Wir haben vor kurzem angekündigt Unterstützung für AWS Lake-Formation fein abgestufte Zugriffskontrollrichtlinien in Amazonas Athena Abfragen von Daten, die in einem beliebigen unterstützten Dateiformat gespeichert sind, unter Verwendung von Tabellenformaten wie Apache Iceberg, Apache Hudi und Apache Hive. Mit AWS Lake Formation können Sie Zugriffsrichtlinien auf Datenbank-, Tabellen- und Spaltenebene definieren und durchsetzen, um in Amazon S3 gespeicherte Iceberg-Tabellen abzufragen. Lake Formation bietet eine Autorisierungs- und Governance-Ebene für in Amazon S3 gespeicherte Daten. Diese Funktion erfordert ein Upgrade auf Athena-Engine-Version 3.
Große Organisationen haben oft Geschäftsbereiche (LoBs), die bei der Verwaltung ihrer Geschäftsdaten autonom agieren. Es macht das Teilen von Daten über LoBs hinweg nicht trivial. Diese Organisationen haben ein föderiertes Modell eingeführt, bei dem jede LoB die Autonomie hat, Entscheidungen über ihre Daten zu treffen. Sie verwenden das Publisher/Consumer-Modell mit einer zentralisierten Governance-Schicht, die zur Durchsetzung von Zugriffskontrollen verwendet wird. Wenn Sie mehr über die Data-Mesh-Architektur erfahren möchten, besuchen Sie Entwerfen Sie eine Data-Mesh-Architektur mit AWS Lake Formation und AWS Glue. Mit der Version 3 der Athena-Engine können Kunden die gleichen feinkörnigen Steuerelemente für Open-Data-Frameworks wie Apache Iceberg, Apache Hudi und Apache Hive verwenden.
In diesem Beitrag tauchen wir tief in einen Anwendungsfall ein, in dem Sie ein Producer/Consumer-Modell mit aktivierter Datenfreigabe haben, um eingeschränkten Zugriff auf eine Apache Iceberg-Tabelle zu gewähren, die der Consumer abfragen kann. Wir besprechen die Spaltenfilterung zum Einschränken bestimmter Zeilen, die Filterung zum Einschränken des Zugriffs auf Spaltenebene, Schemaentwicklung und Zeitreisen.
Lösungsüberblick
Um die Funktionalität feingranularer Berechtigungen für Apache Iceberg-Tabellen mit Athena und Lake Formation zu veranschaulichen, richten wir die folgenden Komponenten ein:
- Im Produzentenkonto:
- An AWS-Kleber Data Catalog zum Registrieren des Schemas einer Tabelle im Apache Iceberg-Format
- Lake Formation, um einen differenzierten Zugriff auf das Verbraucherkonto bereitzustellen
- Athena, um Daten aus dem Produzentenkonto zu überprüfen
- Im Verbraucherkonto:
- AWS-Ressourcenzugriffsmanager (AWS RAM), um einen Handshake zwischen dem Producer Data Catalog und dem Consumer zu erstellen
- Lake Formation, um einen differenzierten Zugriff auf das Verbraucherkonto bereitzustellen
- Athena, um Daten vom Produzentenkonto zu überprüfen
Das folgende Diagramm zeigt die Architektur.

Voraussetzungen:
Bevor Sie beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
Einrichtung des Datenproduzenten
In diesem Abschnitt stellen wir die Schritte zum Einrichten des Datenproduzenten vor.
Erstellen Sie einen S3-Bucket zum Speichern der Tabellendaten
Wir erstellen einen neuen S3-Bucket, um die Daten für die Tabelle zu speichern:
- Auf der Amazon S3-Konsole, Erstellen Sie einen S3-Bucket mit eindeutigem Namen (für diesen Beitrag verwenden wir
iceberg-athena-lakeformation-blog). - Erstellen Sie den Producer-Ordner innerhalb des Buckets, der für die Tabelle verwendet werden soll.

