In der sich entwickelnden Fertigungslandschaft ist die transformative Kraft von KI und maschinellem Lernen (ML) offensichtlich und treibt eine digitale Revolution voran, die Abläufe rationalisiert und die Produktivität steigert. Dieser Fortschritt bringt jedoch einzigartige Herausforderungen für Unternehmen mit sich, die datengesteuerte Lösungen nutzen möchten. Industrieanlagen haben mit riesigen Mengen unstrukturierter Daten zu kämpfen, die von Sensoren, Telemetriesystemen und Geräten stammen, die über Produktionslinien verteilt sind. Echtzeitdaten sind für Anwendungen wie vorausschauende Wartung und Anomalieerkennung von entscheidender Bedeutung. Die Entwicklung benutzerdefinierter ML-Modelle für jeden industriellen Anwendungsfall mit solchen Zeitreihendaten erfordert jedoch viel Zeit und Ressourcen von Datenwissenschaftlern, was einer breiten Einführung entgegensteht.
Generative KI unter Verwendung großer vorab trainierter Fundamentmodelle (FMs), wie z Claude kann schnell eine Vielzahl von Inhalten generieren, von Konversationstexten bis hin zu Computercode, basierend auf einfachen Texteingabeaufforderungen, die als bezeichnet werden Zero-Shot-Eingabeaufforderung. Dadurch entfällt für Datenwissenschaftler die Notwendigkeit, für jeden Anwendungsfall spezifische ML-Modelle manuell zu entwickeln, und demokratisiert sich der KI-Zugriff, wovon auch kleine Hersteller profitieren. Mitarbeiter steigern die Produktivität durch KI-generierte Erkenntnisse, Ingenieure können Anomalien proaktiv erkennen, Supply-Chain-Manager optimieren Bestände und die Werksleitung trifft fundierte, datengesteuerte Entscheidungen.
Dennoch stoßen eigenständige FMs auf Einschränkungen bei der Verarbeitung komplexer Industriedaten mit Kontextgrößenbeschränkungen (typischerweise). weniger als 200,000 Token), was Herausforderungen mit sich bringt. Um dieses Problem zu lösen, können Sie die Fähigkeit des FM nutzen, Code als Reaktion auf Abfragen in natürlicher Sprache (Natural Language Queries, NLQs) zu generieren. Agenten mögen PandasAI Kommen Sie ins Spiel, indem Sie diesen Code auf hochauflösenden Zeitreihendaten ausführen und Fehler mithilfe von FMs behandeln. PandasAI ist eine Python-Bibliothek, die Pandas, dem beliebten Datenanalyse- und -manipulationstool, generative KI-Funktionen hinzufügt.
Komplexe NLQs wie die Verarbeitung von Zeitreihendaten, die Aggregation auf mehreren Ebenen sowie Pivot- oder Joint-Table-Operationen können jedoch bei einer Zero-Shot-Eingabeaufforderung zu einer inkonsistenten Python-Skriptgenauigkeit führen.
Um die Genauigkeit der Codegenerierung zu verbessern, schlagen wir eine dynamische Konstruktion vor Multi-Shot-Eingabeaufforderungen für NLQs. Multi-Shot-Prompting bietet zusätzlichen Kontext zum FM, indem es mehrere Beispiele gewünschter Ausgaben für ähnliche Prompts anzeigt und so die Genauigkeit und Konsistenz erhöht. In diesem Beitrag werden Multi-Shot-Eingabeaufforderungen aus einer Einbettung abgerufen, die erfolgreichen Python-Code enthält, der mit einem ähnlichen Datentyp ausgeführt wird (z. B. hochauflösende Zeitreihendaten von Geräten für das Internet der Dinge). Die dynamisch erstellte Multi-Shot-Eingabeaufforderung stellt dem FM den relevantesten Kontext bereit und steigert die Fähigkeiten des FM bei fortgeschrittenen mathematischen Berechnungen, der Verarbeitung von Zeitreihendaten und dem Verständnis von Datenakronymen. Diese verbesserte Reaktion erleichtert Unternehmensmitarbeitern und Betriebsteams den Umgang mit Daten und die Ableitung von Erkenntnissen, ohne dass umfangreiche datenwissenschaftliche Kenntnisse erforderlich sind.
Über die Analyse von Zeitreihendaten hinaus erweisen sich FMs in verschiedenen industriellen Anwendungen als wertvoll. Wartungsteams bewerten den Anlagenzustand und erfassen Bilder für Amazon-Anerkennung-basierte Funktionszusammenfassungen und Analyse der Grundursache von Anomalien mithilfe intelligenter Suchvorgänge mit Augmented Generation abrufen (LAPPEN). Um diese Arbeitsabläufe zu vereinfachen, hat AWS eingeführt Amazonas Grundgestein, sodass Sie generative KI-Anwendungen mit hochmodernen vortrainierten FMs wie erstellen und skalieren können Claude v2. Mit Wissensdatenbanken für Amazon Bedrockkönnen Sie den RAG-Entwicklungsprozess vereinfachen, um Werksmitarbeitern eine genauere Analyse der Grundursache von Anomalien zu ermöglichen. Unser Beitrag stellt einen intelligenten Assistenten für industrielle Anwendungsfälle vor, der von Amazon Bedrock unterstützt wird und NLQ-Herausforderungen bewältigt, Teilezusammenfassungen aus Bildern generiert und FM-Reaktionen für die Gerätediagnose durch den RAG-Ansatz verbessert.
Lösungsüberblick
Das folgende Diagramm zeigt die Lösungsarchitektur.

Der Workflow umfasst drei verschiedene Anwendungsfälle:
Anwendungsfall 1: NLQ mit Zeitreihendaten
Der Workflow für NLQ mit Zeitreihendaten besteht aus den folgenden Schritten:
- Wir verwenden ein Zustandsüberwachungssystem mit ML-Funktionen zur Anomalieerkennung, wie z Amazon-Monitor, um den Zustand industrieller Anlagen zu überwachen. Amazon Monitron ist in der Lage, potenzielle Geräteausfälle anhand der Vibrations- und Temperaturmessungen der Geräte zu erkennen.
