Wir freuen uns, dies heute bekannt geben zu können Amazon DataZone ist nun in der Lage, Informationen zur Datenqualität für Datenbestände zu präsentieren. Mithilfe dieser Informationen können Endbenutzer fundierte Entscheidungen darüber treffen, ob sie bestimmte Vermögenswerte verwenden möchten oder nicht.
Viele Organisationen nutzen es bereits AWS Glue-Datenqualität Datenqualitätsregeln für ihre Daten zu definieren und durchzusetzen, Validieren Sie Daten anhand vordefinierter Regeln, Datenqualitätsmetriken verfolgen und Überwachen Sie die Datenqualität im Laufe der Zeit mithilfe künstlicher Intelligenz (KI).. Andere Organisationen überwachen die Qualität ihrer Daten durch Lösungen von Drittanbietern.
Amazon DataZone lässt sich jetzt direkt in AWS Glue integrieren, um Datenqualitätswerte für AWS Glue Data Catalog-Assets anzuzeigen. Darüber hinaus bietet Amazon DataZone jetzt APIs zum Importieren von Datenqualitätswerten aus externen Systemen.
In diesem Beitrag besprechen wir die neuesten Funktionen von Amazon DataZone für die Datenqualität, die Integration zwischen Amazon DataZone und AWS Glue Data Quality und wie Sie von externen Systemen erstellte Datenqualitätswerte über die API in Amazon DataZone importieren können.
Herausforderungen
Eine der häufigsten Fragen, die wir von Kunden erhalten, betrifft die Anzeige von Datenqualitätswerten im Amazon DataZone-Geschäftsdatenkatalog um Geschäftsanwendern Einblick in den Zustand und die Zuverlässigkeit der Datensätze zu geben.
Da Daten für Geschäftsentscheidungen immer wichtiger werden, sind Amazon DataZone-Benutzer sehr daran interessiert, höchste Datenqualitätsstandards bereitzustellen. Sie sind sich der Bedeutung genauer, vollständiger und aktueller Daten bewusst, um eine fundierte Entscheidungsfindung zu ermöglichen und das Vertrauen in ihre Analyse- und Berichtsprozesse zu stärken.
Amazon DataZone-Datenbestände können in unterschiedlichen Häufigkeiten aktualisiert werden. Wenn Daten aktualisiert und aktualisiert werden, kann es durch vorgelagerte Prozesse zu Änderungen kommen, die das Risiko mit sich bringen, dass die beabsichtigte Qualität nicht eingehalten wird. Datenqualitätsbewertungen helfen Ihnen zu verstehen, ob die Daten das erwartete Qualitätsniveau für die Nutzung durch Datenkonsumenten beibehalten haben (durch Analyse oder nachgelagerte Prozesse).
Aus Produzentensicht können Datenverwalter jetzt Amazon DataZone so einrichten, dass die Datenqualitätswerte automatisch aus AWS Glue Data Quality importiert werden (geplant oder auf Anfrage) und diese Informationen in den Amazon DataZone-Katalog aufnehmen, um sie mit Geschäftsbenutzern zu teilen. Darüber hinaus können Sie jetzt neue Amazon DataZone-APIs verwenden, um von externen Systemen erstellte Datenqualitätsbewertungen in die Datenbestände zu importieren.
Mit der neuesten Verbesserung können Amazon DataZone-Benutzer jetzt Folgendes erreichen:
- Erhalten Sie Einblicke in Datenqualitätsstandards direkt über das Amazon DataZone-Webportal
- Zeigen Sie Datenqualitätswerte für verschiedene KPIs an, einschließlich Datenvollständigkeit, Einzigartigkeit und Genauigkeit
- Stellen Sie sicher, dass Benutzer einen ganzheitlichen Überblick über die Qualität und Vertrauenswürdigkeit ihrer Daten haben.
Im ersten Teil dieses Beitrags gehen wir auf die Integration zwischen AWS Glue Data Quality und Amazon DataZone ein. Wir besprechen, wie Sie Datenqualitätswerte in Amazon DataZone visualisieren, AWS Glue Data Quality beim Erstellen einer neuen Amazon DataZone-Datenquelle aktivieren und die Datenqualität für ein vorhandenes Datenasset aktivieren.
Im zweiten Teil dieses Beitrags besprechen wir, wie Sie von externen Systemen erstellte Datenqualitätswerte über die API in Amazon DataZone importieren können. In diesem Beispiel verwenden wir Amazon EMR ohne Server in Kombination mit der Open-Source-Bibliothek Pydeequ als externes System für die Datenqualität zu fungieren.
Visualisieren Sie die Datenqualitätsergebnisse von AWS Glue in Amazon DataZone
Sie können jetzt AWS Glue-Datenqualitätsbewertungen in Datenbeständen visualisieren, die im Amazon DataZone-Geschäftskatalog veröffentlicht wurden und über das Amazon DataZone-Webportal durchsuchbar sind.
Wenn für das Asset AWS Glue Data Quality aktiviert ist, können Sie den Datenqualitätsfaktor jetzt schnell direkt im Suchbereich des Katalogs visualisieren.

