Viele Organisationen auf der ganzen Welt sind auf den Einsatz physischer Vermögenswerte, wie beispielsweise Fahrzeuge, angewiesen, um ihren Endkunden einen Service zu bieten. Durch die Verfolgung dieser Assets in Echtzeit und die Speicherung der Ergebnisse können Asset-Eigentümer wertvolle Erkenntnisse darüber gewinnen, wie ihre Assets genutzt werden, um kontinuierlich Geschäftsverbesserungen zu erzielen und zukünftige Änderungen zu planen. Beispielsweise muss ein Lieferunternehmen, das eine Fahrzeugflotte betreibt, möglicherweise die Auswirkungen lokaler Richtlinienänderungen ermitteln, die außerhalb seiner Kontrolle liegen, beispielsweise die angekündigte Erweiterung eines Ultra-Low-Emission-Zone (ULEZ). Durch die Kombination historischer Fahrzeugstandortdaten mit Informationen aus anderen Quellen kann das Unternehmen empirische Ansätze für eine bessere Entscheidungsfindung entwickeln. Beispielsweise kann das Beschaffungsteam des Unternehmens diese Informationen nutzen, um Entscheidungen darüber zu treffen, welche Fahrzeuge vorrangig ersetzt werden sollen, bevor Richtlinienänderungen in Kraft treten.
Entwickler können die Unterstützung in nutzen Amazon-Standortservice für Veröffentlichung von Gerätepositionsaktualisierungen zu Amazon EventBridge um eine Datenpipeline nahezu in Echtzeit aufzubauen, in der die Standorte der verfolgten Vermögenswerte gespeichert werden Amazon Simple Storage-Service (Amazon S3). Darüber hinaus können Sie verwenden AWS Lambda um eingehende Standortdaten mit Daten aus anderen Quellen anzureichern, z Amazon DynamoDB Tabelle mit Einzelheiten zur Fahrzeugwartung. Dann kann ein Datenanalyst das verwenden Geodaten-Abfragefunktionen of Amazonas Athena um Erkenntnisse zu gewinnen, beispielsweise über die Anzahl der Tage, die ihre Fahrzeuge in den vorgeschlagenen Grenzen einer erweiterten ULEZ gefahren sind. Da für Fahrzeuge, die die ULEZ-Abgasnormen nicht erfüllen, für den Betrieb innerhalb der Zone eine tägliche Gebühr anfällt, können Sie die Standortdaten zusammen mit Wartungsdaten wie Alter des Fahrzeugs, aktuellem Kilometerstand und aktuellen Abgasnormen verwenden, um die Menge abzuschätzen Das Unternehmen müsste für Tagesgebühren aufkommen.
Dieser Beitrag zeigt, wie Sie Amazon Location, EventBridge, Lambda, Amazon Data Firehoseund Amazon S3, um eine standortbezogene Datenpipeline aufzubauen und diese Daten zu nutzen, um aussagekräftige Erkenntnisse zu gewinnen AWS-Kleber und Athena.
Lösungsübersicht
Dabei handelt es sich um eine vollständig serverlose Lösung für die standortbasierte Vermögensverwaltung. Die Lösung besteht aus folgenden Schnittstellen:
- IoT oder mobile Anwendung – Eine mobile Anwendung oder ein Internet-of-Things-Gerät (IoT) ermöglicht die Verfolgung eines Firmenfahrzeugs während der Nutzung und übermittelt seinen aktuellen Standort sicher an die Datenaufnahmeebene in AWS. Der Aufnahmeansatz ist nicht Gegenstand dieses Beitrags. Stattdessen simuliert eine Lambda-Funktion in unserer Lösung beispielhafte Fahrzeugfahrten und aktualisiert Amazon Location Tracker-Objekte direkt mit zufälligen Standorten.
- Datenanalyse – Geschäftsanalysten sammeln betriebliche Erkenntnisse aus mehreren Datenquellen, einschließlich der von den Fahrzeugen erfassten Standortdaten. Datenanalysten suchen nach Antworten auf Fragen wie: „Wie lange hat sich ein bestimmtes Fahrzeug in der Vergangenheit in einer vorgeschlagenen Zone aufgehalten und wie hoch wären die Gebühren gewesen, wenn die Richtlinie in den letzten 12 Monaten in Kraft gewesen wäre?“
Das folgende Diagramm zeigt die Lösungsarchitektur.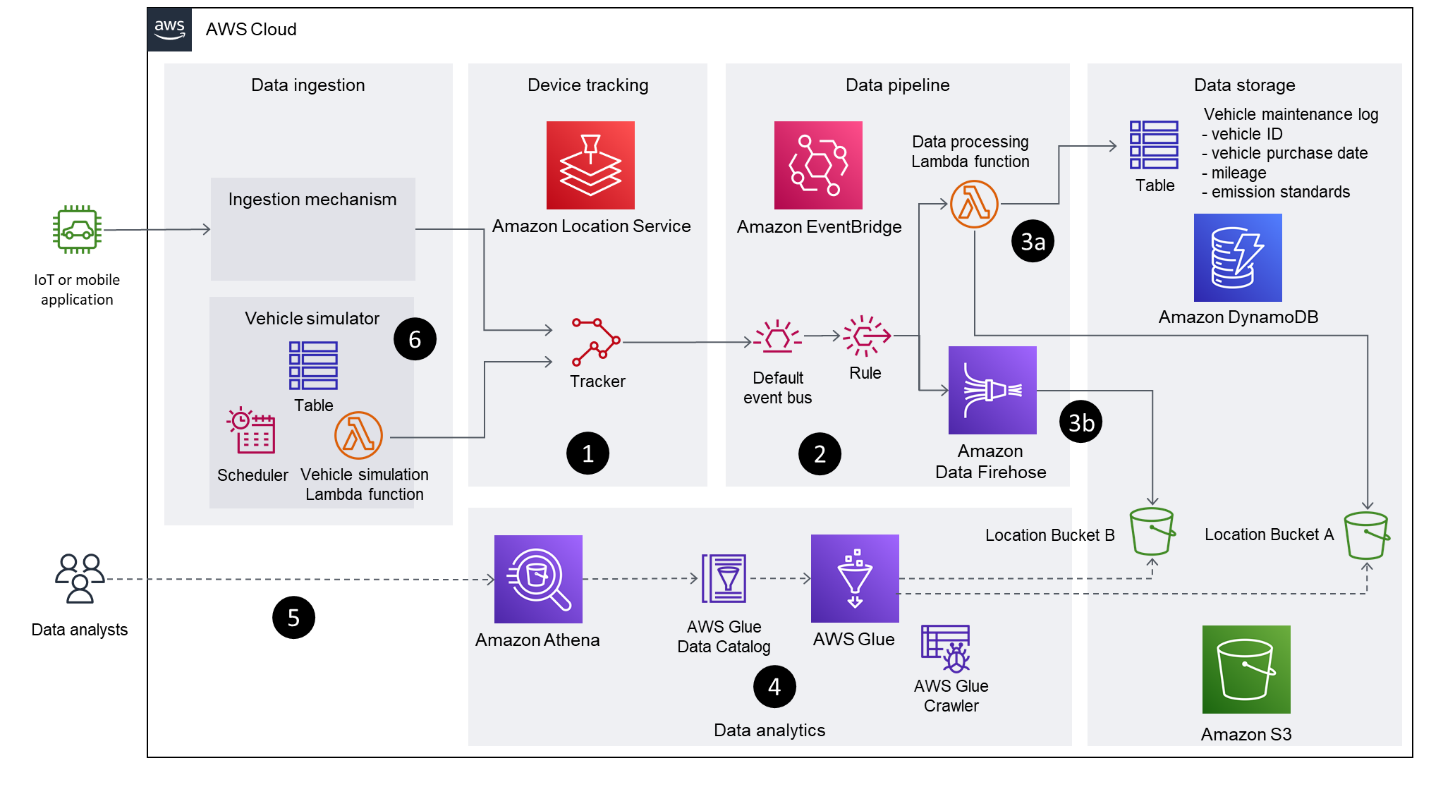
Der Workflow besteht aus den folgenden Hauptschritten:
- Zur Verfolgung des Fahrzeugs wird die Tracking-Funktionalität von Amazon Location genutzt. Mithilfe der EventBridge-Integration werden gefilterte Positionsaktualisierungen in einem EventBridge-Ereignisbus veröffentlicht. Diese Lösung verwendet distanzbasiert Filterung zur Reduzierung von Kosten und Jitter. Bei der entfernungsbasierten Filterung werden Standortaktualisierungen ignoriert, bei denen sich Geräte weniger als 30 Meter (98.4 Fuß) bewegt haben.