- Wir sammeln Zeitreihendaten durch Verarbeitung Amazon-Monitor Daten durch Amazon Kinesis-Datenströme und Amazon Data Firehose, Konvertieren Sie es in ein tabellarisches CSV-Format und speichern Sie es in einem Amazon Simple Storage-Service (Amazon S3) Eimer.
- Der Endbenutzer kann mit seinen Zeitreihendaten in Amazon S3 chatten, indem er eine Abfrage in natürlicher Sprache an die Streamlit-App sendet.
- Die Streamlit-App leitet Benutzeranfragen an die weiter Texteinbettungsmodell von Amazon Bedrock Titan um diese Abfrage einzubetten, und führt eine Ähnlichkeitssuche innerhalb einer durch Amazon OpenSearch-Dienst Index, der frühere NLQs und Beispielcodes enthält.
- Nach der Ähnlichkeitssuche werden die häufigsten ähnlichen Beispiele, einschließlich NLQ-Fragen, Datenschemata und Python-Codes, in eine benutzerdefinierte Eingabeaufforderung eingefügt.
- PandasAI sendet diese benutzerdefinierte Eingabeaufforderung an das Amazon Bedrock Claude v2-Modell.
- Die App verwendet den PandasAI-Agenten, um mit dem Amazon Bedrock Claude v2-Modell zu interagieren und Python-Code für die Amazon Monitron-Datenanalyse und NLQ-Antworten zu generieren.
- Nachdem das Amazon Bedrock Claude v2-Modell den Python-Code zurückgibt, führt PandasAI die Python-Abfrage für die von der App hochgeladenen Amazon Monitron-Daten aus, sammelt Codeausgaben und berücksichtigt alle erforderlichen Wiederholungsversuche für fehlgeschlagene Ausführungen.
- Die Streamlit-App sammelt die Antwort über PandasAI und stellt die Ausgabe den Benutzern zur Verfügung. Wenn die Ausgabe zufriedenstellend ist, kann der Benutzer sie als hilfreich markieren und den von NLQ und Claude generierten Python-Code im OpenSearch Service speichern.
Anwendungsfall 2: Zusammenfassende Generierung fehlerhafter Teile
Unser Anwendungsfall zur Zusammenfassungsgenerierung besteht aus den folgenden Schritten:
- Nachdem der Benutzer weiß, welche Industrieanlage ein anormales Verhalten aufweist, kann er Bilder des fehlerhaften Teils hochladen, um anhand seiner technischen Spezifikation und seines Betriebszustands festzustellen, ob mit diesem Teil ein physischer Fehler vorliegt.
- Der Benutzer kann die Amazon Recognition DetectText-API um Textdaten aus diesen Bildern zu extrahieren.
- Die extrahierten Textdaten sind in der Eingabeaufforderung für das Amazon Bedrock Claude v2-Modell enthalten, sodass das Modell eine 200-Wörter-Zusammenfassung des fehlerhaften Teils erstellen kann. Der Benutzer kann diese Informationen verwenden, um eine weitere Prüfung des Teils durchzuführen.
Anwendungsfall 3: Ursachendiagnose
Unser Anwendungsfall zur Ursachendiagnose besteht aus den folgenden Schritten:
- Der Benutzer erhält Unternehmensdaten in verschiedenen Dokumentformaten (PDF, TXT usw.), die sich auf fehlerhafte Anlagen beziehen, und lädt sie in einen S3-Bucket hoch.
- Eine Wissensdatenbank dieser Dateien wird in Amazon Bedrock mit einem Titan-Texteinbettungsmodell und einem standardmäßigen OpenSearch Service-Vektorspeicher generiert.
- Der Benutzer stellt Fragen zur Grundursachendiagnose für fehlerhafte Geräte. Antworten werden über die Wissensdatenbank von Amazon Bedrock mit einem RAG-Ansatz generiert.
Voraussetzungen:
Um diesem Beitrag folgen zu können, sollten Sie die folgenden Voraussetzungen erfüllen:
Stellen Sie die Lösungsinfrastruktur bereit
Führen Sie die folgenden Schritte aus, um Ihre Lösungsressourcen einzurichten:
- Bereitstellen der AWS CloudFormation Vorlage opensearchsagemaker.yml, das eine OpenSearch Service-Sammlung und einen OpenSearch-Index erstellt, Amazon Sage Maker Notebook-Instanz und S3-Bucket. Sie können diesen AWS CloudFormation-Stack wie folgt benennen:
genai-sagemaker. - Öffnen Sie die SageMaker-Notebook-Instanz in JupyterLab. Sie finden Folgendes GitHub Repo bereits auf diese Instanz heruntergeladen: Erschließung des Potenzials generativer KI im industriellen Betrieb.
- Führen Sie das Notebook aus dem folgenden Verzeichnis in diesem Repository aus: unlocking-the-potential-of-generative-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Dieses Notebook lädt den OpenSearch Service-Index mithilfe des SageMaker-Notebooks, um Schlüssel-Wert-Paare aus dem zu speichern vorhandene 23 NLQ-Beispiele.
- Laden Sie Dokumente aus dem Datenordner hoch assetpartdoc im GitHub-Repository in den S3-Bucket, der in den CloudFormation-Stack-Ausgaben aufgeführt ist.

Als Nächstes erstellen Sie die Wissensdatenbank für die Dokumente in Amazon S3.
- Wählen Sie auf der Amazon Bedrock-Konsole Wissensbasis im Navigationsbereich.
- Auswählen Wissensbasis schaffen.
- Aussichten für Name der Wissensdatenbank, Geben Sie einen Namen ein.
- Aussichten für LaufzeitrolleWählen Erstellen und verwenden Sie eine neue Servicerolle.
- Aussichten für Name der DatenquelleGeben Sie den Namen Ihrer Datenquelle ein.
