Amazonレッドシフト は、数万の顧客が分析ワークロードを強化するために依存している、高速でペタバイト規模のクラウド データ ウェアハウスです。数千のお客様が Amazon Redshift 読み取りデータ共有を使用して、Redshift でプロビジョニングされたクラスターとサーバーレス ワークグループ全体での即時、きめ細かな、高速なデータ アクセスを可能にしています。これにより、データを移動またはコピーすることなく、読み取りワークロードを数千の同時ユーザーに拡張できます。
現在、Amazon Redshift では、データ共有によるマルチデータ ウェアハウスの書き込みをパブリック プレビューで発表しています。これにより、ワークロードのニーズに基づいて、さまざまなタイプとサイズのさまざまなウェアハウスを使用することで、抽出、変換、ロード (ETL) ワークロードのパフォーマンスを向上させることができます。さらに、これにより、数回クリックするだけで ETL ジョブを倉庫間で分割できるため、ETL ジョブをより予測どおりに実行し続けることができ、各倉庫が独自の監視とコスト管理を備えているためコストを監視および制御でき、さまざまなチームを有効にできるためコラボレーションを促進できます。数回クリックするだけで、別のチームのデータベースに書き込むことができます。
データはライブであり、クロスアカウントまたはクロスリージョンに書き込まれた場合でも、コミットされるとすぐにすべてのウェアハウスで利用可能になります。プレビューでは、ra3.4xl クラスター、ra3.16xl クラスター、またはサーバーレス ワークグループを組み合わせて使用できます。
この投稿では、同じデータベースに書き込むために複数のウェアハウスの使用を検討する必要がある場合について説明し、データ共有による複数のウェアハウスの書き込みがどのように機能するかを説明し、複数のウェアハウスを使用して同じデータベースに書き込む方法の例を説明します。
同じデータベースに書き込むために複数のウェアハウスを使用する理由
このセクションでは、同じデータベースに書き込むために複数のウェアハウスの使用を検討する必要がある理由のいくつかについて説明します。
混合ワークロードのパフォーマンスと予測可能性の向上
顧客は多くの場合、初期のワークロードのニーズに合わせたサイズの倉庫から開始します。たとえば、時折発生するユーザー クエリや、毎晩の 10 万行の購入データの取り込みをサポートする必要がある場合、32 RPU のワークグループがニーズに最適である可能性があります。ただし、ユーザーの Web サイトとアプリのインタラクションの 400 億行を XNUMX 時間ごとに新たに取り込むと、新しいワークロードが大量のリソースを消費するため、既存のユーザーの応答時間が遅くなる可能性があります。より大きなワークグループに合わせてサイズを変更できるため、リソースを争うことなく読み取りおよび書き込みワークロードが迅速に完了します。ただし、これにより、既存のワークロードに不必要な電力とコストが発生する可能性があります。また、ワークロードはコンピューティングを共有するため、XNUMX つのワークロードが急増すると、他のワークロードが SLA を満たす能力に影響を与える可能性があります。
次の図は、単一ウェアハウスのアーキテクチャを示しています。
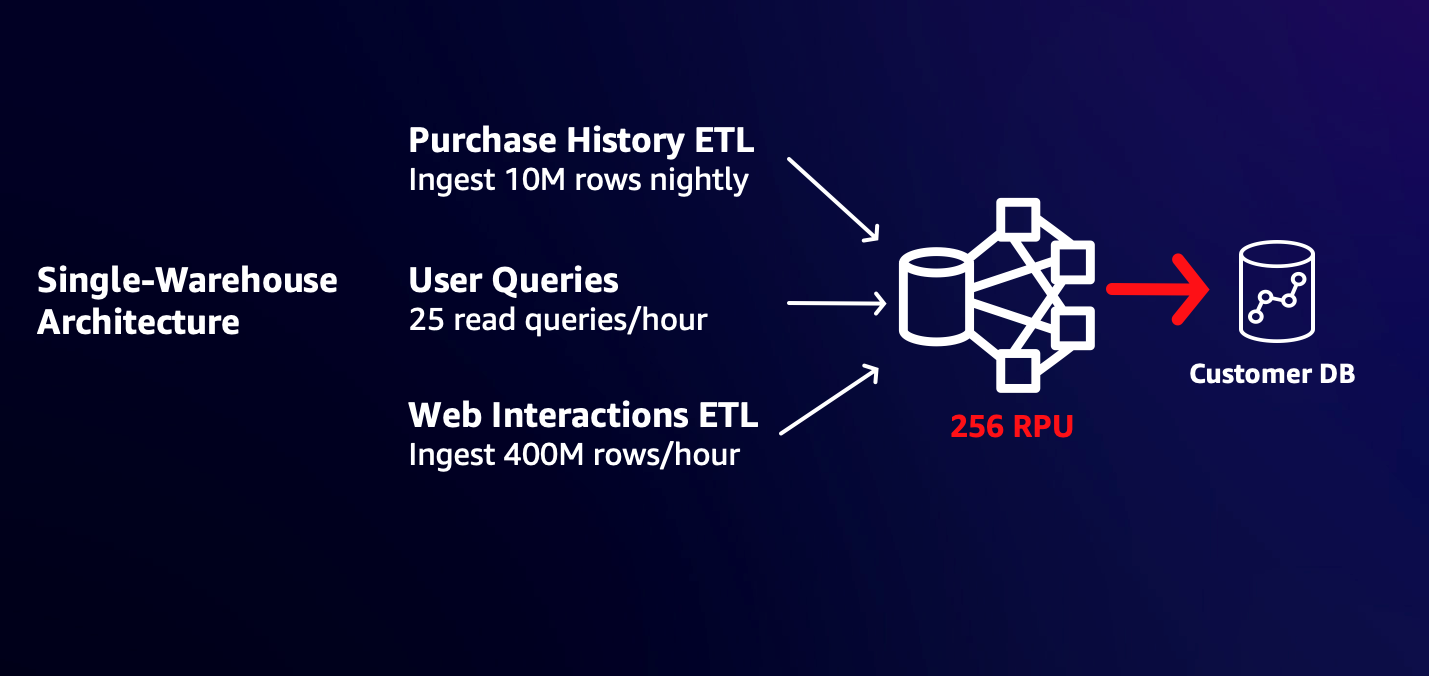
