現在、金融サービス、ヘルスケアとライフ サイエンス、旅行とホスピタリティ、メディアとエンターテイメント、電気通信、サービスとしてのソフトウェア (SaaS)、さらには独自のモデル プロバイダーなど、あらゆる業界の顧客が大規模言語モデル (LLM) を使用して、質問と回答 (QnA) チャットボット、検索エンジン、ナレッジ ベースなどのアプリケーションを構築します。これら generative AI アプリケーションは、既存のビジネス プロセスを自動化するために使用されるだけでなく、これらのアプリケーションを使用して顧客のエクスペリエンスを変革する機能も備えています。のような LLM の進歩により、 Mixtral-8x7B 命令、などのアーキテクチャの派生。 専門家の混合(環境省)、顧客は、幅広いクローズド ソース モデルとオープン ソース モデルを効果的に使用しながら、生成 AI アプリケーションのパフォーマンスと精度を向上させる方法を継続的に模索しています。
LLM の出力の精度とパフォーマンスを向上させるには、通常、次のような微調整などの多くの手法が使用されます。 パラメータ効率的な微調整 (PEFT), 人間のフィードバックから学ぶ強化(RLHF)、そしてパフォーマンス 知識蒸留。ただし、生成 AI アプリケーションを構築する場合は、既存の基本モデルを微調整することなく、外部知識の動的な組み込みを可能にし、生成に使用される情報を制御できる代替ソリューションを使用できます。ここで、これまで説明してきたより高価で堅牢な微調整代替手段とは対照的に、特に生成 AI アプリケーションの場合に、検索拡張生成 (RAG) が登場します。複雑な RAG アプリケーションを日常業務に実装している場合、不正確な検索、ドキュメントのサイズと複雑さの増加、コンテキストのオーバーフローなど、RAG システムでよくある課題に遭遇する可能性があり、生成される回答の品質と信頼性に大きな影響を与える可能性があります。 。
この投稿では、開発者が既存の生成 AI アプリケーションを改善できるようにするために、コンテキスト圧縮などの技術に加えて、LangChain や親ドキュメント取得ツールなどのツールを使用して応答精度を向上させる RAG パターンについて説明します。
ソリューションの概要
この投稿では、Mixtral-8x7B Instruct テキスト生成を BGE Large En 埋め込みモデルと組み合わせて使用し、親ドキュメント取得ツールとコンテキスト圧縮技術を使用して Amazon SageMaker ノートブック上に RAG QnA システムを効率的に構築する方法を示します。次の図は、このソリューションのアーキテクチャを示しています。
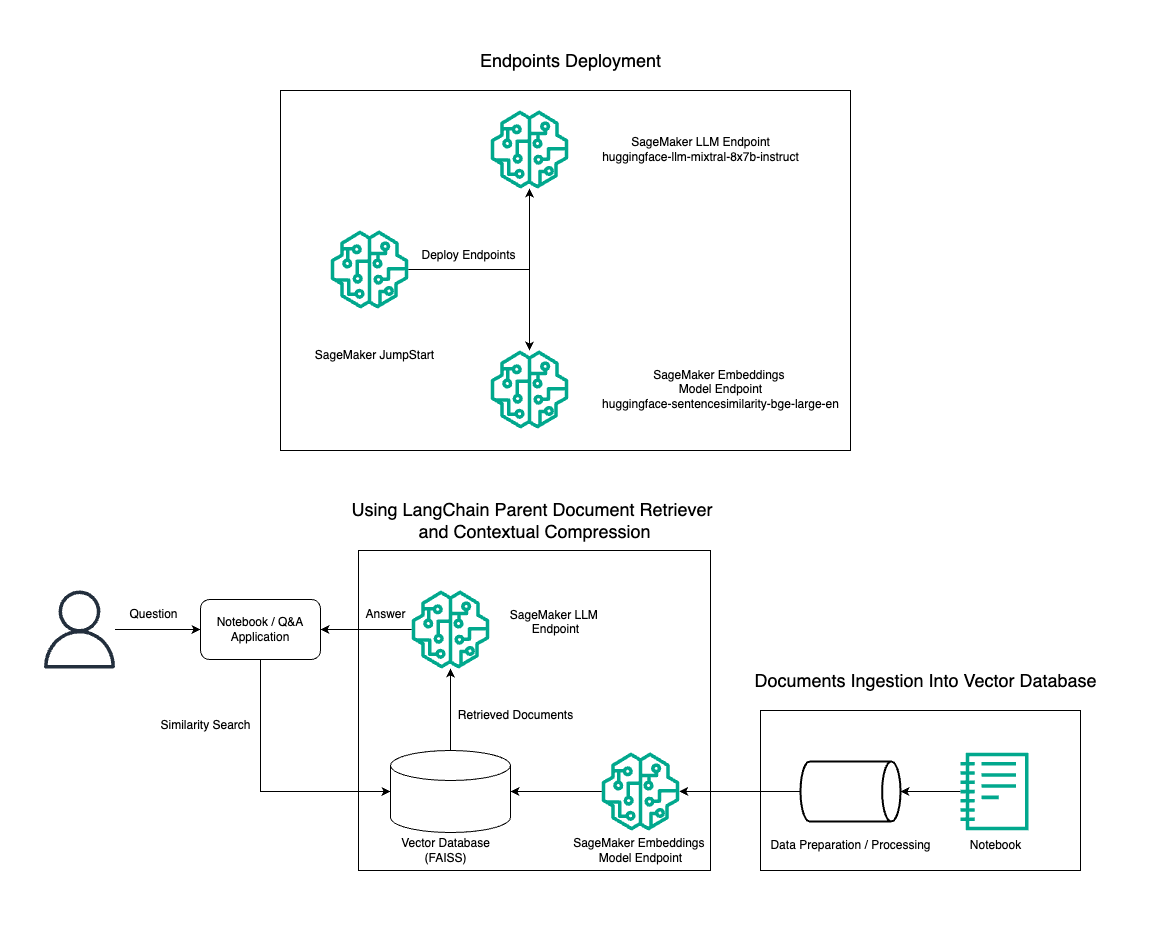
このソリューションは、次のコマンドを使用して数回クリックするだけでデプロイできます。 Amazon SageMaker ジャンプスタートは、コンテンツ作成、コード生成、質問応答、コピーライティング、要約、分類、情報検索などのさまざまなユースケースに最先端の基盤モデルを提供するフルマネージド プラットフォームです。迅速かつ簡単にデプロイできる事前トレーニング済みモデルのコレクションを提供し、機械学習 (ML) アプリケーションの開発とデプロイを加速します。 SageMaker JumpStart の重要なコンポーネントの 8 つはモデル ハブです。これは、さまざまなタスクに対応する、Mixtral-7xXNUMXB などの事前トレーニングされたモデルの膨大なカタログを提供します。
