2023 war ein arbeitsreiches Jahr für Amazon OpenSearch-Dienst! Erfahren Sie mehr über die Veröffentlichungen, die OpenSearch Service im veröffentlicht hat ersten Halb 2023.
In der zweiten Hälfte des Jahres 2023 fügte OpenSearch Service die Unterstützung von zwei neuen hinzu Öffnet die Suche Versionen: 2.9 und 2.11 Diese beiden Versionen führen neue Funktionen im Suchbereich, im Suchbereich für maschinelles Lernen (ML), bei Migrationen und auf der Betriebsseite des Dienstes ein.
Mit der Veröffentlichung der Zero-ETL-Integration mit Amazon Simple Storage-Service (Amazon S3) können Sie Ihre Daten in Ihrem Data Lake mit OpenSearch Service analysieren, um Dashboards zu erstellen und die Daten abzufragen, ohne Ihre Daten aus Amazon S3 verschieben zu müssen.
OpenSearch Service kündigte außerdem eine neue Zero-ETL-Integration mit an Amazon DynamoDB über das DynamoDB-Plugin für Amazon OpenSearch-Aufnahme. OpenSearch Ingestion kümmert sich um das Bootstrapping und streamt kontinuierlich Daten aus Ihrer DynamoDB-Quelle.
OpenSearch Serverless gab die allgemeine Verfügbarkeit von bekannt Vector Engine für Amazon OpenSearch Serverless zusammen mit anderen Funktionen, um Ihre Erfahrung mit Zeitreihensammlungen zu verbessern, Ihre Kosten für Entwicklungsumgebungen zu verwalten und Ihre Ressourcen schnell an Ihre Arbeitslastanforderungen anzupassen.
In diesem Beitrag besprechen wir die neuen Versionen von OpenSearch Service, um Ihr Unternehmen mit Suche, Observability, Sicherheitsanalysen und Migrationen zu unterstützen.
Erstellen Sie kostengünstige Lösungen mit OpenSearch Service
Mit der Zero-ETL-Integration für Amazon S3 können Sie mit OpenSearch Service Ihre Daten jetzt direkt abfragen und so Speicherkosten sparen. Die Datenverschiebung ist ein kostspieliger Vorgang, da Sie Daten über verschiedene Datenspeicher hinweg replizieren müssen. Dies erhöht Ihren Datenbedarf und treibt die Kosten in die Höhe. Das Verschieben von Daten erhöht auch den Aufwand für die Verwaltung von Pipelines, um die Daten von einer Quelle zu einem neuen Ziel zu migrieren.
OpenSearch Service hat außerdem neue Instanztypen für Datenknoten – Im4gn und OR1 – hinzugefügt, um Ihnen bei der weiteren Optimierung Ihrer Infrastrukturkosten zu helfen. Mit maximal 30 TB nichtflüchtigem Speicher (NVMe) und Solid-State-Laufwerken (SSD) bietet die Im4gn-Instanz dichten Speicher und bessere Leistung. OR1-Instanzen nutzen Segmentreplikation und Remote-Backed-Storage, um den Durchsatz für indizierungsintensive Arbeitslasten erheblich zu steigern.
Zero-ETL von DynamoDB zum OpenSearch Service
Im November 2023 führten DynamoDB und OpenSearch Ingestion eine Zero-ETL-Integration für OpenSearch Service ein. OpenSearch Service-Domänen und OpenSearch Serverless-Sammlungen bieten erweiterte Suchfunktionen wie Volltext- und Vektorsuche für Ihre DynamoDB-Daten. Mit ein paar Klicks auf die AWS-Managementkonsolekönnen Sie Ihre Daten jetzt nahtlos von DynamoDB mit OpenSearch Service laden und synchronisieren, sodass Sie keinen benutzerdefinierten Code zum Extrahieren, Transformieren und Laden der Daten schreiben müssen.
Direkte Abfrage (Zero-ETL für Amazon S3-Daten, in der Vorschau)
OpenSearch Service hat eine neue Möglichkeit für Sie angekündigt, Betriebsprotokolle in Amazon S3 und S3-basierten Data Lakes abzufragen, ohne zwischen Tools zur Analyse von Betriebsdaten wechseln zu müssen. Bisher mussten Sie Daten von Amazon S3 in OpenSearch Service kopieren, um die umfangreichen Analyse- und Visualisierungsfunktionen von OpenSearch nutzen zu können, um Ihre Daten zu verstehen, Anomalien zu identifizieren und potenzielle Bedrohungen zu erkennen.
Allerdings kann die kontinuierliche Replikation von Daten zwischen Diensten teuer sein und erfordert betriebliche Arbeit. Mit der Direktabfragefunktion von OpenSearch Service können Sie auf in Amazon S3 gespeicherte Betriebsprotokolldaten zugreifen, ohne die Daten selbst verschieben zu müssen. Jetzt können Sie komplexe Abfragen und Visualisierungen Ihrer Daten durchführen, ohne dass Daten verschoben werden müssen.
Unterstützung von Im4gn mit OpenSearch Service
Im4gn-Instanzen sind für Workloads optimiert, die große Datenmengen verwalten und eine hohe Speicherdichte pro vCPU benötigen. Im4gn-Instanzen gibt es in den Größen Large bis 16xlarge mit einer NVMe-SSD-Festplattengröße von bis zu 30 TB. Im4gn-Instanzen basieren darauf AWS Nitro-System SSDs, die einen Festplattenzugriff mit hohem Durchsatz und geringer Latenz für beste Leistung bieten. OpenSearch Service Im4gn-Instanzen unterstützen alle OpenSearch-Versionen und Elasticsearch-Versionen 7.9 und höher. Weitere Einzelheiten finden Sie unter Unterstützte Instanztypen im Amazon OpenSearch Service.
