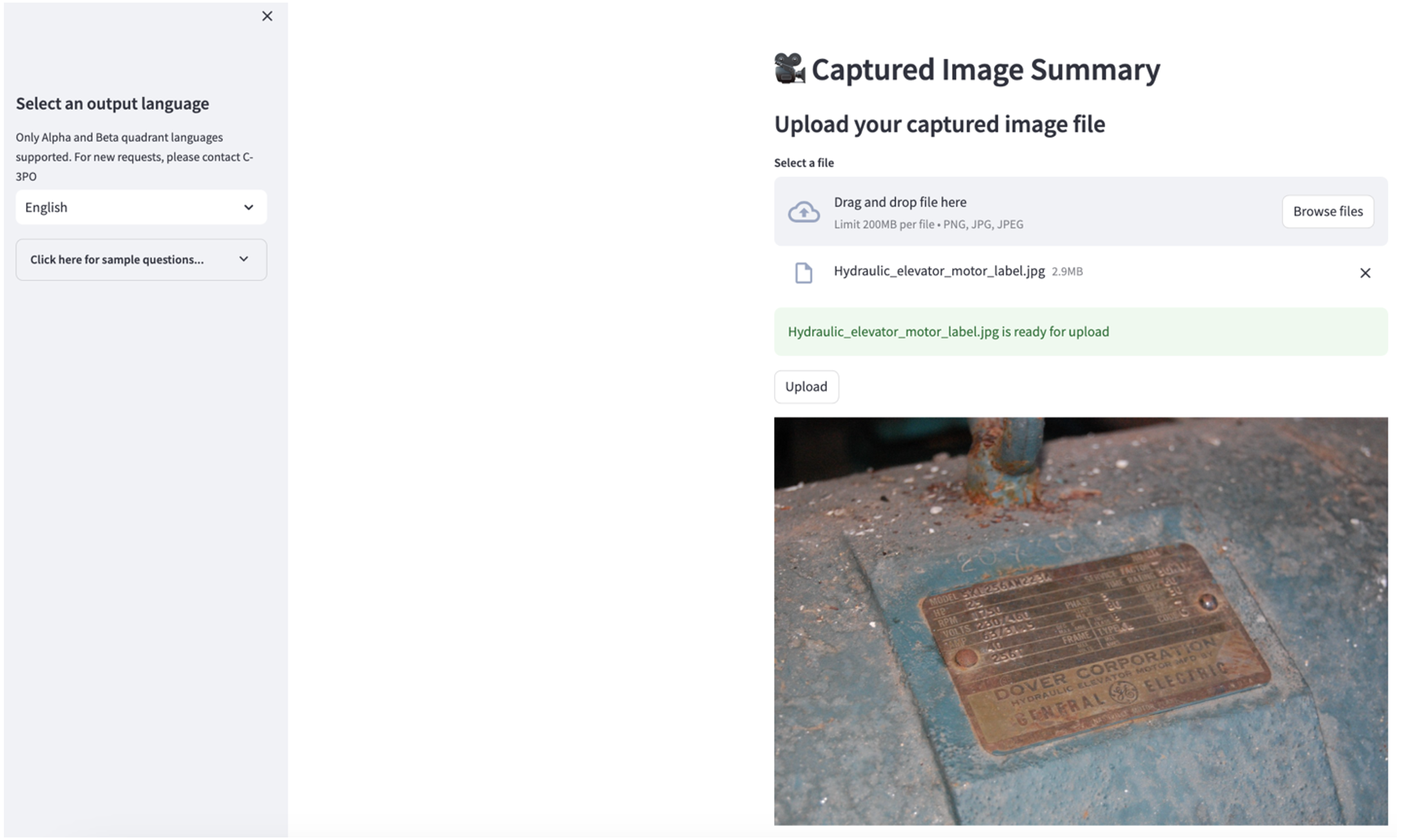
油圧エレベーターモーターのラベル」クラレンス・リッシャー著は以下のライセンスを取得しています CC BY-SA 2.0.