Registrieren Sie den S3-Pfad, in dem die Tabelle gespeichert ist, mit Lake Formation
Wir registrieren den vollständigen S3-Pfad in Lake Formation:
- Navigieren Sie zur Lake Formation-Konsole.
- Wenn Sie sich zum ersten Mal anmelden, werden Sie aufgefordert, einen Admin-Benutzer zu erstellen.

- Im Navigationsbereich unter Registrieren und einnehmen, wählen Datenseestandorte.
- Auswählen Ort registrieren, und geben Sie den zuvor erstellten S3-Bucket-Pfad an.
- Auswählen
AWSServiceRoleForLakeFormationDataAccessfür IAM-Rolle.
Weitere Informationen zu Rollen finden Sie unter Anforderungen für Rollen, die zum Registrieren von Standorten verwendet werden.
Wenn Sie die Verschlüsselung Ihres S3-Buckets aktiviert haben, müssen Sie Lake Formation Berechtigungen erteilen, um Verschlüsselungs- und Entschlüsselungsvorgänge durchzuführen. Beziehen auf Registrieren eines verschlüsselten Amazon S3-Standorts zur Führung.
- Auswählen Ort registrieren.

Erstellen Sie mit Athena eine Iceberg-Tabelle
Lassen Sie uns nun die Tabelle mit Athena erstellen, das vom Apache Iceberg-Format unterstützt wird:
- Wählen Sie auf der Athena-Konsole Abfrage-Editor im Navigationsbereich.
- Wenn Sie Athena zum ersten Mal verwenden, unter Einstellungen , wählen Verwalten und geben Sie den S3-Bucket-Standort ein, den Sie zuvor erstellt haben (
iceberg-athena-lakeformation-blog/producer). - Auswählen Speichern.
- Geben Sie im Abfrageeditor die folgende Abfrage ein (ersetzen Sie den Standort durch den S3-Bucket, den Sie bei Lake Formation registriert haben). Beachten Sie, dass wir die Standarddatenbank verwenden, aber Sie können jede andere Datenbank verwenden.
- Auswählen Führen Sie.

Teilen Sie die Tabelle mit dem Verbraucherkonto
Um die Funktionalität zu veranschaulichen, implementieren wir die folgenden Szenarien:
- Gewähren Sie Zugriff auf ausgewählte Spalten
- Gewähren Sie basierend auf einem Filter Zugriff auf ausgewählte Zeilen
Führen Sie die folgenden Schritte aus:
- Auf der Lake Formation-Konsole im Navigationsbereich unter Datenkatalog, wählen Datenfilter.
- Auswählen Neuen Filter erstellen.
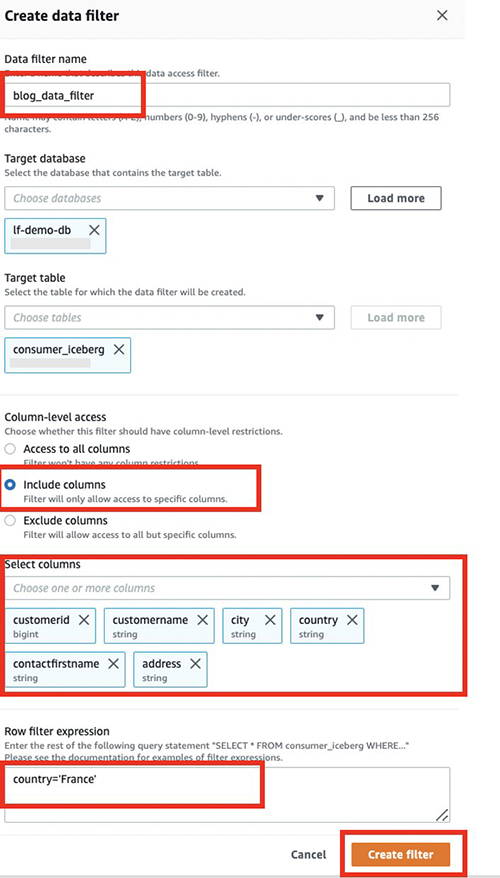
- Aussichten für Name des Datenfilters, eingeben
blog_data_filter. - Aussichten für Zieldatenbank, eingeben
lf-demo-db. - Aussichten für Zieltabelle, eingeben
consumer_iceberg. - Aussichten für Zugriff auf SpaltenebeneWählen Spalten einschließen.
- Wählen Sie die Spalten aus, die Sie mit dem Verbraucher teilen möchten:
country, address, contactfirstname, city, customerid,undcustomername. - Aussichten für Zeilenfilterausdruck, geben Sie den Filter ein
country='France'. - Auswählen Filter erstellen.
Lassen Sie uns nun Zugriff auf das Verbraucherkonto auf der gewähren consumer_iceberg Tabelle.
- Wählen Sie im Navigationsbereich Tische.
- Wählen Sie die Tabelle „consumer_iceberg“ aus und wählen Sie Gewähren auf die Aktionen Menü.