データ共有を介した書き込み機能により、新しいユーザーの Web サイトとアプリのインタラクション ETL を別個の大きなワークグループに分離できるようになり、既存のワークロードのコストや完了時間に影響を与えることなく、必要なパフォーマンスで迅速に完了することができます。次の図は、このマルチウェアハウス アーキテクチャを示しています。

マルチ ウェアハウス アーキテクチャにより、すべてのワークロードをサポートする単一のウェアハウスに比べて、より少ないコンピューティングの組み合わせで、すべての書き込みワークロードを時間通りに完了させることができ、結果としてコストが低くなります。
コストの管理と監視
すべての ETL ジョブに単一のウェアハウスを使用する場合、どのワークロードがコストに影響しているかを理解するのが困難になることがあります。たとえば、あるチームが CRM システムからデータを取り込む ETL ワークロードを実行している一方で、別のチームが内部運用システムからデータを取り込んでいるとします。クエリはウェアハウス内の同じコンピューティングを使用して一緒に実行されるため、ワークロードのコストを監視および制御するのは困難です。書き込みワークロードを個別のウェアハウスに分割することで、コストを個別に監視および制御できると同時に、リソースの競合なしにワークロードを独立して進めることができます。
ライブデータを簡単に共同作業できます
360 つのチームがデータ ガバナンス、コンピューティング パフォーマンス、またはコストの理由から異なるウェアハウスを使用する場合がありますが、同じ共有データに書き込む必要がある場合もあります。たとえば、顧客がマーケティング、営業、カスタマー サービス チームとやり取りするときにライブで更新する必要がある顧客 XNUMX テーブルのセットがあるとします。これらのチームが異なるウェアハウスを使用している場合、次のようなツールを使用してマルチサービス ETL パイプラインを構築する必要がある場合があるため、このデータをライブに維持することが困難になる可能性があります。 Amazon シンプル ストレージ サービス (Amazon S3)、 Amazon シンプル通知サービス (Amazon SNS)、 Amazon シンプル キュー サービス (Amazon SQS)、および AWSラムダ 各チームのデータのライブ変更を追跡し、それを単一のソースに取り込みます。
データ共有を介した書き込み機能を使用すると、数回クリックするだけで、データベース オブジェクトに対するきめ細かな権限 (たとえば、あるテーブルでは SELECT、別のテーブルでは SELECT、INSERT、および TRUNCATE) を、異なるウェアハウスを使用する異なるチームに付与できます。これにより、チームは独自のウェアハウスを使用して共有オブジェクトへの書き込みを開始できるようになります。データはライブであり、コミットされるとすぐにすべてのウェアハウスで利用可能になります。これは、ウェアハウスが異なるアカウントやリージョンを使用している場合でも機能します。
次のセクションでは、複数のウェアハウスを使用して、データ共有を通じて同じデータベースに書き込む方法について説明します。
ソリューションの概要
このソリューションでは次の用語を使用します。
- 名前空間 – データベース オブジェクト、ユーザーとロール、データベース オブジェクトに対する権限、およびコンピューティング (サーバーレス ワークグループとプロビジョニングされたクラスター) の論理コンテナー。
- データ共有 – データ共有の共有単位。オブジェクトに対するアクセス許可をデータ共有に付与します。