ユースケース 3 を検討する
3 番目の使用例を検討するには、 根本原因の診断 タブ。 「アクチュエータの動作が遅いのですが、何が原因でしょうか?」など、壊れた工業用資産に関連するクエリを入力します。次のスクリーンショットに示されているように、アプリケーションは、回答の生成に使用されたソース ドキュメントの抜粋を含む応答を送信します。
使用例 1: 設計の詳細
このセクションでは、最初の使用例のアプリケーション ワークフローの設計の詳細について説明します。
カスタムプロンプトの構築
ユーザーの自然言語クエリには、簡単、難しい、挑戦的な、さまざまな難易度のレベルがあります。
率直な質問には、次のようなリクエストが含まれる場合があります。
- 一意の値を選択してください
- 合計数を数える
- 値の並べ替え
これらの質問に対して、PandasAI は FM と直接対話して、処理用の Python スクリプトを生成できます。
難しい質問には、次のような基本的な集計操作または時系列分析が必要です。
- 最初に値を選択し、結果を階層的にグループ化します
- 最初のレコード選択後に統計を実行する
- タイムスタンプ数 (最小値と最大値など)
難しい質問については、詳細なステップバイステップの指示が記載されたプロンプト テンプレートを使用すると、FM が正確に回答できるようになります。
チャレンジレベルの質問には、次のような高度な数学計算と時系列処理が必要です。
- 各センサーの異常継続時間を計算
- サイトの異常センサーを月次で計算します
- 正常な動作時と異常な状態でのセンサーの読み取り値を比較します
これらの質問に対しては、カスタム プロンプトでマルチショットを使用して応答の精度を高めることができます。このようなマルチショットは、高度な時系列処理と数学的計算の例を示し、FM が同様の分析で関連する推論を実行するためのコンテキストを提供します。 NLQ 質問バンクから最も関連性の高い例をプロンプトに動的に挿入するのは困難な場合があります。 1 つの解決策は、既存の NLQ 質問サンプルからエンベディングを構築し、これらのエンベディングを OpenSearch Service などのベクター ストアに保存することです。質問が Streamlit アプリに送信されると、質問は次によってベクトル化されます。 岩盤埋め込み。その質問に最も関連性の高い上位 N 個の埋め込みは、次のコマンドを使用して取得されます。 opensearch_vector_search.similarity_search マルチショット プロンプトとしてプロンプト テンプレートに挿入されます。
次の図は、このワークフローを示しています。