Mixtral-8x7B は MoE アーキテクチャを使用します。このアーキテクチャにより、ニューラル ネットワークのさまざまな部分がさまざまなタスクに特化できるようになり、複数の専門家間でワークロードを効果的に分割できます。このアプローチにより、従来のアーキテクチャと比較して、大規模なモデルの効率的なトレーニングとデプロイが可能になります。
MoE アーキテクチャの主な利点の 1 つは、そのスケーラビリティです。ワークロードを複数の専門家に分散することで、MoE モデルをより大きなデータセットでトレーニングでき、同じサイズの従来のモデルよりも優れたパフォーマンスを実現できます。さらに、MoE モデルは、特定の入力に対してアクティブ化する必要がある専門家のサブセットのみであるため、推論中により効率的になります。
AWS での Mixtral-8x7B Instruct の詳細については、以下を参照してください。 Mixtral-8x7B が Amazon SageMaker JumpStart で利用可能になりました。 Mixtral-8x7B モデルは、制限なく使用できる寛容な Apache 2.0 ライセンスに基づいて提供されています。
この投稿では、その使用方法について説明します ラングチェーン 効果的でより効率的な RAG アプリケーションを作成します。 LangChain は、LLM を使用してアプリケーションを構築するように設計されたオープンソースの Python ライブラリです。 LLM をナレッジ ベース、検索システム、その他の AI ツールなどの他のコンポーネントと組み合わせて、強力でカスタマイズ可能なアプリケーションを作成するためのモジュール式で柔軟なフレームワークを提供します。
Mixtral-8x7B を使用して SageMaker 上に RAG パイプラインを構築する手順を説明します。 Mixtral-8x7B Instruct テキスト生成モデルと BGE Large En 埋め込みモデルを使用して、SageMaker ノートブック上で RAG を使用する効率的な QnA システムを作成します。 ml.t3.medium インスタンスを使用して、SageMaker JumpStart 経由で LLM をデプロイする方法を示します。これには、SageMaker で生成された API エンドポイントを通じてアクセスできます。このセットアップにより、LangChain を使用した高度な RAG テクニックの探索、実験、最適化が可能になります。また、RAG ワークフローへの FAISS エンベディング ストアの統合についても説明し、システムのパフォーマンスを向上させるためのエンベディングの保存と取得におけるその役割を強調します。
SageMaker ノートブックの簡単なチュートリアルを実行します。さらに詳しい手順については、「 SageMaker Jumpstart GitHub リポジトリの Mixtral を使用した高度な RAG パターン.
