Amazon Relational Database Service (Amazon RDS) für MySQL Zero-ETL-Integration mit Amazon RedShift wurde angekündigt in der Vorschau auf AWS re:Invent 2023 für Amazon RDS für MySQL Version 8.0.28 oder höher. In diesem Beitrag bieten wir eine Schritt-für-Schritt-Anleitung für den Einstieg in nahezu Echtzeit-Betriebsanalysen mithilfe dieser Funktion. Dieser Beitrag ist eine Fortsetzung der Zero-ETL-Serie, die mit begann Leitfaden für die ersten Schritte für Betriebsanalysen nahezu in Echtzeit mithilfe der Zero-ETL-Integration von Amazon Aurora mit Amazon Redshift.
Herausforderungen
Kunden aus allen Branchen möchten heute Daten zu ihrem Wettbewerbsvorteil nutzen und den Umsatz und die Kundenbindung steigern, indem sie Anwendungsfälle für Analysen nahezu in Echtzeit implementieren, z. B. Personalisierungsstrategien, Betrugserkennung, Bestandsüberwachung und vieles mehr. Es gibt zwei allgemeine Ansätze zur Analyse von Betriebsdaten für diese Anwendungsfälle:
- Analysieren Sie die Daten direkt in der Betriebsdatenbank (z. B. Lesereplikate, föderierte Abfragen und Analysebeschleuniger).
- Verschieben Sie die Daten in einen Datenspeicher, der für die Ausführung anwendungsfallspezifischer Abfragen optimiert ist, beispielsweise ein Data Warehouse
Die Zero-ETL-Integration konzentriert sich auf die Vereinfachung des letztgenannten Ansatzes.
Der Prozess „Extrahieren, Transformieren und Laden“ (ETL) ist ein gängiges Muster zum Verschieben von Daten aus einer Betriebsdatenbank in ein Analyse-Data-Warehouse. Bei ELT werden die extrahierten Daten zunächst unverändert in das Ziel geladen und dann transformiert. Der Aufbau von ETL- und ELT-Pipelines kann teuer und die Verwaltung komplex sein. Bei mehreren Berührungspunkten können zeitweilige Fehler in ETL- und ELT-Pipelines zu langen Verzögerungen führen, sodass Data-Warehouse-Anwendungen veraltete oder fehlende Daten aufweisen, was wiederum zu verpassten Geschäftsmöglichkeiten führt.
Alternativ eignen sich Lösungen, die Daten vor Ort analysieren, möglicherweise hervorragend zur Beschleunigung von Abfragen in einer einzelnen Datenbank. Solche Lösungen sind jedoch nicht in der Lage, Daten aus mehreren Betriebsdatenbanken für Kunden zu aggregieren, die einheitliche Analysen ausführen müssen.
Null-ETL
Im Gegensatz zu herkömmlichen Systemen, bei denen Daten in einer Datenbank isoliert sind und der Benutzer einen Kompromiss zwischen einheitlicher Analyse und Leistung eingehen muss, können Dateningenieure jetzt Daten aus mehreren RDS-für-MySQL-Datenbanken in einem einzigen Redshift-Data-Warehouse replizieren, um ganzheitliche Erkenntnisse daraus abzuleiten viele Anwendungen oder Partitionen. Aktualisierungen in Transaktionsdatenbanken werden automatisch und kontinuierlich an Amazon Redshift weitergegeben, sodass Dateningenieure nahezu in Echtzeit über die neuesten Informationen verfügen. Es muss keine Infrastruktur verwaltet werden und die Integration kann je nach Datenvolumen automatisch nach oben oder unten skaliert werden.
Bei AWS haben wir stetige Fortschritte bei der Umsetzung unserer gemacht Zero-ETL-Vision zum Leben. Die folgenden Quellen werden derzeit für Zero-ETL-Integrationen unterstützt:
Wenn Sie eine Zero-ETL-Integration für Amazon Redshift erstellen, zahlen Sie weiterhin für die Nutzung der zugrunde liegenden Quelldatenbank und der Zieldatenbank von Redshift. Beziehen auf Zero-ETL-Integrationskosten (Vorschau) für weitere Details.
Bei der Zero-ETL-Integration mit Amazon Redshift repliziert die Integration Daten aus der Quelldatenbank in das Ziel-Data Warehouse. Die Daten stehen innerhalb von Sekunden in Amazon Redshift zur Verfügung, sodass Sie die Analysefunktionen von Amazon Redshift und Funktionen wie Datenfreigabe, autonome Arbeitslastoptimierung, Parallelitätsskalierung, maschinelles Lernen und vieles mehr nutzen können. Sie können mit Ihrer Transaktionsverarbeitung auf Amazon RDS fortfahren oder Amazonas-Aurora bei gleichzeitiger Nutzung von Amazon Redshift für Analyse-Workloads wie Berichte und Dashboards.
Das folgende Diagramm veranschaulicht diese Architektur.
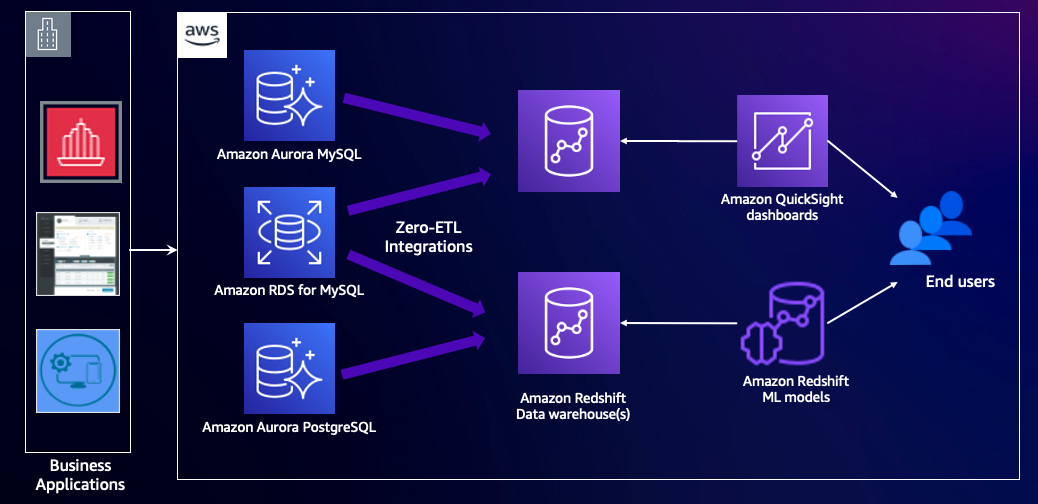
Lösungsüberblick
Lassen Sie uns überlegen KREUZEN SIE AN, eine fiktive Website, auf der Benutzer online Tickets für Sportveranstaltungen, Shows und Konzerte kaufen und verkaufen. Die Transaktionsdaten dieser Website werden in eine Datenbank von Amazon RDS für MySQL 8.0.28 (oder höher) geladen. Die Geschäftsanalysten des Unternehmens möchten Kennzahlen generieren, um Ticketbewegungen im Laufe der Zeit, Erfolgsraten für Verkäufer sowie die meistverkauften Veranstaltungen, Veranstaltungsorte und Saisons zu ermitteln. Sie möchten diese Kennzahlen mithilfe einer Zero-ETL-Integration nahezu in Echtzeit erhalten.
Die Integration wird zwischen Amazon RDS für MySQL (Quelle) und Amazon Redshift (Ziel) eingerichtet. Die Transaktionsdaten von der Quelle werden nahezu in Echtzeit am Ziel aktualisiert, das analytische Abfragen verarbeitet.
Sie können entweder die serverlose Option oder einen verschlüsselten RA3-Cluster für Amazon Redshift verwenden. Für diesen Beitrag verwenden wir eine bereitgestellte RDS-Datenbank und ein von Redshift bereitgestelltes Data Warehouse.
Das folgende Diagramm veranschaulicht die High-Level-Architektur.
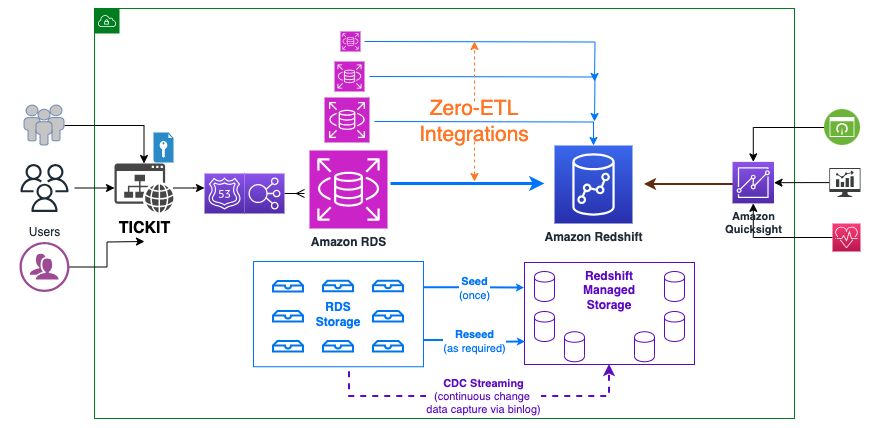
Im Folgenden sind die Schritte aufgeführt, die zum Einrichten der Zero-ETL-Integration erforderlich sind. Diese Schritte können vom Zero-ETL-Assistenten automatisch durchgeführt werden, Sie benötigen jedoch einen Neustart, wenn der Assistent die Einstellung für Amazon RDS oder Amazon Redshift ändert. Sie können diese Schritte manuell ausführen, sofern sie nicht bereits konfiguriert sind, und die Neustarts nach Belieben durchführen. Die vollständigen Anleitungen für die ersten Schritte finden Sie unter Arbeiten mit Amazon RDS Zero-ETL-Integrationen mit Amazon Redshift (Vorschau) und Arbeiten mit Zero-ETL-Integrationen.
