At AWS re: Invent 2023 haben wir die allgemeine Verfügbarkeit von bekannt gegeben Wissensdatenbanken für Amazon Bedrock. Mit Knowledge Bases für Amazon Bedrock können Sie Fundamentmodelle (FMs) sicher verbinden Amazonas Grundgestein Zugriff auf Ihre Unternehmensdaten mithilfe eines vollständig verwalteten Retrieval Augmented Generation (RAG)-Modells.
Bei RAG-basierten Anwendungen hängt die Genauigkeit der generierten Antworten von FMs vom Kontext ab, der dem Modell bereitgestellt wird. Kontexte werden basierend auf Benutzerabfragen aus Vektorspeichern abgerufen. In der kürzlich veröffentlichten Funktion für Wissensdatenbanken für Amazon Bedrock: Hybridsuchekönnen Sie die semantische Suche mit der Stichwortsuche kombinieren. In vielen Situationen müssen Sie jedoch möglicherweise Dokumente abrufen, die in einem bestimmten Zeitraum erstellt oder mit bestimmten Kategorien versehen wurden. Um die Suchergebnisse zu verfeinern, können Sie anhand von Dokumentmetadaten filtern, um die Abrufgenauigkeit zu verbessern, was wiederum zu relevanteren FM-Generationen führt, die Ihren Interessen entsprechen.
In diesem Beitrag besprechen wir die neue Funktion zur benutzerdefinierten Metadatenfilterung in den Wissensdatenbanken für Amazon Bedrock, mit der Sie Suchergebnisse verbessern können, indem Sie Ihre Abrufe aus Vektorshops vorfiltern.
Übersicht über die Metadatenfilterung
Vor der Veröffentlichung der Metadatenfilterung wurden alle semantisch relevanten Blöcke bis zum voreingestellten Maximum als Kontext zurückgegeben, den das FM zum Generieren einer Antwort verwenden konnte. Jetzt können Sie mit Metadatenfiltern nicht nur semantisch relevante Blöcke abrufen, sondern eine genau definierte Teilmenge dieser relevanten Chucks basierend auf angewendeten Metadatenfiltern und zugehörigen Werten.
Mit dieser Funktion können Sie jetzt für jedes Dokument in der Wissensdatenbank eine benutzerdefinierte Metadatendatei (jeweils bis zu 10 KB) bereitstellen. Sie können Filter auf Ihre Abrufe anwenden und den Vektorspeicher anweisen, eine Vorfilterung basierend auf Dokumentmetadaten durchzuführen und dann nach relevanten Dokumenten zu suchen. Auf diese Weise haben Sie die Kontrolle über die abgerufenen Dokumente, insbesondere wenn Ihre Abfragen nicht eindeutig sind. Sie können beispielsweise Rechtsdokumente mit ähnlichen Begriffen für unterschiedliche Kontexte oder Filme mit einer ähnlichen Handlung verwenden, die in verschiedenen Jahren veröffentlicht wurden. Darüber hinaus erzielen Sie durch die Reduzierung der Anzahl der durchsuchten Blöcke Leistungsvorteile wie eine Reduzierung der CPU-Zyklen und der Kosten für die Abfrage des Vektorspeichers sowie eine Verbesserung der Genauigkeit.

Um die Metadatenfilterfunktion verwenden zu können, müssen Sie neben den Quelldatendateien auch Metadatendateien mit demselben Namen wie die Quelldatendatei und bereitstellen .metadata.json Suffix. Metadaten können Zeichenfolgen, Zahlen oder boolesche Werte sein. Das Folgende ist ein Beispiel für den Inhalt der Metadatendatei:
Die Metadatenfilterfunktion von Knowledge Bases für Amazon Bedrock ist in den AWS-Regionen USA Ost (Nord-Virginia) und USA West (Oregon) verfügbar.
Im Folgenden sind häufige Anwendungsfälle für die Metadatenfilterung aufgeführt:
- Dokumenten-Chatbot für ein Softwareunternehmen – Auf diese Weise können Benutzer Produktinformationen und Anleitungen zur Fehlerbehebung finden. Filter zum Beispiel nach dem Betriebssystem oder der Anwendungsversion können dabei helfen, das Abrufen veralteter oder irrelevanter Dokumente zu vermeiden.
