Dieser Beitrag wurde gemeinsam mit Ramesh Daddala, Jitendra Kumar Dash und Pavan Kumar Bijja von Bristol Myers Squibb verfasst.
Bristol Myers Squibb (BMS) ist ein globales biopharmazeutisches Unternehmen, dessen Mission es ist, innovative Medikamente zu entdecken, zu entwickeln und bereitzustellen, die Patienten dabei helfen, schwere Krankheiten zu überwinden. BMS arbeitet kontinuierlich an Innovationen und erzielt bedeutende klinische und regulatorische Erfolge. In Zusammenarbeit mit AWS erkannte BMS einen geschäftlichen Bedarf, seine benutzerdefinierte ETL-Plattform (Extrahieren, Transformieren und Laden) auf eine native AWS-Lösung zu migrieren und zu modernisieren, um Komplexität, Ressourcen und Investitionen für ein Upgrade zu reduzieren, wenn neue Spark-, Python- oder AWS-Kleber Versionen werden veröffentlicht. Neben der Nutzung nativ verwalteter AWS-Dienste, über deren Aktualisierung sich BMS keine Gedanken machen musste, wollte BMS auch technisch nicht versierten Geschäftsanwendern einen ETL-Dienst anbieten, mit dem Datentransformations-Workflows visuell erstellt und nahtlos auf dem AWS Glue Apache Spark ausgeführt werden können -basierte serverlose Datenintegrations-Engine. AWS Glue Studio ist eine grafische Oberfläche, die das Erstellen, Ausführen und Überwachen von ETL-Jobs in AWS Glue vereinfacht. Durch die Bereitstellung dieses Dienstes reduzierte BMS den Betriebsaufwand und die Kosten und bot Geschäftsanwendern die Flexibilität, ETL-Aufgaben problemlos durchzuführen.
In den letzten fünf Jahren nutzte BMS ein benutzerdefiniertes Framework namens Enterprise Data Lake Services (EDLS), um ETL-Jobs für Geschäftsanwender zu erstellen. Obwohl dieses Framework ihre ETL-Ziele erfüllte, war es schwierig zu warten und zu aktualisieren. Die EDLS-Plattform von BMS beherbergt über 5 Arbeitsplätze und wächst im Jahresvergleich um 5,000 %. Jedes Mal, wenn die neuere Version von Apache Spark (und die entsprechende AWS Glue-Version) veröffentlicht wurde, waren erhebliche betriebliche Unterstützung und zeitaufwändige manuelle Änderungen erforderlich, um bestehende ETL-Jobs zu aktualisieren. Das manuelle Aktualisieren, Testen und Bereitstellen von über 15 Jobs alle paar Quartale war zeitaufwändig, fehleranfällig, kostspielig und nicht nachhaltig. Da eine weitere Veröffentlichung des EDLS-Frameworks ausstand, beschloss BMS, alternative verwaltete Lösungen zu prüfen, um deren Betriebs- und Upgrade-Herausforderungen zu reduzieren.
In diesem Beitrag teilen wir mit, wie BMS modernisieren wird, indem es den Erfolg des Proof-of-Concept nutzt, der auf die ETL-Plattform von BMS mit AWS Glue Studio abzielt.
Lösungsüberblick
Diese Lösung erfüllt die EDLS-Anforderungen von BMS, um Herausforderungen mithilfe eines maßgeschneiderten ETL-Frameworks zu meistern, das häufige Wartung und Komponenten-Upgrades (die umfangreiche Testzyklen erforderten) erforderte, Komplexität zu vermeiden und die Gesamtkosten der zugrunde liegenden Infrastruktur zu reduzieren, die aus dem Proof of Concept abgeleitet wurden. BMS hatte folgende Ziele:
- Entwickeln Sie ETL-Jobs mit visuellen Workflows, die von bereitgestellt werden AWS Glue Studio Visueller Editor. Der visuelle Editor von AWS Glue Studio ist eine Low-Code-Umgebung, mit der Sie Datentransformations-Workflows erstellen, diese nahtlos auf der serverlosen Datenintegrations-Engine AWS Glue Apache Spark ausführen und das Schema und die Datenergebnisse in jedem Schritt des Auftrags überprüfen können .
