Dieser Beitrag wurde in Zusammenarbeit mit Bhajandeep Singh und Ajay Vishwakarma von Wipros AWS AI/ML Practice verfasst.
Viele Organisationen nutzen eine Kombination aus lokalen und Open-Source-Data-Science-Lösungen, um Modelle für maschinelles Lernen (ML) zu erstellen und zu verwalten.
Datenwissenschafts- und DevOps-Teams stehen möglicherweise vor Herausforderungen bei der Verwaltung dieser isolierten Tool-Stacks und Systeme. Die Integration mehrerer Tool-Stacks zum Aufbau einer kompakten Lösung kann die Erstellung benutzerdefinierter Konnektoren oder Workflows erfordern. Die Verwaltung verschiedener Abhängigkeiten basierend auf der aktuellen Version jedes Stacks und die Aufrechterhaltung dieser Abhängigkeiten bei der Veröffentlichung neuer Updates jedes Stacks erschwert die Lösung. Dies erhöht die Kosten für die Wartung der Infrastruktur und beeinträchtigt die Produktivität.
Angebote für künstliche Intelligenz (KI) und maschinelles Lernen (ML) von Amazon Web Services (AWS)Zusammen mit integrierten Überwachungs- und Benachrichtigungsdiensten helfen sie Unternehmen dabei, den erforderlichen Grad an Automatisierung, Skalierbarkeit und Modellqualität zu optimalen Kosten zu erreichen. AWS unterstützt außerdem Data-Science- und DevOps-Teams bei der Zusammenarbeit und optimiert den gesamten Modelllebenszyklusprozess.
Das AWS-Portfolio an ML-Services umfasst eine Reihe robuster Services, mit denen Sie die Entwicklung, Schulung und Bereitstellung von Anwendungen für maschinelles Lernen beschleunigen können. Die Servicesuite kann zur Unterstützung des gesamten Modelllebenszyklus einschließlich der Überwachung und Neuschulung von ML-Modellen genutzt werden.
In diesem Beitrag besprechen wir die Modellentwicklung und die Implementierung des MLOps-Frameworks für einen Kunden von Wipro, der es verwendet Amazon Sage Maker und andere AWS-Services.
Wipro ist ein AWS Premier Tier Services-Partner und Managed Service Provider (MSP). Es ist KI/ML-Lösungen steigern die betriebliche Effizienz, Produktivität und das Kundenerlebnis für viele ihrer Unternehmenskunden.
Derzeitige Herausforderungen
Lassen Sie uns zunächst einige der Herausforderungen verstehen, mit denen die Data Science- und DevOps-Teams des Kunden bei ihrem aktuellen Setup konfrontiert waren. Anschließend können wir untersuchen, wie die integrierten AI/ML-Angebote von SageMaker zur Lösung dieser Herausforderungen beigetragen haben.
- Zusammenarbeit – Datenwissenschaftler arbeiteten jeweils an ihren eigenen lokalen Jupyter-Notebooks, um ML-Modelle zu erstellen und zu trainieren. Ihnen fehlte eine effektive Methode für den Austausch und die Zusammenarbeit mit anderen Datenwissenschaftlern.
- Skalierbarkeit – Das Training und erneute Training von ML-Modellen nahm immer mehr Zeit in Anspruch, da die Modelle komplexer wurden, während die zugewiesene Infrastrukturkapazität gleich blieb.
- MLOps – Modellüberwachung und laufende Governance waren nicht eng in die ML-Modelle integriert und automatisiert. Bei der Integration von Tools von Drittanbietern in die MLOps-Pipeline gibt es Abhängigkeiten und Komplexitäten.
- Wiederverwendbarkeit – Ohne wiederverwendbare MLOps-Frameworks muss jedes Modell separat entwickelt und verwaltet werden, was den Gesamtaufwand erhöht und die Modelloperationalisierung verzögert.
Dieses Diagramm fasst die Herausforderungen zusammen und wie die Implementierung von Wipro auf SageMaker diese mit integrierten SageMaker-Diensten und -Angeboten bewältigte.
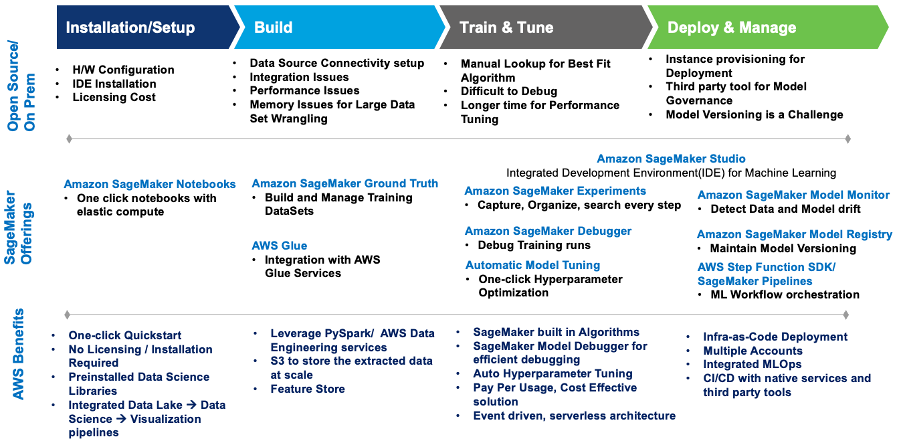
Abbildung 1 – SageMaker-Angebote für die ML-Workload-Migration
Wipro hat eine Architektur definiert, die die Herausforderungen kostenoptimiert und vollautomatisch angeht.