高度な RAG パターンの必要性
高度な RAG パターンは、人間のようなテキストの処理、理解、生成における LLM の現在の機能を向上させるために不可欠です。ドキュメントのサイズと複雑さが増大するにつれて、ドキュメントの複数の側面を 1 つの埋め込みで表現すると、具体性が失われる可能性があります。文書の一般的な本質を捉えることは不可欠ですが、文書内のさまざまなサブコンテキストを認識して表現することも同様に重要です。これは、大きなドキュメントを扱うときによく直面する課題です。 RAG のもう 1 つの課題は、取得の場合、取り込み時にドキュメント ストレージ システムが処理する特定のクエリが分からないことです。これにより、クエリに最も関連のある情報がテキストの下に埋もれてしまう可能性があります (コンテキスト オーバーフロー)。障害を軽減し、既存の RAG アーキテクチャを改善するには、高度な RAG パターン (親ドキュメント取得機能とコンテキスト圧縮) を使用して、取得エラーを減らし、回答の品質を向上させ、複雑な質問の処理を可能にすることができます。
この投稿で説明した手法を使用すると、外部ナレッジの取得と統合に関連する主要な課題に対処でき、アプリケーションがより正確でコンテキストを認識した応答を提供できるようになります。
次のセクションでは、その方法について説明します。 親文書取得者 & コンテキスト圧縮 これまで説明してきた問題のいくつかに対処するのに役立ちます。
親文書取得者
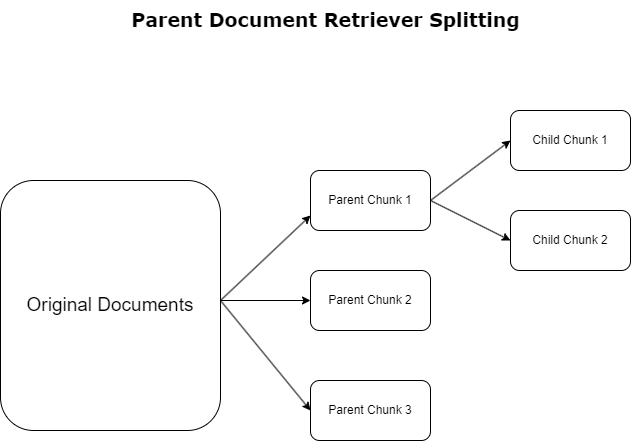
前のセクションでは、RAG アプリケーションが大量のドキュメントを処理するときに遭遇する課題を強調しました。これらの課題に対処するために、 親文書取得者 受信したドキュメントを分類して指定する 親文書。これらのドキュメントはその包括的な性質が認められていますが、元の形式で埋め込みに直接利用されることはありません。親ドキュメント取得機能は、ドキュメント全体を 1 つの埋め込みに圧縮するのではなく、これらの親ドキュメントを次のように分割します。 子ドキュメント。各子ドキュメントは、より広範な親ドキュメントから異なる側面やトピックをキャプチャします。これらの子セグメントの識別に続いて、個別のエンベディングがそれぞれに割り当てられ、特定のテーマの本質が捉えられます (次の図を参照)。取得中に、親ドキュメントが呼び出されます。この技術は、対象を絞った広範囲の検索機能を提供し、LLM に広い視野を提供します。親ドキュメント取得機能は、LLM に 2 つの利点を提供します。それは、正確で関連性の高い情報を取得するための子ドキュメントの埋め込みの特異性と、応答生成のための親ドキュメントの呼び出しと相まって、階層化された徹底的なコンテキストで LLM の出力を充実させることです。
コンテキスト圧縮
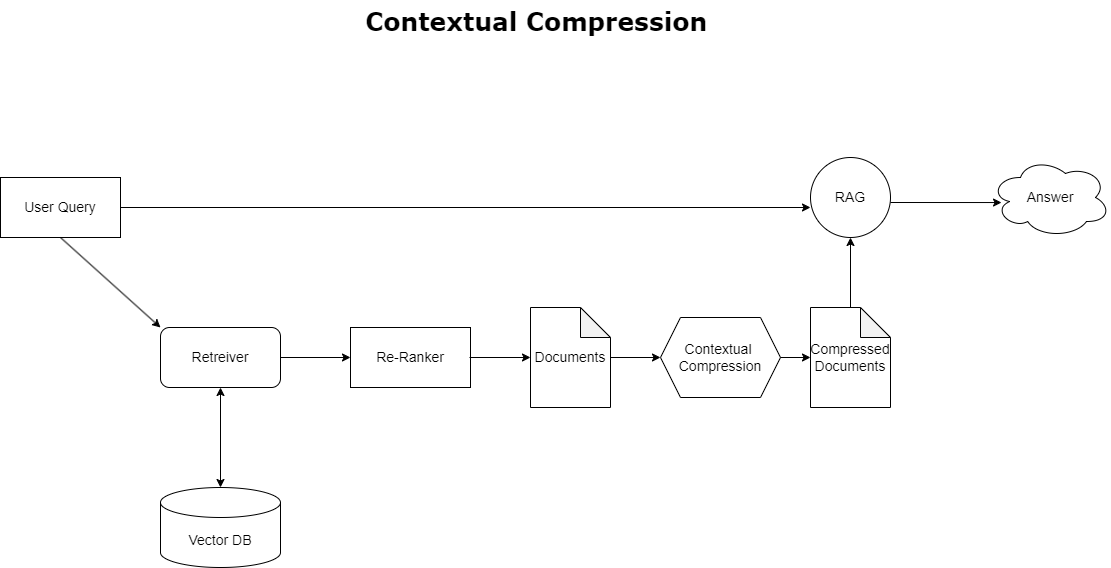
前に説明したコンテキスト オーバーフローの問題に対処するには、次を使用できます。 コンテキスト圧縮 クエリのコンテキストに合わせて取得したドキュメントを圧縮およびフィルタリングするため、関連する情報のみが保持および処理されます。これは、次の図に示すように、最初のドキュメントを取得するベース取得機能と、コンテンツを絞り込むか、関連性に基づいて完全に除外することでこれらのドキュメントを洗練するドキュメント コンプレッサーの組み合わせによって実現されます。コンテキスト圧縮リトリーバーによって促進されるこの合理化されたアプローチは、大量の情報から重要なものだけを抽出して利用する方法を提供することにより、RAG アプリケーションの効率を大幅に向上させます。情報過多と無関係なデータ処理の問題に正面から取り組み、応答品質の向上、よりコスト効率の高い LLM 運用、および全体的な取得プロセスのよりスムーズな実現につながります。基本的に、これは、手元のクエリに合わせて情報を調整するフィルターであり、RAG アプリケーションを最適化してパフォーマンスとユーザー満足度を向上させることを目指す開発者にとって非常に必要なツールとなります。
前提条件
SageMaker を初めて使用する場合は、以下を参照してください。 Amazon SageMaker 開発ガイド.
