基礎モデル (FM) は、広範囲のラベルなしの一般化されたデータセットでトレーニングされた大規模な機械学習 (ML) モデルです。 FM は、その名前が示すように、より特殊化されたダウンストリーム アプリケーションを構築するための基盤を提供し、その適応性において独特です。自然言語処理、画像の分類、傾向の予測、感情の分析、質問への回答など、さまざまなタスクを実行できます。このスケールと汎用的な適応性が、FM を従来の ML モデルと異なるものにしています。 FM はマルチモーダルです。テキスト、ビデオ、オーディオ、画像などのさまざまなデータ タイプを処理します。大規模言語モデル (LLM) は FM の一種で、膨大な量のテキスト データで事前トレーニングされており、通常はテキスト生成、インテリジェント チャットボット、要約などのアプリケーションで使用されます。
データのストリーミングにより、多様で最新の情報の継続的なフローが促進され、より正確でコンテキストに関連した出力を適応および生成するモデルの能力が強化されます。このストリーミング データの動的な統合により、 generative AI アプリケーションが状況の変化に即座に対応し、さまざまなタスクにおける適応性と全体的なパフォーマンスを向上させます。
これをよりよく理解するには、旅行者の旅行予約を支援するチャットボットを想像してください。このシナリオでは、チャットボットは航空会社の在庫、フライト状況、ホテルの在庫、最新の価格変更などにリアルタイムでアクセスする必要があります。通常、このデータはサードパーティから取得されるため、開発者はこのデータを取り込み、データの変更が発生したときにそれを処理する方法を見つける必要があります。
バッチ処理は、このシナリオには最適ではありません。データが急速に変化する場合、バッチで処理すると、チャットボットで古いデータが使用され、顧客に不正確な情報が提供され、全体的な顧客エクスペリエンスに影響を与える可能性があります。ただし、ストリーム処理を使用すると、チャットボットがリアルタイム データにアクセスし、在庫状況や価格の変化に適応できるようになり、顧客に最適なガイダンスを提供し、顧客エクスペリエンスを向上させることができます。
もう 1 つの例は、FM がシステムのリアルタイムの内部メトリクスを監視し、アラートを生成する、AI 主導の可観測性および監視ソリューションです。モデルが異常または異常なメトリック値を検出した場合、直ちにアラートを生成し、オペレーターに通知する必要があります。ただし、そのような重要なデータの価値は時間の経過とともに大幅に減少します。これらの通知は、理想的には数秒以内、または通知の発生中に受信される必要があります。オペレーターが通知の発生から数分または数時間後にこれらの通知を受け取った場合、そのような洞察は実用的ではなく、価値を失う可能性があります。小売、自動車製造、エネルギー、金融業界などの他の業界でも同様の使用例が見つかります。
この投稿では、データ ストリーミングがそのリアルタイム性により、生成 AI アプリケーションの重要なコンポーネントである理由について説明します。以下のような AWS データ ストリーミング サービスの価値について説明します。 ApacheKafkaのAmazonマネージドストリーミング (Amazon MSK)、 Amazon Kinesisデータストリーム, Apache Flink 向け Amazon マネージドサービス, Amazon Kinesis データ ファイアホース 生成 AI アプリケーションの構築において。
インコンテキスト学習
LLM はポイントインタイム データを使用してトレーニングされており、推論時に新しいデータにアクセスする固有の機能はありません。新しいデータが出現すると、モデルを継続的に微調整したり、さらにトレーニングしたりする必要があります。これはコストがかかる操作であるだけでなく、新しいデータの生成速度が微調整の速度をはるかに上回るため、実際には非常に制限的な操作になります。さらに、LLM は文脈の理解を欠き、トレーニング データのみに依存するため、幻覚を起こしやすくなります。これは、流暢で一貫性があり、構文的には正しいが、事実としては不正確な応答を生成する可能性があることを意味します。また、関連性、パーソナライゼーション、コンテキストも欠如しています。
