Einleitung
In diesem Artikel wird das Konzept der Datenmodellierung vorgestellt, ein entscheidender Prozess, der beschreibt, wie Daten in einer Datenbank oder einem Datensystem gespeichert, organisiert und abgerufen werden. Dabei geht es darum, reale Geschäftsanforderungen in ein logisches und strukturiertes Format umzuwandeln, das in einer Datenbank oder einem Data Warehouse umgesetzt werden kann. Wir werden untersuchen, wie die Datenmodellierung einen konzeptionellen Rahmen für das Verständnis der Beziehungen und Zusammenhänge von Daten innerhalb einer Organisation oder eines bestimmten Bereichs schafft. Darüber hinaus besprechen wir die Bedeutung des Entwurfs von Datenstrukturen und -beziehungen, um eine effiziente Datenspeicherung, -abfrage und -bearbeitung sicherzustellen.

Anwendungsfälle für die Datenmodellierung
Die Datenmodellierung ist für die effektive Verwaltung und Nutzung von Daten in verschiedenen Szenarien von grundlegender Bedeutung. Hier sind einige typische Anwendungsfälle für die Datenmodellierung, die jeweils ausführlich erläutert werden:
Datenerfassung
Bei der Datenmodellierung geht es bei der Datenerfassung darum, zu definieren, wie Daten aus verschiedenen Quellen erfasst oder generiert werden. In dieser Phase wird die erforderliche Datenstruktur zur Speicherung der eingehenden Daten eingerichtet, um sicherzustellen, dass diese effizient integriert und gespeichert werden können. Durch die Modellierung der Daten in dieser Phase können Unternehmen sicherstellen, dass die gesammelten Daten so strukturiert sind, dass sie ihren Analyseanforderungen und Geschäftsprozessen entsprechen. Es hilft dabei, die Art der benötigten Daten zu identifizieren, das Format, in dem sie vorliegen sollten, und wie sie für die weitere Verwendung verarbeitet werden.
Laden von Daten
Sobald die Daten erfasst sind, müssen sie in das Zielsystem, beispielsweise eine Datenbank, geladen werden. Data Warehouseoder Datensee. Dabei spielt die Datenmodellierung eine entscheidende Rolle, indem sie das Schema oder die Struktur definiert, in die die Daten eingefügt werden. Dazu gehört die Angabe, wie Daten aus verschiedenen Quellen den Tabellen und Spalten der Datenbank zugeordnet werden, und das Einrichten von Beziehungen zwischen verschiedenen Datenentitäten. Durch die richtige Datenmodellierung wird sichergestellt, dass die Daten optimal geladen werden, was eine effiziente Speicherung, einen effizienten Zugriff und eine effiziente Abfrageleistung ermöglicht.
Geschäftsberechnung
Die Datenmodellierung ist ein wesentlicher Bestandteil bei der Einrichtung der Rahmenbedingungen für Geschäftsberechnungen. Diese Berechnungen generieren Erkenntnisse, Metriken und Key Performance Indicators (KPIs) aus den gespeicherten Daten. Durch die Einrichtung eines klaren Datenmodells können Unternehmen definieren, wie Daten aus verschiedenen Quellen aggregiert, transformiert und analysiert werden können, um komplexe Geschäftsberechnungen durchzuführen. Dadurch wird sichergestellt, dass die zugrunde liegenden Daten die Ableitung aussagekräftiger und genauer Daten unterstützen Business Intelligence, die als Leitfaden für die Entscheidungsfindung und strategische Planung dienen können.