Das Folgende ist der Anwendungsfall und das Modell, die zum Erstellen der Lösung verwendet wurden:
- Anwendungsfall: Preisvorhersage basierend auf dem Gebrauchtwagendatensatz
- Problemtyp: Regression
- Verwendete Modelle: XGBoost und Linear Learner (integrierte SageMaker-Algorithmen)
Lösungsarchitektur
Die Berater von Wipro führten einen Deep-Dive-Discovery-Workshop mit den Data-Science-, DevOps- und Data-Engineering-Teams des Kunden durch, um die aktuelle Umgebung sowie deren Anforderungen und Erwartungen an eine moderne Lösung auf AWS zu verstehen. Am Ende des Beratungsauftrags hatte das Team die folgende Architektur implementiert, die die Kernanforderungen des Kundenteams effektiv erfüllte, darunter:
Code-Sharing – Mit SageMaker-Notizbüchern können Datenwissenschaftler experimentieren und Code mit anderen Teammitgliedern teilen. Wipro beschleunigte seine ML-Modellreise weiter durch die Implementierung der Codebeschleuniger und Snippets von Wipro, um das Feature-Engineering, das Modelltraining, die Modellbereitstellung und die Pipeline-Erstellung zu beschleunigen.
Pipeline für kontinuierliche Integration und kontinuierliche Bereitstellung (CI/CD). – Verwendung der GitHub-Repository-fähigen Codeversionierung des Kunden und automatisierter Skripte, um die Pipeline-Bereitstellung zu starten, wann immer neue Versionen des Codes festgeschrieben werden.
MLOps – Die Architektur implementiert eine SageMaker-Modellüberwachungspipeline für eine kontinuierliche Modellqualitätskontrolle durch Validierung von Daten und Modellabweichungen gemäß den Anforderungen des definierten Zeitplans. Immer wenn eine Abweichung erkannt wird, wird ein Ereignis gestartet, um die jeweiligen Teams zu benachrichtigen, Maßnahmen zu ergreifen oder eine Neuschulung des Modells einzuleiten.
Ereignisgesteuerte Architektur – Die Pipelines für Modelltraining, Modellbereitstellung und Modellüberwachung sind durch die Nutzung gut integriert Amazon EventBridge, ein serverloser Ereignisbus. Wenn definierte Ereignisse auftreten, kann EventBridge eine Pipeline aufrufen, die als Reaktion darauf ausgeführt wird. Dies stellt einen lose gekoppelten Satz von Pipelines bereit, die je nach Bedarf als Reaktion auf die Umgebung ausgeführt werden können.
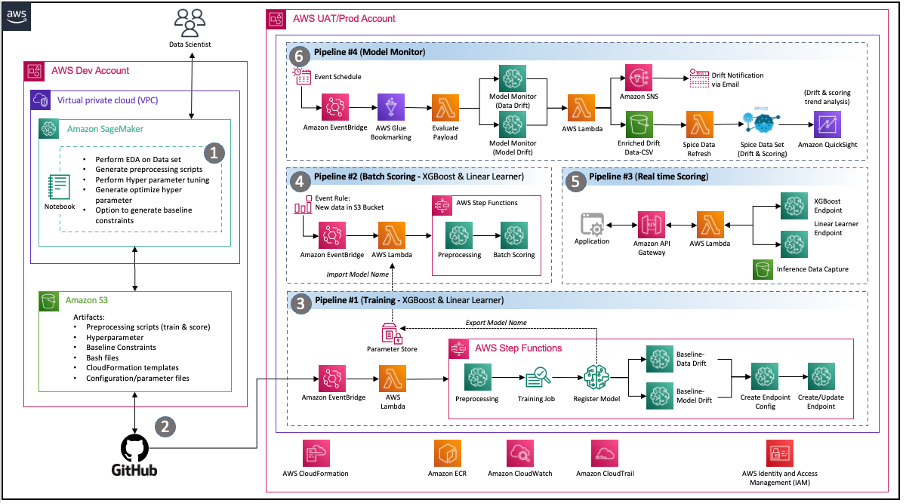
Abbildung 2 – Ereignisgesteuerte MLOps-Architektur mit SageMaker
Lösungskomponenten
In diesem Abschnitt werden die verschiedenen Lösungskomponenten der Architektur beschrieben.
