AWS re:Invent 2022 では、 Amazon Athena が Apache Spark のサポートを開始。 今回の発売に伴い、 アマゾンアテナ は、Apache Spark と Trino という XNUMX つのオープンソース クエリ エンジンをサポートしています。 Athena Spark を使用すると、Athena コンソールまたは Athena API を通じて簡素化されたノートブック エクスペリエンスを使用して、Apache Spark アプリケーションを構築できます。 Athena Spark ノートブックは PySpark とノートブック マジックをサポートしており、Spark SQL を操作できるようになります。 インタラクティブなアプリケーションの場合、Athena Spark を使用すると、待ち時間が短縮され、アプリケーションの起動時間が XNUMX 秒未満になるため、生産性が向上します。 また、Athena はサーバーレスでフルマネージドであるため、基盤となるインフラストラクチャを気にせずにワークロードを実行できます。
最新のアプリケーションは大量のデータを保存します Amazon シンプル ストレージ サービス (Amazon S3) データレイク。コスト効率が高く耐久性の高いストレージを提供し、データレイクから分析と機械学習 (ML) を実行してデータに関する洞察を生成できるようにします。 これらのワークロードを実行する前に、ほとんどのお客様は SQL クエリを実行して、対話的にデータを抽出、フィルタリング、結合し、意思決定、モデルのトレーニング、または推論に使用できる形に集約します。 データレイク上での SQL の実行は高速であり、Athena は、強力なオプティマイザーを含む、最適化された Trino および Presto 互換の API を提供します。 さらに、金融サービス、ヘルスケア、小売などの複数の業界の組織が、あらゆるサイズのデータに対する高速分析と高度な変換のために最適化された人気のオープンソース分散処理システムである Apache Spark を採用しています。 Athena での Apache Spark のサポートにより、単一のノートブックで Spark SQL と PySpark の両方を使用して、アプリケーションの分析情報を生成したり、モデルを構築したりできます。 Spark SQL を開始して、操作する属性を抽出、フィルター、および投影します。 次に、回帰テストや時系列予測などのより複雑なデータ分析を実行するには、Python で Apache Spark を使用します。これにより、Matplot、Seaborn、Plotly でのデータ視覚化を含むライブラリの豊富なエコシステムを利用できます。
3 部構成のシリーズの最初の投稿では、Athena ノートブックで Spark SQL の使用を開始する方法を説明します。 Amazon SXNUMX でデータベースとテーブルをクエリする方法と、 AWSグルー Athena で Spark SQL を使用したデータ カタログ。 Spark SQL で使用される一般的な SQL コマンドと高度な SQL コマンドをいくつか取り上げ、Python を使用してユーザー定義関数 (UDF) で機能を拡張し、クエリされたデータを視覚化する方法を示します。 次回の投稿では、オープンソースのトランザクション テーブル形式で Athena Spark を使用する方法を説明します。 3 番目の投稿では、Athena Spark を使用した Amazon SXNUMX 以外のデータソースの分析について説明します。
前提条件
開始するには、次のものが必要です。
IAM ロールを通じて Athena Spark にデータへのアクセスを提供する
このチュートリアルを進めると、新しいデータベースとテーブルが作成されます。 デフォルトでは、Athena Spark にはこれを行う権限がありません。 このアクセスを提供するには、次のインライン ポリシーを AWS IDおよびアクセス管理 ワークグループにアタッチされた (IAM) ロール。リージョンとアカウント番号を指定します。 詳細については、「 ユーザーまたはロールのインライン ポリシーを埋め込むには (コンソール) in IAM ID アクセス許可の追加 (コンソール).