Vertrieb
In der Verteilungsphase werden die verarbeiteten Daten Endbenutzern oder anderen Systemen zur Analyse, Berichterstellung und Entscheidungsfindung zur Verfügung gestellt. Die Datenmodellierung konzentriert sich in dieser Phase darauf, sicherzustellen, dass die Daten so strukturiert und formatiert sind, dass sie für die Zielgruppe zugänglich und verständlich sind. Dies könnte die Modellierung von Daten in dimensionalen Schemata zur Verwendung in Business-Intelligence-Tools, die Erstellung von APIs für den programmgesteuerten Zugriff oder die Definition von Exportformaten für die Datenfreigabe umfassen. Eine effektive Datenmodellierung stellt sicher, dass Daten problemlos über verschiedene Plattformen und von verschiedenen Interessengruppen verteilt und genutzt werden können, wodurch ihr Nutzen und Wert erhöht wird.
Jeder dieser Anwendungsfälle verdeutlicht die Bedeutung des gesamten Datenlebenszyklus, von der Erfassung und Speicherung bis hin zur Analyse und Verteilung. Durch die sorgfältige Gestaltung von Datenstrukturen und -beziehungen in jeder Phase können Unternehmen sicherstellen, dass ihre Datenarchitektur ihre betrieblichen und analytischen Anforderungen effizient und effektiv unterstützt.
Dateningenieure/Modellierer
Dateningenieure und Datenmodellierer spielen eine zentrale Rolle bei der Datenverwaltung und -analyse und bringen jeweils einzigartige Fähigkeiten und Fachkenntnisse ein, um die Leistungsfähigkeit der Daten innerhalb eines Unternehmens zu nutzen. Das gegenseitige Verständnis der Rollen und Verantwortlichkeiten kann dabei helfen, zu klären, wie sie zusammenarbeiten, um robuste Dateninfrastrukturen aufzubauen und aufrechtzuerhalten.
Dateningenieure
Dateningenieure sind für das Design, den Aufbau und die Wartung der Systeme und Architekturen verantwortlich, die eine effiziente Handhabung und Zugänglichkeit von Daten ermöglichen. Ihre Rolle umfasst oft:
- Aufbau und Pflege von Datenpipelines: Sie schaffen die Infrastruktur zum Extrahieren, Transformieren und Laden von Daten (ETL) aus verschiedenen Quellen.
- Datenspeicherung und -verwaltung: Sie entwerfen und implementieren Datenbanksysteme, Data Lakes und andere Speicherlösungen, um Daten organisiert und zugänglich zu halten.
- Leistungsoptimierung: Dateningenieure sorgen dafür, dass Datenprozesse effizient ablaufen, häufig durch Optimierung der Datenspeicherung und Abfrageausführung.
- Zusammenarbeit mit Stakeholdern: Sie arbeiten eng mit Geschäftsanalysten, Datenwissenschaftlern und anderen Benutzern zusammen, um Datenanforderungen zu verstehen und Lösungen zu implementieren, die eine datengesteuerte Entscheidungsfindung ermöglichen.
- Sicherstellung der Datenqualität und -integrität: Sie implementieren Systeme und Prozesse zur Überwachung, Validierung und Bereinigung von Daten und stellen so sicher, dass Benutzer Zugang zu zuverlässigen und genauen Informationen haben.
Datenmodellierer
Datenmodellierer konzentrieren sich auf die Gestaltung des Entwurfs für Datenmanagementsysteme. Ihre Arbeit besteht darin, Geschäftsanforderungen zu verstehen und sie in Datenstrukturen zu übersetzen, die eine effiziente Datenspeicherung, -abfrage und -analyse unterstützen. Zu den Hauptaufgaben gehören:
- Entwicklung konzeptioneller, logischer und physischer Datenmodelle: Sie erstellen Modelle, die definieren, wie Daten verknüpft sind und wie sie in Datenbanken gespeichert werden.
- Definieren von Datenentitäten und Beziehungen: Datenmodellierer identifizieren die wichtigsten Entitäten, die das Datensystem einer Organisation darstellen muss, und definieren, wie diese Entitäten miteinander in Beziehung stehen.
- Sicherstellung der Datenkonsistenz und Standardisierung: Sie legen Namenskonventionen und Standards für Datenelemente fest, um die Konsistenz im gesamten Unternehmen sicherzustellen.
