Die Erschließung präziser und aufschlussreicher Antworten aus riesigen Textmengen ist eine spannende Fähigkeit, die durch große Sprachmodelle (LLMs) ermöglicht wird. Beim Erstellen von LLM-Anwendungen ist es häufig erforderlich, externe Datenquellen zu verbinden und abzufragen, um dem Modell relevanten Kontext bereitzustellen. Ein beliebter Ansatz ist die Verwendung von Retrieval Augmented Generation (RAG), um Q&A-Systeme zu erstellen, die komplexe Informationen erfassen und natürliche Antworten auf Anfragen liefern. RAG ermöglicht es Modellen, auf umfangreiche Wissensdatenbanken zuzugreifen und menschenähnliche Dialoge für Anwendungen wie Chatbots und Unternehmenssuchassistenten bereitzustellen.
In diesem Beitrag untersuchen wir, wie wir die Kraft von nutzen können LamaIndex, Lama 2-70B-Chat und LangChain um leistungsstarke Q&A-Anwendungen zu erstellen. Mit diesen hochmodernen Technologien können Sie Textkorpora aufnehmen, kritisches Wissen indizieren und Texte generieren, die die Fragen der Benutzer präzise und klar beantworten.
Lama 2-70B-Chat
Llama 2-70B-Chat ist ein leistungsstarkes LLM, das mit führenden Modellen konkurriert. Es ist auf zwei Billionen Text-Tokens vorab trainiert und von Meta für die Chat-Unterstützung von Benutzern vorgesehen. Die Vortrainingsdaten stammen aus öffentlich verfügbaren Daten und enden im September 2022, die Feinabstimmungsdaten enden im Juli 2023. Weitere Einzelheiten zum Trainingsprozess des Modells, zu Sicherheitsüberlegungen, Erkenntnissen und beabsichtigten Verwendungszwecken finden Sie im Dokument Lama 2: Open Foundation und fein abgestimmte Chat-Modelle. Llama 2-Modelle sind auf verfügbar Amazon SageMaker-JumpStart für eine schnelle und unkomplizierte Bereitstellung.
LamaIndex
LamaIndex ist ein Datenframework, das die Erstellung von LLM-Anwendungen ermöglicht. Es bietet Tools, die Datenkonnektoren bieten, um Ihre vorhandenen Daten mit verschiedenen Quellen und Formaten (PDFs, Dokumente, APIs, SQL und mehr) aufzunehmen. Ganz gleich, ob Sie Daten in Datenbanken oder in PDFs gespeichert haben, mit LlamaIndex können Sie diese Daten ganz einfach für LLMs nutzen. Wie wir in diesem Beitrag zeigen, ermöglichen LlamaIndex-APIs einen mühelosen Datenzugriff und ermöglichen Ihnen die Erstellung leistungsstarker benutzerdefinierter LLM-Anwendungen und -Workflows.
Wenn Sie mit LLMs experimentieren und bauen, sind Sie wahrscheinlich mit LangChain vertraut, das ein robustes Framework bietet, das die Entwicklung und Bereitstellung von LLM-basierten Anwendungen vereinfacht. Ähnlich wie LangChain bietet LlamaIndex eine Reihe von Tools, darunter Datenkonnektoren, Datenindizes, Engines und Datenagenten, sowie Anwendungsintegrationen wie Tools und Observability, Tracing und Evaluation. LlamaIndex konzentriert sich darauf, die Lücke zwischen den Daten und leistungsstarken LLMs zu schließen und Datenaufgaben mit benutzerfreundlichen Funktionen zu rationalisieren. LlamaIndex wurde speziell für die Erstellung von Such- und Abrufanwendungen wie RAG entwickelt und optimiert, da es eine einfache Schnittstelle zum Abfragen von LLMs und zum Abrufen relevanter Dokumente bietet.