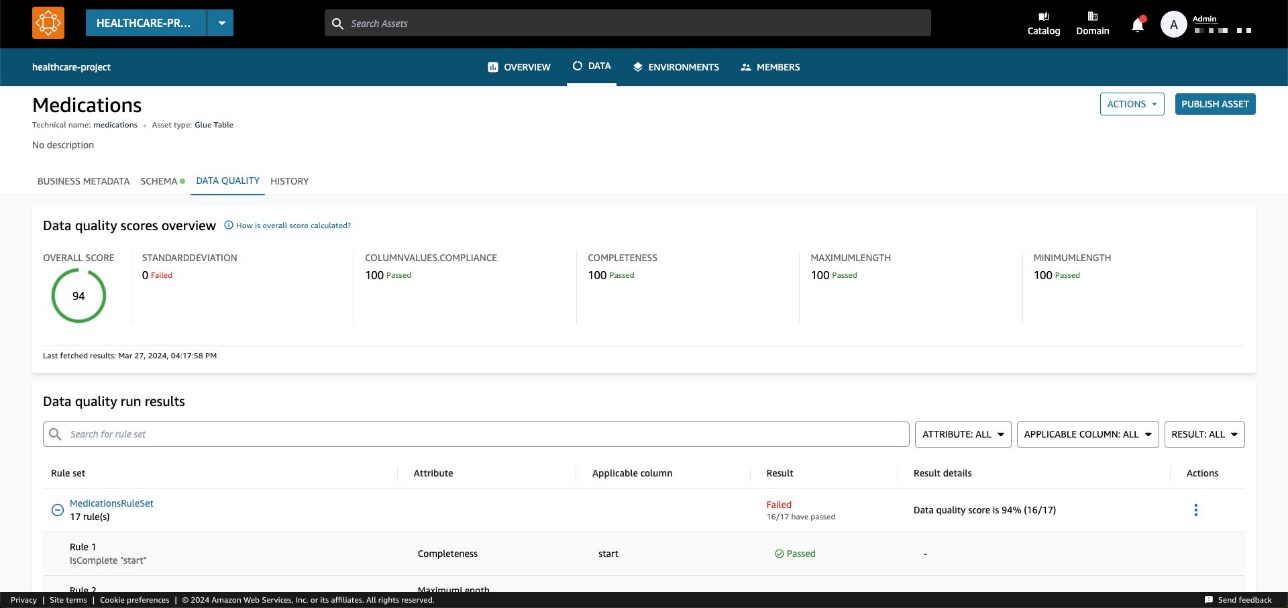
Durch Auswahl des entsprechenden Assets können Sie dessen Inhalt in der Readme-Datei nachvollziehen. Glossarbegriffe und technische und geschäftliche Metadaten. Darüber hinaus wird der Gesamtindikator für die Qualitätsbewertung im angezeigt Asset-Details .