- プロデューサー – データ共有を作成し、オブジェクトに対する権限をデータ共有に付与し、他のウェアハウスとアカウントにデータ共有へのアクセスを許可するウェアハウス。
- 消費財 – データ共有へのアクセスが許可されているウェアハウス。コンシューマはデータ共有テナントと考えることができます。
この使用例には、2 つのウェアハウスを持つお客様が含まれます。1 つはほとんどの読み取りおよび書き込みクエリのためにプライマリ名前空間に接続され、もう 1 つはプライマリ名前空間への書き込みに主に使用されるセカンダリ名前空間に接続されたセカンダリ ウェアハウスです。一般に公開されているものを使用します 10 GB TPCH データセット S3 バケットでホストされている AWS Labs から。多くのコマンドをコピーして貼り付けることができます。データ ウェアハウスとしては小さいですが、このデータセットを使用すると、この機能の機能テストを簡単に行うことができます。
次の図は、ソリューションアーキテクチャを示しています。

ウェアハウス経由でプライマリ名前空間に接続し、その中にマーケティング データベースを作成してプライマリ ネームスペースを設定します。 prod & staging スキーマを作成し、その中に 3 つのテーブルを作成します。 prod と呼ばれるスキーマ region, nation, af_customer。次に、データを region & nation 倉庫を利用したテーブル。データを af_customer 列で番号の横にあるXをクリックします。
次に、プライマリ名前空間にデータ共有を作成します。データ共有にオブジェクトを作成する機能を付与します。 staging スキーマと、そのオブジェクトの選択、挿入、更新、および削除の機能 prod スキーマ。次に、スキーマの使用をアカウント内の別の名前空間に許可します。
その時点で、二次倉庫に接続します。そのウェアハウス内のデータ共有と新しいユーザーからデータベースを作成します。次に、データ共有オブジェクトに対する権限を新しいユーザーに付与します。次に、新しいユーザーとしてセカンダリ ウェアハウスに再接続します。
次に、データ共有内に顧客テーブルを作成します。 staging スキーマを作成し、TPCH 10 顧客データセットからステージング テーブルにデータをコピーします。ステージング顧客テーブルのデータを共有テーブルに挿入します。 af_customer 本番テーブルを削除し、テーブルを切り詰めます。
この時点で ETL は完了し、セカンダリ ETL ウェアハウスによって挿入されたプライマリ ネームスペース内のデータを、プライマリ ウェアハウスとセカンダリ ETL ウェアハウスの両方から読み取ることができるようになります。
前提条件
この投稿をフォローするには、次の前提条件が必要です。
- で作成された 2 つの倉庫
PREVIEW_2023追跡。ウェアハウスは、サーバーレス ワークグループ、ra3.4xl クラスター、および ra3.16xl クラスターを組み合わせて使用できます。 - へのアクセス スーパーユーザ 両方の倉庫にあります。
- An AWS IDおよびアクセス管理 Amazon Redshift から Amazon S3 にデータを取り込むことができる (IAM) ロール (Amazon Redshift は、クラスターまたはサーバーレスワークグループを作成するときにデフォルトで作成します)。
- クロスアカウントの場合のみ、データ共有の承認が許可されている IAM ユーザーまたはロールへのアクセスが必要です。 IAM ポリシーについては、以下を参照してください。 データシェアの共有.