- Zusammenarbeit mit Dateningenieuren und Architekten: Datenmodellierer arbeiten eng mit Dateningenieuren zusammen, um sicherzustellen, dass die Datenarchitektur die entworfenen Modelle effektiv unterstützt.
- Daten-Governance und Strategie: Sie spielen häufig eine Rolle bei der Datenverwaltung und helfen dabei, Richtlinien und Standards für die Datenverwaltung innerhalb der Organisation zu definieren.
Obwohl es einige Überschneidungen in den Fähigkeiten und Aufgaben von Dateningenieuren und Datenmodellierern gibt, ergänzen sich die beiden Rollen. Dateningenieure konzentrieren sich auf den Aufbau und die Wartung der Infrastruktur, die die Datenspeicherung und den Datenzugriff unterstützt, während Datenmodellierer die Struktur und Organisation der Daten innerhalb dieser Systeme entwerfen. Sie stellen sicher, dass die Datenarchitektur eines Unternehmens robust, skalierbar und auf die Geschäftsziele abgestimmt ist, und ermöglichen so eine effektive datengesteuerte Entscheidungsfindung.
Schlüsselkomponenten der Datenmodellierung
Die Datenmodellierung ist ein entscheidender Prozess beim Entwurf und der Implementierung von Datenbanken und Datensystemen, die effizient und skalierbar sind und die Anforderungen verschiedener Anwendungen erfüllen können. Zu den Schlüsselkomponenten gehören Entitäten, Attribute, Beziehungen und Schlüssel. Das Verständnis dieser Komponenten ist für die Erstellung eines kohärenten und funktionalen Datenmodells von entscheidender Bedeutung.
Entities
Eine Entität stellt ein reales Objekt oder Konzept dar, das eindeutig identifiziert werden kann. In einer Datenbank wird eine Entität oft in eine Tabelle übersetzt. Entitäten werden verwendet, um die Informationen zu kategorisieren, die wir speichern möchten. Typische Entitäten in einem Customer-Relationship-Management-System (CRM) könnten beispielsweise „Kunde“, „Bestellung“ usw. sein Product.
Attributes
Attribute sind die Eigenschaften oder Merkmale einer Entität. Sie liefern Details über das Unternehmen und helfen so, es umfassender zu beschreiben. In einer Datenbanktabelle repräsentieren Attribute die Spalten. Für die Entität „Kunde“ könnten Attribute „Kunden-ID“, „Name“, „Adresse“, „Telefonnummer“ usw. umfassen. Attribute definieren den Datentyp (z. B. Ganzzahl, Zeichenfolge, Datum usw.), der für jede Entität gespeichert wird Beispiel.
Beziehungen
Beziehungen beschreiben, wie Entitäten in einem System miteinander verbunden sind, und stellen ihre Interaktionen dar. Es gibt verschiedene Arten von Beziehungen:
- Eins-zu-eins (1:1): Jede Instanz von Entität A ist mit einer und nur einer Instanz von Entität B verknüpft und umgekehrt.
- Eins-zu-Viele (1:N): Jede Instanz von Entität A kann mit null, einer oder mehreren Instanzen von Entität B verknüpft sein, aber jede Instanz von Entität B ist nur mit einer Instanz von Entität A verknüpft.
- Viele-zu-Viele (M:N): Jede Instanz von Entität A kann mit null, einer oder mehreren Instanzen von Entität B verknüpft werden, und jede Instanz von Entität B kann mit null, einer oder mehreren Instanzen von Entität A verknüpft werden.
Beziehungen sind von entscheidender Bedeutung für die Verknüpfung von Daten, die in verschiedenen Entitäten gespeichert sind, und erleichtern den Datenabruf und die Berichterstellung über mehrere Tabellen hinweg.