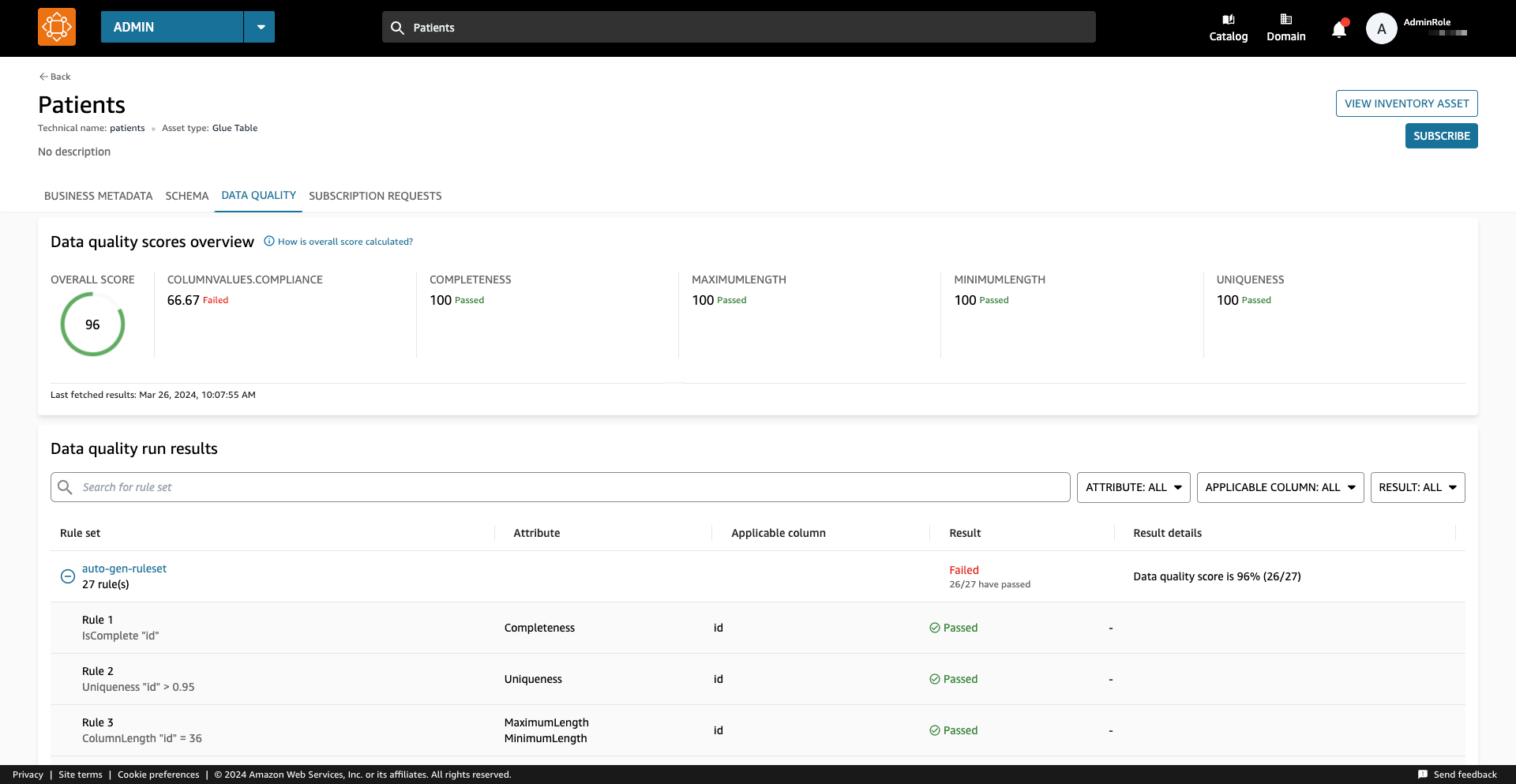
Ein Datenqualitätswert dient als Gesamtindikator für die Qualität eines Datensatzes und wird auf der Grundlage der von Ihnen definierten Regeln berechnet.
Auf dem Datenqualität Auf der Registerkarte können Sie auf die Details der Datenqualitätsübersichtsindikatoren und die Ergebnisse der Datenqualitätsläufe zugreifen.
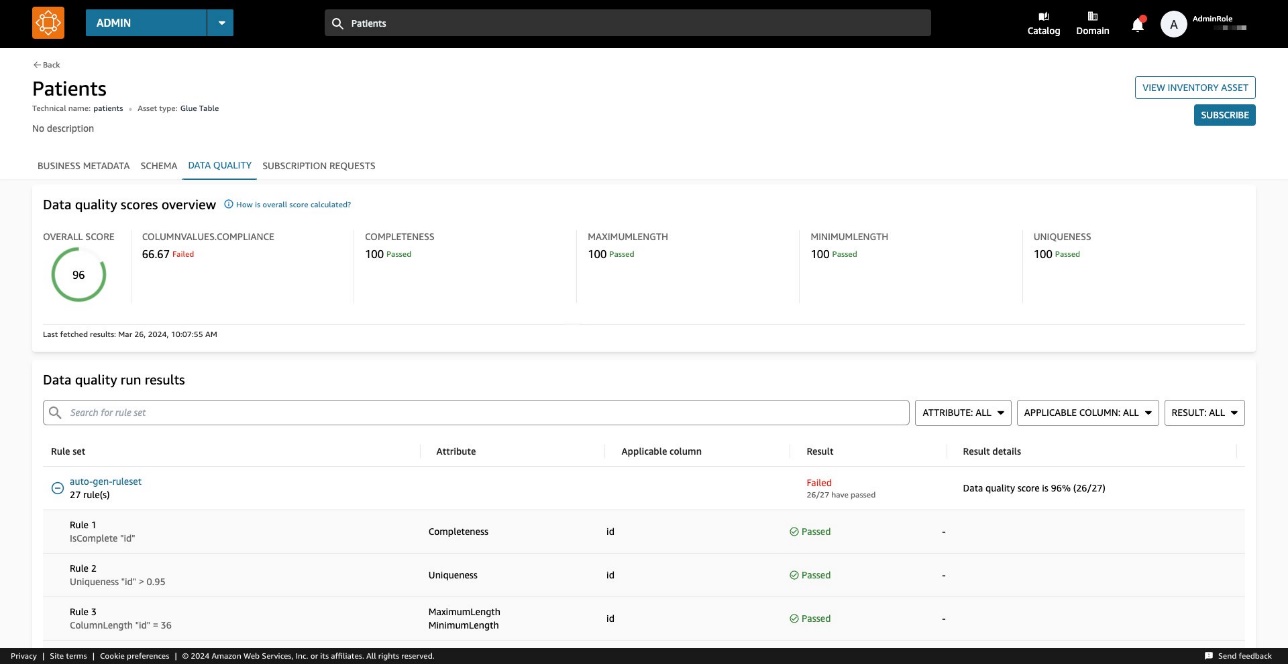
Die auf dem angezeigten Indikatoren Überblick werden basierend auf den Ergebnissen der Regelsätze aus den Datenqualitätsläufen berechnet.
Jeder Regel ist ein Attribut zugeordnet, das zur Berechnung des Indikators beiträgt. Zum Beispiel Regeln, die das haben Completeness Das Attribut trägt zur Berechnung des entsprechenden Indikators bei Überblick Tab.
Um Datenqualitätsergebnisse zu filtern, wählen Sie die Option aus Anwendbare Spalte Dropdown-Menü und wählen Sie den gewünschten Filterparameter aus.