参照する AWS アカウント内またはアカウント間で読み取りデータと書き込みデータの両方を共有する (プレビュー) 最新の情報については。
プライマリ名前空間 (プロデューサー) をセットアップする
このセクションでは、データの保存に使用するプライマリ (プロデューサー) 名前空間を設定する方法を示します。
プロデューサーに接続する
プロデューサに接続するには、次の手順を実行します。
- Amazon Redshiftコンソールで、 クエリエディタv2 ナビゲーションペインに表示されます。

クエリ エディター v2 では、アクセスできるすべてのウェアハウスが左側のペインに表示されます。展開してデータベースを表示できます。
- スーパーユーザーを使用してプライマリ ウェアハウスに接続します。
- 次のコマンドを実行して、
marketingデータベース:
共有するデータベース オブジェクトを作成する
共有するデータベース オブジェクトを作成するには、次の手順を実行します。
- を作成した後、
marketingデータベースの場合は、データベース接続をmarketingデータベース。
表示するにはページを更新する必要がある場合があります。
- 次のコマンドを実行して、共有する 2 つのスキーマを作成します。
- 次のコードで共有するテーブルを作成します。これらは、テーブル名が変更された AWS Labs DDL ファイルからの標準 DDL ステートメントです。
データを region & nation テーブル
次のコマンドを実行して、AWS Labs S3 バケットからデータを region & nation テーブル。デフォルトで作成された IAM ロールを維持したままクラスターを作成した場合は、次のコマンドをコピーして貼り付けて、テーブルにデータをロードできます。
データ共有を作成する
次のコマンドを使用してデータ共有を作成します。
publicaccessible この設定では、パブリックにアクセス可能なプロビジョニングされたクラスターおよびサーバーレス ワークグループを持つコンシューマーがデータ共有を使用できるかどうかを指定します。倉庫が一般公開されていない場合は、そのフィールドを無視してかまいません。
スキーマに対するアクセス許可をデータ共有に付与します。
アクセス許可を持つオブジェクトをデータ共有に追加するには、grant 構文を使用して、アクセス許可を付与するデータ共有を指定します。
これにより、データ共有コンシューマーは、 prod スキーマに追加されたオブジェクトを使用および作成します。 staging スキーマ。下位互換性を維持するために、 alter datashare コマンドを使用してスキーマを追加すると、スキーマに対する使用を許可することと同じになります。
テーブルに対するアクセス許可をデータ共有に付与します。
これで、権限とデータ共有を指定する許可構文を使用して、データ共有へのテーブルへのアクセスを許可できるようになりました。次のコードは、 af_customer テーブルをデータ共有に:
下位互換性を維持するために、alter datashare コマンドを使用してテーブルを追加すると、テーブルに対する選択を許可することと同じになります。
さらに、データ共有内の現在および将来のすべてのオブジェクトに同じ権限を付与できるようにする、範囲指定された権限を追加しました。スコープ指定された選択権限を追加します。 突く スキーマ テーブルをデータ共有に追加します。
この付与後、顧客は prod スキーマ内の現在および将来のすべてのテーブルに対する選択権限を持ちます。これにより、ユーザーは、 region & nation テーブル。
データ共有に付与されたアクセス許可の表示
次のコマンドを実行すると、データ共有に付与された権限を表示できます。
セカンダリ ETL 名前空間にアクセス許可を付与する
既存の構文を使用して、セカンダリ ETL 名前空間にアクセス許可を付与できます。これを行うには、名前空間 ID を指定します。セカンダリ ETL 名前空間がサーバーレスの場合は、名前空間の詳細ページで名前空間を見つけることができます。セカンダリ ETL 名前空間がプロビジョニングされている場合は、クラスターの詳細ページの名前空間 ID の一部として、またはクエリ エディター v2 でセカンダリ ETL ウェアハウスに接続することによって、名前空間を見つけることができます。そして走っています select current_namespace. 次に、次のコマンドを使用して、他の名前空間へのアクセスを許可できます (コンシューマー名前空間を独自のセカンダリ ETL ウェアハウスの名前空間 UID に変更します)。
