„Daten stehen im Mittelpunkt jeder Anwendung, jedes Prozesses und jeder Geschäftsentscheidung. Wenn Daten zur Verbesserung des Kundenerlebnisses und zur Förderung von Innovationen genutzt werden, kann dies zu Geschäftswachstum führen.“
- Swami Sivasubramanian, Vizepräsident für Datenbanken, Analysen und maschinelles Lernen bei AWS in Mit einem Zero-ETL-Ansatz unterstützt AWS Bauherren bei der Umsetzung von Analysen nahezu in Echtzeit.
Kunden aus allen Branchen werden zunehmend datengesteuert und möchten ihren Umsatz steigern, Kosten senken und ihre Geschäftsabläufe optimieren, indem sie nahezu Echtzeitanalysen für Transaktionsdaten implementieren und so ihre Agilität erhöhen. Basierend auf den Kundenbedürfnissen und ihrem Feedback investiert AWS und macht stetig Fortschritte bei der Verwirklichung unserer Zero-ETL-Vision, damit sich Bauherren mehr auf die Wertschöpfung aus Daten konzentrieren können, anstatt Daten für die Analyse aufzubereiten.
Unsere Null-ETL Integration mit Amazon RedShift erleichtert die Punkt-zu-Punkt-Datenverschiebung, um sie mithilfe von Amazon Redshift für Analysen, künstliche Intelligenz (KI) und maschinelles Lernen (ML) auf Petabytes an Daten vorzubereiten. Innerhalb von Sekunden nach dem Einschreiben von Transaktionsdaten unterstützt AWS-Datenbanken, Zero-ETL stellt die Daten nahtlos in Amazon Redshift zur Verfügung, sodass keine komplexen Datenpipelines erstellt und verwaltet werden müssen, die Extraktions-, Transformations- und Ladevorgänge (ETL) durchführen.
Damit Sie sich auf die Wertschöpfung aus Daten konzentrieren können, anstatt undifferenzierte Zeit und Ressourcen in den Aufbau und die Verwaltung von ETL-Pipelines zwischen Transaktionsdatenbanken und Data Warehouses zu investieren, haben wir kündigte auf der AWS re:Invent 2023 vier AWS-Datenbank-Zero-ETL-Integrationen mit Amazon Redshift an:
In diesem Beitrag bieten wir eine Schritt-für-Schritt-Anleitung für den Einstieg in nahezu Echtzeit-Betriebsanalysen mithilfe von Amazon Aurora PostgreSQL Zero-ETL-Integration mit Amazon Redshift.
Lösungsüberblick
Um eine Zero-ETL-Integration zu erstellen, geben Sie eine an Amazon Aurora PostgreSQL-kompatible Edition Cluster (kompatibel mit PostgreSQL 15.4 und Zero-ETL-Unterstützung) als Quelle und ein Redshift Data Warehouse als Ziel. Die Integration repliziert Daten aus der Quelldatenbank in das Ziel-Data Warehouse.
Sie müssen von Aurora PostgreSQL DB bereitgestellte Cluster innerhalb erstellen Amazon RDS-Datenbankvorschauumgebung und eine Rotverschiebung bereitgestellter Vorschau-Cluster or Serverlose Vorschau-Arbeitsgruppe, in der AWS-Region USA Ost (Ohio). Stellen Sie für Amazon Redshift sicher, dass Sie den Track „preview_2023“ auswählen, um Zero-ETL-Integrationen zu verwenden.
Das folgende Diagramm veranschaulicht die in diesem Beitrag implementierte Architektur.
Im Folgenden sind die Schritte aufgeführt, die zum Einrichten der Zero-ETL-Integration für diese Lösung erforderlich sind. Vollständige Anleitungen für die ersten Schritte finden Sie unter Arbeiten mit Aurora Zero-ETL-Integrationen mit Amazon Redshift und Arbeiten mit Zero-ETL-Integrationen.
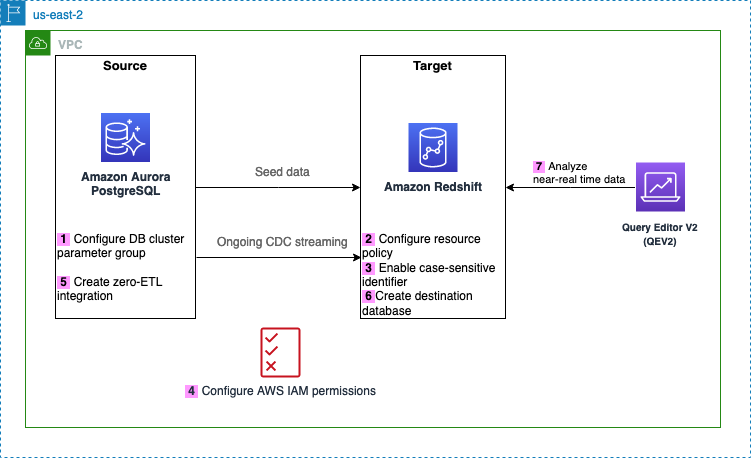
Nach Schritt 1 können Sie auch die Schritte 2–4 überspringen und direkt ab Schritt 5 mit der Erstellung Ihrer Zero-ETL-Integration beginnen. In diesem Fall zeigt Amazon RDS eine Meldung über fehlende Konfigurationen an und Sie können auswählen Repariere es für mich Damit Amazon RDS die Schritte automatisch konfigurieren kann.
- Konfigurieren Sie die Aurora PostgreSQL-Quelle mit einer benutzerdefinierten DB-Cluster-Parametergruppe.
- Konfigurieren Sie die Amazon Redshift ohne Server Ziel mit der erforderlichen Ressourcenrichtlinie für seinen Namespace.
- Aktualisieren Sie die Redshift Serverless-Arbeitsgruppe, um Bezeichner zu aktivieren, bei denen die Groß-/Kleinschreibung beachtet wird.
- Konfigurieren Sie die erforderlichen Berechtigungen.
- Erstellen Sie die Zero-ETL-Integration.
- Erstellen Sie eine Datenbank aus der Integration in Amazon Redshift.
- Beginnen Sie mit der Analyse der Transaktionsdaten nahezu in Echtzeit.
Konfigurieren Sie die Aurora PostgreSQL-Quelle mit einer benutzerdefinierten DB-Cluster-Parametergruppe
Für Aurora PostgreSQL-DB-Cluster müssen Sie die benutzerdefinierte Parametergruppe innerhalb erstellen Amazon RDS-Datenbankvorschauumgebung, in der Region USA Ost (Ohio). Du kannst Greifen Sie direkt auf die Amazon RDS-Vorschauumgebung zu.
Führen Sie die folgenden Schritte aus, um eine Aurora PostgreSQL-Datenbank zu erstellen:
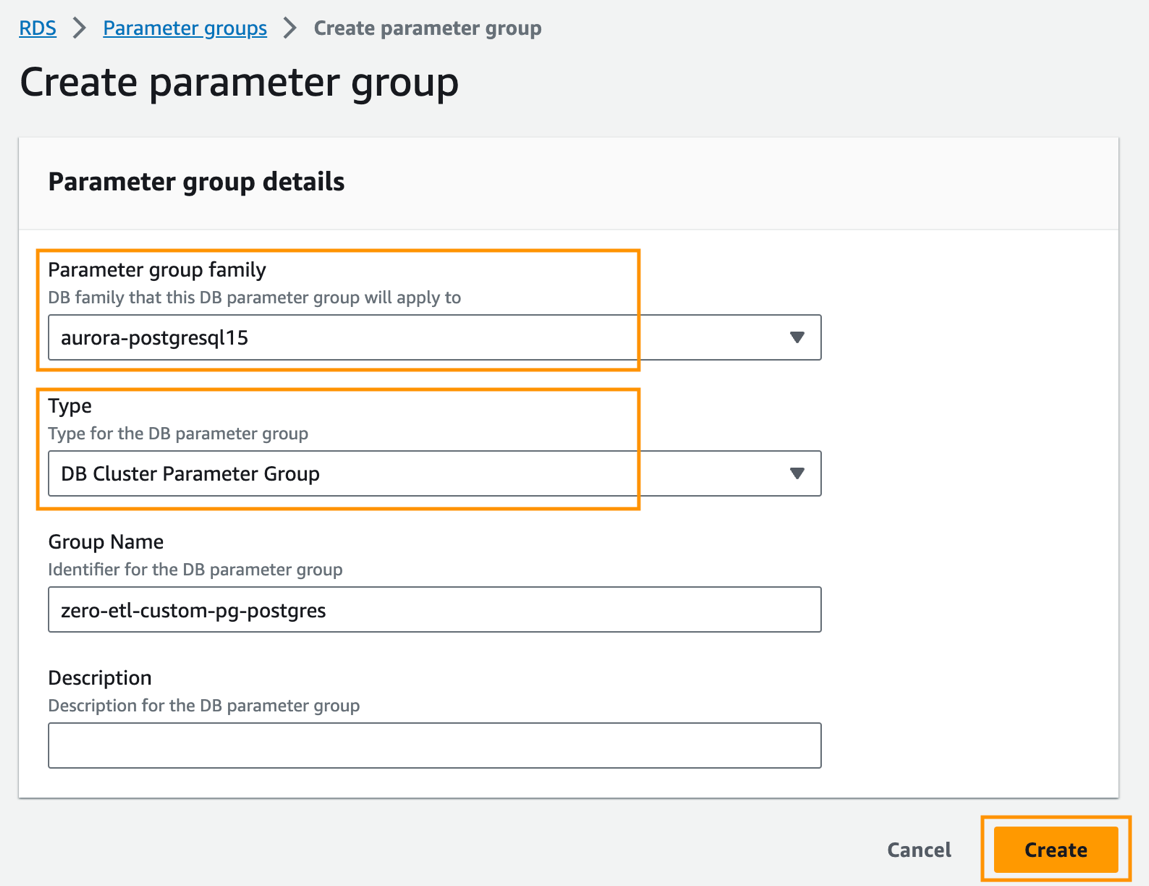
- Wählen Sie in der Amazon RDS-Konsole aus Parametergruppen im Navigationsbereich.
- Auswählen Parametergruppe erstellen.
- Aussichten für Parametergruppenfamilie, wählen
aurora-postgresql15. - Aussichten für Typ, wählen
DB Cluster Parameter Group. - Aussichten für GruppennameGeben Sie einen Namen ein (z. B.
zero-etl-custom-pg-postgres). - Auswählen
Erstellen.
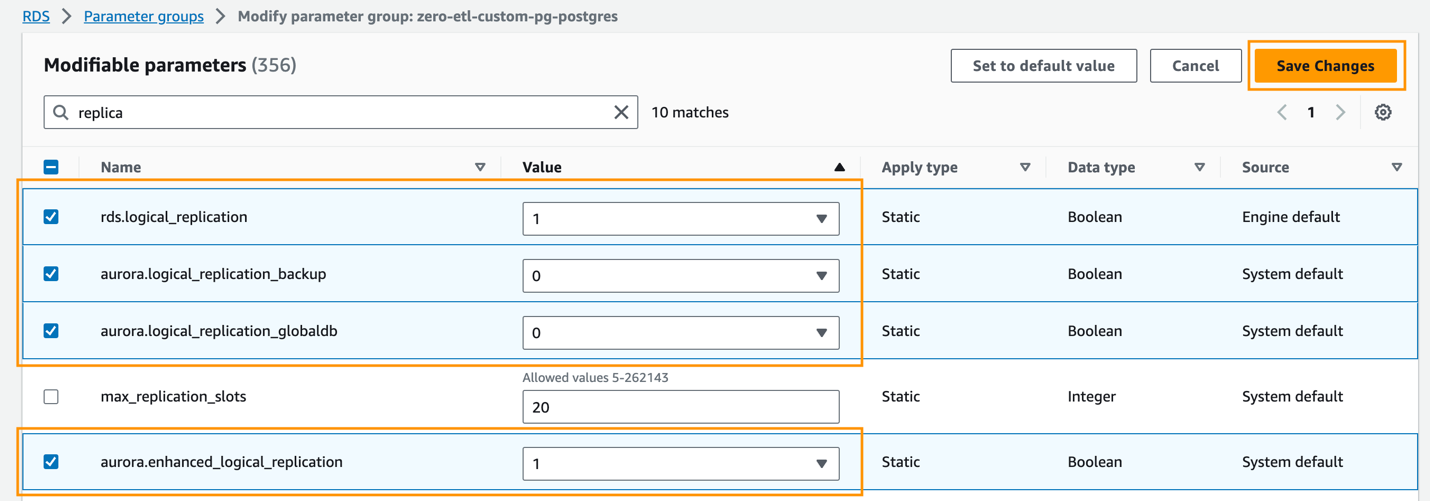
Aurora PostgreSQL Zero-ETL-Integrationen mit Amazon Redshift erfordern bestimmte Werte für Parameter des Aurora DB-Clusters, was eine erweiterte logische Replikation erfordert (aurora.enhanced_logical_replication).
- Auf dem Parametergruppen Wählen Sie auf der Seite die neu erstellte Parametergruppe aus.
- Auf dem Aktionen Menü, wählen Sie Bearbeiten.
- Legen Sie Folgendes fest: Aurora PostgreSQL (aurora-postgresql15-Familie) Cluster-Parametereinstellungen:
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
Durch die Aktivierung der erweiterten logischen Replikation (aurora.enhanced_logical_replication) wird der Parameter REPLICA IDENTITY automatisch auf FULL gesetzt, was bedeutet, dass alle Spaltenwerte in das Write-Ahead-Protokoll (WAL) geschrieben werden.