Tasten
Schlüssel sind spezifische Attribute, die dazu dienen, Datensätze innerhalb einer Tabelle eindeutig zu identifizieren und Beziehungen zwischen Tabellen herzustellen. Es gibt verschiedene Arten von Schlüsseln:
- Primärschlüssel: Eine Spalte oder eine Reihe von Spalten identifiziert jeden Tabellendatensatz eindeutig. Innerhalb einer Tabelle können keine zwei Datensätze denselben Primärschlüsselwert haben.
- Unbekannter Schlüssel: Eine Spalte oder eine Reihe von Spalten in einer Tabelle, die auf den Primärschlüssel einer anderen Tabelle verweist. Fremdschlüssel werden verwendet, um Beziehungen zwischen Tabellen herzustellen und durchzusetzen.
- Zusammengesetzter Schlüssel: Eine Kombination aus zwei oder mehr Spalten in einer Tabelle, die zur eindeutigen Identifizierung jedes Datensatzes in der Tabelle verwendet werden kann.
- Kandidatenschlüssel: Jede Spalte oder jeder Spaltensatz, der als Primärschlüssel in der Tabelle gelten könnte.
Das Verständnis und die korrekte Implementierung dieser Schlüsselkomponenten sind für die Erstellung effektiver Datenspeicher-, -abruf- und -verwaltungssysteme von grundlegender Bedeutung. Eine ordnungsgemäße Datenmodellierung führt zu gut organisierten und hinsichtlich Leistung und Skalierbarkeit optimierten Datenbanken, die den Anforderungen von Entwicklern und Endbenutzern gerecht werden.
Phasen von Datenmodellen
Die Datenmodellierung verläuft typischerweise in drei Hauptphasen: dem konzeptionellen Datenmodell, dem logischen Datenmodell und dem physischen Datenmodell. Jede Phase dient einem bestimmten Zweck und baut auf der vorherigen auf, um abstrakte Ideen schrittweise in ein konkretes Datenbankdesign umzuwandeln. Das Verständnis dieser Phasen ist für jeden, der Datensysteme erstellt oder verwaltet, von entscheidender Bedeutung.
Konzeptionelles Datenmodell
Das konzeptionelle Datenmodell ist die abstrakteste Ebene der Datenmodellierung. Diese Phase konzentriert sich auf die Definition der Entitäten auf hoher Ebene und der Beziehungen zwischen ihnen, ohne auf die Details der Speicherung der Daten einzugehen. Das Hauptziel besteht darin, die wichtigsten Datenobjekte, die für die Geschäftsdomäne relevant sind, und ihre Interaktionen so zu skizzieren, dass auch nicht-technische Stakeholder sie verstehen. Dieses Modell wird häufig für die anfängliche Planung und Kommunikation verwendet und verbindet die geschäftlichen Anforderungen mit der technischen Umsetzung.
Zu den wichtigsten Merkmalen gehören:
- Identifizierung wichtiger Entitäten und ihrer Beziehungen.
- Auf hoher Ebene, häufig unter Verwendung von Geschäftsterminologie.
- Unabhängig von einem Datenbankmanagementsystem (DBMS) oder einer Technologie.
Logisches Datenmodell
Das logische Datenmodell fügt dem konzeptionellen Modell weitere Details hinzu, indem es die Struktur der Datenelemente spezifiziert und die Beziehungen zwischen ihnen festlegt. Es umfasst die Definition von Entitäten, Attributen jeder Entität, Primärschlüsseln und Fremdschlüsseln. Es bleibt jedoch weiterhin unabhängig von der Technologie, die zur Implementierung verwendet wird. Das logische Modell ist detaillierter und strukturierter als das konzeptionelle Modell und beginnt mit der Einführung von Regeln und Einschränkungen, die die Daten steuern.
Zu den wichtigsten Merkmalen gehören:
- Detaillierte Definition von Entitäten, Beziehungen und Attributen.
- Zur Herstellung von Beziehungen ist die Einbeziehung von Primärschlüsseln und Fremdschlüsseln erforderlich.