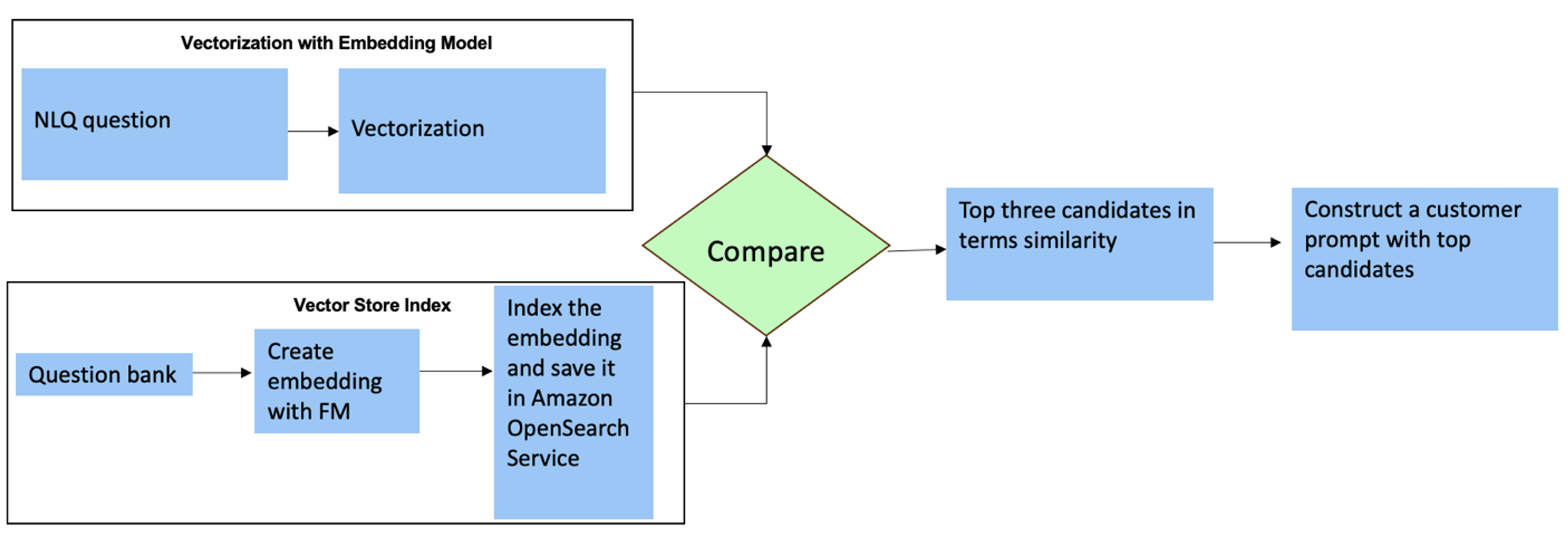
埋め込み層は、次の 3 つの主要なツールを使用して構築されます。
- 埋め込みモデル – Amazon Bedrock から入手できる Amazon Titan 埋め込みを使用します (amazon.titan-embed-text-v1) テキスト文書の数値表現を生成します。
- ベクターストア – ベクター ストアでは、LangChain フレームワーク経由で OpenSearch サービスを使用し、このノートブックの NLQ サンプルから生成された埋め込みのストレージを合理化します。
- インデックス – OpenSearch Service インデックスは、入力埋め込みとドキュメント埋め込みを比較し、関連するドキュメントの検索を容易にする上で極めて重要な役割を果たします。 Python サンプル コードは JSON ファイルとして保存されているため、OpenSearch Service では、 OpenSearchVevtorSearch.fromtexts API呼び出し。
Streamlit を介して人間が監査したサンプルを継続的に収集
アプリ開発の初めに、OpenSearch Service インデックスに埋め込みとして 23 個のサンプルを保存することから始めました。アプリが現場で稼働すると、ユーザーはアプリ経由で NLQ の入力を開始します。ただし、テンプレートで使用できる例が限られているため、一部の NLQ では同様のプロンプトが見つからない場合があります。これらの埋め込みを継続的に強化し、より関連性の高いユーザー プロンプトを提供するには、Streamlit アプリを使用して人間が監査したサンプルを収集します。
アプリ内では、次の関数がこの目的を果たします。エンドユーザーが出力が役立つと判断し、選択した場合 役立ちます、アプリケーションは次の手順に従います。
- PandasAI のコールバック メソッドを使用して、Python スクリプトを収集します。
- Python スクリプト、入力質問、CSV メタデータを文字列に再フォーマットします。
- 次のコマンドを使用して、この NLQ サンプルが現在の OpenSearch Service インデックスに既に存在するかどうかを確認します。 opensearch_vector_search.similarity_search_with_score.
- 同様の例がない場合、この NLQ は次を使用して OpenSearch サービスのインデックスに追加されます。 opensearch_vector_search.add_texts.