- Gerätepositionsereignisse von Amazon Location kommen auf der EventBridge an
defaultBus mitsource: ["aws.geo"]unddetail-type: ["Location Device Position Event"]. Es wird eine Regel erstellt, um diese Ereignisse an zwei nachgelagerte Ziele weiterzuleiten: eine Lambda-Funktion und einen Firehose-Bereitstellungsstream. - In diesem Beitrag werden zwei unterschiedliche Muster, basierend auf jedem Ziel, beschrieben, um unterschiedliche Ansätze zum Übertragen der Daten in einen S3-Bucket zu veranschaulichen:
- Lambda-Funktion – Der erste Ansatz verwendet eine Lambda-Funktion, um zu demonstrieren, wie Sie Code in der Datenpipeline verwenden können, um die eingehenden Standortdaten direkt umzuwandeln. Sie können die Lambda-Funktion ändern, um zusätzliche Fahrzeuginformationen aus einem separaten Datenspeicher (z. B. einer DynamoDB-Tabelle oder einem Customer-Relationship-Management-System) abzurufen, um die Daten anzureichern, bevor die Ergebnisse in einem S3-Bucket gespeichert werden. In diesem Modell wird die Lambda-Funktion für jedes eingehende Ereignis aufgerufen.
- Feuerwehrschlauch-Lieferstrom – Der zweite Ansatz verwendet einen Firehose-Lieferstrom, um die eingehenden Positionsaktualisierungen zu puffern und zu stapeln, bevor sie ohne Änderungen in einem S3-Bucket gespeichert werden. Diese Methode nutzt die GZIP-Komprimierung, um den Speicherverbrauch und die Abfrageleistung zu optimieren. Sie können auch die verwenden Datenumwandlung Funktion von Data Firehose zum Aufrufen einer Lambda-Funktion, um Datentransformationen in Stapeln durchzuführen.
- AWS Glue crawlt beide S3-Bucket-Pfade, füllt die AWS Glue-Datenbanktabellen basierend auf den abgeleiteten Schemata und stellt die Daten anderen Analyseanwendungen über den AWS Glue-Datenkatalog zur Verfügung.
- Athena wird verwendet, um Geodatenabfragen für die in den S3-Buckets gespeicherten Standortdaten auszuführen. Der Datenkatalog stellt Metadaten bereit, die es Analyseanwendungen, die Athena verwenden, ermöglichen, die in Amazon S3 gespeicherten Standortdaten zu finden, zu lesen und zu verarbeiten.
- Diese Lösung beinhaltet eine Lambda-Funktion, die den Amazon Location Tracker kontinuierlich mit simulierten Standortdaten von fiktiven Fahrten aktualisiert. Die Lambda-Funktion wird in regelmäßigen Abständen mithilfe einer geplanten EventBridge-Regel ausgelöst.
Sie können diese Lösung selbst testen AWS Samples GitHub-Repository. Das Repository enthält die AWS Serverless-Anwendungsmodell (AWS SAM)-Vorlage und Lambda-Code erforderlich, um diese Lösung auszuprobieren. Beachten Sie die Anweisungen in der README In der Datei finden Sie Schritte zur Bereitstellung und Außerbetriebnahme dieser Lösung.
Die visuellen Layouts in einigen Screenshots in diesem Beitrag unterscheiden sich möglicherweise von denen auf Ihrem AWS-Managementkonsole.
Datengenerierung
In diesem Abschnitt besprechen wir die Schritte zum manuellen oder automatischen Generieren von Reisedaten.
Reisedaten manuell generieren
Sie können Gerätepositionen mithilfe von manuell aktualisieren AWS-Befehlszeilenschnittstelle (AWS CLI)-Befehl aws location batch-update-device-position. Ersetze das tracker-name, device-id, Position und SampleTime Vergleichen Sie die Werte mit Ihren eigenen Werten und stellen Sie sicher, dass aufeinanderfolgende Aktualisierungen mehr als 30 Meter voneinander entfernt sind, um ein Ereignis darauf zu platzieren default EventBridge-Eventbus:
Generieren Sie automatisch Reisedaten mit dem Simulator
Die bereitgestellten AWS CloudFormation Die Vorlage stellt eine geplante EventBridge-Regel und eine zugehörige Lambda-Funktion bereit, die Tracker-Updates von Fahrzeugen simuliert. Diese Regel ist standardmäßig aktiviert und wird mit einer von der angegebenen Häufigkeit ausgeführt SimulationIntervalMinutes CloudFormation-Parameter. Die Lambda-Funktion zur Datengenerierung aktualisiert den Amazon Location Tracker mit einem zufälligen Positionsoffset von den Basisstandorten der Fahrzeuge.
Fahrzeugnamen und Basisstandorte werden im gespeichert Fahrzeuge.json Datei. Die Startposition eines Fahrzeugs wird jeden Tag zurückgesetzt, und die Basisstandorte wurden so ausgewählt, dass sie an einem bestimmten Tag in die ULEZ ein- und ausfahren können, um eine realistische Fahrtsimulation zu ermöglichen.
Du kannst dich Deaktivieren Sie die Regel vorübergehend, indem Sie zu den geplanten Regeldetails in der EventBridge-Konsole navigieren. Alternativ können Sie den Parameter ändern State: ENABLED zu State: DISABLED für die geplante Regelressource GenerateDevicePositionsScheduleRule der template.yml Datei. Erstellen Sie die AWS SAM-Vorlage neu und stellen Sie sie erneut bereit, damit diese Änderung wirksam wird.
Standortdaten-Pipeline-Ansätze
Die in diesem Abschnitt beschriebenen Konfigurationen werden automatisch von der bereitgestellten AWS SAM-Vorlage bereitgestellt. Die Informationen in diesem Abschnitt dienen zur Beschreibung der relevanten Teile der Lösung.
Amazon Location-Gerätepositionsereignisse
Amazon Location sendet Gerätepositionsaktualisierungsereignisse im folgenden Format an EventBridge:
Sie können optional eine angeben Eingabetransformation um das Format und den Inhalt der Gerätepositionsereignisdaten zu ändern, bevor sie das Ziel erreichen.
Datenanreicherung mit Lambda
Die Datenanreicherung in diesem Muster wird durch den Aufruf einer Lambda-Funktion erleichtert. In diesem Beispiel rufen wir diese Funktion auf ProcessDevicePosition, und verwenden Sie eine Python-Laufzeitumgebung. In der EventBridge-Zieldefinition wird eine benutzerdefinierte Transformation angewendet, um die Ereignisdaten im folgenden Format zu empfangen:
Sie könnten zusätzliche Transformationen anwenden, z. B. das Refactoring von Latitude und Longitude Daten in separate Schlüssel-Wert-Paare, wenn dies für die nachgelagerte Geschäftslogik erforderlich ist, die die Ereignisse verarbeitet.
Der folgende Code demonstriert die Python-Anwendungslogik, die von ausgeführt wird ProcessDevicePosition Lambda-Funktion. Der Kürze halber wurde in diesem Codeausschnitt die Fehlerbehandlung übersprungen. Der vollständige Code ist im verfügbar GitHub Repo.
Der vorangehende Code erstellt ein S3-Objekt für jedes von EventBridge empfangene Gerätepositionsereignis. Der Code verwendet die DeviceId als Präfix, um die Objekte in den Bucket zu schreiben.
Sie können dem vorhergehenden Lambda-Funktionscode zusätzliche Logik hinzufügen, um die Ereignisdaten mithilfe anderer Quellen anzureichern. Das Beispiel im GitHub Repo demonstriert die Anreicherung des Ereignisses mit Daten aus einer DynamoDB-Fahrzeugwartungstabelle.
Zusätzlich zur Voraussetzung AWS Identity and Access Management and (IAM)-Berechtigungen, die von der Rolle bereitgestellt werden AWSBasicLambdaExecutionRole, der ProcessDevicePosition Für die Funktion sind Berechtigungen zum Ausführen von S3 erforderlich put_object Aktion und alle anderen Aktionen, die von der Datenanreicherungslogik erforderlich sind. Die für die Lösung erforderlichen IAM-Berechtigungen sind in dokumentiert template.yml Datei.
Datenpipeline mit Amazon Data Firehose
Führen Sie die folgenden Schritte aus, um Ihren Firehose-Lieferstream zu erstellen:
- Wählen Sie in der Amazon Data Firehose-Konsole aus Firehose-Streams im Navigationsbereich.
- Auswählen Erstellen Sie einen Firehose-Stream.
- Aussichten für Quelle, wählen Sie als Direkt PUT.
- Aussichten für Reiseziel, wählen Amazon S3.