- Um die Datenintegrität sicherzustellen und Redundanzen zu reduzieren, werden Normalisierungsprozesse angewendet.
- Dennoch unabhängig von der spezifischen DBMS-Technologie.
Physisches Datenmodell
Das physische Datenmodell ist die detaillierteste Phase und umfasst die Implementierung des Datenmodells in einem bestimmten Datenbankverwaltungssystem. Dieses Modell übersetzt das logische Datenmodell in ein detailliertes Schema, das in einer Datenbank implementiert werden kann. Es enthält alle für die Implementierung erforderlichen Details wie Tabellen, Spalten, Datentypen, Einschränkungen, Indizes, Trigger und andere datenbankspezifische Funktionen.
Zu den wichtigsten Merkmalen gehören:
- Spezifisch für ein bestimmtes DBMS und beinhaltet datenbankspezifische Optimierung.
- Detaillierte Spezifikationen von Tabellen, Spalten, Datentypen und Einschränkungen.
- Berücksichtigung physischer Speicheroptionen, Indizierungsstrategien und Leistungsoptimierung.
Der Übergang durch diese Phasen ermöglicht die sorgfältige Planung und Gestaltung eines Datensystems, das auf die Geschäftsanforderungen abgestimmt und für die Leistung in einer bestimmten technischen Umgebung optimiert ist. Das konzeptionelle Modell stellt sicher, dass die Gesamtstruktur mit den Geschäftszielen übereinstimmt, das logische Modell schließt die Lücke zwischen konzeptioneller Planung und physischer Implementierung und das physische Modell stellt sicher, dass die Datenbank für die tatsächliche Verwendung optimiert ist.
Beispiel-Schuldatensatz
Entitäten: Schüler, Lehrer und Klassen.
Konzeptionelles Datenmodell
Dieses konzeptionelle Datenmodell beschreibt ein Datenbanksystem zur Verwaltung von Schulunterlagen mit drei Haupteinheiten: Schüler, Lehrer und Klasse. In diesem Modell können Schüler mehreren Lehrern und Klassen zugeordnet werden, während Lehrer mehrere Schüler unterrichten und verschiedene Klassen leiten können. Jede Klasse beherbergt zahlreiche Schüler, wird aber von einem einzigen Lehrer unterrichtet. Das Design zielt darauf ab, das Verständnis der Beziehungen zwischen Entitäten sowohl für technische als auch für nichttechnische Interessengruppen zu vereinfachen und einen klaren und intuitiven Überblick über die Struktur des Systems zu bieten. Der Beginn mit einem konzeptionellen Modell ermöglicht die schrittweise Integration detaillierterer Elemente und schafft so eine solide Grundlage für die Entwicklung anspruchsvoller Datenbankmodelle.
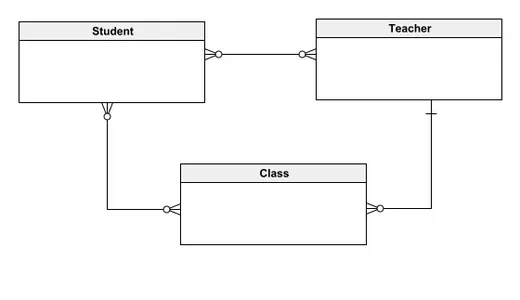
Logisches Datenmodell
Das logische Datenmodell, das wegen seiner Ausgewogenheit zwischen Klarheit und Detaillierung sehr beliebt ist, umfasst Entitäten, Beziehungen, Attribute, PRIMÄRSCHLÜSSEL und AUSLÄNDISCHE SCHLÜSSEL. Es beschreibt akribisch den logischen Verlauf der Daten innerhalb einer Datenbank und verdeutlicht detaillierte Einzelheiten wie die Zusammensetzung oder die verwendeten Datentypen. Das logische Datenmodell bietet ausreichend Grundlage für die Softwareentwicklung, um mit dem eigentlichen Datenbankaufbau zu beginnen.
