この投稿は、Snowflake の Andries Engelbrecht と Scott Teal との共同執筆です。
ビジネスは常に進化しており、データ リーダーは新しい要件を満たすことが日々求められています。多くの企業や大組織にとって、さまざまなビジネス要件に対処するために 1 つの処理エンジンやツールを使用することは現実的ではありません。彼らは、画一的なアプローチがもはや機能しないことを理解しており、新しいソリューションの提供を加速するために最新のデータ アーキテクチャでの相互運用性をサポートする、スケーラブルで柔軟なツールとオープン データ形式を採用することの価値を認識しています。
顧客は AWS と Snowflake を使用して、最新の分析と人工知能 (AI) のユースケースに必要なパフォーマンスを提供する専用のデータ アーキテクチャを開発しています。これらのソリューションを実装するには、専用のデータ ストア間でデータを共有する必要があります。このため、Snowflake と AWS は、データ サービス間のデータの相互運用性を可能にし、促進するために Apache Iceberg のサポートを強化しています。
Apache Iceberg は、さまざまな処理エンジン間のトランザクション整合性を備えた大規模なデータセットの信頼性、シンプルさ、および高いパフォーマンスを提供するオープンソースのテーブル形式です。この投稿では、次のことについて説明します。
- データレイクにおける Iceberg テーブルの利点
- AWS と Snowflake 間で Iceberg テーブルを共有するための 2 つのアーキテクチャ パターン:
- Iceberg テーブルを管理するには AWSグルー データカタログ
- Snowflake を使用して Iceberg テーブルを管理する
- データをコピーせずに、既存のデータ レイク テーブルを Iceberg テーブルに変換するプロセス
トピックについて大まかに理解したところで、それぞれのトピックを詳しく見ていきましょう。
Apache Iceberg の利点
Apache Iceberg は、分散型、コミュニティ主導型、Apache 2.0 ライセンスの 100% オープンソース データ テーブル形式であり、データ レイクに保存されている大規模なデータセットのデータ処理を簡素化するのに役立ちます。データ エンジニアが Apache Iceberg を使用するのは、Apache Iceberg がどのような規模でも高速、効率的、信頼性が高く、データセットが時間の経過とともにどのように変化するかの記録が保存されるためです。 Apache Iceberg は、Apache Spark、Apache Flink、Apache Hive、Presto などの一般的なデータ処理フレームワークとの統合を提供します。
Iceberg テーブルは、ファイルの大規模なコレクションを抽象化するためのメタデータを維持し、タイムトラベル、ロールバック、データ圧縮、完全なスキーマ進化などのデータ管理機能を提供して、管理オーバーヘッドを削減します。 Apache Iceberg は、もともと Netflix で開発され、Apache Software Foundation にオープンソース化されましたが、次のような一般的なデータ レイクの課題を解決するための白紙の設計でした。 ユーザー体験, 信頼性とパフォーマンス、現在は、継続的な改善とプロジェクトへの新機能の追加、実際のユーザーのニーズに応え、オプションを提供することに重点を置いた開発者の強力なコミュニティによってサポートされています。
AWS と Snowflake 上に構築されたトランザクション データ レイク