- Aussichten für Name des Firehose-Streams, geben Sie einen Namen ein (für diesen Beitrag,
ProcessDevicePositionFirehose).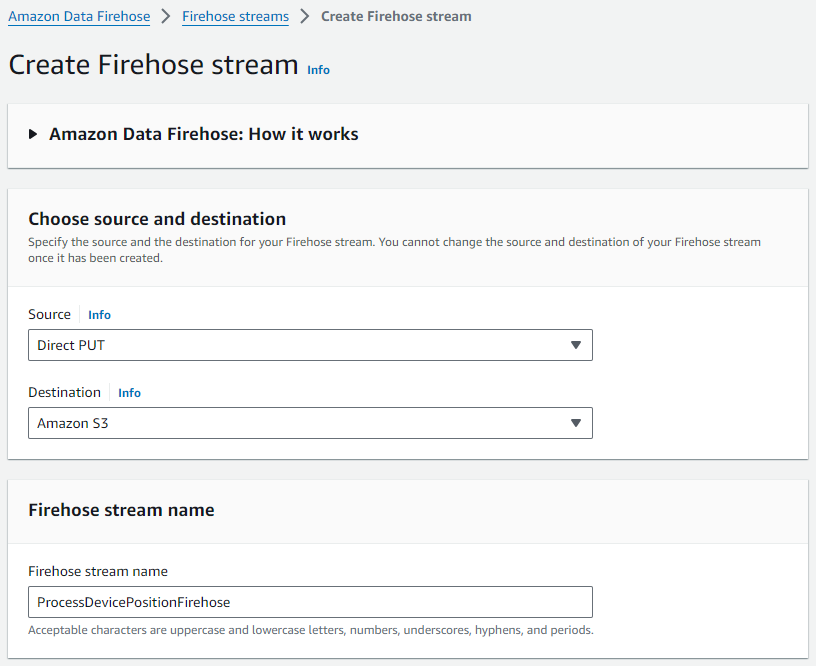
- Konfigurieren Sie die Zieleinstellungen mit Details zum S3-Bucket, in dem die Standortdaten gespeichert sind, zusammen mit der Partitionierungsstrategie:
- Verwenden Sie die und um die Bucket- und Objektpräfixe zu bestimmen.
- Verwenden Sie die
DeviceIdals zusätzliches Präfix, um die Objekte in den Bucket zu schreiben.
- Ermöglichen Dynamische Partitionierung und Neues Zeilentrennzeichen um sicherzustellen, dass die Partitionierung automatisch erfolgt
DeviceIdund dass zwischen Datensätzen in Objekten, die an Amazon S3 übermittelt werden, neue Zeilentrennzeichen hinzugefügt werden.
Diese werden von AWS Glue benötigt, um die Daten später zu crawlen und damit Athena einzelne Datensätze erkennen kann.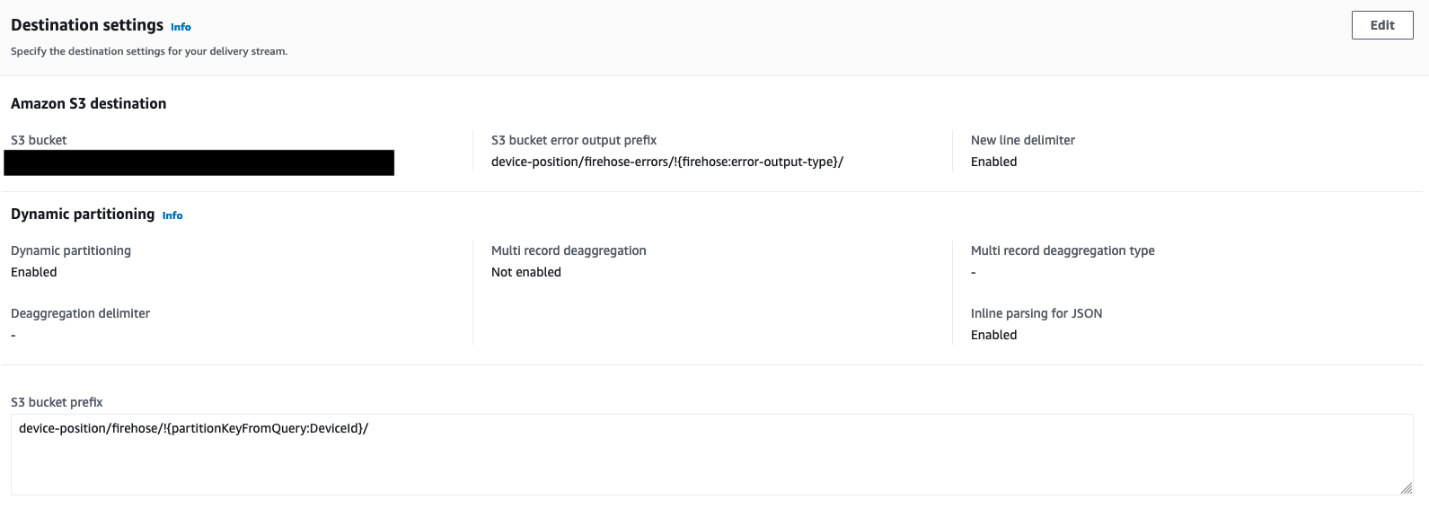
Erstellen Sie eine EventBridge-Regel und fügen Sie Ziele hinzu
Die EventBridge-Regel ProcessDevicePosition definiert zwei Ziele: die ProcessDevicePosition Lambda-Funktion und die ProcessDevicePositionFirehose Lieferstrom. Führen Sie die folgenden Schritte aus, um die Regel zu erstellen und Ziele anzuhängen:
- Erstellen Sie in der EventBridge-Konsole eine neue Regel.
- Aussichten für Name und Vorname, geben Sie einen Namen ein (für diesen Beitrag,
ProcessDevicePosition). - Aussichten für Eventbuswählen Standard.
- Aussichten für Regeltypwählen Regel mit einem Ereignismuster.
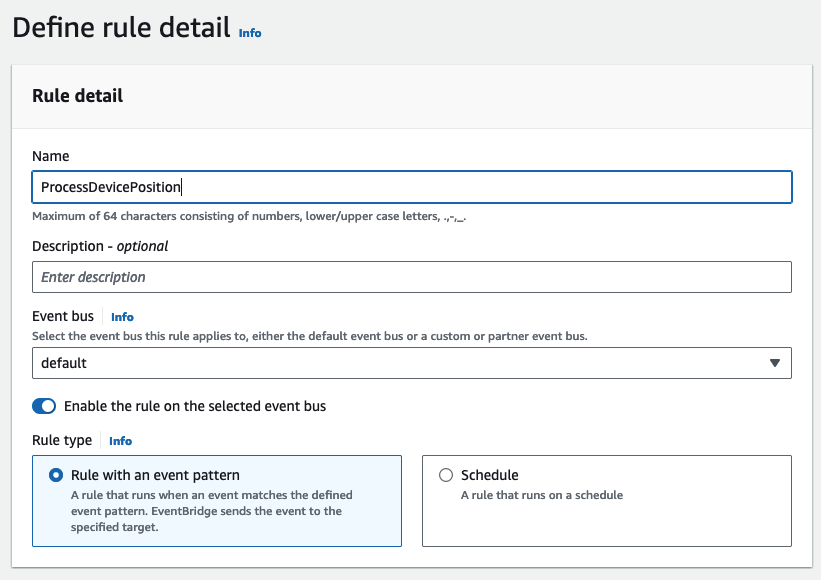
- Aussichten für EreignisquelleWählen AWS-Veranstaltungen oder EventBridge-Partnerveranstaltungen.