Lösungsüberblick
In diesem Beitrag zeigen wir, wie man mit LlamaIndex und einem LLM eine RAG-basierte Anwendung erstellt. Das folgende Diagramm zeigt die schrittweise Architektur dieser Lösung, die in den folgenden Abschnitten beschrieben wird.
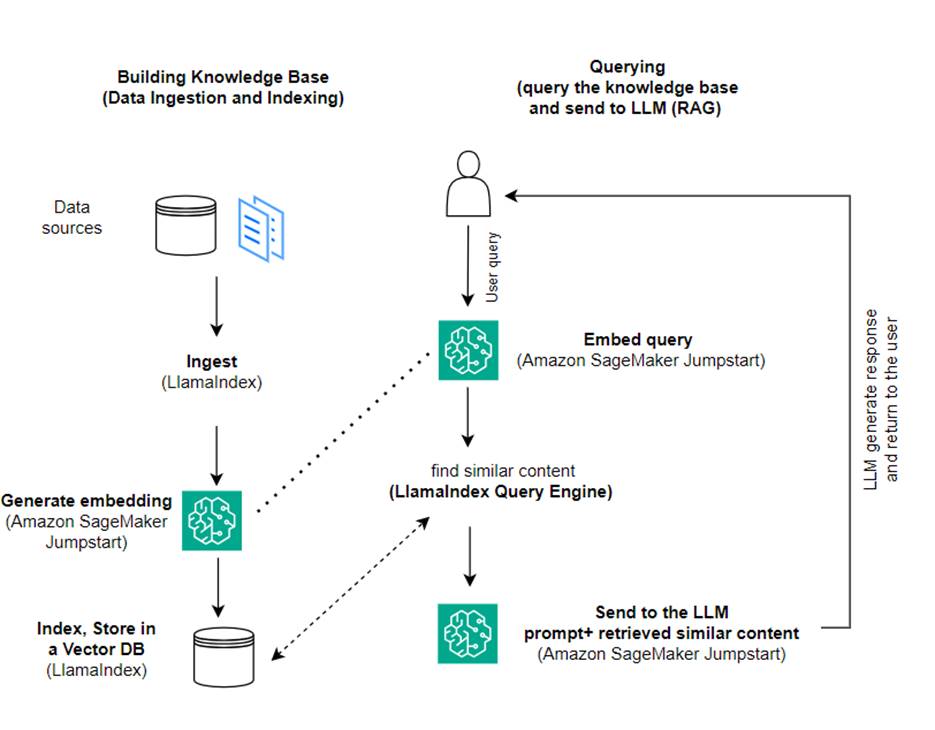
RAG kombiniert den Informationsabruf mit der Erzeugung natürlicher Sprache, um aufschlussreichere Antworten zu erhalten. Wenn RAG dazu aufgefordert wird, durchsucht es zunächst Textkorpora, um die relevantesten Beispiele für die Eingabe abzurufen. Während der Antwortgenerierung berücksichtigt das Modell diese Beispiele, um seine Fähigkeiten zu erweitern. Durch die Einbeziehung relevanter abgerufener Passagen sind RAG-Antworten tendenziell sachlicher, kohärenter und im Einklang mit dem Kontext im Vergleich zu grundlegenden generativen Modellen. Dieses Retrieval-Generate-Framework nutzt die Stärken von Retrieval und Generierung und hilft dabei, Probleme wie Wiederholungen und fehlenden Kontext anzugehen, die bei rein autoregressiven Gesprächsmodellen auftreten können. RAG stellt einen effektiven Ansatz zum Aufbau von Konversationsagenten und KI-Assistenten mit kontextualisierten, qualitativ hochwertigen Antworten vor.
Der Aufbau der Lösung besteht aus den folgenden Schritten:
- Einrichten Amazon SageMaker-Studio als Entwicklungsumgebung und installieren Sie die erforderlichen Abhängigkeiten.
- Stellen Sie ein Einbettungsmodell über den Amazon SageMaker JumpStart-Hub bereit.
- Laden Sie Pressemitteilungen herunter, um sie als unsere externe Wissensdatenbank zu nutzen.