- Auswählen Externe Konten.
- Geben Sie die externe Konto-ID ein.

- Auswählen Benannte Datenkatalogressourcen.
- Wählen Sie Ihre Datenbank und Tabelle.
- Aussichten für Datenfilter, wählen Sie den von Ihnen erstellten Datenfilter aus.

- Aussichten für Berechtigungen für Datenfilter und Erteilbare BerechtigungenWählen Auswählen.
- Auswählen Gewähren.

Einrichtung des Datenkonsumenten
Um den Datenkonsumenten einzurichten, akzeptieren wir die Ressourcenfreigabe und erstellen eine Tabelle mit AWS RAM und Lake Formation. Führen Sie die folgenden Schritte aus:
- Melden Sie sich beim Verbraucherkonto an und navigieren Sie zur AWS RAM-Konsole.
- Der Mit mir geteilt Wählen Sie im Navigationsbereich Ressourcenfreigaben.
- Wählen Sie Ihren Ressourcenanteil.

- Auswählen Ressourcenfreigabe akzeptieren.
- Notieren Sie sich den Namen der Ressourcenfreigabe, der in den nächsten Schritten verwendet werden soll.

- Navigieren Sie zur Lake Formation-Konsole.
- Wenn Sie sich zum ersten Mal anmelden, werden Sie aufgefordert, einen Admin-Benutzer zu erstellen.
- Auswählen Datenbanken im Navigationsbereich und wählen Sie dann Ihre Datenbank aus.
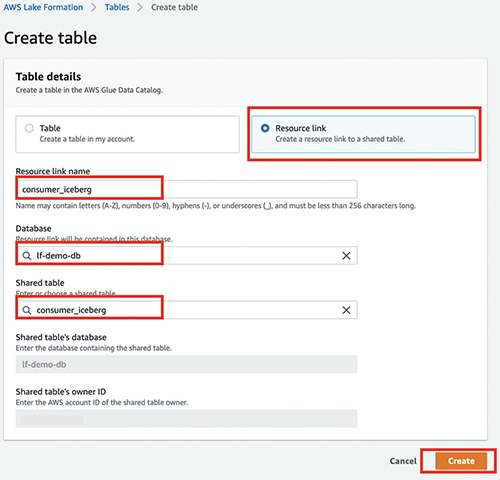
- Auf dem Aktionen Menü, wählen Sie Ressourcenlink erstellen.