ただし、LLM には、モデルの重みを変更せずに、コンテキストから受信したデータから学習して、より正確に応答する機能があります。これはと呼ばれます インコンテキスト学習を使用して、パーソナライズされた回答を作成したり、組織のポリシーに基づいて正確な回答を提供したりできます。
たとえば、チャットボットでは、データ イベントは、ストリーミング ストレージ エンジンに常に取り込まれる航空券やホテルの在庫、または価格の変更に関係する可能性があります。さらに、データ イベントは、ストリーム プロセッサを使用してフィルタリングされ、強化され、利用可能な形式に変換されます。最新のスナップショットをクエリすることで、結果をアプリケーションで利用できるようになります。スナップショットはストリーム処理を通じて常に更新されます。したがって、最新のデータはモデルに対するユーザー プロンプトのコンテキストで提供されます。これにより、モデルは価格と在庫状況の最新の変化に適応できます。次の図は、基本的なコンテキスト内学習ワークフローを示しています。
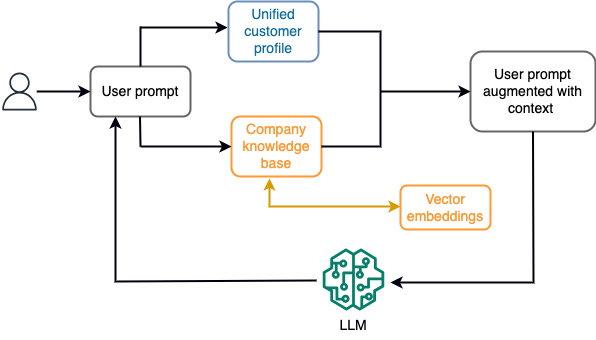
一般的に使用されるコンテキスト内学習アプローチは、検索拡張生成 (RAG) と呼ばれる手法を使用することです。 RAG では、最も関連性の高いポリシーや顧客記録などの関連情報を、ユーザーの質問とともにプロンプトに提供します。このように、LLM はコンテキストとして提供された追加情報を使用して、ユーザーの質問に対する回答を生成します。 RAG について詳しくは、以下を参照してください。 Amazon SageMaker JumpStart の基盤モデルで検索拡張生成を使用した質問応答.
RAG ベースの生成 AI アプリケーションは、トレーニング データとナレッジ ベース内の関連ドキュメントに基づいて一般的な応答のみを生成できます。アプリケーションからほぼリアルタイムのパーソナライズされた応答が期待される場合、このソリューションは不十分です。たとえば、旅行用チャットボットは、ユーザーの現在の予約、利用可能なホテルや航空券の在庫などを考慮することが期待されています。また、関連するお客様の個人データ(通称: 統一された顧客プロファイル)は通常、変更される可能性があります。生成 AI のユーザー プロファイル データベースを更新するためにバッチ プロセスが採用されている場合、顧客は古いデータに基づいて不満な応答を受け取る可能性があります。
この投稿では、リアルタイム アクセスから統合された顧客プロファイルや組織のナレッジ ベースまでのコンテキストを備えた質問応答エージェントの構築に使用される RAG ソリューションを強化するためのストリーム処理のアプリケーションについて説明します。
ほぼリアルタイムの顧客プロファイルの更新
通常、顧客レコードは組織内のデータ ストア全体に分散されます。生成 AI アプリケーションが関連性があり、正確で最新の顧客プロファイルを提供するには、分散データ ストア全体で ID 解決とプロファイル集約を実行できるストリーミング データ パイプラインを構築することが重要です。ストリーミング ジョブは、システム間で同期するために新しいデータを常に取り込み、時間枠全体でエンリッチメント、変換、結合、および集計をより効率的に実行できます。変更データ キャプチャ (CDC) イベントには、ソース レコード、更新、および時間、ソース、分類 (挿入、更新、または削除)、変更の開始者などのメタデータに関する情報が含まれています。
次の図は、CDC ストリーミングの取り込みと統合された顧客プロファイルの処理のワークフローの例を示しています。

このセクションでは、RAG ベースの生成 AI アプリケーションをサポートするために必要な CDC ストリーミング パターンの主なコンポーネントについて説明します。
CDC ストリーミング インジェスト
CDC レプリケーターは、ソース システムから (通常はトランザクション ログまたはバイナリログを読み取ることによって) データ変更を収集し、ストリーミング データ ストリームまたはトピックで発生したのとまったく同じ順序で CDC イベントを書き込むプロセスです。これには、次のようなツールを使用したログベースのキャプチャが含まれます。 AWSデータベース移行サービス (AWS DMS) または Apache Kafka 接続用の Debezium などのオープンソース コネクタ。 Apache Kafka Connect は Apache Kafka 環境の一部であり、さまざまなソースからデータを取り込み、さまざまな宛先に配信できます。 Apache Kafka コネクタは次の場所で実行できます。 アマゾンMSKコネクト Apache Kafka クラスターの構成、セットアップ、操作について心配することなく、数分以内に実行できます。コネクタのコンパイル済みコードをアップロードするだけです。 Amazon シンプル ストレージ サービス (Amazon S3) を作成し、ワークロード固有の構成でコネクタをセットアップします。