- Auswählen
Änderungen speichern.
- Auswählen
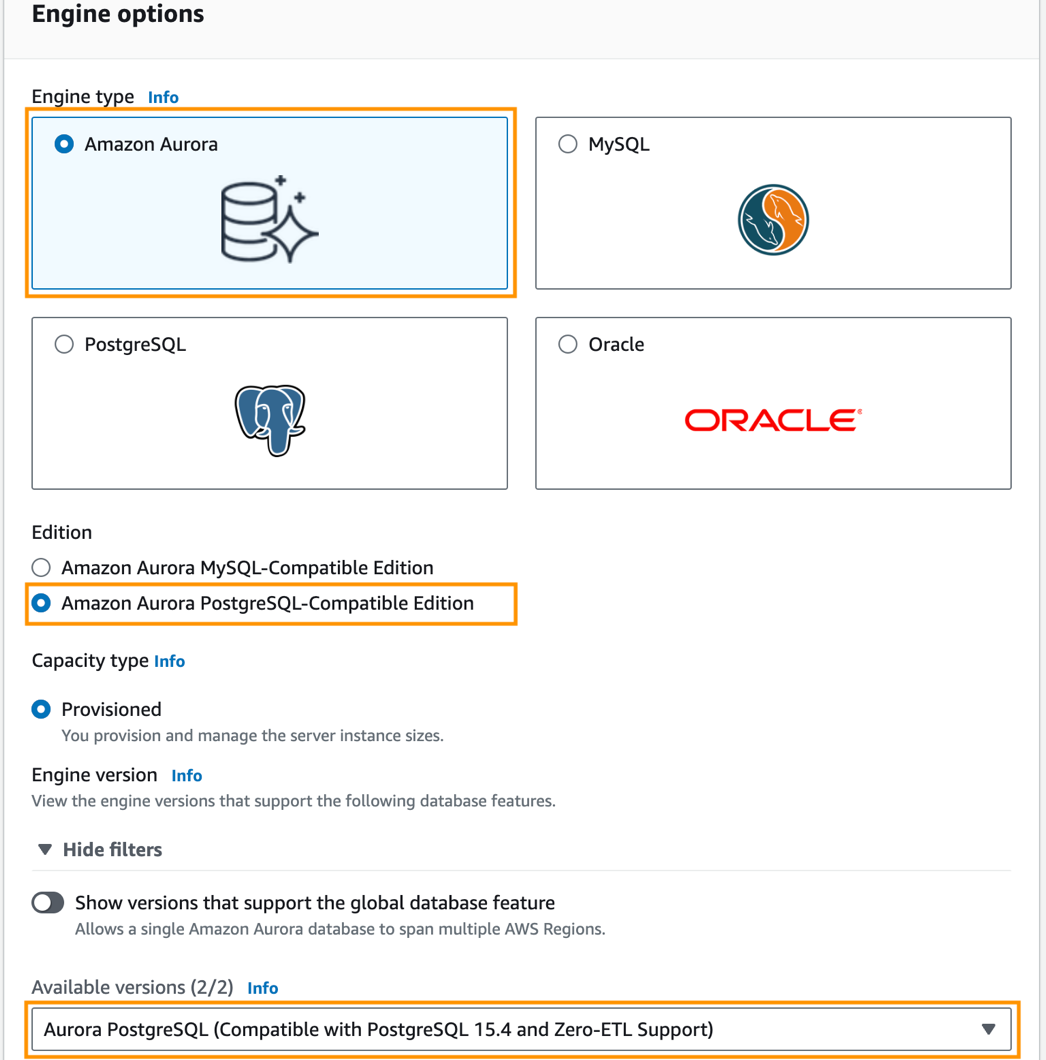
Datenbanken im Navigationsbereich und wählen Sie dann aus Datenbank erstellen.

- Aussichten für MotortypWählen Amazonas-Aurora.
- Aussichten für AusgabeWählen Amazon Aurora PostgreSQL-kompatible Edition.
- Aussichten für Verfügbare Versionen, wählen Aurora PostgreSQL (kompatibel mit PostgreSQL 15.4 und Zero-ETL-Unterstützung).
- Aussichten für TemplateWählen Produktion.
- Aussichten für DB-Cluster-ID, eingeben
zero-etl-source-pg.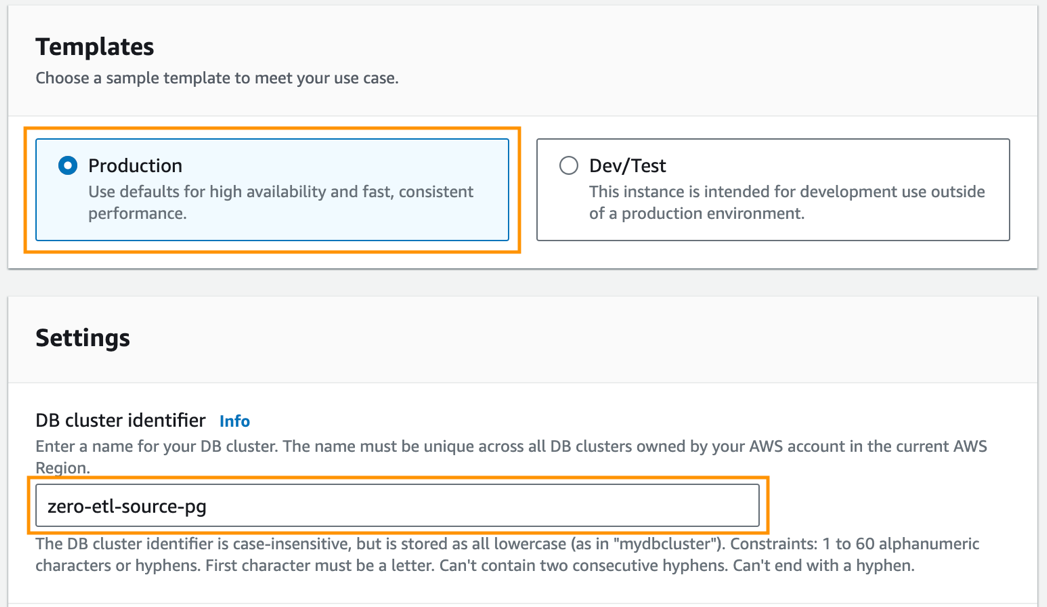
- Der Anmeldeinformationseinstellungen, geben Sie ein Passwort für ein Master Passwort oder nutzen Sie die Option, automatisch ein Passwort für Sie zu generieren.
- Im Abschnitt zur InstanzkonfigurationWählen Speicheroptimierte Klassen.
- Wählen Sie eine geeignete Instanzgröße (Standard ist).
db.r5.2xlarge).
- Der Zusätzliche KonfigurationZ. DB-Cluster-Parametergruppe, wählen Sie die Parametergruppe aus, die Sie zuvor erstellt haben (
zero-etl-custom-pg-postgres).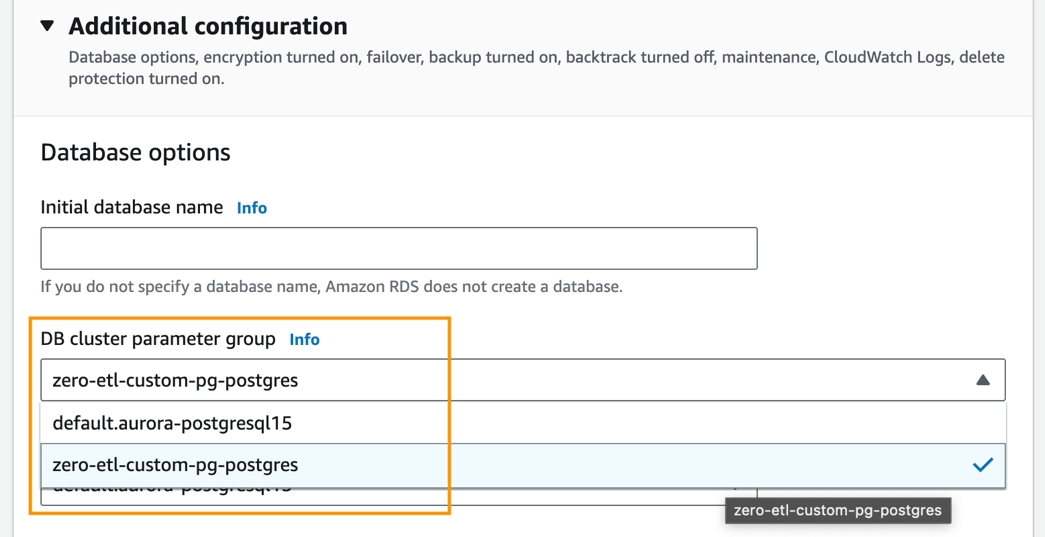
- Behalten Sie für die restlichen Konfigurationen die Standardeinstellungen bei.
- Auswählen Datenbank erstellen.
In wenigen Minuten sollte dadurch ein Aurora PostgreSQL-Cluster mit einer Writer- und einer Reader-Instanz gestartet werden, wobei sich der Status von ändert Erstellen zu Verfügbar. Der neu erstellte Aurora PostgreSQL-Cluster wird die Quelle für die Zero-ETL-Integration sein.
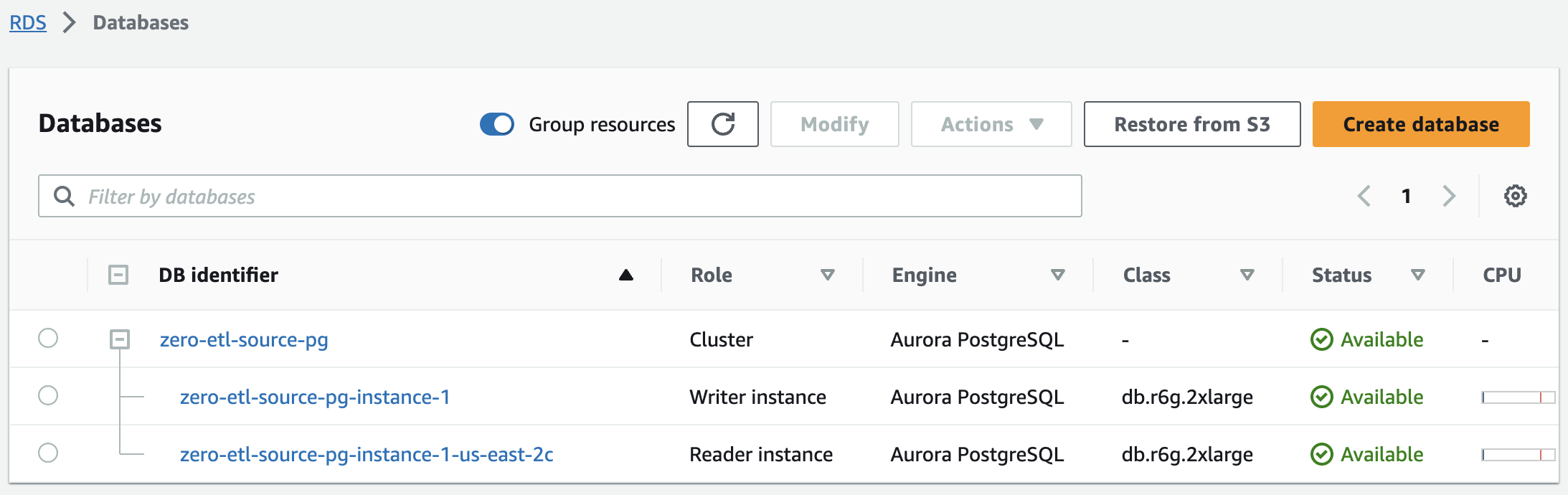
Der nächste Schritt besteht darin, eine benannte Datenbank in Amazon Aurora PostgreSQL für die Zero-ETL-Integration zu erstellen.
Mit dem PostgreSQL-Ressourcenmodell können Sie mehrere Datenbanken innerhalb eines Clusters erstellen. Daher müssen Sie während des Erstellungsschritts der Zero-ETL-Integration angeben, welche Datenbank Sie als Quelle für Ihre Integration verwenden möchten.
Beim Einrichten von PostgreSQL erhalten Sie standardmäßig drei Standarddatenbanken: template0, template1 und postgres. Wann immer Sie eine neue Datenbank in PostgreSQL erstellen, basiert sie tatsächlich auf einer dieser drei Datenbanken in Ihrem Cluster. Die während der Aurora PostgreSQL-Clustererstellung erstellte Datenbank basiert auf template0. Der CREATE DATABASE Der Befehl funktioniert, indem er eine vorhandene Datenbank kopiert. Wenn er nicht explizit angegeben wird, kopiert er standardmäßig die Standardsystemdatenbankvorlage1. Für die benannte Datenbank für die Zero-ETL-Integration muss die Datenbank mit Vorlage1 und nicht mit Vorlage0 erstellt werden. Daher wird unter ein anfänglicher Datenbankname hinzugefügt Zusätzliche Konfiguration, das mit template0 erstellt würde und nicht für die Zero-ETL-Integration verwendet werden kann.