- Migrieren Sie über 5,000 bestehende ETL-Jobs mit dem nativen AWS Glue Studio auf automatisierte und skalierbare Weise.
EDLS-Jobschritte und Metadaten
Jeder EDLS-Job besteht aus einem oder mehreren Jobschritten, die miteinander verkettet sind und in einer vordefinierten Reihenfolge ausgeführt werden, die vom benutzerdefinierten ETL-Framework orchestriert wird. Jeder Jobschritt umfasst die folgenden ETL-Funktionen:
- Dateiaufnahme – Mit der Dateiaufnahme können Sie Dateien aus mehreren Dateiquellen aufnehmen oder auflisten, z Amazon Simple Storage-Service (Amazon S3), SFTP und mehr. Die Metadaten enthalten Konfigurationen für den Dateiaufnahmeschritt, um eine Verbindung zu Amazon S3- oder SFTP-Endpunkten herzustellen und Dateien am Zielspeicherort aufzunehmen. Es ruft die angegebenen Dateien und verfügbaren Metadaten ab, um sie auf der Benutzeroberfläche anzuzeigen.
- Datenqualitätsprüfung – Mit dem Datenqualitätsmodul können Sie Qualitätsprüfungen für große Datenmengen durchführen und Berichte erstellen, die die Datenqualität beschreiben und validieren. Der Datenqualitätsschritt verwendet ein von EDLS aufgenommenes Quellobjekt von Amazon S3 und führt eine oder mehrere vom Mandanten konfigurierte Datenkonformitätsprüfungen durch.
- Datentransformationsbeitritt – Dies ist eines der Untermodule des Datentransformationsmoduls, das Verknüpfungen zwischen den Datensätzen mithilfe eines benutzerdefinierten SQL basierend auf der Metadatenkonfiguration durchführen kann.
- Datenbankaufnahme – Der Datenbankaufnahmeschritt ist eine der wichtigen Servicekomponenten in EDLS, die es Ihnen erleichtert, die gewünschten Daten aus der Datenbank abzurufen, zu importieren und in eine bestimmte Datei am Speicherort Ihrer Wahl zu exportieren.
- Datentransformation – Das Datentransformationsmodul führt mithilfe von JSON-gesteuerten Regeln verschiedene Datentransformationen für die Quelldaten durch. Jede Datentransformationsfunktion verfügt über eine eigene JSON-Regel und basierend auf der spezifischen JSON-Regel, die Sie bereitstellen, führt EDLS die Datentransformation für die am Amazon S3-Speicherort verfügbaren Dateien durch.
- Datenpersistenz – Das Datenpersistenzmodul ist eine der wichtigen Servicekomponenten in EDLS, die es Ihnen ermöglicht, die gewünschten Daten von der Quelle zu beziehen und sie in einem zu speichern Relationaler Amazon-Datenbankdienst (Amazon RDS) Datenbank.
Zu den jedem Jobschritt entsprechenden Metadaten gehören Aufnahmequellen, Transformationsregeln, Datenqualitätsprüfungen und Datenziele, die in einer RDS-Instanz gespeichert sind.
Migrationsdienstprogramm
Die Lösung besteht darin, ein Python-Dienstprogramm zu erstellen, das EDLS-Metadaten aus der RDS-Datenbank liest und jeden Jobschritt in eine entsprechende JSON-Knotendarstellung des visuellen AWS Glue Studio-Editors übersetzt.
AWS Glue Studio bietet zwei Arten von Transformationen:
- AWS Glue-native Transformationen – Diese stehen allen Benutzern zur Verfügung und werden von AWS Glue verwaltet.
- Benutzerdefinierte visuelle Transformationen – Mit dieser neuen Funktionalität können Sie benutzerdefinierte Transformationen hochladen, die in AWS Glue Studio verwendet werden. Benutzerdefinierte visuelle Transformationen erweitern die verwalteten Transformationen und ermöglichen Ihnen die Suche und Verwendung von Transformationen über die AWS Glue Studio-Schnittstelle.