Lassen Sie uns ausgehend vom zuvor besprochenen konzeptionellen Datenmodell ein typisches logisches Datenmodell untersuchen. Im Gegensatz zu seinem konzeptionellen Vorgänger ist dieses Modell mit Attributen und Primärschlüsseln angereichert. Die Student-Entität zeichnet sich beispielsweise durch eine StudentID als Primärschlüssel und eindeutige Kennung sowie durch andere wichtige Attribute wie Name und Alter aus.
Dieser Ansatz wird konsequent auf andere Entitäten wie Lehrer und Klasse angewendet, wobei die im konzeptionellen Modell festgelegten Beziehungen erhalten bleiben und das Modell dennoch um ein detailliertes Schema erweitert wird, das Attribute und Schlüsselidentifikatoren enthält.
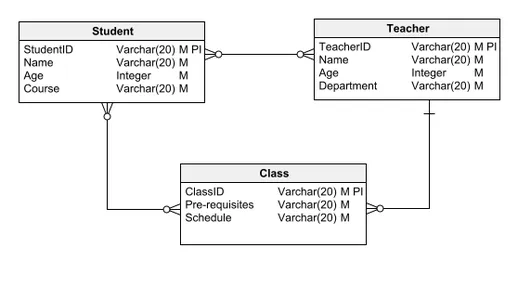
Physisches Datenmodell
Das physische Datenmodell ist das detaillierteste unter den Abstraktionsebenen und beinhaltet Besonderheiten, die auf das gewählte Datenbankverwaltungssystem wie PostgreSQL, Oracle oder MySQL zugeschnitten sind. In diesem Modell werden Entitäten in Tabellen übersetzt und Attribute zu Spalten, die die Struktur einer tatsächlichen Datenbank widerspiegeln. Jeder Spalte ist ein bestimmter Datentyp zugewiesen, beispielsweise INT für Ganzzahlen, VARCHAR für variable Zeichenfolgen oder DATE für Datumsangaben.
Aufgrund seiner detaillierten Natur befasst sich das physische Datenmodell mit den technischen Besonderheiten der verwendeten Datenbankplattform. Diese umfassenden Aspekte gehen über den Rahmen einer umfassenden Übersicht hinaus. Dazu gehören Überlegungen wie Speicherzuweisung, Indizierungsstrategien und die Implementierung von Einschränkungen, die für die Leistung und Integrität der Datenbank von entscheidender Bedeutung sind, aber in der Regel zu detailliert sind, als dass eine Vorbesprechung erforderlich wäre.

Phasen der Datenmodellierung
- Geschäftsanforderungen verstehen: Nehmen Sie an ausführlichen Diskussionen mit Stakeholdern teil, um den Geschäftszweck der Datenbank zu verstehen. Zu den wichtigsten Überlegungen gehört die Identifizierung des Geschäftsbereichs, der Datenspeicheranforderungen und der Probleme, die die Datenbank lösen soll. Konzentrieren Sie sich darauf, das Datenbankdesign an den Geschäftszielen hinsichtlich Leistung, Kosten und Sicherheit auszurichten.
- Gruppenarbeit: Arbeiten Sie eng mit anderen Teams zusammen (z. B. UX/UI-Designer und -Entwickler), um sicherzustellen, dass die Datenbank die umfassendere Lösung unterstützt. Passen Sie Datenformate und -typen an die Anwendungsanforderungen an und legen Sie dabei Wert auf kollaboratives Design und Kommunikationsfähigkeiten.
- Nutzen Sie Branchenstandards: Recherchieren Sie bestehende Modelle und Standards, um nicht bei Null anzufangen. Nutzen Sie branchenübliche Best Practices, um Zeit und Ressourcen zu sparen, und konzentrieren Sie Ihre Bemühungen auf Aspekte Ihrer Datenbank, die sie von bestehenden Modellen unterscheiden.