- Erstellen Sie einen Index aus den Pressemitteilungen, um sie abfragen und als zusätzlichen Kontext zur Eingabeaufforderung hinzufügen zu können.
- Fragen Sie die Wissensdatenbank ab.
- Erstellen Sie eine Q&A-Anwendung mit LlamaIndex- und LangChain-Agenten.
Der gesamte Code in diesem Beitrag ist im verfügbar GitHub Repo.
Voraussetzungen:
Für dieses Beispiel benötigen Sie ein AWS-Konto mit einer SageMaker-Domäne und entsprechendem AWS Identity and Access Management and (IAM)-Berechtigungen. Anweisungen zur Kontoeinrichtung finden Sie unter Erstellen Sie ein AWS-Konto. Wenn Sie noch keine SageMaker-Domäne haben, lesen Sie hier Amazon SageMaker-Domäne Übersicht, um eine zu erstellen. In diesem Beitrag verwenden wir die AmazonSageMakerFullAccess Rolle. Es wird nicht empfohlen, diese Anmeldeinformationen in einer Produktionsumgebung zu verwenden. Stattdessen sollten Sie eine Rolle mit den geringsten Berechtigungen erstellen und verwenden. Sie können auch erkunden, wie Sie es verwenden können Amazon SageMaker-Rollenmanager zum Erstellen und Verwalten personenbasierter IAM-Rollen für allgemeine maschinelle Lernanforderungen direkt über die SageMaker-Konsole.
Darüber hinaus benötigen Sie Zugriff auf mindestens die folgenden Instanzgrößen:
- ml.g5.2xgroß für die Endpunktnutzung bei der Bereitstellung Umarmendes Gesicht GPT-J Texteinbettungsmodell
- ml.g5.48xgroß für die Endpunktnutzung bei der Bereitstellung des Endpunkts des Llama 2-Chat-Modells
Informationen zum Erhöhen Ihres Kontingents finden Sie unter Beantragung einer Kontingenterhöhung.
Stellen Sie ein GPT-J-Einbettungsmodell mit SageMaker JumpStart bereit
Dieser Abschnitt bietet Ihnen zwei Optionen für die Bereitstellung von SageMaker JumpStart-Modellen. Sie können eine codebasierte Bereitstellung mithilfe des bereitgestellten Codes verwenden oder die Benutzeroberfläche (UI) von SageMaker JumpStart verwenden.
Bereitstellung mit dem SageMaker Python SDK
Sie können das SageMaker Python SDK verwenden, um die LLMs bereitzustellen, wie im gezeigt Code im Repository verfügbar. Führen Sie die folgenden Schritte aus:
- Legen Sie die Instanzgröße fest, die für die Bereitstellung des Einbettungsmodells verwendet werden soll
instance_type = "ml.g5.2xlarge" - Suchen Sie die ID des Modells, das für Einbettungen verwendet werden soll. In SageMaker JumpStart wird es als identifiziert
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Rufen Sie den vorab trainierten Modellcontainer ab und stellen Sie ihn zur Inferenz bereit.
SageMaker gibt den Namen des Modellendpunkts und die folgende Meldung zurück, wenn das Einbettungsmodell erfolgreich bereitgestellt wurde:
Bereitstellen mit SageMaker JumpStart in SageMaker Studio
Um das Modell mit SageMaker JumpStart in Studio bereitzustellen, führen Sie die folgenden Schritte aus:
- Wählen Sie in der SageMaker Studio-Konsole im Navigationsbereich JumpStart aus.

- Suchen Sie nach dem Modell GPT-J 6B Embedding FP16 und wählen Sie es aus.
- Wählen Sie „Bereitstellen“ und passen Sie die Bereitstellungskonfiguration an.

- Für dieses Beispiel benötigen wir eine ml.g5.2xlarge-Instanz, die die von SageMaker JumpStart vorgeschlagene Standardinstanz ist.