- Aussichten für S3-URIGeben Sie den S3-Pfad des Buckets ein, in den Sie die Ursachendokumente hochgeladen haben.
- Auswählen
Weiter.
 Das Titan-Einbettungsmodell wird automatisch ausgewählt.
Das Titan-Einbettungsmodell wird automatisch ausgewählt. - Auswählen Erstellen Sie schnell einen neuen Vektorspeicher.
- Überprüfen Sie Ihre Einstellungen und erstellen Sie die Wissensdatenbank, indem Sie auswählen Wissensbasis schaffen.
- Nachdem die Wissensdatenbank erfolgreich erstellt wurde, wählen Sie Synchronisierung um den S3-Bucket mit der Wissensdatenbank zu synchronisieren.

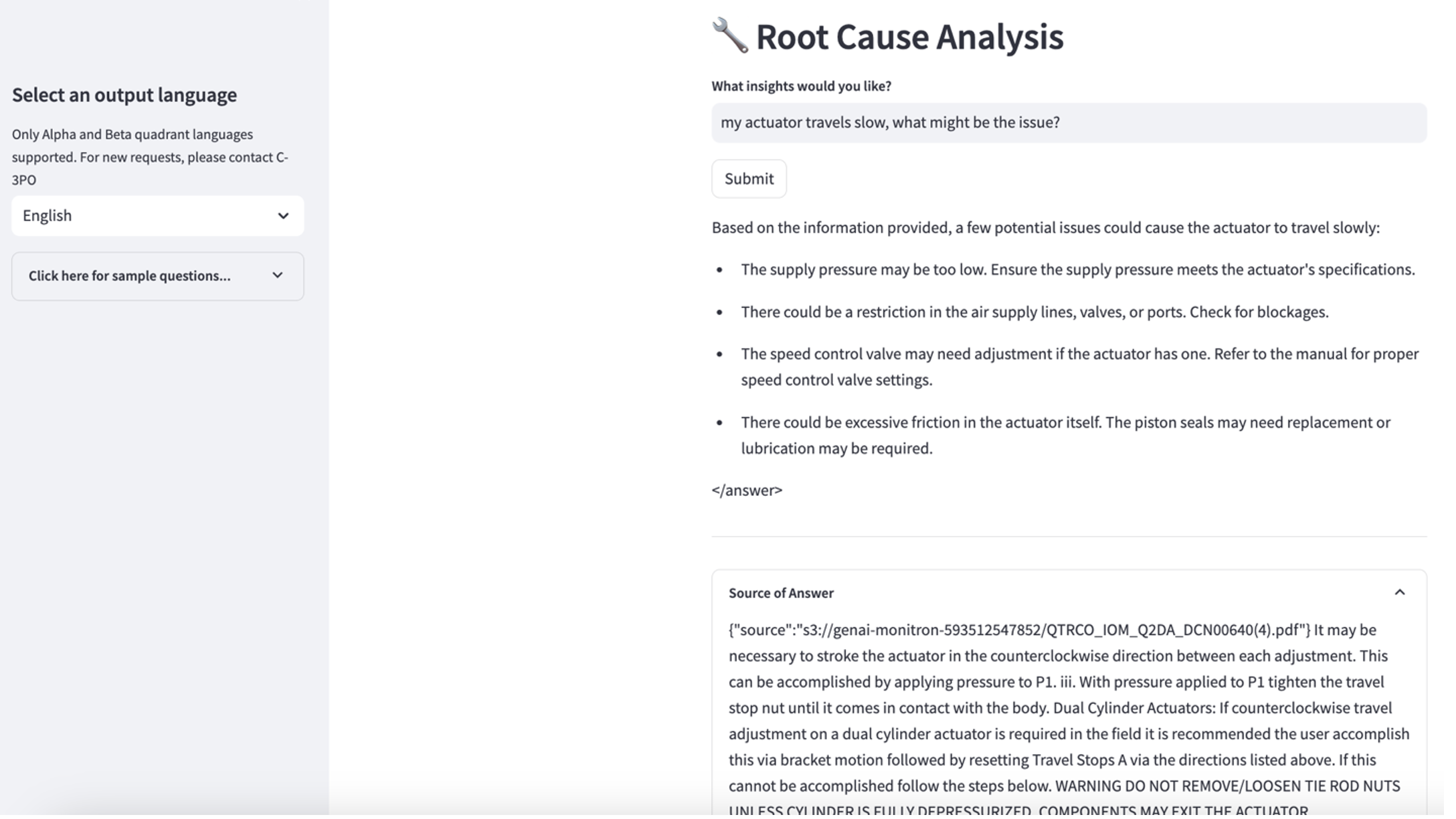
- Nachdem Sie die Wissensdatenbank eingerichtet haben, können Sie den RAG-Ansatz zur Grundursachendiagnose testen, indem Sie Fragen stellen wie „Mein Aktuator bewegt sich langsam, was könnte das Problem sein?“
Der nächste Schritt besteht darin, die App mit den erforderlichen Bibliothekspaketen entweder auf Ihrem PC oder einer EC2-Instanz (Ubuntu Server 22.04 LTS) bereitzustellen.
- Richten Sie Ihre AWS-Anmeldeinformationen ein mit der AWS CLI auf Ihrem lokalen PC. Der Einfachheit halber können Sie dieselbe Administratorrolle verwenden, die Sie für die Bereitstellung des CloudFormation-Stacks verwendet haben. Wenn Sie Amazon EC2 verwenden, Fügen Sie der Instanz eine geeignete IAM-Rolle hinzu.
- Clone GitHub Repo:
- Ändern Sie das Verzeichnis zu
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcund renne diesetup.shSkript in diesem Ordner, um die erforderlichen Pakete zu installieren, einschließlich LangChain und PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Führen Sie die Streamlit-App mit dem folgenden Befehl aus:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Geben Sie den OpenSearch Service-Sammlungs-ARN an, den Sie im vorherigen Schritt in Amazon Bedrock erstellt haben.