Snowflake は、次のような複数のストレージ オプションを備えた Iceberg テーブルのさまざまな統合を提供します。 アマゾンS3、および複数のカタログ オプションを含む AWSGlueデータカタログ & スノーフレーク. AWS はさまざまな AWS サービスの統合を提供します テーブルのメタデータを追跡するための AWS Glue データ カタログなど、Iceberg テーブルも使用できます。 Snowflake と AWS を組み合わせると、分析やデータ共有やコラボレーションなどのその他のユースケース向けのトランザクション データ レイクを構築するための複数のオプションが提供されます。データ レイクにメタデータ レイヤーを追加すると、非常に大規模なデータセットのユーザー エクスペリエンスが向上し、管理が簡素化され、パフォーマンスと信頼性が向上します。
AWS Glue を使用して Iceberg テーブルを管理する
AWS Glue を使用して、データの取り込み、カタログ化、変換、管理を行うことができます。 Amazon シンプル ストレージ サービス (アマゾンS3)。 AWS Glue は、抽出、変換、ロード (ETL) パイプラインを視覚的に作成、実行、監視して、データを Iceberg 形式でデータレイクにロードできるサーバーレス データ統合サービスです。 AWS Glue を使用すると、70 を超える多様なデータソースを検出して接続し、一元化されたデータカタログでデータを管理できます。 Snowflake は AWS Glue データ カタログと統合します Iceberg テーブル カタログと Amazon S3 上のファイルにアクセスして分析クエリを実行します。これにより、以前と比較してパフォーマンスと計算コストが大幅に向上します。 Snowflake の外部テーブル追加のメタデータにより、クエリ プランでの枝刈りが改善されるためです。
これと同じ統合を使用して、Snowflake のデータ共有およびコラボレーション機能を活用できます。これは、Amazon S3 にデータがあり、他のビジネスユニット、パートナー、サプライヤー、または顧客との Snowflake データ共有を有効にする必要がある場合に非常に強力です。
次のアーキテクチャ図は、このパターンの概要を示しています。
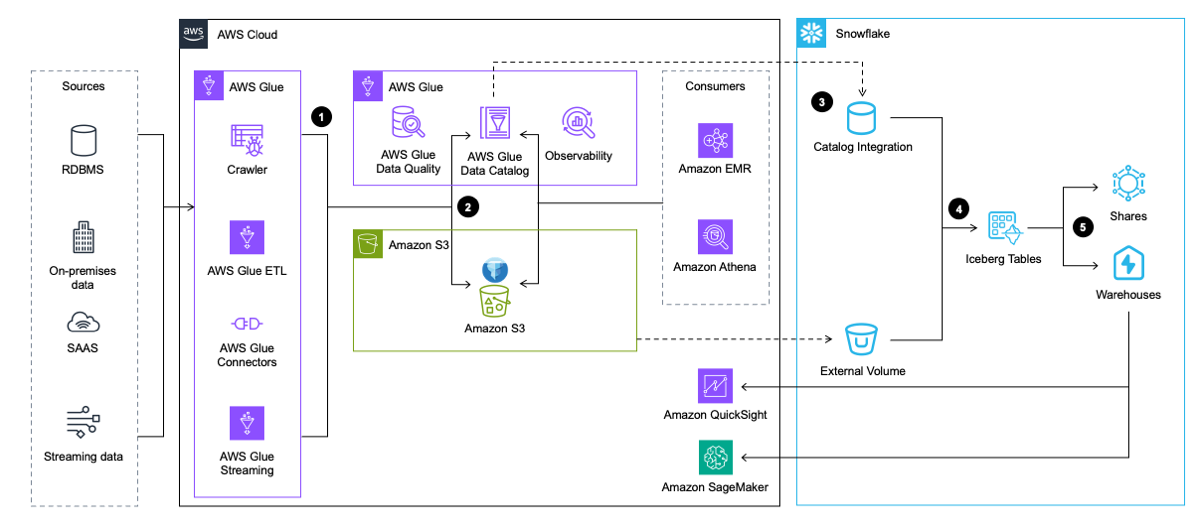
ワークフローには次の手順が含まれます。
- AWS Glue は、アプリケーション、データベース、ストリーミング ソースからデータを抽出します。次に、AWS Glue はそれを変換し、Iceberg テーブル形式で Amazon S3 のデータレイクにロードします。同時に、AWS Glue データカタログ内の Iceberg テーブルに関するメタデータを挿入および更新します。
- AWS Glue クローラーは、Iceberg テーブルのメタデータを生成および更新し、S3 データレイク上の既存の Iceberg テーブルの AWS Glue データ カタログに保存します。
- Snowflake は AWS Glue データ カタログと統合して、スナップショットの場所を取得します。
- クエリのイベントでは、Snowflake は AWS Glue データ カタログのスナップショットの場所を使用して、Amazon S3 内の Iceberg テーブル データを読み取ります。
- Snowflake は、Iceberg と Snowflake のテーブル形式にわたってクエリを実行できます。あなたはできる データを共有する 同じ Snowflake リージョン内の 1 つ以上のアカウントとのコラボレーション用。 Snowflake のデータを次の目的で使用することもできます。 可視化 アマゾンクイックサイト、または次の用途に使用します。 機械学習 (ML) と人工知能 (AI) の目的 アマゾンセージメーカー.