Wir stellen OR1 vor, eine OpenSearch-optimierte Instanzfamilie für die Indizierung hoher Arbeitslasten
Im November 2023 wurde der OpenSearch Service gestartet OR1, die OpenSearch Optimized Instance-Familie, das in internen Benchmarks eine Preis-Leistungs-Verbesserung von bis zu 30 % gegenüber bestehenden Instanzen bietet und Amazon S3 nutzt, um eine Haltbarkeit von 11 9 Sekunden zu bieten. Eine Domäne mit OR1-Instanzen verwendet Amazon Elastic Block-Shop (Amazon EBS)-Volumes für den Primärspeicher, wobei die Daten bei Ankunft synchron nach Amazon S3 kopiert werden. OR1-Instanzen verwenden OpenSearch Segmentreplikationsfunktion um Replikat-Shards das direkte Lesen von Daten aus Amazon S3 zu ermöglichen und so die Ressourcenkosten für die Indizierung sowohl in primären als auch in Replikat-Shards zu vermeiden. Die OR1-Instanzfamilie unterstützt auch die automatische Datenwiederherstellung im Fehlerfall. Weitere Informationen zu den OR1-Instanztypoptionen finden Sie unter Instanztypen der aktuellen Generation im OpenSearch-Dienst.
Stärken Sie Ihr Unternehmen mit Sicherheitsanalysefunktionen
Das Security Analytics-Plugin im OpenSearch Service unterstützt sofort einsatzbereit vorgefertigte Protokolltypen und stellt Sicherheitserkennungsregeln (SIGMA-Regeln) bereit, um potenzielle Sicherheitsvorfälle zu erkennen.
In OpenSearch 2.9 fügte das Security Analytics-Plugin Unterstützung für Kundenprotokolltypen und native Unterstützung für hinzu Offenes Cybersecurity Schema Framework (OCSF) Datei Format. Mit dieser neuen Unterstützung können Sie Detektoren mit darin gespeicherten OCSF-Daten erstellen Amazon Security Lake um Sicherheitsbefunde zu analysieren und mögliche Vorfälle einzudämmen. Das Security Analytics-Plugin bietet außerdem die Möglichkeit, eigene benutzerdefinierte Protokolltypen und benutzerdefinierte Erkennungsregeln zu erstellen.
Erstellen Sie ML-gestützte Suchlösungen
Im Jahr 2023 investierte OpenSearch Service in die Eliminierung des schweren Arbeitsaufwands, der für die Entwicklung von Suchanwendungen der nächsten Generation erforderlich ist. Mit Funktionen wie Suchpipelines, Suchprozessoren und AI/ML-Konnektoren ermöglichte OpenSearch Service die schnelle Entwicklung von Suchanwendungen, die auf neuronaler Suche, Hybridsuche und personalisierten Ergebnissen basieren. Darüber hinaus verbesserten Verbesserungen am kNN-Plugin die Speicherung und den Abruf von Vektordaten. Neu eingeführte optionale Plugins für OpenSearch Service ermöglichen eine nahtlose Integration mit zusätzlichen Sprachanalysatoren und Amazon personalisieren.
Suchpipelines
Suchpipelines bieten neue Möglichkeiten zur Erweiterung von Suchanfragen und zur Verbesserung der Suchergebnisse. Sie definieren eine Suchpipeline und senden dann Ihre Abfragen an diese. Wenn Sie die Suchpipeline definieren, geben Sie Folgendes an Prozessoren die Ihre Abfragen transformieren und erweitern und Ihre Ergebnisse neu einordnen. Die vorgefertigten Abfrageprozessoren umfassen Datumskonvertierung, Aggregation, Zeichenfolgenmanipulation und Datentypkonvertierung. Der Ergebnisprozessor in der Suchpipeline fängt die Ergebnisse im laufenden Betrieb ab und passt sie an, bevor er sie in die nächste Phase überträgt. Sowohl die Anforderungs- als auch die Antwortverarbeitung für die Pipeline werden auf dem Koordinatorknoten durchgeführt, sodass keine Verarbeitung auf Shard-Ebene erfolgt.
Optionale Plugins
Mit dem OpenSearch-Dienst können Sie vorinstallierte Dateien verknüpfen optionale OpenSearch-Plugins zur Verwendung mit Ihrer Domain. Ein optionales Plugin-Paket ist mit einer bestimmten OpenSearch-Version kompatibel und kann nur Domänen mit dieser Version zugeordnet werden. Verfügbare Plugins sind auf der aufgeführt Angebote Seite auf der OpenSearch Service-Konsole. Das optionale Plugin umfasst das Amazon Personalize-Plugin, das OpenSearch Service mit Amazon Personalize integriert, sowie neue Sprachanalysatoren wie Nori, Sudachi, STConvert und Pinyin.
Unterstützung für neue Sprachanalysatoren
OpenSearch Service hat Unterstützung für vier neue hinzugefügt Sprachanalysator-Plugins: Nori (Koreanisch), Sudachi (Japanisch), Pinyin (Chinesisch) und STConvert Analysis (Chinesisch). Diese sind in allen AWS-Regionen als optionale Plugins verfügbar, die Sie mit Domänen verknüpfen können, auf denen eine beliebige OpenSearch-Version ausgeführt wird. Du kannst den ... benutzen Angebote Seite auf der OpenSearch Service-Konsole, um diese Plugins Ihrer Domain zuzuordnen, oder verwenden Sie die Associate Package API.