- Konfigurieren Sie die RDS für MySQL-Quelle mit einer benutzerdefinierten DB-Parametergruppe.
- Konfigurieren Sie den Redshift-Cluster, um Bezeichner zu aktivieren, bei denen die Groß-/Kleinschreibung beachtet wird.
- Konfigurieren Sie die erforderlichen Berechtigungen.
- Erstellen Sie die Zero-ETL-Integration.
- Erstellen Sie eine Datenbank aus der Integration in Amazon Redshift.
Konfigurieren Sie die RDS für MySQL-Quelle mit einer benutzerdefinierten DB-Parametergruppe
Führen Sie die folgenden Schritte aus, um eine RDS-für-MySQL-Datenbank zu erstellen:
- Erstellen Sie auf der Amazon RDS-Konsole eine DB-Parametergruppe mit dem Namen
zero-etl-custom-pg.
Die Zero-ETL-Integration funktioniert mithilfe von Binärprotokollen (Binlogs), die von der MySQL-Datenbank generiert werden. Um Binlogs auf Amazon RDS für MySQL zu aktivieren, muss ein bestimmter Parametersatz aktiviert werden.
- Legen Sie die folgenden Parametereinstellungen für den Binlog-Cluster fest:
binlog_format = ROWbinlog_row_image = FULLbinlog_checksum = NONE
Stellen Sie außerdem sicher, dass die binlog_row_value_options Parameter ist nicht auf eingestellt PARTIAL_JSON. Standardmäßig ist dieser Parameter nicht festgelegt.
- Auswählen Datenbanken im Navigationsbereich und wählen Sie dann aus Datenbank erstellen.
- Aussichten für Motor Version, wählen MySQL 8.0.28 (oder höher).

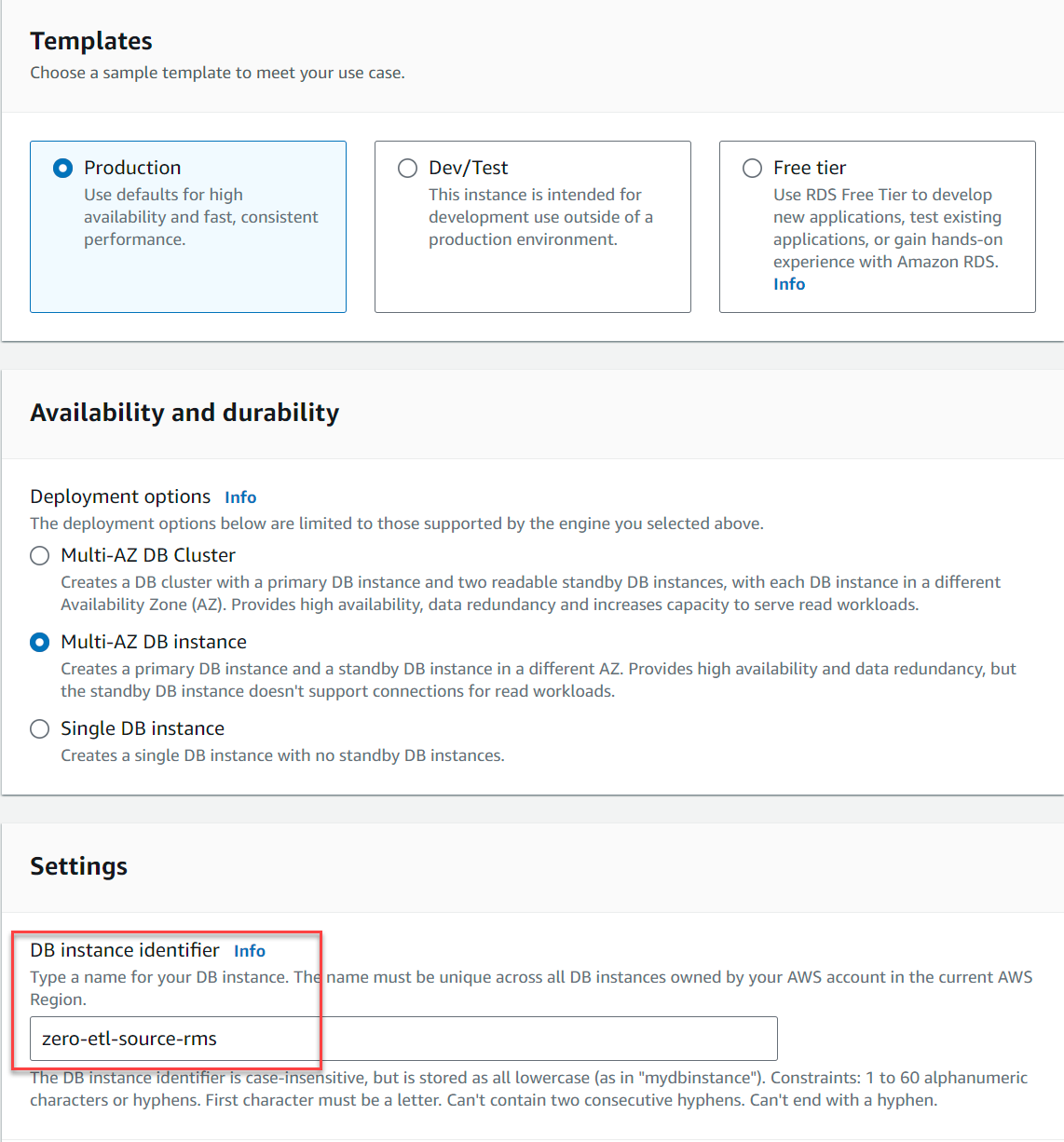
- Aussichten für TemplateWählen Produktion.
- Aussichten für Verfügbarkeit und Haltbarkeit, wählen Sie entweder Multi-AZ-DB-Instanz or Einzelne DB-Instanz (Multi-AZ-DB-Cluster werden zum jetzigen Zeitpunkt nicht unterstützt.)
- Aussichten für DB-Instance-ID, eingeben
zero-etl-source-rms.
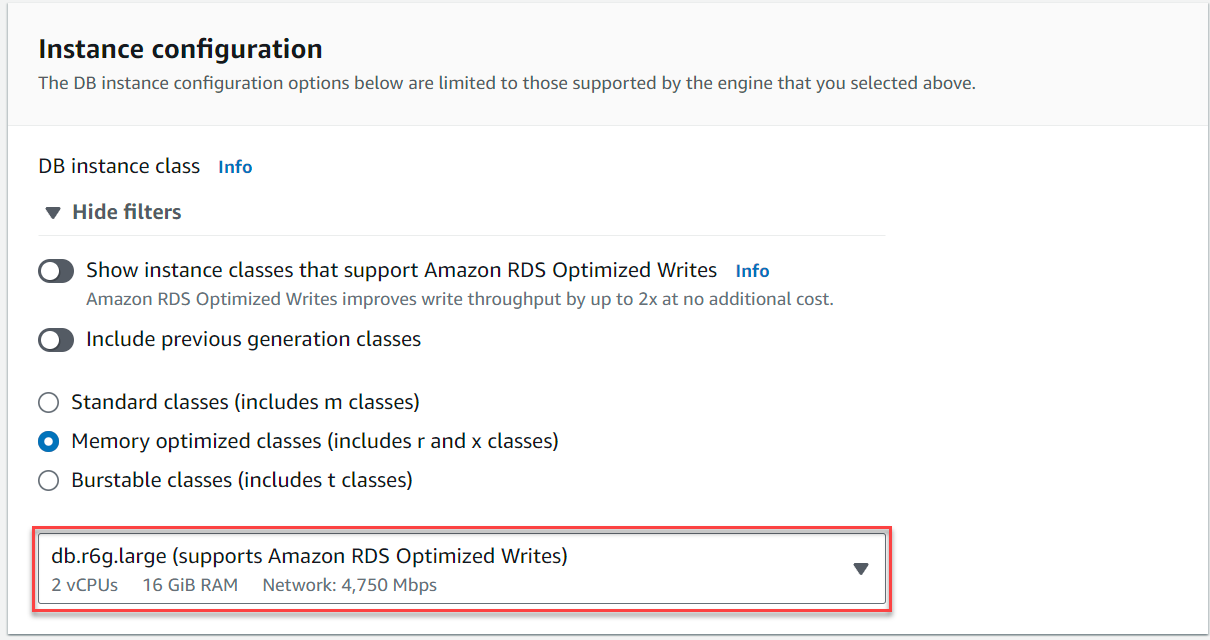
- Der InstanzkonfigurationWählen Speicheroptimierte Klassen und wählen Sie die Instanz aus
db.r6g.large, was für den TICKIT-Anwendungsfall ausreichend sein sollte.
- Der Zusätzliche KonfigurationZ. DB-Cluster-Parametergruppe, wählen Sie die Parametergruppe aus, die Sie zuvor erstellt haben (
zero-etl-custom-pg).