- Wählen Sie erneut „Bereitstellen“, um den Endpunkt zu erstellen.
Es dauert etwa 5–10 Minuten, bis der Endpunkt betriebsbereit ist.

Nachdem Sie das Einbettungsmodell bereitgestellt haben, müssen Sie zur Verwendung der LangChain-Integration mit SageMaker-APIs eine Funktion erstellen, um Eingaben (Rohtext) zu verarbeiten und diese mithilfe des Modells in Einbettungen umzuwandeln. Sie tun dies, indem Sie eine Klasse namens erstellen ContentHandler, das einen JSON-Wert der Eingabedaten entgegennimmt und einen JSON-Wert der Texteinbettungen zurückgibt: class ContentHandler(EmbeddingsContentHandler).
Übergeben Sie den Namen des Modellendpunkts an ContentHandler Funktion zum Konvertieren des Textes und Zurückgeben von Einbettungen:
Sie können den Endpunktnamen entweder in der Ausgabe des SDK oder in den Bereitstellungsdetails in der SageMaker JumpStart-Benutzeroberfläche finden.
Sie können das testen ContentHandler Funktion und Endpunkt funktionieren wie erwartet, indem Sie Rohtext eingeben und ausführen embeddings.embed_query(text) Funktion. Sie können das bereitgestellte Beispiel verwenden text = "Hi! It's time for the beach" oder versuchen Sie es mit Ihrem eigenen Text.
Stellen Sie Llama 2-Chat mit SageMaker JumpStart bereit und testen Sie es
Jetzt können Sie das Modell bereitstellen, das interaktive Gespräche mit Ihren Benutzern führen kann. In diesem Fall wählen wir eines der Llama 2-Chat-Modelle, das über identifiziert wird
Das Modell muss mithilfe von auf einem Echtzeit-Endpunkt bereitgestellt werden predictor = my_model.deploy(). SageMaker gibt den Endpunktnamen des Modells zurück, den Sie für verwenden können endpoint_name Variable, auf die später verwiesen werden soll.
Sie definieren a print_dialogue Funktion zum Senden von Eingaben an das Chat-Modell und zum Empfangen der Ausgabeantwort. Die Nutzlast umfasst Hyperparameter für das Modell, einschließlich der folgenden:
- max_new_tokens – Bezieht sich auf die maximale Anzahl an Token, die das Modell in seinen Ausgaben generieren kann.
- top_p – Bezieht sich auf die kumulative Wahrscheinlichkeit der Token, die das Modell bei der Generierung seiner Ausgaben behalten kann
- Temperatur – Bezieht sich auf die Zufälligkeit der vom Modell generierten Ausgaben. Eine Temperatur größer als 0 oder gleich 1 erhöht den Grad der Zufälligkeit, wohingegen eine Temperatur von 0 die wahrscheinlichsten Token generiert.
Sie sollten Ihre Hyperparameter basierend auf Ihrem Anwendungsfall auswählen und entsprechend testen. Bei Modellen wie der Llama-Familie müssen Sie einen zusätzlichen Parameter angeben, der angibt, dass Sie die Endbenutzer-Lizenzvereinbarung (EULA) gelesen und akzeptiert haben:
Um das Modell zu testen, ersetzen Sie den Inhaltsabschnitt der Eingabenutzlast: "content": "what is the recipe of mayonnaise?". Sie können Ihre eigenen Textwerte verwenden und die Hyperparameter aktualisieren, um sie besser zu verstehen.