Sie können die Datenqualität auch auf Spaltenebene visualisieren, beginnend mit Schema Tab.

Wenn die Datenqualität für das Asset aktiviert ist, werden die Datenqualitätsergebnisse verfügbar und liefern aufschlussreiche Qualitätsbewertungen, die die Integrität und Zuverlässigkeit jeder Spalte im Datensatz widerspiegeln.
Wenn Sie einen der Datenqualitäts-Ergebnislinks auswählen, werden Sie zur Datenqualitäts-Detailseite weitergeleitet, gefiltert nach der ausgewählten Spalte.

Historische Ergebnisse zur Datenqualität in Amazon DataZone
Die Datenqualität kann sich im Laufe der Zeit aus vielen Gründen ändern:
- Datenformate können sich aufgrund von Änderungen in den Quellsystemen ändern
- Da sich Daten im Laufe der Zeit ansammeln, können sie veraltet oder inkonsistent werden
- Die Datenqualität kann durch menschliche Fehler bei der Dateneingabe, Datenverarbeitung oder Datenmanipulation beeinträchtigt werden
In Amazon DataZone können Sie jetzt die Datenqualität im Zeitverlauf verfolgen, um Zuverlässigkeit und Genauigkeit zu bestätigen. Durch die Analyse des historischen Berichts-Snapshots können Sie Bereiche mit Verbesserungspotenzial identifizieren, Änderungen implementieren und die Wirksamkeit dieser Änderungen messen.

Aktivieren Sie AWS Glue Data Quality, wenn Sie eine neue Amazon DataZone-Datenquelle erstellen
In diesem Abschnitt gehen wir die Schritte durch, um AWS Glue Data Quality beim Erstellen einer neuen Amazon DataZone-Datenquelle zu aktivieren.
Voraussetzungen:
Um mitzumachen, sollten Sie eine Domäne für Amazon DataZone, ein Amazon DataZone-Projekt und ein neues haben Amazon DataZone-Umgebung (mit einem DataLakeProfile). Anweisungen finden Sie unter Amazon DataZone-Schnellstart mit AWS Glue-Daten.
Sie müssen außerdem einen Regelsatz für Ihre Daten definieren und ausführen, bei dem es sich um einen Satz Datenqualitätsregeln in AWS Glue Data Quality handelt. Informationen zum Einrichten der Datenqualitätsregeln und weitere Informationen zum Thema finden Sie in den folgenden Beiträgen:
Nachdem Sie die Datenqualitätsregeln erstellt haben, stellen Sie sicher, dass Amazon DataZone über die Berechtigungen verfügt, auf die über verwaltete AWS Glue-Datenbank zuzugreifen AWS Lake-Formation. Anweisungen finden Sie unter Konfigurieren Sie Lake Formation-Berechtigungen für Amazon DataZone.
In unserem Beispiel haben wir einen Regelsatz für eine Tabelle konfiguriert, die Patientendaten innerhalb eines enthält Synthetischer Datensatz für das Gesundheitswesen generiert mit Synthea. Synthea ist ein synthetischer Patientengenerator, der realistische Patientendaten und zugehörige Krankenakten erstellt, die zum Testen von Softwareanwendungen im Gesundheitswesen verwendet werden können.
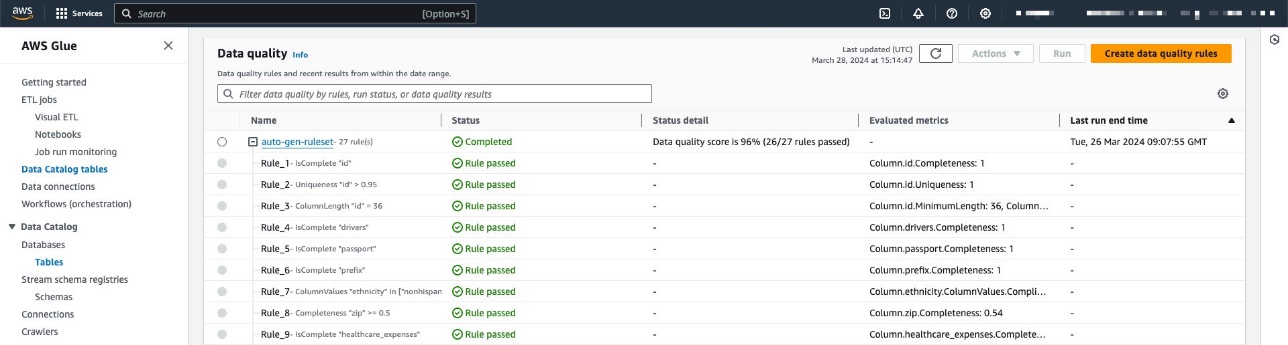
Der Regelsatz enthält 27 einzelne Regeln (eine davon schlägt fehl), sodass die Gesamtbewertung der Datenqualität 96 % beträgt.
Wenn Sie von Amazon DataZone verwaltete Richtlinien verwenden, ist keine Aktion erforderlich, da diese automatisch mit den erforderlichen Aktionen aktualisiert werden. Andernfalls müssen Sie Amazon DataZone die erforderlichen Berechtigungen zum Auflisten und Abrufen von AWS Glue Data Quality-Ergebnissen gewähren, wie in der Abbildung gezeigt Amazon DataZone-Benutzerhandbuch.
Erstellen Sie eine Datenquelle mit aktivierter Datenqualität
In diesem Abschnitt erstellen wir eine Datenquelle und aktivieren die Datenqualität. Sie können auch eine vorhandene Datenquelle aktualisieren, um die Datenqualität zu ermöglichen. Wir verwenden diese Datenquelle, um Metadateninformationen zu unseren Datensätzen zu importieren. Amazon DataZone importiert auch Datenqualitätsinformationen zu den (einem oder mehreren) Assets, die in der Datenquelle enthalten sind.
- Wählen Sie in der Amazon DataZone-Konsole Datenquellen im Navigationsbereich.
- Auswählen
Datenquelle erstellen.