解決策を始める前に、 AWS アカウントを作成する。 AWS アカウントを作成すると、アカウント内のすべての AWS サービスとリソースに完全にアクセスできるシングル サインオン (SSO) ID を取得できます。この ID は AWS アカウントと呼ばれます rootユーザー.
サインイン AWSマネジメントコンソール アカウントの作成に使用したメールアドレスとパスワードを使用すると、アカウント内のすべての AWS リソースに完全にアクセスできます。たとえ管理用であっても、日常的なタスクには root ユーザーを使用しないことを強くお勧めします。
代わりに、 セキュリティのベストプラクティス in AWS IDおよびアクセス管理 (IAM)、および 管理ユーザーとグループを作成する。次に、root ユーザーの資格情報を安全にロックし、それらの資格情報をいくつかのアカウントおよびサービス管理タスクの実行にのみ使用します。
Mixtral-8x7b モデルには、ml.g5.48xlarge インスタンスが必要です。 SageMaker JumpStart は、100 を超えるさまざまなオープンソースおよびサードパーティの基盤モデルにアクセスしてデプロイするための簡素化された方法を提供します。するために SageMaker JumpStart から Mixtral-8x7B をホストするエンドポイントを起動します、エンドポイントを使用するために ml.g5.48xlarge インスタンスにアクセスするには、サービス クォータの増加をリクエストする必要がある場合があります。あなたはできる サービスクォータの増加をリクエストする コンソールを通じて、 AWSコマンドラインインターフェイス (AWS CLI)、またはそれらの追加リソースへのアクセスを許可する API。
SageMaker ノートブック インスタンスをセットアップし、依存関係をインストールする
まず、SageMaker ノートブック インスタンスを作成し、必要な依存関係をインストールします。を参照してください。 GitHubレポ セットアップを確実に成功させるために。ノートブック インスタンスを設定した後、モデルをデプロイできます。
好みの統合開発環境 (IDE) 上でノートブックをローカルに実行することもできます。 Jupyter ノートブック ラボがインストールされていることを確認してください。
モデルを展開する
Mixtral-8X7B Instruct LLM モデルを SageMaker JumpStart にデプロイします。
BGE Large En 埋め込みモデルを SageMaker JumpStart にデプロイします。
ラングチェーンをセットアップする
必要なライブラリをすべてインポートし、Mixtral-8x7B モデルと BGE Large En 埋め込みモデルをデプロイした後、LangChain をセットアップできるようになります。詳しい手順については、「 GitHubレポ.
データの準備
この投稿では、QnA を実行するためのテキスト コーパスとして、数年分の Amazon の株主への手紙を使用します。データを準備するための詳細な手順については、「 GitHubレポ.