Ähnlich wie bei der Bereitstellung des Einbettungsmodells können Sie Llama-70B-Chat mithilfe der SageMaker JumpStart-Benutzeroberfläche bereitstellen:
- Wählen Sie auf der SageMaker Studio-Konsole Starthilfe im Navigationsbereich
- Suchen und wählen Sie die aus
Llama-2-70b-Chat model - Akzeptieren Sie die EULA und wählen Sie Deploy, wobei wieder die Standardinstanz verwendet wird
Ähnlich wie beim Einbettungsmodell können Sie die LangChain-Integration nutzen, indem Sie eine Content-Handler-Vorlage für die Ein- und Ausgaben Ihres Chat-Modells erstellen. In diesem Fall definieren Sie die Eingaben als solche, die von einem Benutzer kommen, und geben an, dass sie von der gesteuert werden system promptdem „Vermischten Geschmack“. Seine system prompt informiert das Modell über seine Rolle bei der Unterstützung des Benutzers für einen bestimmten Anwendungsfall.
Dieser Content-Handler wird dann beim Aufruf des Modells zusätzlich zu den oben genannten Hyperparametern und benutzerdefinierten Attributen (EULA-Akzeptanz) übergeben. Sie analysieren alle diese Attribute mit dem folgenden Code:
Wenn der Endpunkt verfügbar ist, können Sie testen, ob er wie erwartet funktioniert. Sie können aktualisieren llm("what is amazon sagemaker?") mit Ihrem eigenen Text. Sie müssen auch das Spezifische definieren ContentHandler um das LLM mit LangChain aufzurufen, wie im gezeigt Code und das folgende Code-Snippet:
Verwenden Sie LlamaIndex, um die RAG zu erstellen
Um fortzufahren, installieren Sie LlamaIndex, um die RAG-Anwendung zu erstellen. Sie können LlamaIndex mit dem pip installieren: pip install llama_index
Sie müssen zunächst Ihre Daten (Wissensdatenbank) zur Indizierung auf LlamaIndex laden. Dies umfasst einige Schritte:
- Wählen Sie einen Datenlader:
LlamaIndex stellt eine Reihe von Datenkonnektoren zur Verfügung LamaHub für gängige Datentypen wie JSON, CSV und Textdateien sowie andere Datenquellen, sodass Sie eine Vielzahl von Datensätzen aufnehmen können. In diesem Beitrag verwenden wir SimpleDirectoryReader um ein paar PDF-Dateien aufzunehmen, wie im Code gezeigt. Unser Datenbeispiel besteht aus zwei Amazon-Pressemitteilungen in PDF-Version im Pressemitteilungen Ordner in unserem Code-Repository. Nachdem Sie die PDFs geladen haben, können Sie sehen, dass sie in eine Liste mit 11 Elementen konvertiert wurden.
Anstatt die Dokumente direkt zu laden, können Sie sie auch verdeckt laden Document Objekt in Node Objekte, bevor sie an den Index gesendet werden. Die Wahl zwischen dem Versenden des gesamten Document Objekt in den Index einfügen oder das Dokument in konvertieren Node Die Objekte vor der Indizierung hängen von Ihrem spezifischen Anwendungsfall und der Struktur Ihrer Daten ab. Der Knotenansatz ist im Allgemeinen eine gute Wahl für lange Dokumente, bei denen Sie bestimmte Teile eines Dokuments aufteilen und abrufen möchten und nicht das gesamte Dokument. Weitere Informationen finden Sie unter Dokumente / Knoten.
- Instanziieren Sie den Loader und laden Sie die Dokumente:
Dieser Schritt initialisiert die Loader-Klasse und alle erforderlichen Konfigurationen, z. B. ob versteckte Dateien ignoriert werden sollen. Weitere Einzelheiten finden Sie unter SimpleDirectoryReader.