Experimentierhefte
- Zweck: Das Data-Science-Team des Kunden wollte mit verschiedenen Datensätzen und mehreren Modellen experimentieren, um die optimalen Funktionen zu finden, und diese als weitere Eingaben für die automatisierte Pipeline verwenden.
- Lösung: Wipro hat SageMaker-Experiment-Notebooks mit Codeausschnitten für jeden wiederverwendbaren Schritt erstellt, z. B. Lesen und Schreiben von Daten, Modell-Feature-Engineering, Modelltraining und Hyperparameter-Tuning. Feature-Engineering-Aufgaben können auch in Data Wrangler vorbereitet werden, der Kunde hat jedoch ausdrücklich nach SageMaker-Verarbeitungsaufträgen gefragt AWS Step-Funktionen weil sie sich mit der Nutzung dieser Technologien wohler fühlten. Wir haben das AWS Step Function Data Science SDK verwendet, um eine Step-Funktion – für Flow-Tests – direkt aus der Notebook-Instanz zu erstellen, um klar definierte Eingaben für die Pipelines zu ermöglichen. Dies hat dem Datenwissenschaftlerteam geholfen, Pipelines viel schneller zu erstellen und zu testen.
Automatisierte Trainingspipeline
- Zweck: Um eine automatisierte Trainings- und Umschulungspipeline mit konfigurierbaren Parametern wie Instanztyp, Hyperparametern und einem zu ermöglichen Einfacher Amazon-Speicherdienst (Amazon S3) Bucket-Standort. Die Pipeline sollte auch durch das Daten-Push-Ereignis an S3 gestartet werden.
- Lösung: Wipro implementierte eine wiederverwendbare Trainingspipeline mithilfe des Step Functions SDK, der SageMaker-Verarbeitung, Trainingsjobs, eines SageMaker-Modellmonitorcontainers für die Baseline-Generierung, AWS Lambdaund EventBridge-Dienste. Mithilfe der ereignisgesteuerten AWS-Architektur wird die Pipeline so konfiguriert, dass sie automatisch gestartet wird, wenn ein neues Datenereignis an den zugeordneten S3-Bucket übertragen wird. Benachrichtigungen sind so konfiguriert, dass sie an die definierten E-Mail-Adressen gesendet werden. Auf hoher Ebene sieht der Trainingsablauf wie im folgenden Diagramm aus:
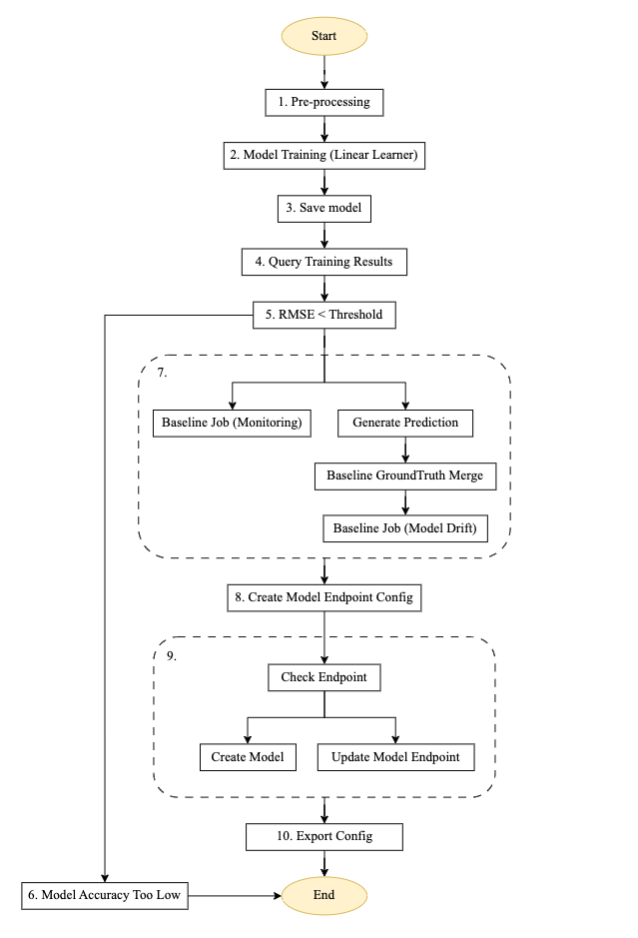
Abbildung 3 – Pipeline-Schrittmaschine trainieren.