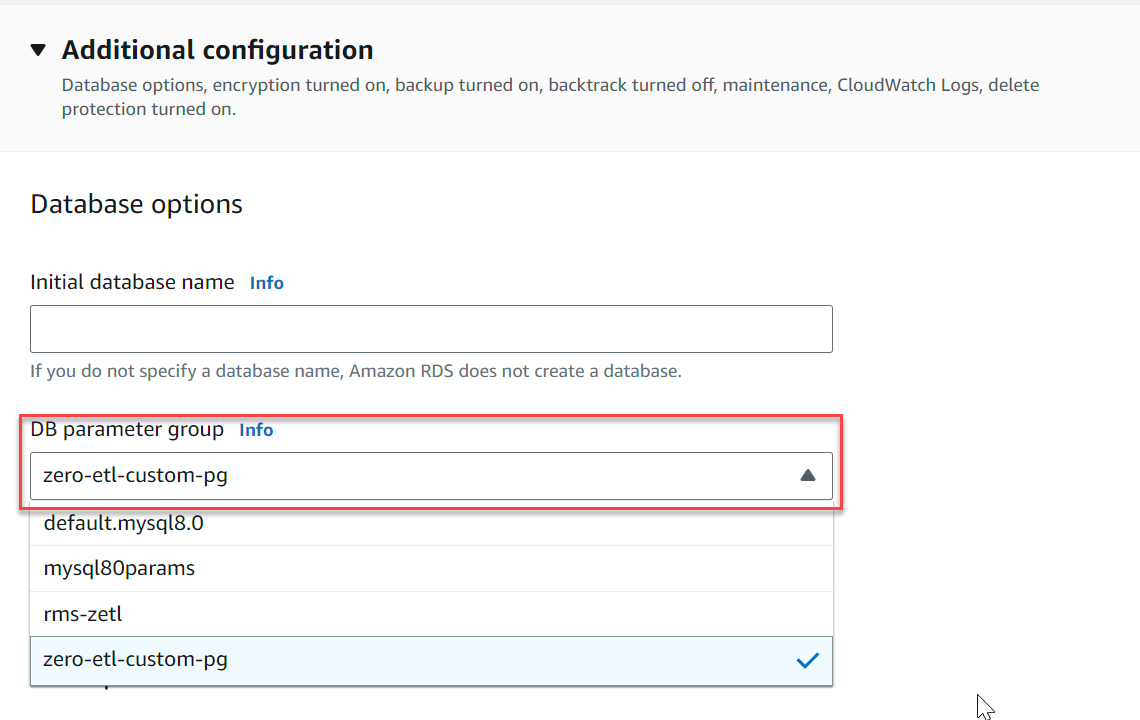
- Auswählen Datenbank erstellen.
In ein paar Minuten sollte eine RDS-für-MySQL-Datenbank als Quelle für die Zero-ETL-Integration eingerichtet sein.
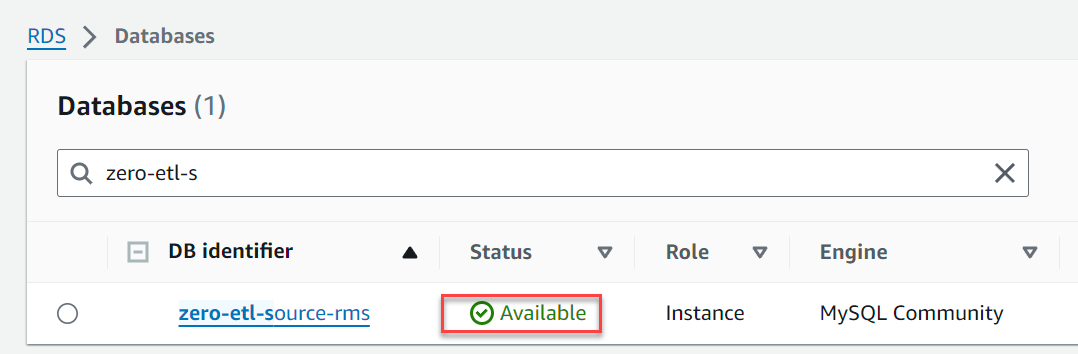
Konfigurieren Sie das Redshift-Ziel
Nachdem Sie Ihren Quell-DB-Cluster erstellt haben, müssen Sie ein Ziel-Data Warehouse in Amazon Redshift erstellen und konfigurieren. Das Data Warehouse muss folgende Anforderungen erfüllen:
- Verwendung eines RA3-Knotentyps (
ra3.16xlarge,ra3.4xlarge, oderra3.xlplusoder Amazon Redshift ohne Server - Verschlüsselt (bei Verwendung eines bereitgestellten Clusters)
Erstellen Sie für unseren Anwendungsfall einen Redshift-Cluster, indem Sie die folgenden Schritte ausführen:
- Wählen Sie in der Amazon Redshift-Konsole aus Konfigurationen und dann wählen Workload-Management.
- Wählen Sie im Abschnitt „Parametergruppe“ die Option aus Erstellen.
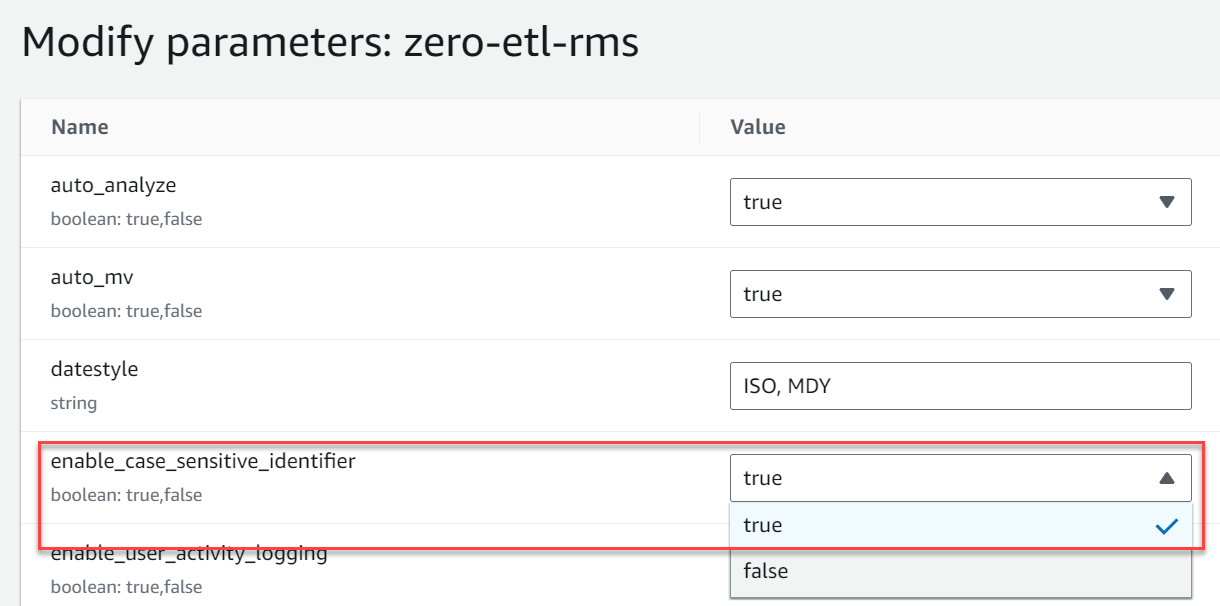
- Erstellen Sie eine neue Parametergruppe mit dem Namen
zero-etl-rms. - Auswählen
Parameter bearbeiten und ändere den Wert von
enable_case_sensitive_identifierzuTrue. - Auswählen Speichern.
Sie können auch die Tasten AWS-Befehlszeilenschnittstelle (AWS CLI)-Befehl Update-Arbeitsgruppe für Redshift Serverless:
- Auswählen Dashboard für bereitgestellte Cluster.
Oben in Ihrem Konsolenfenster sehen Sie ein Probieren Sie neue Amazon Redshift-Funktionen in der Vorschau aus Banner.
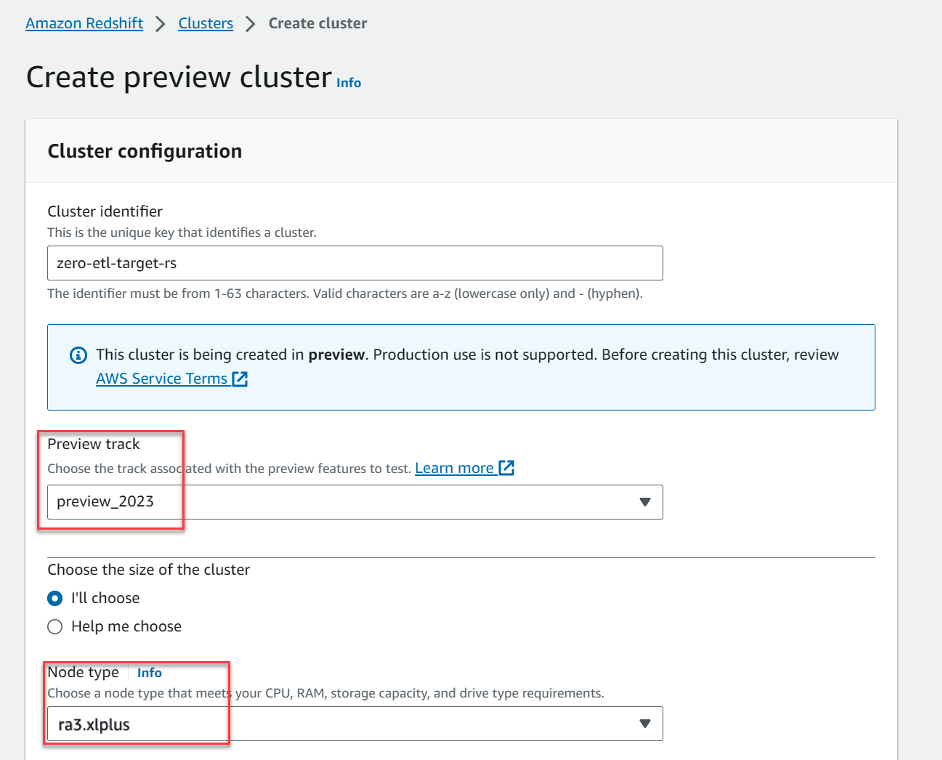
- Auswählen Vorschaucluster erstellen.

- Aussichten für Vorschau-Trackwählte
preview_2023. - Aussichten für Knotentyp, wählen Sie einen der unterstützten Knotentypen (für diesen Beitrag verwenden wir
ra3.xlplus).
- Der Zusätzliche Konfigurationen, erweitern Datenbankkonfigurationen.
- Aussichten für Parametergruppen, wählen
zero-etl-rms. - Aussichten für VerschlüsselungWählen Verwenden Sie den AWS Key Management Service.