- Beginnen Sie mit der Datenbankmodellierung: Mit einem soliden Verständnis der Geschäftsanforderungen, Teameingaben und Industriestandards beginnen Sie mit der konzeptionellen Modellierung, gehen Sie zur logischen über und schließen Sie mit dem physischen Modell ab. Dieser strukturierte Ansatz gewährleistet ein umfassendes Verständnis der erforderlichen Entitäten, Attribute und Beziehungen und erleichtert eine reibungslose Datenbankimplementierung im Einklang mit den Geschäftszielen.
Datenmodellierungstools sind für den Entwurf, die Pflege und die Weiterentwicklung organisatorischer Datenstrukturen unerlässlich. Diese Tools bieten eine Reihe von Funktionen zur Unterstützung des gesamten Datenbankdesign- und -verwaltungslebenszyklus. Zu den wichtigsten Funktionen, auf die Sie bei Datenmodellierungstools achten sollten, gehören:
- Erstellen Sie Datenmodelle: Erleichtern Sie die Erstellung konzeptioneller, logischer und physischer Datenmodelle und ermöglichen Sie eine klare Definition von Entitäten, Attributen und Beziehungen. Diese Kernfunktionalität unterstützt den anfänglichen und fortlaufenden Entwurf der Datenbankarchitektur.
- Zusammenarbeit und zentrales Repository: Ermöglichen Sie Teammitgliedern die Zusammenarbeit bei der Gestaltung und Änderung von Datenmodellen. Ein zentrales Repository stellt sicher, dass die neuesten Versionen allen Beteiligten zugänglich sind, und fördert so Konsistenz und Effizienz in der Entwicklung.
- Reverse Engineering: Bieten Sie die Möglichkeit, SQL-Skripte zu importieren oder eine Verbindung zu vorhandenen Datenbanken herzustellen, um Datenmodelle zu generieren. Dies ist besonders nützlich, um Legacy-Systeme zu verstehen und zu dokumentieren oder bestehende Datenbanken zu integrieren.
- Vorwärtsentwicklung: Ermöglicht die Generierung von SQL-Skripten oder Code aus dem Datenmodell. Diese Funktion optimiert die Implementierung von Änderungen in der Datenbankstruktur und stellt sicher, dass die physische Datenbank das neueste Modell widerspiegelt.
- Unterstützung für verschiedene Datenbanktypen: Bieten Sie Kompatibilität mit mehreren Datenbankverwaltungssystemen (DBMS), wie MySQL, PostgreSQL, Oracle, SQL Server und mehr. Diese Flexibilität stellt sicher, dass das Tool in verschiedenen Projekten und technologischen Umgebungen eingesetzt werden kann.
- Versionskontrolle: Integrieren Sie Versionskontrollsysteme oder integrieren Sie diese, um Änderungen an Datenmodellen im Laufe der Zeit zu verfolgen. Diese Funktion ist entscheidend für die Verwaltung von Iterationen der Datenbankstruktur und erleichtert bei Bedarf das Rollback auf frühere Versionen.
- Diagramme in verschiedene Formate exportieren: Ermöglichen Sie Benutzern den Export von Datenmodellen und Diagrammen in verschiedenen Formaten (z. B. PDF, PNG, XML) und erleichtern Sie so die gemeinsame Nutzung und Dokumentation. Dadurch wird sichergestellt, dass auch technisch nicht versierte Stakeholder die Datenarchitektur überprüfen und verstehen können.
Die Wahl eines Datenmodellierungstools mit diesen Funktionen kann die Effizienz, Genauigkeit und Zusammenarbeit der Datenverwaltungsbemühungen innerhalb einer Organisation erheblich verbessern und sicherstellen, dass Datenbanken gut gestaltet, aktuell und auf die Geschäftsanforderungen abgestimmt sind.
ER / Studio

Bietet umfassende Modellierungsfunktionen und Kollaborationsfunktionen und unterstützt verschiedene Datenbankplattformen.