- So erstellen Sie eine neue benannte Datenbank mit
CREATE DATABASEinnerhalb des neuen Aurora PostgreSQL-Clusterszero-etl-source-pgRufen Sie zunächst den Endpunkt der Writer-Instanz des PostgreSQL-Clusters ab.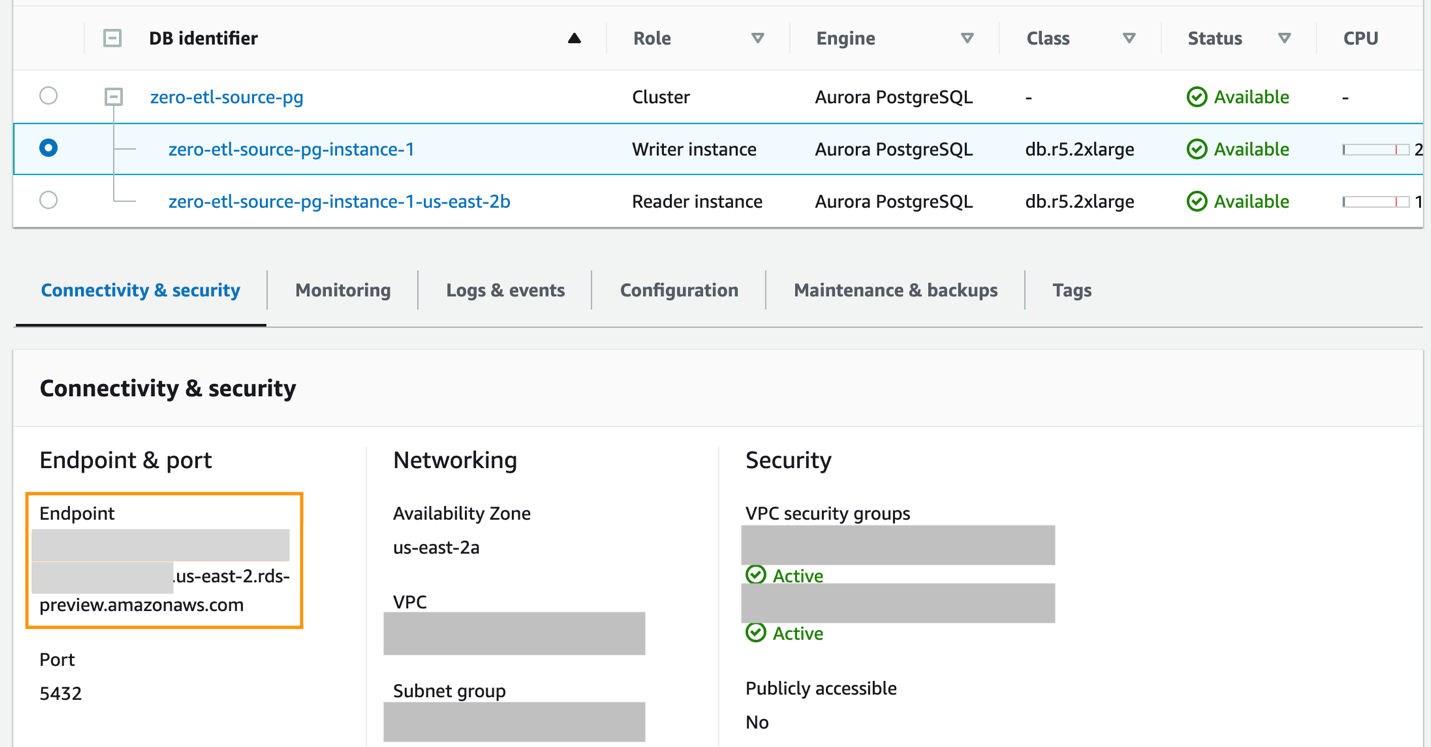
- Von einem Terminal oder über AWS CloudShellStellen Sie eine SSH-Verbindung zum PostgreSQL-Cluster her und führen Sie die folgenden Befehle aus, um psql zu installieren und eine neue Datenbank zu erstellen
zeroetl_db:
Hinzufügen template template1 ist optional, da standardmäßig, sofern nicht erwähnt, CREATE DATABASE wird benutzen template1.
Sie können sich auch über einen Client verbinden und die Datenbank erstellen. Beziehen auf Stellen Sie eine Verbindung zu einem Aurora PostgreSQL-DB-Cluster her für die Optionen zum Herstellen einer Verbindung mit dem PostgreSQL-Cluster.
Konfigurieren Sie Redshift Serverless als Ziel
Nachdem Sie Ihren Aurora PostgreSQL-Quelldatenbank-Cluster erstellt haben, konfigurieren Sie ein Redshift-Ziel-Data-Warehouse. Das Data Warehouse muss folgende Anforderungen erfüllen:
- In der Vorschau erstellt (nur für Aurora PostgreSQL-Quellen)
- Verwendet einen RA3-Knotentyp (ra3.16xlarge, ra3.4xlarge oder ra3.xlplus) mit mindestens zwei Knoten oder Redshift Serverless
- Verschlüsselt (bei Verwendung eines bereitgestellten Clusters)
Für diesen Beitrag erstellen und konfigurieren wir eine Redshift Serverless-Arbeitsgruppe und einen Namespace als Ziel-Data-Warehouse, indem wir die folgenden Schritte befolgen:
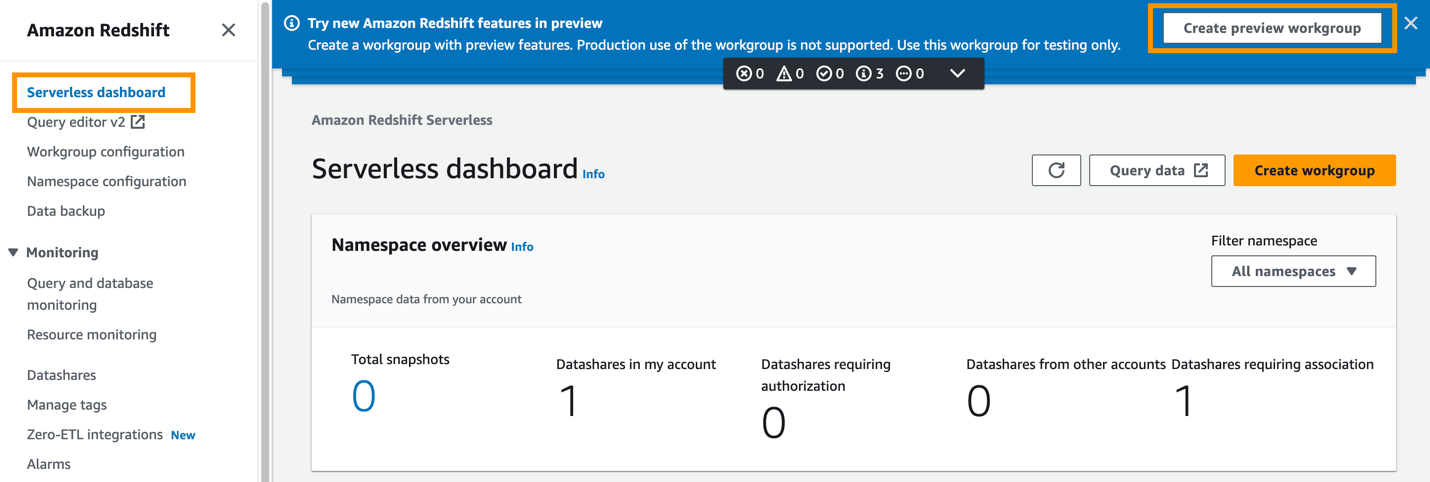
- Wählen Sie in der Amazon Redshift-Konsole aus Serverloses Dashboard im Navigationsbereich.
Da die Zero-ETL-Integration für Amazon Aurora PostgreSQL in Amazon Redshift in der Vorschau (nicht für Produktionszwecke) gestartet wurde, müssen Sie das Ziel-Data Warehouse in einer Vorschauumgebung erstellen.
- Auswählen
Erstellen Sie eine Vorschau-Arbeitsgruppe.
Der erste Schritt besteht darin, die Redshift Serverless-Arbeitsgruppe zu konfigurieren.
- Aussichten für ArbeitsgruppennameGeben Sie einen Namen ein (z. B.
zero-etl-target-rs-wg).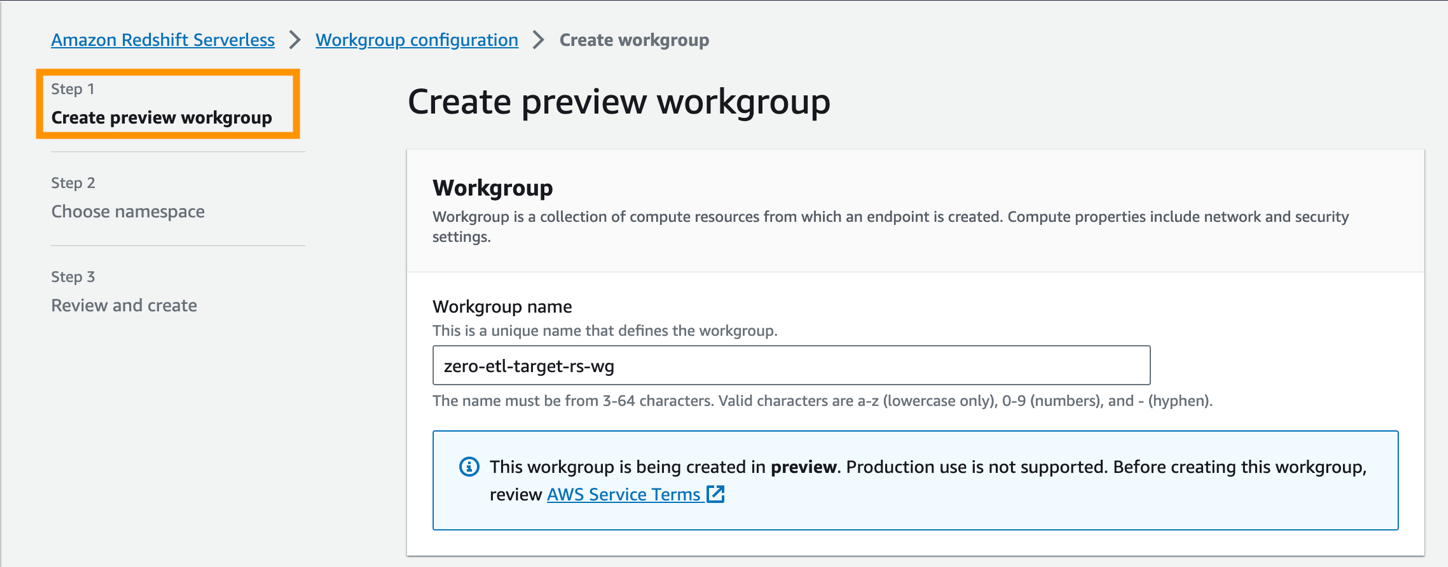
- Darüber hinaus können Sie die Kapazität auswählen, um die Rechenressourcen des Data Warehouse zu begrenzen. Die Kapazität kann in 8er-Schritten von 8 bis 512 RPUs konfiguriert werden. Stellen Sie dies für diesen Beitrag auf ein
8RPUs. - Auswählen
Weiter.

Als Nächstes müssen Sie den Namespace des Data Warehouse konfigurieren.
- Auswählen Erstellen Sie einen neuen Namensraum.
- Aussichten für NamespaceGeben Sie einen Namen ein (z. B.
zero-etl-target-rs-ns). - Auswählen
Weiter.
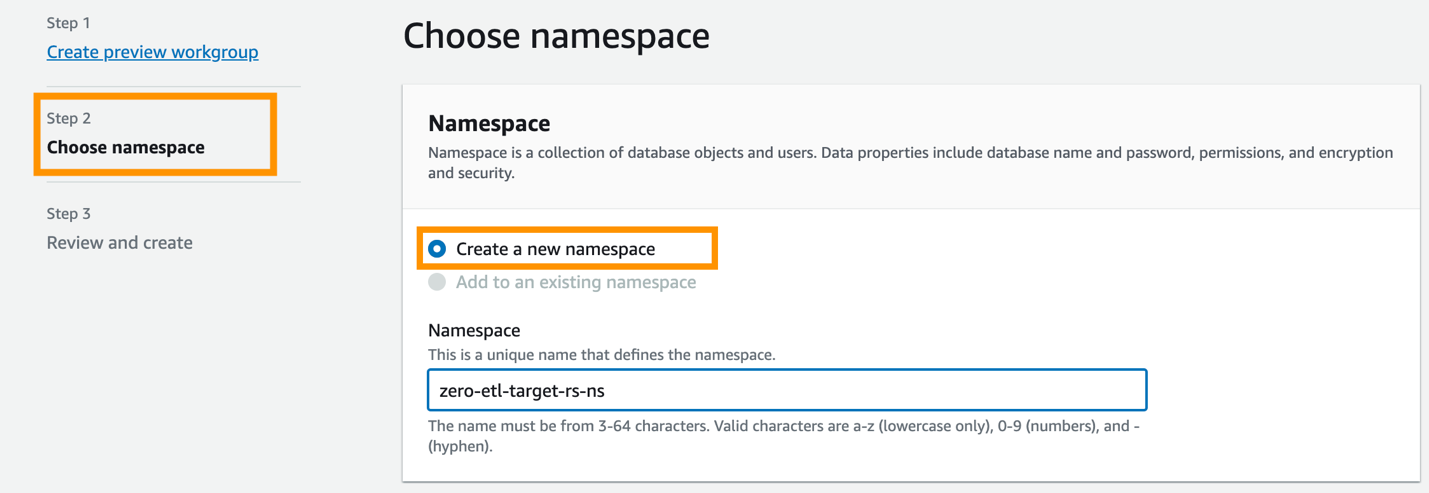
- Auswählen Arbeitsgruppe erstellen.
- Nachdem die Arbeitsgruppe und der Namespace erstellt wurden, wählen Sie Namespace-Konfigurationen im Navigationsbereich und öffnen Sie die Namespace-Konfiguration.