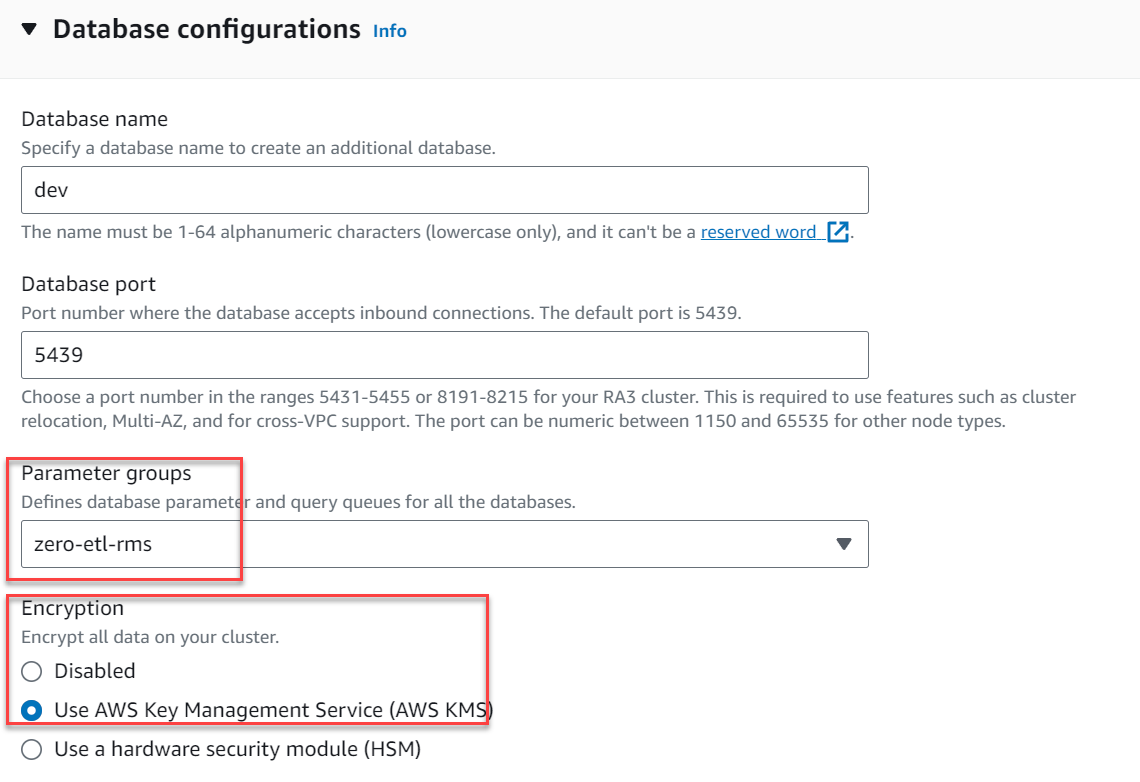
- Auswählen Cluster erstellen.
Der Cluster sollte werden Verfügbar In ein paar Minuten.

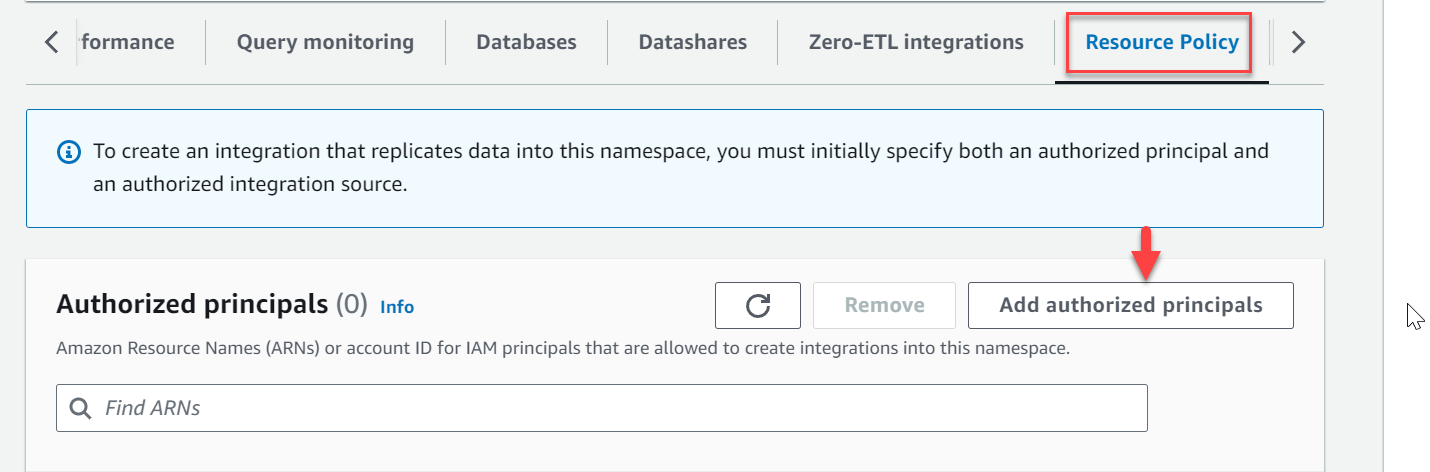
- Navigieren Sie zum Namespace
zero-etl-target-rs-nsund wähle das Ressourcenpolitik Tab. - Auswählen Fügen Sie autorisierte Auftraggeber hinzu.
- Geben Sie entweder den Amazon-Ressourcennamen (ARN) des AWS-Benutzers oder der AWS-Rolle oder die AWS-Konto-ID (IAM-Prinzipale) ein, die Integrationen erstellen dürfen.
Eine Konto-ID wird als ARN beim Root-Benutzer gespeichert.
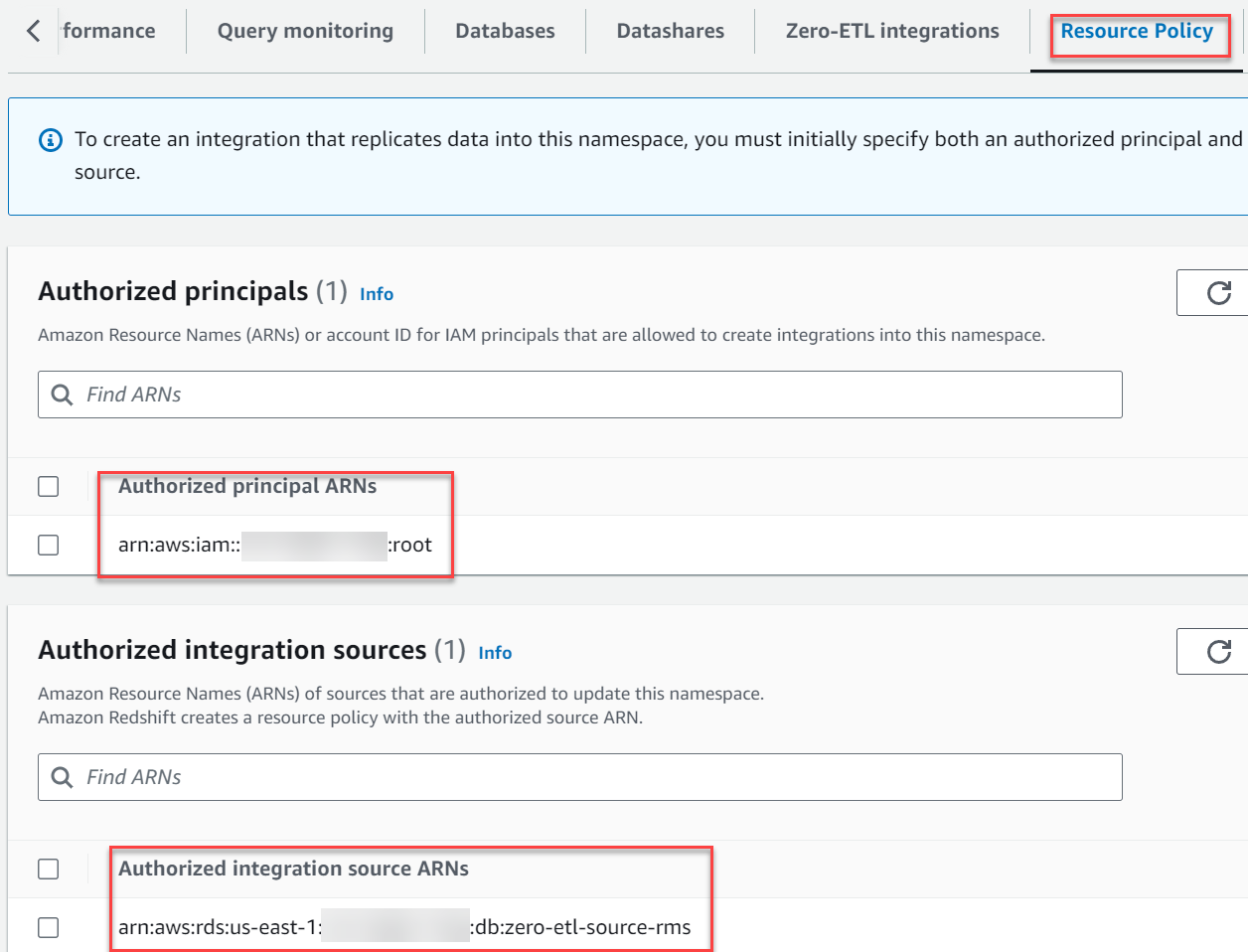
- Im Autorisierte Integrationsquellen Wählen Sie im Abschnitt Fügen Sie eine autorisierte Integrationsquelle hinzu um den ARN der RDS für MySQL-DB-Instanz hinzuzufügen, die die Datenquelle für die Zero-ETL-Integration ist.
Sie können diesen Wert finden, indem Sie zur Amazon RDS-Konsole gehen und zu navigieren Konfiguration Registerkarte der zero-etl-source-rms DB-Instanz.

Ihre Ressourcenrichtlinie sollte dem folgenden Screenshot ähneln.