Chatten Sie mit Ihrem Asset-Health-Assistenten
Nachdem Sie die End-to-End-Bereitstellung abgeschlossen haben, können Sie über localhost auf Port 8501 auf die App zugreifen, wodurch ein Browserfenster mit der Weboberfläche geöffnet wird. Wenn Sie die App auf einer EC2-Instanz bereitgestellt haben, Erlauben Sie den Zugriff auf Port 8501 über die Eingangsregel der Sicherheitsgruppe. Sie können für verschiedene Anwendungsfälle zu verschiedenen Registerkarten navigieren.
Entdecken Sie Anwendungsfall 1
Um den ersten Anwendungsfall zu erkunden, wählen Sie Dateneinblick und Diagramm. Beginnen Sie mit dem Hochladen Ihrer Zeitreihendaten. Wenn Sie keine vorhandene Zeitreihendatendatei zur Verwendung haben, können Sie Folgendes hochladen Beispiel-CSV-Datei mit anonymen Amazon Monitron-Projektdaten. Wenn Sie bereits über ein Amazon Monitron-Projekt verfügen, finden Sie weitere Informationen unter Generieren Sie umsetzbare Erkenntnisse für das vorausschauende Wartungsmanagement mit Amazon Monitron und Amazon Kinesis um Ihre Amazon Monitron-Daten an Amazon S3 zu streamen und Ihre Daten mit dieser Anwendung zu verwenden.
Wenn der Upload abgeschlossen ist, geben Sie eine Abfrage ein, um eine Konversation mit Ihren Daten zu initiieren. Die linke Seitenleiste bietet eine Reihe von Beispielfragen für Ihre Bequemlichkeit. Die folgenden Screenshots veranschaulichen die Antwort und den Python-Code, der vom FM generiert wird, wenn eine Frage wie „Sagen Sie mir die eindeutige Anzahl von Sensoren für jeden Standort, der als Warnung bzw. Alarm angezeigt wird?“ eingegeben wird. (eine schwierige Frage) oder „Können Sie für Sensoren, deren Temperatursignal als NICHT fehlerfrei angezeigt wird, die Zeitdauer in Tagen für jeden Sensor berechnen, der ein abnormales Vibrationssignal anzeigt?“ (eine Frage auf Herausforderungsniveau). Die App beantwortet Ihre Frage und zeigt auch das Python-Skript der Datenanalyse an, die zur Generierung solcher Ergebnisse durchgeführt wurde.


Wenn Sie mit der Antwort zufrieden sind, können Sie sie als markieren Hilfreich, wodurch der von NLQ und Claude generierte Python-Code in einem OpenSearch Service-Index gespeichert wird.

Entdecken Sie Anwendungsfall 2
Um den zweiten Anwendungsfall zu erkunden, wählen Sie die aus Zusammenfassung der aufgenommenen Bilder Registerkarte in der Streamlit-App. Sie können ein Bild Ihrer Industrieanlage hochladen und die Anwendung erstellt auf der Grundlage der Bildinformationen eine 200-Wörter-Zusammenfassung der technischen Spezifikationen und des Betriebszustands. Der folgende Screenshot zeigt die Zusammenfassung, die aus einem Bild eines Riemenmotorantriebs erstellt wurde. Um diese Funktion zu testen, können Sie Folgendes verwenden, wenn Ihnen ein geeignetes Bild fehlt Beispielbild.
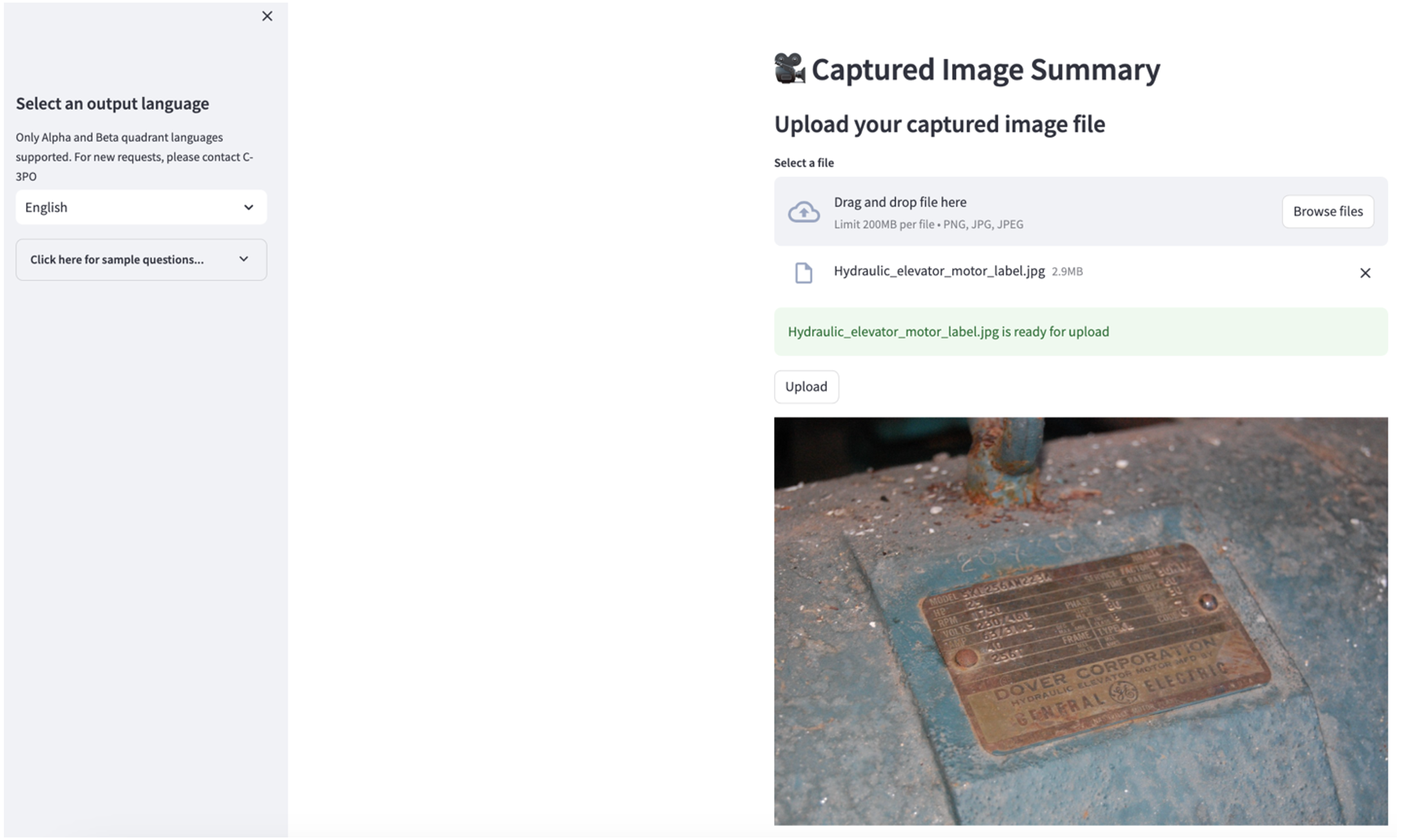
Etikett für hydraulischen Aufzugsmotor” von Clarence Risher ist lizenziert unter CC BY-SA 2.0.

