Der Aufstieg der kontextuellen und semantischen Suche hat dazu geführt, dass E-Commerce- und Einzelhandelsunternehmen die Suche für ihre Verbraucher einfacher gestalten. Suchmaschinen und Empfehlungssysteme, die auf generativer KI basieren, können das Produktsucherlebnis exponentiell verbessern, indem sie Anfragen in natürlicher Sprache verstehen und genauere Ergebnisse liefern. Dies verbessert das allgemeine Benutzererlebnis und hilft Kunden, genau das zu finden, was sie suchen.
Amazon OpenSearch-Dienst unterstützt jetzt die Kosinusähnlichkeit Metrik für k-NN-Indizes. Die Kosinusähnlichkeit misst den Kosinus des Winkels zwischen zwei Vektoren, wobei ein kleinerer Kosinuswinkel eine größere Ähnlichkeit zwischen den Vektoren anzeigt. Mit Kosinus-Ähnlichkeit können Sie die Orientierung zwischen zwei Vektoren messen, was es zu einer guten Wahl für einige spezifische semantische Suchanwendungen macht.
In diesem Beitrag zeigen wir, wie Sie mithilfe von eine kontextbezogene Text- und Bildsuchmaschine für Produktempfehlungen erstellen Amazon Titan Multimodal Embeddings-Modell, verfügbar in Amazonas Grundgestein, mit Amazon OpenSearch ohne Server.
Ein multimodales Einbettungsmodell soll gemeinsame Darstellungen verschiedener Modalitäten wie Text, Bilder und Audio erlernen. Durch Training an großen Datensätzen, die Bilder und die entsprechenden Bildunterschriften enthalten, lernt ein multimodales Einbettungsmodell, Bilder und Texte in einen gemeinsamen latenten Raum einzubetten. Im Folgenden finden Sie einen allgemeinen Überblick über die konzeptionelle Funktionsweise:
- Separate Encoder – Diese Modelle verfügen über separate Encoder für jede Modalität – einen Text-Encoder für Text (z. B. BERT oder RoBERTa), einen Bild-Encoder für Bilder (z. B. CNN für Bilder) und Audio-Encoder für Audio (z. B. Modelle wie Wav2Vec). . Jeder Encoder generiert Einbettungen, die semantische Merkmale seiner jeweiligen Modalitäten erfassen
- Modalitätsfusion – Die Einbettungen der unimodalen Encoder werden mithilfe zusätzlicher neuronaler Netzwerkschichten kombiniert. Ziel ist es, Wechselwirkungen und Zusammenhänge zwischen den Modalitäten zu erlernen. Zu den gängigen Fusionsansätzen gehören Verkettung, elementweise Operationen, Pooling und Aufmerksamkeitsmechanismen.
- Gemeinsamer Repräsentationsraum – Die Fusionsschichten helfen dabei, die einzelnen Modalitäten in einen gemeinsamen Darstellungsraum zu projizieren. Durch das Training mit multimodalen Datensätzen lernt das Modell einen gemeinsamen Einbettungsraum, in dem Einbettungen aus jeder Modalität, die denselben zugrunde liegenden semantischen Inhalt darstellen, näher beieinander liegen.
- Nachgelagerte Aufgaben – Die generierten gemeinsamen multimodalen Einbettungen können dann für verschiedene nachgelagerte Aufgaben wie multimodale Abfrage, Klassifizierung oder Übersetzung verwendet werden. Das Modell nutzt modalitätsübergreifende Korrelationen, um die Leistung bei diesen Aufgaben im Vergleich zu einzelnen modalen Einbettungen zu verbessern. Der Hauptvorteil ist die Fähigkeit, Interaktionen und Semantik zwischen Modalitäten wie Text, Bildern und Audio durch gemeinsame Modellierung zu verstehen.
Lösungsüberblick
Die Lösung bietet eine Implementierung für den Aufbau eines Suchmaschinenprototyps mit großem Sprachmodell (LLM), um Produkte basierend auf Text- oder Bildabfragen abzurufen und zu empfehlen. Wir beschreiben die Schritte zur Verwendung eines Multimodale Einbettungen von Amazon Titan Modell, um Bilder und Text in Einbettungen zu kodieren, Einbettungen in einen OpenSearch Service-Index aufzunehmen und den Index mithilfe des OpenSearch Service abzufragen Funktionalität der k-nächsten Nachbarn (k-NN)..