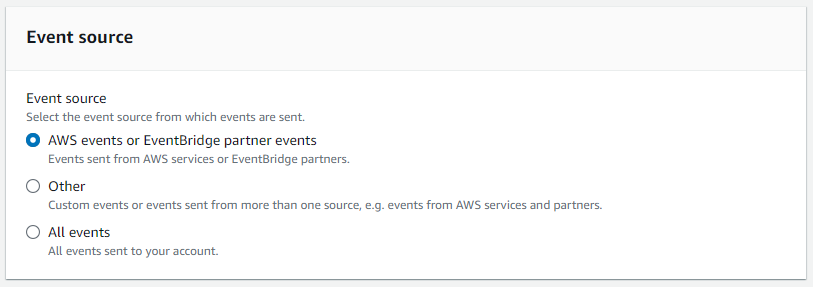
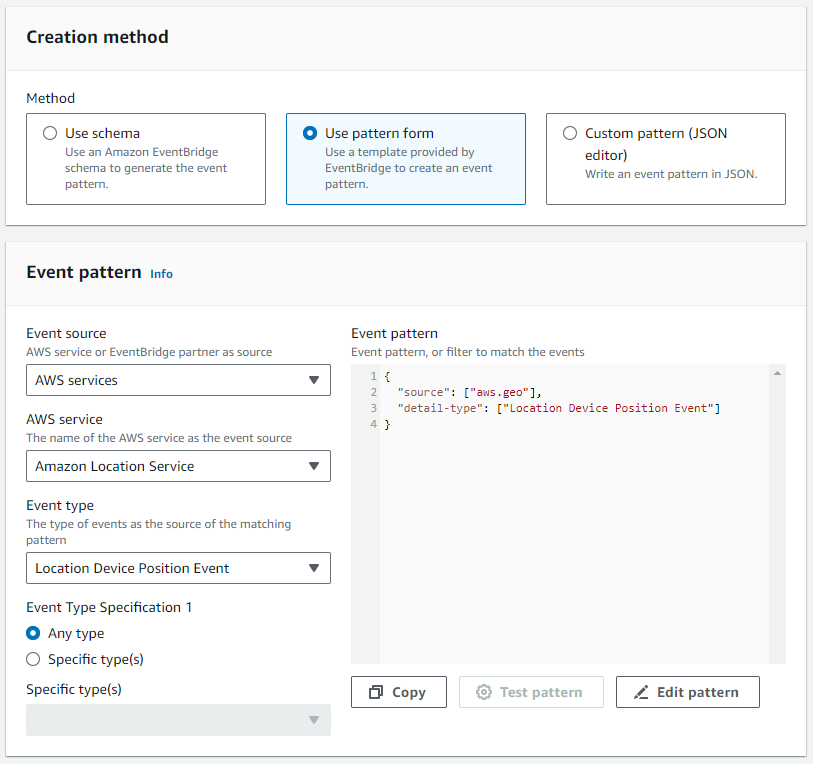
- Aussichten für VersandartWählen Musterform verwenden.
- Im Ereignismuster Abschnitt angeben AWS-Services als Quelle, Amazon-Standortservice als spezifischer Dienst und Standort-Gerätepositionsereignis als Veranstaltungstyp.
- Aussichten für Ziel 1, hänge an
ProcessDevicePositionLambda-Funktion als Ziel.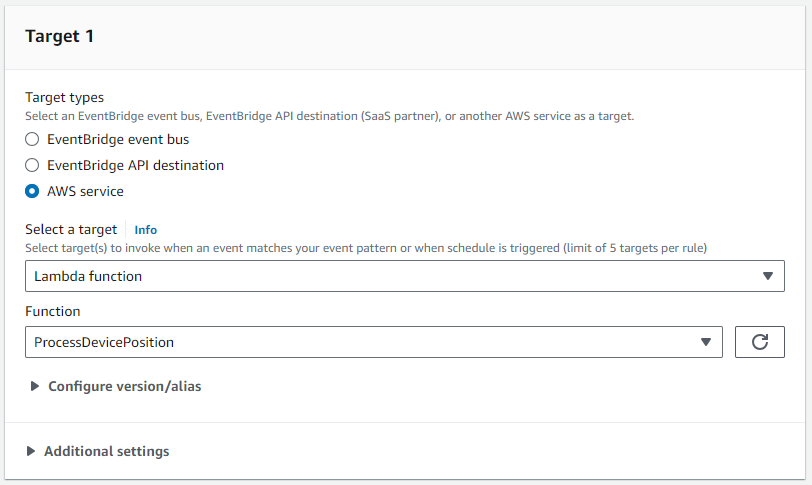
- Wir verwenden Eingangstransformator um das Ereignis anzupassen, das für den S3-Bucket festgeschrieben wird.
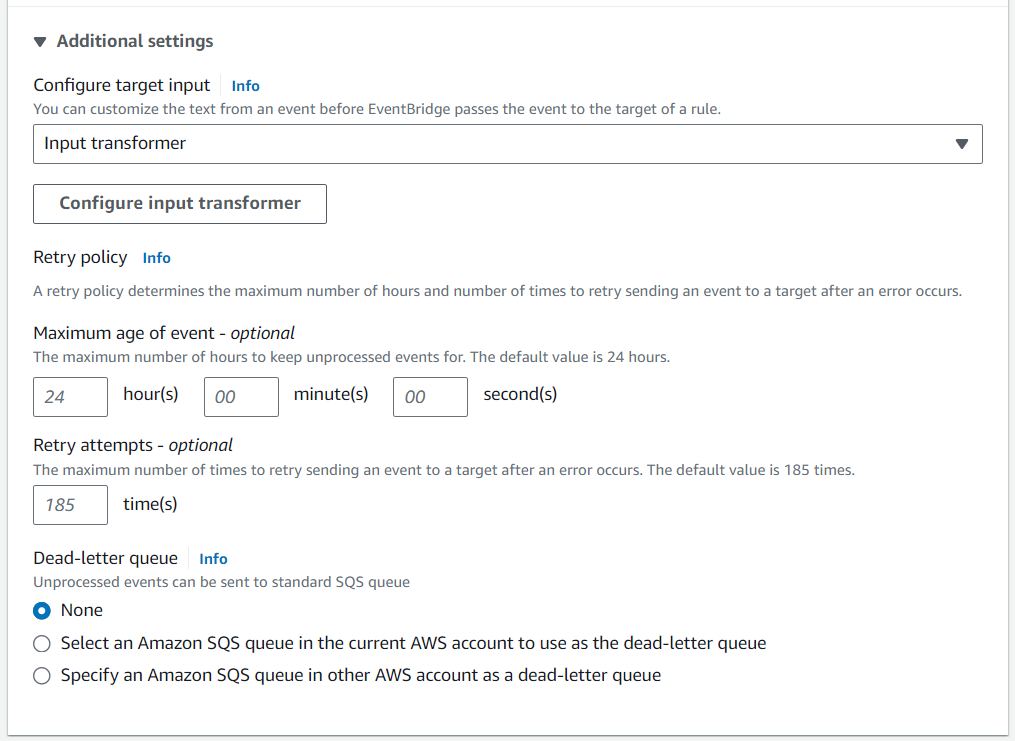
- Einrichtung Karte der Eingabepfade und Eingabevorlage um die Nutzlast im gewünschten Format zu organisieren.
- Der folgende Code ist die Zuordnung der Eingabepfade:
- Der folgende Code ist die Eingabevorlage:
- Aussichten für Ziel 2, wählen Sie das
ProcessDevicePositionFirehoseLieferstrom als Ziel.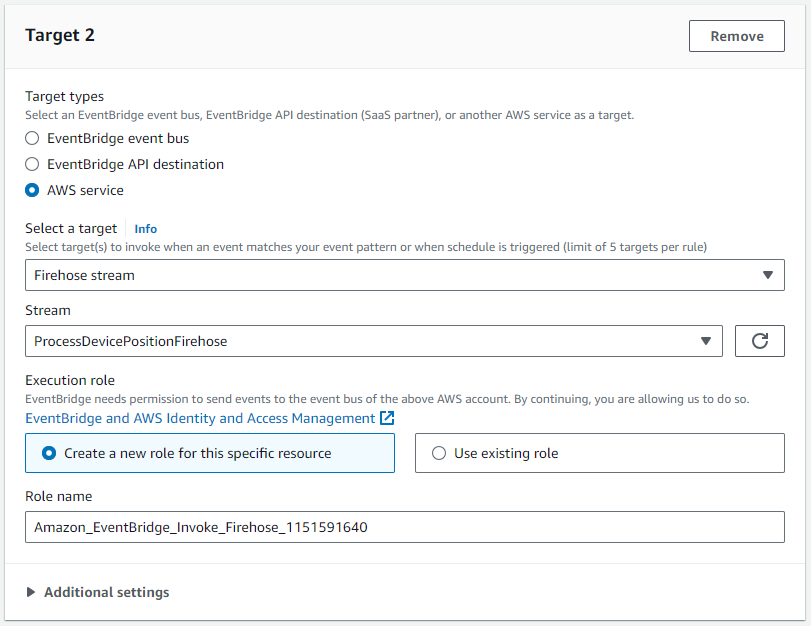
Dieses Ziel erfordert eine IAM-Rolle, die das Schreiben eines oder mehrerer Datensätze in den Firehose-Bereitstellungsstream ermöglicht:
Crawlen und katalogisieren Sie die Daten mit AWS Glue
Nachdem genügend Daten generiert wurden, führen Sie die folgenden Schritte aus:
- Wählen Sie in der AWS Glue-Konsole aus Crawlers im Navigationsbereich.
- Wählen Sie die erstellten Crawler aus.
location-analytics-glue-crawler-lambdaundlocation-analytics-glue-crawler-firehose. - Auswählen Führen Sie.