Ablaufbeschreibung für die automatisierte Trainingspipeline
Das obige Diagramm ist eine automatisierte Trainingspipeline, die mit Step Functions, Lambda und SageMaker erstellt wurde. Es handelt sich um eine wiederverwendbare Pipeline zum Einrichten eines automatisierten Modelltrainings, zum Generieren von Vorhersagen, zum Erstellen einer Basislinie für die Modellüberwachung und Datenüberwachung sowie zum Erstellen und Aktualisieren eines Endpunkts basierend auf dem vorherigen Modellschwellenwert.
- Vorverarbeitung: Dieser Schritt verwendet Daten von einem Amazon S3-Standort als Eingabe und verwendet den SageMaker SKLearn-Container, um notwendige Aufgaben zur Funktionsentwicklung und Datenvorverarbeitung durchzuführen, wie z. B. das Trainieren, Testen und Validieren der Aufteilung.
- Modelltraining: Mit dem SageMaker SDK führt dieser Schritt Trainingscode mit dem jeweiligen Modellbild aus und trainiert Datensätze aus Vorverarbeitungsskripten, während die trainierten Modellartefakte generiert werden.
- Modell speichern: In diesem Schritt wird ein Modell aus den trainierten Modellartefakten erstellt. Der Modellname wird zur Referenz in einer anderen Pipeline mithilfe von gespeichert AWS Systems Manager-Parameterspeicher.
- Trainingsergebnisse abfragen: Dieser Schritt ruft die Lambda-Funktion auf, um die Metriken des abgeschlossenen Trainingsjobs aus dem früheren Modelltrainingsschritt abzurufen.
- RMSE-Schwelle: In diesem Schritt wird die Metrik des trainierten Modells (RMSE) anhand eines definierten Schwellenwerts überprüft, um zu entscheiden, ob mit der Endpunktbereitstellung fortgefahren oder dieses Modell abgelehnt werden soll.
- Modellgenauigkeit zu gering: In diesem Schritt wird die Modellgenauigkeit mit dem vorherigen besten Modell verglichen. Wenn das Modell bei der Metrikvalidierung fehlschlägt, wird die Benachrichtigung von einer Lambda-Funktion an das in registrierte Zielthema gesendet Einfacher Amazon-Benachrichtigungsdienst (Amazon SNS). Wenn diese Prüfung fehlschlägt, wird der Ablauf beendet, da das neu trainierte Modell den definierten Schwellenwert nicht erreicht hat.
- Basisabweichung der Jobdaten: Wenn das trainierte Modell die Validierungsschritte besteht, werden Basisstatistiken für diese trainierte Modellversion generiert, um die Überwachung zu ermöglichen, und die parallelen Verzweigungsschritte werden ausgeführt, um die Basislinie für die Modellqualitätsprüfung zu generieren.
- Erstellen Sie eine Modellendpunktkonfiguration: Dieser Schritt erstellt eine Endpunktkonfiguration für das bewertete Modell im vorherigen Schritt mit einem Datenerfassung aktivieren Konfiguration.
- Endpunkt prüfen: In diesem Schritt wird überprüft, ob der Endpunkt vorhanden ist oder erstellt werden muss. Basierend auf der Ausgabe besteht der nächste Schritt darin, den Endpunkt zu erstellen oder zu aktualisieren.
- Konfiguration exportieren: In diesem Schritt werden der Modellname, der Endpunktname und die Endpunktkonfiguration des Parameters exportiert AWS-Systemmanager Parameterspeicher.
Warnungen und Benachrichtigungen sind so konfiguriert, dass sie an die konfigurierte SNS-Themen-E-Mail gesendet werden, wenn die Statusänderung des Zustandsautomaten fehlschlägt oder erfolgreich ist. Die gleiche Pipeline-Konfiguration wird für das XGBoost-Modell wiederverwendet.
Automatisierte Batch-Scoring-Pipeline
- Zweck: Starten Sie die Batch-Bewertung, sobald die Bewertungs-Eingabe-Batch-Daten am jeweiligen Amazon S3-Standort verfügbar sind. Bei der Chargenbewertung sollte das zuletzt registrierte Modell für die Bewertung verwendet werden.
- Lösung: Wipro implementierte eine wiederverwendbare Scoring-Pipeline mithilfe des Step Functions SDK, SageMaker-Batch-Transformationsjobs, Lambda und EventBridge. Die Pipeline wird basierend auf der Verfügbarkeit der neuen Scoring-Batch-Daten am jeweiligen S3-Standort automatisch ausgelöst.
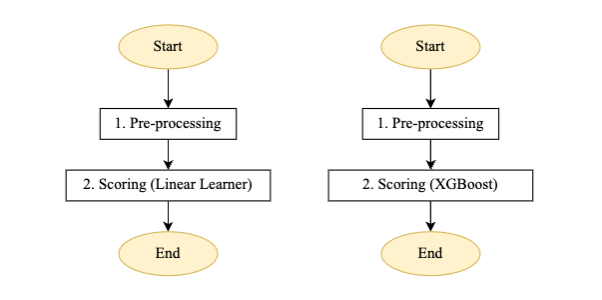
Abbildung 4 – Scoring-Pipeline-Schrittmaschine für lineares Lernen und XGBoost-Modell
Ablaufbeschreibung für die automatisierte Batch-Scoring-Pipeline:
- Vorverarbeitung: Die Eingabe für diesen Schritt ist eine Datendatei vom jeweiligen S3-Speicherort und führt die erforderliche Vorverarbeitung durch, bevor der SageMaker-Stapeltransformationsauftrag aufgerufen wird.