- Konversationssuche in der Bewerbung einer Organisation – Dadurch können Benutzer Dokumente, Kanbans, Protokolle von Besprechungsaufzeichnungen und andere Assets durchsuchen. Mithilfe von Metadatenfiltern für Arbeitsgruppen, Geschäftseinheiten oder Projekt-IDs können Sie das Chat-Erlebnis personalisieren und die Zusammenarbeit verbessern. Ein Beispiel wäre „Wie ist der Status des Projekts Sphinx und welche Risiken bestehen?“, wo Benutzer Dokumente nach einem bestimmten Projekt oder Quelltyp (z. B. E-Mail oder Besprechungsdokumente) filtern können.
- Intelligente Suche nach Softwareentwicklern – Dadurch können Entwickler nach Informationen zu einer bestimmten Version suchen. Filter nach Release-Version und Dokumenttyp (z. B. Code, API-Referenz oder Problem) können dabei helfen, relevante Dokumente zu lokalisieren.
Lösungsüberblick
In den folgenden Abschnitten zeigen wir, wie Sie einen Datensatz für die Verwendung als Wissensdatenbank vorbereiten und ihn dann mit Metadatenfilterung abfragen. Sie können entweder mit dem abfragen AWS-Managementkonsole oder SDK.
Bereiten Sie einen Datensatz für Wissensdatenbanken für Amazon Bedrock vor
Für diesen Beitrag verwenden wir a Beispieldatensatz über fiktive Videospiele, um zu veranschaulichen, wie Metadaten mithilfe von Wissensdatenbanken für Amazon Bedrock aufgenommen und abgerufen werden. Wenn Sie in Ihrem eigenen AWS-Konto mitverfolgen möchten, laden Sie die Datei herunter.
Wenn Sie Metadaten zu Ihren Dokumenten in einer vorhandenen Wissensdatenbank hinzufügen möchten, erstellen Sie die Metadatendateien mit dem erwarteten Dateinamen und Schema und fahren Sie dann mit dem Schritt zum Synchronisieren Ihrer Daten mit der Wissensdatenbank fort, um die inkrementelle Aufnahme zu starten.
In unserem Beispieldatensatz ist das Dokument jedes Spiels eine separate CSV-Datei (z. B. s3://$bucket_name/video_game/$game_id.csv) mit den folgenden Spalten:
title, description, genres, year, publisher, score
Die Metadaten jedes Spiels haben das Suffix .metadata.json (zum Beispiel, s3://$bucket_name/video_game/$game_id.csv.metadata.json) mit folgendem Schema:
Erstellen Sie eine Wissensdatenbank für Amazon Bedrock
Anweisungen zum Erstellen einer neuen Wissensdatenbank finden Sie unter Erstellen Sie eine Wissensbasis. Für dieses Beispiel verwenden wir die folgenden Einstellungen:
- Auf dem Datenquelle einrichten Seite unter Chunking-StrategieWählen Kein Chunking, da Sie die Dokumente bereits im vorherigen Schritt vorverarbeitet haben.
- Im Einbettungsmodell Wählen Sie im Abschnitt Titan G1-Einbettungen – Text.
- Im Vektordatenbank Wählen Sie im Abschnitt Erstellen Sie schnell einen neuen Vektorspeicher. Die Metadatenfilterfunktion ist für alle unterstützten Vektorspeicher verfügbar.
Synchronisieren Sie den Datensatz mit der Wissensdatenbank
Nachdem Sie die Wissensdatenbank erstellt haben und Ihre Datendateien und Metadatendateien in einer sind Amazon Simple Storage-Service (Amazon S3)-Bucket können Sie mit der inkrementellen Aufnahme beginnen. Anweisungen finden Sie unter Synchronisieren Sie, um Ihre Datenquellen in die Wissensdatenbank aufzunehmen.
Abfrage mit Metadatenfilterung auf der Amazon Bedrock-Konsole
Um die Metadatenfilteroptionen auf der Amazon Bedrock-Konsole zu verwenden, führen Sie die folgenden Schritte aus:
- Wählen Sie auf der Amazon Bedrock-Konsole Wissensbasen im Navigationsbereich.
- Wählen Sie die von Ihnen erstellte Wissensdatenbank aus.