質問に答える
データが準備されたら、LangChain が提供するラッパーを使用できます。このラッパーは、ベクター ストアをラップし、LLM への入力を受け取ります。このラッパーは次の手順を実行します。
- 質問を入力してください。
- 質問の埋め込みを作成します。
- 関連するドキュメントを取得します。
- 文書と質問をプロンプトに組み込みます。
- プロンプトを使用してモデルを呼び出し、読みやすい方法で回答を生成します。
ベクター ストアが配置されたので、質問を開始できます。
通常のレトリバーチェーン
前述のシナリオでは、質問に対するコンテキストを考慮した回答を得る迅速かつ簡単な方法を検討しました。次に、RetrievalQA を利用した、よりカスタマイズ可能なオプションを見てみましょう。このオプションでは、chain_type パラメーターを使用して、取得したドキュメントをプロンプトに追加する方法をカスタマイズできます。また、取得する関連ドキュメントの数を制御するために、次のコードの k パラメーターを変更して、さまざまな出力を表示できます。多くのシナリオでは、LLM が回答を生成するためにどのソース文書を使用したかを知りたい場合があります。これらのドキュメントを出力で取得するには、次を使用します。 return_source_documents、LLM プロンプトのコンテキストに追加されたドキュメントを返します。 RetrievalQA では、モデルに固有のカスタム プロンプト テンプレートを提供することもできます。
質問してみましょう:
親ドキュメント取得チェーン
次の助けを借りて、より高度な RAG オプションを見てみましょう。 親ドキュメントレトリバー。ドキュメントの取得を行う場合、正確な埋め込みのためにドキュメントの小さなチャンクを保存するか、より多くのコンテキストを保持するために大きなドキュメントを保存するかのトレードオフが発生する場合があります。親ドキュメント取得機能は、データの小さな塊を分割して保存することでバランスをとります。
我々は parent_splitter 元のドキュメントを親ドキュメントと呼ばれる大きな塊に分割し、 child_splitter 元のドキュメントから小さな子ドキュメントを作成するには、次のようにします。
次に、子ドキュメントは、埋め込みを使用してベクター ストア内でインデックス付けされます。これにより、類似性に基づいて関連する子ドキュメントを効率的に取得できるようになります。関連情報を取得するために、親ドキュメント取得機能はまずベクトル ストアから子ドキュメントをフェッチします。次に、それらの子ドキュメントの親 ID を検索し、対応するより大きな親ドキュメントを返します。
質問してみましょう:
コンテキスト圧縮チェーン
という別の高度な RAG オプションを見てみましょう。 コンテキスト圧縮。取得に関する課題の 1 つは、通常、データをシステムに取り込むときにドキュメント ストレージ システムが直面する特定のクエリがわからないことです。これは、クエリに最も関連する情報が、無関係なテキストが多く含まれる文書の中に埋もれている可能性があることを意味します。その完全なドキュメントをアプリケーションに渡すと、LLM 呼び出しがより高価になり、応答が低下する可能性があります。
コンテキスト圧縮取得機能は、大量のテキストを含む文書内に関連データが埋もれている可能性がある文書ストレージ システムから関連情報を取得するという課題に対処します。指定されたクエリ コンテキストに基づいて取得したドキュメントを圧縮およびフィルタリングすることにより、最も関連性の高い情報のみが返されます。
コンテキスト圧縮リトリーバーを使用するには、次のものが必要です。
- ベースレトリバー – これは、クエリに基づいてストレージ システムからドキュメントを取得する最初の取得者です。
- ドキュメントコンプレッサー – このコンポーネントは、最初に取得したドキュメントを取得し、クエリ コンテキストを使用して関連性を判断し、個々のドキュメントの内容を削減するか、無関係なドキュメントを完全に削除することでドキュメントを短縮します。
LLM チェーン抽出機能を使用してコンテキスト圧縮を追加する
まず、ベースレトリバーを ContextualCompressionRetriever。を追加します LLMチェーンエクストラクタこれにより、最初に返されたドキュメントが反復処理され、それぞれのドキュメントからクエリに関連するコンテンツのみが抽出されます。
を使用してチェーンを初期化します。 ContextualCompressionRetriever とともに LLMChainExtractor そして、プロンプトを経由して渡します chain_type_kwargs 引数。
質問してみましょう:
LLM チェーン フィルターを使用してドキュメントをフィルター処理する
LLMチェーンフィルター これは、ドキュメントの内容を操作することなく、LLM チェーンを使用して、最初に取得したドキュメントのうちどのドキュメントをフィルタリングして除外し、どのドキュメントを返すかを決定する、少し単純ですがより堅牢なコンプレッサーです。
を使用してチェーンを初期化します。 ContextualCompressionRetriever とともに LLMChainFilter そして、プロンプトを経由して渡します chain_type_kwargs 引数。
質問してみましょう:
結果を比較する
次の表では、さまざまなクエリの結果を手法に基づいて比較しています。
| 技術 | クエリ 1 | クエリ 2 | 比較 |
| AWS はどのように進化したのでしょうか? | なぜアマゾンは成功しているのでしょうか? | ||