Im Folgenden finden Sie ein allgemeines Diagramm, das den Ablauf der Migration eines BMS EDLS-Auftrags zu einem visuellen Editor-Auftrag von AWS Glue Studio darstellt.

Die Migration von BMS EDLS-Jobs zu AWS Glue Studio umfasst die folgenden Schritte:
- Das Python-Dienstprogramm liest vorhandene Metadaten aus der EDLS-Metadatendatenbank.
- Für jeden Auftragsschritttyp wählt das Python-Dienstprogramm basierend auf den Auftragsmetadaten entweder die native AWS Glue-Transformation aus, sofern verfügbar, oder eine benutzerdefinierte visuelle Transformation (wenn die native Funktionalität fehlt).
- Das Python-Dienstprogramm analysiert die Abhängigkeitsinformationen aus Metadaten und erstellt ein JSON-Objekt, das einen visuellen Workflow darstellt, der als gerichteter azyklischer Graph (DAG) dargestellt wird.
- Das JSON-Objekt wird an gesendet AWS Glue-API, wodurch der AWS Glue ETL-Job erstellt wird. Diese Jobs werden im visuellen Editor von AWS Glue Studio mithilfe einer Reihe von Quellen, Transformationen (nativ und benutzerdefiniert) und Zielen visuell dargestellt.
Beispiel für die Generierung eines ETL-Jobs mit AWS Glue Studio
Das folgende Flussdiagramm zeigt einen Beispiel-ETL-Auftrag, der die Quell-RDBMS-Daten in AWS Glue basierend auf geänderten Zeitstempeln mithilfe eines benutzerdefinierten SQL inkrementell aufnimmt und sie mit den Zieldaten auf Amazon S3 zusammenführt.
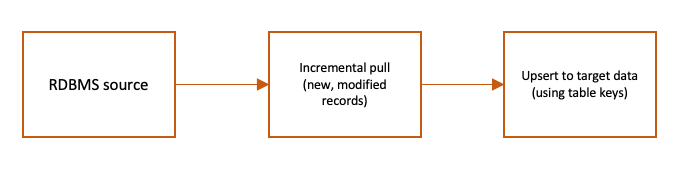
Der vorhergehende ETL-Ablauf kann mit dem visuellen Editor von AWS Glue Studio durch eine Kombination aus nativen und benutzerdefinierten visuellen Transformationen dargestellt werden.
Benutzerdefinierte visuelle Transformation für die inkrementelle Aufnahme
Post POC, BMS und AWS haben festgestellt, dass ein Bedarf besteht, benutzerdefinierte Transformationen zu nutzen, um eine Teilmenge von Jobs unter Nutzung ihres aktuellen EDLS-Service auszuführen, bei denen die Glue Studio-Funktionalität nicht selbstverständlich ist. Die Anforderung des BMS-Teams bestand darin, Daten aus verschiedenen Datenbanken aufzunehmen, ohne von der Existenz von Transaktionsprotokollen oder einem bestimmten Schema abhängig zu sein AWS-Datenbankmigrationsservice (AWS DMS) war für sie keine Option. AWS Glue Studio bietet die visuelle Transformation nativer SQL-Abfragen, wobei eine benutzerdefinierte SQL-Abfrage zum Transformieren der Quelldaten verwendet werden kann. Um jedoch die Quelldatenbanktabelle basierend auf einer geänderten Zeitstempelspalte abzufragen und neue und geänderte Datensätze seit dem letzten ETL-Lauf abzurufen, muss der vorherige Zustand der Zeitstempelspalte beibehalten werden, damit er im aktuellen ETL-Lauf verwendet werden kann. Dies muss ein wiederkehrender Prozess sein und kann auch über verschiedene RDBMS-Quellen abstrahiert werden, darunter Oracle, MySQL, Microsoft SQL Server, SAP Hana und mehr.
AWS Glue bietet eine Job-Lesezeichenfunktion, um die Daten zu verfolgen, die bereits während eines früheren ETL-Laufs verarbeitet wurden. Ein AWS Glue-Job-Lesezeichen unterstützt eine oder mehrere Spalten als Lesezeichenschlüssel zur Bestimmung neuer und verarbeiteter Daten und erfordert, dass die Schlüssel lückenlos nacheinander erhöht oder verringert werden. Obwohl dies für viele Anwendungsfälle mit inkrementeller Last funktioniert, besteht die Anforderung darin, Daten aus verschiedenen Quellen aufzunehmen, ohne von einem bestimmten Schema abhängig zu sein. Daher haben wir in diesem Anwendungsfall kein AWS Glue-Job-Lesezeichen verwendet.