Python を使用せずにノートブックで直接 SQL クエリを実行する
Athena Spark ノートブックを使用すると、PySpark を使用せずに SQL クエリを直接実行できます。 これは、セル マジックを使用して行います。セル マジックは、セルの動作を変更するノートブックの特別なヘッダーです。 SQL の場合、%%sql マジックを追加できます。これは、セルの内容全体を Athena Spark で実行される SQL ステートメントとして解釈します。
ワークグループとノートブックが作成されたので、探索を開始しましょう。 NOAA グローバル サーフェス デイのサマリー 地球上のさまざまな場所の環境対策を提供するデータセット。 この投稿で使用されているデータセットは、次の Amazon S3 の場所でホストされているパブリック データセットです。
- 2020 年の寄木細工のデータ –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2020/ - 2021 年の寄木細工のデータ –
s3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/year=2021/ - 2022 年の寄木細工のデータ –
s3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/year=2022/
このデータを使用するには、Athena のメタストアとして機能する AWS Glue データ カタログ データベースが必要です。これにより、Amazon S3 内のデータセットの場所を指す外部テーブルを作成できるようになります。 まず、Athena と Spark を使用して Data Catalog にデータベースを作成します。
データベースを作成する
次の SQL をノートブックで実行します。 %%sql マジック:
次の出力が得られます。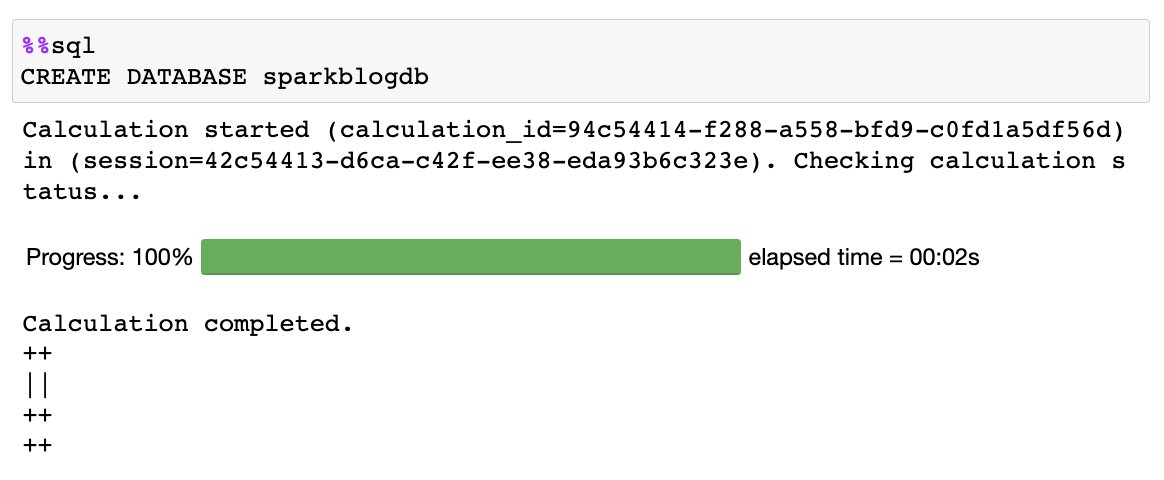
テーブルを作成する
データカタログにデータベースを作成したので、Amazon S3 に保存されているデータセットを指すパーティションテーブルを作成できます。
このデータセットは年ごとに分割されています。つまり、データ ファイルを年ごとに個別に保存します。これにより、クエリで特定の S3 の場所をターゲットにできるため、管理が簡素化され、パフォーマンスが向上します。 データ カタログはテーブルについて認識しているので、次は、 MSCK ユーティリティ:
前述のステートメントが完了したら、次のコマンドを実行して、テーブル内で見つかった年次パーティションを一覧表示できます。

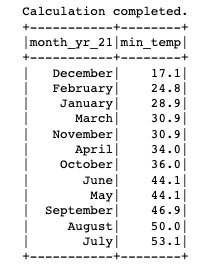
テーブルを作成し、パーティションを追加したので、クエリを実行して、その場所で記録された最低温度を見つけてみましょう。 'SEATTLE TACOMA AIRPORT, WA US' 場所:

Athena Spark からクロスアカウント データ カタログをクエリする
Athena は、クロスアカウント AWS Glue データ カタログへのアクセスをサポートしています。これにより、Athena Spark の Spark SQL を使用して、承認された AWS アカウントのデータ カタログにクエリを実行できるようになります。
クロスアカウント データ カタログ アクセス パターンは、多くの場合、 データメッシュ データ作成者がカタログとデータを消費者アカウントと共有したい場合のアーキテクチャ。 その後、消費者アカウントは、共有データに対してデータ分析と探索を実行できます。 これは簡略化されたモデルであり、使用する必要はありません。 AWSレイクフォーメーション データ共有。 次の図は、XNUMX つのプロデューサー アカウントと XNUMX つのコンシューマー アカウントの間で設定がどのように機能するかの概要を示しています。これは、複数のプロデューサー アカウントとコンシューマー アカウントに拡張できます。
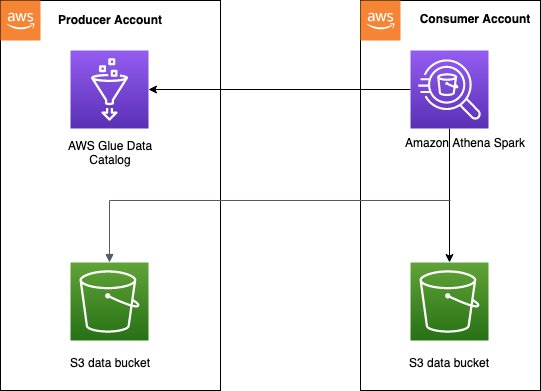
クロスアカウント アクセスを有効にするには、プロデューサー アカウントのデータ カタログに適切なアクセス ポリシーを設定する必要があります。 具体的には、Athena で Spark 計算を実行するために使用されるコンシューマー アカウントの IAM ロールが、クロスアカウント データ カタログと Amazon S3 のデータにアクセスできることを確認する必要があります。 セットアップ手順については、以下を参照してください。 Athena for Spark でのクロスアカウント AWS Glue アクセスの構成.
コンシューマー アカウントが Athena Spark からクロスアカウント データ カタログにアクセスするには、クエリを XNUMX つのプロデューサー アカウントから行うか複数から行うかに応じて XNUMX つの方法があります。
単一のプロデューサー テーブルをクエリする
単一プロデューサーの AWS アカウントからデータをクエリするだけの場合は、データベース オブジェクトを解決するためにそのアカウントのカタログのみを使用するように Athena Spark に指示できます。 このオプションを使用する場合、セッション レベルで AWS アカウント ID を設定しているため、SQL を変更する必要はありません。 このメソッドを有効にするには、セッションを編集してプロパティを設定します。 "spark.hadoop.hive.metastore.glue.catalogid": "999999999999" 次の手順を使用します。
- ノートブック エディターの セッションを開く メニュー、選択 セッションの編集.
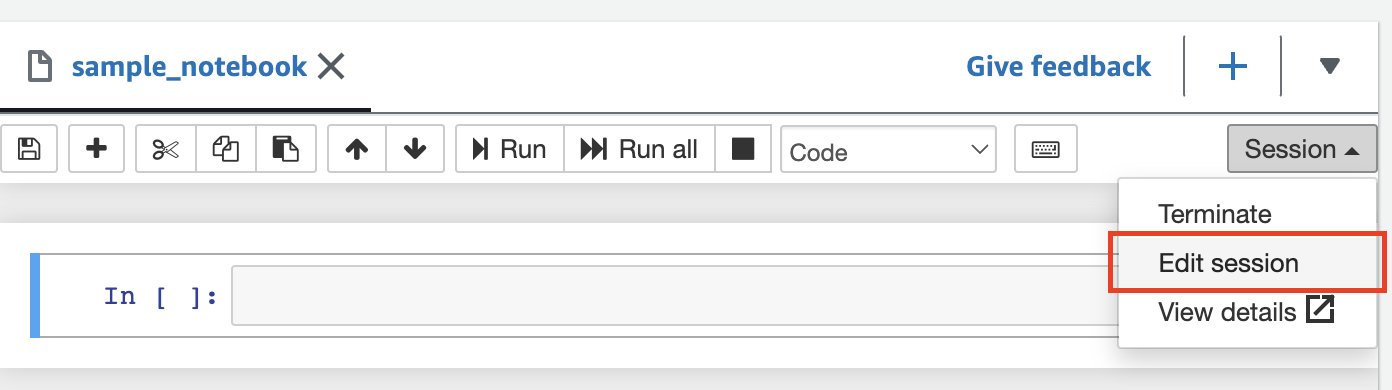
- 選択する JSONで編集する.