- Besetzung: In diesem Schritt wird der Stapeltransformationsauftrag ausgeführt, um Rückschlüsse zu generieren, die neueste Version des registrierten Modells aufzurufen und die Bewertungsausgabe in einem S3-Bucket zu speichern. Wipro hat den Eingabefilter und die Join-Funktionalität der SageMaker-Stapeltransformations-API verwendet. Es hat dazu beigetragen, die Bewertungsdaten für eine bessere Entscheidungsfindung anzureichern.
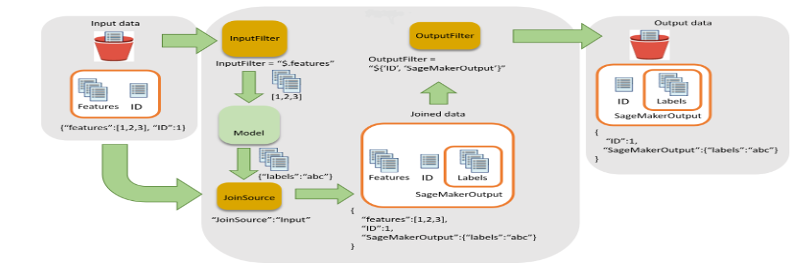
Abbildung 5 – Eingabefilter und Join-Ablauf für die Batch-Transformation
- In diesem Schritt wird die State-Machine-Pipeline durch eine neue Datendatei im S3-Bucket gestartet.
Die Benachrichtigung ist so konfiguriert, dass sie an die konfigurierte SNS-Themen-E-Mail gesendet wird, wenn die Zustandsmaschinenstatusänderung fehlschlägt/erfolgreich erfolgt.
Echtzeit-Inferenzpipeline
- Zweck: Um Echtzeit-Inferenzen von den Endpunkten beider Modelle (Linear Learner und XGBoost) zu ermöglichen und den maximalen vorhergesagten Wert zu erhalten (oder durch Verwendung einer anderen benutzerdefinierten Logik, die als Lambda-Funktion geschrieben werden kann), der an die Anwendung zurückgegeben werden soll.
- Lösung: Das Wipro-Team hat eine wiederverwendbare Architektur mithilfe von implementiert Amazon API-Gateway, Lambda und SageMaker-Endpunkt, wie in Abbildung 6 dargestellt:

Abbildung 6 – Echtzeit-Inferenzpipeline
Flussbeschreibung für die in Abbildung 6 dargestellte Echtzeit-Inferenzpipeline:
- Die Nutzlast wird von der Anwendung an Amazon API Gateway gesendet, das sie an die entsprechende Lambda-Funktion weiterleitet.
- Eine Lambda-Funktion (mit integrierter benutzerdefinierter SageMaker-Ebene) führt die erforderliche Vorverarbeitung, JSON- oder CSV-Nutzlastformatierung durch und ruft die jeweiligen Endpunkte auf.
- Die Antwort wird an Lambda zurückgegeben und über API Gateway an die Anwendung zurückgesendet.
Der Kunde nutzte diese Pipeline für kleine und mittlere Modelle, einschließlich der Verwendung verschiedener Arten von Open-Source-Algorithmen. Einer der Hauptvorteile von SageMaker besteht darin, dass verschiedene Arten von Algorithmen in SageMaker integriert und mithilfe einer BYOC-Technik (Bring Your Own Container) bereitgestellt werden können. BYOC beinhaltet die Containerisierung des Algorithmus und die Registrierung des Bildes Amazon Elastic Container Registry (Amazon ECR)und verwenden Sie dann dasselbe Bild, um einen Container für Training und Inferenz zu erstellen.
Die Skalierung ist eines der größten Probleme im maschinellen Lernzyklus. SageMaker verfügt über die notwendigen Werkzeuge zum Skalieren eines Modells während der Inferenz. In der vorherigen Architektur müssen Benutzer die automatische Skalierung von SageMaker aktivieren, der letztendlich die Arbeitslast bewältigt. Um die automatische Skalierung zu aktivieren, müssen Benutzer eine Richtlinie zur automatischen Skalierung bereitstellen, die den Durchsatz pro Instanz sowie maximale und minimale Instanzen anfragt. Im Rahmen der geltenden Richtlinie übernimmt SageMaker automatisch die Arbeitslast für Echtzeit-Endpunkte und wechselt bei Bedarf zwischen Instanzen.