Snowflake で Iceberg テーブルを管理する
3 番目のパターンも AWS と Snowflake 間の相互運用性を提供しますが、取り込みと Snowflake への変換のためのデータ エンジニアリング パイプラインを実装します。このパターンでは、AWS Glue などの AWS サービスとの統合、または Snowpipe などの他のソースを通じて、Snowflake によってデータが Iceberg テーブルにロードされます。次に、Snowflake は、Snowflake およびさまざまな AWS サービスによるダウンストリーム アクセスのために、データを Iceberg 形式で Amazon SXNUMX に直接書き込みます。また、Snowflake は、AWS サービスがアクセスするテーブル全体のスナップショットの場所を追跡する Iceberg カタログを管理します。
前のパターンと同様に、Snowflake データ共有で Snowflake 管理の Iceberg テーブルを使用できますが、一方のパーティが Snowflake にアクセスできない場合は、S3 を使用してデータセットを共有することもできます。
次のアーキテクチャ図は、Snowflake で管理される Iceberg テーブルを使用したこのパターンの概要を示しています。
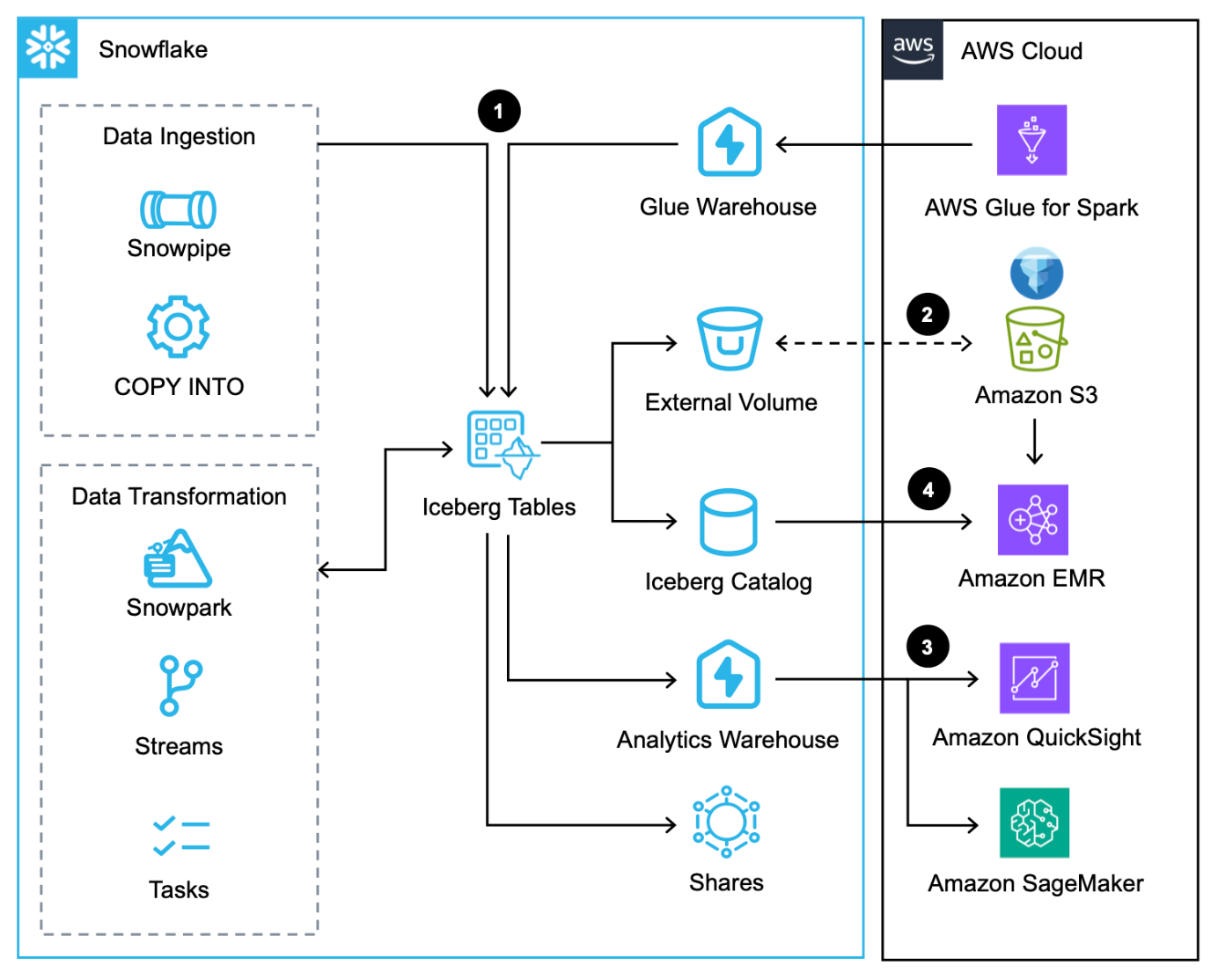
このワークフローは次の手順で構成されます。
- データをロードするだけでなく、 COPYコマンド, スノーパイプ, AWS Glue のネイティブ Snowflake コネクタ、Snowflake経由でデータを統合できます。 データ共有.