- 次のプロパティを追加して選択します Save:
{"spark.hadoop.hive.metastore.glue.catalogid": "999999999999"}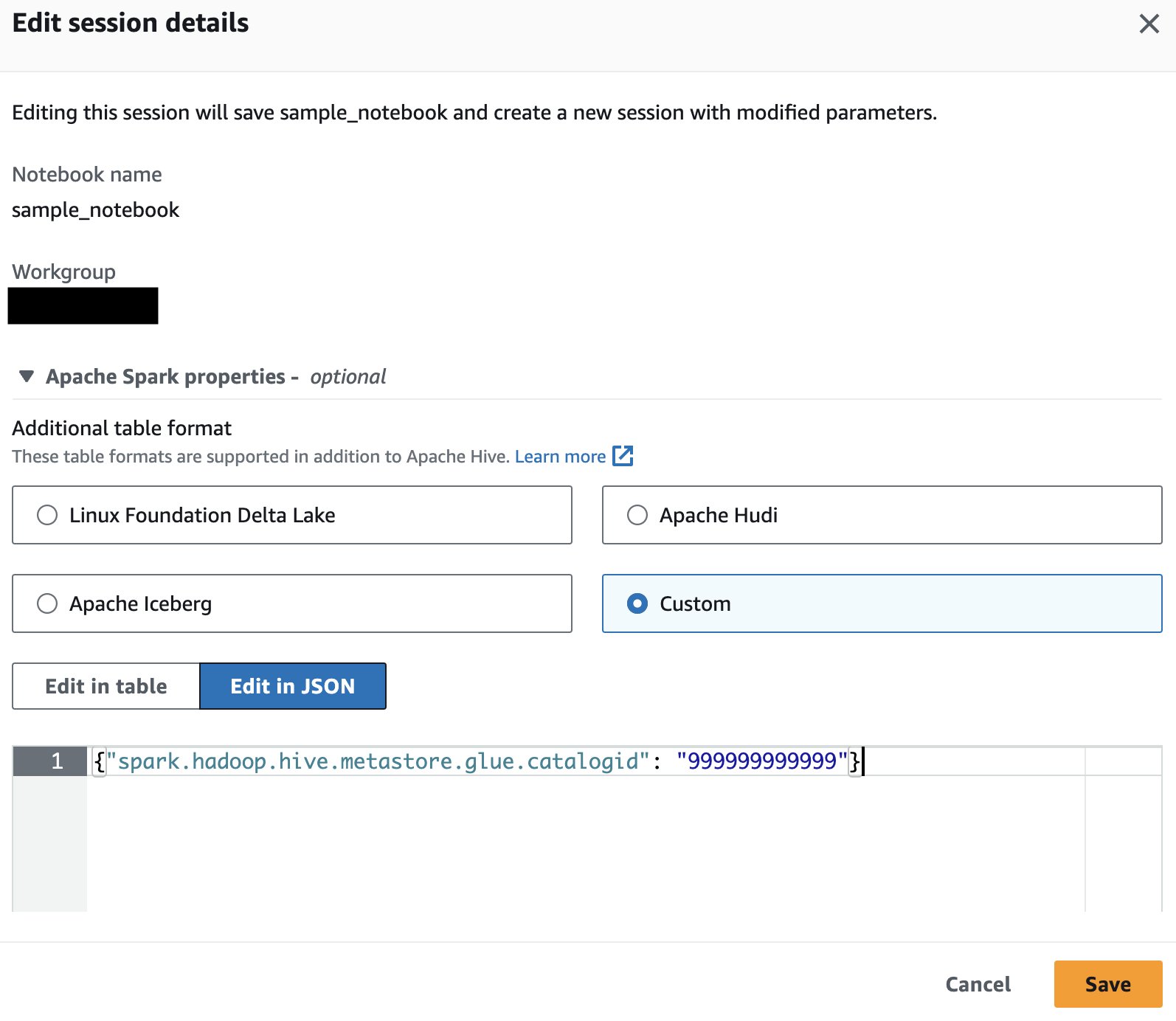 これにより、更新されたパラメータで新しいセッションが開始されます。
これにより、更新されたパラメータで新しいセッションが開始されます。 - Spark で次の SQL ステートメントを実行して、プロデューサー アカウントのカタログからテーブルをクエリします。
複数のプロデューサーテーブルをクエリする
あるいは、各データベース名にプロデューサー AWS アカウント ID を追加することもできます。これは、異なる所有者からデータ カタログにクエリを実行する場合に役立ちます。 このメソッドを有効にするには、プロパティを設定します {"spark.hadoop.aws.glue.catalog.separator": "/"} セッションを起動または編集するとき (前のセクションと同じ手順を使用)。 次に、ソース データ カタログの AWS アカウント ID をデータベース名の一部として追加します。
プロデューサー AWS アカウントに属する S3 バケットがリクエスタ支払いを有効にして設定されている場合、リクエストとダウンロードに対してバケット所有者の代わりにコンシューマに請求されます。 この場合、Athena Spark セッションを起動または編集するときに次のプロパティを追加して、これらのバケットからデータを読み取ることができます。
{"spark.hadoop.fs.s3.useRequesterPaysHeader": "true"}
Amazon S3 内のデータのスキーマを推測し、データ カタログ内でクロールされたテーブルと結合します。
Spark は、データ カタログを介してテーブル構造を理解するだけでなく、スキーマを推論し、ストレージからデータを直接読み取ることができます。 この機能を使用すると、データ アナリストやデータ サイエンティストは、データベースやテーブルを作成することなく、データの迅速な探索を実行できます。また、同じアカウントまたは異なるアカウントのデータ カタログに保存されている他の既存のテーブルでも使用できます。 これを行うには、データ フレームに格納されたデータのスキーマを格納するメモリ内データ構造である Spark temp ビューを使用します。