IBM InfoSphere Data Architect

Bietet eine robuste Umgebung zum Entwerfen und Verwalten von Datenmodellen mit Unterstützung für die Integration und Synchronisierung mit anderen IBM-Produkten.
Link zu IBM InfoSphere Data Architect
Oracle SQL Developer Data Modeler

Ein kostenloses Tool, das Forward- und Reverse-Engineering, Versionskontrolle und Multi-Datenbank-Unterstützung unterstützt.
Link zum Oracle SQL Developer Data Modeler
PowerDesigner (SAP)

Bietet umfangreiche Modellierungsfunktionen, einschließlich Daten-, Informations- und Unternehmensarchitekturunterstützung.
Navicat-Datenmodellierer
Es ist bekannt für seine benutzerfreundliche Oberfläche und die Unterstützung einer breiten Palette von Datenbanken und ermöglicht Forward- und Reverse-Engineering.
Diese Tools rationalisieren den Datenmodellierungsprozess, verbessern die Zusammenarbeit im Team und stellen die Kompatibilität zwischen verschiedenen Datenbanksystemen sicher.
Lies auch: Fragen im Vorstellungsgespräch zur Datenmodellierung
Zusammenfassung
Dieser Artikel befasste sich eingehend mit der grundlegenden Praxis der Datenmodellierung und betonte deren entscheidende Rolle bei der Organisation, Speicherung und dem Zugriff auf Daten in Datenbanken und Datensystemen. Durch die Aufteilung des Prozesses in konzeptionelle, logische und physische Modelle haben wir veranschaulicht, wie die Datenmodellierung Geschäftsanforderungen in strukturierte Datenrahmen übersetzt und so eine effiziente Datenverarbeitung und aufschlussreiche Analyse ermöglicht.
Zu den wichtigsten Erkenntnissen gehören die Bedeutung des Verständnisses von Geschäftsanforderungen, der kollaborative Charakter des Datenbankdesigns unter Einbeziehung verschiedener Interessengruppen und der strategische Einsatz von Datenmodellierungstools zur Optimierung des Entwicklungsprozesses. Durch die Datenmodellierung wird sichergestellt, dass Datenstrukturen für aktuelle Anforderungen optimiert werden und Skalierbarkeit für zukünftiges Wachstum bereitgestellt wird.
Die Datenmodellierung ist das Herzstück eines effektiven Datenmanagements und ermöglicht es Unternehmen, ihre Daten für strategische Entscheidungen und betriebliche Effizienz zu nutzen.
Häufig gestellte Fragen
Antwort. Die Datenmodellierung stellt die Daten eines Systems visuell dar und beschreibt, wie sie gespeichert, organisiert und abgerufen werden. Dies ist entscheidend für die Übersetzung von Geschäftsanforderungen in ein strukturiertes Datenbankformat und ermöglicht eine effiziente Datennutzung.
Antwort. Zu den wichtigsten Anwendungsfällen gehören die Datenerfassung, das Laden, Geschäftsberechnungen und die Verteilung, um sicherzustellen, dass Daten effektiv erfasst, gespeichert und für geschäftliche Erkenntnisse genutzt werden.
Antwort. Dateningenieure bauen und warten die Dateninfrastruktur, während Datenmodellierer die Struktur und Organisation der Daten entwerfen, um Geschäftsziele und Datenintegrität zu unterstützen.
Antwort. Der Prozess reicht vom Verständnis der Geschäftsanforderungen über die Zusammenarbeit mit Teams, die Nutzung von Industriestandards bis hin zur Modellierung der Datenbank durch konzeptionelle, logische und physische Phasen.
Antwort. Diese Tools erleichtern den Entwurf, die Zusammenarbeit und die Weiterentwicklung von Datenmodellen, unterstützen verschiedene Datenbanktypen und ermöglichen Reverse- und Forward-Engineering für eine effiziente Datenbankverwaltung.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/data-modeling-demystified-crafting-efficient-databases-for-business-insights/