データ変更をキャプチャする他の方法もあります。例えば、 Amazon DynamoDB CDC データをストリーミングする機能を提供します AmazonDynamoDBストリーム またはKinesis Data Streams。 Amazon S3 は、 AWSラムダ 新しい文書が保存されたときの機能。
ストリーミングストレージ
ストリーミング ストレージは、CDC イベントが処理される前に格納する中間バッファとして機能します。ストリーミング ストレージは、ストリーミング データのための信頼性の高いストレージを提供します。設計上、可用性が高く、ハードウェアまたはノードの障害に対する回復力が高く、イベントが書き込まれたときの順序が維持されます。ストリーミング ストレージは、データ イベントを永続的に、または一定期間保存できます。これにより、障害が発生した場合や再処理が必要な場合に、ストリーム プロセッサがストリームの一部から読み取ることができます。 Kinesis Data Streams は、大規模なデータ ストリームのキャプチャ、処理、保存を簡単にするサーバーレス ストリーミング データ サービスです。 Amazon MSK は、Apache Kafka を実行するために AWS が提供するフルマネージドで可用性が高く、安全なサービスです。
ストリーム処理
ストリーム処理システムは、高いデータ スループットを処理できるように並列処理を考慮して設計する必要があります。複数の計算ノードで実行されている複数のタスク間で入力ストリームを分割する必要があります。タスクは、ある操作の結果をネットワーク経由で次の操作に送信できる必要があり、これにより、結合、フィルタリング、エンリッチメント、集計などの操作を実行しながらデータを並列処理できるようになります。ストリーム処理アプリケーションは、イベントが遅れて到着する可能性があるユースケースや、正しい計算がシステム時間ではなくイベントの発生時間に依存するユースケースでは、イベント時間を考慮してイベントを処理できる必要があります。詳細については、以下を参照してください。 時間の概念: イベント時間と処理時間.
ストリーム プロセスは、ターゲット システムに出力する必要があるデータ イベントの形式で結果を継続的に生成します。ターゲット システムは、プロセスと直接統合できるシステム、または仲介としてストリーミング ストレージを介して統合できる任意のシステムです。ストリーム処理用に選択したフレームワークに応じて、利用可能なシンク コネクタに応じてターゲット システムのオプションが異なります。結果を中間ストリーミング ストレージに書き込むことにした場合は、Apache Kafka シンク コネクタを実行するなど、イベントを読み取り、ターゲット システムに変更を適用する別のプロセスを構築できます。どのオプションを選択するかに関係なく、CDC データはその性質上、特別な処理が必要です。 CDC イベントには更新または削除に関する情報が含まれるため、これらのイベントが正しい順序でターゲット システムにマージされることが重要です。変更が間違った順序で適用されると、ターゲット システムはソースと同期しなくなります。
ApacheFlink は、低遅延と高スループット機能で知られる強力なストリーム処理フレームワークです。イベント時処理、1 回限りの処理セマンティクス、および高いフォールト トレランスをサポートします。さらに、と呼ばれる特別な構造を介して CDC データのネイティブ サポートを提供します。 動的テーブル。動的テーブルはソース データベース テーブルを模倣し、ストリーミング データの列形式の表現を提供します。動的テーブル内のデータは、イベントが処理されるたびに変更されます。新しいレコードはいつでも追加、更新、削除できます。動的テーブルは、レコード操作 (挿入、更新、削除) ごとに個別に実装する必要がある追加のロジックを抽象化します。詳細については、以下を参照してください。 動的テーブル.