- Aussichten für Name und Vorname, geben Sie einen Namen für Ihre Datenquelle ein.
- Aussichten für DatenquellentypWählen AWS-Kleber.
- Aussichten für Arbeitsumfeld, wählen Sie Ihre Umgebung.

- Aussichten für Name der DatenbankGeben Sie einen Namen für die Datenbank ein.
- Aussichten für Kriterien für die Tabellenauswahl, wählen Sie Ihre Kriterien.
- Auswählen
Weiter.

- Aussichten für DatenqualitätWählen Aktivieren Sie die Datenqualität für diese Datenquelle.
Wenn die Datenqualität aktiviert ist, ruft Amazon DataZone bei jedem Datenquellenlauf automatisch Datenqualitätswerte von AWS Glue ab.
- Auswählen
Weiter.

Jetzt können Sie die Datenquelle ausführen.

Während die Datenquelle ausgeführt wird, importiert Amazon DataZone die letzten 100 AWS Glue Data Quality-Laufergebnisse. Diese Informationen sind jetzt auf der Asset-Seite sichtbar und nach der Veröffentlichung des Assets für alle Amazon DataZone-Benutzer sichtbar.
Aktivieren Sie die Datenqualität für ein vorhandenes Datenasset
In diesem Abschnitt aktivieren wir die Datenqualität für ein vorhandenes Asset. Dies kann für Benutzer nützlich sein, die bereits über Datenquellen verfügen und die Funktion anschließend aktivieren möchten.
Voraussetzungen:
Um mitzumachen, sollten Sie die Datenquelle bereits ausgeführt und ein AWS Glue-Tabellendatenasset erstellt haben. Darüber hinaus sollten Sie in AWS Glue Data Quality einen Regelsatz für die Zieltabelle im Datenkatalog definiert haben.

In diesem Beispiel haben wir den Datenqualitätsauftrag mehrmals für die Tabelle ausgeführt und dabei die zugehörigen AWS Glue-Datenqualitätswerte erstellt, wie im folgenden Screenshot dargestellt.

Importieren Sie Datenqualitätswerte in das Datenasset
Führen Sie die folgenden Schritte aus, um die vorhandenen AWS Glue-Datenqualitätsbewertungen in das Datenasset in Amazon DataZone zu importieren:
- Navigieren Sie im Amazon DataZone-Projekt zu Inventurdaten Bereich und wählen Sie die Datenquelle aus.
Wenn Sie die Datenqualität Auf der Registerkarte können Sie sehen, dass noch keine Informationen zur Datenqualität vorliegen, da die AWS Glue Data Quality-Integration für dieses Datenasset noch nicht aktiviert ist.
- Auf dem Datenqualität Tab, wählen Sie Aktivieren Sie Datenqualität.

- Im Datenqualität Abschnitt auswählen Aktivieren Sie die Datenqualität für diese Datenquelle.
- Auswählen
Speichern.