Neuronale Suchfunktion
Neuronale Suche ist allgemein mit OpenSearch Service Version 2.9 und höher verfügbar. Die neuronale Suche ermöglicht Ihnen die Integration in ML-Modelle, die mithilfe des Model Serving Framework remote gehostet werden. Wenn Sie während der Suche eine neuronale Abfrage verwenden, wandelt die neuronale Suche den Abfragetext in Vektoreinbettungen um, verwendet die Vektorsuche, um die Abfrage und die Dokumenteinbettung zu vergleichen, und gibt die nächstgelegenen Ergebnisse zurück. Während der Aufnahme wandelt die neuronale Suche Dokumenttext in Vektoreinbettungen um und indiziert sowohl den Text als auch seine Vektoreinbettungen in einem Vektorindex.
Integration mit Amazon Personalize
OpenSearch Service hat ein optionales Plugin zur Integration mit Amazon Personalize in OpenSearch-Versionen 2.9 oder höher eingeführt. Mit dem OpenSearch Service-Plugin für das Suchranking von Amazon Personalize können Sie die Endbenutzereinbindung und -konvertierung Ihrer Website- und Anwendungssuche verbessern, indem Sie die Deep-Learning-Funktionen von Amazon Personalize nutzen. Als optionales Plugin ist das Das Paket ist mit OpenSearch Version 2.9 oder höher kompatibelund kann nur Domänen mit dieser Version zugeordnet werden.
Effiziente Abfragefilterung mit k-NN FAISS von OpenSearch
OpenSearch Service führte in Version 2.9 und höher eine effiziente Abfragefilterung mit k-NN FAISS von OpenSearch ein. OpenSearchs effiziente Vektorabfragefilter Die Funktion bewertet auf intelligente Weise optimale Filterstrategien – Vorfilterung mit dem ungefähren nächsten Nachbarn (ANN) oder Filterung mit dem genauen k-nächsten Nachbarn (k-NN) – um die beste Strategie für die Bereitstellung präziser Vektorsuchanfragen mit geringer Latenz zu ermitteln. In früheren OpenSearch-Versionen verwendeten Vektorabfragen auf der FAISS-Engine Nachfiltertechniken, die gefilterte Abfragen in großem Maßstab ermöglichten, aber möglicherweise weniger als die angeforderte „k“-Anzahl an Ergebnissen lieferten. Effiziente Vektorabfragefilter liefern geringe Latenz und genaue Ergebnisse, sodass Sie eine hybride Suche über Vektor- und lexikalische Techniken hinweg nutzen können.
Bytequantisierte Vektoren im OpenSearch Service
Mit dem neuen Byte-quantisierter Vektor Mit 2.9 eingeführt, können Sie den Speicherbedarf um den Faktor 4 reduzieren und die Suchlatenz deutlich reduzieren, bei minimalem Qualitätsverlust (Recall). Mit dieser Funktion werden die üblichen 32-Bit-Floats, die für Vektoren verwendet werden, quantisiert oder in 8-Bit-Ganzzahlen mit Vorzeichen umgewandelt. Für viele Anwendungen können vorhandene Float-Vektordaten mit geringem Qualitätsverlust quantisiert werden. Beim Vergleich von Benchmarks werden Sie feststellen, dass die Verwendung von Byte-Vektoren anstelle von 32-Bit-Floats zu einer erheblichen Reduzierung der Speicher- und Arbeitsspeichernutzung führt und gleichzeitig den Indexierungsdurchsatz verbessert und die Abfragelatenz verringert. Eine interne Maßstab zeigte, dass die Speichernutzung um bis zu 78 % und die RAM-Nutzung um bis zu 59 % reduziert wurden (für den Glove-200-Angular-Datensatz). Die Rückrufwerte für Winkeldatensätze waren niedriger als die für euklidische Datensätze.
AI/ML-Anschlüsse
OpenSearch 2.9 und höher unterstützt Integrationen mit ML-Modellen gehostet auf AWS-Diensten oder Plattformen von Drittanbietern. Dadurch können Systemadministratoren und Datenwissenschaftler ML-Workloads außerhalb ihrer OpenSearch Service-Domäne ausführen. Die ML-Konnektoren werden mit einem unterstützten Satz von ML-Blueprints geliefert – Vorlagen, die den Satz von Parametern definieren, die Sie bereitstellen müssen, wenn Sie API-Anfragen an einen bestimmten Konnektor senden. OpenSearch Service bietet Konnektoren für mehrere Plattformen, wie z Amazon SageMaker, Amazonas Grundgestein, OpenAI-ChatGPT und Zusammenhängen.
Integrationen der OpenSearch Service-Konsole
OpenSearch 2.9 und höher fügte der Konsole eine neue Integrationsfunktion hinzu. Integrations bietet Ihnen eine AWS CloudFormation Vorlage zum Erstellen Ihres semantische Suche Anwendungsfall, indem Sie eine Verbindung zu Ihren auf SageMaker oder Amazon Bedrock gehosteten ML-Modellen herstellen. Die CloudFormation-Vorlage generiert den Modellendpunkt und registriert die Modell-ID bei der OpenSearch Service-Domäne, die Sie als Eingabe für die Vorlage bereitstellen.
Hybride Suche und Bereichsnormalisierung
Das Normalisierungsprozessor und Hybridabfrage baut auf den beiden Funktionen auf, die Anfang 2023 veröffentlicht wurden:neuronale Suche und Suchpipelines. Da lexikalische und semantische Abfragen Relevanzwerte auf unterschiedlichen Skalen zurückgeben, war die Feinabstimmung hybrider Suchabfragen schwierig.