Apache Flink 向け Amazon マネージドサービス、Apache Flink ジョブを実行し、他の AWS サービスと統合できます。管理するサーバーやクラスターはなく、セットアップするコンピューティング インフラストラクチャやストレージ インフラストラクチャもありません。
AWSグルー はフルマネージドの抽出、変換、ロード (ETL) サービスです。つまり、AWS がインフラストラクチャのプロビジョニング、スケーリング、メンテナンスを処理します。 AWS Glue は主に ETL 機能で知られていますが、Spark ストリーミング アプリケーションにも使用できます。 AWS Glue は、CDC データを処理および変換するために、Kinesis Data Streams や Amazon MSK などのストリーミング データ サービスと対話できます。 AWS Glue は、Lambda などの他の AWS サービスとシームレスに統合することもできます。 AWSステップ関数、DynamoDB は、データ処理パイプラインを構築および管理するための包括的なエコシステムを提供します。
統合された顧客プロファイル
さまざまなソース システムにわたる顧客プロファイルの統一を克服するには、堅牢なデータ パイプラインの開発が必要です。すべてのレコードを 1 つのデータ ストアに取り込んで同期できるデータ パイプラインが必要です。このデータ ストアは、RAG ベースの生成 AI アプリケーションの運用効率化に必要な包括的な顧客レコード ビューを組織に提供します。このようなデータ ストアを構築するには、非構造化データ ストアが最適です。
ID グラフは、さまざまなソースからの顧客データを統合して統合し、データの正確性と重複排除を保証し、リアルタイムの更新を提供し、システム間の洞察を接続し、パーソナライゼーションを可能にし、顧客エクスペリエンスを向上させ、統合された顧客プロファイルを作成するのに便利な構造です。規制順守をサポートします。この統合された顧客プロファイルにより、生成 AI アプリケーションが顧客を効果的に理解して顧客と関わり、データ プライバシー規制を順守できるようになり、最終的に顧客エクスペリエンスが向上し、ビジネスの成長が促進されます。次を使用してアイデンティティ グラフ ソリューションを構築できます。 アマゾン海王星、高速で信頼性の高い、フルマネージドのグラフ データベース サービスです。
AWS は、非構造化キー/値オブジェクト用のマネージドおよびサーバーレス NoSQL ストレージ サービスを他にもいくつか提供しています。 アマゾンドキュメントDB (MongoDB との互換性を備えた) は、高速、スケーラブル、高可用性のフルマネージド エンタープライズです 文書データベース ネイティブ JSON ワークロードをサポートするサービス。 DynamoDB は、シームレスなスケーラビリティを備えた高速で予測可能なパフォーマンスを提供するフルマネージド NoSQL データベース サービスです。
ほぼリアルタイムの組織ナレッジベースの更新
顧客記録と同様に、企業ポリシーや組織文書などの内部ナレッジ リポジトリは、ストレージ システム全体にサイロ化されています。これは通常、非構造化データであり、非増分方式で更新されます。 AI アプリケーションでの非構造化データの使用は、テキスト ファイル、画像、オーディオ ファイルなどの高次元データを多次元数値として表現する手法であるベクトル埋め込みを使用すると効果的です。
AWS はいくつかのサービスを提供しています ベクトルエンジンサービス、 といった Amazon OpenSearch サーバーレス, アマゾンケンドラ, AmazonAuroraPostgreSQL互換版 ベクトル埋め込みを保存するための pgvector 拡張子を使用します。生成 AI アプリケーションは、ユーザー プロンプトをベクトルに変換し、それを使用してベクトル エンジンにクエリを実行し、コンテキストに関連する情報を取得することで、ユーザー エクスペリエンスを向上させることができます。その後、プロンプトと取得されたベクトル データの両方が LLM に渡され、より正確でパーソナライズされた応答が返されます。
次の図は、ベクトル埋め込みのストリーム処理ワークフローの例を示しています。
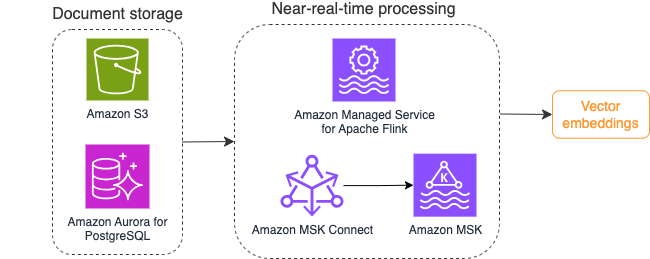
ナレッジ ベースのコンテンツは、ベクトル データ ストアに書き込む前にベクトル埋め込みに変換する必要があります。 アマゾンの岩盤 or アマゾンセージメーカー 選択したモデルにアクセスし、この変換用のプライベート エンドポイントを公開するのに役立ちます。さらに、LangChain などのライブラリを使用して、これらのエンドポイントと統合できます。バッチ プロセスを構築すると、ナレッジ ベースのコンテンツをベクトル データに変換し、最初にベクトル データベースに保存するのに役立ちます。ただし、ベクター データベースとナレッジ ベース コンテンツの変更を同期するには、一定の間隔でドキュメントを再処理する必要があります。ドキュメントの数が多い場合、このプロセスは非効率になる可能性があります。これらの間隔の間に、生成 AI アプリケーションのユーザーは古いコンテンツに従って回答を受け取るか、新しいコンテンツがまだベクトル化されていないために不正確な回答を受け取ることになります。
