Die heutige schnelllebige Welt erfordert zeitnahe Erkenntnisse und Entscheidungen, was die Bedeutung des Streamings von Daten erhöht. Unter Streaming-Daten versteht man Daten, die kontinuierlich aus verschiedenen Quellen generiert werden. Die Quellen dieser Daten, wie Clickstream-Ereignisse, Change Data Capture (CDC), Anwendungs- und Serviceprotokolle sowie Internet of Things (IoT)-Datenströme nehmen zu. Snowflake bietet zwei Optionen, um Streaming-Daten in seine Plattform zu integrieren: Snowpipe und Snowflake Snowpipe Streaming. Snowpipe eignet sich für Anwendungsfälle der Dateiaufnahme (Batching), z. B. das Laden großer Dateien aus Amazon Simple Storage-Service (Amazon S3) zu Snowflake. Snowpipe Streaming, eine neuere Funktion, die im März 2023 veröffentlicht wurde, eignet sich für Anwendungsfälle der Rowset-Aufnahme (Streaming), wie zum Beispiel das Laden eines kontinuierlichen Datenstroms aus Amazon Kinesis-Datenströme or Amazon Managed Streaming für Apache Kafka (Amazon MSK).
Vor Snowpipe Streaming nutzten AWS-Kunden Snowpipe für beide Anwendungsfälle: Dateiaufnahme und Rowsetaufnahme. Zuerst haben Sie Streaming-Daten in Kinesis Data Streams oder Amazon MSK aufgenommen, dann Amazon Data Firehose verwendet, um Streams zu aggregieren und in Amazon S3 zu schreiben, und anschließend Snowpipe verwendet, um die Daten in Snowflake zu laden. Dieser mehrstufige Prozess kann jedoch zu Verzögerungen von bis zu einer Stunde führen, bevor Daten für die Analyse in Snowflake verfügbar sind. Darüber hinaus ist es teuer, insbesondere wenn Sie kleine Dateien haben, die Snowpipe in den Snowflake-Kundencluster hochladen muss.
Um dieses Problem zu lösen, lässt sich Amazon Data Firehose jetzt in Snowpipe Streaming integrieren, sodass Sie Datenströme von Kinesis Data Streams, Amazon MSK und Firehose Direct PUT in Sekundenschnelle und zu geringen Kosten erfassen, transformieren und an Snowflake übermitteln können. Mit ein paar Klicks auf der Amazon Data Firehose-Konsole können Sie einen Firehose-Stream einrichten, um Daten an Snowflake zu liefern. Für die Nutzung von Amazon Data Firehose fallen keine Verpflichtungen oder Vorabinvestitionen an, und Sie zahlen nur für die gestreamte Datenmenge.
Zu den wichtigsten Funktionen von Amazon Data Firehose gehören:
- Vollständig verwalteter serverloser Dienst – Sie müssen keine Ressourcen verwalten, und Amazon Data Firehose passt sich automatisch an den Durchsatz Ihrer Datenquelle an, ohne dass eine fortlaufende Verwaltung erforderlich ist.
- Einfache Verwendung ohne Code – Sie müssen keine Bewerbungen schreiben.
- Datenbereitstellung in Echtzeit – Sie können Daten in Sekundenschnelle und effizient an Ihre Ziele bringen.
- Integration mit über 20 AWS-Diensten – Eine nahtlose Integration ist für viele AWS-Dienste verfügbar, wie z. B. Kinesis Data Streams, Amazon MSK, Amazon VPC Flow Logs, AWS WAF-Protokolle, Amazon CloudWatch Logs, Amazon EventBridge, AWS IoT Core und mehr.
- Pay-as-you-go-Modell – Sie zahlen nur für das Datenvolumen, das Amazon Data Firehose verarbeitet.
- Konnektivität – Amazon Data Firehose kann eine Verbindung zu öffentlichen oder privaten Subnetzen in Ihrer VPC herstellen.
In diesem Beitrag wird erklärt, wie Sie Streaming-Daten von AWS innerhalb von Sekunden in Snowflake übertragen können, um erweiterte Analysen durchzuführen. Wir untersuchen gängige Architekturen und veranschaulichen, wie Sie eine serverlose, kostengünstige Low-Code-Lösung für Datenstreaming mit geringer Latenz einrichten.
Lösungsübersicht
Im Folgenden sind die Schritte zum Implementieren der Lösung zum Streamen von Daten von AWS zu Snowflake aufgeführt:
- Erstellen Sie eine Snowflake-Datenbank, ein Schema und eine Tabelle.