セカンダリ ETL 名前空間 (コンシューマ) をセットアップする
この時点で、共有データへの書き込みを開始するためにセカンダリ (コンシューマー) ETL ウェアハウスをセットアップする準備が整いました。
データ共有からデータベースを作成する
データベースを作成するには、次の手順を実行します。
- クエリ エディター v2 で、セカンダリ ETL ウェアハウスに切り替えます。
- コマンドを実行する
show datasharesマーケティング データシェアとデータシェア プロデューサーの名前空間を確認します。 - 次のコードに示すように、その名前空間を使用してデータ共有からデータベースを作成します。
指定 with permissions 個々のデータベース ユーザーおよびロールに詳細な権限を付与できます。これを行わずに、データ共有データベースに対する使用権限を付与すると、ユーザーとロールはデータ共有データベース内のすべてのオブジェクトに対するすべての権限を取得します。
ユーザーを作成し、そのユーザーに権限を付与します
を使用してユーザーを作成します。 ユーザーを作成 コマンド:
これらの許可により、ユーザーに与えられたもの data_engineer データ共有内のすべてのオブジェクトに対するすべての権限。さらに、スキーマで使用可能なすべての権限を、範囲指定された権限として付与しました。 data_engineer。これらのスキーマに追加されたオブジェクトに対する権限は、自動的に付与されます。 data_engineer.
この時点で、現在サインインしている管理者ユーザーまたは data_engineer.
データ共有データベースへの書き込みオプション
データ共有データベースにデータを書き込むには、3 つの方法があります。
ローカル データベースに接続しているときに 3 部構成の表記を使用する
読み取りデータ共有と同様に、3 部構成の表記を使用してデータ共有データベース オブジェクトを参照できます。例えば、 insert into marketing_ds_db.prod.customer。このように、複数ステートメントのトランザクションを使用してデータ共有データベース内のオブジェクトに書き込むことはできないことに注意してください。
データ共有データベースに直接接続する
Amazon Redshift Data API (新規) に加えて、Redshift JDBC、ODBC、または Python ドライバーを介してデータ共有データベースに直接接続できます。このように接続するには、接続文字列にデータ共有データベース名を指定します。これにより、2 部構成の表記法を使用してデータ共有データベースに書き込み、複数ステートメントのトランザクションを使用してデータ共有データベースに書き込むことができます。一部のシステム テーブルとカタログ テーブルはこの方法では使用できないことに注意してください。
useコマンドを実行します
コマンドで別のデータベースを使用することを指定できるようになりました。 use <database_name>。これにより、2 部構成の表記法を使用してデータ共有データベースに書き込み、複数ステートメントのトランザクションを使用してデータ共有データベースに書き込むことができます。一部のシステム テーブルとカタログ テーブルはこの方法では使用できないことに注意してください。また、システム テーブルとカタログ テーブルをクエリするときは、使用しているデータベースではなく、接続しているデータベースのシステム テーブルとカタログ テーブルをクエリすることになります。
この方法を試すには、次のコマンドを実行します。
データ共有データベースへの書き込みを開始する
このセクションでは、説明した 2 番目と 3 番目のオプション (直接接続またはコマンドを使用) を使用してデータ共有データベースに書き込む方法を示します。私たちが使用するのは、 AWS ラボが提供した SQL データ共有データベースに書き込むため。
ステージングテーブルを作成する