OpenSearch Service 2.11 unterstützt jetzt einen Kombinations- und Normalisierungsprozessor für die Hybridsuche. Sie können jetzt hybride Suchabfragen durchführen, indem Sie eine lexikalische und eine auf natürlicher Sprache basierende k-NN-Vektorsuchabfrage kombinieren. Mit OpenSearch Service können Sie außerdem Ihre hybriden Suchergebnisse mithilfe mehrerer Bewertungskombinationen und Normalisierungstechniken auf maximale Relevanz abstimmen.
Multimodale Suche mit Amazon Bedrock
OpenSearch Service 2.11 führt die Unterstützung der multimodalen Suche ein, die Ihnen die Suche nach Text- und Bilddaten mithilfe multimodaler Einbettungsmodelle ermöglicht. Um Vektoreinbettungen zu generieren, müssen Sie eine Aufnahmepipeline erstellen, die eine enthält text_image_embedding-Prozessor, das die Text- oder Bildbinärdateien in einem Dokumentfeld in Vektoreinbettungen konvertiert. Sie können die neuronale Abfrageklausel entweder im verwenden k-NN-Plugin-API or DSL abfragen Abfragen, um eine Kombination aus Text- und Bildsuche durchzuführen. Sie können die neuen OpenSearch Service-Integrationsfunktionen nutzen, um schnell mit der multimodalen Suche zu beginnen.
Neural spärlicher Abruf
Die neuronale Sparse-Suche, eine neue effiziente Methode zum semantischen Abrufen, ist in OpenSearch Service 2.11 verfügbar. Die neuronale Sparse-Suche funktioniert in zwei Modi: Bi-Encoder und Nur-Dokument. Im Bi-Encoder-Modus werden sowohl Dokumente als auch Suchanfragen durch Deep-Encoder geleitet. Im Nur-Dokument-Modus werden nur Dokumente durch Deep-Encoder geleitet, während Suchanfragen tokenisiert werden. Ein Nur-Dokument-Encoder mit geringer Dichte generiert einen Index, der 10.4 % der Größe eines Index für dichte Codierung beträgt. Bei einem Bi-Encoder beträgt die Indexgröße 7.2 % der Größe eines dichten Codierungsindex. Die neuronale Sparse-Suche wird durch Sparse-Codierungsmodelle ermöglicht, die spärliche Vektoreinbettungen erstellen: eine Reihe von <token: weight> Paare, die den Texteintrag und sein entsprechendes Gewicht im dünn besetzten Vektor darstellen. Weitere Informationen zu den vorab trainierten Modellen für die spärliche neuronale Suche finden Sie unter Sparse-Codierungsmodelle.
Die neuronale Sparse-Suche senkt die Kosten, verbessert die Suchrelevanz und hat eine geringere Latenz. Sie können die neuen OpenSearch Service-Integrationsfunktionen verwenden, um schnell mit der neuronalen Sparse-Suche zu beginnen.
Aktualisierungen der OpenSearch-Aufnahme
OpenSearch-Aufnahme ist eine vollständig verwaltete und automatisch skalierte Aufnahmepipeline, die Ihre Daten an OpenSearch Service-Domänen und OpenSearch Serverless-Sammlungen liefert. Seit seiner Veröffentlichung im Jahr 2023 fügt OpenSearch Ingestion weiterhin neue Funktionen hinzu, um die Transformation und Verschiebung Ihrer Daten zu vereinfachen unterstützte Quellen zu Downstream-Zielen wie OpenSearch Service, OpenSearch Serverless und Amazon S3.
Neue Migrationsfunktionen in OpenSearch Ingestion
Im November 2023 kündigte OpenSearch Ingestion die Veröffentlichung neuer Funktionen zur Unterstützung der Datenmigration von selbstverwalteten Elasticsearch-Domänen der Version 7.x auf die neuesten Versionen von OpenSearch Service an.
OpenSearch Ingestion unterstützt auch die Migration von Daten von OpenSearch Service-verwalteten Domänen, auf denen OpenSearch Version 2.x ausgeführt wird, zu OpenSearch Serverless-Sammlungen.
Erfahren Sie, wie Sie OpenSearch Ingestion nutzen können Migrieren Sie Ihre Daten zum OpenSearch Service.