Diese Lösung umfasst die folgenden Komponenten:
- Amazon Titan Multimodal Embeddings-Modell – Dieses Foundation Model (FM) generiert Einbettungen der in diesem Beitrag verwendeten Produktbilder. Mit Amazon Titan Multimodal Embeddings können Sie Einbettungen für Ihre Inhalte generieren und diese in einer Vektordatenbank speichern. Wenn ein Endbenutzer eine beliebige Kombination aus Text und Bild als Suchabfrage einreicht, generiert das Modell Einbettungen für die Suchabfrage und ordnet sie den gespeicherten Einbettungen zu, um Endbenutzern relevante Such- und Empfehlungsergebnisse bereitzustellen. Sie können das Modell weiter anpassen, um das Verständnis Ihres einzigartigen Inhalts zu verbessern und mithilfe von Bild-Text-Paaren zur Feinabstimmung aussagekräftigere Ergebnisse zu liefern. Standardmäßig generiert das Modell Vektoren (Einbettungen) mit 1,024 Dimensionen und der Zugriff erfolgt über Amazon Bedrock. Sie können auch kleinere Dimensionen generieren, um Geschwindigkeit und Leistung zu optimieren
- Amazon OpenSearch ohne Server – Es handelt sich um eine serverlose On-Demand-Konfiguration für den OpenSearch-Dienst. Wir verwenden Amazon OpenSearch Serverless als Vektordatenbank zum Speichern von Einbettungen, die vom Amazon Titan Multimodal Embeddings-Modell generiert wurden. Ein in der Amazon OpenSearch Serverless-Sammlung erstellter Index dient als Vektorspeicher für unsere Retrieval Augmented Generation (RAG)-Lösung.
- Amazon SageMaker-Studio – Es handelt sich um eine integrierte Entwicklungsumgebung (IDE) für maschinelles Lernen (ML). ML-Praktiker können alle ML-Entwicklungsschritte durchführen – von der Vorbereitung Ihrer Daten bis hin zum Erstellen, Trainieren und Bereitstellen von ML-Modellen.
Das Lösungsdesign besteht aus zwei Teilen: Datenindizierung und kontextbezogene Suche. Bei der Datenindizierung verarbeiten Sie die Produktbilder, um Einbettungen für diese Bilder zu generieren und dann den Vektordatenspeicher zu füllen. Diese Schritte werden vor den Schritten zur Benutzerinteraktion abgeschlossen.
In der kontextbezogenen Suchphase wird eine Suchanfrage (Text oder Bild) des Benutzers in Einbettungen umgewandelt und eine Ähnlichkeitssuche in der Vektordatenbank durchgeführt, um ähnliche Produktbilder basierend auf der Ähnlichkeitssuche zu finden. Anschließend werden die besten ähnlichen Ergebnisse angezeigt. Der gesamte Code für diesen Beitrag ist im verfügbar GitHub Repo.
Das folgende Diagramm zeigt die Lösungsarchitektur.