作成権限が付与されているので、ステージング スキーマ内にテーブルを作成します。データ共有内にテーブルを作成します。 staging 次の DDL ステートメントを含むスキーマ:
USE コマンドを使用したか、データ共有データベースに直接接続したため、2 部構成の表記を使用できます。そうでない場合は、データ共有データベース名も指定する必要があります。
データをステージング テーブルにコピーする
次のコマンドを使用して、顧客の TPCH 10 データを AWS Labs のパブリック S3 バケットからテーブルにコピーします。
前と同様に、このウェアハウスを作成するときにデフォルトの IAM ロールを設定しておく必要があります。
アフリカの顧客データをテーブルに取り込む prod.af_customer
次のコマンドを実行して、アフリカの顧客データのみをテーブルに取り込みます prod.af_customer:
これには、選択権限を持つ国と地域のテーブルに参加する必要があります。
ステージングテーブルを切り詰める
切り捨てることができます ステージング テーブルを作成すると、将来のジョブでテーブルを再作成しなくても書き込むことができます。切り捨てアクションはトランザクション的に実行され、データ共有データベースに直接接続している場合、または use コマンドを使用している場合 (データ共有データベースを使用していない場合でも) ロールバックできます。次のコードを使用します。
この時点で、プライマリ名前空間へのデータの取り込みが完了しました。クエリを実行できます。 af_customer プライマリ ウェアハウスとセカンダリ ETL ウェアハウスの両方からテーブルを取得し、同じデータを参照します。
まとめ
この投稿では、複数のウェアハウスを使用して同じデータベースに書き込む方法を説明しました。このソリューションには次の利点があります。
- 異なるサイズのプロビジョニングされたクラスターとサーバーレス ワークグループを使用して、同じデータベースに書き込むことができます。
- アカウントやリージョンを越えて書き込み可能
- データはライブであり、コミットされるとすぐにすべてのウェアハウスで利用可能になります
- プロデューサー ウェアハウス (データベースを所有するウェアハウス) が一時停止している場合でも、書き込みは機能します。
この機能の詳細については、次を参照してください。 AWS アカウント内またはアカウント間で読み取りデータと書き込みデータの両方を共有する (プレビュー)。さらに、フィードバックがある場合は、次のアドレスに電子メールを送信してください。 dsw-フィードバック@amazon.com.
著者について
 ライアン・ウォルドーフ Amazon Redshift のシニアプロダクトマネージャーです。 Ryan は、データ共有や同時実行のスケーリングなど、顧客がコンピューティングを定義して拡張できるようにする機能に重点を置いています。
ライアン・ウォルドーフ Amazon Redshift のシニアプロダクトマネージャーです。 Ryan は、データ共有や同時実行のスケーリングなど、顧客がコンピューティングを定義して拡張できるようにする機能に重点を置いています。
 ハルシダ・パテル アマゾン ウェブ サービス (AWS) の分析スペシャリスト、プリンシパル ソリューション アーキテクトです。
ハルシダ・パテル アマゾン ウェブ サービス (AWS) の分析スペシャリスト、プリンシパル ソリューション アーキテクトです。
 スディプト・ダス アマゾン ウェブ サービス (AWS) のシニア プリンシパル エンジニアです。彼は、特に Amazon Redshift と Amazon Aurora に重点を置き、AWS の複数のデータベースと分析サービスの技術アーキテクチャと戦略を主導しています。
スディプト・ダス アマゾン ウェブ サービス (AWS) のシニア プリンシパル エンジニアです。彼は、特に Amazon Redshift と Amazon Aurora に重点を置き、AWS の複数のデータベースと分析サービスの技術アーキテクチャと戦略を主導しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/improve-your-etl-performance-using-multiple-redshift-warehouses-for-writes/