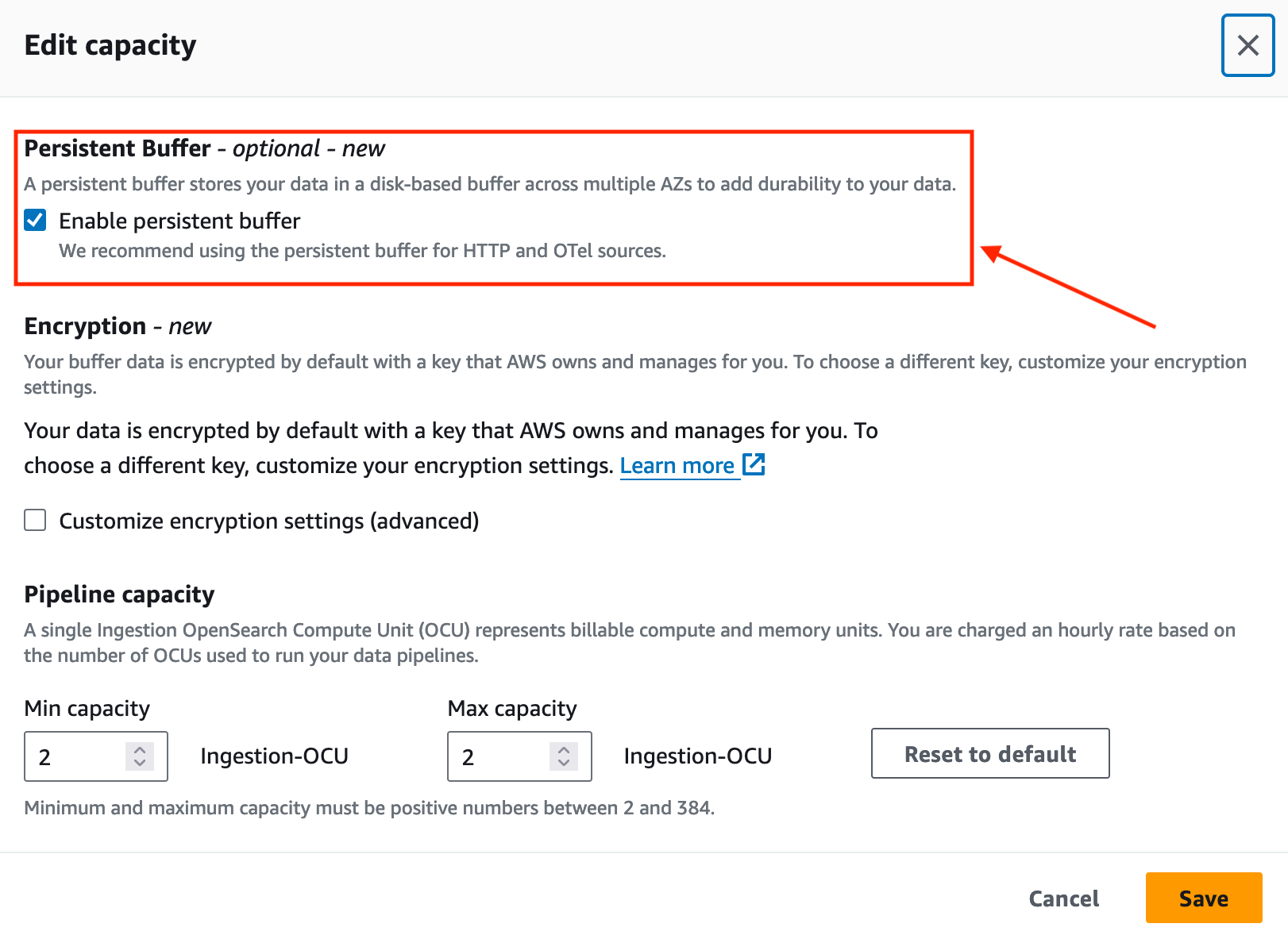
Verbessern Sie die Datenbeständigkeit mit OpenSearch Ingestion
Im November 2023 führte OpenSearch Ingestion dauerhafte Pufferung für Push-basierte Quellen wie HTTP-Quellen (HTTP, Fluentd, FluentBit) und OpenTelemetry-Collectors ein.
Standardmäßig verwendet OpenSearch Ingestion die In-Memory-Pufferung. Mit dauerhafter Pufferung speichert OpenSearch Ingestion Ihre Daten in einem festplattenbasierten Speicher, der stabiler ist. Wenn Sie über bestehende Aufnahmepipelines verfügen, können Sie die dauerhafte Pufferung für diese Pipelines aktivieren, wie im folgenden Screenshot gezeigt.
Unterstützung neuer Plugins
Anfang 2023 fügte OpenSearch Ingestion Unterstützung für hinzu Amazon Managed Streaming für Apache Kafka (Amazon MSK). OpenSearch Ingestion verwendet die Kafka-Plugin um Daten von Amazon MSK an von OpenSearch Service verwaltete Domänen oder OpenSearch Serverless-Sammlungen zu streamen. Weitere Informationen zum Einrichten von Amazon MSK als Datenquelle finden Sie unter Verwendung einer OpenSearch-Ingestion-Pipeline mit Amazon Managed Streaming für Apache Kafka.
OpenSearch Serverless-Updates
OpenSearch Serverless hat Ihr serverloses Erlebnis mit OpenSearch weiter verbessert, indem es die Unterstützung einer neuen Sammlung von Typvektorsuchen zum Speichern von Einbettungen und zum Ausführen einer Ähnlichkeitssuche eingeführt hat. OpenSearch Serverless unterstützt jetzt die Skalierung von Shard-Replikaten, um Spitzen im Abfragedurchsatz zu bewältigen. Und wenn Sie eine Zeitreihensammlung verwenden, können Sie jetzt Ihre benutzerdefinierte Datenaufbewahrungsrichtlinie einrichten, die Ihren Anforderungen an die Datenaufbewahrung entspricht.
Vector Engine für OpenSearch Serverless
Im November 2023 haben wir das gestartet Vektor-Engine für Amazon OpenSearch Serverless. Mit der Vektor-Engine ist es einfach, moderne ML-erweiterte Sucherlebnisse und Anwendungen für generative künstliche Intelligenz (generative KI) zu erstellen, ohne dass die zugrunde liegende Vektordatenbank-Infrastruktur verwaltet werden muss. Es ermöglicht Ihnen auch die Ausführung einer Hybridsuche, bei der Vektorsuche und Volltextsuche in derselben Abfrage kombiniert werden, sodass keine separaten Datenspeicher oder ein komplexer Anwendungsstapel verwaltet und verwaltet werden müssen.