Benutzerdefinierte Modellmonitor-Pipeline
- Zweck: Das Kundenteam wünschte sich eine automatisierte Modellüberwachung, um sowohl Datendrift als auch Modelldrift zu erfassen. Das Wipro-Team nutzte die SageMaker-Modellüberwachung, um sowohl Datendrift als auch Modelldrift mit einer wiederverwendbaren Pipeline für Echtzeit-Inferenzen und Stapeltransformation zu ermöglichen. Beachten Sie, dass die SageMaker-Modellüberwachung während der Entwicklung dieser Lösung keine Möglichkeit zur Erkennung von Daten oder Daten bot Modelldrift für Batch-Transformation. Wir haben Anpassungen implementiert, um den Modellmonitorcontainer für die Nutzlast der Stapeltransformationen zu verwenden.
- Lösung: Das Wipro-Team hat eine wiederverwendbare Modellüberwachungspipeline für Echtzeit- und Batch-Inferenznutzlasten implementiert AWS-Kleber um die inkrementelle Nutzlast zu erfassen und den Modellüberwachungsjob gemäß dem definierten Zeitplan aufzurufen.

Abbildung 7 – Modell einer Monitor-Schrittmaschine
Ablaufbeschreibung für die benutzerdefinierte Modellmonitor-Pipeline:
Die Pipeline wird gemäß dem definierten Zeitplan ausgeführt, der über EventBridge konfiguriert wurde.
- CSV-Konsolidierung – Es verwendet die Lesezeichenfunktion von AWS Glue, um das Vorhandensein inkrementeller Nutzlast im definierten S3-Bucket der Echtzeit-Datenerfassung und -antwort sowie der Batch-Datenantwort zu erkennen. Anschließend werden diese Daten zur weiteren Verarbeitung aggregiert.
- Nutzlast auswerten – Wenn für den aktuellen Lauf inkrementelle Daten oder Nutzdaten vorhanden sind, wird der Überwachungszweig aufgerufen. Andernfalls wird der Job ohne Verarbeitung umgangen und beendet.
- Nachbearbeitung – Der Überwachungszweig ist so konzipiert, dass er über zwei parallele Unterzweige verfügt – einen für die Datendrift und einen für die Modelldrift.
- Überwachung (Datendrift) – Der Datendriftzweig wird immer dann ausgeführt, wenn eine Nutzlast vorhanden ist. Es verwendet die neuesten Basiseinschränkungen und Statistikdateien des trainierten Modells, die über die Trainingspipeline für die Datenfunktionen generiert wurden, und führt den Modellüberwachungsauftrag aus.
- Überwachung (Modelldrift) – Der Modelldriftzweig wird nur ausgeführt, wenn Ground-Truth-Daten zusammen mit der Inferenznutzlast bereitgestellt werden. Es verwendet Basiseinschränkungen des trainierten Modells und Statistikdateien, die über die Trainingspipeline für die Modellqualitätsmerkmale generiert wurden, und führt den Modellüberwachungsauftrag aus.
- Drift auswerten – Das Ergebnis sowohl der Daten- als auch der Modelldrift ist eine Datei mit Einschränkungsverletzungen, die von der Lambda-Funktion „Evaluation Drift“ ausgewertet wird, die eine Benachrichtigung mit Details zur Drift an die jeweiligen Amazon SNS-Themen sendet. Driftdaten werden durch das Hinzufügen von Attributen für Berichtszwecke weiter angereichert. Die E-Mails mit Abweichungsbenachrichtigungen ähneln den Beispielen in Abbildung 8.

Abbildung 8 – Benachrichtigungsmeldung zu Daten- und Modellabweichungen

Abbildung 9 – Benachrichtigungsmeldung zu Daten- und Modellabweichungen
Einblicke mit der Amazon QuickSight-Visualisierung:
- Zweck: Der Kunde wollte Einblicke in die Daten- und Modelldrift erhalten, die Driftdaten den jeweiligen Modellüberwachungsaufgaben zuordnen und die Inferenzdatentrends herausfinden, um die Art der Interferenzdatentrends zu verstehen.
- Lösung: Das Wipro-Team hat die Driftdaten angereichert, indem es Eingabedaten mit dem Driftergebnis verknüpft hat, was eine Triage von der Drift zur Überwachung und den entsprechenden Bewertungsdaten ermöglicht. Visualisierungen und Dashboards wurden mit erstellt Amazon QuickSight mit Amazonas Athena als Datenquelle (unter Verwendung der Amazon S3 CSV-Bewertungs- und Driftdaten).