Entdecken Sie Anwendungsfall 3
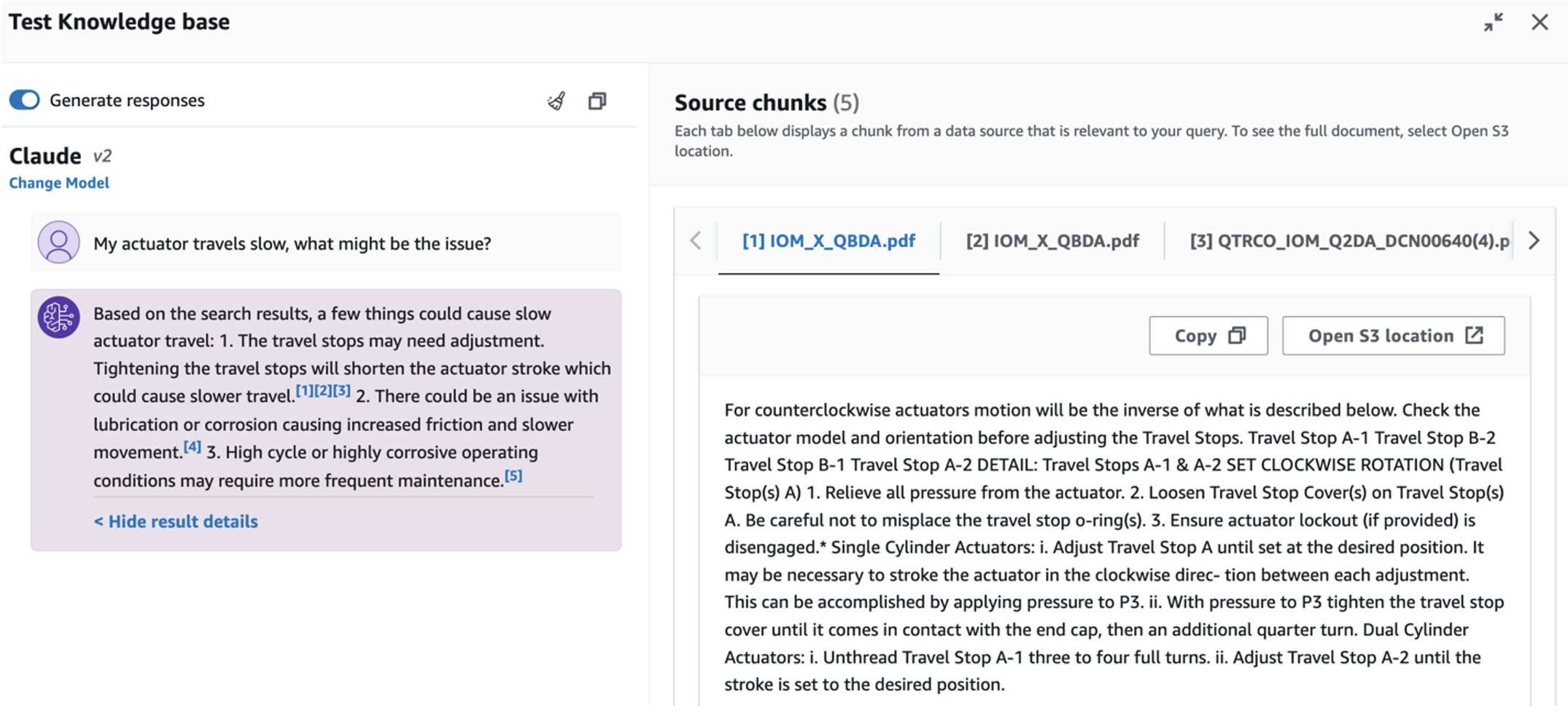
Um den dritten Anwendungsfall zu erkunden, wählen Sie Ursachendiagnose Tab. Geben Sie eine Frage ein, die sich auf Ihre defekte Industrieanlage bezieht, z. B. „Mein Aktuator bewegt sich langsam, was könnte das Problem sein?“ Wie im folgenden Screenshot dargestellt, liefert die Anwendung eine Antwort mit dem Quelldokumentauszug, der zum Generieren der Antwort verwendet wurde.
Anwendungsfall 1: Designdetails
In diesem Abschnitt besprechen wir die Designdetails des Anwendungsworkflows für den ersten Anwendungsfall.
Benutzerdefinierte Eingabeaufforderungserstellung
Die natürliche Sprachabfrage des Benutzers weist verschiedene Schwierigkeitsstufen auf: einfach, schwer und herausfordernd.