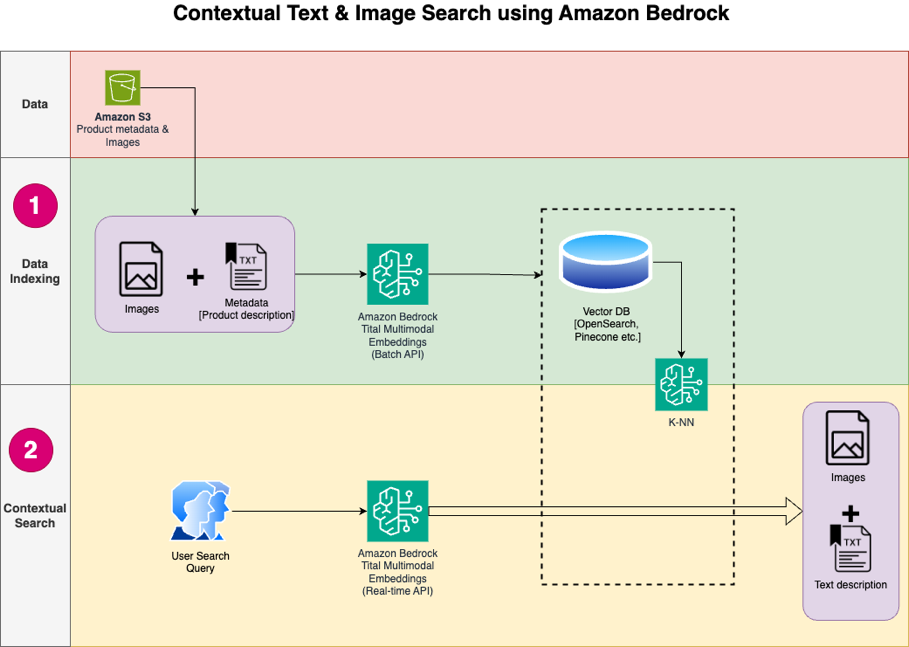
Im Folgenden sind die Schritte des Lösungsworkflows aufgeführt:
- Laden Sie den Produktbeschreibungstext und die Bilder öffentlich herunter Amazon Simple Storage-Service (Amazon S3) Eimer.
- Überprüfen und bereiten Sie den Datensatz vor.
- Generieren Sie Einbettungen für die Produktbilder mit dem Amazon Titan Multimodal Embeddings-Modell (amazon.titan-embed-image-v1). Wenn Sie über eine große Anzahl an Bildern und Beschreibungen verfügen, können Sie optional die verwenden Batch-Inferenz für Amazon Bedrock.
- Speichern Sie Einbettungen in der Amazon OpenSearch ohne Server als Suchmaschine.
- Rufen Sie abschließend die Benutzerabfrage in natürlicher Sprache ab, konvertieren Sie sie mithilfe des Amazon Titan Multimodal Embeddings-Modells in Einbettungen und führen Sie eine k-NN-Suche durch, um die relevanten Suchergebnisse zu erhalten.
Wir verwenden SageMaker Studio (im Diagramm nicht dargestellt) als IDE zur Entwicklung der Lösung.
Diese Schritte werden in den folgenden Abschnitten ausführlich erläutert. Wir fügen auch Screenshots und Details der Ausgabe hinzu.
Voraussetzungen:
Um die in diesem Beitrag bereitgestellte Lösung zu implementieren, sollten Sie über Folgendes verfügen:
- An AWS-Konto und Vertrautheit mit FMs, Amazon Bedrock, Amazon Sage Makerund OpenSearch-Dienst.
- Das in Amazon Bedrock aktivierte Amazon Titan Multimodal Embeddings-Modell. Sie können bestätigen, dass es aktiviert ist Modellzugriff Seite der Amazon Bedrock-Konsole. Wenn Amazon Titan Multimodal Embeddings aktiviert ist, wird der Zugriffsstatus als angezeigt Zugang gewährt, wie im folgenden Screenshot gezeigt.

Wenn das Modell nicht verfügbar ist, aktivieren Sie den Zugriff auf das Modell, indem Sie wählen Modellzugriff verwalten, auswählend Amazon Titan Multimodal Embeddings G1und wählen Modellzugang anfordern. Das Modell ist sofort betriebsbereit.

Richten Sie die Lösung ein
Wenn die erforderlichen Schritte abgeschlossen sind, können Sie die Lösung einrichten:
- Öffnen Sie in Ihrem AWS-Konto die SageMaker-Konsole und wählen Sie Studio im Navigationsbereich.
- Wählen Sie Ihre Domain und Ihr Benutzerprofil aus und wählen Sie dann Open Studio.
Ihr Domain- und Benutzerprofilname können unterschiedlich sein.

- Auswählen Systemendgerät für Dienstprogramme und Dateien.