OpenSearch Serverlose, kostengünstigere Entwicklungs- und Testumgebungen
OpenSearch Serverless unterstützt jetzt Entwicklungs- und Test-Workloads, indem es Ihnen ermöglicht, die Ausführung einer Replik zu vermeiden. Durch das Entfernen von Replikaten entfällt die Notwendigkeit, redundante OCUs ausschließlich aus Verfügbarkeitsgründen in einer anderen Availability Zone zu haben. Wenn Sie OpenSearch Serverless für Entwicklung und Tests verwenden, bei denen die Verfügbarkeit keine Rolle spielt, können Sie Ihre Mindest-OCUs von 4 auf 2 senken.
OpenSearch Serverless unterstützt die automatisierte zeitbasierte Datenlöschung mithilfe von Datenlebenszyklusrichtlinien
Im Dezember 2023 kündigte OpenSearch Serverless Unterstützung für die Verwaltung der Datenaufbewahrung von Zeitreihensammlungen und -indizes an. Mit der neuen automatischen zeitbasierten Datenlöschfunktion können Sie festlegen, wie lange Sie Daten aufbewahren möchten. OpenSearch Serverless verwaltet automatisch den Lebenszyklus der Daten basierend auf dieser Konfiguration. Weitere Informationen finden Sie unter Amazon OpenSearch Serverless unterstützt jetzt die automatische zeitbasierte Datenlöschung.
OpenSearch Serverless kündigte Unterstützung für die Skalierung von Replikaten auf Shard-Ebene an
Beim Start unterstützte OpenSearch Serverless die automatische Erhöhung der Kapazität als Reaktion auf wachsende Datenmengen. Mit dem Neue Shard-Replika-Skalierung Mit dieser Funktion erkennt OpenSearch Serverless automatisch Shards, die aufgrund plötzlicher Spitzen in den Abfrageraten unter Druck stehen, und fügt dynamisch neue Shard-Replikate hinzu, um den erhöhten Abfragedurchsatz zu bewältigen und gleichzeitig schnelle Antwortzeiten aufrechtzuerhalten. Dieser Ansatz erweist sich als kosteneffizienter als das einfache Hinzufügen neuer Indexreplikate.
AWS-Benutzerbenachrichtigungen zur Überwachung Ihrer OCU-Nutzung
Mit diesem Start können Sie das System so konfigurieren, dass es Benachrichtigungen sendet, wenn sich die OCU-Auslastung nähert oder die konfigurierten Höchstgrenzen für Suche oder Aufnahme erreicht hat. Mit der neuen AWS-Benutzerbenachrichtigungsintegration können Sie das System so konfigurieren, dass es Benachrichtigungen sendet, wenn der Kapazitätsschwellenwert überschritten wird. Durch die Benutzerbenachrichtigungsfunktion entfällt die Notwendigkeit, den Dienst ständig zu überwachen. Weitere Informationen finden Sie unter Überwachung von Amazon OpenSearch Serverless mithilfe von AWS-Benutzerbenachrichtigungen.
Verbessern Sie Ihr Erlebnis mit OpenSearch-Dashboards
OpenSearch 2.9 im OpenSearch Service führte neue Funktionen ein, um die schnelle Analyse Ihrer Daten in OpenSearch-Dashboards zu vereinfachen. Zu diesen neuen Funktionen gehören die neuen, sofort einsatzbereiten, vorkonfigurierten Dashboards mit OpenSearch-Integrationen und die Möglichkeit, Warnungen und Anomalieerkennung aus einer vorhandenen Visualisierung in Ihren Dashboards zu erstellen.
OpenSearch Dashboard-Integrationen
OpenSearch 2.9 hat die Unterstützung von OpenSearch-Integrationen in OpenSearch-Dashboards hinzugefügt. OpenSearch-Integrationen umfassen vorkonfigurierte Dashboards, sodass Sie schnell mit der Analyse Ihrer Daten aus beliebten Quellen beginnen können, z AWS CloudFront, AWS-WAF, AWS CloudTrail und Amazon Virtual Private Cloud (Amazon VPC) Flussprotokolle.
Warnungen und Anomalien in OpenSearch-Dashboards
In OpenSearch Service 2.9 können Sie direkt von Ihrem aus einen neuen Alarmmonitor erstellen Visualisierung eines Liniendiagramms in OpenSearch-Dashboards. Sie können der Dashboard-Visualisierung auch die vorhandenen Monitore oder Detektoren zuordnen, die zuvor in OpenSearch erstellt wurden.
Diese neue Funktion trägt dazu bei, den Kontextwechsel zwischen Dashboards und den Plugins „Alerting“ oder „Anomaly Detection“ zu reduzieren. Sehen Sie sich das folgende Dashboard an, um einen Warnmonitor hinzuzufügen, um einen Rückgang des durchschnittlichen Datenvolumens in Ihren Diensten zu erkennen.

OpenSearch erweitert die Unterstützung für Geodaten-Aggregationen
Mit OpenSearch Version 2.9 hat OpenSearch Service die Unterstützung von drei Arten von hinzugefügt Geoform Datenaggregation über API: geo_bounds, geo_hash und geo_tile.
Der Geoshape-Feldtyp bietet die Möglichkeit, Standortdaten in verschiedenen geografischen Formaten wie einem Punkt, einem Polygon oder einer Linienfolge zu indizieren. Mit den neuen Aggregationstypen haben Sie mehr Flexibilität beim Aggregieren von Dokumenten aus einem Index mithilfe von Metrik- und Multi-Bucket-Geodatenaggregationen.