- Erstellen Sie einen Kinesis-Datenstrom.
- Erstellen Sie mithilfe einer sicheren privaten Verbindung einen Firehose-Bereitstellungsstream mit Kinesis Data Streams als Quelle und Snowflake als Ziel.
- Um das Setup zu testen, generieren Sie Beispiel-Stream-Daten aus dem Amazon Kinesis-Datengenerator (KDG) mit dem Firehose-Lieferstrom als Ziel.
- Fragen Sie die Snowflake-Tabelle ab, um die in Snowflake geladenen Daten zu validieren.
Die Lösung ist im folgenden Architekturdiagramm dargestellt.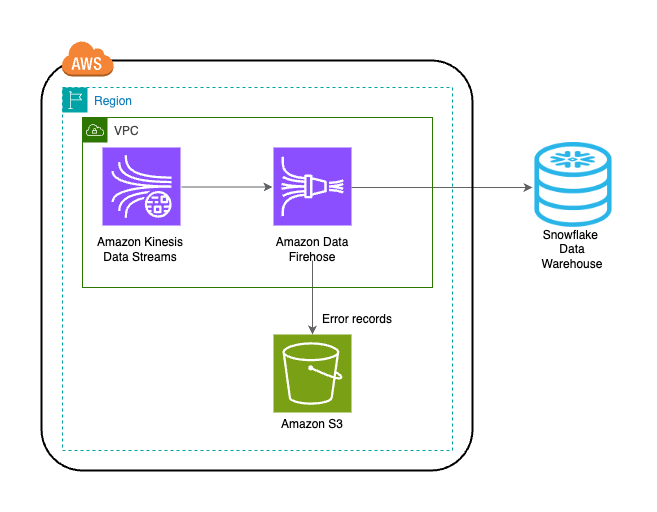
Voraussetzungen:
Folgende Voraussetzungen sollten Sie mitbringen:
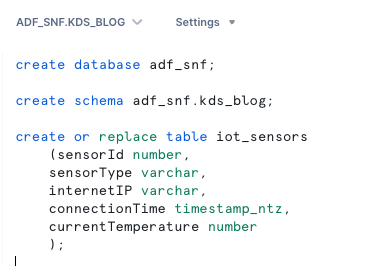
Erstellen Sie eine Snowflake-Datenbank, ein Schema und eine Tabelle
Führen Sie die folgenden Schritte aus, um Ihre Daten in Snowflake einzurichten:
- Melden Sie sich bei Ihrem Snowflake-Konto an und erstellen Sie die Datenbank:
- Erstellen Sie ein Schema in der neuen Datenbank:
- Erstellen Sie eine Tabelle im neuen Schema:
Erstellen Sie einen Kinesis-Datenstrom
Führen Sie die folgenden Schritte aus, um Ihren Datenstrom zu erstellen:
- Wählen Sie in der Kinesis Data Streams-Konsole aus Datenströme im Navigationsbereich.
- Auswählen
Datenstrom erstellen.

- Geben Sie für Datenstromname einen Namen ein (z. B.
KDS-Demo-Stream). - Behalten Sie die restlichen Einstellungen als Standard bei.
- Wählen Sie Datenstrom erstellen.