| 通常のレトリーバーチェーン出力 | AWS (アマゾン ウェブ サービス) は、当初は採算が合わなかった投資から、年間 85 億ドルの収益性の高いビジネスへと進化し、幅広いサービスと機能を提供し、Amazon のポートフォリオの重要な部分を占めるようになりました。懐疑論や短期的な逆風に直面したにもかかわらず、AWS は革新を続け、新規顧客を獲得し、アクティブな顧客を移行し、機敏性、イノベーション、コスト効率、セキュリティなどのメリットを提供しました。 AWS はまた、新しい機能を提供し、顧客の可能性を変えるために、チップ開発を含む長期投資を拡大しました。 | Amazon は、継続的なイノベーションと、テクノロジー インフラストラクチャ サービス、デジタル読み取りデバイス、音声駆動型パーソナル アシスタント、サードパーティ マーケットプレイスのような新しいビジネス モデルなどの新しい分野への拡大により成功を収めています。フルフィルメントおよび輸送ネットワークの急速な拡大に見られるように、事業を迅速に拡大する能力も成功に貢献しています。さらに、Amazon はプロセスの最適化と効率向上に重点を置いているため、生産性の向上とコスト削減が実現しました。 Amazon ビジネスの例は、さまざまな分野で電子商取引と物流の強みを活用する同社の能力を浮き彫りにしています。 | 通常の取得チェーンからの応答に基づいて、長い応答が提供されているものの、コンテキスト オーバーフローが発生しており、提供されたクエリへの応答に関してコーパスからの重要な詳細がまったく言及されていないことがわかります。通常の検索チェーンでは、深みのあるニュアンスや文脈上の洞察を捉えることができず、文書の重要な側面が失われる可能性があります。 |
| 親ドキュメント取得出力 | AWS (アマゾン ウェブ サービス) は、2 年に機能が乏しい Elastic Compute Cloud (EC2006) サービスの初期立ち上げから始まり、世界の 20 つのデータセンター、XNUMX つの地域で XNUMX つのインスタンス サイズのみを提供し、Linux オペレーティング システム インスタンスのみを提供しました。 、監視、負荷分散、自動スケーリング、永続ストレージなどの多くの主要な機能がありません。しかし、AWS の成功により、欠落している機能を迅速に反復して追加することができ、最終的にはコンピューティング、ストレージ、ネットワーキングのさまざまなフレーバー、サイズ、最適化を提供するように拡張し、さらに価格とパフォーマンスをさらに高めるために独自のチップ (Graviton) を開発することができました。 。 AWS の反復的なイノベーションプロセスでは、顧客のニーズを満たし、長期的な顧客エクスペリエンス、ロイヤルティ、株主への利益を向上させるために、XNUMX 年以上にわたって資金と人的リソースへの多大な投資が必要であり、多くの場合、支払いのかなり前に行われました。 | Amazon が成功を収めているのは、常に革新し、変化する市場状況に適応し、さまざまな市場セグメントで顧客のニーズを満たす能力にあります。これは、法人顧客に品揃え、価値、利便性を提供することで、年間総売上高約 35 億ドルを生み出すまでに成長した Amazon ビジネスの成功からも明らかです。 Amazon の e コマースおよび物流機能への投資により、「Buy with Prime」のようなサービスの作成も可能になり、消費者直販 Web サイトを持つ販売業者が閲覧から購入へのコンバージョンを促進するのに役立ちます。 | 親ドキュメント取得ツールは、顧客からのフィードバックに基づいて新機能を追加する反復プロセスや、機能が乏しい初期リリースから市場で支配的な地位を獲得するまでの詳細な過程など、AWS の成長戦略の詳細をさらに深く掘り下げ、コンテキストに富んだ応答を提供します。 。回答は技術革新や市場戦略から組織の効率性や顧客重視に至るまで幅広い側面をカバーしており、成功に寄与する要因の全体像を事例とともに提供します。これは、親文書検索機能の対象を絞った広範囲にわたる検索機能に起因すると考えられます。 |
| LLM チェーン エクストラクター: コンテキスト圧縮出力 | AWS は Amazon 社内の小規模プロジェクトとしてスタートして発展しましたが、多額の設備投資が必要であり、社内外からの懐疑にも直面しました。しかし、AWS は潜在的な競合他社に先んじてスタートし、AWS が顧客と Amazon にもたらす価値を信じていました。 AWS は投資を継続するための長期的な取り組みを行い、その結果、3,300 年に 2022 を超える新機能とサービスがリリースされました。AWS は、顧客のテクノロジーインフラストラクチャの管理方法を変革し、年間売上高 85 億ドルの高い収益性を誇るビジネスになりました。 AWS はまた、最初のリリース後に追加の機能やサービスで EC2 を強化するなど、サービスを継続的に改善してきました。 | 提供されたコンテキストに基づくと、Amazon の成功は、書籍販売プラットフォームから、活発なサードパーティ販売者エコシステムを備えたグローバル マーケットプレイスへの戦略的拡大、AWS への初期投資、Kindle と Alexa の導入における革新、および大幅な成長に起因すると考えられます。この成長により、フルフィルメント センターの設置面積の拡大、ラストマイル輸送ネットワークの構築、生産性とコスト削減のために最適化された新しい仕分けセンター ネットワークの構築が行われました。 | LLM チェーン エクストラクターは、重要なポイントを包括的にカバーすることと、不必要な深さを回避することの間のバランスを維持します。クエリのコンテキストに合わせて動的に調整されるため、出力は直接関連性があり、包括的なものになります。 |