Betriebsaktualisierungen des OpenSearch-Dienstes
Durch den OpenSearch-Dienst entfällt die Notwendigkeit, beim Ändern der von der Domäne verwalteten Knoten eine Blau/Grün-Bereitstellung auszuführen. Darüber hinaus hat der Dienst die Auto-Tune-Ereignisse durch die Unterstützung neuer Auto-Tune-Metriken verbessert, um die Änderungen innerhalb Ihrer OpenSearch-Service-Domäne zu verfolgen.
Mit OpenSearch Service können Sie jetzt Domänenmanagerknoten ohne Blau/Grün-Bereitstellung aktualisieren
Seit Beginn der zweiten Jahreshälfte 2 können Sie mit dem OpenSearch Service den Instanztyp oder die Instanzanzahl dedizierter Cluster-Manager-Knoten ändern, ohne dass eine Blau/Grün-Bereitstellung erforderlich ist. Diese Verbesserung ermöglicht schnellere Aktualisierungen mit minimaler Unterbrechung Ihres Domänenbetriebs und vermeidet gleichzeitig jegliche Datenverschiebung.
Bisher bedeutete die Aktualisierung Ihrer dedizierten Cluster-Manager-Knoten im OpenSearch Service, dass für die Änderung eine Blau/Grün-Bereitstellung verwendet wurde. Obwohl Blau/Grün-Bereitstellungen dazu gedacht sind, Störungen Ihrer Domänen zu vermeiden, wird empfohlen, sie in Zeiten mit geringem Datenverkehr durchzuführen, da die Bereitstellung zusätzliche Ressourcen in der Domäne beansprucht. Jetzt können Sie Cluster-Manager-Instanztypen oder Instanzzahlen aktualisieren, ohne dass eine blaue/grüne Bereitstellung erforderlich ist, sodass diese Aktualisierungen schneller abgeschlossen werden können und gleichzeitig mögliche Unterbrechungen Ihres Domänenbetriebs vermieden werden. In Fällen, in denen Sie sowohl den Typ als auch die Anzahl der Domänenmanager-Instanzen ändern, verwendet OpenSearch Service weiterhin eine Blau/Grün-Bereitstellung, um die Änderung vorzunehmen. Mithilfe der Probelaufoption können Sie prüfen, ob Ihre Änderung eine Blau/Grün-Bereitstellung erfordert.
Verbessertes Auto-Tune-Erlebnis
Im September 2023 hat OpenSearch Service neue Auto-Tune-Metriken und verbesserte Auto-Tune-Ereignisse hinzugefügt, die Ihnen einen besseren Einblick in die von Auto-Tune vorgenommenen Optimierungen der Domänenleistung geben.
Auto-Tune ist ein adaptives Ressourcenverwaltungssystem, das OpenSearch Service-Domänenressourcen automatisch aktualisiert, um Effizienz und Leistung zu verbessern. Auto-Tune optimiert beispielsweise speicherbezogene Konfigurationen wie Warteschlangengrößen, Cachegrößen und Java Virtual Machine (JVM)-Einstellungen auf Ihren Knoten.
Mit dieser Einführung können Sie nun den Verlauf der Änderungen prüfen und diese in Echtzeit verfolgen Amazon CloudWatch Konsole.
Darüber hinaus veröffentlicht OpenSearch Service jetzt Details zu den Änderungen an Amazon EventBridge wenn Auto-Tune-Einstellungen empfohlen oder auf eine OpenSearch Service-Domäne angewendet werden. Diese Auto-Tune-Ereignisse werden auch auf der angezeigt Benachrichtigungen Seite auf der OpenSearch Service-Konsole.
Beschleunigen Sie Ihre Migration zum OpenSearch Service mit der neuen Migration Assistant-Lösung
Im November 2023 brachte das OpenSearch-Team eine neue Open-Source-Lösung auf den Markt:Migrationsassistent für Amazon OpenSearch Service. Die Lösung unterstützt die Datenmigration von selbstverwalteten Elasticsearch- und OpenSearch-Domänen zum OpenSearch Service und unterstützt Elasticsearch 7.x (<=7.10), OpenSearch 1.x und OpenSearch 2.x als Migrationsquellen. Die Lösung erleichtert die Migration der vorhandenen und Live-Daten zwischen Quelle und Ziel.
Zusammenfassung
In diesem Beitrag haben wir die neuen Versionen von OpenSearch Service behandelt, um Sie bei der Innovation Ihres Unternehmens durch Suche, Observability, Sicherheitsanalysen und Migrationen zu unterstützen. Wir haben Ihnen Informationen darüber bereitgestellt, wann Sie die einzelnen neuen Funktionen in OpenSearch Service, OpenSearch Ingestion und OpenSearch Serverless verwenden sollten.
Erfahren Sie mehr über OpenSearch-Dashboards und OpenSearch-Plugins sowie den neuen aufregenden OpenSearch-Assistenten OpenSearch-Spielplatz.
Schauen Sie sich die in diesem Beitrag beschriebenen Funktionen an und wir freuen uns über Ihr wertvolles Feedback.
Über die Autoren
 Jon Handler ist Senior Principal Solutions Architect bei Amazon Web Services mit Sitz in Palo Alto, Kalifornien. Jon arbeitet eng mit OpenSearch und Amazon OpenSearch Service zusammen und bietet Hilfe und Anleitung für eine breite Palette von Kunden, die Such- und Protokollanalyse-Workloads haben, die sie in die AWS Cloud verlagern möchten. Bevor er zu AWS kam, war Jon in seiner Karriere als Softwareentwickler vier Jahre lang mit der Programmierung einer großen E-Commerce-Suchmaschine beschäftigt. Jon hat einen Bachelor of the Arts von der University of Pennsylvania sowie einen Master of Science und einen Ph.D. in Informatik und Künstlicher Intelligenz von der Northwestern University.