Konfigurieren Sie die erforderlichen Berechtigungen
Um eine Zero-ETL-Integration zu erstellen, muss Ihr Benutzer oder Ihre Rolle über eine angehängte Datei verfügen identitätsbasierte Politik mit dem entsprechenden AWS Identity and Access Management and (IAM)-Berechtigungen. Ein AWS-Kontoinhaber kann Konfigurieren Sie die erforderlichen Berechtigungen für Benutzer oder Rollen, die Zero-ETL-Integrationen erstellen dürfen. Mit der Beispielrichtlinie kann der zugehörige Prinzipal die folgenden Aktionen ausführen:
- Erstellen Sie Zero-ETL-Integrationen für die Quell-RDS für die MySQL-DB-Instanz.
- Alle Zero-ETL-Integrationen anzeigen und löschen.
- Erstellen Sie eingehende Integrationen in das Ziel-Data-Warehouse. Diese Berechtigung ist nicht erforderlich, wenn dasselbe Konto das Redshift-Data-Warehouse besitzt und dieses Konto ein autorisierter Prinzipal für dieses Data-Warehouse ist. Beachten Sie außerdem, dass Amazon Redshift ein anderes ARN-Format für bereitgestellte und serverlose Cluster hat:
- Vorausgesetzt -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Serverlos -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Vorausgesetzt -
Führen Sie die folgenden Schritte aus, um die Berechtigungen zu konfigurieren:
- Wählen Sie in der IAM-Konsole Richtlinien im Navigationsbereich.
- Auswählen Richtlinie erstellen.
- Erstellen Sie eine neue Richtlinie namens
rds-integrationsunter Verwendung des folgenden JSON (ersetzenregionundaccount-idmit Ihren tatsächlichen Werten):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:db:source-instancename",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}
- Hängen Sie die von Ihnen erstellte Richtlinie an Ihre IAM-Benutzer- oder Rollenberechtigungen an.
Erstellen Sie die Zero-ETL-Integration
Führen Sie die folgenden Schritte aus, um die Zero-ETL-Integration zu erstellen:
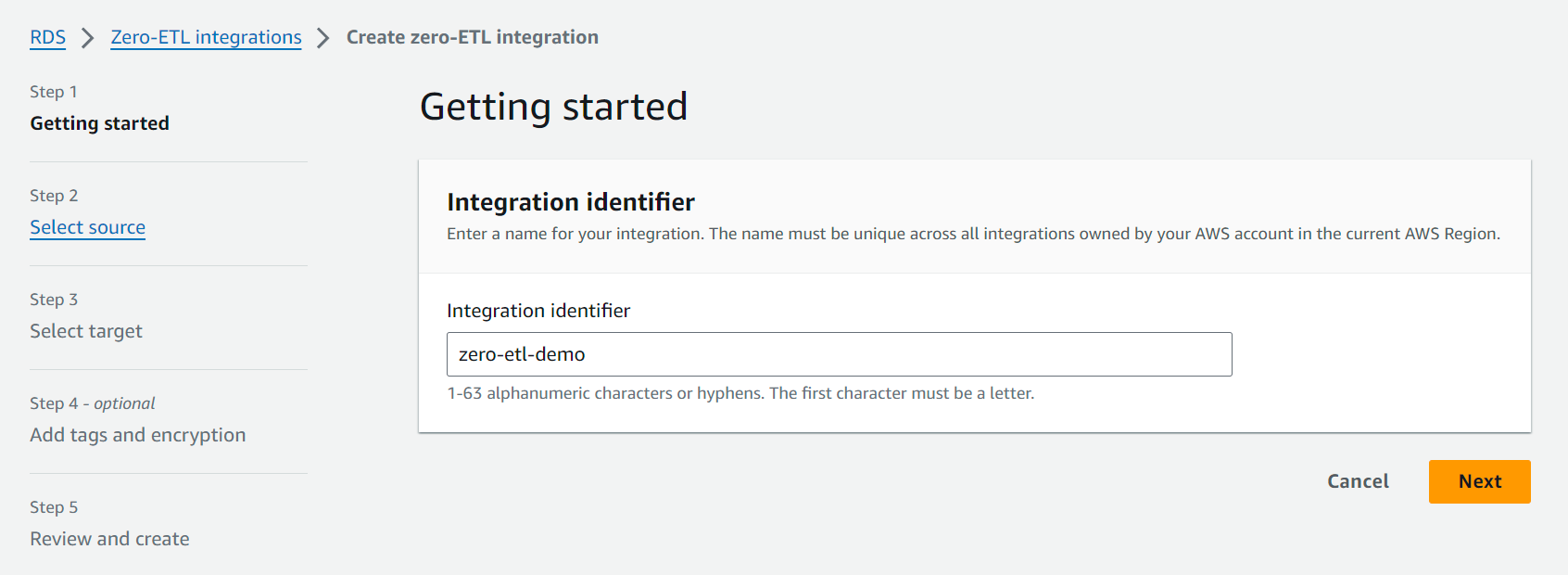
- Wählen Sie in der Amazon RDS-Konsole aus Zero-ETL-Integrationen im Navigationsbereich.
- Auswählen Erstellen Sie eine Zero-ETL-Integration.

- Aussichten für IntegrationskennungGeben Sie beispielsweise einen Namen ein
zero-etl-demo.
- Aussichten für Quelldatenbank, wählen Durchsuchen Sie RDS-Datenbanken und wählen Sie den Quellcluster aus
zero-etl-source-rms. - Auswählen Weiter.

- Der TargetZ. Amazon Redshift-Data Warehouse, wählen Durchsuchen Sie die Data Warehouses von Redshift und wählen Sie das Redshift Data Warehouse (
zero-etl-target-rs). - Auswählen Weiter.
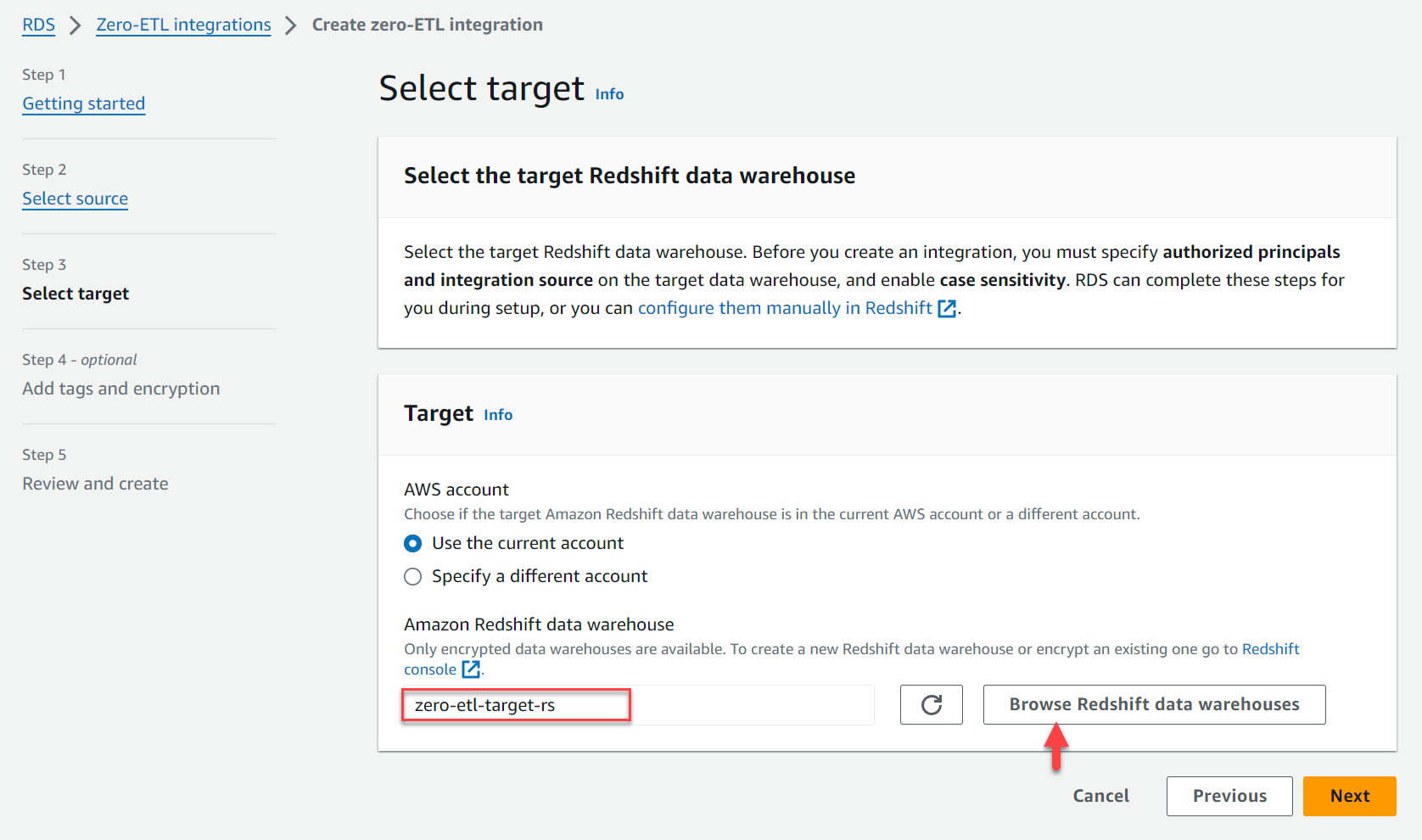
- Fügen Sie ggf. Tags und Verschlüsselung hinzu.
- Auswählen Weiter.
- Überprüfen Sie den Integrationsnamen, die Quelle, das Ziel und andere Einstellungen.
- Auswählen Erstellen Sie eine Zero-ETL-Integration.