- Snowflake は、Iceberg テーブルを Amazon S3 に書き込み、トランザクションごとにメタデータを自動的に更新します。
- Amazon S3 の Iceberg テーブルは、QuickSight や SageMaker などのサービスを使用して、分析ワークロードおよび ML ワークロードについて Snowflake によってクエリされます。
- AWS 上の Apache Spark サービスでは、次のことができます。 Snowflak からスナップショットの場所にアクセスするSnowflake Iceberg Catalog SDK を介して、Amazon S3 内の Iceberg テーブル ファイルを直接スキャンします。
ソリューションの比較
これら 3 つのパターンは、Apache Iceberg を使用して Snowflake と AWS の間のデータの相互運用性を最大化するために、データ ペルソナが現在利用できるオプションを強調しています。しかし、あなたのユースケースにはどのパターンが理想的でしょうか?すでに AWS Glue データカタログを使用していて、読み取りクエリにのみ Snowflake が必要な場合、最初のパターンでは、Snowflake を AWS Glue および Amazon SXNUMX と統合して、Iceberg テーブルにクエリを実行できます。まだ AWS Glue データ カタログを使用しておらず、Snowflake による読み取りと書き込みの実行が必要な場合は、AWS からのデータの保存とアクセスを可能にする XNUMX 番目のパターンが適切なソリューションである可能性があります。
読み取りと書き込みがデータ アーキテクチャ全体ではなくテーブルごとに動作する可能性が高いことを考慮すると、両方のパターンを組み合わせて使用することをお勧めします。
Apache Iceberg を使用して既存のデータ レイクをトランザクション データ レイクに移行する
Amazon S3 上の既存の Parquet、ORC、Avro ベースのデータ レイク テーブルを Iceberg 形式に変換して、パフォーマンスとユーザー エクスペリエンスを向上させながらトランザクションの整合性のメリットを得ることができます。 Iceberg テーブルの移行オプションはいくつかあります (概要, 移住する, 追加ファイル) 既存のデータ レイク テーブルをインプレースで Iceberg 形式に移行します。これは、基盤となるデータ ファイルをすべて書き換えるよりも望ましい方法です。大規模なデータセットではコストと時間がかかります。このセクションでは、カスタム移行に役立つ ADD_FILES に焦点を当てます。
ADD_FILES オプションの場合、AWS Glue を使用して既存のデータレイクテーブルの Iceberg メタデータと統計を生成し、基礎となるデータを書き換えることなく、将来使用できるように AWS Glue データカタログに新しい Iceberg テーブルを作成できます。 AWS Glue を使用して Iceberg のメタデータと統計を生成する手順については、を参照してください。 Apache Iceberg を使用して既存のデータ レイクをトランザクション データ レイクに移行する or AWS Glue を使用して、既存の Amazon S3 データ レイク テーブルを Snowflake アンマネージド Iceberg テーブルに変換します.
このオプションでは、ファイルを Iceberg テーブルに変換するときにデータ パイプラインを一時停止する必要があります。これは、宛先を Iceberg テーブルに変更するだけなので、AWS Glue では簡単なプロセスです。
まとめ
この投稿では、AWS と Snowflake 間の相互運用性を向上させるためにデータ レイクに Apache Iceberg を実装するための 2 つのアーキテクチャ パターンについて説明しました。また、既存のデータ レイク テーブルを Iceberg 形式に移行するためのガイダンスも提供しました。
サインアップする 10 月 XNUMX 日の AWS Dev Day Apache Iceberg だけでなく、ストリーミング データ パイプラインも実際に体験できます。 Amazon データ ファイアホース & スノーパイプストリーミング、および生成 AI アプリケーション スノーフレークのストリームライト & アマゾンの岩盤.