Jon Handler ist Senior Principal Solutions Architect bei Amazon Web Services mit Sitz in Palo Alto, Kalifornien. Jon arbeitet eng mit OpenSearch und Amazon OpenSearch Service zusammen und bietet Hilfe und Anleitung für eine breite Palette von Kunden, die Such- und Protokollanalyse-Workloads haben, die sie in die AWS Cloud verlagern möchten. Bevor er zu AWS kam, war Jon in seiner Karriere als Softwareentwickler vier Jahre lang mit der Programmierung einer großen E-Commerce-Suchmaschine beschäftigt. Jon hat einen Bachelor of the Arts von der University of Pennsylvania sowie einen Master of Science und einen Ph.D. in Informatik und Künstlicher Intelligenz von der Northwestern University.
 Hajer Bouafif ist ein Analytics Specialist Solutions Architect bei Amazon Web Services. Sie konzentriert sich auf den Amazon OpenSearch Service und unterstützt Kunden beim Entwerfen und Aufbau gut strukturierter Analyse-Workloads in verschiedenen Branchen. Hajer verbringt gerne Zeit im Freien und entdeckt neue Kulturen.
Hajer Bouafif ist ein Analytics Specialist Solutions Architect bei Amazon Web Services. Sie konzentriert sich auf den Amazon OpenSearch Service und unterstützt Kunden beim Entwerfen und Aufbau gut strukturierter Analyse-Workloads in verschiedenen Branchen. Hajer verbringt gerne Zeit im Freien und entdeckt neue Kulturen.
 Aruna Govindaraju ist ein Amazon OpenSearch Specialist Solutions Architect und hat mit vielen kommerziellen und Open-Source-Suchmaschinen zusammengearbeitet. Ihre Leidenschaft gilt der Suche, Relevanz und Benutzererfahrung. Ihre Expertise in der Korrelation von Endbenutzersignalen mit dem Suchmaschinenverhalten hat vielen Kunden dabei geholfen, ihr Sucherlebnis zu verbessern.
Aruna Govindaraju ist ein Amazon OpenSearch Specialist Solutions Architect und hat mit vielen kommerziellen und Open-Source-Suchmaschinen zusammengearbeitet. Ihre Leidenschaft gilt der Suche, Relevanz und Benutzererfahrung. Ihre Expertise in der Korrelation von Endbenutzersignalen mit dem Suchmaschinenverhalten hat vielen Kunden dabei geholfen, ihr Sucherlebnis zu verbessern.
 Prashant Agrawal ist Senior Search Specialist Solutions Architect beim Amazon OpenSearch Service. Er arbeitet eng mit Kunden zusammen, um ihnen bei der Migration ihrer Workloads in die Cloud zu helfen, und hilft bestehenden Kunden bei der Feinabstimmung ihrer Cluster, um eine bessere Leistung zu erzielen und Kosten zu sparen. Bevor er zu AWS kam, half er verschiedenen Kunden, OpenSearch und Elasticsearch für ihre Such- und Protokollanalyse-Anwendungsfälle zu verwenden. Wenn er nicht arbeitet, reist er oft und erkundet neue Orte. Kurz gesagt, er macht gerne Eat → Travel → Repeat.
Prashant Agrawal ist Senior Search Specialist Solutions Architect beim Amazon OpenSearch Service. Er arbeitet eng mit Kunden zusammen, um ihnen bei der Migration ihrer Workloads in die Cloud zu helfen, und hilft bestehenden Kunden bei der Feinabstimmung ihrer Cluster, um eine bessere Leistung zu erzielen und Kosten zu sparen. Bevor er zu AWS kam, half er verschiedenen Kunden, OpenSearch und Elasticsearch für ihre Such- und Protokollanalyse-Anwendungsfälle zu verwenden. Wenn er nicht arbeitet, reist er oft und erkundet neue Orte. Kurz gesagt, er macht gerne Eat → Travel → Repeat.
 Muslim Abu Taha ist Senior OpenSearch Specialist Solutions Architect und widmet sich der Führung von Kunden durch nahtlose Such-Workload-Migrationen, der Feinabstimmung von Clustern für Spitzenleistung und der Gewährleistung von Kosteneffizienz. Mit einem Hintergrund als Technical Account Manager (TAM) bringt Muslim umfangreiche Erfahrung in der Unterstützung von Unternehmenskunden bei der Cloud-Einführung und der Optimierung ihrer unterschiedlichen Arbeitslasten mit. Muslim verbringt gerne Zeit mit seiner Familie, reist und erkundet neue Orte.
Muslim Abu Taha ist Senior OpenSearch Specialist Solutions Architect und widmet sich der Führung von Kunden durch nahtlose Such-Workload-Migrationen, der Feinabstimmung von Clustern für Spitzenleistung und der Gewährleistung von Kosteneffizienz. Mit einem Hintergrund als Technical Account Manager (TAM) bringt Muslim umfangreiche Erfahrung in der Unterstützung von Unternehmenskunden bei der Cloud-Einführung und der Optimierung ihrer unterschiedlichen Arbeitslasten mit. Muslim verbringt gerne Zeit mit seiner Familie, reist und erkundet neue Orte.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/amazon-opensearch-h2-2023-in-review/