Der SQL-basierte inkrementelle Ingestion-Pull kann auf generische Weise mit a entwickelt werden benutzerdefinierte visuelle Transformation Verwenden eines Beispieljobs für die inkrementelle Aufnahme aus einer MySQL-Datenbank. Die inkrementellen Daten werden mithilfe eines Upsert-Schreibvorgangs im Amazon S3-Zielspeicherort im Apache Hudi-Format zusammengeführt.
Im folgenden Beispiel verwenden wir den MySQL-Datenquellenknoten, um die Verbindung zu definieren, aber der DynamicFrame der Datenquelle selbst wird nicht verwendet. Der benutzerdefinierte Transformationsknoten (inkrementelle DB-Aufnahme) fungiert als Quelle für das inkrementelle Lesen der Daten unter Verwendung der benutzerdefinierten SQL-Abfrage und des zuvor beibehaltenen Zeitstempels der letzten Aufnahme.
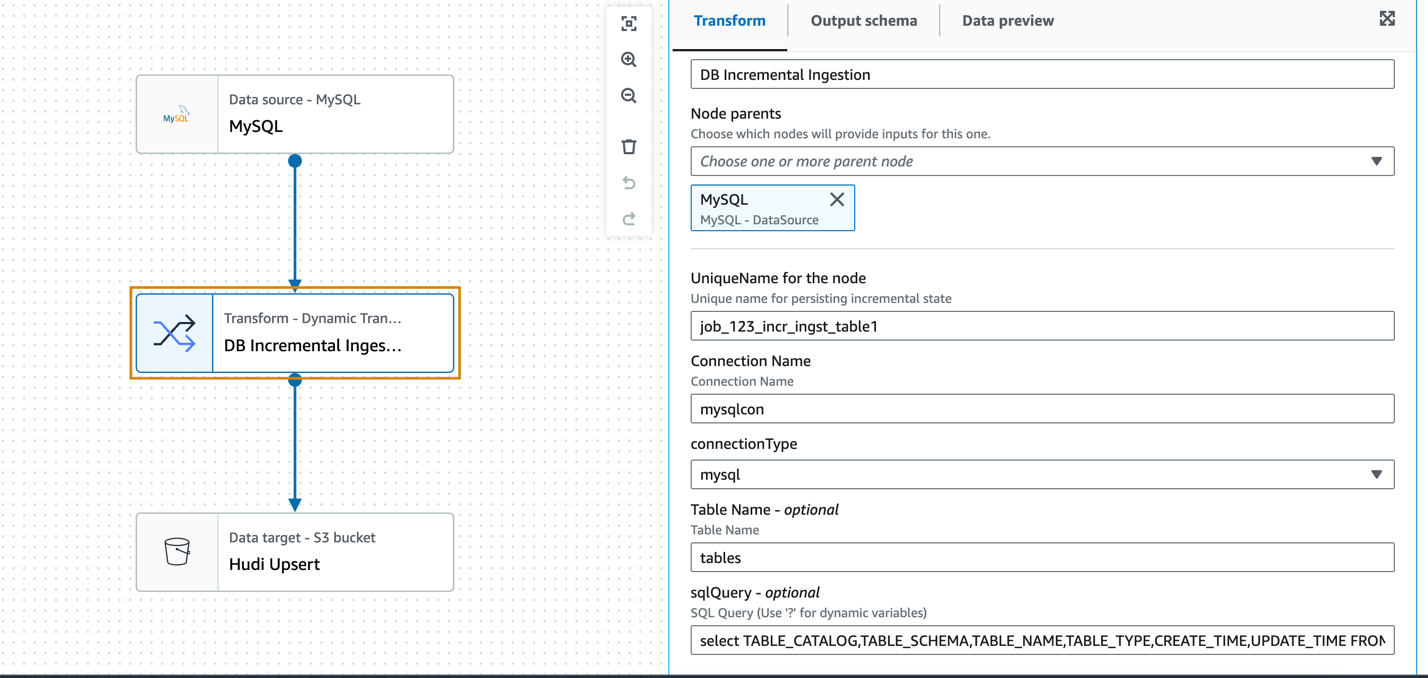
Die Transformation akzeptiert als Eingabeparameter den vorkonfigurierten AWS Glue-Verbindungsnamen, den Datenbanktyp, den Tabellennamen und benutzerdefiniertes SQL (parametrisiertes Zeitstempelfeld).