ストリーム処理は、これらの課題に対する理想的なソリューションです。最初は既存のドキュメントに従ってイベントを生成し、さらにソース システムを監視して、イベントが発生するとすぐにドキュメント変更イベントを作成します。これらのイベントはストリーミング ストレージに保存し、ストリーミング ジョブによる処理を待つことができます。ストリーミング ジョブは、これらのイベントを読み取り、ドキュメントのコンテンツをロードし、そのコンテンツを関連する単語のトークンの配列に変換します。各トークンは、埋め込み FM への API 呼び出しを介してベクトル データにさらに変換されます。結果は、シンク オペレーターを介してベクトル ストレージに保存のために送信されます。
ドキュメントの保存に Amazon S3 を使用している場合は、Lambda の S3 オブジェクト変更トリガーに基づいてイベントソース アーキテクチャを構築できます。 Lambda 関数は、希望の形式でイベントを作成し、それをストリーミング ストレージに書き込むことができます。
Apache Flink を使用してストリーミング ジョブとして実行することもできます。 Apache Flink は、既存のファイルを検出してその内容を最初に読み取ることができるネイティブ FileSystem ソース コネクタを提供します。その後、ファイル システムを継続的に監視して新しいファイルがないかそのコンテンツをキャプチャできます。このコネクタは、Amazon S3 や HDFS などの分散ファイル システムからプレーン テキスト、Avro、CSV、Parquet などの形式で一連のファイルを読み取ることをサポートし、ストリーミング レコードを生成します。フルマネージド サービスである Apache Flink のマネージド サービスは、Flink ジョブのデプロイと保守にかかる運用上のオーバーヘッドを排除し、ストリーミング アプリケーションの構築とスケーリングに集中できるようにします。 Amazon MSK や Kinesis Data Streams などの AWS ストリーミング サービスへのシームレスな統合により、自動スケーリング、セキュリティ、復元力などの機能が提供され、リアルタイム ストリーミング データを処理するための信頼性が高く効率的な Flink アプリケーションが提供されます。
DevOps の設定に基づいて、ストリーミング レコードの保存に Kinesis Data Streams または Amazon MSK のいずれかを選択できます。 Kinesis Data Streams は、カスタムストリーミングデータアプリケーションの構築と管理の複雑さを簡素化し、インフラストラクチャのメンテナンスではなく、データから洞察を引き出すことに集中できるようにします。 Apache Kafka を使用する顧客は、AWS 環境内で Apache Kafka クラスターを監視する際の簡単さ、拡張性、信頼性により、Amazon MSK を選択することがよくあります。フルマネージド型サービスである Amazon MSK は、Apache Kafka クラスターのデプロイと保守に伴う運用の複雑さを引き受け、ストリーミング アプリケーションの構築と拡張に集中できるようにします。
RESTful API 統合はこのプロセスの性質に適しているため、失敗を追跡し、失敗したリクエストを再試行するには、RESTful API 呼び出しを介したステートフル エンリッチメント パターンをサポートするフレームワークが必要です。 Apache Flink もまた、メモリ上の速度でステートフルな操作を実行できるフレームワークです。 Apache Flink 経由で API 呼び出しを行う最良の方法を理解するには、以下を参照してください。 Amazon Kinesis Data Analytics for Apache Flink の一般的なストリーミング データ強化パターン.
Apache Flink は、pgvector を使用した Amazon Aurora for PostgreSQL やベクター データストアにデータを書き込むためのネイティブ シンク コネクタを提供します。 AmazonOpenSearchサービス VectorDB を使用します。あるいは、Flink ジョブの出力 (ベクトル化されたデータ) を MSK トピックまたは Kinesis データストリームにステージングすることもできます。 OpenSearch Service は、Kinesis データストリームまたは MSK トピックからのネイティブ取り込みのサポートを提供します。詳細については、以下を参照してください。 Amazon OpenSearch インジェストのソースとして Amazon MSK を導入 & Amazon Kinesis Data Streams からストリーミング データをロードする.