- Auswählen Testen Sie die Wissensdatenbank.
- Wähle die Konfigurationen Symbol, dann erweitern Filter.
- Geben Sie eine Bedingung im Format ein: Schlüssel = Wert (z. B. Genres = Strategie) und drücken Sie Enter.
- Um den Schlüssel, Wert oder Operator zu ändern, wählen Sie die Bedingung aus.
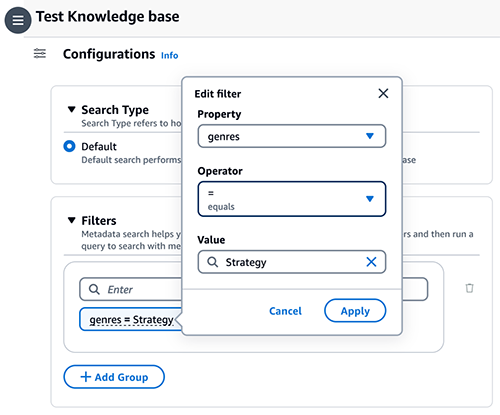
- Fahren Sie mit den verbleibenden Bedingungen fort (z. B. (Genres = Strategie UND Jahr >= 2023) ODER (Bewertung >= 9))

- Wenn Sie fertig sind, geben Sie Ihre Anfrage in das Meldungsfeld ein und wählen Sie dann Führen Sie.
Für diesen Beitrag geben wir die Suchanfrage „Ein Strategiespiel mit cooler Grafik, veröffentlicht nach 2023“ ein.
Abfrage mit Metadatenfilterung mithilfe des SDK
Um das SDK zu verwenden, erstellen Sie zunächst den Client für Agenten für Amazon Bedrock Laufzeit:
Erstellen Sie dann den Filter (im Folgenden einige Beispiele):
Übergeben Sie den Filter an retrievalConfiguration dauert ebenfalls 3 Jahre. Das erste Jahr ist das sog. Abruf-API or Abrufen und generieren API:
In der folgenden Tabelle sind einige Antworten mit unterschiedlichen Metadatenfilterbedingungen aufgeführt.
| Abfrage | Metadatenfilterung | Abgerufene Dokumente | Beobachtungen |
| „Ein Strategiespiel mit cooler Grafik, veröffentlicht nach 2023“ | Off |
* Viking Saga: The Sea Raider, Jahr: 2023, Genres: Strategie * Medieval Castle: Siege and Conquest, Jahr:2022, Genres: Strategie * Kybernetische Revolution: Aufstieg der Maschinen, Jahr:2022, Genres: Strategie |
2/5 Spiele erfüllen die Bedingung (Genres = Strategie und Jahr >= 2023) |
| On | * Viking Saga: The Sea Raider, Jahr: 2023, Genres: Strategie * Fantasy Kingdoms: Chronicles of Eldoria, Jahr: 2023, Genres: Strategie |
2/2 Spiele erfüllen die Bedingung (Genres = Strategie und Jahr >= 2023) |
Zusätzlich zu benutzerdefinierten Metadaten können Sie auch mithilfe von S3-Präfixen filtern (dabei handelt es sich um integrierte Metadaten, sodass Sie keine Metadatendateien bereitstellen müssen). Wenn Sie beispielsweise die Spieldokumente nach Herausgebern in Präfixen organisieren (z. B. s3://$bucket_name/video_game/$publisher/$game_id.csv), können Sie nach dem spezifischen Herausgeber filtern (z. B. neo_tokyo_games) mit der folgenden Syntax:
Aufräumen
Führen Sie die folgenden Schritte aus, um Ihre Ressourcen zu bereinigen:
- Löschen Sie die Wissensdatenbank:
- Wählen Sie auf der Amazon Bedrock-Konsole Wissensbasen für Besetzung im Navigationsbereich.
- Wählen Sie die von Ihnen erstellte Wissensdatenbank aus.
- Beachten Sie die AWS Identity and Access Management and (IAM)-Dienstrollenname im Übersicht über die Wissensdatenbank .
- Im Vektordatenbank Beachten Sie im Abschnitt den Sammlungs-ARN.
- Auswählen Löschen, und geben Sie dann zur Bestätigung „Löschen“ ein.