- Aussichten für Name des Ressourcenlinks, geben Sie den Namen Ihres Ressourcenlinks ein (z. B.
consumer_iceberg). - Wählen Sie Ihre Datenbank und gemeinsam genutzte Tabelle aus.
- Auswählen
Erstellen.
Validieren Sie die Lösung
Jetzt können wir verschiedene Operationen auf den Tabellen ausführen, um die differenzierten Zugriffskontrollen zu validieren.
Einfügevorgang
Lassen Sie uns Daten in die einfügen consumer_iceberg Tabelle im Producer-Konto und überprüfen Sie, ob die Datenfilterung wie erwartet im Consumer-Konto funktioniert.
- Melden Sie sich beim Produzentenkonto an.
- Wählen Sie auf der Athena-Konsole Abfrage-Editor im Navigationsbereich.
- Verwenden Sie die folgende SQL, um Daten in die Iceberg-Tabelle zu schreiben und einzufügen. Verwenden Sie den Abfrageeditor, um jeweils eine Abfrage auszuführen. Sie können jeweils eine Abfrage markieren/auswählen und auf „Ausführen“/„Erneut ausführen“ klicken:

- Verwenden Sie die folgende SQL, um Daten in der Iceberg-Tabelle zu lesen und auszuwählen:
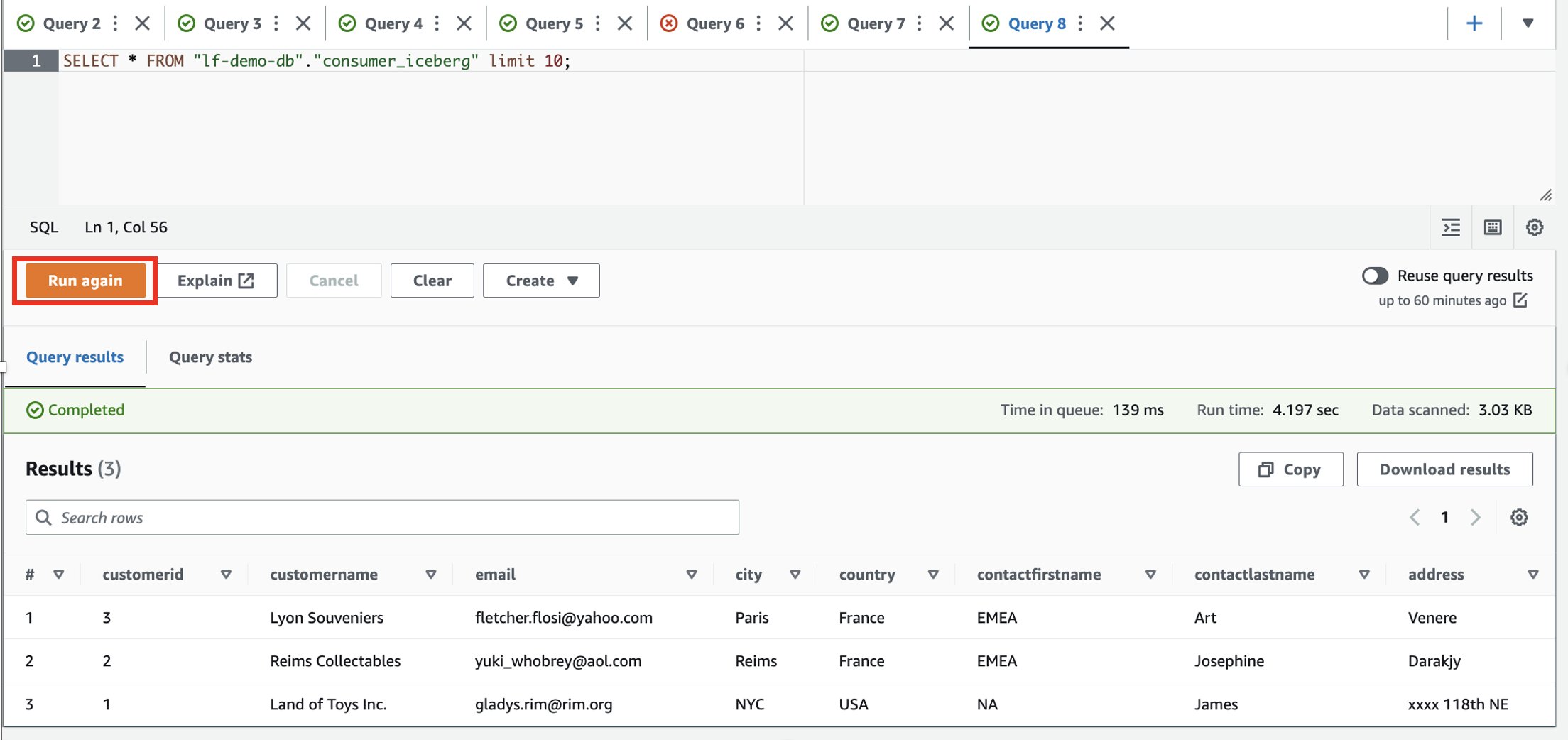
- Melden Sie sich beim Verbraucherkonto an.
- Führen Sie im Athena-Abfrage-Editor die folgende SELECT-Abfrage für die freigegebene Tabelle aus:

Basierend auf den Filtern hat der Verbraucher Einblick in eine Teilmenge von Spalten und Zeilen, in denen das Land Frankreich ist.
Vorgänge aktualisieren/löschen
Lassen Sie uns nun eine der Zeilen aktualisieren und eine aus dem für den Verbraucher freigegebenen Dataset löschen.
- Melden Sie sich beim Produzentenkonto an.
- Aktualisierung
city='Paris' WHERE city='Reims'und lösche die Zeilecustomerid = 3;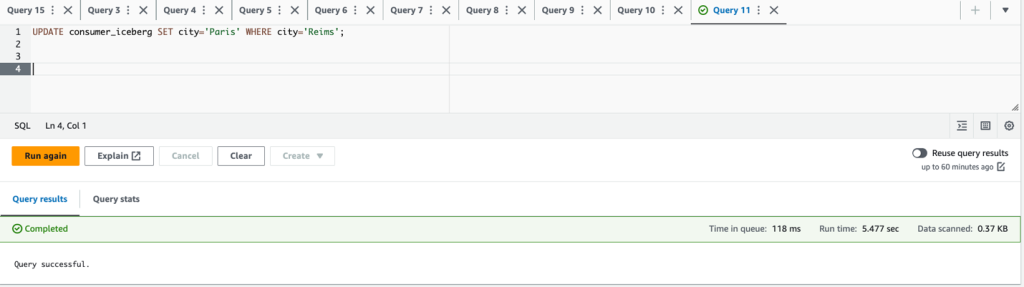

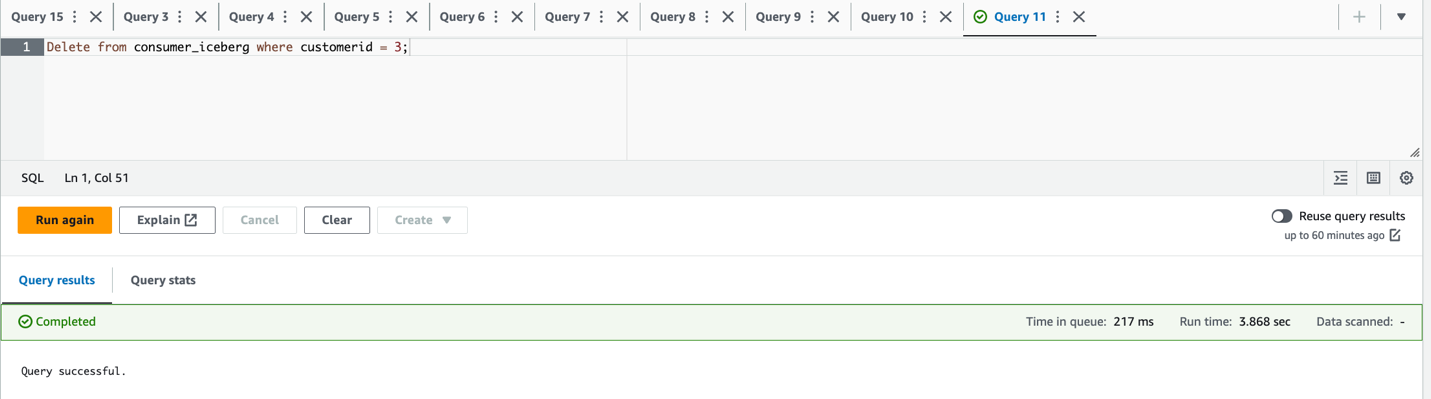
- Überprüfen Sie das aktualisierte und gelöschte Dataset:

- Melden Sie sich beim Verbraucherkonto an.
- Führen Sie im Athena-Abfrage-Editor die folgende SELECT-Abfrage für die freigegebene Tabelle aus:

Wir können beobachten, dass nur eine Zeile verfügbar ist und die Stadt auf Paris aktualisiert wird.
Schemaentwicklung: Fügen Sie eine neue Spalte hinzu
Lassen Sie uns eine der Zeilen aktualisieren und eine aus dem für den Verbraucher freigegebenen Dataset löschen.
- Melden Sie sich beim Produzentenkonto an.
- Fügen Sie eine neue Spalte mit dem Namen hinzu
geo_locin der Iceberg-Tabelle. Verwenden Sie den Abfrageeditor, um jeweils eine Abfrage auszuführen. Sie können jeweils eine Abfrage markieren/auswählen und auf „Ausführen“/„Erneut ausführen“ klicken:

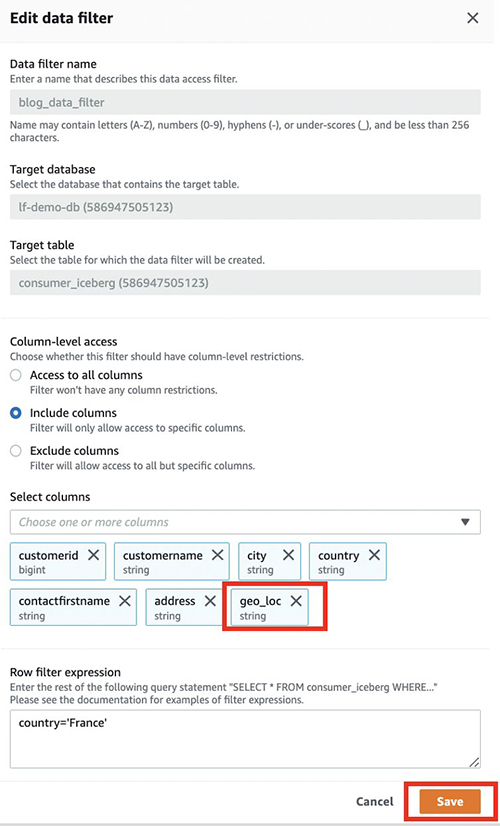
Um die neu hinzugefügten sichtbar zu machen geo_loc Spalte müssen wir den Datenfilter Lake Formation aktualisieren.
- Wählen Sie in der Lake Formation-Konsole aus Datenfilter im Navigationsbereich.
- Wählen Sie Ihren Datenfilter und wählen Sie Bearbeiten.