Erstellen Sie einen Firehose-Lieferstrom
Führen Sie die folgenden Schritte aus, um einen Firehose-Bereitstellungsstream mit Kinesis Data Streams als Quelle und Snowflake als Ziel zu erstellen:
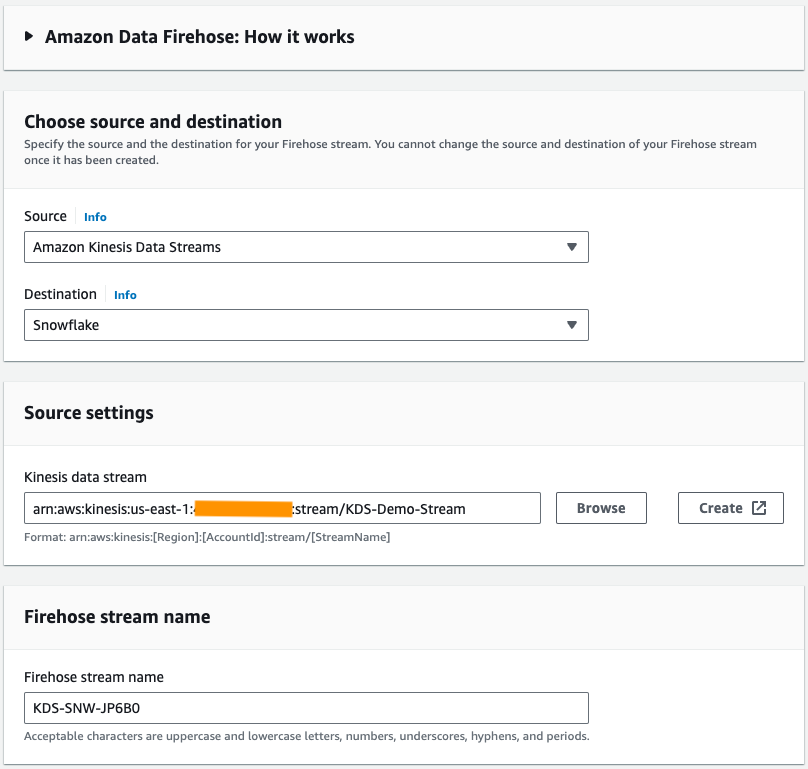
- Wählen Sie in der Amazon Data Firehose-Konsole aus Erstellen Sie einen Firehose-Stream.
- Aussichten für Quelle, wählen Amazon Kinesis-Datenströme.
- Aussichten für Reiseziel, wählen Schneeflocke.
- Aussichten für Kinesis-Datenstrom, navigieren Sie zu dem Datenstrom, den Sie zuvor erstellt haben.
- Aussichten für Name des Firehose-Streams, belassen Sie den standardmäßig generierten Namen oder geben Sie einen Namen Ihrer Wahl ein.
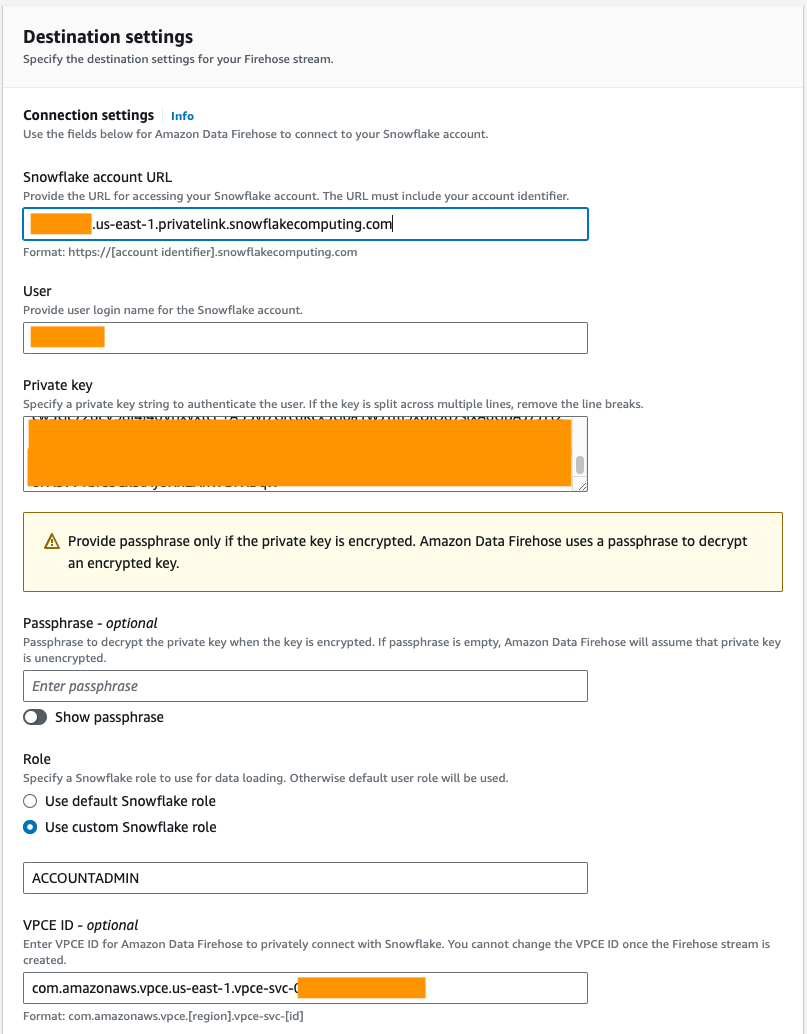
- Der VerbindungseinstellungenGeben Sie die folgenden Informationen an, um Amazon Data Firehose mit Snowflake zu verbinden:
- Aussichten für URL des Snowflake-KontosGeben Sie die URL Ihres Snowflake-Kontos ein.