フィードバック分析と微調整
データ操作マネージャーと AI/ML 開発者にとって、生成 AI アプリケーションと使用中の FM のパフォーマンスについて洞察を得ることが重要です。これを実現するには、ユーザーのフィードバック、さまざまなアプリケーション ログおよびメトリクスに基づいて重要な主要業績評価指標 (KPI) データを計算するデータ パイプラインを構築する必要があります。この情報は、関係者が FM、アプリケーションのパフォーマンス、およびアプリケーションから受けられるサポートの品質に関する全体的なユーザーの満足度についてリアルタイムで洞察を得るのに役立ちます。また、ドメイン固有のタスクを実行する能力を向上させるために FM をさらに微調整するために、会話履歴を収集して保存する必要もあります。
このユースケースは、ストリーミング分析ドメインに非常によく適合します。アプリケーションでは、各会話をストリーミング ストレージに保存する必要があります。アプリケーションは、各回答の正確さの評価と全体的な満足度をユーザーに尋ねることができます。このデータは、二者択一の形式または自由形式のテキストの形式にすることができます。このデータは Kinesis データストリームまたは MSK トピックに保存でき、処理されてリアルタイムで KPI を生成できます。ユーザーの感情分析に FM を活用できます。 FM は各回答を分析し、ユーザー満足度のカテゴリを割り当てることができます。
Apache Flink のアーキテクチャにより、時間枠にわたる複雑なデータの集約が可能になります。また、データ イベントのストリームに対する SQL クエリのサポートも提供します。したがって、Apache Flink を使用すると、使い慣れた SQL クエリを作成して、生のユーザー入力を迅速に分析し、リアルタイムで KPI を生成できます。詳細については、以下を参照してください。 テーブルAPIとSQL.
Apache Flink Studio 向け Amazon マネージドサービスでは、対話型ノートブックで標準 SQL、Python、Scala を使用して Apache Flink ストリーム処理アプリケーションを構築して実行できます。 Studio ノートブックは Apache Zeppelin を搭載しており、ストリーム処理エンジンとして Apache Flink を使用します。 Studio ノートブックはこれらのテクノロジーをシームレスに組み合わせて、あらゆるスキル セットの開発者がデータ ストリームの高度な分析にアクセスできるようにします。ユーザー定義関数 (UDF) のサポートにより、Apache Flink では感情分析などの複雑なタスクを実行するための FM などの外部リソースと統合するカスタム オペレーターを構築できます。 UDF を使用すると、さまざまなメトリックを計算したり、ユーザーのセンチメントなどの追加の洞察を使用してユーザー フィードバックの生データを強化したりできます。このパターンの詳細については、次を参照してください。 GenAI、Flink、Apache Kafka、Kinesis を使用して顧客の懸念にリアルタイムで積極的に対処します.
Apache Flink Studio のマネージド サービスを使用すると、ワンクリックで Studio ノートブックをストリーミング ジョブとしてデプロイできます。 Apache Flink が提供するネイティブ シンク コネクタを使用して、出力を選択したストレージに送信したり、Kinesis データ ストリームまたは MSK トピックにステージングしたりできます。 Amazonレッドシフト と OpenSearch Service はどちらも分析データの保存に最適です。どちらのエンジンも、分析のためにデータレイクまたはデータウェアハウスへの別のストリーミングパイプラインを介して、Kinesis Data Streams と Amazon MSK からのネイティブ取り込みサポートを提供します。
Amazon Redshift は、SQL を使用してデータ ウェアハウスとデータレイク全体の構造化データおよび半構造化データを分析し、AWS が設計したハードウェアと機械学習を使用して、大規模な場合に最高のコストパフォーマンスを提供します。 OpenSearch Service は、OpenSearch Dashboards と Kibana (バージョン 1.5 ~ 7.10) を活用した視覚化機能を提供します。
このような分析の結果をユーザー プロンプト データと組み合わせて使用すると、必要に応じて FM を微調整できます。 SageMaker は、FM を微調整する最も簡単な方法です。 SageMaker で Amazon S3 を使用すると、モデルを微調整するための強力かつシームレスな統合が実現します。 Amazon S3 は、スケーラブルで耐久性のあるオブジェクト ストレージ ソリューションとして機能し、大規模なデータセット、トレーニング データ、モデル アーティファクトの簡単な保存と取得を可能にします。 SageMaker は、ML ライフサイクル全体を簡素化するフルマネージド ML サービスです。 Amazon S3 を SageMaker のストレージ バックエンドとして使用すると、SageMaker のトレーニングおよびデプロイ機能とシームレスに統合しながら、Amazon S3 のスケーラビリティ、信頼性、コスト効率の恩恵を受けることができます。この組み合わせにより、効率的なデータ管理が可能になり、協調的なモデル開発が容易になり、ML ワークフローが合理化されてスケーラブルになり、最終的に ML プロセス全体の俊敏性とパフォーマンスが向上します。詳細については、以下を参照してください。 @remote デコレータを使用して Amazon SageMaker 上の Falcon 7B およびその他の LLM を微調整する.