- Rufen Sie den Lader an
load_dataMethode zum Analysieren Ihrer Quelldateien und -daten und zum Konvertieren in LlamaIndex-Dokumentobjekte, die für die Indizierung und Abfrage bereit sind. Sie können den folgenden Code verwenden, um die Datenaufnahme und Vorbereitung für die Volltextsuche mithilfe der Indizierungs- und Abruffunktionen von LlamaIndex abzuschließen:
- Erstellen Sie den Index:
Das Hauptmerkmal von LlamaIndex ist seine Fähigkeit, organisierte Indizes für Daten zu erstellen, die als Dokumente oder Knoten dargestellt werden. Die Indizierung ermöglicht eine effiziente Abfrage der Daten. Wir erstellen unseren Index mit dem standardmäßigen In-Memory-Vektorspeicher und mit unserer definierten Einstellungskonfiguration. Der LamaIndex Einstellungen ist ein Konfigurationsobjekt, das häufig verwendete Ressourcen und Einstellungen für Indizierungs- und Abfragevorgänge in einer LlamaIndex-Anwendung bereitstellt. Es fungiert als Singleton-Objekt, sodass Sie globale Konfigurationen festlegen und gleichzeitig bestimmte Komponenten lokal überschreiben können, indem Sie sie direkt an die Schnittstellen (z. B. LLMs, Einbettungsmodelle) übergeben, die sie verwenden. Wenn eine bestimmte Komponente nicht explizit bereitgestellt wird, greift das LlamaIndex-Framework auf die in definierten Einstellungen zurück Settings Objekt als globalen Standard. Um unsere Einbettungs- und LLM-Modelle mit LangChain zu verwenden und zu konfigurieren Settings wir müssen installieren llama_index.embeddings.langchain und llama_index.llms.langchain. Wir können das konfigurieren Settings Objekt wie im folgenden Code:
Standardmäßig VectorStoreIndex verwendet einen In-Memory SimpleVectorStore Dies wird als Teil des Standardspeicherkontexts initialisiert. In realen Anwendungsfällen müssen Sie häufig eine Verbindung zu externen Vektorspeichern herstellen, z Amazon OpenSearch-Dienst. Weitere Einzelheiten finden Sie unter Vector Engine für Amazon OpenSearch Serverless.
Jetzt können Sie Ihre Dokumente mit Fragen und Antworten durchgehen query_engine von LlamaIndex. Übergeben Sie dazu den Index, den Sie zuvor für Abfragen erstellt haben, und stellen Sie Ihre Frage. Die Abfrage-Engine ist eine generische Schnittstelle zum Abfragen von Daten. Es nimmt eine Abfrage in natürlicher Sprache als Eingabe und gibt eine umfangreiche Antwort zurück. Die Abfrage-Engine basiert normalerweise auf einer oder mehreren Indizes Verwendung von Retriever.
Sie können sehen, dass die RAG-Lösung in der Lage ist, die richtige Antwort aus den bereitgestellten Dokumenten abzurufen:
Verwenden Sie LangChain-Tools und -Agenten
Loader Klasse. Der Loader dient zum Laden von Daten in LlamaIndex oder anschließend als Tool in einem LangChain-Agent. Dies gibt Ihnen mehr Leistung und Flexibilität, um dies als Teil Ihrer Anwendung zu verwenden. Sie beginnen mit der Definition Ihres Werkzeug aus der LangChain-Agentenklasse. Die Funktion, die Sie an Ihr Tool übergeben, fragt den Index ab, den Sie mit LlamaIndex über Ihre Dokumente erstellt haben.
Anschließend wählen Sie den richtigen Agententyp aus, den Sie für Ihre RAG-Implementierung verwenden möchten. In diesem Fall verwenden Sie die chat-zero-shot-react-description Agent. Mit diesem Agenten nutzt das LLM das verfügbare Tool (in diesem Szenario das RAG über die Wissensdatenbank), um die Antwort bereitzustellen. Anschließend initialisieren Sie den Agenten, indem Sie Ihr Tool, LLM und den Agententyp übergeben:
Sie können sehen, wie der Agent durchgeht thoughts, actions und observation , verwenden Sie das Tool (in diesem Szenario Abfragen Ihrer indizierten Dokumente); und ein Ergebnis zurückgeben:
Den End-to-End-Implementierungscode finden Sie im Anhang GitHub Repo.
Aufräumen
Um unnötige Kosten zu vermeiden, können Sie Ihre Ressourcen bereinigen, entweder über die folgenden Codeausschnitte oder die Amazon JumpStart-Benutzeroberfläche.