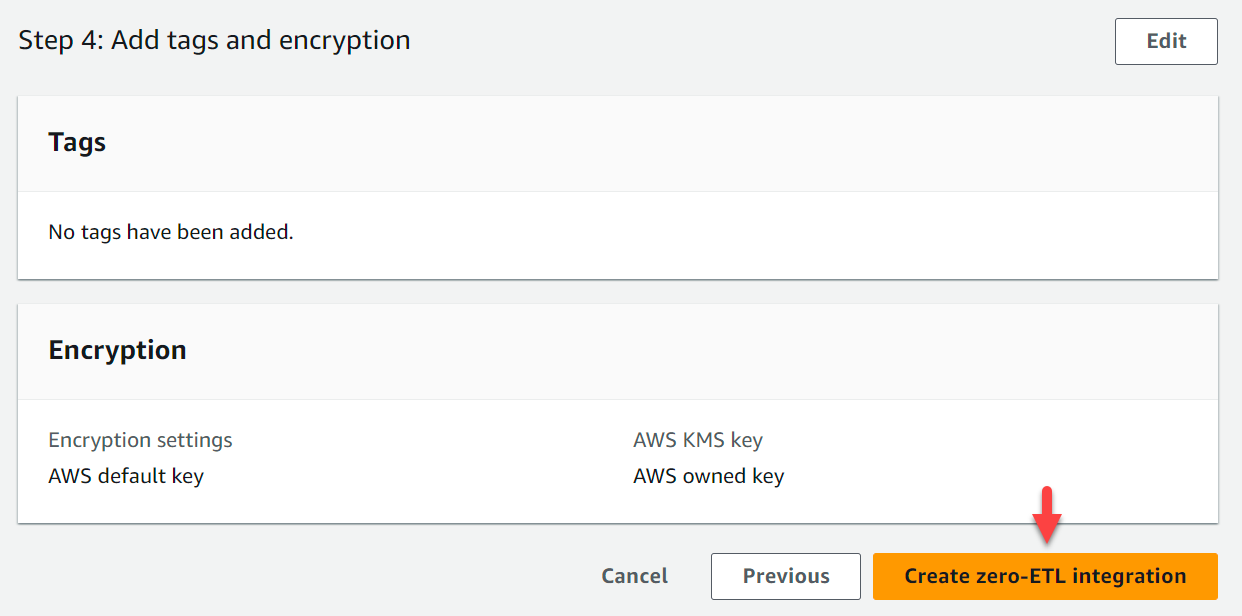
Sie können die Integration auswählen, um die Details anzuzeigen und ihren Fortschritt zu überwachen. Es dauerte etwa 30 Minuten, bis sich der Status änderte Erstellen zu Aktives.

Die Zeit variiert je nach Größe Ihres Datensatzes in der Quelle.
Erstellen Sie eine Datenbank aus der Integration in Amazon Redshift
Um Ihre Datenbank aus der Zero-ETL-Integration zu erstellen, führen Sie die folgenden Schritte aus:
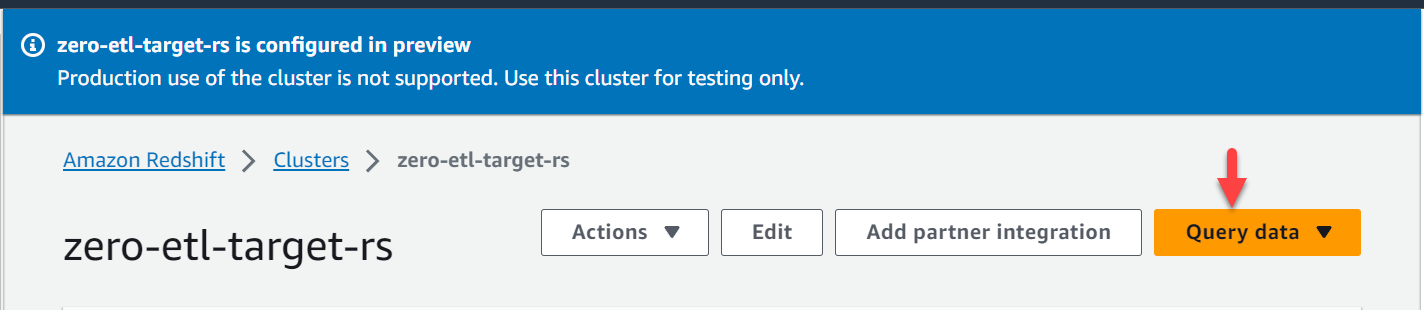
- Wählen Sie in der Amazon Redshift-Konsole aus Cluster im Navigationsbereich.
- Öffnen Sie den Microsoft Store auf Ihrem Windows-PC.
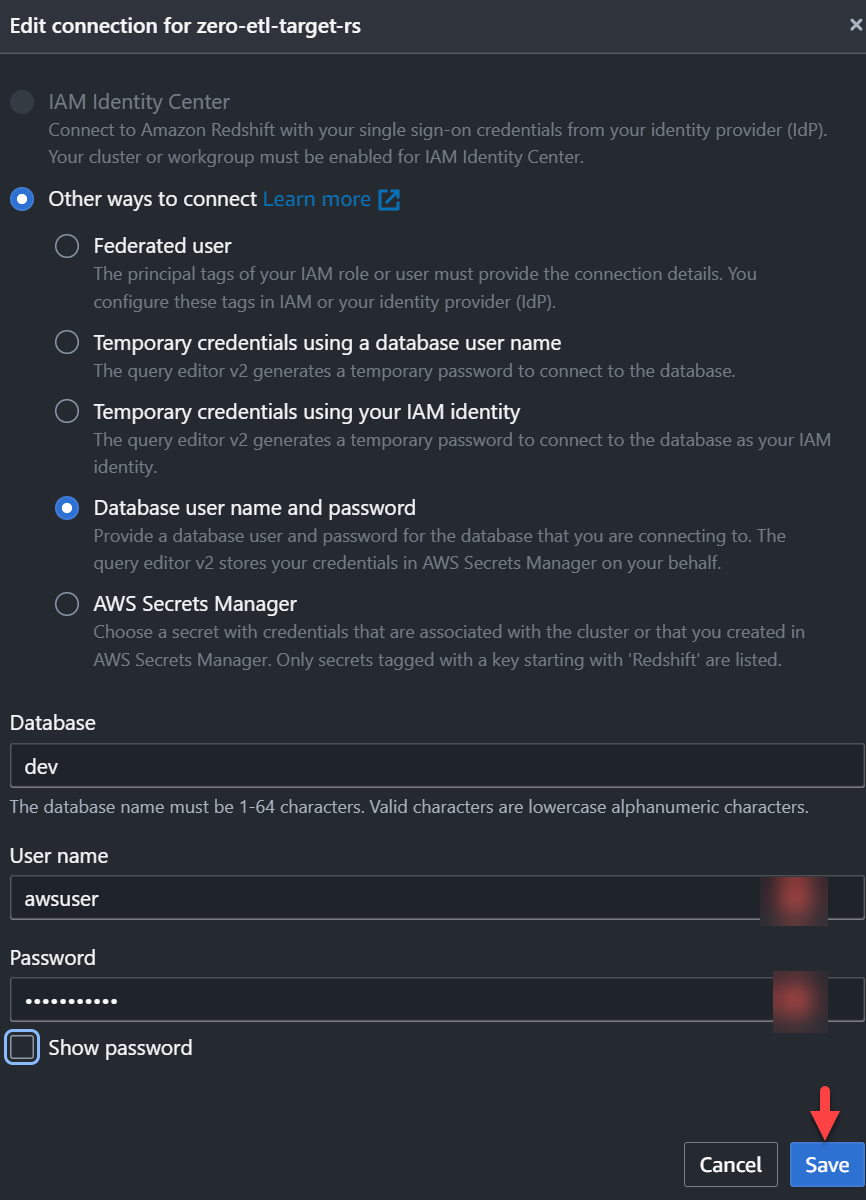
zero-etl-target-rsCluster. - Auswählen Daten abfragen um den Abfrageeditor v2 zu öffnen.
- Stellen Sie eine Verbindung zum Redshift-Data-Warehouse her, indem Sie auswählen Speichern.