- Der Zugriff auf Spaltenebene, fügen Sie die neue Spalte hinzu (
geo_loc). - Auswählen
Speichern.
- Melden Sie sich beim Verbraucherkonto an.
- Führen Sie im Athena-Abfrage-Editor Folgendes aus
SELECTAbfrage auf der gemeinsam genutzten Tabelle:

Die neue Kolumne geo_loc sichtbar ist und eine zusätzliche Zeile.
Schemaentwicklung: Spalte löschen
Lassen Sie uns eine der Zeilen aktualisieren und eine aus dem für den Verbraucher freigegebenen Dataset löschen.
- Melden Sie sich beim Produzentenkonto an.
- Ändern Sie die Tabelle, um die Adressspalte aus der Iceberg-Tabelle zu löschen. Verwenden Sie den Abfrageeditor, um jeweils eine Abfrage auszuführen. Sie können jeweils eine Abfrage markieren/auswählen und auf „Ausführen“/„Erneut ausführen“ klicken:

Wir können beobachten, dass die Spaltenadresse nicht in der Tabelle vorhanden ist.
- Melden Sie sich beim Verbraucherkonto an.
- Führen Sie im Athena-Abfrage-Editor die folgende SELECT-Abfrage für die freigegebene Tabelle aus:

Die Spaltenadresse ist in der Tabelle nicht vorhanden.
Zeitreise
Wir haben die Iceberg-Tabelle nun mehrfach geändert. Die Iceberg-Tabelle verfolgt die Snapshots. Führen Sie die folgenden Schritte aus, um die Zeitreisefunktion zu erkunden:
- Melden Sie sich beim Produzentenkonto an.
- Abfrage der Systemtabelle:
Wir können beobachten, dass wir mehrere Snapshots generiert haben.
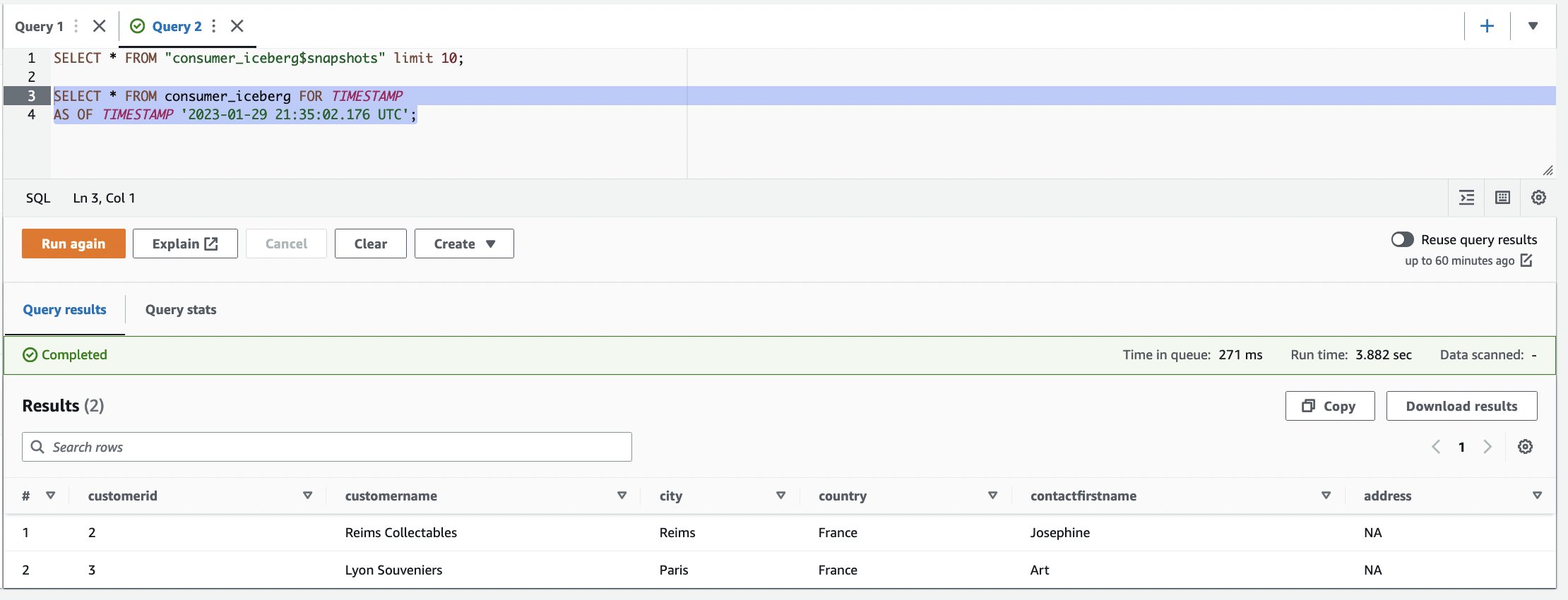
- Notieren Sie eine der
committed_atWerte, die in den nächsten Schritten verwendet werden sollen (für dieses Beispiel2023-01-29 21:35:02.176 UTC).
- Verwenden Sie die Zeitreise, um den Tabellenschnappschuss zu finden. Verwenden Sie den Abfrageeditor, um jeweils eine Abfrage auszuführen. Sie können jeweils eine Abfrage markieren/auswählen und auf „Ausführen“/„Erneut ausführen“ klicken:
Aufräumen
Führen Sie die folgenden Schritte aus, um zukünftige Gebühren zu vermeiden:
- Löschen Sie auf der Amazon S3-Konsole den Tabellenspeicher-Bucket (für diesen Beitrag iceberg-athena-lakeformation-blog).
- Führen Sie im Producer-Konto auf der Athena-Konsole die folgenden Befehle aus, um die von Ihnen erstellten Tabellen zu löschen:
- Widerrufen Sie im Producer-Konto in der Lake Formation-Konsole die Berechtigungen für das Consumer-Konto.