- Führen Sie den folgenden Befehl aus, um das zu klonen GitHub Repo zur SageMaker Studio-Instanz:
- Navigieren Sie zu der
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2e-Ordner. - Öffnen Sie den Microsoft Store auf Ihrem Windows-PC.
titan_mm_embed_search_blog.ipynbNotebook.
Führen Sie die Lösung aus
Öffnen Sie die Datei titan_mm_embed_search_blog.ipynb und verwenden Sie den Data Science Python 3-Kernel. Auf der Führen Sie Menü, wählen Sie Führen Sie alle Zellen aus um den Code in diesem Notebook auszuführen.
Dieses Notebook führt die folgenden Schritte aus:
- Installieren Sie die für diese Lösung erforderlichen Pakete und Bibliotheken.
- Laden Sie die öffentlich verfügbare Datei Amazon Berkeley Objects-Datensatz und Metadaten in einem Pandas-Datenrahmen.
Der Datensatz ist eine Sammlung von 147,702 Produktlisten mit mehrsprachigen Metadaten und 398,212 einzigartigen Katalogbildern. Für diesen Beitrag verwenden Sie ausschließlich die Artikelbilder und Artikelnamen in US-Englisch. Sie nutzen rund 1,600 Produkte.

- Generieren Sie Einbettungen für die Artikelbilder mithilfe des Amazon Titan Multimodal Embeddings-Modells mithilfe von
get_titan_multomodal_embedding()Funktion. Aus Gründen der Abstraktion haben wir alle wichtigen Funktionen, die in diesem Notebook verwendet werden, im definiertutils.pyDatei.

Als Nächstes erstellen und richten Sie einen Amazon OpenSearch Serverless-Vektorspeicher (Sammlung und Index) ein.
- Bevor Sie die neue Vektorsuchsammlung und den neuen Index erstellen, müssen Sie zunächst drei zugehörige OpenSearch-Service-Richtlinien erstellen: die Verschlüsselungssicherheitsrichtlinie, die Netzwerksicherheitsrichtlinie und die Datenzugriffsrichtlinie.

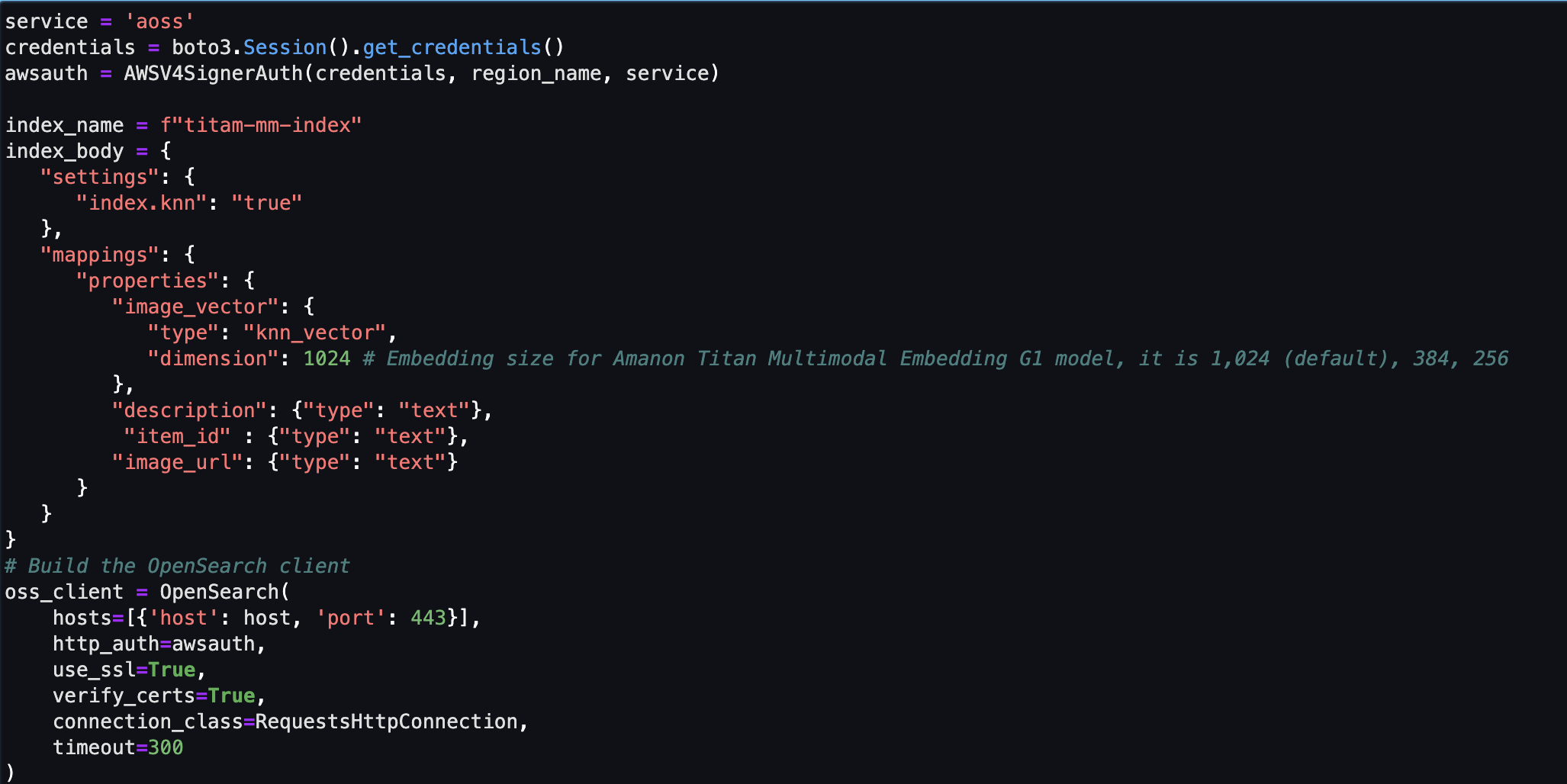
- Nehmen Sie abschließend die Bildeinbettung in den Vektorindex auf.
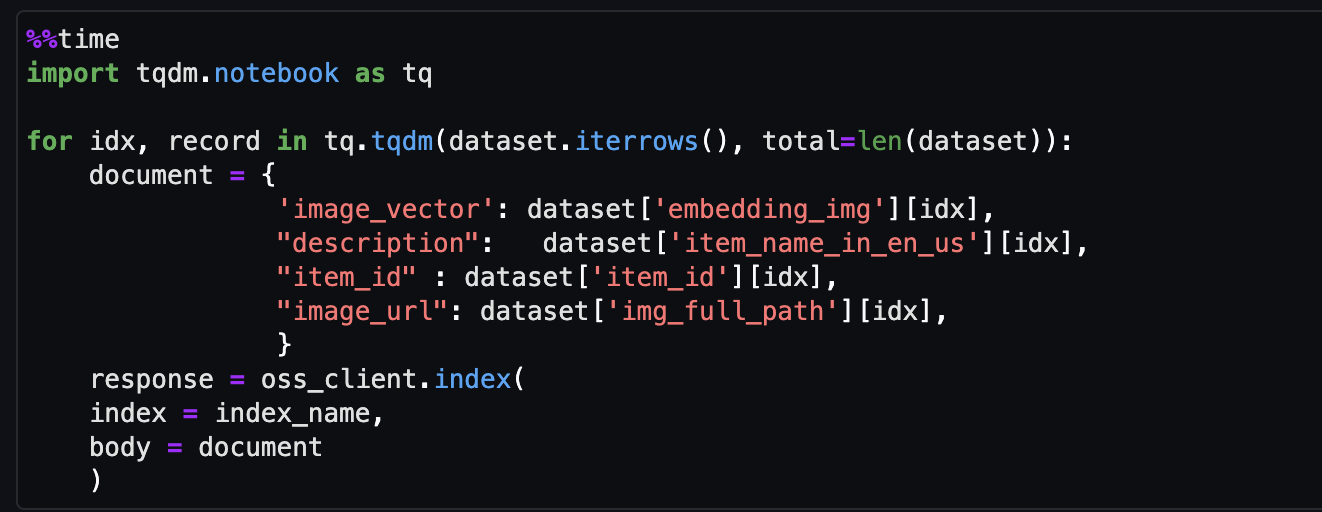
Jetzt können Sie eine multimodale Suche in Echtzeit durchführen.