- Erhalten Sie die
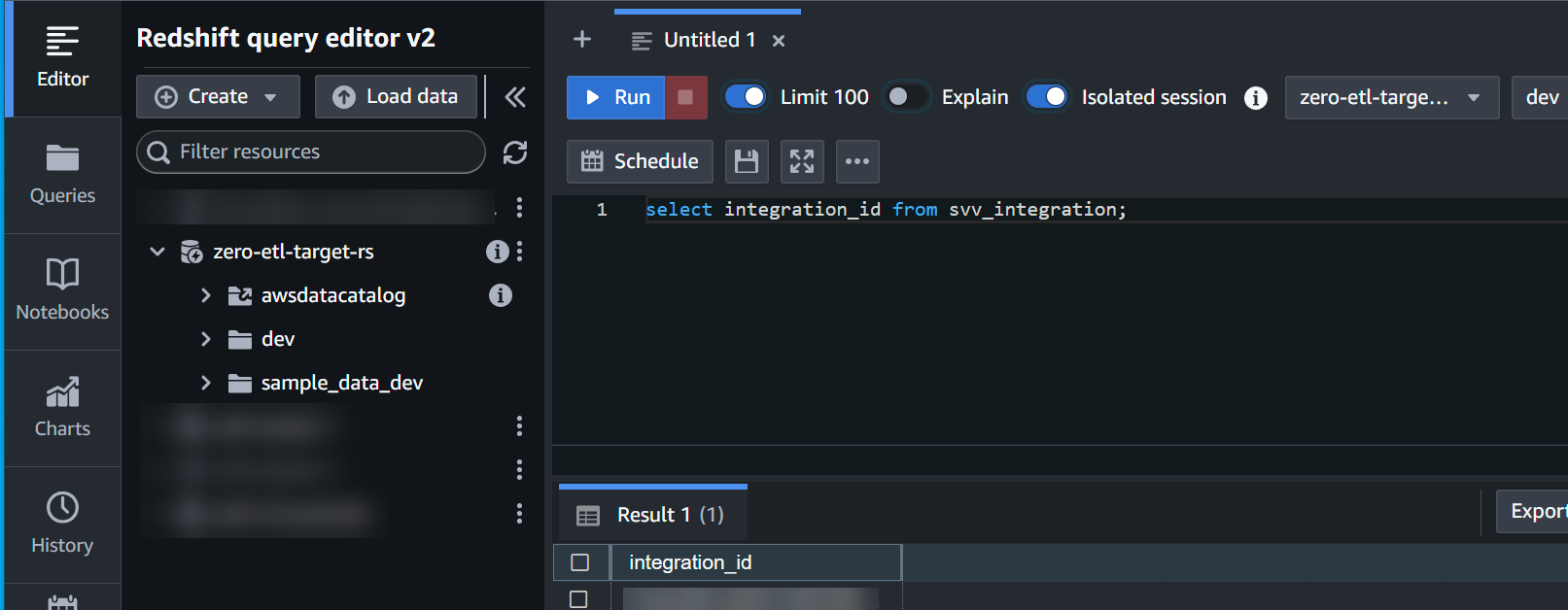
integration_idvon demsvv_integrationSystemtabelle:
select integration_id from svv_integration; -- copy this result, use in the next sql
- Verwenden Sie das
integration_idaus dem vorherigen Schritt, um eine neue Datenbank aus der Integration zu erstellen:
CREATE DATABASE zetl_source FROM INTEGRATION '<result from above>';
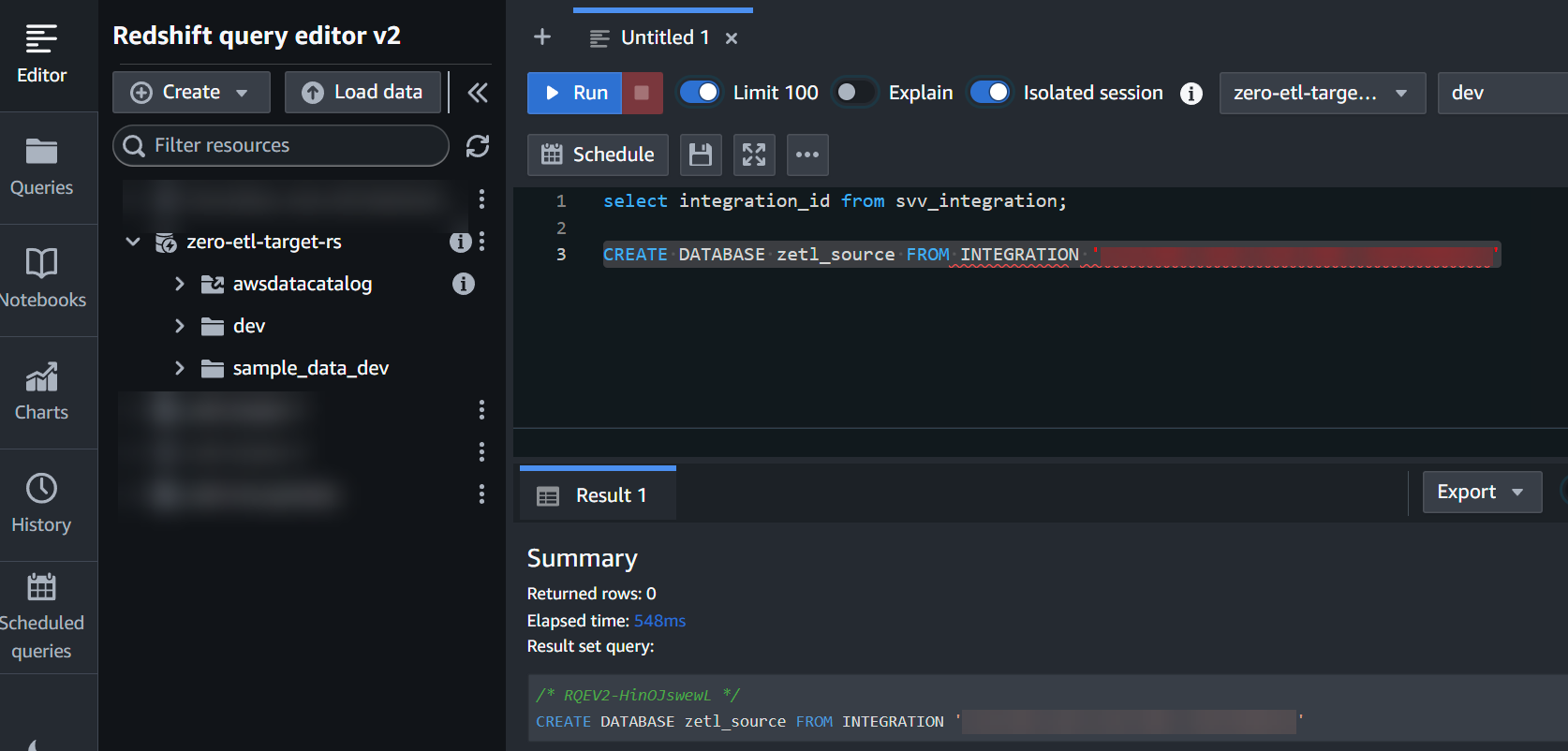
Die Integration ist nun abgeschlossen und ein vollständiger Snapshot der Quelle wird im Ziel so angezeigt, wie er ist. Laufende Änderungen werden nahezu in Echtzeit synchronisiert.
Analysieren Sie die Transaktionsdaten nahezu in Echtzeit
Jetzt können wir Analysen der Betriebsdaten von TICKIT durchführen.
Füllen Sie die TICKIT-Quelldaten aus
Führen Sie die folgenden Schritte aus, um die Quelldaten aufzufüllen:
- Kopieren Sie die CSV-Eingabedatendateien in ein lokales Verzeichnis. Das Folgende ist ein Beispielbefehl:
aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit' . --recursive
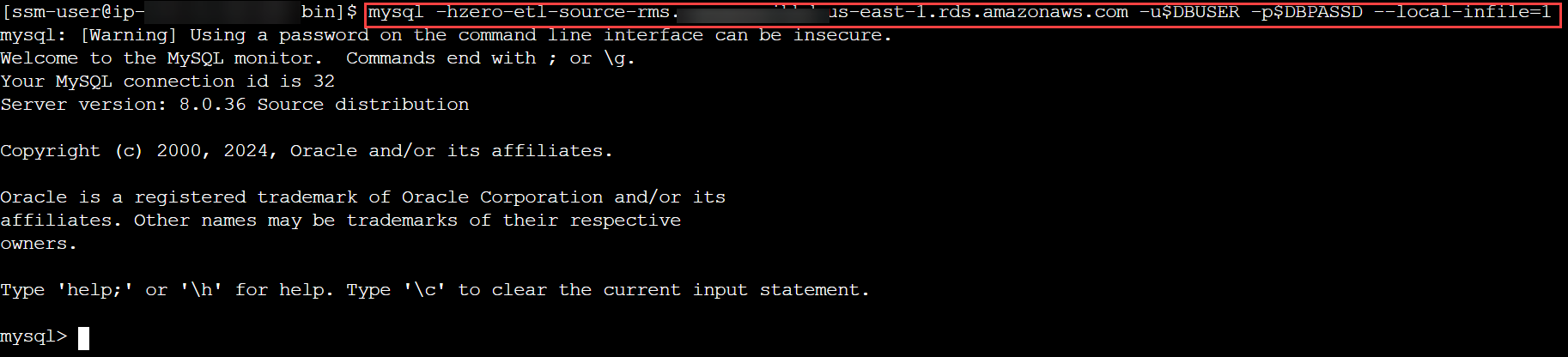
- Stellen Sie eine Verbindung zu Ihrem RDS für MySQL-Cluster her und erstellen Sie eine Datenbank oder ein Schema für das TICKIT-Datenmodell. Überprüfen Sie, ob die Tabellen in diesem Schema über einen Primärschlüssel verfügen, und starten Sie den Ladevorgang:
mysql -h <rds_db_instance_endpoint> -u admin -p password --local-infile=1
- Verwenden Sie Folgendes CREATE TABLE-Befehle.
- Laden Sie die Daten aus lokalen Dateien mit dem Befehl LOAD DATA.
Das Folgende ist ein Beispiel. Beachten Sie, dass die Eingabe-CSV-Datei in mehrere Dateien aufgeteilt ist. Dieser Befehl muss für jede Datei ausgeführt werden, wenn Sie alle Daten laden möchten. Für Demozwecke sollte auch ein teilweises Laden der Daten funktionieren.

Analysieren Sie die TICKIT-Quelldaten im Ziel
Öffnen Sie in der Amazon-Redshift-Konsole den Abfrage-Editor v2 mit der Datenbank, die Sie im Rahmen der Integrationseinrichtung erstellt haben. Verwenden Sie den folgenden Code, um die Seed- oder CDC-Aktivität zu validieren:

Sie können Ihre Geschäftslogik für Transformationen jetzt direkt auf die Daten anwenden, die in das Data Warehouse repliziert wurden. Sie können auch Techniken zur Leistungsoptimierung verwenden, z. B. das Erstellen einer materialisierten Redshift-Ansicht, die die replizierten Tabellen und andere lokale Tabellen verbindet, um die Abfrageleistung für Ihre analytischen Abfragen zu verbessern.
Netzwerk Performance
Sie können die folgenden Systemansichten und Tabellen in Amazon Redshift abfragen, um Informationen über Ihre Zero-ETL-Integrationen mit Amazon Redshift zu erhalten:
Um die für die Integration veröffentlichten Metriken anzuzeigen Amazon CloudWatch, öffnen Sie die Amazon Redshift-Konsole. Wählen Zero-ETL-Integrationen im Navigationsbereich und wählen Sie die Integration aus, um Aktivitätsmetriken anzuzeigen.