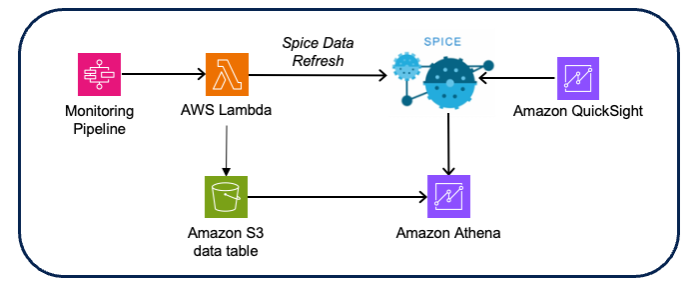
Abbildung 10 – Architektur der Modellüberwachungsvisualisierung
Entwurfsüberlegungen:
- Verwenden Sie den QuickSight-Gewürzdatensatz für eine bessere In-Memory-Leistung.
- Verwenden Sie QuickSight-APIs zum Aktualisieren von Datensätzen, um die Aktualisierung der Spice-Daten zu automatisieren.
- Implementieren Sie gruppenbasierte Sicherheit für die Zugriffskontrolle für Dashboards und Analysen.
- Automatisieren Sie die kontenübergreifende Bereitstellung mithilfe von Export- und Importdatensätzen, Datenquellen und Analyse-API-Aufrufen, die von QuickSight bereitgestellt werden.
Modellüberwachungs-Dashboard:
Um ein effektives Ergebnis und aussagekräftige Einblicke in die Modellüberwachungsaufgaben zu ermöglichen, wurden benutzerdefinierte Dashboards für die Modellüberwachungsdaten erstellt. Die Eingabedatenpunkte werden parallel mit Inferenzanforderungsdaten, Jobdaten und Überwachungsausgaben kombiniert, um eine Visualisierung der durch die Modellüberwachung aufgedeckten Trends zu erstellen.
Dies hat dem Kundenteam wirklich dabei geholfen, die Aspekte verschiedener Datenfunktionen zusammen mit dem vorhergesagten Ergebnis jedes Stapels von Inferenzanfragen zu visualisieren.
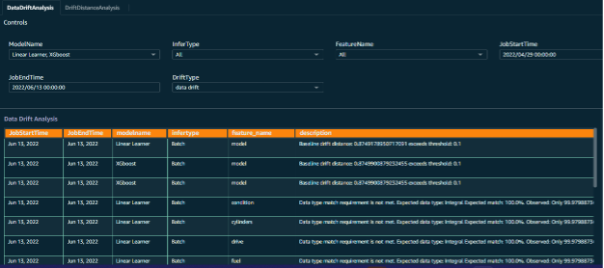
Abbildung 11 – Modellmonitor-Dashboard mit Auswahlaufforderungen

Abbildung 12 – Driftanalyse des Modellmonitors
Zusammenfassung
Die in diesem Beitrag erläuterte Implementierung ermöglichte es Wipro, seine lokalen Modelle effektiv auf AWS zu migrieren und ein skalierbares, automatisiertes Modellentwicklungs-Framework aufzubauen.
Durch die Verwendung wiederverwendbarer Framework-Komponenten kann das Data-Science-Team seine Arbeit effektiv als bereitstellbare AWS Step Functions-JSON-Komponenten verpacken. Gleichzeitig nutzten und verbesserten die DevOps-Teams die automatisierte CI/CD-Pipeline, um die nahtlose Förderung und Umschulung von Modellen in höheren Umgebungen zu ermöglichen.
Die Modellüberwachungskomponente ermöglicht eine kontinuierliche Überwachung der Modellleistung und Benutzer erhalten Warnungen und Benachrichtigungen, wenn Daten oder Modellabweichungen erkannt werden.
Das Team des Kunden nutzt dieses MLOps-Framework, um weitere Modelle zu migrieren oder zu entwickeln und die Akzeptanz von SageMaker zu erhöhen.
Durch die Nutzung der umfassenden Suite von SageMaker-Diensten in Verbindung mit unserer sorgfältig entwickelten Architektur können Kunden nahtlos mehrere Modelle integrieren, was die Bereitstellungszeit erheblich verkürzt und die mit der Codefreigabe verbundenen Komplexitäten verringert. Darüber hinaus vereinfacht unsere Architektur die Wartung der Codeversionierung und sorgt so für einen optimierten Entwicklungsprozess.
Diese Architektur verwaltet den gesamten maschinellen Lernzyklus und umfasst automatisiertes Modelltraining, Echtzeit- und Batch-Inferenz, proaktive Modellüberwachung und Driftanalyse. Diese End-to-End-Lösung ermöglicht es Kunden, eine optimale Modellleistung zu erzielen und gleichzeitig strenge Überwachungs- und Analysefunktionen beizubehalten, um fortlaufende Genauigkeit und Zuverlässigkeit sicherzustellen.