2020 年の NOAA データセット パーティションを使用して、S3 データをデータ フレームに読み込んで一時ビューを作成します。
これで、クエリを実行できるようになりました。 y20view Spark SQL を Data Catalog データベースであるかのように使用します。

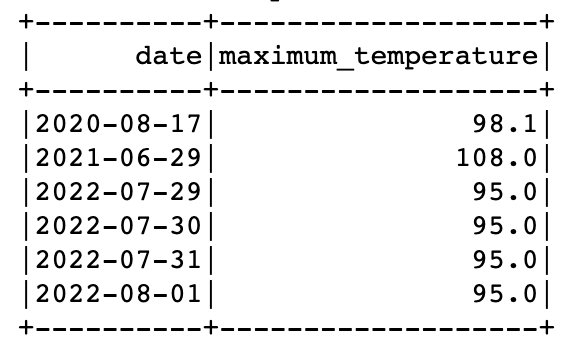
Spark の同じクエリで、一時ビューとデータ カタログ テーブルの両方からデータをクエリできます。 たとえば、2021 年と 2022 年のデータを含むテーブルと、2020 年のデータを含む一時ビューができたので、各年の最高気温が記録された日付を見つけることができます。 'SEATTLE TACOMA AIRPORT, WA US'.
これを行うには、ウィンドウ関数と UNION を使用します。
Spark SQL の UDF を使用して SQL を拡張する
Athena Spark にカスタム ユーザー定義関数を登録して使用することで、SQL 機能を拡張できます。 これらの UDF は、Spark SQL で使用できる一般的な事前定義関数に加えて使用され、一度作成すると、特定のセッション内で何度も再利用できます。
このセクションでは、月の数値を完全な月名に変換する簡単な UDF について説明します。 UDF を Java または Python で作成するオプションがあります。
JavaベースのUDF
UDF の Java コードは次の場所にあります。 GitHubリポジトリ。 この投稿では、UDF の事前構築済み JAR を次の場所にアップロードしました。 s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.jar.
UDF を登録するには、Spark SQL を使用して一時関数を作成します。
Python ベースの UDF
次に、Python UDF を既存の Spark セッションに追加する方法を見てみましょう。 UDF の Python コードは次の場所にあります。 GitHubリポジトリ。 この投稿のコードは次の場所にアップロードされています s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.py.