Führen Sie eine kontextbezogene Suche durch
In diesem Abschnitt zeigen wir die Ergebnisse einer kontextbezogenen Suche basierend auf einer Text- oder Bildabfrage.
Führen wir zunächst eine Bildsuche basierend auf der Texteingabe durch. Im folgenden Beispiel verwenden wir die Texteingabe „Getränkeglas“ und senden sie an die Suchmaschine, um ähnliche Artikel zu finden.
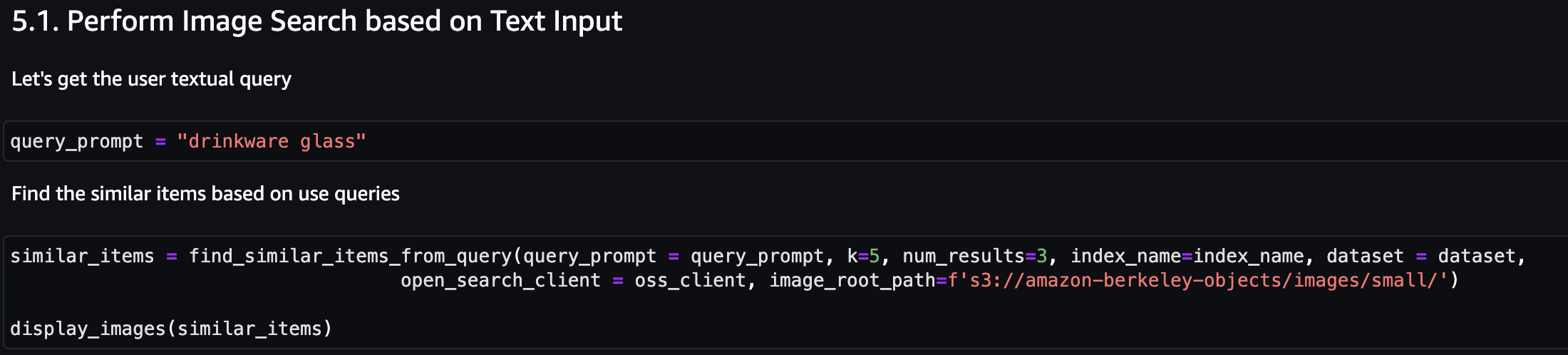
Der folgende Screenshot zeigt die Ergebnisse.

Schauen wir uns nun die Ergebnisse anhand eines einfachen Bildes an. Das Eingabebild wird in Vektoreinbettungen umgewandelt und basierend auf der Ähnlichkeitssuche gibt das Modell das Ergebnis zurück.
Sie können jedes Bild verwenden, aber für das folgende Beispiel verwenden wir ein zufälliges Bild aus dem Datensatz basierend auf der Element-ID (z. B. item_id = „B07JCDQWM6“) und senden Sie dieses Bild dann an die Suchmaschine, um ähnliche Artikel zu finden.

Der folgende Screenshot zeigt die Ergebnisse.

Aufräumen
Um künftige Gebühren zu vermeiden, löschen Sie die in dieser Lösung verwendeten Ressourcen. Sie können dies tun, indem Sie den Bereinigungsabschnitt des Notebooks ausführen.

Zusammenfassung
In diesem Beitrag wurde eine exemplarische Vorgehensweise für die Verwendung des Amazon Titan Multimodal Embeddings-Modells in Amazon Bedrock vorgestellt, um leistungsstarke kontextbezogene Suchanwendungen zu erstellen. Insbesondere haben wir ein Beispiel für eine Suchanwendung für Produktlisten demonstriert. Wir haben gesehen, wie das Einbettungsmodell eine effiziente und genaue Entdeckung von Informationen aus Bildern und Textdaten ermöglicht und dadurch das Benutzererlebnis bei der Suche nach den relevanten Elementen verbessert.