ユーザーが選択した場合 役に立たない、何もアクションは実行されません。この反復プロセスにより、ユーザーが提供した例を組み込むことでシステムが継続的に改善されます。
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
人間による監査を組み込むことで、アプリの使用量が増えるにつれて、プロンプト埋め込みに利用できる OpenSearch Service のサンプルの量が増加します。この拡張された埋め込みデータセットにより、時間の経過とともに検索精度が向上します。具体的には、難しい NLQ の場合、同様の例を動的に挿入して各 NLQ 質問のカスタム プロンプトを構築すると、FM の応答精度は約 90% に達します。これは、マルチショット プロンプトのないシナリオと比較して 28% という顕著な増加を表します。
使用例 2: 設計の詳細
Streamlit アプリの場合 キャプチャ画像の概要 タブでは、画像ファイルを直接アップロードできます。これにより、Amazon Rekognition API (テキストの検出 API)、マシンの仕様を詳しく説明する画像ラベルからテキストを抽出します。その後、抽出されたテキストデータがプロンプトのコンテキストとして Amazon Bedrock Claude モデルに送信され、200 語の要約が生成されます。
ユーザー エクスペリエンスの観点からは、テキスト要約タスクのストリーミング機能を有効にすることが最も重要です。これにより、ユーザーは出力全体を待つのではなく、FM で生成された要約を小さなチャンクで読むことができるようになります。 Amazon Bedrock は、API 経由でストリーミングを容易にします (bedrock_runtime.invoke_model_with_response_stream).
使用例 3: 設計の詳細
このシナリオでは、RAG アプローチを採用して、根本原因分析に重点を置いたチャットボット アプリケーションを開発しました。このチャットボットは、根本原因の分析を容易にするために、軸受装置に関連する複数の文書を基にしています。この RAG ベースの根本原因分析チャットボットは、ベクトル テキスト表現または埋め込みを生成するためにナレッジ ベースを使用します。 Amazon Bedrock のナレッジベースは、データ ソースへのカスタム統合を構築したり、データ フローと RAG 実装の詳細を管理したりすることなく、取り込みから取得、プロンプト拡張に至る RAG ワークフロー全体の実装に役立つフルマネージド機能です。
Amazon Bedrock からのナレッジベースの応答に満足したら、ナレッジベースからの根本原因の応答を Streamlit アプリに統合できます。
クリーンアップ
コストを節約するには、この投稿で作成したリソースを削除します。
- Amazon Bedrock からナレッジベースを削除します。
- OpenSearch サービスのインデックスを削除します。
- genai-sagemaker CloudFormation スタックを削除します。
- EC2 インスタンスを使用して Streamlit アプリを実行した場合は、EC2 インスタンスを停止します。
まとめ
生成 AI アプリケーションはすでにさまざまなビジネス プロセスを変革し、従業員の生産性とスキル セットを向上させています。しかし、時系列データ分析の処理における FM の限界により、産業界のクライアントによる FM の十分な活用が妨げられてきました。この制約により、毎日処理される主要なデータ タイプへの生成 AI の適用が妨げられてきました。
この投稿では、産業ユーザーのこの課題を軽減するために設計された生成 AI アプリケーション ソリューションを紹介しました。このアプリケーションは、オープンソース エージェントである PandasAI を使用して、FM の時系列分析機能を強化します。このアプリは、時系列データを FM に直接送信するのではなく、PandasAI を使用して非構造化時系列データを分析するための Python コードを生成します。 Python コード生成の精度を高めるために、人間による監査を伴うカスタム プロンプト生成ワークフローが実装されました。
産業従事者は、資産の健全性に関する洞察を得ることで、根本原因の診断や部品交換計画など、さまざまなユースケースで生成 AI の可能性を最大限に活用できます。 Amazon Bedrock のナレッジベースを使用すると、開発者は RAG ソリューションを簡単に構築および管理できます。
企業データの管理と運用の軌道は、運用の健全性に関する包括的な洞察を得るために、生成 AI とのより深い統合に向かって進んでいることは間違いありません。 Amazon Bedrock が主導するこの変化は、次のような LLM の堅牢性と可能性の増大によって大幅に増幅されます。 アマゾン岩盤クロード 3 ソリューションをさらに進化させます。詳細については、次のサイトを参照してください。 Amazon Bedrock ドキュメント、実際に操作してみましょう アマゾン ベッドロック ワークショップ.