Einfache Fragen können die folgenden Anfragen umfassen:
- Wählen Sie eindeutige Werte aus
- Zählen Sie die Gesamtzahl
- Werte sortieren
Für diese Fragen kann PandasAI direkt mit dem FM interagieren, um Python-Skripte zur Verarbeitung zu generieren.
Schwierige Fragen erfordern grundlegende Aggregationsoperationen oder Zeitreihenanalysen, wie zum Beispiel die folgenden:
- Wählen Sie zuerst den Wert aus und gruppieren Sie die Ergebnisse hierarchisch
- Führen Sie Statistiken nach der ersten Datensatzauswahl durch
- Zeitstempelanzahl (z. B. Min. und Max.)
Bei schwierigen Fragen unterstützt eine Eingabeaufforderungsvorlage mit detaillierten Schritt-für-Schritt-Anleitungen FMs bei der Bereitstellung präziser Antworten.
Fragen auf Herausforderungsebene erfordern fortgeschrittene mathematische Berechnungen und Zeitreihenverarbeitung, wie zum Beispiel die folgenden:
- Berechnen Sie die Anomaliedauer für jeden Sensor
- Berechnen Sie monatlich Anomaliesensoren für den Standort
- Vergleichen Sie die Sensorwerte unter normalen Betriebsbedingungen und unter anormalen Bedingungen
Für diese Fragen können Sie Mehrfachschüsse in einer benutzerdefinierten Eingabeaufforderung verwenden, um die Antwortgenauigkeit zu verbessern. Solche Mehrfachaufnahmen zeigen Beispiele für fortgeschrittene Zeitreihenverarbeitung und mathematische Berechnungen und liefern dem FM Kontext, um relevante Rückschlüsse auf ähnliche Analysen zu ziehen. Das dynamische Einfügen der relevantesten Beispiele aus einer NLQ-Fragendatenbank in die Eingabeaufforderung kann eine Herausforderung sein. Eine Lösung besteht darin, Einbettungen aus vorhandenen NLQ-Fragenbeispielen zu erstellen und diese Einbettungen in einem Vektorspeicher wie OpenSearch Service zu speichern. Wenn eine Frage an die Streamlit-App gesendet wird, wird die Frage von vektorisiert GrundgesteinEinbettungen. Die N-relevantesten Einbettungen zu dieser Frage werden mit abgerufen opensearch_vector_search.similarity_search und als Multi-Shot-Prompt in die Prompt-Vorlage eingefügt.
Das folgende Diagramm veranschaulicht diesen Workflow.
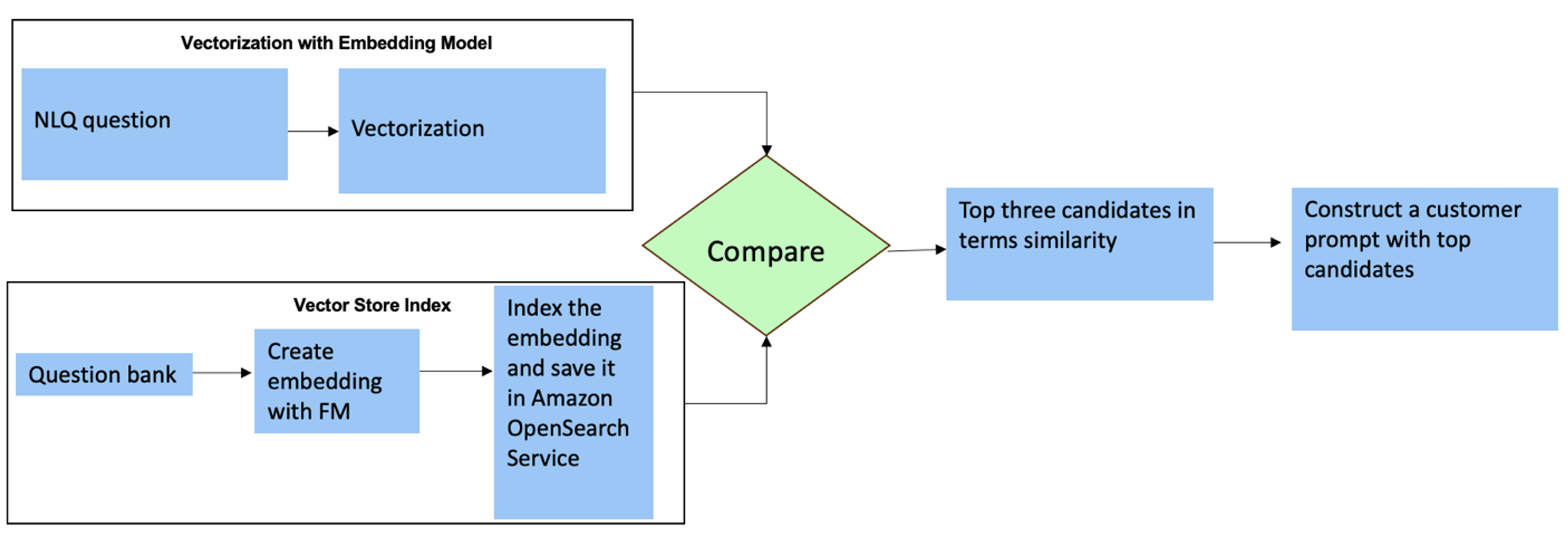
Die Einbettungsschicht wird mit drei Schlüsselwerkzeugen erstellt:
- Einbettungsmodell – Wir verwenden Amazon Titan Embeddings, erhältlich über Amazon Bedrock (amazon.titan-embed-text-v1), um numerische Darstellungen von Textdokumenten zu generieren.
- Vektorspeicher – Für unseren Vektorspeicher verwenden wir OpenSearch Service über das LangChain-Framework und optimieren so die Speicherung von Einbettungen, die aus NLQ-Beispielen in diesem Notebook generiert wurden.
- Index – Der OpenSearch Service-Index spielt eine entscheidende Rolle beim Vergleich von Eingabeeinbettungen mit Dokumenteinbettungen und erleichtert das Abrufen relevanter Dokumente. Da die Python-Beispielcodes als JSON-Datei gespeichert wurden, wurden sie im OpenSearch Service als Vektoren über eine indiziert OpenSearchVevtorSearch.fromtexts API-Aufruf.