Das Folgende ist ein Beispiel für den Python-Code für die visuelle Transformation:
Um die Quelldaten mit dem Amazon S3-Ziel zusammenzuführen, kann ein Data-Lake-Framework wie Apache Hudi oder Apache Iceberg verwendet werden, das in AWS Glue 3.0 und höher nativ unterstützt wird.
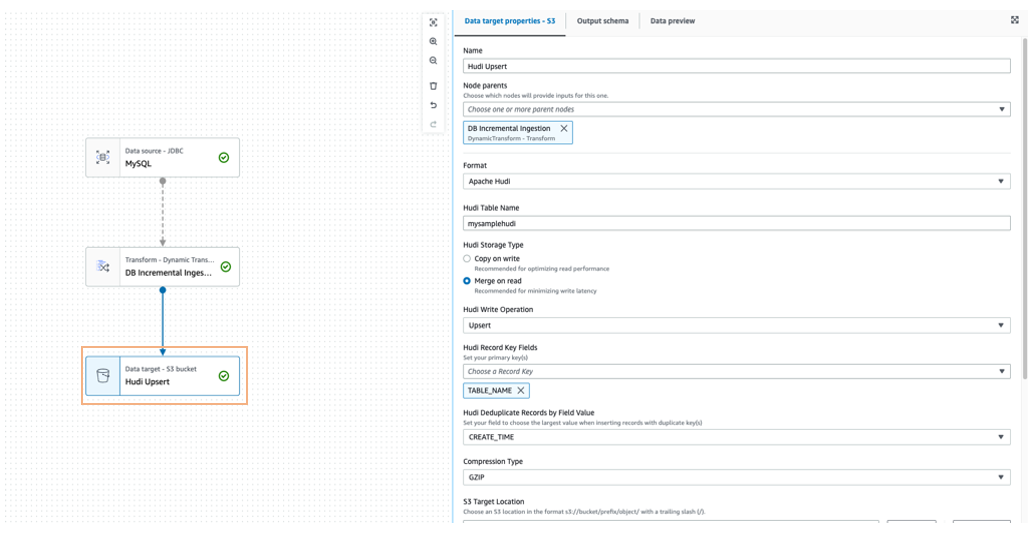
Sie können auch Amazon EventBridge um die endgültige Statusänderung des AWS Glue-Auftrags zu erkennen und zu aktualisieren Amazon DynamoDB entsprechend den zuletzt aufgenommenen Zeitstempel der Tabelle.
Erstellen Sie den AWS Glue Studio-Job mit dem AWS SDK for Python (Boto3) und der AWS Glue API
Für den Beispiel-ETL-Fluss und den entsprechenden AWS Glue Studio ETL-Job haben wir zuvor die zugrunde liegende Funktion gezeigt CodeGenConfigurationNode struct (eine AWS Glue-Auftragsdefinition, die mithilfe von erstellt wurde AWS-Befehlszeilenschnittstelle (AWS CLI)-Befehl aws glue get-job –job-name <jobname>) wird als JSON-Objekt dargestellt, wie im folgenden Code dargestellt:
Das im dargestellten JSON-Objekt (ETL-Job-DAG). CodeGenConfigurationNode wird durch eine Reihe nativer und benutzerdefinierter Transformationen mit den jeweiligen Eingabeparameter-Arrays generiert. Dies kann mithilfe von Python-JSON-Encodern erreicht werden, die die Klassenobjekte in JSON serialisieren und anschließend mithilfe der Boto3-Bibliothek und der AWS Glue-API den visuellen Editor-Job von AWS Glue Studio erstellen.