Um das Boto3 SDK zu verwenden, verwenden Sie den folgenden Code, um den Endpunkt des Texteinbettungsmodells und den Endpunkt des Textgenerierungsmodells sowie die Endpunktkonfigurationen zu löschen:
Um die SageMaker-Konsole zu verwenden, führen Sie die folgenden Schritte aus:
- Wählen Sie in der SageMaker-Konsole unter „Inferenz“ im Navigationsbereich „Endpunkte“ aus
- Suchen Sie nach den Endpunkten für die Einbettung und Textgenerierung.
- Wählen Sie auf der Seite mit den Endpunktdetails die Option Löschen aus.
- Wählen Sie zur Bestätigung erneut Löschen.
Zusammenfassung
Für Anwendungsfälle, die sich auf Suche und Abruf konzentrieren, bietet LlamaIndex flexible Funktionen. Es zeichnet sich durch die Indizierung und den Abruf für LLMs aus und ist damit ein leistungsstarkes Werkzeug für die tiefgreifende Untersuchung von Daten. Mit LlamaIndex können Sie organisierte Datenindizes erstellen, verschiedene LLMs verwenden, Daten für eine bessere LLM-Leistung erweitern und Daten in natürlicher Sprache abfragen.
In diesem Beitrag wurden einige wichtige Konzepte und Funktionen von LlamaIndex demonstriert. Wir haben GPT-J zum Einbetten und Llama 2-Chat als LLM zum Erstellen einer RAG-Anwendung verwendet, Sie können jedoch stattdessen jedes geeignete Modell verwenden. Sie können die umfassende Modellpalette von SageMaker JumpStart erkunden.
Wir haben auch gezeigt, wie LlamaIndex leistungsstarke, flexible Tools zum Verbinden, Indizieren, Abrufen und Integrieren von Daten mit anderen Frameworks wie LangChain bereitstellen kann. Mit LlamaIndex-Integrationen und LangChain können Sie leistungsfähigere, vielseitigere und aufschlussreichere LLM-Anwendungen erstellen.
Über die Autoren
 Romina Sharifpour ist Senior Architect für maschinelles Lernen und künstliche Intelligenz bei Amazon Web Services (AWS). Sie hat über 10 Jahre damit verbracht, den Entwurf und die Implementierung innovativer End-to-End-Lösungen zu leiten, die durch Fortschritte in ML und KI ermöglicht werden. Rominas Interessengebiete sind die Verarbeitung natürlicher Sprache, große Sprachmodelle und MLOps.
Romina Sharifpour ist Senior Architect für maschinelles Lernen und künstliche Intelligenz bei Amazon Web Services (AWS). Sie hat über 10 Jahre damit verbracht, den Entwurf und die Implementierung innovativer End-to-End-Lösungen zu leiten, die durch Fortschritte in ML und KI ermöglicht werden. Rominas Interessengebiete sind die Verarbeitung natürlicher Sprache, große Sprachmodelle und MLOps.
 Nicole Pinto ist ein auf KI/ML spezialisierter Lösungsarchitekt mit Sitz in Sydney, Australien. Ihr Hintergrund im Gesundheitswesen und im Finanzdienstleistungsbereich verleiht ihr eine einzigartige Perspektive bei der Lösung von Kundenproblemen. Ihre Leidenschaft liegt darin, Kunden durch maschinelles Lernen zu unterstützen und die nächste Generation von Frauen im MINT-Bereich zu stärken.
Nicole Pinto ist ein auf KI/ML spezialisierter Lösungsarchitekt mit Sitz in Sydney, Australien. Ihr Hintergrund im Gesundheitswesen und im Finanzdienstleistungsbereich verleiht ihr eine einzigartige Perspektive bei der Lösung von Kundenproblemen. Ihre Leidenschaft liegt darin, Kunden durch maschinelles Lernen zu unterstützen und die nächste Generation von Frauen im MINT-Bereich zu stärken.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