Kontinuierliche Sammlung von von Menschen geprüften Beispielen über Streamlit
Zu Beginn der App-Entwicklung begannen wir mit nur 23 gespeicherten Beispielen im OpenSearch Service-Index als Einbettungen. Sobald die App im Feld live geht, beginnen Benutzer mit der Eingabe ihrer NLQs über die App. Aufgrund der begrenzten Beispiele, die in der Vorlage verfügbar sind, finden einige NLQs jedoch möglicherweise keine ähnlichen Eingabeaufforderungen. Um diese Einbettungen kontinuierlich zu bereichern und relevantere Benutzeraufforderungen anzubieten, können Sie die Streamlit-App zum Sammeln von von Menschen geprüften Beispielen verwenden.
Hierzu dient innerhalb der App die folgende Funktion. Wenn Endbenutzer die Ausgabe hilfreich finden und auswählen Hilfreich, die Anwendung folgt diesen Schritten:
- Verwenden Sie die Callback-Methode von PandasAI, um das Python-Skript zu erfassen.
- Formatieren Sie das Python-Skript, die Eingabefrage und die CSV-Metadaten in eine Zeichenfolge neu.
- Überprüfen Sie mithilfe von, ob dieses NLQ-Beispiel bereits im aktuellen OpenSearch-Service-Index vorhanden ist opensearch_vector_search.similarity_search_with_score.
- Wenn es kein ähnliches Beispiel gibt, wird diese NLQ mit zum OpenSearch Service-Index hinzugefügt opensearch_vector_search.add_texts.
Für den Fall, dass ein Benutzer auswählt Nicht hilfreich, es wird keine Aktion durchgeführt. Dieser iterative Prozess stellt sicher, dass sich das System kontinuierlich verbessert, indem von Benutzern beigesteuerte Beispiele einbezogen werden.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Durch die Einbeziehung menschlicher Prüfungen wächst die Anzahl der Beispiele im OpenSearch Service, die für eine sofortige Einbettung verfügbar sind, mit zunehmender Nutzung der App. Dieser erweiterte Einbettungsdatensatz führt im Laufe der Zeit zu einer verbesserten Suchgenauigkeit. Insbesondere bei anspruchsvollen NLQs erreicht die FM-Antwortgenauigkeit etwa 90 %, wenn ähnliche Beispiele dynamisch eingefügt werden, um benutzerdefinierte Eingabeaufforderungen für jede NLQ-Frage zu erstellen. Dies entspricht einer beachtlichen Steigerung von 28 % im Vergleich zu Szenarien ohne Mehrfachschuss-Eingabeaufforderungen.
Anwendungsfall 2: Designdetails
Auf der Streamlit-App Zusammenfassung der aufgenommenen Bilder Auf der Registerkarte können Sie direkt eine Bilddatei hochladen. Dies initiiert die Amazon Rekognition API (Erkennungstext API) und extrahiert Text aus dem Bildetikett mit detaillierten Angaben zu den Maschinenspezifikationen. Anschließend werden die extrahierten Textdaten als Kontext einer Eingabeaufforderung an das Amazon Bedrock Claude-Modell gesendet, wodurch eine Zusammenfassung mit 200 Wörtern entsteht.
Aus Sicht des Benutzererlebnisses ist die Aktivierung der Streaming-Funktionalität für eine Textzusammenfassungsaufgabe von größter Bedeutung, damit Benutzer die FM-generierte Zusammenfassung in kleineren Abschnitten lesen können, anstatt auf die gesamte Ausgabe warten zu müssen. Amazon Bedrock erleichtert das Streaming über seine API (bedrock_runtime.invoke_model_with_response_stream).
Anwendungsfall 3: Designdetails
In diesem Szenario haben wir unter Verwendung des RAG-Ansatzes eine Chatbot-Anwendung entwickelt, die sich auf die Ursachenanalyse konzentriert. Dieser Chatbot greift auf mehrere Dokumente zu Lagerausrüstung zurück, um die Ursachenanalyse zu erleichtern. Dieser RAG-basierte Chatbot zur Ursachenanalyse nutzt Wissensdatenbanken zum Generieren von Vektortextdarstellungen oder Einbettungen. Knowledge Bases für Amazon Bedrock ist eine vollständig verwaltete Funktion, die Sie bei der Implementierung des gesamten RAG-Workflows unterstützt, von der Aufnahme über den Abruf bis hin zur sofortigen Erweiterung, ohne benutzerdefinierte Integrationen für Datenquellen erstellen oder Datenflüsse und RAG-Implementierungsdetails verwalten zu müssen.
Wenn Sie mit der Wissensdatenbank-Antwort von Amazon Bedrock zufrieden sind, können Sie die Grundursachen-Antwort aus der Wissensdatenbank in die Streamlit-App integrieren.
Aufräumen
Um Kosten zu sparen, löschen Sie die Ressourcen, die Sie in diesem Beitrag erstellt haben:
- Löschen Sie die Wissensdatenbank aus Amazon Bedrock.
- Löschen Sie den OpenSearch Service-Index.
- Löschen Sie den genai-sagemaker CloudFormation-Stack.
- Stoppen Sie die EC2-Instanz, wenn Sie eine EC2-Instanz zum Ausführen der Streamlit-App verwendet haben.
Zusammenfassung
Generative KI-Anwendungen haben bereits verschiedene Geschäftsprozesse verändert und die Produktivität und Fähigkeiten der Mitarbeiter verbessert. Die Einschränkungen von FMs bei der Analyse von Zeitreihendaten haben jedoch ihre vollständige Nutzung durch Industriekunden behindert. Diese Einschränkung hat die Anwendung generativer KI auf den vorherrschenden Datentyp, der täglich verarbeitet wird, behindert.