Die Crawler klassifizieren die Daten automatisch im JSON-Format, gruppieren die Datensätze in Tabellen und Partitionen und übergeben die zugehörigen Metadaten an den AWS Glue Data Catalog.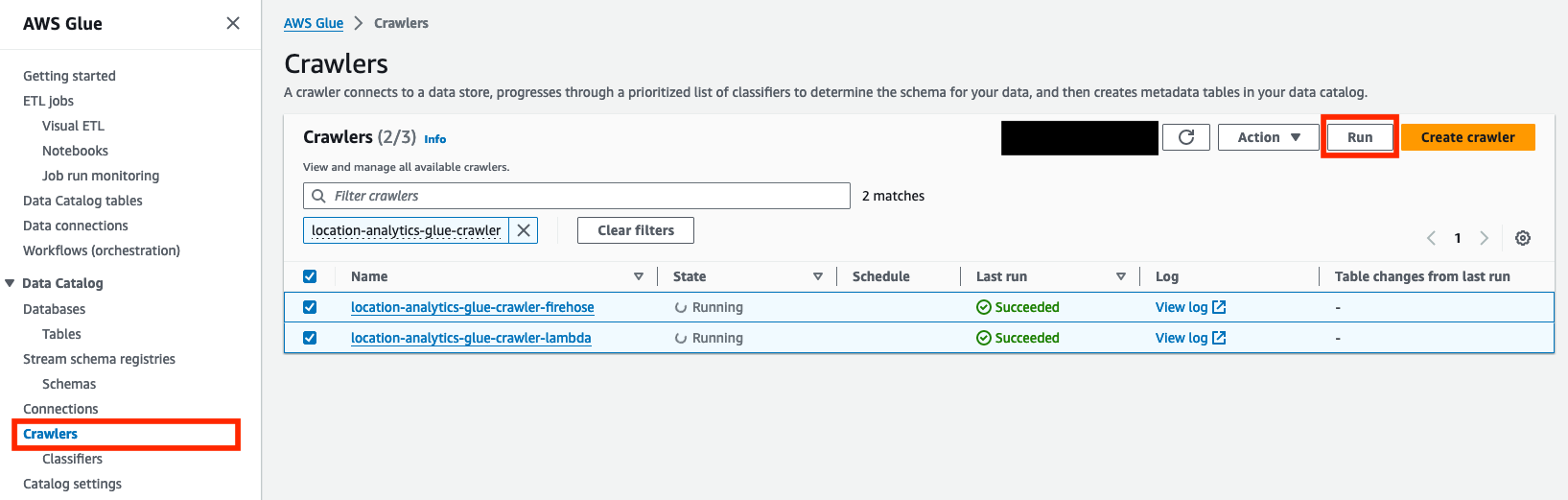
- Wenn das Letzte Fahrt Der Status beider Crawler wird als angezeigt Gelungen, bestätigen Sie, dass zwei Tabellen (
lambdaundfirehose) wurden auf der erstellt Tische
Die Lösung partitioniert die eingehenden Standortdaten basierend auf deviceid Feld. Daher müssen die Crawler nicht erneut ausgeführt werden, solange keine neuen Geräte oder Schemaänderungen vorliegen. Wenn jedoch neue Geräte hinzugefügt werden oder ein anderes Feld zur Partitionierung verwendet wird, müssen die Crawler erneut ausgeführt werden.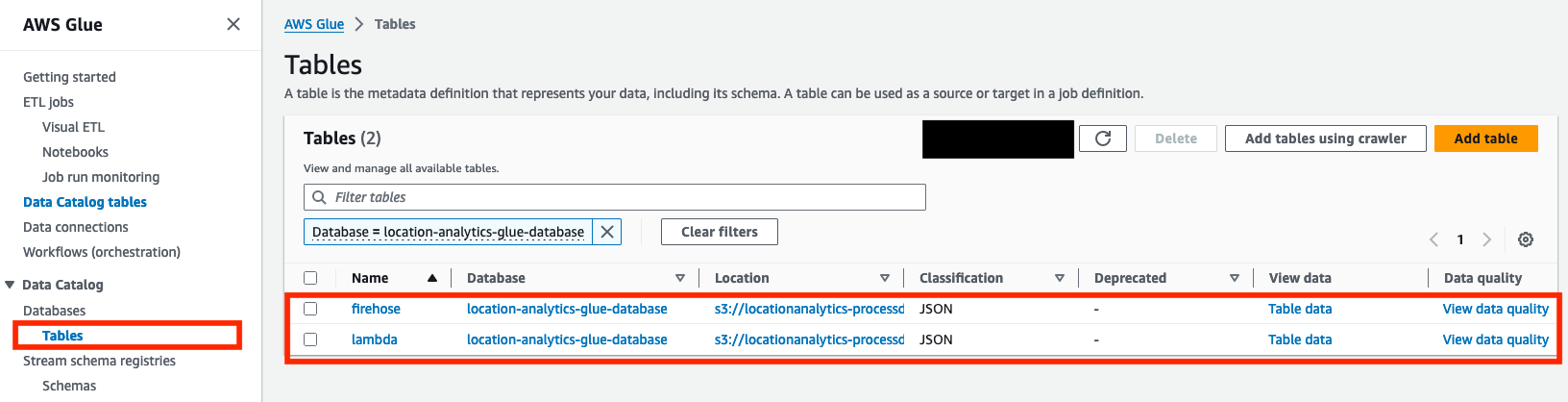
Jetzt können Sie die Tabellen mit Athena abfragen.
Fragen Sie die Daten mit Athena ab
Athena ist ein serverloser, interaktiver Analysedienst, der für die Analyse unstrukturierter, halbstrukturierter und strukturierter Daten dort entwickelt wurde, wo sie gehostet werden. Wenn Sie die Athena-Konsole zum ersten Mal verwenden, folge den Anweisungen um einen Speicherort für Abfrageergebnisse in Amazon S3 einzurichten. Um die Daten mit Athena abzufragen, führen Sie die folgenden Schritte aus:
- Öffnen Sie in der Athena-Konsole den Abfrage-Editor.
- Aussichten für Datenquelle, wählen
AwsDataCatalog. - Aussichten für Datenbase, wählen
location-analytics-glue-database. - Wählen Sie im Optionsmenü (drei vertikale Punkte) aus Vorschautabelle um den Inhalt beider Tabellen abzufragen.
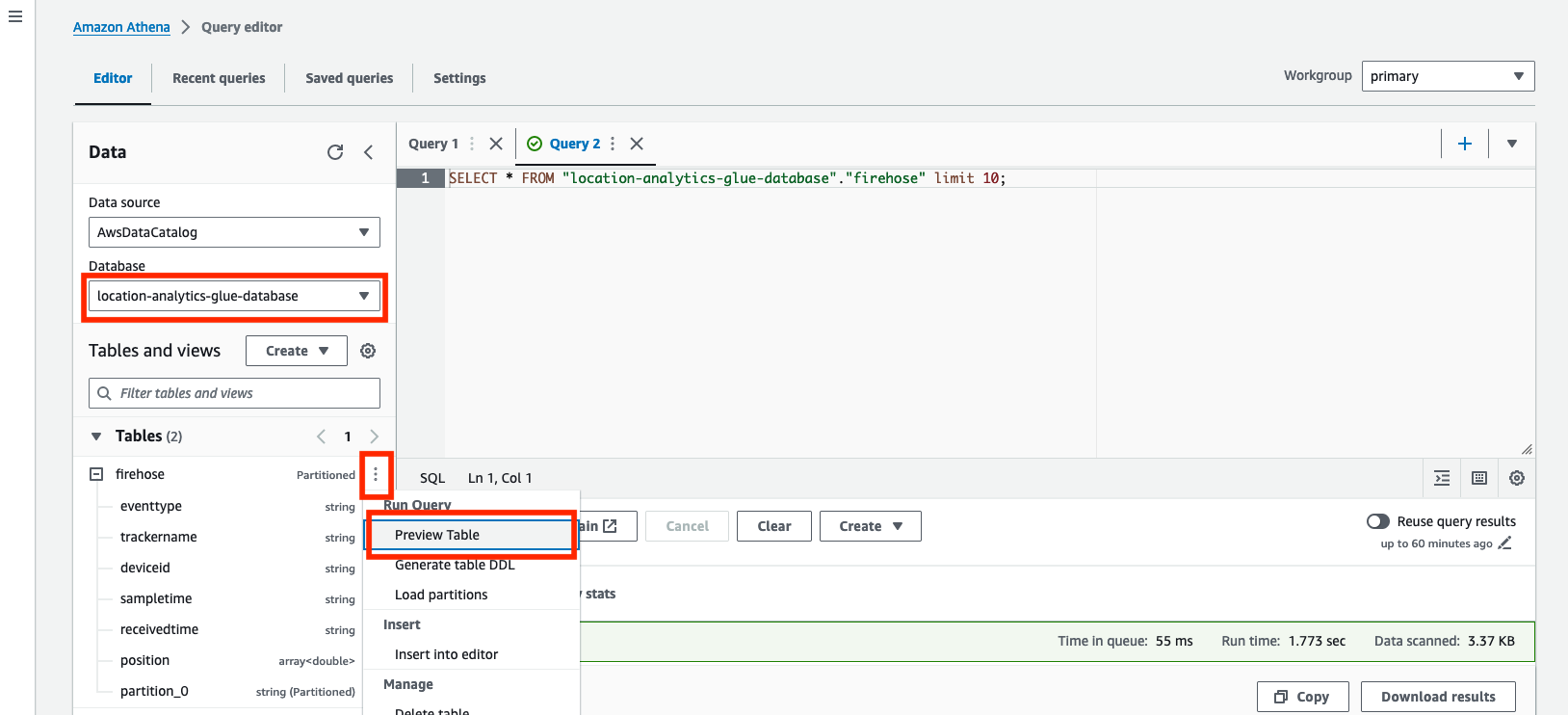
Die Abfrage zeigt 10 Beispielpositionsdatensätze an, die derzeit in der Tabelle gespeichert sind. Der folgende Screenshot ist ein Beispiel aus der Vorschau firehose Tabelle. Das firehose In der Tabelle werden rohe, unveränderte Daten vom Amazon Location Tracker gespeichert.