ファイル システム シンク コネクタを使用すると、Apache Flink ジョブはデータ オブジェクトとしてオープン形式 (JSON、Avro、Parquet など) ファイルでデータを Amazon S3 に配信できます。トランザクション データ レイク フレームワーク (Apache Hudi、Apache Iceberg、Delta Lake など) を使用してデータ レイクを管理する場合、これらのフレームワークはすべて Apache Flink 用のカスタム コネクタを提供します。詳細については、を参照してください。 Amazon MSK Connect、Apache Flink、およびApache Hudiを使用して、低レイテンシのソースからデータレイクへのパイプラインを作成します.
まとめ
RAG モデルに基づく生成 AI アプリケーションの場合は、2 つのデータ ストレージ システムの構築を検討する必要があり、すべてのソース システムでシステムを最新の状態に保つデータ操作を構築する必要があります。従来のバッチ ジョブでは、生成 AI アプリケーションと統合するために必要なデータのサイズと多様性を処理するには不十分です。ソース システムの変更の処理が遅れると、応答が不正確になり、生成 AI アプリケーションの効率が低下します。データ ストリーミングを使用すると、さまざまなシステムのさまざまなデータベースからデータを取り込むことができます。また、多くのソースにわたるデータをほぼリアルタイムで効率的に変換、強化、結合、集約することもできます。データ ストリーミングは、アプリケーションの応答に対するユーザーのリアルタイムの反応やコメントを収集して変換するための簡略化されたデータ アーキテクチャを提供し、モデルの微調整のために結果をデータ レイクに配信して保存するのに役立ちます。データ ストリーミングは、変更イベントのみを処理することでデータ パイプラインを最適化することにも役立ち、データの変更により迅速かつ効率的に対応できるようになります。
詳細については、こちらから AWS データストリーミングサービス 独自のデータ ストリーミング ソリューションの構築を始めましょう。
著者について
 アリ・アレミ AWSのストリーミングスペシャリストソリューションアーキテクトです。 Aliは、AWSのお客様にアーキテクチャのベストプラクティスをアドバイスし、信頼性、安全性、効率性、費用効果の高いリアルタイム分析データシステムの設計を支援します。 彼は顧客のユースケースから逆戻りし、ビジネス上の問題を解決するためのデータソリューションを設計します。 AWSに参加する前、Aliは、アプリケーションのモダナイゼーションの過程とクラウドへの移行において、いくつかの公共部門の顧客とAWSコンサルティングパートナーをサポートしていました。
アリ・アレミ AWSのストリーミングスペシャリストソリューションアーキテクトです。 Aliは、AWSのお客様にアーキテクチャのベストプラクティスをアドバイスし、信頼性、安全性、効率性、費用効果の高いリアルタイム分析データシステムの設計を支援します。 彼は顧客のユースケースから逆戻りし、ビジネス上の問題を解決するためのデータソリューションを設計します。 AWSに参加する前、Aliは、アプリケーションのモダナイゼーションの過程とクラウドへの移行において、いくつかの公共部門の顧客とAWSコンサルティングパートナーをサポートしていました。
 Imtiaz(Taz)は言った は、AWS の分析分野における世界的な技術リーダーです。彼は、データと分析に関するあらゆることに関してコミュニティと関わることを楽しんでいます。彼には次の方法で連絡できます LinkedIn.
Imtiaz(Taz)は言った は、AWS の分析分野における世界的な技術リーダーです。彼は、データと分析に関するあらゆることに関してコミュニティと関わることを楽しんでいます。彼には次の方法で連絡できます LinkedIn.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