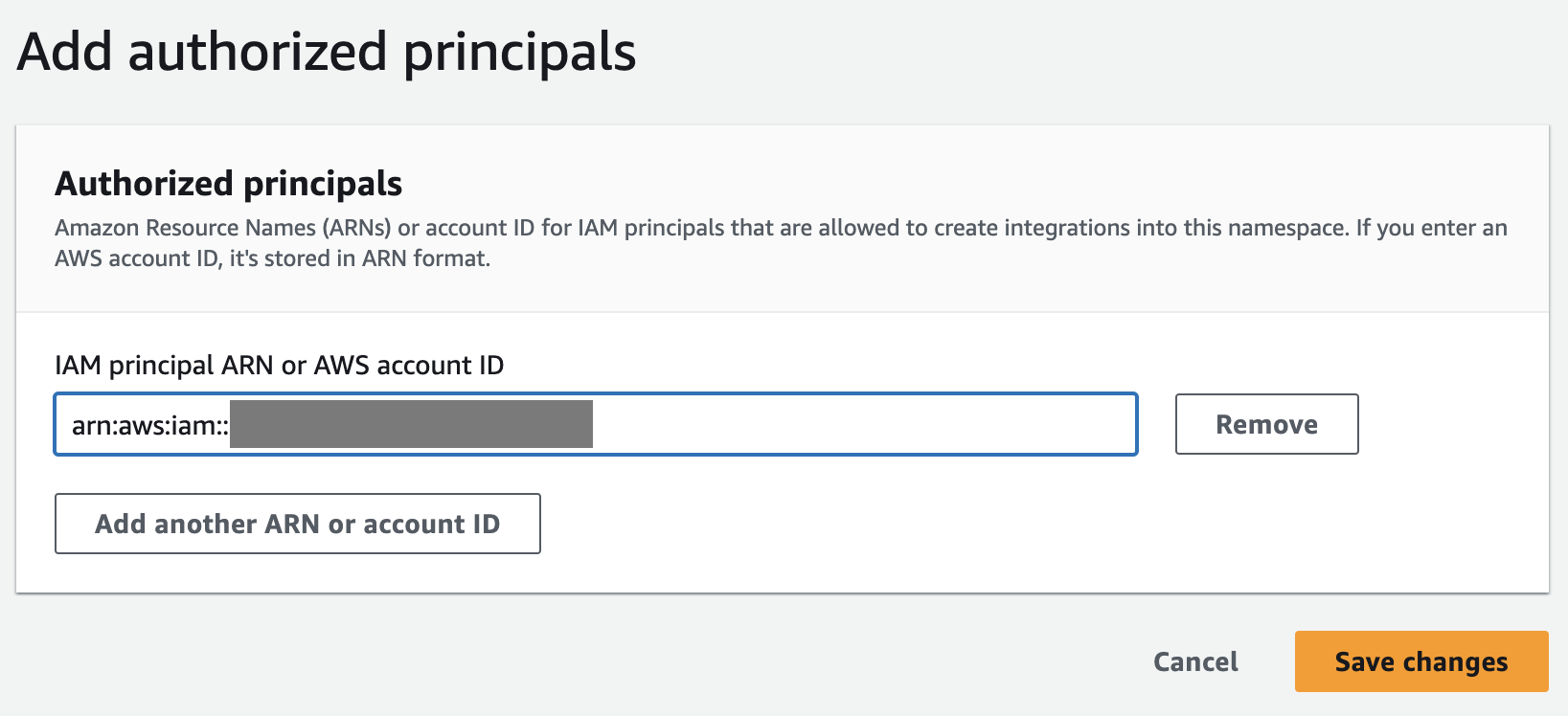
- Auf dem Ressourcenpolitik Tab, wählen Sie Fügen Sie autorisierte Auftraggeber hinzu.
Ein autorisierter Prinzipal identifiziert den Benutzer oder die Rolle, der Zero-ETL-Integrationen in das Data Warehouse erstellen kann.

- Aussichten für IAM-Prinzipal-ARN oder AWS-Konto-IDkönnen Sie entweder den ARN des AWS-Benutzers oder der AWS-Rolle oder die ID des AWS-Kontos eingeben, dem Sie Zugriff gewähren möchten, um Zero-ETL-Integrationen zu erstellen. (Eine Konto-ID wird als ARN gespeichert.)
- Auswählen
Änderungen speichern.
Nachdem der autorisierte Prinzipal konfiguriert wurde, müssen Sie der Quelldatenbank erlauben, Ihr Redshift Data Warehouse zu aktualisieren. Daher müssen Sie die Quelldatenbank als autorisierte Integrationsquelle zum Namespace hinzufügen.
- Auswählen
Fügen Sie eine autorisierte Integrationsquelle hinzu.
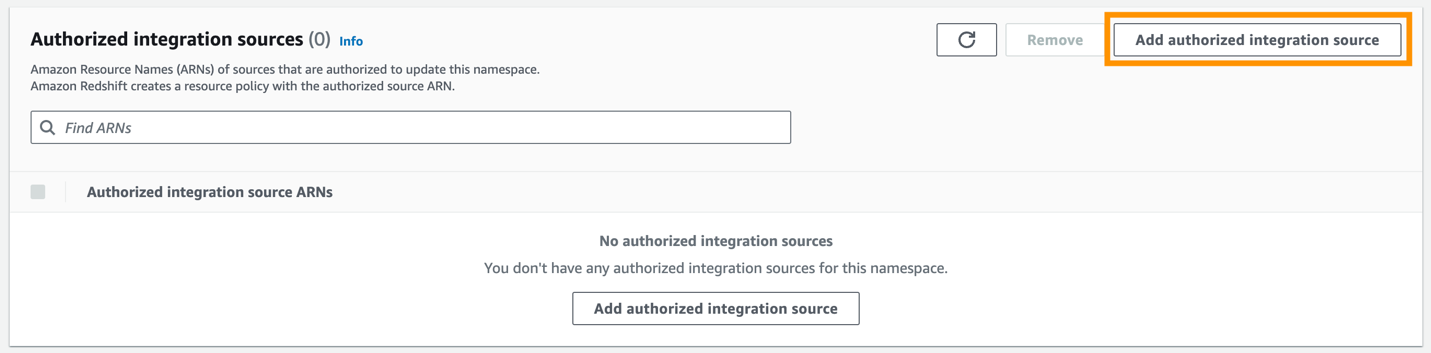
- Aussichten für Autorisierte Quelle ARNGeben Sie den ARN des Aurora PostgreSQL-Clusters ein, da dieser die Quelle der Zero-ETL-Integration ist.
Sie können den ARN des Aurora PostgreSQL-Clusters auf der Amazon RDS-Konsole abrufen Konfiguration Tab unter Amazon-Ressourcenname.
- Auswählen
Änderungen speichern.
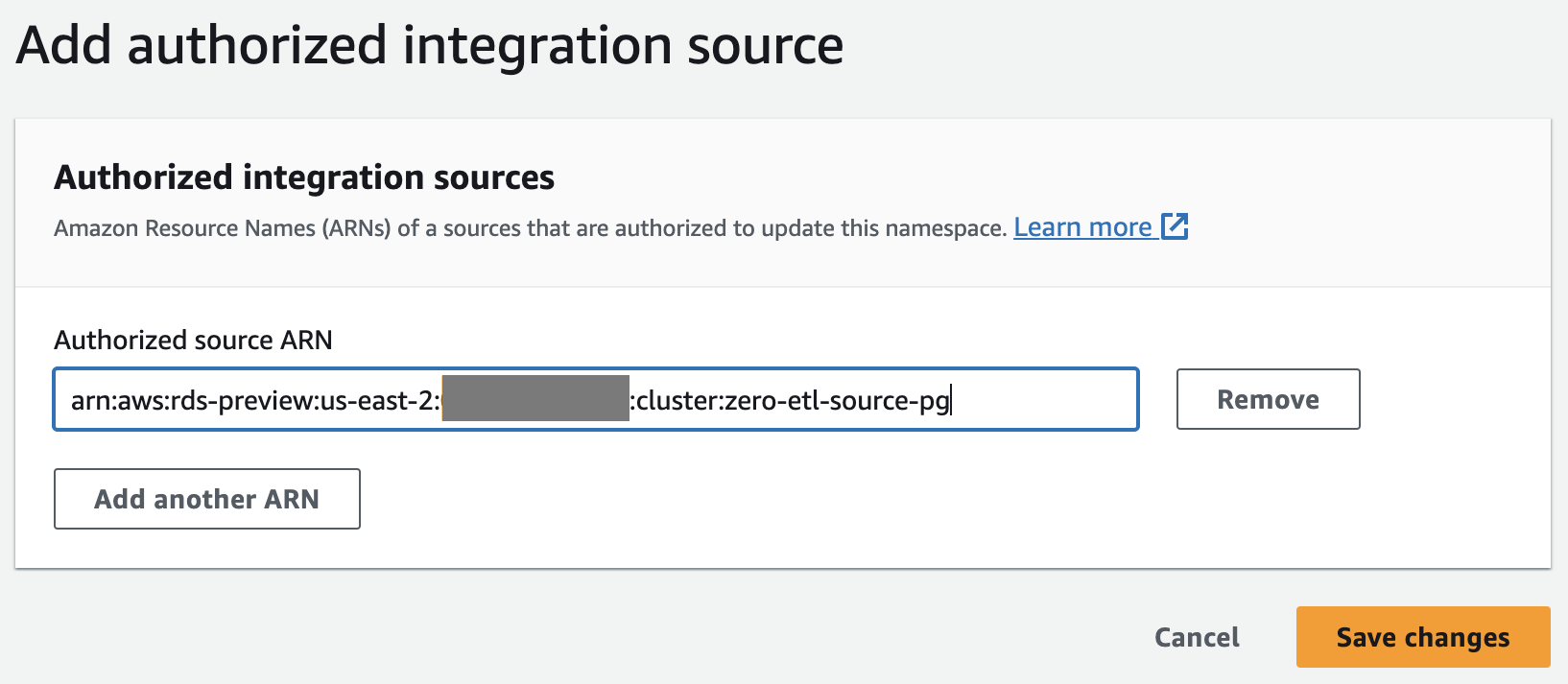
Aktualisieren Sie die Redshift Serverless-Arbeitsgruppe, um Bezeichner zu aktivieren, bei denen die Groß-/Kleinschreibung beachtet wird
Amazon Aurora PostgreSQL berücksichtigt standardmäßig die Groß-/Kleinschreibung und die Groß-/Kleinschreibung ist auf allen bereitgestellten Clustern und Redshift Serverless-Arbeitsgruppen deaktiviert. Damit die Integration erfolgreich ist, muss der Parameter für die Groß-/Kleinschreibung berücksichtigt werden enable_case_sensitive_identifier muss für das Data Warehouse aktiviert sein.
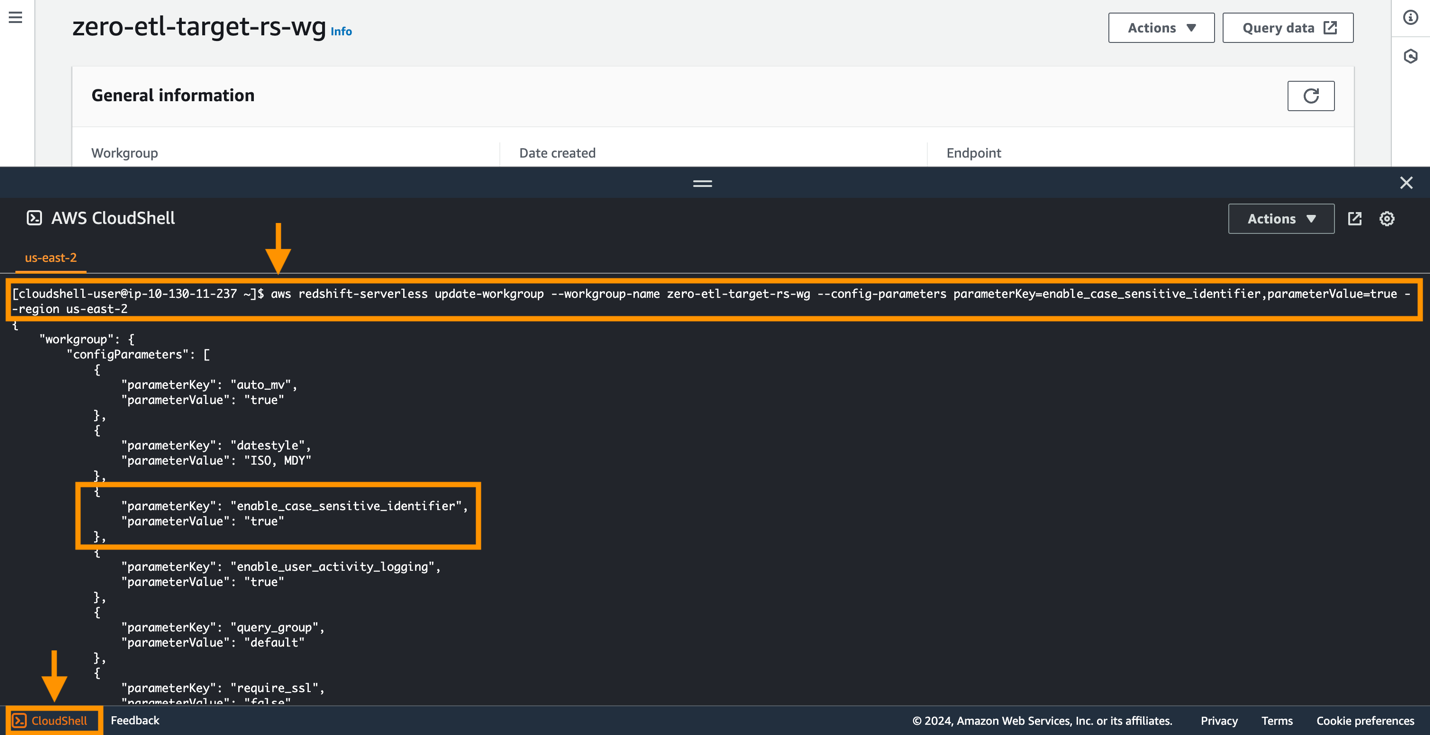
Um die zu ändern enable_case_sensitive_identifier Parameter in einer Redshift Serverless-Arbeitsgruppe müssen Sie den verwenden AWS-Befehlszeilenschnittstelle (AWS CLI), da die Amazon Redshift-Konsole derzeit das Ändern von Redshift Serverless-Parameterwerten nicht unterstützt. Führen Sie den folgenden Befehl aus, um den Parameter zu aktualisieren:
Eine einfache Möglichkeit, eine Verbindung zur AWS CLI herzustellen, ist die Verwendung von CloudShell, einer browserbasierten Shell, die Befehlszeilenzugriff auf die AWS-Ressourcen und -Tools direkt über einen Browser ermöglicht. Der folgende Screenshot zeigt, wie der Befehl in der CloudShell ausgeführt wird.