In diesem Beitrag haben wir eine generative KI-Anwendungslösung vorgestellt, die diese Herausforderung für industrielle Anwender lindern soll. Diese Anwendung verwendet einen Open-Source-Agenten, PandasAI, um die Zeitreihenanalysefähigkeit eines FM zu stärken. Anstatt Zeitreihendaten direkt an FMs zu senden, nutzt die App PandasAI, um Python-Code für die Analyse unstrukturierter Zeitreihendaten zu generieren. Um die Genauigkeit der Python-Codegenerierung zu verbessern, wurde ein benutzerdefinierter Workflow zur Eingabeaufforderungsgenerierung mit menschlicher Prüfung implementiert.
Mit Einblicken in den Zustand ihrer Anlagen können Industriearbeiter das Potenzial der generativen KI in verschiedenen Anwendungsfällen, einschließlich der Ursachendiagnose und der Planung des Teileaustauschs, voll ausschöpfen. Mit Knowledge Bases für Amazon Bedrock ist die RAG-Lösung für Entwickler einfach zu erstellen und zu verwalten.
Die Entwicklung des Unternehmensdatenmanagements und -betriebs geht eindeutig in Richtung einer tieferen Integration mit generativer KI, um umfassende Einblicke in den Betriebszustand zu erhalten. Dieser von Amazon Bedrock angeführte Wandel wird durch die wachsende Robustheit und das wachsende Potenzial von LLMs wie z. B. erheblich verstärkt Amazon Bedrock Claude 3 Lösungen weiter zu verbessern. Um mehr zu erfahren, besuchen Sie die Seite Amazon Bedrock-Dokumentation, und machen Sie sich mit dem vertraut Amazon Bedrock-Workshop.
Über die Autoren
 Julia Hu ist Senior AI/ML Solutions Architect bei Amazon Web Services. Sie ist spezialisiert auf generative KI, angewandte Datenwissenschaft und IoT-Architektur. Derzeit ist sie Teil des Amazon Q-Teams und aktives Mitglied/Mentorin der Machine Learning Technical Field Community. Sie arbeitet mit Kunden, von Start-ups bis hin zu Unternehmen, zusammen, um einige generative KI-Lösungen zu entwickeln. Ihre besondere Leidenschaft gilt der Nutzung großer Sprachmodelle für erweiterte Datenanalysen und der Erforschung praktischer Anwendungen, die reale Herausforderungen angehen.
Julia Hu ist Senior AI/ML Solutions Architect bei Amazon Web Services. Sie ist spezialisiert auf generative KI, angewandte Datenwissenschaft und IoT-Architektur. Derzeit ist sie Teil des Amazon Q-Teams und aktives Mitglied/Mentorin der Machine Learning Technical Field Community. Sie arbeitet mit Kunden, von Start-ups bis hin zu Unternehmen, zusammen, um einige generative KI-Lösungen zu entwickeln. Ihre besondere Leidenschaft gilt der Nutzung großer Sprachmodelle für erweiterte Datenanalysen und der Erforschung praktischer Anwendungen, die reale Herausforderungen angehen.
 Sudeesh Sasidharan ist Senior Solutions Architect bei AWS im Energieteam. Sudeesh liebt es, mit neuen Technologien zu experimentieren und innovative Lösungen zu entwickeln, die komplexe geschäftliche Herausforderungen lösen. Wenn er nicht gerade Lösungen entwirft oder an den neuesten Technologien bastelt, findet man ihn auf dem Tennisplatz bei der Arbeit an seiner Rückhand.
Sudeesh Sasidharan ist Senior Solutions Architect bei AWS im Energieteam. Sudeesh liebt es, mit neuen Technologien zu experimentieren und innovative Lösungen zu entwickeln, die komplexe geschäftliche Herausforderungen lösen. Wenn er nicht gerade Lösungen entwirft oder an den neuesten Technologien bastelt, findet man ihn auf dem Tennisplatz bei der Arbeit an seiner Rückhand.
 Neil Desai ist eine Führungskraft im Technologiebereich mit über 20 Jahren Erfahrung in den Bereichen künstliche Intelligenz (KI), Datenwissenschaft, Softwareentwicklung und Unternehmensarchitektur. Bei AWS leitet er ein Team von auf weltweite KI-Dienste spezialisierten Lösungsarchitekten, die Kunden beim Aufbau innovativer generativer KI-gestützter Lösungen unterstützen, Best Practices mit Kunden teilen und die Produkt-Roadmap vorantreiben. In seinen früheren Positionen bei Vestas, Honeywell und Quest Diagnostics hatte Neil Führungsrollen bei der Entwicklung und Einführung innovativer Produkte und Dienstleistungen inne, die Unternehmen dabei geholfen haben, ihre Abläufe zu verbessern, Kosten zu senken und den Umsatz zu steigern. Er setzt sich leidenschaftlich für den Einsatz von Technologie zur Lösung realer Probleme ein und ist ein strategischer Denker mit nachweislicher Erfolgsbilanz.
Neil Desai ist eine Führungskraft im Technologiebereich mit über 20 Jahren Erfahrung in den Bereichen künstliche Intelligenz (KI), Datenwissenschaft, Softwareentwicklung und Unternehmensarchitektur. Bei AWS leitet er ein Team von auf weltweite KI-Dienste spezialisierten Lösungsarchitekten, die Kunden beim Aufbau innovativer generativer KI-gestützter Lösungen unterstützen, Best Practices mit Kunden teilen und die Produkt-Roadmap vorantreiben. In seinen früheren Positionen bei Vestas, Honeywell und Quest Diagnostics hatte Neil Führungsrollen bei der Entwicklung und Einführung innovativer Produkte und Dienstleistungen inne, die Unternehmen dabei geholfen haben, ihre Abläufe zu verbessern, Kosten zu senken und den Umsatz zu steigern. Er setzt sich leidenschaftlich für den Einsatz von Technologie zur Lösung realer Probleme ein und ist ein strategischer Denker mit nachweislicher Erfolgsbilanz.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