| LLM チェーン フィルター: コンテキスト圧縮出力 | AWS (アマゾン ウェブ サービス) は、当初は機能が乏しいものの、顧客のフィードバックに基づいて迅速に反復して必要な機能を追加することで進化しました。このアプローチにより、AWS は 2 年に機能を限定して EC2006 をリリースし、その後、追加のインスタンス サイズ、データセンター、リージョン、オペレーティング システム オプション、モニタリング ツール、ロード バランシング、自動スケーリング、永続ストレージなどの新しい機能を継続的に追加することができました。時間の経過とともに、AWS は顧客のニーズ、俊敏性、イノベーション、コスト効率、セキュリティに重点を置くことで、機能が乏しいサービスから数十億ドル規模のビジネスに変わりました。 AWS は現在、年間 85 億ドルの収益を上げており、毎年 3,300 を超える新機能とサービスを提供し、新興企業から多国籍企業、公共部門組織まで幅広い顧客に対応しています。 | Amazon は、革新的なビジネス モデル、継続的な技術進歩、戦略的な組織変更により成功を収めています。同社は、さまざまな製品やサービスの e コマース プラットフォーム、サードパーティ マーケットプレイス、クラウド インフラストラクチャ サービス (AWS)、Kindle 電子リーダー、Alexa 音声駆動パーソナル アシスタントなどの新しいアイデアを導入することで、伝統的な業界を常に変革してきました。 。さらに、Amazon はコストと配送時間を削減するために米国のフルフィルメント ネットワークを再編成するなど、効率を向上させるための構造的な変更を行っており、これが同社の成功にさらに貢献しています。 | LLM チェーン エクストラクターと同様に、LLM チェーン フィルターは、重要なポイントがカバーされているにもかかわらず、簡潔で状況に応じた回答を求める顧客にとって効率的な出力であることを確認します。 |
これらのさまざまな技術を比較すると、AWS の単純なサービスから複雑な数十億ドル規模の事業体への移行を詳しく説明したり、Amazon の戦略的成功を説明したりするような文脈では、通常のレトリバー チェーンには、より洗練された技術が提供する精度が欠けていることがわかります。ターゲットを絞った情報が少なくなる可能性があります。ここで説明した高度なテクニックの間にはほとんど違いはありませんが、通常のレトリーバー チェーンよりもはるかに有益です。
アプリケーションに RAG を実装しようとしている医療、電気通信、金融サービスなどの業界の顧客にとって、通常のレトリーバー チェーンは精度の提供、冗長性の回避、情報の効果的な圧縮に限界があるため、これらのニーズを満たすのにはあまり適していません。より高度な親ドキュメント取得機能とコンテキスト圧縮技術に対応します。これらの技術は、コストパフォーマンスの向上に役立ちながら、膨大な量の情報を抽出して、必要な集中的で影響力のある洞察を得ることができます。
クリーンアップ
ノートブックの実行が完了したら、使用中のリソースに対する料金が発生しないように、作成したリソースを削除します。
まとめ
この投稿では、親ドキュメント取得機能とコンテキスト圧縮チェーン技術を実装して、LLM の情報の処理と生成の能力を強化できるソリューションを紹介しました。私たちは、SageMaker JumpStart で利用可能な Mixtral-8x7B Instruct および BGE Large En モデルを使用して、これらの高度な RAG テクニックをテストしました。また、埋め込みとドキュメント チャンクのための永続ストレージの使用と、エンタープライズ データ ストアとの統合についても検討しました。
私たちが実行した手法は、LLM モデルが外部の知識にアクセスして取り込む方法を改良するだけでなく、出力の品質、関連性、効率を大幅に向上させます。これらの高度な RAG 技術により、大規模なテキスト コーパスからの検索と言語生成機能を組み合わせることで、LLM はより事実に基づいた一貫性のあるコンテキストに適した応答を生成できるようになり、さまざまな自然言語処理タスク全体でパフォーマンスが向上します。
SageMaker JumpStart は、このソリューションの中心です。 SageMaker JumpStart を使用すると、幅広いオープンおよびクローズド ソース モデルにアクセスできるようになり、ML を開始するプロセスが合理化され、迅速な実験とデプロイが可能になります。このソリューションの展開を開始するには、 GitHubレポ.
著者について
 ニーティン・ヴィジェシュワラン AWS のソリューションアーキテクトです。彼の重点分野は、生成 AI と AWS AI アクセラレーターです。彼はコンピューター サイエンスとバイオインフォマティクスの学士号を取得しています。 Niithiyn は、Generative AI GTM チームと緊密に連携して、AWS の顧客をさまざまな面でサポートし、Generative AI の導入を促進します。彼はダラス マーベリックスの熱烈なファンであり、スニーカーの収集を楽しんでいます。
ニーティン・ヴィジェシュワラン AWS のソリューションアーキテクトです。彼の重点分野は、生成 AI と AWS AI アクセラレーターです。彼はコンピューター サイエンスとバイオインフォマティクスの学士号を取得しています。 Niithiyn は、Generative AI GTM チームと緊密に連携して、AWS の顧客をさまざまな面でサポートし、Generative AI の導入を促進します。彼はダラス マーベリックスの熱烈なファンであり、スニーカーの収集を楽しんでいます。