- Aussichten für MitgliedGeben Sie den in den Voraussetzungen generierten Benutzernamen ein.
- Aussichten für Privat SchlüsselGeben Sie den in den Voraussetzungen generierten privaten Schlüssel ein. Stellen Sie sicher, dass der private Schlüssel im PKCS8-Format vorliegt. Schließen Sie das PEM nicht ein
header-BEGINPräfix undfooter-ENDSuffix als Teil des privaten Schlüssels. Wenn der Schlüssel über mehrere Zeilen verteilt ist, entfernen Sie die Zeilenumbrüche. - Aussichten für RollenWählen Verwenden Sie eine benutzerdefinierte Snowflake-Rolle und geben Sie die IAM-Rolle ein, die Schreibzugriff auf die Datenbanktabelle hat.
Sie können über öffentliche oder private Konnektivität eine Verbindung zu Snowflake herstellen. Wenn Sie keinen VPC-Endpunkt angeben, ist der Standardkonnektivitätsmodus öffentlich. Informationen zum Zulassen der Liste von Firehose-IPs in Ihrer Snowflake-Netzwerkrichtlinie finden Sie unter Wählen Sie Snowflake als Reiseziel. Wenn Sie eine private Link-URL verwenden, geben Sie die VPCE-ID an SYSTEM$GET_PRIVATELINK_CONFIG:
Diese Funktion gibt eine JSON-Darstellung der Snowflake-Kontoinformationen zurück, die erforderlich sind, um die Self-Service-Konfiguration der privaten Konnektivität zum Snowflake-Dienst zu erleichtern, wie im folgenden Screenshot gezeigt.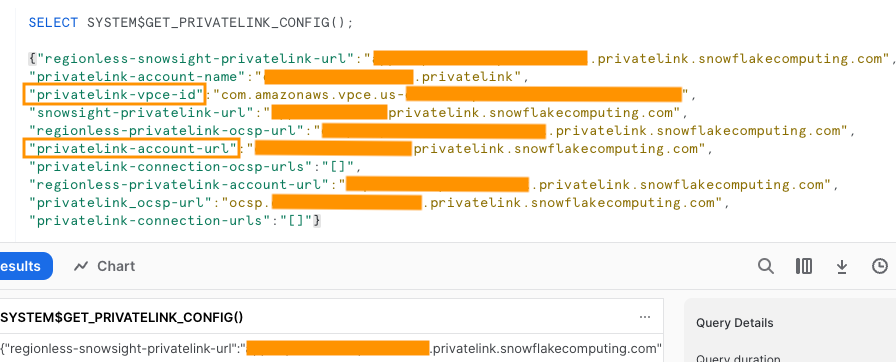