- Löschen Sie die Vektordatenbank:
- Auf dem Amazon OpenSearch-Dienst Konsole wählen Kollektionen für Serverlos im Navigationsbereich.
- Geben Sie den Sammlungs-ARN ein, den Sie in der Suchleiste gespeichert haben.
- Wählen Sie die Sammlung aus und wählen Sie Löschen.
- Geben Sie in der Bestätigungsaufforderung „Bestätigen“ ein und wählen Sie dann „ Löschen.
- Löschen Sie die IAM-Dienstrolle:
- Wählen Sie in der IAM-Konsole Rollen im Navigationsbereich.
- Suchen Sie nach dem Rollennamen, den Sie zuvor notiert haben.
- Wählen Sie die Rolle aus und wählen Sie Löschen.
- Geben Sie in der Bestätigungsaufforderung den Rollennamen ein und löschen Sie die Rolle.
- Löschen Sie den Beispieldatensatz:
- Navigieren Sie in der Amazon S3-Konsole zu dem S3-Bucket, den Sie verwendet haben.
- Wählen Sie das Präfix und die Dateien aus und wählen Sie dann Löschen.
- Geben Sie zum Löschen in der Bestätigungsaufforderung „Permanent delete“ ein.
Zusammenfassung
In diesem Beitrag haben wir die Metadatenfilterfunktion in den Wissensdatenbanken für Amazon Bedrock behandelt. Sie haben gelernt, wie Sie benutzerdefinierte Metadaten zu Dokumenten hinzufügen und diese als Filter verwenden, während Sie die Dokumente mithilfe der Amazon Bedrock-Konsole und des SDK abrufen und abfragen. Dies trägt dazu bei, die Kontextgenauigkeit zu verbessern, die Abfrageantworten noch relevanter zu machen und gleichzeitig die Kosten für die Abfrage der Vektordatenbank zu senken.
Weitere Ressourcen finden Sie hier:
Über die Autoren
 Corvus Lee ist Senior GenAI Labs Solutions Architect mit Sitz in London. Seine Leidenschaft gilt dem Design und der Entwicklung von Prototypen, die generative KI nutzen, um Kundenprobleme zu lösen. Er hält sich auch über die neuesten Entwicklungen im Bereich der generativen KI und Retrieval-Techniken auf dem Laufenden, indem er sie auf reale Szenarien anwendet.
Corvus Lee ist Senior GenAI Labs Solutions Architect mit Sitz in London. Seine Leidenschaft gilt dem Design und der Entwicklung von Prototypen, die generative KI nutzen, um Kundenprobleme zu lösen. Er hält sich auch über die neuesten Entwicklungen im Bereich der generativen KI und Retrieval-Techniken auf dem Laufenden, indem er sie auf reale Szenarien anwendet.
 Ahmed Ewis ist Senior Solutions Architect bei AWS GenAI Labs und unterstützt Kunden beim Aufbau generativer KI-Prototypen zur Lösung von Geschäftsproblemen. Wenn er nicht gerade mit Kunden zusammenarbeitet, spielt er gerne mit seinen Kindern und kocht.
Ahmed Ewis ist Senior Solutions Architect bei AWS GenAI Labs und unterstützt Kunden beim Aufbau generativer KI-Prototypen zur Lösung von Geschäftsproblemen. Wenn er nicht gerade mit Kunden zusammenarbeitet, spielt er gerne mit seinen Kindern und kocht.
 Chris Pecora ist Generative AI Data Scientist bei Amazon Web Services. Er ist begeistert von der Entwicklung innovativer Produkte und Lösungen und konzentriert sich gleichzeitig auf die kundenorientierte Wissenschaft. Wenn er nicht gerade Experimente durchführt und sich über die neuesten Entwicklungen bei GenAI auf dem Laufenden hält, verbringt er gerne Zeit mit seinen Kindern.
Chris Pecora ist Generative AI Data Scientist bei Amazon Web Services. Er ist begeistert von der Entwicklung innovativer Produkte und Lösungen und konzentriert sich gleichzeitig auf die kundenorientierte Wissenschaft. Wenn er nicht gerade Experimente durchführt und sich über die neuesten Entwicklungen bei GenAI auf dem Laufenden hält, verbringt er gerne Zeit mit seinen Kindern.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-metadata-filtering-to-improve-retrieval-accuracy/