Um diese Architektur zu erstellen, erstellen Sie zunächst wichtige Ressourcen wie Amazon Virtual Private Cloud (Amazon-VPC), SageMaker-Notizbücher und Lambda-Funktionen. Stellen Sie sicher, dass Sie es angemessen einrichten AWS Identitäts- und Zugriffsverwaltung (IAM) Richtlinien für diese Ressourcen.
Konzentrieren Sie sich als Nächstes auf den Aufbau der Komponenten der Architektur – wie Schulungs- und Vorverarbeitungsskripts – in SageMaker Studio oder Jupyter Notebook. Dieser Schritt beinhaltet die Entwicklung des notwendigen Codes und der Konfigurationen, um die gewünschten Funktionalitäten zu ermöglichen.
Nachdem die Komponenten der Architektur definiert sind, können Sie mit der Erstellung der Lambda-Funktionen zum Generieren von Schlussfolgerungen oder zum Durchführen von Nachbearbeitungsschritten für die Daten fortfahren.
Verwenden Sie am Ende Schrittfunktionen, um die Komponenten zu verbinden und einen reibungslosen Arbeitsablauf einzurichten, der die Ausführung jedes Schritts koordiniert.
Über die Autoren
 Stefan Randolph ist Senior Partner Solutions Architect bei Amazon Web Services (AWS). Er befähigt und unterstützt Global Systems Integrator (GSI)-Partner mit der neuesten AWS-Technologie bei der Entwicklung von Branchenlösungen zur Lösung geschäftlicher Herausforderungen. Stephen hat eine besondere Leidenschaft für Sicherheit und generative KI und unterstützt Kunden und Partner bei der Entwicklung sicherer, effizienter und innovativer Lösungen auf AWS.
Stefan Randolph ist Senior Partner Solutions Architect bei Amazon Web Services (AWS). Er befähigt und unterstützt Global Systems Integrator (GSI)-Partner mit der neuesten AWS-Technologie bei der Entwicklung von Branchenlösungen zur Lösung geschäftlicher Herausforderungen. Stephen hat eine besondere Leidenschaft für Sicherheit und generative KI und unterstützt Kunden und Partner bei der Entwicklung sicherer, effizienter und innovativer Lösungen auf AWS.
 Bhajadeep Singh war als Leiter des AWS AI/ML Center of Excellence bei Wipro Technologies tätig und leitete Kundenprojekte zur Bereitstellung von Datenanalysen und KI-Lösungen. Er verfügt über die AWS AI/ML Specialty-Zertifizierung und verfasst technische Blogs zu AI/ML-Diensten und -Lösungen. Mit seiner Erfahrung in der branchenübergreifenden Führung von AWS-KI/ML-Lösungen hat Bhajandeep seinen Kunden durch sein Fachwissen und seine Führungsqualitäten ermöglicht, den Wert der AWS-KI/ML-Dienste zu maximieren.
Bhajadeep Singh war als Leiter des AWS AI/ML Center of Excellence bei Wipro Technologies tätig und leitete Kundenprojekte zur Bereitstellung von Datenanalysen und KI-Lösungen. Er verfügt über die AWS AI/ML Specialty-Zertifizierung und verfasst technische Blogs zu AI/ML-Diensten und -Lösungen. Mit seiner Erfahrung in der branchenübergreifenden Führung von AWS-KI/ML-Lösungen hat Bhajandeep seinen Kunden durch sein Fachwissen und seine Führungsqualitäten ermöglicht, den Wert der AWS-KI/ML-Dienste zu maximieren.
 Ajay Vishwakarma ist ein ML-Ingenieur für den AWS-Bereich der KI-Lösungspraxis von Wipro. Er verfügt über gute Erfahrung in der Entwicklung von BYOM-Lösungen für benutzerdefinierte Algorithmen in SageMaker, der End-to-End-ETL-Pipeline-Bereitstellung, der Erstellung von Chatbots mit Lex, der kontoübergreifenden QuickSight-Ressourcenfreigabe und der Erstellung von CloudFormation-Vorlagen für Bereitstellungen. Er erforscht gerne AWS und nimmt jedes Kundenproblem als Herausforderung, mehr zu erforschen und Lösungen dafür anzubieten.
Ajay Vishwakarma ist ein ML-Ingenieur für den AWS-Bereich der KI-Lösungspraxis von Wipro. Er verfügt über gute Erfahrung in der Entwicklung von BYOM-Lösungen für benutzerdefinierte Algorithmen in SageMaker, der End-to-End-ETL-Pipeline-Bereitstellung, der Erstellung von Chatbots mit Lex, der kontoübergreifenden QuickSight-Ressourcenfreigabe und der Erstellung von CloudFormation-Vorlagen für Bereitstellungen. Er erforscht gerne AWS und nimmt jedes Kundenproblem als Herausforderung, mehr zu erforschen und Lösungen dafür anzubieten.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/modernizing-data-science-lifecycle-management-with-aws-and-wipro/