著者について
 ジュリア・フー アマゾン ウェブ サービスのシニア AI/ML ソリューション アーキテクトです。彼女はジェネレーティブ AI、応用データ サイエンス、IoT アーキテクチャを専門としています。現在、彼女は Amazon Q チームの一員であり、機械学習技術分野コミュニティのアクティブなメンバー/メンターです。彼女は、新興企業から大企業に至るまでの顧客と協力して、AWSome 生成 AI ソリューションを開発しています。彼女は、高度なデータ分析に大規模言語モデルを活用し、現実世界の課題に対処する実用的なアプリケーションを探索することに特に熱心に取り組んでいます。
ジュリア・フー アマゾン ウェブ サービスのシニア AI/ML ソリューション アーキテクトです。彼女はジェネレーティブ AI、応用データ サイエンス、IoT アーキテクチャを専門としています。現在、彼女は Amazon Q チームの一員であり、機械学習技術分野コミュニティのアクティブなメンバー/メンターです。彼女は、新興企業から大企業に至るまでの顧客と協力して、AWSome 生成 AI ソリューションを開発しています。彼女は、高度なデータ分析に大規模言語モデルを活用し、現実世界の課題に対処する実用的なアプリケーションを探索することに特に熱心に取り組んでいます。
 スディーシュ・サシダラン AWS のエネルギー チームのシニア ソリューション アーキテクトです。 Sudeesh は、新しいテクノロジーを実験し、複雑なビジネス課題を解決する革新的なソリューションを構築することが大好きです。彼がソリューションを設計したり、最新テクノロジーをいじったりしていないときは、テニスコートでバックハンドに取り組んでいるのを見つけることができます。
スディーシュ・サシダラン AWS のエネルギー チームのシニア ソリューション アーキテクトです。 Sudeesh は、新しいテクノロジーを実験し、複雑なビジネス課題を解決する革新的なソリューションを構築することが大好きです。彼がソリューションを設計したり、最新テクノロジーをいじったりしていないときは、テニスコートでバックハンドに取り組んでいるのを見つけることができます。
 ニール・デサイ は、人工知能 (AI)、データ サイエンス、ソフトウェア エンジニアリング、エンタープライズ アーキテクチャの分野で 20 年以上の経験を持つテクノロジー幹部です。 AWS では、顧客が革新的な Generative AI を活用したソリューションを構築し、ベストプラクティスを顧客と共有し、製品ロードマップを推進するのを支援する、世界規模の AI サービス専門ソリューションアーキテクトのチームを率いています。ニールは、Vestas、Honeywell、Quest Diagnostics でのこれまでの役職で、企業の業務改善、コスト削減、収益増加を支援する革新的な製品やサービスの開発と発売において指導的な役割を果たしてきました。彼はテクノロジーを使用して現実世界の問題を解決することに情熱を持っており、成功の実績を持つ戦略的思考の持ち主です。
ニール・デサイ は、人工知能 (AI)、データ サイエンス、ソフトウェア エンジニアリング、エンタープライズ アーキテクチャの分野で 20 年以上の経験を持つテクノロジー幹部です。 AWS では、顧客が革新的な Generative AI を活用したソリューションを構築し、ベストプラクティスを顧客と共有し、製品ロードマップを推進するのを支援する、世界規模の AI サービス専門ソリューションアーキテクトのチームを率いています。ニールは、Vestas、Honeywell、Quest Diagnostics でのこれまでの役職で、企業の業務改善、コスト削減、収益増加を支援する革新的な製品やサービスの開発と発売において指導的な役割を果たしてきました。彼はテクノロジーを使用して現実世界の問題を解決することに情熱を持っており、成功の実績を持つ戦略的思考の持ち主です。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