Mit Amazon Titan Multimodal Embeddings können Sie Endbenutzern genauere und kontextrelevantere multimodale Such-, Empfehlungs- und Personalisierungserlebnisse bieten. Beispielsweise kann ein Stock-Fotografie-Unternehmen mit Hunderten Millionen Bildern das Modell nutzen, um seine Suchfunktion zu verbessern, sodass Benutzer nach Bildern suchen können, indem sie eine Phrase, ein Bild oder eine Kombination aus Bild und Text verwenden.
Das Amazon Titan Multimodal Embeddings-Modell in Amazon Bedrock ist jetzt in den AWS-Regionen USA Ost (Nord-Virginia) und USA West (Oregon) verfügbar. Weitere Informationen finden Sie unter Amazon Titan Image Generator, Multimodal Embeddings und Textmodelle sind jetzt in Amazon Bedrock verfügbar, der Amazon Titan-Produktseiteund der Amazon Bedrock-Benutzerhandbuch. Um mit Amazon Titan Multimodal Embeddings in Amazon Bedrock zu beginnen, besuchen Sie die Amazon Bedrock-Konsole.
Beginnen Sie mit der Entwicklung mit dem Amazon Titan Multimodal Embeddings-Modell in Amazonas Grundgestein heute.
Über die Autoren
 Sandeep Singh ist Senior Generative AI Data Scientist bei Amazon Web Services und unterstützt Unternehmen bei Innovationen mit generativer KI. Er ist spezialisiert auf generative KI, künstliche Intelligenz, maschinelles Lernen und Systemdesign. Seine Leidenschaft gilt der Entwicklung modernster KI/ML-gestützter Lösungen zur Lösung komplexer Geschäftsprobleme für verschiedene Branchen sowie der Optimierung von Effizienz und Skalierbarkeit.
Sandeep Singh ist Senior Generative AI Data Scientist bei Amazon Web Services und unterstützt Unternehmen bei Innovationen mit generativer KI. Er ist spezialisiert auf generative KI, künstliche Intelligenz, maschinelles Lernen und Systemdesign. Seine Leidenschaft gilt der Entwicklung modernster KI/ML-gestützter Lösungen zur Lösung komplexer Geschäftsprobleme für verschiedene Branchen sowie der Optimierung von Effizienz und Skalierbarkeit.
 Mani Chanuja ist Tech Lead – Generative AI Specialists, Autorin des Buches Applied Machine Learning and High Performance Computing on AWS und Mitglied des Vorstands der Women in Manufacturing Education Foundation. Sie leitet Projekte zum maschinellen Lernen in verschiedenen Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache und generative KI. Sie spricht auf internen und externen Konferenzen wie AWS re:Invent, Women in Manufacturing West, YouTube-Webinaren und GHC 23. In ihrer Freizeit unternimmt sie gerne lange Läufe am Strand.
Mani Chanuja ist Tech Lead – Generative AI Specialists, Autorin des Buches Applied Machine Learning and High Performance Computing on AWS und Mitglied des Vorstands der Women in Manufacturing Education Foundation. Sie leitet Projekte zum maschinellen Lernen in verschiedenen Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache und generative KI. Sie spricht auf internen und externen Konferenzen wie AWS re:Invent, Women in Manufacturing West, YouTube-Webinaren und GHC 23. In ihrer Freizeit unternimmt sie gerne lange Läufe am Strand.
 Rupinder Grewal ist Senior AI/ML Specialist Solutions Architect bei AWS. Derzeit konzentriert er sich auf die Bereitstellung von Modellen und MLOps auf Amazon SageMaker. Vor dieser Rolle arbeitete er als Ingenieur für maschinelles Lernen beim Erstellen und Hosten von Modellen. Außerhalb der Arbeit spielt er gerne Tennis und radelt auf Bergwegen.
Rupinder Grewal ist Senior AI/ML Specialist Solutions Architect bei AWS. Derzeit konzentriert er sich auf die Bereitstellung von Modellen und MLOps auf Amazon SageMaker. Vor dieser Rolle arbeitete er als Ingenieur für maschinelles Lernen beim Erstellen und Hosten von Modellen. Außerhalb der Arbeit spielt er gerne Tennis und radelt auf Bergwegen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