Sie können jetzt mit Geodatenabfragen experimentieren GeoJSON-Datei für die Londoner ULEZ-Erweiterung 2021 ist Teil des Repositorys und wurde bereits in eine Abfrage konvertiert, die mit beiden Athena-Tabellen kompatibel ist.
- Kopieren Sie den Inhalt und fügen Sie ihn ein 1-firehose-athena-ulez-2021-create-view.sql Datei gefunden in der
examples/firehoseOrdner in den Abfrageeditor.
Diese Abfrage verwendet die ST_Within Geodatenfunktion zur Bestimmung, ob eine aufgezeichnete Position innerhalb oder außerhalb der durch das Polygon definierten ULEZ-Zone liegt. Eine neue Ansicht namens ulezvehicleanalysis_firehose wird mit einer neuen Spalte erstellt, insidezone, die erfasst, ob die aufgezeichnete Position innerhalb der Zone existiert.
Ein einfaches Python Nutzen bereitgestellt, das die in der heruntergeladenen GeoJSON-Datei gefundenen Polygon-Features in konvertiert ST_Polygon Zeichenfolgen basierend auf dem bekanntes Textformat das direkt in einer Athena-Abfrage verwendet werden kann.
- Auswählen
Vorschauansicht auf die
ulezvehicleanalysis_firehoseAnsicht, um den Inhalt zu erkunden.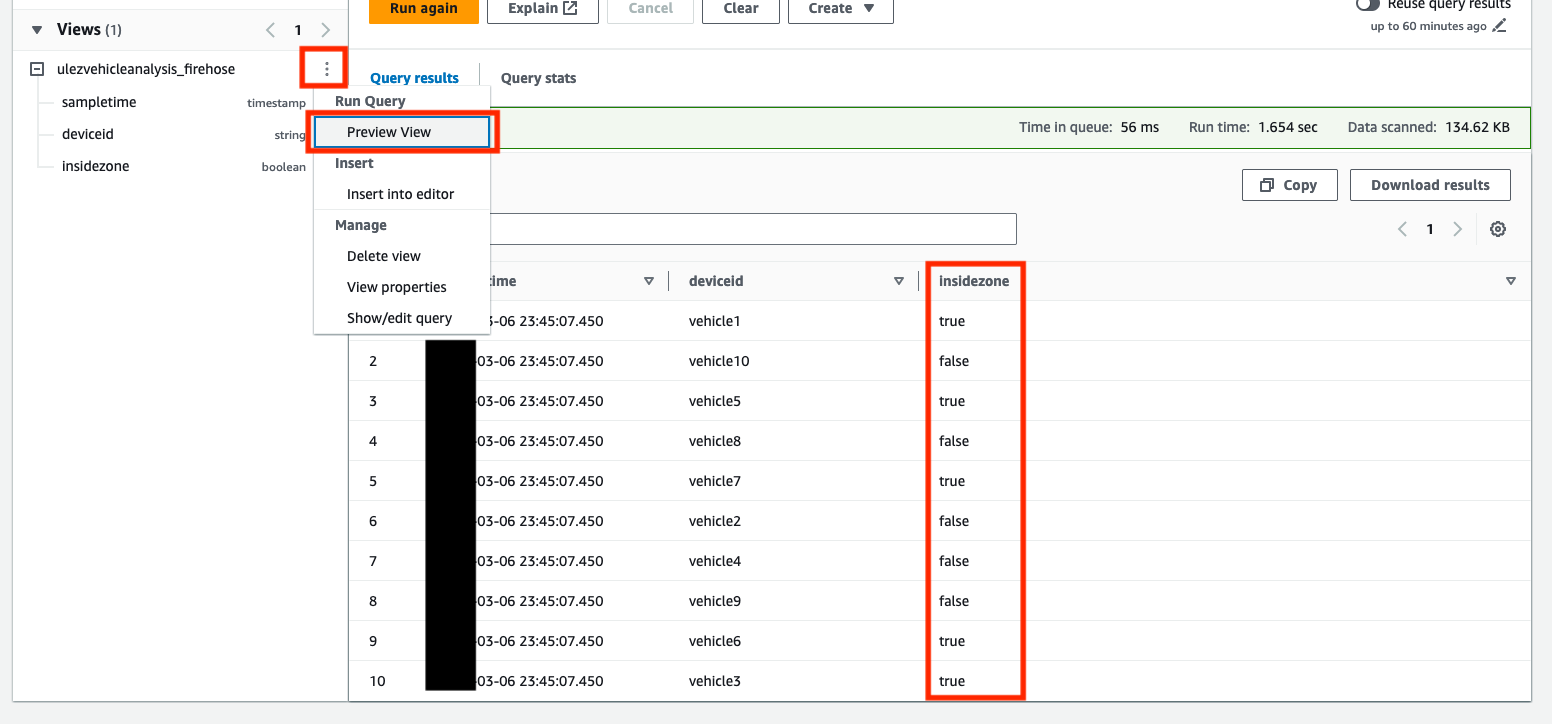
Sie können jetzt Abfragen für diese Ansicht ausführen, um übergreifende Erkenntnisse zu gewinnen.
- Kopieren Sie den Inhalt und fügen Sie ihn ein 2-firehose-athena-ulez-2021-query-days-in-zone.sql Datei gefunden in der
examples/firehoseOrdner in den Abfrageeditor.
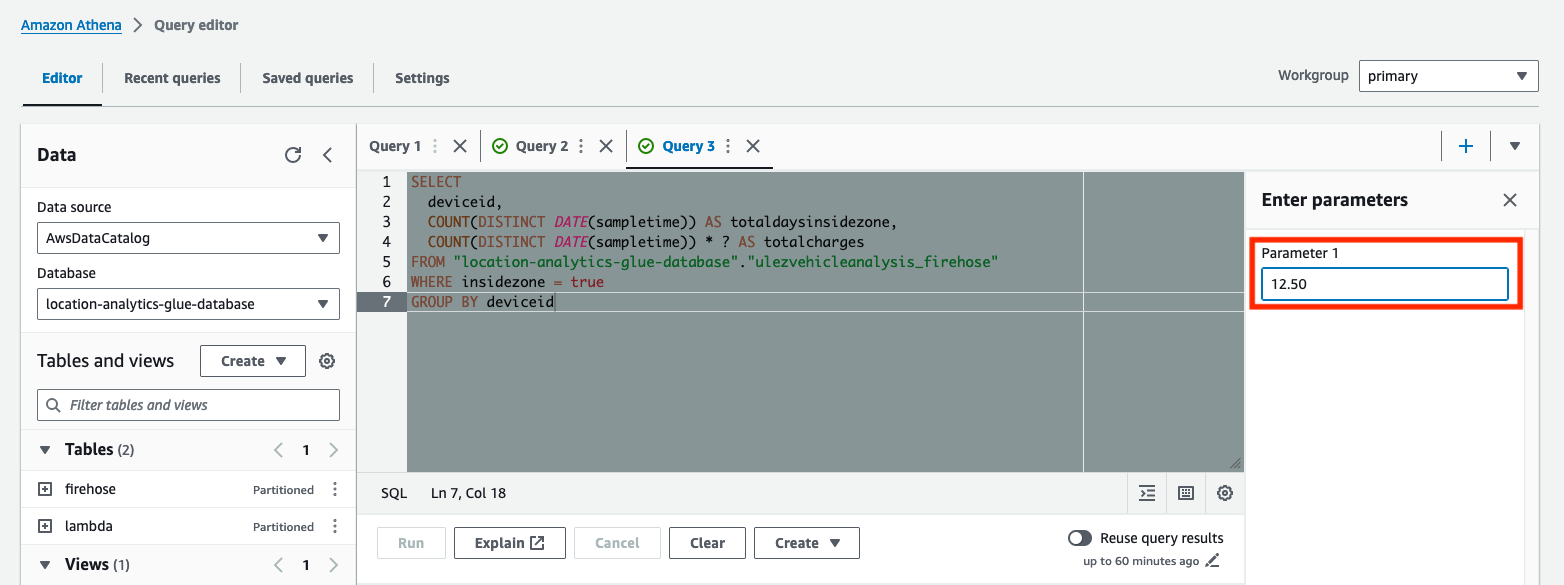
Diese Abfrage ermittelt die Gesamtzahl der Tage, die jedes Fahrzeug in die ULEZ eingefahren ist, und wie hoch die erwarteten Gesamtgebühren sein würden. Die Abfrage wurde mit parametrisiert ? Platzhalterzeichen. Parametrisierte Abfragen ermöglichen es Ihnen, dieselbe Abfrage mit unterschiedlichen Parameterwerten erneut auszuführen.