- Für diesen Beitrag verwenden wir einen privaten Link VPCE-ID, geben Sie die VPCE-ID ein.
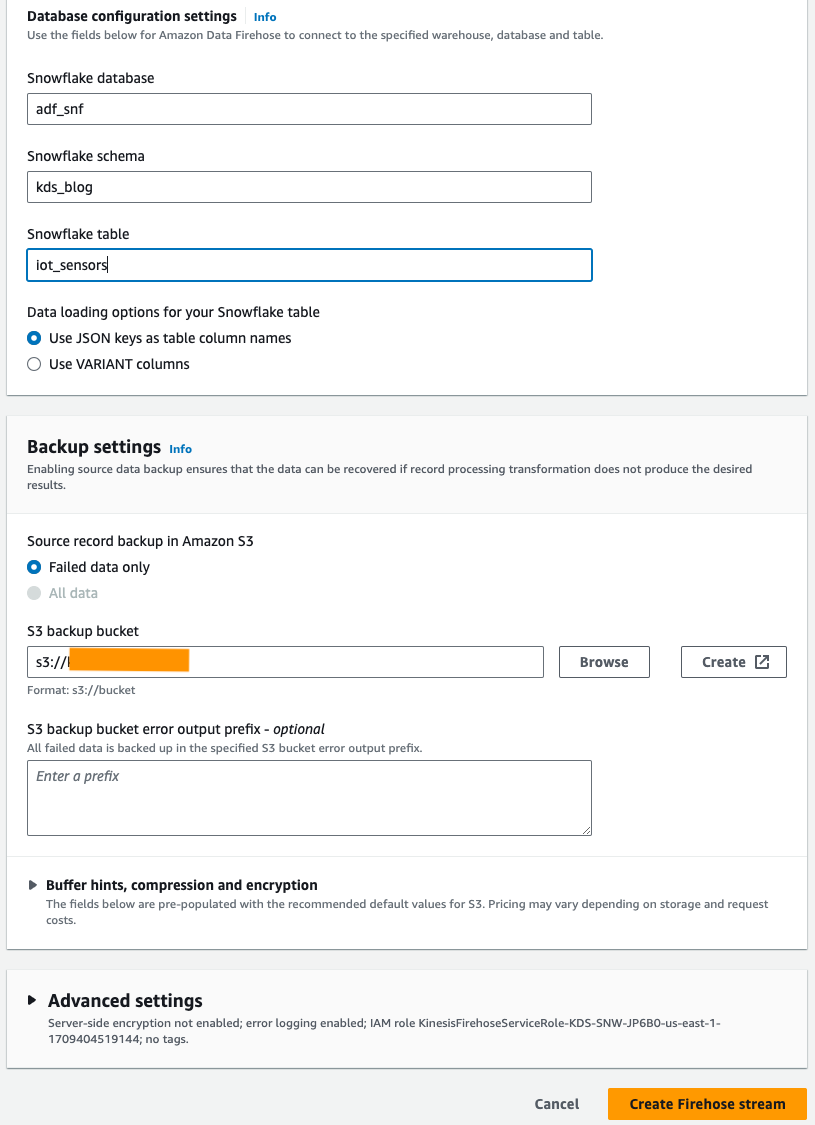
- Der DatenbankkonfigurationseinstellungenGeben Sie Ihre Snowflake-Datenbank, Ihr Schema und Ihre Tabellennamen ein.
- Im Backup-Einstellungen Abschnitt, für S3-Backup-BucketGeben Sie den Bucket ein, den Sie als Teil der Voraussetzungen erstellt haben.
- Auswählen
Erstellen Sie einen Firehose-Stream.
Alternativ können Sie ein AWS CloudFormation Vorlage zum Erstellen des Firehose-Bereitstellungsstreams mit Snowflake als Ziel, anstatt die Amazon Data Firehose-Konsole zu verwenden.
Um den CloudFormation-Stack zu verwenden, wählen Sie
![]()
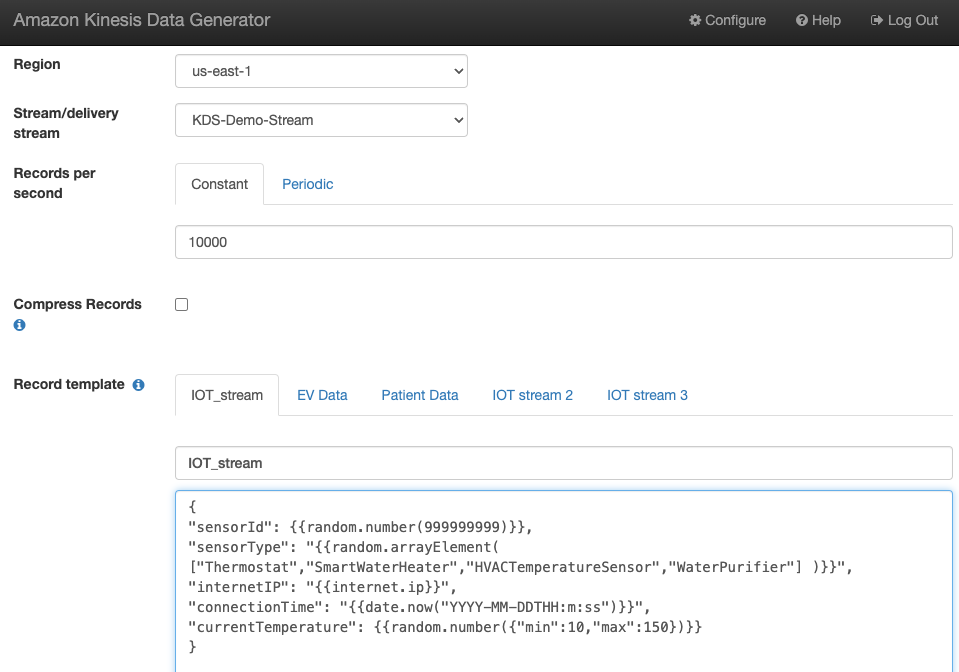
Generieren Sie Beispiel-Stream-Daten
Generieren Sie Beispiel-Stream-Daten aus dem KDG mit dem von Ihnen erstellten Kinesis-Daten-Stream:
Fragen Sie die Snowflake-Tabelle ab
Fragen Sie die Snowflake-Tabelle ab:
Sie können bestätigen, dass die vom KDG generierten und an Kinesis Data Streams gesendeten Daten über Amazon Data Firehose in die Snowflake-Tabelle geladen werden.