Konfigurieren Sie die erforderlichen Berechtigungen
Um eine Zero-ETL-Integration zu erstellen, muss Ihr Benutzer oder Ihre Rolle über eine angehängte Datei verfügen identitätsbasierte Politik mit dem entsprechenden AWS Identity and Access Management and (IAM)-Berechtigungen. Ein AWS-Kontoinhaber kann Konfigurieren Sie die erforderlichen Berechtigungen für Benutzer oder Rollen, die Zero-ETL-Integrationen erstellen dürfen. Mit der Beispielrichtlinie kann der zugehörige Prinzipal die folgenden Aktionen ausführen:
- Erstellen Sie Zero-ETL-Integrationen für den Aurora-DB-Quellcluster.
- Alle Zero-ETL-Integrationen anzeigen und löschen.
- Erstellen Sie eingehende Integrationen in das Ziel-Data-Warehouse. Amazon Redshift hat ein anderes ARN-Format für bereitgestellt und serverlos:
- Bereitgestellter Cluster -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Serverlos -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
Diese Berechtigung ist nicht erforderlich, wenn dasselbe Konto das Redshift-Data-Warehouse besitzt und dieses Konto ein autorisierter Prinzipal für dieses Data-Warehouse ist.
Führen Sie die folgenden Schritte aus, um die Berechtigungen zu konfigurieren:
- Wählen Sie in der IAM-Konsole Richtlinien im Navigationsbereich.
- Auswählen Richtlinie erstellen.
- Erstellen Sie mit dem folgenden JSON eine neue Richtlinie namens „rds-integrations“. Für die Amazon Aurora PostgreSQL-Vorschau werden alle ARNs und Aktionen innerhalb der Amazon RDS-Datenbankvorschauumgebung habe -preview an den Service-Namespace angehängt. Daher müssen Sie in der folgenden Richtlinie anstelle von rds verwenden
rds-preview. Beispielsweise,rds-preview:CreateIntegration.
- Hängen Sie die von Ihnen erstellte Richtlinie an Ihre IAM-Benutzer- oder Rollenberechtigungen an.
Erstellen Sie die Zero-ETL-Integration
Führen Sie die folgenden Schritte aus, um die Zero-ETL-Integration zu erstellen:
- Wählen Sie in der Amazon RDS-Konsole aus Zero-ETL-Integrationen im Navigationsbereich.
- Auswählen
Erstellen Sie eine Zero-ETL-Integration.
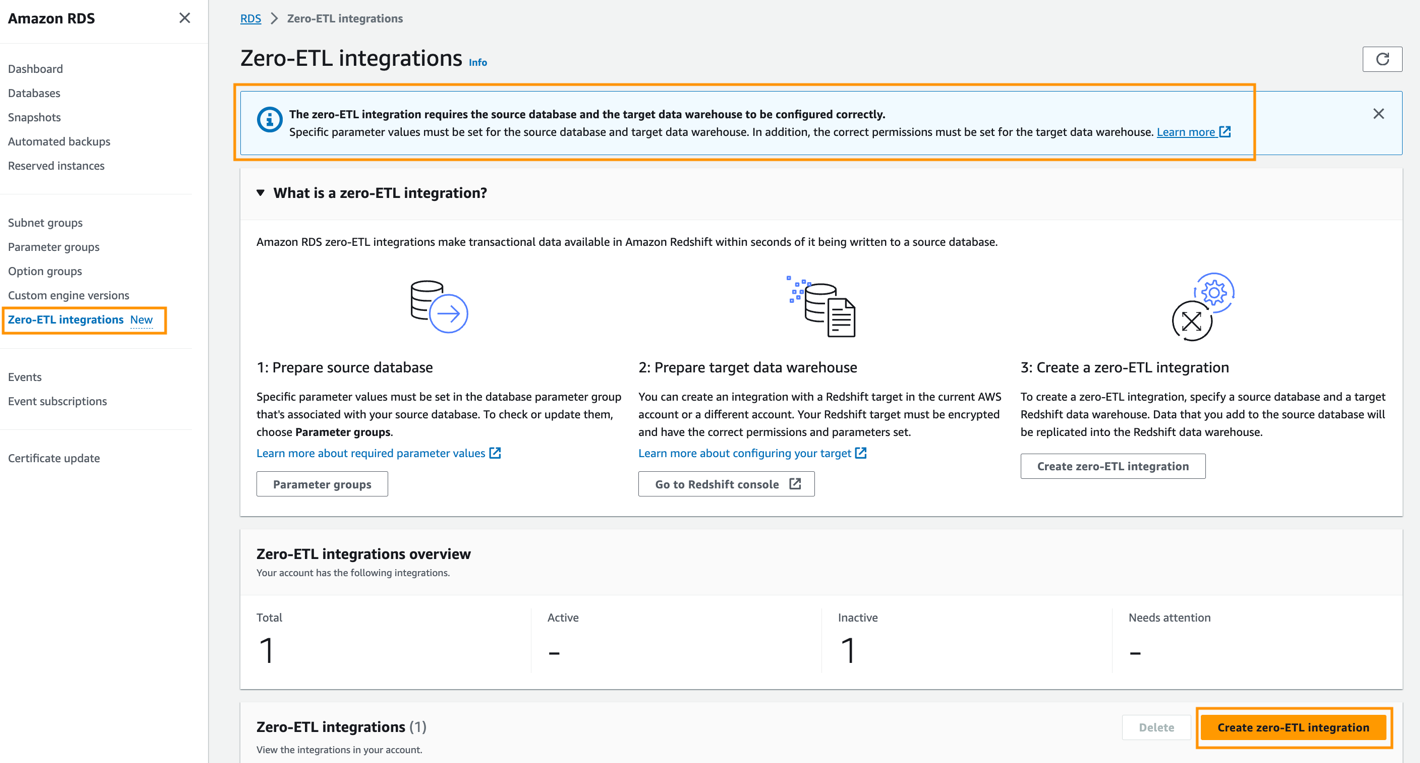
- Aussichten für IntegrationskennungGeben Sie beispielsweise einen Namen ein
zero-etl-demo. - Auswählen
Weiter.

- Aussichten für Quelldatenbank, wählen Durchsuchen Sie RDS-Datenbanken.
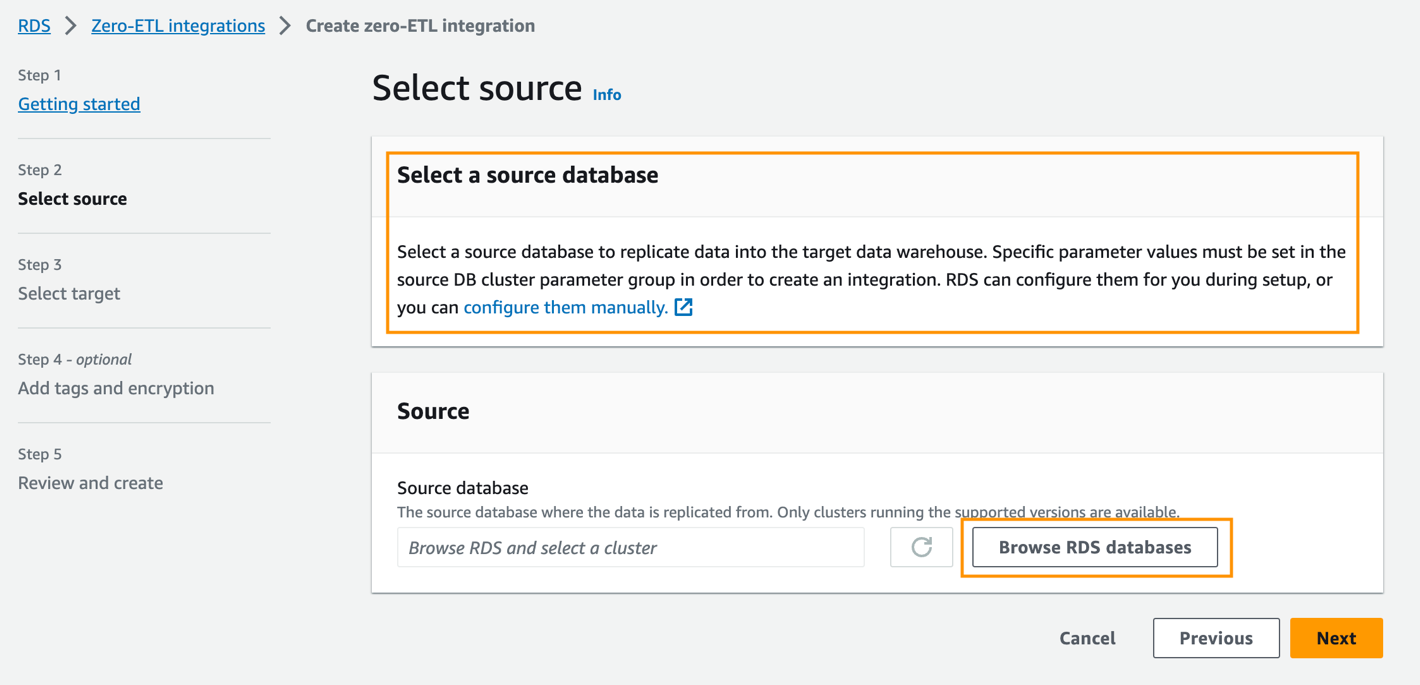
- Wählen Sie die Quelldatenbank aus
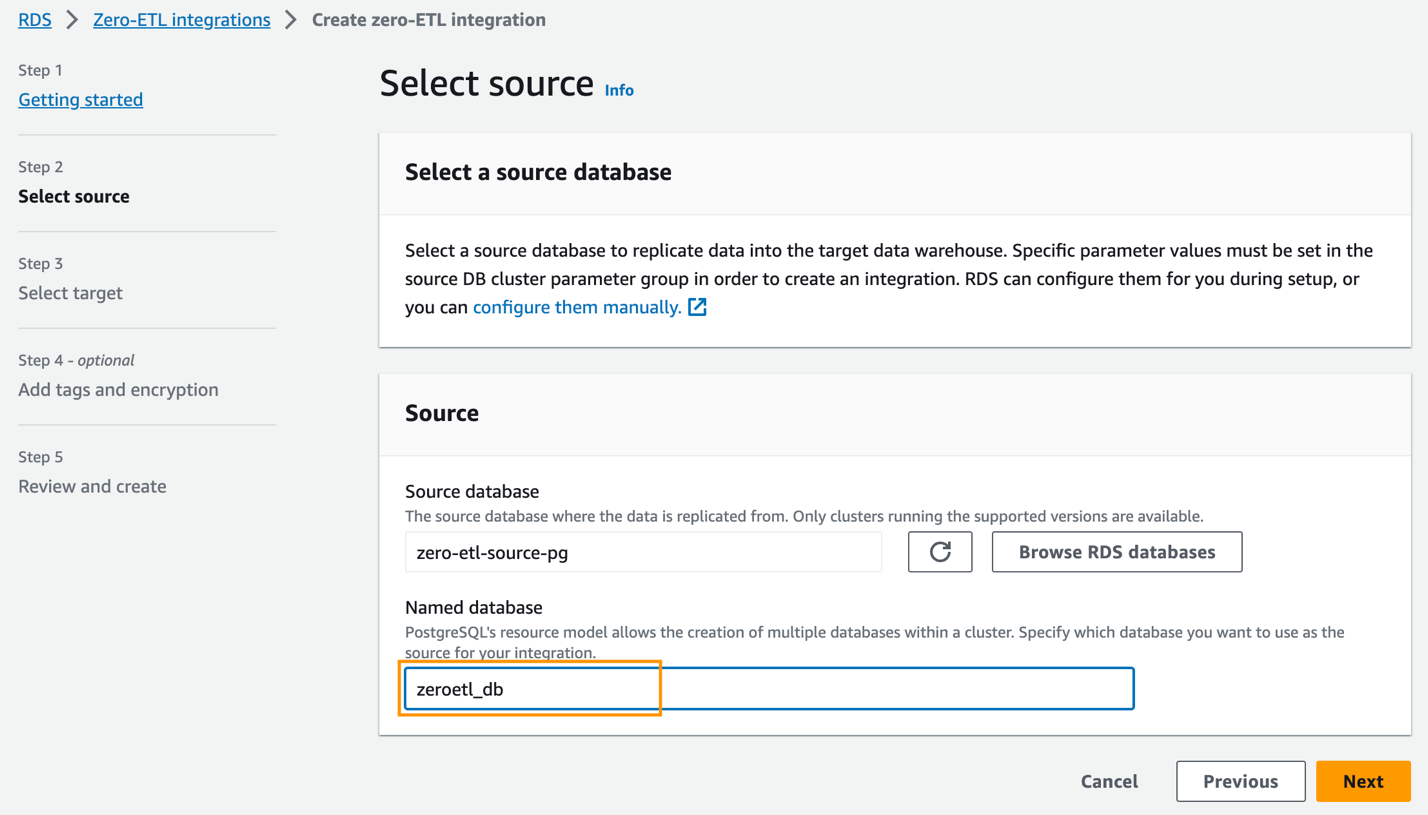
zero-etl-source-pgund wählen Sie Auswählen . - Aussichten für Benannte DatenbankGeben Sie den Namen der neuen Datenbank ein, die in Amazon Aurora PostgreSQL erstellt wurde (
zeroetl-db). - Auswählen
Weiter.