- Geben Sie den täglichen Gebührenbetrag ein Parameter 1, und führen Sie dann die Abfrage aus.
Die Ergebnisse zeigen jedes Fahrzeug, die Gesamtzahl der im vorgeschlagenen ULEZ verbrachten Tage und die Gesamtgebühren basierend auf der von Ihnen eingegebenen Tagesgebühr.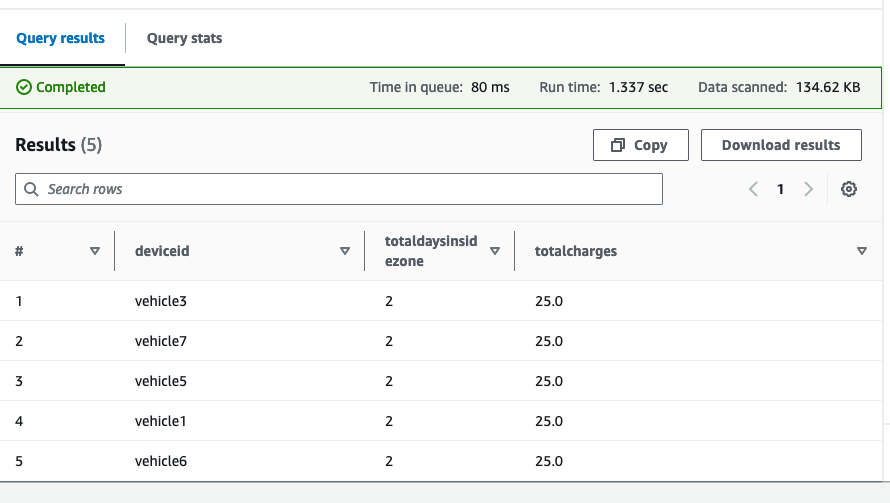
Sie können diese Übung mit dem wiederholen lambda Tisch. Daten in der lambda Die Tabelle wird um zusätzliche Fahrzeugdetails erweitert, die zum Zeitpunkt der Verarbeitung durch die Lambda-Funktion in der DynamoDB-Tabelle für die Fahrzeugwartung vorhanden sind. Die Lösung unterstützt die folgenden Bereiche:
MeetsEmissionStandards(Boolescher Wert)Mileage(Nummer)PurchaseDate(String, inYYYY-MM-DDFormat)
Sie können die neuen Daten auch anreichern, sobald sie eintreffen.
- Auf der DynamoDB-Konsole finden Sie unten die Fahrzeugwartungstabelle Tische. Als Ausgabe wird der Tabellenname bereitgestellt
VehicleMaintenanceDynamoTableim bereitgestellten CloudFormation-Stack. - Auswählen Erkunden Sie Tabellenelemente um den Inhalt der Tabelle anzuzeigen.
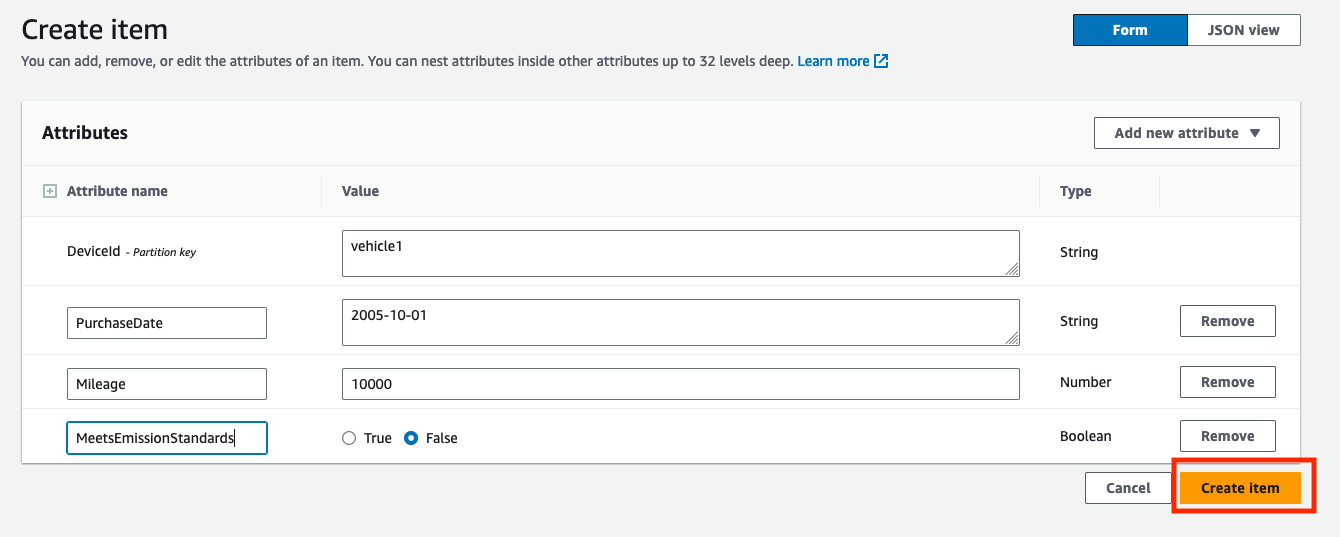
- Auswählen
Element erstellen um einen neuen Datensatz für ein Fahrzeug zu erstellen.

- Enter
DeviceId(Wie z. B.vehicle1als String),PurchaseDate(Wie z. B.2005-10-01als String),Mileage(Wie z. B.10000als Zahl) undMeetsEmissionStandards(mit einem Wert wieFalseals Boolean). - Auswählen
Element erstellen um den Datensatz zu erstellen.
- Duplizieren Sie den neu erstellten Datensatz mit zusätzlichen Einträgen für andere Fahrzeuge (z. B. für
vehicle2orvehicle3), wobei die Werte der Attribute jedes Mal leicht geändert werden. - Wiederholen Sie die
location-analytics-glue-crawler-lambdaAWS Glue-Crawler, nachdem neue Daten generiert wurden, um zu bestätigen, dass die Aktualisierung des Schemas mit neuen Feldern registriert ist. - Kopieren Sie den Inhalt und fügen Sie ihn ein 1-lambda-athena-ulez-2021-create-view.sql Datei gefunden in der
examples/lambdaOrdner in den Abfrageeditor. - Vorschau der
ulezvehicleanalysis_lambdaAnsicht, um zu bestätigen, dass die neuen Spalten erstellt wurden.
Wenn Fehler wie z Column 'mileage' cannot be resolved werden angezeigt, die Datenanreicherung findet nicht statt oder der AWS Glue-Crawler hat noch keine Aktualisierungen des Schemas erkannt.