Die zum Konfigurieren der AWS Glue-Transformationen erforderlichen Eingaben stammen aus der Metadatendatenbank der EDLS-Jobs. Das Python-Dienstprogramm liest die Metadateninformationen, analysiert sie und konfiguriert die Knoten automatisch.
Die Reihenfolge und Reihenfolge der Knoten wird aus den Metadaten der EDLS-Jobs ermittelt, wobei ein Knoten als Eingabe für einen oder mehrere nachgelagerte Knoten dient, die den DAG-Fluss aufbauen.
Vorteile der Lösung
Der Migrationspfad wird BMS dabei helfen, seine Kernziele zu erreichen, nämlich das bestehende benutzerdefinierte ETL-Framework mithilfe visueller ETL-Komponenten in modulare, visuell konfigurierbare, weniger komplexe und leicht verwaltbare Pipelines zu zerlegen. Das Dienstprogramm unterstützt die Migration der alten ETL-Pipelines zu nativen AWS Glue Studio-Jobs auf automatisierte und skalierbare Weise.
Mit konsistenten, sofort einsatzbereiten visuellen ETL-Transformationen in der AWS Glue Studio-Schnittstelle ist BMS in der Lage, anspruchsvolle Datenpipelines zu erstellen, ohne Code schreiben zu müssen.
Die benutzerdefinierten visuellen Transformationen erweitern die Funktionen von AWS Glue Studio und erfüllen einige der BMS-ETL-Anforderungen, bei denen den nativen Transformationen diese Funktionalität fehlt. Benutzerdefinierte Transformationen helfen dabei, geschäftsspezifische ETL-Logik zu definieren, wiederzuverwenden und zwischen allen Teams zu teilen. Die Lösung erhöht die Konsistenz zwischen den Teams und hält die ETL-Pipelines auf dem neuesten Stand, indem doppelter Aufwand und Code minimiert werden.
Mit geringfügigen Änderungen kann das Migrationsdienstprogramm wiederverwendet werden, um die Migration von Pipelines bei zukünftigen Upgrades der AWS Glue-Version zu automatisieren.
Zusammenfassung
Das erfolgreiche Ergebnis dieses Proof of Concept hat gezeigt, dass die Migration von über 5,000 Jobs von der benutzerdefinierten BMS-Anwendung zu nativen AWS-Diensten zu erheblichen Produktivitätssteigerungen und Kosteneinsparungen führen kann. Durch den Wechsel zu AWS kann BMS den Aufwand für die Unterstützung von AWS Glue reduzieren, die DevOps-Bereitstellung verbessern und schätzungsweise 58 % der AWS Glue-Ausgaben einsparen.
Diese Ergebnisse sind sehr vielversprechend und BMS freut sich auf die nächste Phase der Migration. Wir glauben, dass sich dieses Projekt positiv auf das Geschäft von BMS auswirken und uns helfen wird, unsere strategischen Ziele zu erreichen.
Über die Autoren
 Sivaprasad Mahamkali ist Senior Streaming Data Engineer bei AWS Professional Services. Siva leitet Kundenengagements im Zusammenhang mit Echtzeit-Streaming-Lösungen, Data Lakes und Analysen mithilfe von OpenSource- und AWS-Diensten. Siva hört gerne Musik und verbringt gerne Zeit mit seiner Familie.
Sivaprasad Mahamkali ist Senior Streaming Data Engineer bei AWS Professional Services. Siva leitet Kundenengagements im Zusammenhang mit Echtzeit-Streaming-Lösungen, Data Lakes und Analysen mithilfe von OpenSource- und AWS-Diensten. Siva hört gerne Musik und verbringt gerne Zeit mit seiner Familie.
 Dan Gibbar ist Senior Engagement Manager bei AWS Professional Services. Dan leitet Engagements im Gesundheitswesen und in den Biowissenschaften und arbeitet mit Kunden und Partnern zusammen, um Ergebnisse zu erzielen. Dan genießt die Natur, nimmt an Triathlons teil, genießt Musik und verbringt Zeit mit der Familie.