- Im ZielabschnittZ. AWS-KontoWählen Nutzen Sie das Girokonto.
- Aussichten für Amazon Redshift-Data Warehouse, wählen Durchsuchen Sie die Data Warehouses von Redshift.

Wir besprechen die Geben Sie ein anderes Konto an Option später in diesem Abschnitt.
- Wählen Sie den Redshift Serverless-Ziel-Namespace aus (
zero-etl-target-rs-ns), und wähle Auswählen .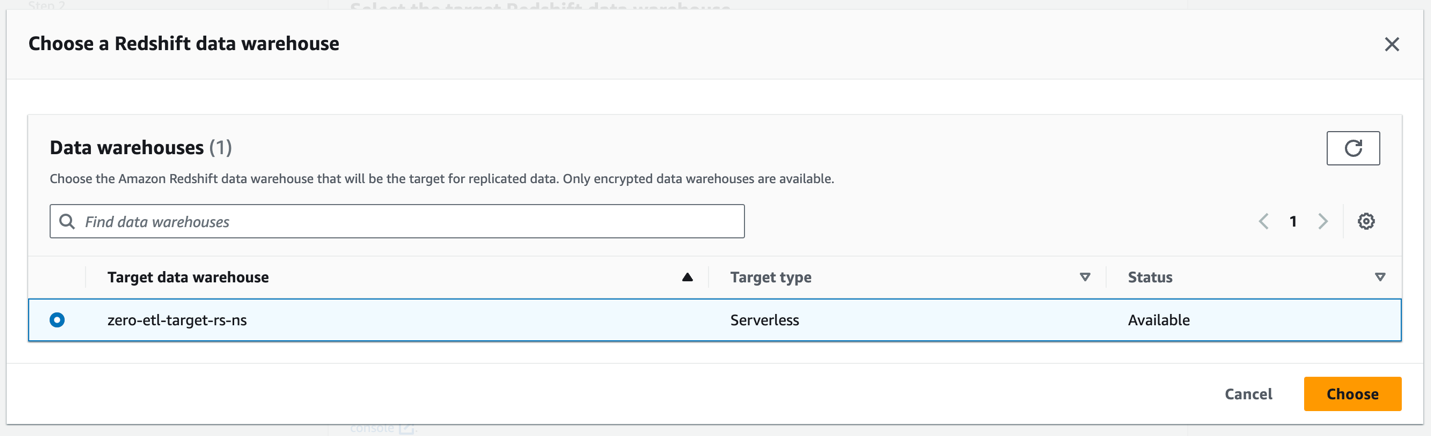
- Fügen Sie ggf. Tags und Verschlüsselung hinzu und wählen Sie Weiter.
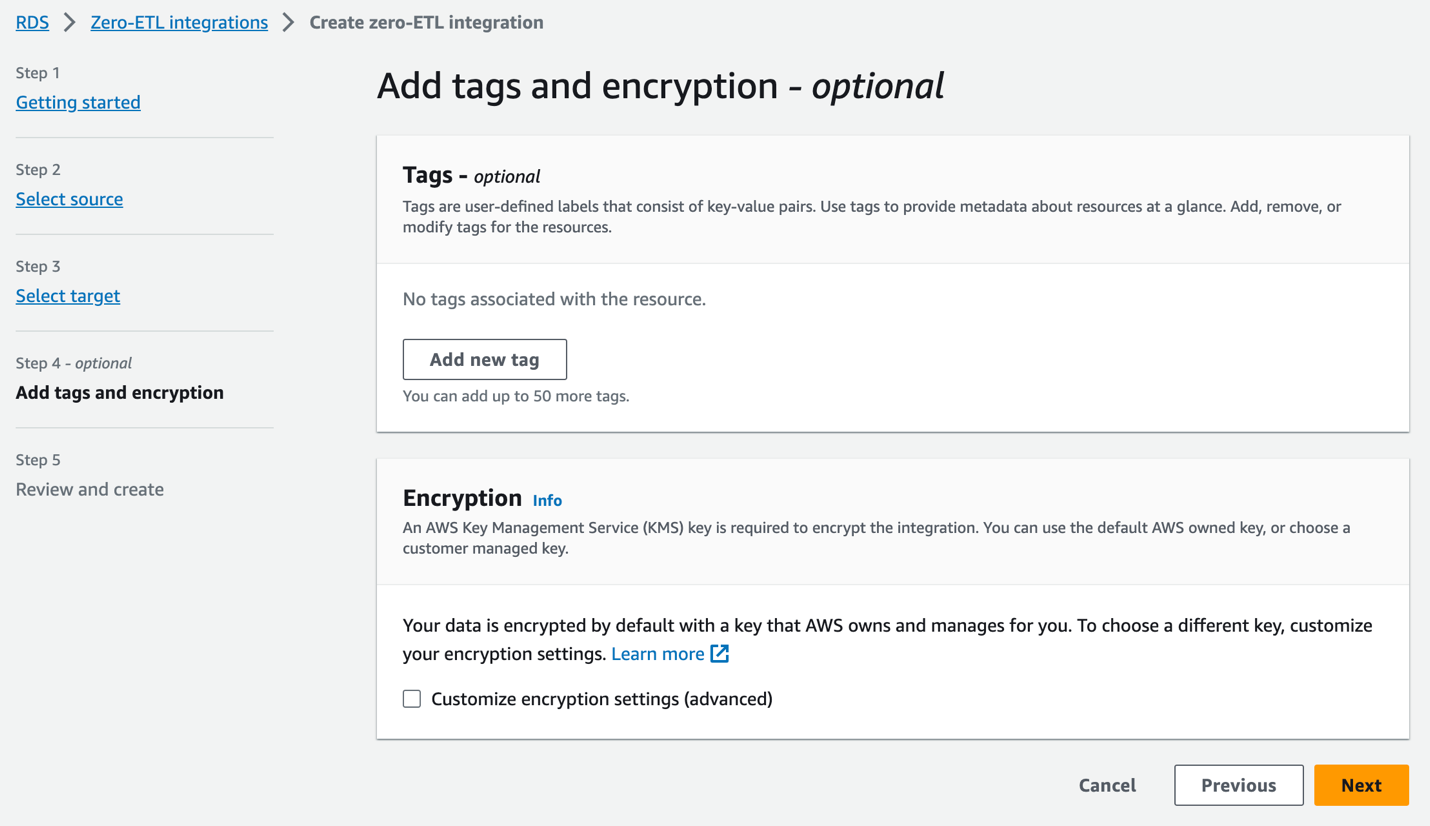
- Überprüfen Sie den Integrationsnamen, die Quelle, das Ziel und andere Einstellungen und wählen Sie aus Erstellen Sie eine Zero-ETL-Integration.
Sie können die Integration in der Amazon RDS-Konsole auswählen, um die Details anzuzeigen und den Fortschritt zu überwachen. Es dauert etwa 30 Minuten, den Status zu ändern Erstellen zu Aktives, abhängig von der Größe des bereits in der Quelle verfügbaren Datensatzes.
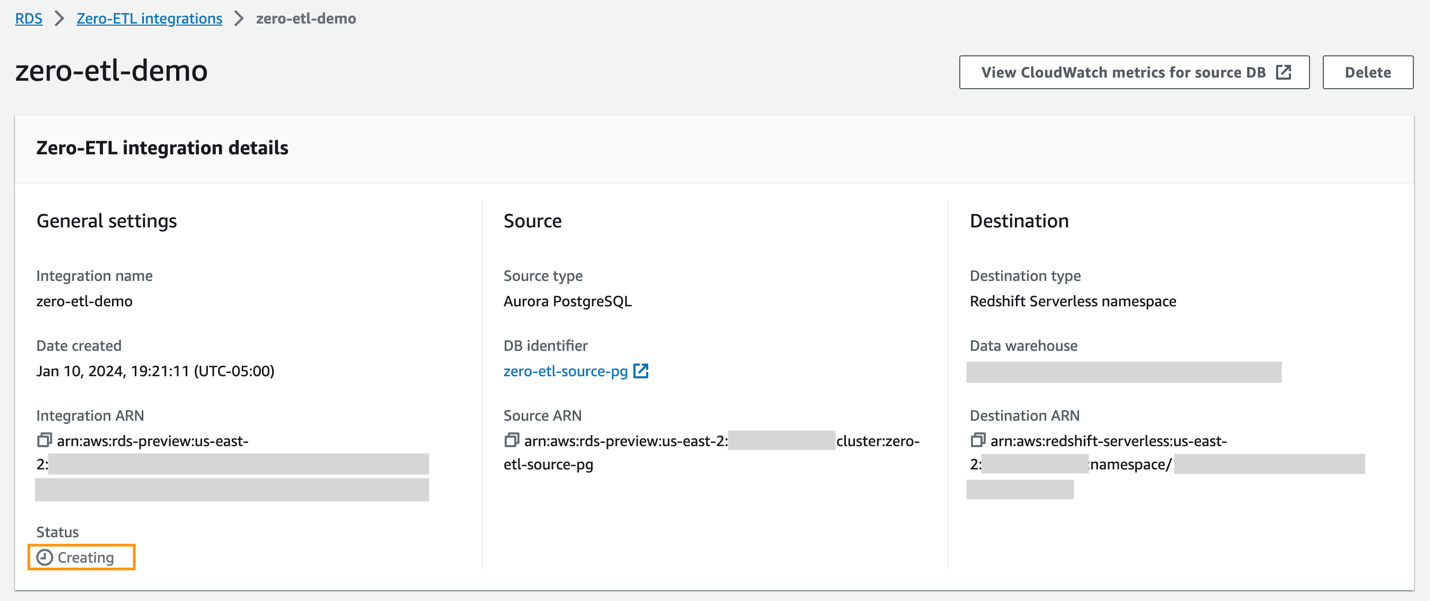
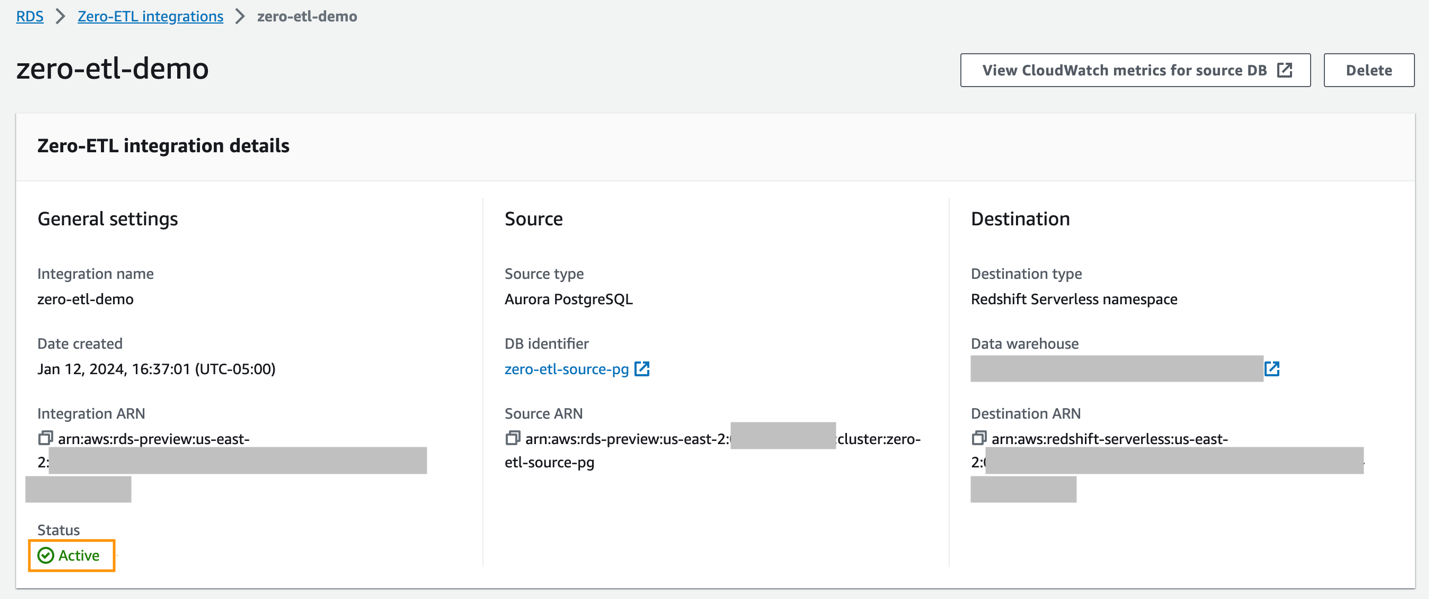
Um ein Ziel-Redshift-Data-Warehouse anzugeben, das sich in einem anderen AWS-Konto befindet, müssen Sie eine Rolle erstellen, die Benutzern im aktuellen Konto den Zugriff auf Ressourcen im Zielkonto ermöglicht. Weitere Informationen finden Sie unter Gewähren des Zugriffs für einen IAM-Benutzer in einem anderen AWS-Konto, das Sie besitzen.