Besitzt das Vorschautabellenoption nur Ergebnisse aus der Zeit vor der Erstellung von Datensätzen in der DynamoDB-Tabelle zurückgibt, geben Sie die Abfrageergebnisse in absteigender Reihenfolge mit zurück sampletime (zum Beispiel, order by sampletime desc limit 100;).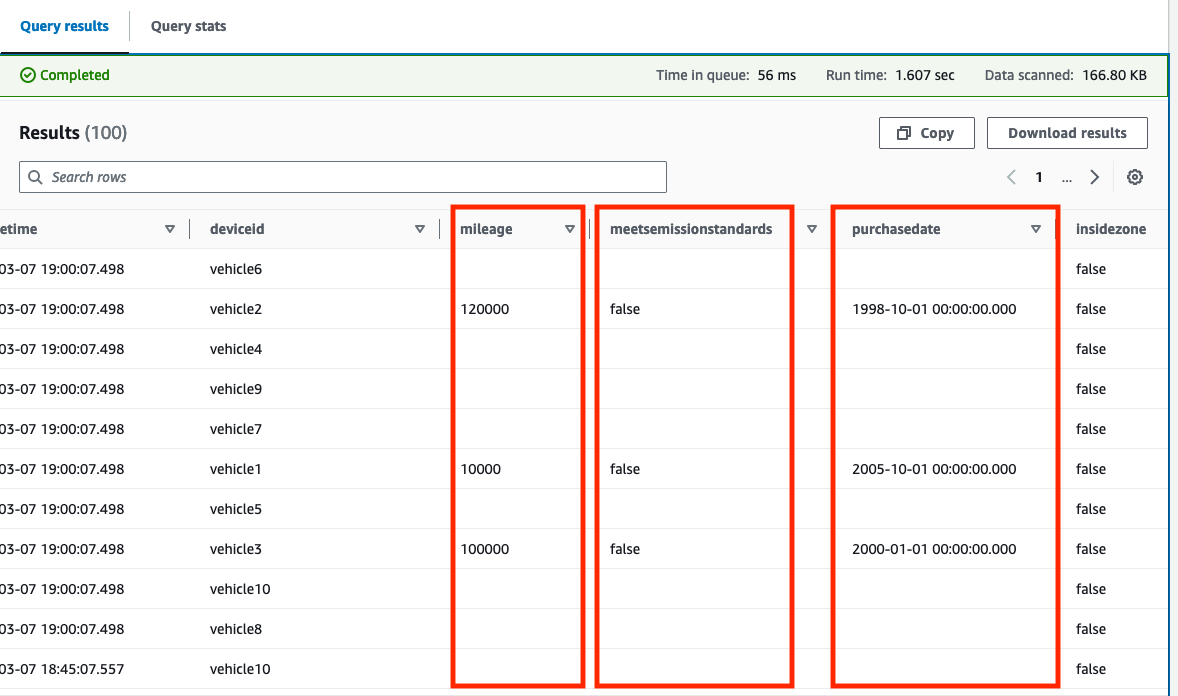
Jetzt konzentrieren wir uns auf die Fahrzeuge, die derzeit nicht den Abgasnormen entsprechen, und ordnen die Fahrzeuge in absteigender Reihenfolge basierend auf der Laufleistung pro Jahr (berechnet anhand der letzten Laufleistung/des Fahrzeugalters in Jahren).
- Kopieren Sie den Inhalt und fügen Sie ihn ein 2-lambda-athena-ulez-2021-query-days-in-zone.sql Datei gefunden in der
examples/lambdaOrdner in den Abfrageeditor.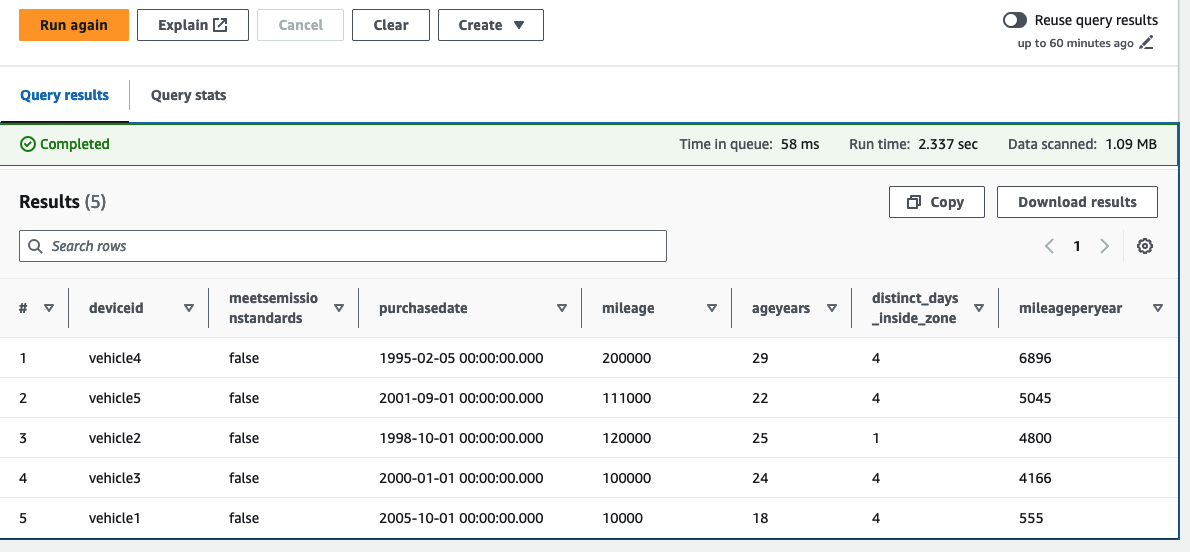
In diesem Beispiel können wir sehen, dass von fünf unserer Fahrzeugflotte gemeldet wurde, dass sie die Abgasnormen nicht erfüllen. Wir können auch die Fahrzeuge sehen, die pro Jahr eine hohe Kilometerleistung erzielt haben, sowie die Anzahl der Tage, die sie im vorgeschlagenen ULEZ verbracht haben. Der Flottenbetreiber kann nun entscheiden, diese Fahrzeuge vorrangig auszutauschen. Da Standortdaten zum Zeitpunkt der Erfassung mit den aktuellsten Fahrzeugwartungsdaten angereichert werden, können Sie diese Abfragen so weiterentwickeln, dass sie über ein definiertes Zeitfenster ausgeführt werden. Beispielsweise könnten Sie Kilometeränderungen im vergangenen Jahr berücksichtigen.
Aufgrund der dynamischen Natur der Datenanreicherung werden alle neuen Daten, die zusammen mit den Abfrageergebnissen an Amazon S3 übermittelt werden, geändert, sobald Datensätze in der DynamoDB-Fahrzeugwartungstabelle aktualisiert werden.
Aufräumen
Beachten Sie die Anweisungen in der README Datei, um die für diese Lösung bereitgestellten Ressourcen zu bereinigen.
Zusammenfassung
In diesem Beitrag wurde gezeigt, wie Sie Amazon Location, EventBridge, Lambda, Amazon Data Firehose und Amazon S3 verwenden können, um eine standortbezogene Datenpipeline aufzubauen und die gesammelten Gerätepositionsdaten zu nutzen, um mithilfe von AWS Glue und Athena analytische Erkenntnisse zu gewinnen. Durch die Verfolgung dieser Anlagen in Echtzeit und die Speicherung der Ergebnisse können Unternehmen wertvolle Erkenntnisse darüber gewinnen, wie effektiv ihre Flotten genutzt werden, und besser auf zukünftige Veränderungen reagieren. Sie können diesen Beispielcode jetzt mit Ihren eigenen Geräteverfolgungsdaten und Analyseanforderungen erweitern.
Über die Autoren
 Alan Peaty ist Senior Partner Solutions Architect bei AWS. Alan unterstützt Global Systems Integrators (GSIs) und Global Independent Software Vendors (GISVs) bei der Lösung komplexer Kundenherausforderungen mithilfe von AWS-Services. Bevor er zu AWS kam, arbeitete Alan als Architekt bei Systemintegratoren, um Geschäftsanforderungen in technische Lösungen umzusetzen. Außerhalb der Arbeit ist Alan ein IoT-Enthusiast und ein begeisterter Läufer, der es liebt, die schlammigen Pfade der englischen Landschaft zu erkunden.
Alan Peaty ist Senior Partner Solutions Architect bei AWS. Alan unterstützt Global Systems Integrators (GSIs) und Global Independent Software Vendors (GISVs) bei der Lösung komplexer Kundenherausforderungen mithilfe von AWS-Services. Bevor er zu AWS kam, arbeitete Alan als Architekt bei Systemintegratoren, um Geschäftsanforderungen in technische Lösungen umzusetzen. Außerhalb der Arbeit ist Alan ein IoT-Enthusiast und ein begeisterter Läufer, der es liebt, die schlammigen Pfade der englischen Landschaft zu erkunden.
 Parag Srivastava ist Lösungsarchitekt bei AWS und unterstützt Unternehmenskunden bei der erfolgreichen Cloud-Einführung und -Migration. Im Laufe seiner beruflichen Laufbahn war er intensiv an komplexen Projekten zur digitalen Transformation beteiligt. Seine Leidenschaft gilt auch der Entwicklung innovativer Lösungen rund um Geodatenaspekte von Adressen.
Parag Srivastava ist Lösungsarchitekt bei AWS und unterstützt Unternehmenskunden bei der erfolgreichen Cloud-Einführung und -Migration. Im Laufe seiner beruflichen Laufbahn war er intensiv an komplexen Projekten zur digitalen Transformation beteiligt. Seine Leidenschaft gilt auch der Entwicklung innovativer Lösungen rund um Geodatenaspekte von Adressen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/gain-insights-from-historical-location-data-using-amazon-location-service-and-aws-analytics-services/