 セバスティアン・バスティーロ AWS のソリューションアーキテクトです。彼は、生成 AI とコンピューティング アクセラレータに深い情熱を持ち、AI/ML テクノロジーに焦点を当てています。 AWS では、生成 AI を通じて顧客がビジネス価値を引き出すのを支援しています。仕事以外のときは、完璧な特製コーヒーを淹れることと、妻と一緒に世界を探索することを楽しんでいます。
セバスティアン・バスティーロ AWS のソリューションアーキテクトです。彼は、生成 AI とコンピューティング アクセラレータに深い情熱を持ち、AI/ML テクノロジーに焦点を当てています。 AWS では、生成 AI を通じて顧客がビジネス価値を引き出すのを支援しています。仕事以外のときは、完璧な特製コーヒーを淹れることと、妻と一緒に世界を探索することを楽しんでいます。
 アルマンドディアス AWS のソリューションアーキテクトです。彼は生成 AI、AI/ML、データ分析に重点を置いています。 AWS では、Armando は、顧客が最先端の生成 AI 機能をシステムに統合し、イノベーションと競争上の優位性を促進できるよう支援します。仕事以外の時は、妻や家族と時間を過ごしたり、ハイキングをしたり、世界中を旅行したりすることを楽しんでいます。
アルマンドディアス AWS のソリューションアーキテクトです。彼は生成 AI、AI/ML、データ分析に重点を置いています。 AWS では、Armando は、顧客が最先端の生成 AI 機能をシステムに統合し、イノベーションと競争上の優位性を促進できるよう支援します。仕事以外の時は、妻や家族と時間を過ごしたり、ハイキングをしたり、世界中を旅行したりすることを楽しんでいます。
 ファルーク・サビル博士 AWS のシニア人工知能および機械学習スペシャリスト ソリューション アーキテクトです。 テキサス大学オースティン校で電気工学の博士号と修士号を取得し、ジョージア工科大学でコンピューター サイエンスの修士号を取得しています。 彼は15年以上の実務経験があり、大学生を教えたり指導したりすることも好きです. AWS では、データ サイエンス、機械学習、コンピューター ビジョン、人工知能、数値最適化、および関連分野におけるビジネス上の問題を顧客が定式化して解決するのを支援しています。 テキサス州ダラスを拠点とする彼と彼の家族は、旅行が大好きで、長いドライブ旅行に出かけます。
ファルーク・サビル博士 AWS のシニア人工知能および機械学習スペシャリスト ソリューション アーキテクトです。 テキサス大学オースティン校で電気工学の博士号と修士号を取得し、ジョージア工科大学でコンピューター サイエンスの修士号を取得しています。 彼は15年以上の実務経験があり、大学生を教えたり指導したりすることも好きです. AWS では、データ サイエンス、機械学習、コンピューター ビジョン、人工知能、数値最適化、および関連分野におけるビジネス上の問題を顧客が定式化して解決するのを支援しています。 テキサス州ダラスを拠点とする彼と彼の家族は、旅行が大好きで、長いドライブ旅行に出かけます。
 マルコ・プニオ は、生成 AI 戦略、応用 AI ソリューション、および AWS での顧客のハイパースケールを支援する研究の実施に重点を置いたソリューション アーキテクトです。 Marco は、FinTech、ヘルスケアとライフ サイエンス、Software-as-a-Service、そして最近では電気通信業界での経験を持つデジタル ネイティブ クラウド アドバイザーです。彼は資格のある技術者であり、機械学習、人工知能、合併と買収に情熱を持っています。 Marco はワシントン州シアトルに拠点を置き、自由時間には執筆、読書、運動、アプリケーションの構築を楽しんでいます。
マルコ・プニオ は、生成 AI 戦略、応用 AI ソリューション、および AWS での顧客のハイパースケールを支援する研究の実施に重点を置いたソリューション アーキテクトです。 Marco は、FinTech、ヘルスケアとライフ サイエンス、Software-as-a-Service、そして最近では電気通信業界での経験を持つデジタル ネイティブ クラウド アドバイザーです。彼は資格のある技術者であり、機械学習、人工知能、合併と買収に情熱を持っています。 Marco はワシントン州シアトルに拠点を置き、自由時間には執筆、読書、運動、アプリケーションの構築を楽しんでいます。
 AJ ディミン AWS のソリューションアーキテクトです。彼は生成 AI、サーバーレス コンピューティング、データ分析を専門としています。彼は機械学習技術分野コミュニティの積極的なメンバー/メンターであり、さまざまな AI/ML トピックに関する科学論文をいくつか出版しています。彼は、新興企業から大企業に至るまでの顧客と協力して、AWSome 生成 AI ソリューションを開発しています。彼は、高度なデータ分析に大規模言語モデルを活用し、現実世界の課題に対処する実践的なアプリケーションを探索することに特に熱心に取り組んでいます。 AJ は仕事以外では旅行が好きで、現在は世界のすべての国を訪問することを目標に 53 か国を訪問しています。
AJ ディミン AWS のソリューションアーキテクトです。彼は生成 AI、サーバーレス コンピューティング、データ分析を専門としています。彼は機械学習技術分野コミュニティの積極的なメンバー/メンターであり、さまざまな AI/ML トピックに関する科学論文をいくつか出版しています。彼は、新興企業から大企業に至るまでの顧客と協力して、AWSome 生成 AI ソリューションを開発しています。彼は、高度なデータ分析に大規模言語モデルを活用し、現実世界の課題に対処する実践的なアプリケーションを探索することに特に熱心に取り組んでいます。 AJ は仕事以外では旅行が好きで、現在は世界のすべての国を訪問することを目標に 53 か国を訪問しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