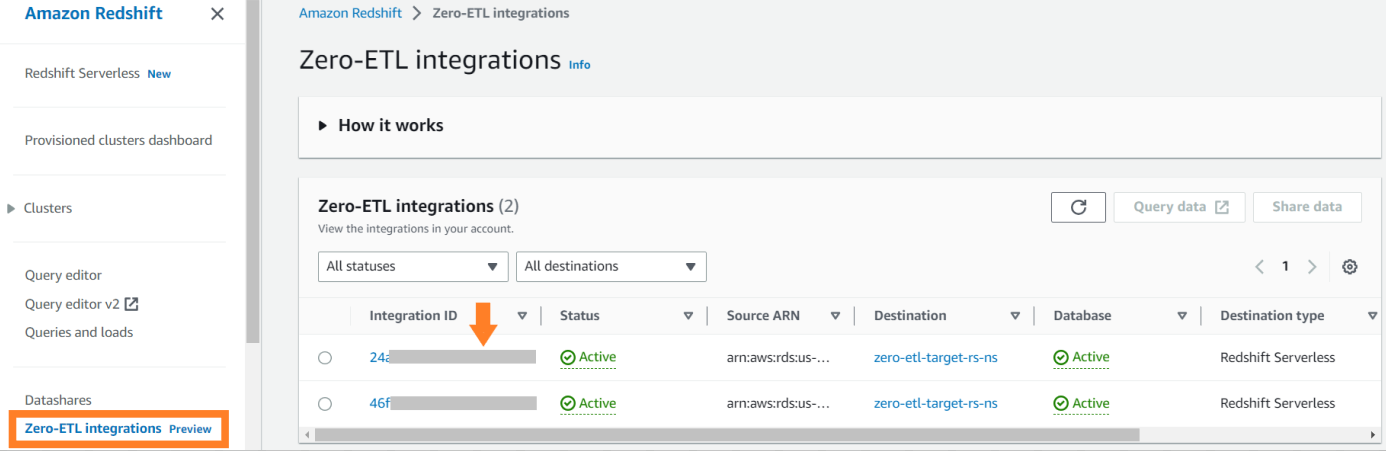
Verfügbare Metriken auf der Amazon-Redshift-Konsole sind Integrationsmetriken und Tabellenstatistiken, wobei Tabellenstatistiken Details zu jeder Tabelle liefern, die von Amazon RDS für MySQL nach Amazon Redshift repliziert wird.

Integrationsmetriken enthalten Erfolgs- und Fehlerzahlen für die Tabellenreplikation sowie Verzögerungsdetails.
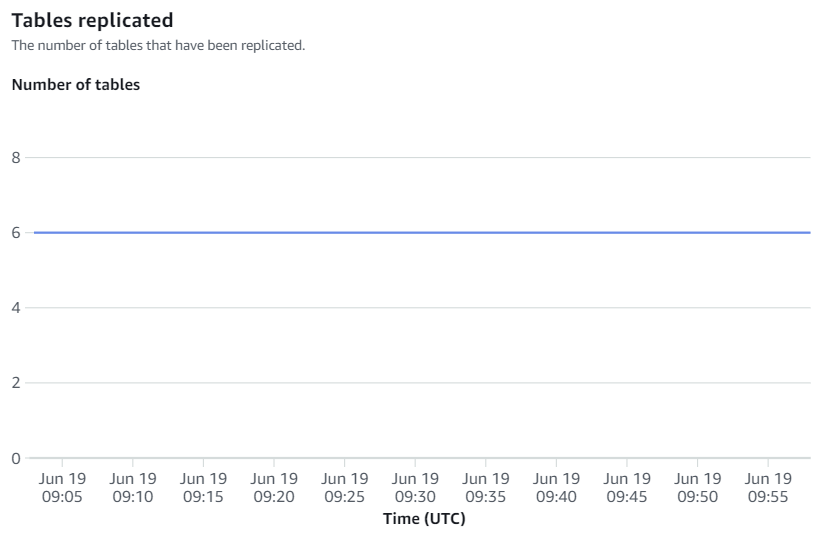
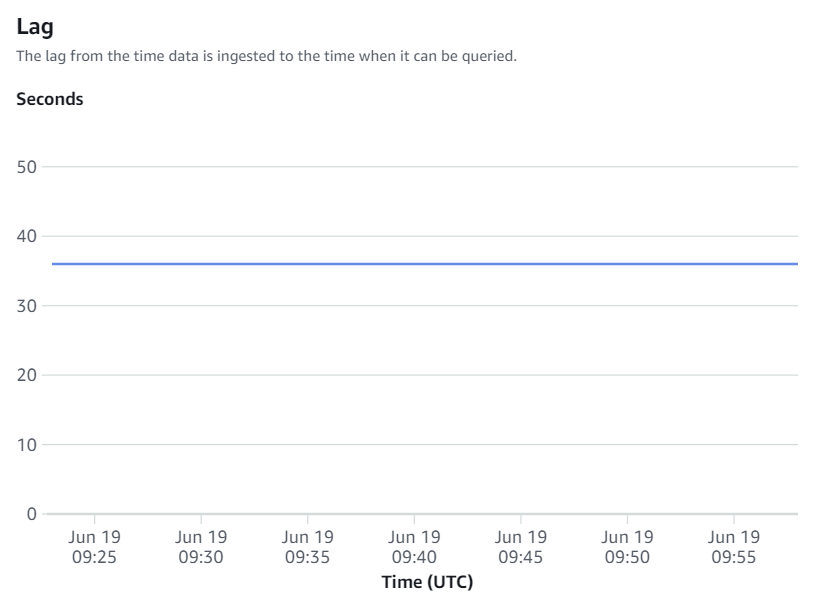
Manuelle Neusynchronisierungen
Die Zero-ETL-Integration initiiert automatisch eine Neusynchronisierung, wenn der Synchronisierungsstatus einer Tabelle als fehlgeschlagen oder Neusynchronisierung erforderlich angezeigt wird. Falls die automatische Neusynchronisierung jedoch fehlschlägt, können Sie eine Neusynchronisierung auf Tabellenebene initiieren:
ALTER DATABASE zetl_source INTEGRATION REFRESH TABLES tbl1, tbl2;
Eine Tabelle kann aus mehreren Gründen in den Status „Fehler“ geraten:
- Der Primärschlüssel wurde aus der Tabelle entfernt. In solchen Fällen müssen Sie den Primärschlüssel erneut hinzufügen und den zuvor erwähnten ALTER-Befehl ausführen.
- Während der Replikation wird ein ungültiger Wert festgestellt oder der Tabelle wird eine neue Spalte mit einem nicht unterstützten Datentyp hinzugefügt. In solchen Fällen müssen Sie die Spalte mit dem nicht unterstützten Datentyp entfernen und den zuvor erwähnten ALTER-Befehl ausführen.
- In seltenen Fällen kann ein interner Fehler zu einem Tabellenfehler führen. Der ALTER-Befehl sollte das Problem beheben.
Aufräumen
Wenn Sie eine Zero-ETL-Integration löschen, werden Ihre Transaktionsdaten nicht aus dem Quell-RDS oder den Ziel-Redshift-Datenbanken gelöscht, aber Amazon RDS sendet keine neuen Änderungen an Amazon Redshift.
Um eine Zero-ETL-Integration zu löschen, führen Sie die folgenden Schritte aus:
- Wählen Sie in der Amazon RDS-Konsole aus Zero-ETL-Integrationen im Navigationsbereich.
- Wählen Sie die Zero-ETL-Integration aus, die Sie löschen möchten, und wählen Sie aus Löschen.
- Um den Löschvorgang zu bestätigen, wählen Sie Löschen.

Zusammenfassung
In diesem Beitrag haben wir Ihnen gezeigt, wie Sie eine Zero-ETL-Integration von Amazon RDS für MySQL zu Amazon Redshift einrichten. Dies minimiert die Notwendigkeit, komplexe Datenpipelines zu pflegen und ermöglicht Analysen von Transaktions- und Betriebsdaten nahezu in Echtzeit.
Weitere Informationen zur Amazon RDS Zero-ETL-Integration mit Amazon Redshift finden Sie unter Arbeiten mit Amazon RDS Zero-ETL-Integrationen mit Amazon Redshift (Vorschau).
Über die Autoren
 Milin Oke ist ein leitender Redshift-Spezialist für Lösungsarchitekten, der drei Jahre lang bei Amazon Web Services gearbeitet hat. Er ist ein AWS-zertifizierter SA Associate, Inhaber der Security Specialty- und Analytics Specialty-Zertifizierung mit Sitz in Queens, New York.
Milin Oke ist ein leitender Redshift-Spezialist für Lösungsarchitekten, der drei Jahre lang bei Amazon Web Services gearbeitet hat. Er ist ein AWS-zertifizierter SA Associate, Inhaber der Security Specialty- und Analytics Specialty-Zertifizierung mit Sitz in Queens, New York.
 Aditya Samant ist ein Veteran der relationalen Datenbankbranche mit über zwei Jahrzehnten Erfahrung in der Arbeit mit kommerziellen und Open-Source-Datenbanken. Derzeit arbeitet er bei Amazon Web Services als Principal Database Specialist Solutions Architect. In seiner Rolle verbringt er viel Zeit damit, mit Kunden zusammenzuarbeiten und skalierbare, sichere und robuste Cloud-native Architekturen zu entwerfen. Aditya arbeitet eng mit den Serviceteams zusammen und arbeitet an der Gestaltung und Bereitstellung der neuen Funktionen für die verwalteten Datenbanken von Amazon mit.
Aditya Samant ist ein Veteran der relationalen Datenbankbranche mit über zwei Jahrzehnten Erfahrung in der Arbeit mit kommerziellen und Open-Source-Datenbanken. Derzeit arbeitet er bei Amazon Web Services als Principal Database Specialist Solutions Architect. In seiner Rolle verbringt er viel Zeit damit, mit Kunden zusammenzuarbeiten und skalierbare, sichere und robuste Cloud-native Architekturen zu entwerfen. Aditya arbeitet eng mit den Serviceteams zusammen und arbeitet an der Gestaltung und Bereitstellung der neuen Funktionen für die verwalteten Datenbanken von Amazon mit.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift/