Dan Gibbar ist Senior Engagement Manager bei AWS Professional Services. Dan leitet Engagements im Gesundheitswesen und in den Biowissenschaften und arbeitet mit Kunden und Partnern zusammen, um Ergebnisse zu erzielen. Dan genießt die Natur, nimmt an Triathlons teil, genießt Musik und verbringt Zeit mit der Familie.
 Shrinath Parikh als Senior Cloud Data Architect bei AWS. Er arbeitet mit Kunden auf der ganzen Welt zusammen, um sie bei ihren Anwendungsfällen in den Bereichen Datenanalyse, Data Lake, Data Lake House, Serverless, Governance und NoSQL zu unterstützen. In seiner Freizeit reist Shrinath gerne, verbringt Zeit mit der Familie und lernt bzw. baut neue Werkzeuge mithilfe modernster Technologien.
Shrinath Parikh als Senior Cloud Data Architect bei AWS. Er arbeitet mit Kunden auf der ganzen Welt zusammen, um sie bei ihren Anwendungsfällen in den Bereichen Datenanalyse, Data Lake, Data Lake House, Serverless, Governance und NoSQL zu unterstützen. In seiner Freizeit reist Shrinath gerne, verbringt Zeit mit der Familie und lernt bzw. baut neue Werkzeuge mithilfe modernster Technologien.
 Ramesh Daddala ist stellvertretender Direktor bei BMS. Ramesh leitet Enterprise Data Engineering-Aufträge im Zusammenhang mit Enterprise Data Lake Services (EDLs) und arbeitet mit Datenpartnern zusammen, um Enterprise Data Engineering und ML-Funktionen bereitzustellen und zu unterstützen. Ramesh liebt die Natur, reist gerne und verbringt gerne Zeit mit der Familie.
Ramesh Daddala ist stellvertretender Direktor bei BMS. Ramesh leitet Enterprise Data Engineering-Aufträge im Zusammenhang mit Enterprise Data Lake Services (EDLs) und arbeitet mit Datenpartnern zusammen, um Enterprise Data Engineering und ML-Funktionen bereitzustellen und zu unterstützen. Ramesh liebt die Natur, reist gerne und verbringt gerne Zeit mit der Familie.
 Jitendra Kumar Dash ist Senior Cloud Architect bei BMS mit Fachkenntnissen in Hybrid-Cloud-Diensten, Infrastruktur-Engineering, DevOps, Data Engineering und Datenanalyselösungen. Er hat eine Leidenschaft für Essen, Sport und Abenteuer.
Jitendra Kumar Dash ist Senior Cloud Architect bei BMS mit Fachkenntnissen in Hybrid-Cloud-Diensten, Infrastruktur-Engineering, DevOps, Data Engineering und Datenanalyselösungen. Er hat eine Leidenschaft für Essen, Sport und Abenteuer.
 Pavan Kumar Bijja ist Senior Data Engineer bei BMS. Pavan ermöglicht Daten-Engineering und Analysedienste für den kommerziellen BMS-Bereich mithilfe von Unternehmensfunktionen. Pavan leitet die Unternehmensmetadatenfunktionen bei BMS. Pavan verbringt gerne Zeit mit seiner Familie und spielt Badminton und Cricket.
Pavan Kumar Bijja ist Senior Data Engineer bei BMS. Pavan ermöglicht Daten-Engineering und Analysedienste für den kommerziellen BMS-Bereich mithilfe von Unternehmensfunktionen. Pavan leitet die Unternehmensmetadatenfunktionen bei BMS. Pavan verbringt gerne Zeit mit seiner Familie und spielt Badminton und Cricket.
 Shovan Kanjilal ist Senior Data Lake Architect und arbeitet mit strategischen Konten in AWS Professional Services. Shovan arbeitet mit Kunden zusammen, um Daten- und maschinelle Lernlösungen auf AWS zu entwickeln.
Shovan Kanjilal ist Senior Data Lake Architect und arbeitet mit strategischen Konten in AWS Professional Services. Shovan arbeitet mit Kunden zusammen, um Daten- und maschinelle Lernlösungen auf AWS zu entwickeln.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/modernize-your-etl-platform-with-aws-glue-studio-a-case-study-from-bms/