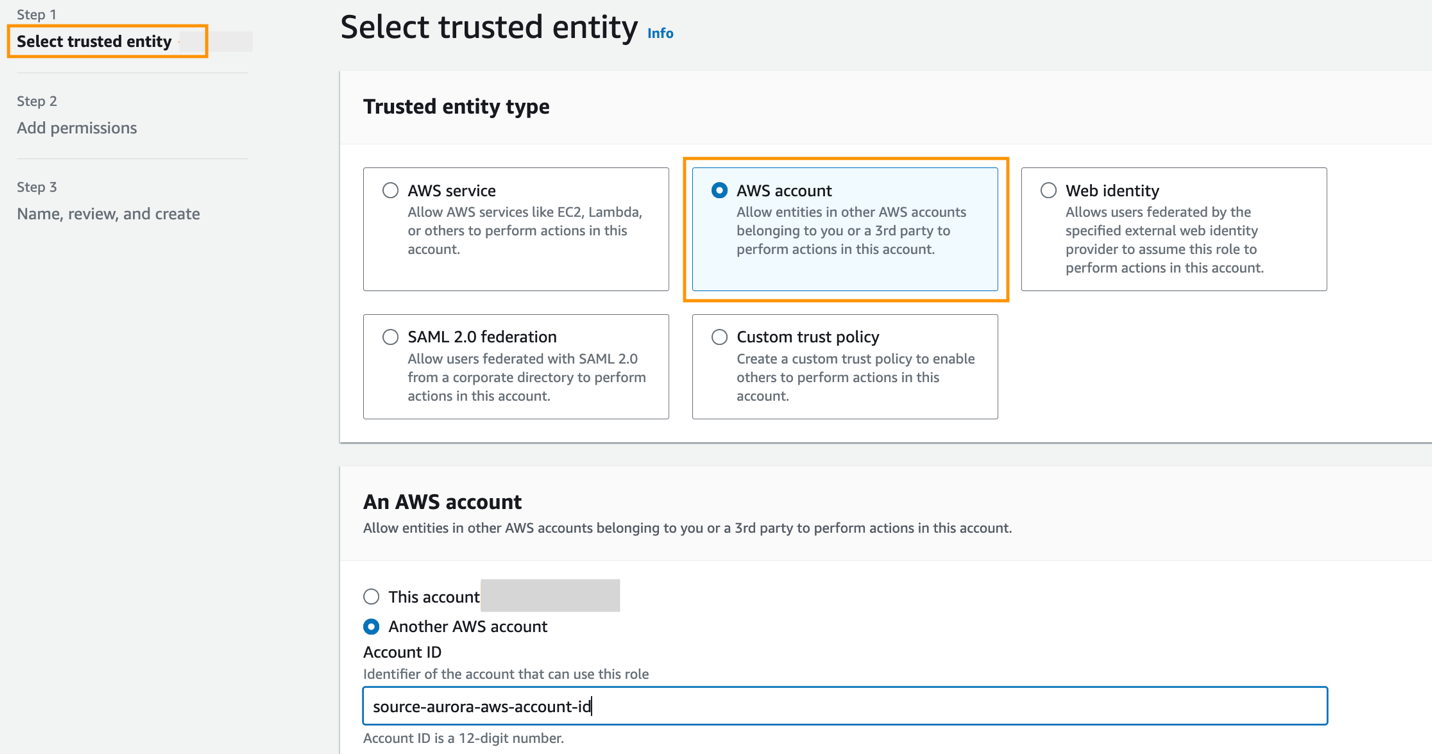
Erstellen Sie im Zielkonto eine Rolle mit den folgenden Berechtigungen:
Die Rolle muss über die folgende Vertrauensrichtlinie verfügen, die die Zielkonto-ID angibt. Sie können dies tun, indem Sie eine Rolle mit einer vertrauenswürdigen Entität als AWS-Konto-ID in einem anderen Konto erstellen.
Der folgende Screenshot veranschaulicht die Erstellung auf der IAM-Konsole.
Dann wird beim Erstellen der Zero-ETL-Integration z Geben Sie ein anderes Konto an, wählen Sie die Zielkonto-ID und den Namen der von Ihnen erstellten Rolle.
Erstellen Sie eine Datenbank aus der Integration in Amazon Redshift
Führen Sie die folgenden Schritte aus, um Ihre Datenbank zu erstellen:
- Navigieren Sie im Redshift Serverless-Dashboard zu
zero-etl-target-rs-nsNamespace. - Auswählen
Daten abfragen um den Abfrageeditor v2 zu öffnen.

- Stellen Sie eine Verbindung zum Redshift Serverless Data Warehouse her, indem Sie auswählen Verbindung herstellen.
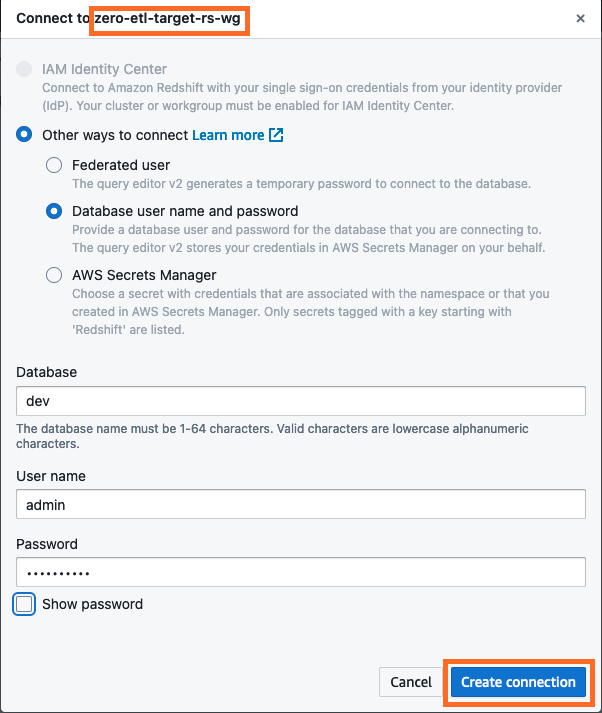
- Erhalten Sie die
integration_idvon demsvv_integrationSystemtabelle: - Verwenden Sie das
integration_idGehen Sie wie im vorherigen Schritt vor, um eine neue Datenbank aus der Integration zu erstellen. Sie müssen außerdem einen Verweis auf die benannte Datenbank innerhalb des Clusters einfügen, den Sie beim Erstellen der Integration angegeben haben.CREATE DATABASE aurora_pg_zetl FROM INTEGRATION '<result from above>' DATABASE zeroetl_db;
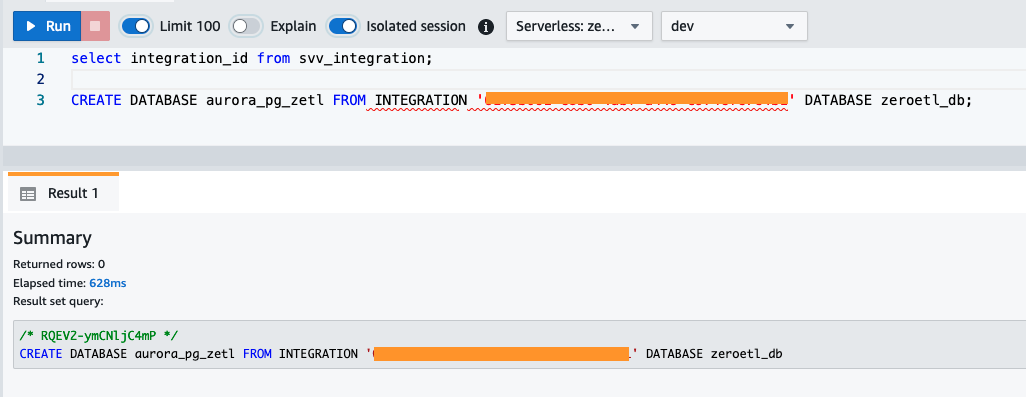
Die Integration ist nun abgeschlossen und ein vollständiger Snapshot der Quelle wird im Ziel so angezeigt, wie er ist. Laufende Änderungen werden nahezu in Echtzeit synchronisiert.
Analysieren Sie die Transaktionsdaten nahezu in Echtzeit
Jetzt können Sie mit der Analyse der Daten nahezu in Echtzeit von der Amazon Aurora PostgreSQL-Quelle zum Amazon Redshift-Ziel beginnen:
- Stellen Sie eine Verbindung zu Ihrer Aurora PostgreSQL-Quelldatenbank her. In dieser Demo verwenden wir psql So stellen Sie eine Verbindung zu Amazon Aurora PostgreSQL her:

- Erstellen Sie eine Beispieltabelle mit einem Primärschlüssel. Stellen Sie sicher, dass alle von der Quelle zum Ziel zu replizierenden Tabellen über einen Primärschlüssel verfügen. Tabellen ohne Primärschlüssel können nicht auf das Ziel repliziert werden.
- Fügen Sie Dummy-Daten in die Ländertabelle ein und überprüfen Sie, ob die Daten ordnungsgemäß geladen wurden:

Diese Beispieldaten sollten nun in Amazon Redshift repliziert werden.
Analysieren Sie die Quelldaten im Ziel
Öffnen Sie im Redshift Serverless-Dashboard den Abfrageeditor v2 und stellen Sie eine Verbindung zur Datenbank her aurora_pg_zetl Sie haben zuvor erstellt.
Führen Sie die folgende Abfrage aus, um die erfolgreiche Replikation der Quelldaten in Amazon Redshift zu validieren:
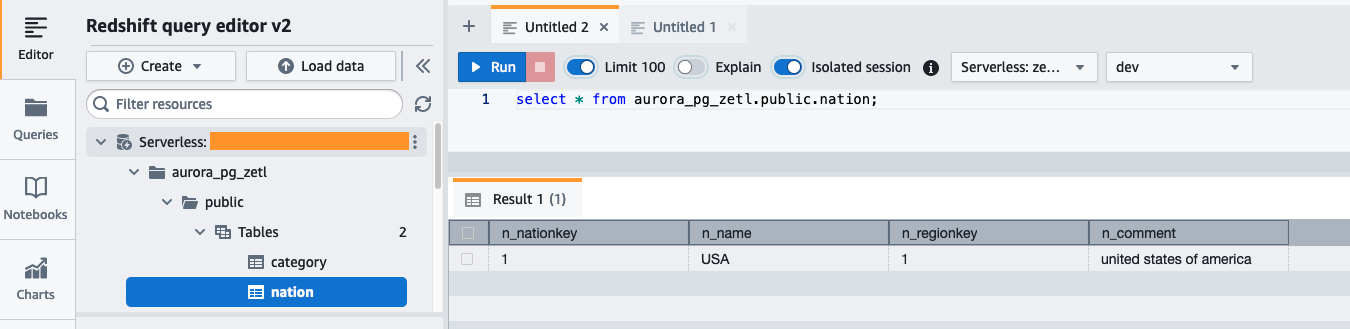
Sie können auch die folgende Abfrage verwenden, um den ersten Snapshot oder die laufende CDC-Aktivität (Change Data Capture) zu validieren:
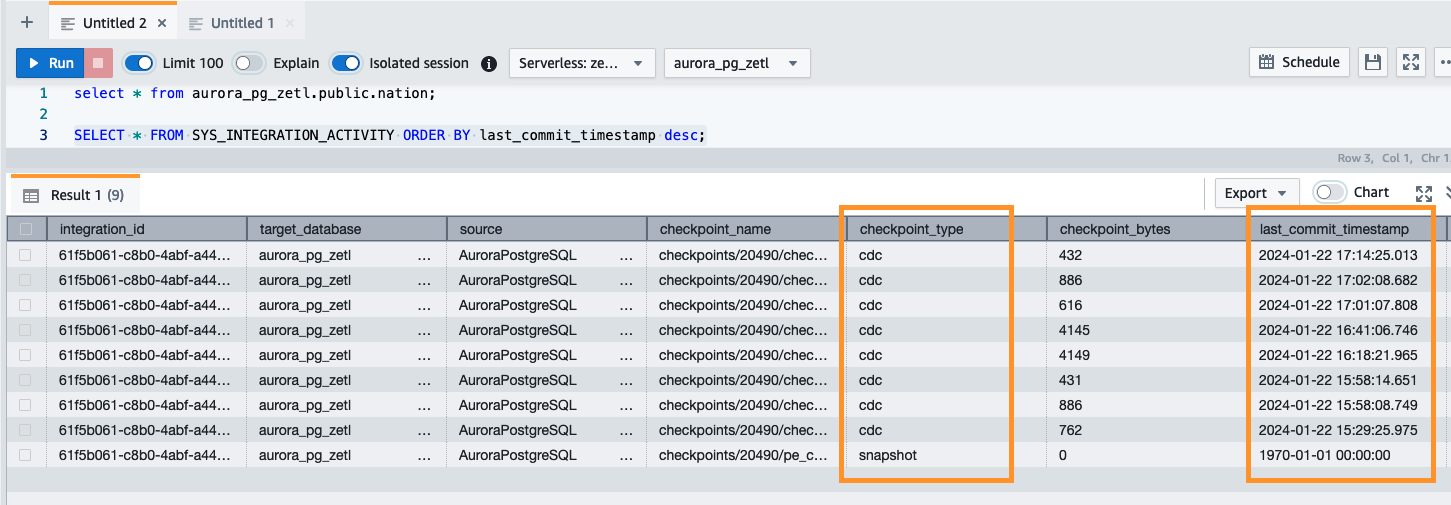
Netzwerk Performance
Es gibt mehrere Optionen, um Kennzahlen zur Leistung und zum Status der Aurora PostgreSQL Zero-ETL-Integration mit Amazon Redshift zu erhalten.