Problemlösung
Wenn Daten nicht in Kinesis Data Steams geladen werden, nachdem das KDG Daten an den Firehose-Bereitstellungsstream gesendet hat, aktualisieren Sie es und stellen Sie sicher, dass Sie beim KDG angemeldet sind.
Wenn Sie Änderungen an der Definition der Snowflake-Zieltabelle vorgenommen haben, erstellen Sie den Firehose-Bereitstellungsstream neu.
Aufräumen
Um künftige Kosten zu vermeiden, löschen Sie die Ressourcen, die Sie im Rahmen dieser Übung erstellt haben, wenn Sie nicht vorhaben, sie weiter zu verwenden.
Zusammenfassung
Amazon Data Firehose bietet eine unkomplizierte Möglichkeit, Daten an Snowpipe Streaming zu liefern, sodass Sie Kosten sparen und die Latenz auf Sekunden reduzieren können. Um Amazon Kinesis Firehose mit Snowflake auszuprobieren, sehen Sie sich das Amazon Data Firehose mit Snowflake als Ziellabor an.
Über die Autoren
 Swapna Bandla ist Senior Solutions Architect im AWS Analytics Specialist SA-Team. Swapna hat eine Leidenschaft dafür, die Daten- und Analysebedürfnisse der Kunden zu verstehen und sie in die Lage zu versetzen, cloudbasierte, gut strukturierte Lösungen zu entwickeln. Außerhalb der Arbeit verbringt sie gerne Zeit mit ihrer Familie.
Swapna Bandla ist Senior Solutions Architect im AWS Analytics Specialist SA-Team. Swapna hat eine Leidenschaft dafür, die Daten- und Analysebedürfnisse der Kunden zu verstehen und sie in die Lage zu versetzen, cloudbasierte, gut strukturierte Lösungen zu entwickeln. Außerhalb der Arbeit verbringt sie gerne Zeit mit ihrer Familie.
 Mostafa Mansur ist Principal Product Manager – Tech bei Amazon Web Services, wo er an Amazon Kinesis Data Firehose arbeitet. Er ist spezialisiert auf die Entwicklung intuitiver Produkterlebnisse, die komplexe Herausforderungen für Kunden in großem Umfang lösen. Wenn er nicht gerade hart an Amazon Kinesis Data Firehose arbeitet, finden Sie Mostafa wahrscheinlich auf dem Squashplatz, wo er es liebt, sich mit Herausforderern zu messen und seine Dropshots zu perfektionieren.
Mostafa Mansur ist Principal Product Manager – Tech bei Amazon Web Services, wo er an Amazon Kinesis Data Firehose arbeitet. Er ist spezialisiert auf die Entwicklung intuitiver Produkterlebnisse, die komplexe Herausforderungen für Kunden in großem Umfang lösen. Wenn er nicht gerade hart an Amazon Kinesis Data Firehose arbeitet, finden Sie Mostafa wahrscheinlich auf dem Squashplatz, wo er es liebt, sich mit Herausforderern zu messen und seine Dropshots zu perfektionieren.
 Bosco Albuquerque ist Sr. Partner Solutions Architect bei AWS und verfügt über mehr als 20 Jahre Erfahrung in der Arbeit mit Datenbank- und Analyseprodukten von Anbietern von Unternehmensdatenbanken und Cloud-Anbietern. Er hat Technologieunternehmen dabei geholfen, Datenanalyselösungen und -produkte zu entwerfen und zu implementieren.
Bosco Albuquerque ist Sr. Partner Solutions Architect bei AWS und verfügt über mehr als 20 Jahre Erfahrung in der Arbeit mit Datenbank- und Analyseprodukten von Anbietern von Unternehmensdatenbanken und Cloud-Anbietern. Er hat Technologieunternehmen dabei geholfen, Datenanalyselösungen und -produkte zu entwerfen und zu implementieren.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/uplevel-your-data-architecture-with-real-time-streaming-using-amazon-data-firehose-and-snowflake/