- Löschen Sie den S3-Bucket, der für den Speicherort des Athena-Abfrageergebnisses verwendet wird, aus dem Verbraucherkonto.
Zusammenfassung
Mit der Unterstützung für kontoübergreifende, feinkörnige Zugriffskontrollrichtlinien für Formate wie Iceberg haben Sie die Flexibilität, mit jedem von Athena unterstützten Format zu arbeiten. Die Möglichkeit, CRUD-Operationen für die Daten in Ihrem S3 Data Lake durchzuführen, kombiniert mit den feinkörnigen Zugriffskontrollen von Lake Formation für alle von Athena unterstützten Tabellen und Formate, bietet Möglichkeiten zur Innovation und Vereinfachung Ihrer Datenstrategie. Wir freuen uns über Ihr Feedback!
Über die Autoren
 Kishore Dhamodaran ist Senior Solutions Architect bei AWS. Kishore unterstützt strategische Kunden bei ihrer Cloud-Unternehmensstrategie und Migrationsreise und nutzt dabei seine jahrelange Branchen- und Cloud-Erfahrung.
Kishore Dhamodaran ist Senior Solutions Architect bei AWS. Kishore unterstützt strategische Kunden bei ihrer Cloud-Unternehmensstrategie und Migrationsreise und nutzt dabei seine jahrelange Branchen- und Cloud-Erfahrung.
 Jack Ye ist Softwareentwickler des Athena Data Lake and Storage-Teams bei AWS. Er ist Apache Iceberg Committer und PMC-Mitglied.
Jack Ye ist Softwareentwickler des Athena Data Lake and Storage-Teams bei AWS. Er ist Apache Iceberg Committer und PMC-Mitglied.
 Chris Olson ist Softwareentwicklungsingenieur bei AWS.
Chris Olson ist Softwareentwicklungsingenieur bei AWS.
 Xiaoxuan Li ist Softwareentwicklungsingenieur bei AWS.
Xiaoxuan Li ist Softwareentwicklungsingenieur bei AWS.
 Rahul Sonawane ist Principal Analytics Solutions Architect bei AWS mit KI/ML und Analytics als Spezialgebiet.
Rahul Sonawane ist Principal Analytics Solutions Architect bei AWS mit KI/ML und Analytics als Spezialgebiet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/interact-with-apache-iceberg-tables-using-amazon-athena-and-cross-account-fine-grained-permissions-using-aws-lake-formation/