Wenn Sie zur Amazon Redshift-Konsole navigieren, können Sie auswählen Zero-ETL-Integrationen im Navigationsbereich. Sie können die gewünschte Zero-ETL-Integration auswählen und anzeigen Amazon CloudWatch Metriken im Zusammenhang mit der Integration. Diese Metriken sind auch direkt in CloudWatch verfügbar.
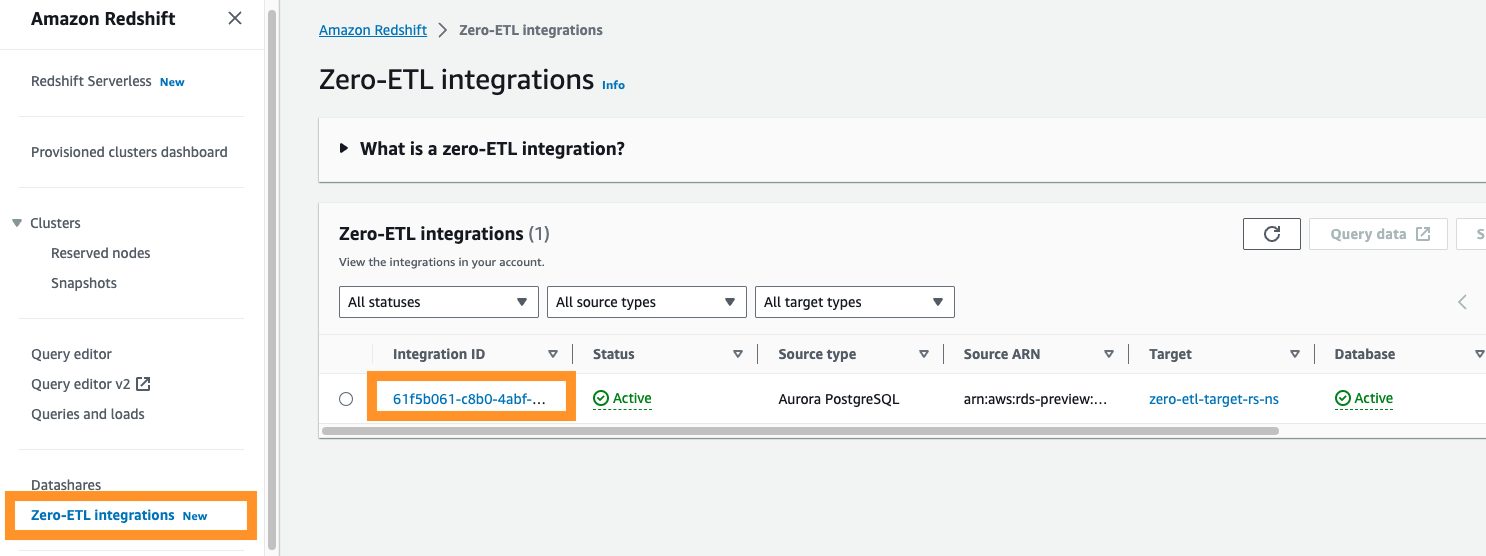
Für jede Integration stehen zwei Registerkarten mit Informationen zur Verfügung:
- Integrationsmetriken – Zeigt Metriken wie die Anzahl der erfolgreich replizierten Tabellen und Verzögerungsdetails an
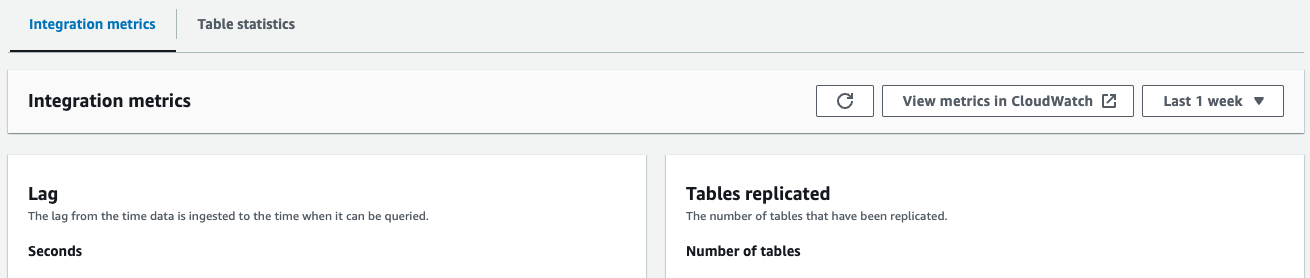
- Tabellenstatistik – Zeigt Details zu jeder Tabelle an, die von Amazon Aurora PostgreSQL nach Amazon Redshift repliziert wurde
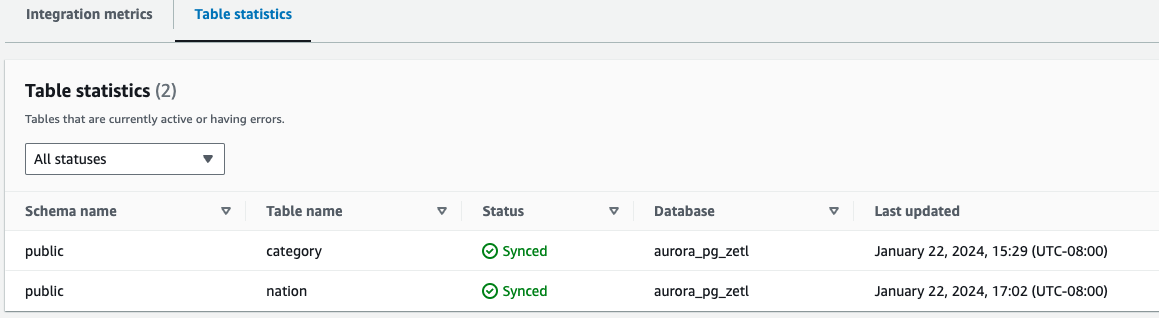
Zusätzlich zu den CloudWatch-Metriken können Sie Folgendes abfragen Systemansichten, die Informationen zu den Integrationen liefern:
Aufräumen
Wenn Sie eine Zero-ETL-Integration löschen, werden Ihre Transaktionsdaten nicht aus Aurora oder Amazon Redshift gelöscht, Aurora sendet jedoch keine neuen Daten an Amazon Redshift.
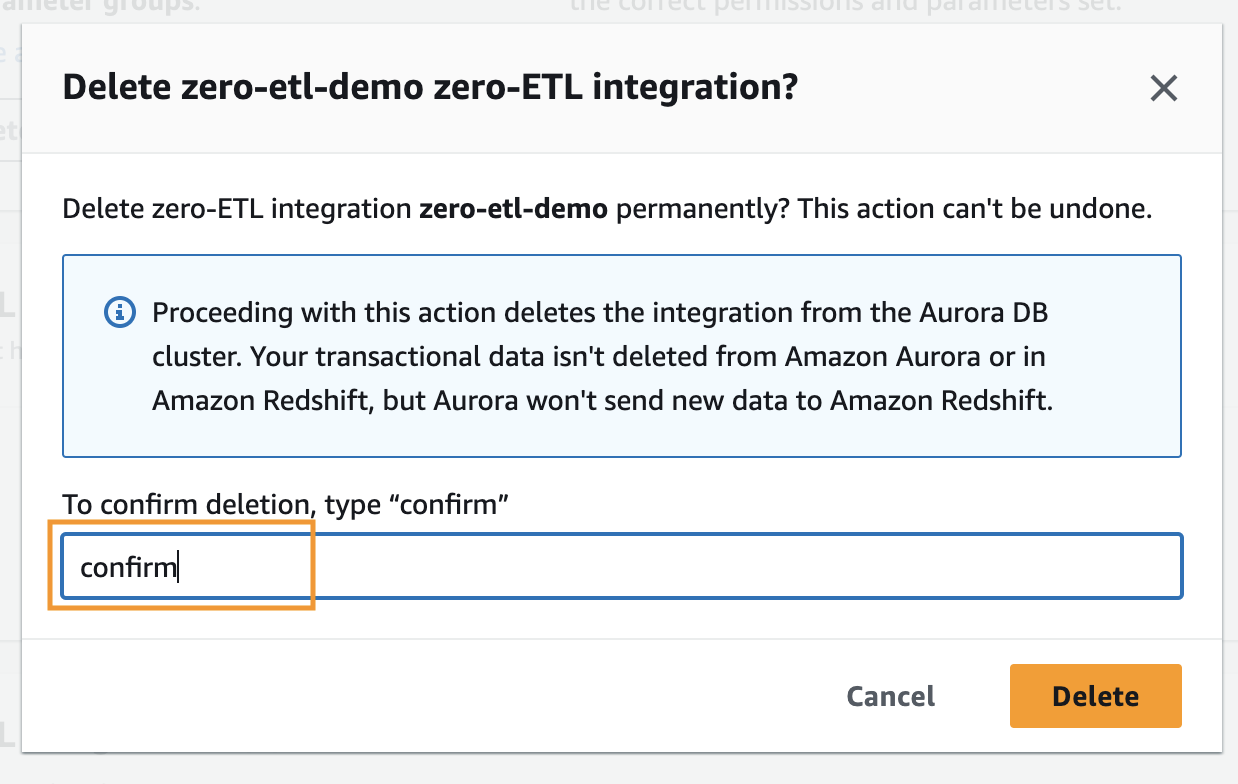
Um eine Zero-ETL-Integration zu löschen, führen Sie die folgenden Schritte aus:
- Wählen Sie in der Amazon RDS-Konsole aus Zero-ETL-Integrationen im Navigationsbereich.
- Wählen Sie die Zero-ETL-Integration aus, die Sie löschen möchten, und wählen Sie aus Löschen.

- Um den Löschvorgang zu bestätigen, geben Sie „Bestätigen“ ein und wählen Sie Löschen.
Zusammenfassung
In diesem Beitrag haben wir erklärt, wie Sie die Zero-ETL-Integration von Amazon Aurora PostgreSQL zu Amazon Redshift einrichten können, eine Funktion, die den Aufwand für die Pflege von Datenpipelines reduziert und nahezu Echtzeitanalysen von Transaktions- und Betriebsdaten ermöglicht.
Weitere Informationen zur Zero-ETL-Integration finden Sie unter Arbeiten mit Aurora Zero-ETL-Integrationen mit Amazon Redshift und Einschränkungen.
Über die Autoren
 Raks Khare ist Analytics Specialist Solutions Architect bei AWS mit Sitz in Pennsylvania. Er unterstützt Kunden bei der Entwicklung von Datenanalyselösungen im großen Maßstab auf der AWS-Plattform.
Raks Khare ist Analytics Specialist Solutions Architect bei AWS mit Sitz in Pennsylvania. Er unterstützt Kunden bei der Entwicklung von Datenanalyselösungen im großen Maßstab auf der AWS-Plattform.
 Juan Luis Polo Garzon ist Associate Specialist Solutions Architect bei AWS, spezialisiert auf Analyse-Workloads. Er verfügt über Erfahrung in der Unterstützung von Kunden beim Entwurf, Aufbau und der Modernisierung ihrer cloudbasierten Analyselösungen. Außerhalb der Arbeit reist er gerne, geht gerne in die Natur, wandert und besucht Live-Musikveranstaltungen.
Juan Luis Polo Garzon ist Associate Specialist Solutions Architect bei AWS, spezialisiert auf Analyse-Workloads. Er verfügt über Erfahrung in der Unterstützung von Kunden beim Entwurf, Aufbau und der Modernisierung ihrer cloudbasierten Analyselösungen. Außerhalb der Arbeit reist er gerne, geht gerne in die Natur, wandert und besucht Live-Musikveranstaltungen.
 Sushmita Barthakur ist Senior Solutions Architect bei Amazon Web Services und unterstützt Unternehmenskunden bei der Architektur ihrer Workloads auf AWS. Mit einem fundierten Hintergrund in den Bereichen Datenanalyse und Datenmanagement verfügt sie über umfangreiche Erfahrung in der Unterstützung von Kunden bei der Konzeption und dem Aufbau von Business Intelligence- und Analyselösungen, sowohl vor Ort als auch in der Cloud. Sushmita lebt in Tampa, Florida und reist gerne, liest und spielt gerne Tennis.
Sushmita Barthakur ist Senior Solutions Architect bei Amazon Web Services und unterstützt Unternehmenskunden bei der Architektur ihrer Workloads auf AWS. Mit einem fundierten Hintergrund in den Bereichen Datenanalyse und Datenmanagement verfügt sie über umfangreiche Erfahrung in der Unterstützung von Kunden bei der Konzeption und dem Aufbau von Business Intelligence- und Analyselösungen, sowohl vor Ort als auch in der Cloud. Sushmita lebt in Tampa, Florida und reist gerne, liest und spielt gerne Tennis.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/achieve-near-real-time-operational-analytics-using-amazon-aurora-postgresql-zero-etl-integration-with-amazon-redshift/