Python UDF は Spark SQL に登録できないため、代わりに小さな PySpark コードを使用して Python ファイルを追加し、関数をインポートして、それを UDF として登録します。
SQL クエリからビジュアルをプロットする
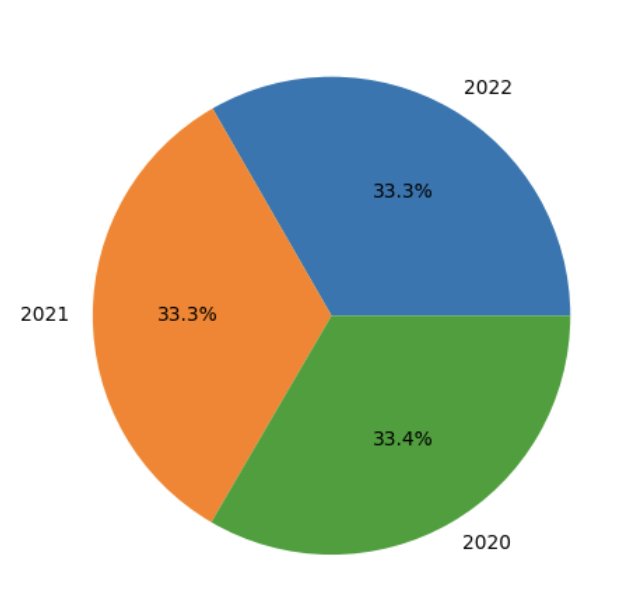
データ探索のための AWS アカウント間での使用など、Spark SQL の使用は簡単であり、UDF を使用して Athena Spark を拡張することも複雑ではありません。 次に、Python を使用して SQL を超えて、同じ Spark セッション内のデータを視覚化し、データ内のパターンを探す方法を見てみましょう。 以前に作成したテーブルと一時ビューを使用して、ステーションの各年に取得された測定値の割合を示す円グラフを生成します。 'SEATTLE TACOMA AIRPORT, WA US'.
まず、SQL クエリから Spark データ フレームを作成し、それを pandas データ フレームに変換します。
クリーンアップ
この投稿用に作成されたリソースをクリーンアップするには、次の手順を実行します。
- ノートブックのセルで次の SQL ステートメントを実行して、データ カタログからデータベースとテーブルを削除します。
- ワークグループを削除する この投稿のために作成されました。 これにより、ワークグループの一部である保存済みのノートブックも削除されます。
- S3 バケットを削除する ワークグループの一部として作成したもの。
まとめ
Athena Spark を使用すると、Athena の Spark SQL を介して AWS Glue データカタログ内のデータベースやテーブルを直接クエリしたり、メタストアを必要とせずに Amazon S3 から直接データをクエリしたりすることがこれまでより簡単になり、迅速なデータ探索が可能になります。 また、カスタム機能用の UDF の登録など、Spark SQL で使用される一般的な高度な SQL コマンドを簡単に使用できるようになります。 さらに、Athena Spark を使用すると、ファスト スタート ノートブック環境で Python を使用して、Spark SQL 経由でクエリされたデータを視覚化し、分析することが簡単になります。
全体として、Spark SQL は Athena の標準 SQL を超える機能を解放し、単一の統合ノートブックで SQL と Python の両方を介して上級ユーザーにさらなる柔軟性とパワーを提供し、インフラストラクチャのセットアップなしで Amazon S3 のデータの高速で複雑な分析を提供します。 Athena Spark について詳しくは、「Athena Spark」を参照してください。 Apache Spark 用 Amazon Athena.
著者について
 パティック・シャー Amazon Athena のシニア分析アーキテクトです。 彼は 2015 年に AWS に入社し、それ以来ビッグデータ分析分野に注力し、AWS 分析サービスを使用して顧客がスケーラブルで堅牢なソリューションを構築できるよう支援しています。
パティック・シャー Amazon Athena のシニア分析アーキテクトです。 彼は 2015 年に AWS に入社し、それ以来ビッグデータ分析分野に注力し、AWS 分析サービスを使用して顧客がスケーラブルで堅牢なソリューションを構築できるよう支援しています。
 ラジ・デヴナス は、Amazon Athena の AWS のプロダクト マネージャーです。 彼は、顧客に愛される製品を構築し、顧客がデータから価値を抽出できるよう支援することに情熱を注いでいます。 彼の経歴は、金融、小売、スマート ビルディング、ホーム オートメーション、データ通信システムなどの複数の最終市場向けのソリューションの提供にあります。
ラジ・デヴナス は、Amazon Athena の AWS のプロダクト マネージャーです。 彼は、顧客に愛される製品を構築し、顧客がデータから価値を抽出できるよう支援することに情熱を注いでいます。 彼の経歴は、金融、小売、スマート ビルディング、ホーム オートメーション、データ通信システムなどの複数の最終市場向けのソリューションの提供にあります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/run-spark-sql-on-amazon-athena-spark/