著者について
 アンドリー・エンゲルブレヒト Snowflake のプリンシパル パートナー ソリューション アーキテクトであり、戦略的パートナーと協力しています。 彼は、製品やサービスの統合をサポートする AWS のような戦略的パートナーや、パートナーとの共同ソリューションの開発に積極的に取り組んでいます。 Andries は、データと分析の分野で 20 年以上の経験があります。
アンドリー・エンゲルブレヒト Snowflake のプリンシパル パートナー ソリューション アーキテクトであり、戦略的パートナーと協力しています。 彼は、製品やサービスの統合をサポートする AWS のような戦略的パートナーや、パートナーとの共同ソリューションの開発に積極的に取り組んでいます。 Andries は、データと分析の分野で 20 年以上の経験があります。
 ディーンバンドゥ・プラサド AWS のシニア分析スペシャリストであり、ビッグデータ サービスを専門としています。彼は、顧客が AWS クラウド上に最新のデータ アーキテクチャを構築できるよう支援することに情熱を注いでいます。彼は、あらゆる規模の顧客がデータ管理、データ ウェアハウス、データ レイク ソリューションを導入するのを支援してきました。
ディーンバンドゥ・プラサド AWS のシニア分析スペシャリストであり、ビッグデータ サービスを専門としています。彼は、顧客が AWS クラウド上に最新のデータ アーキテクチャを構築できるよう支援することに情熱を注いでいます。彼は、あらゆる規模の顧客がデータ管理、データ ウェアハウス、データ レイク ソリューションを導入するのを支援してきました。
 ブライアン・ドラン 海軍飛行士として最初のキャリアを積んだ後、2012 年に軍事関係マネージャーとして Amazon に入社しました。 2014 年に、ブライアンはアマゾン ウェブ サービスに入社し、スタートアップから企業までのカナダの顧客が AWS クラウドを探索できるよう支援しました。最近では、Brian は、Amazon DynamoDB および Amazon Keyspaces の市場開拓スペシャリストとして非リレーショナル ビジネス開発チームのメンバーとして勤務し、2022 年に AWS Glue の市場開拓スペシャリストとして Analytics Worldwide Specialist Organization に加わりました。
ブライアン・ドラン 海軍飛行士として最初のキャリアを積んだ後、2012 年に軍事関係マネージャーとして Amazon に入社しました。 2014 年に、ブライアンはアマゾン ウェブ サービスに入社し、スタートアップから企業までのカナダの顧客が AWS クラウドを探索できるよう支援しました。最近では、Brian は、Amazon DynamoDB および Amazon Keyspaces の市場開拓スペシャリストとして非リレーショナル ビジネス開発チームのメンバーとして勤務し、2022 年に AWS Glue の市場開拓スペシャリストとして Analytics Worldwide Specialist Organization に加わりました。
 ニディ・グプタ AWS のシニア パートナー ソリューション アーキテクトです。彼女は顧客やパートナーと協力して建築上の課題を解決することに日々を費やしています。彼女は、データの統合とオーケストレーション、サーバーレスおよびビッグデータの処理、機械学習に情熱を注いでいます。 Nidhi は、データ ワークロードのアーキテクチャ設計、本番リリース、展開を主導した豊富な経験を持っています。
ニディ・グプタ AWS のシニア パートナー ソリューション アーキテクトです。彼女は顧客やパートナーと協力して建築上の課題を解決することに日々を費やしています。彼女は、データの統合とオーケストレーション、サーバーレスおよびビッグデータの処理、機械学習に情熱を注いでいます。 Nidhi は、データ ワークロードのアーキテクチャ設計、本番リリース、展開を主導した豊富な経験を持っています。
 スコット・ティール Snowflake の製品マーケティング リードであり、データ レイク、ストレージ、ガバナンスに重点を置いています。
スコット・ティール Snowflake の製品マーケティング リードであり、データ レイク、ストレージ、ガバナンスに重点を置いています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-your-data-lake-with-amazon-s3-aws-glue-and-snowflake/