Zurück im Bereich „Inventardaten“ sehen Sie nun eine neue Registerkarte: Datenqualität.
Auf dem Datenqualität Auf der Registerkarte können Sie die aus AWS Glue Data Quality importierten Datenqualitätswerte sehen.
Erfassen Sie Datenqualitätswerte aus einer externen Quelle mithilfe der Amazon DataZone-APIs
Viele Organisationen verwenden bereits Systeme, die die Datenqualität berechnen, indem sie Tests und Aussagen zu ihren Datensätzen durchführen. Amazon DataZone unterstützt jetzt den Import von Datenqualitätsbewertungen Dritter über API, sodass Benutzer, die im Webportal navigieren, diese Informationen anzeigen können.
In diesem Abschnitt simulieren wir ein Drittanbietersystem, das Datenqualitätswerte über APIs in Amazon DataZone überträgt Boto3 (Python SDK für AWS).
Für dieses Beispiel verwenden wir dasselbe synthetischer Datensatz wie zuvor, generiert mit Synthea.
Das folgende Diagramm zeigt die Lösungsarchitektur.

Der Arbeitsablauf besteht aus den folgenden Schritten:
- Lesen Sie einen Datensatz von Patienten ein Amazon Simple Storage-Service (Amazon S3) direkt von Amazon EMR mit Spark.
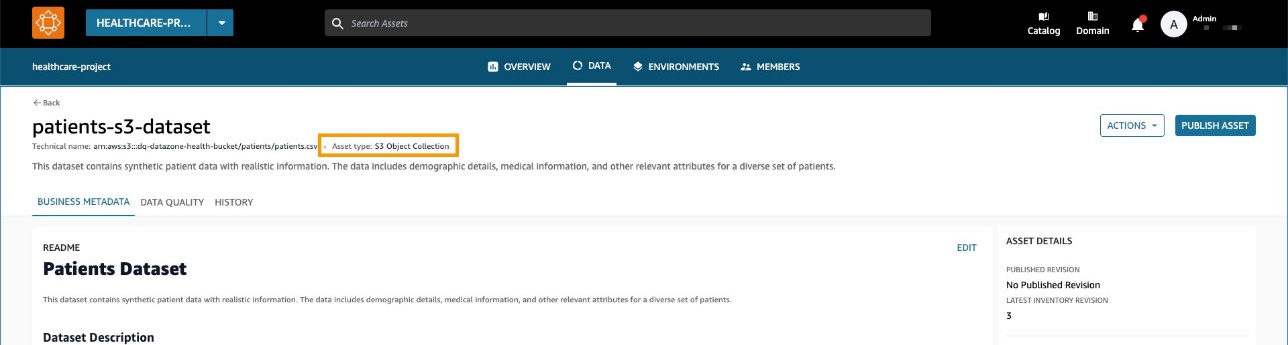
Der Datensatz wird als generische S3-Asset-Sammlung in Amazon DataZone erstellt.
- Führen Sie in Amazon EMR Datenvalidierungsregeln für den Datensatz durch.
- Die Metriken werden in Amazon S3 gespeichert, um eine dauerhafte Ausgabe zu ermöglichen.
- Verwenden Sie Amazon DataZone-APIs über Boto3, um benutzerdefinierte Metadaten zur Datenqualität zu pushen.
- Endbenutzer können die Datenqualitätswerte sehen, indem sie zum Datenportal navigieren.
Voraussetzungen:
Wir verwenden Amazon EMR ohne Server und Pydeequ, um ein vollständig verwaltetes System auszuführen Spark Umfeld. Weitere Informationen zu Pydeequ als Datentest-Framework finden Sie unter Testen Sie die Datenqualität im großen Maßstab mit Pydeequ.
Damit Amazon EMR Daten an die Amazon DataZone-Domäne senden kann, stellen Sie sicher, dass die von Amazon EMR verwendete IAM-Rolle über die Berechtigungen für Folgendes verfügt:
- Lesen und Schreiben in die S3-Buckets
- Ruf den
post_time_series_data_pointsAktion für Amazon DataZone:
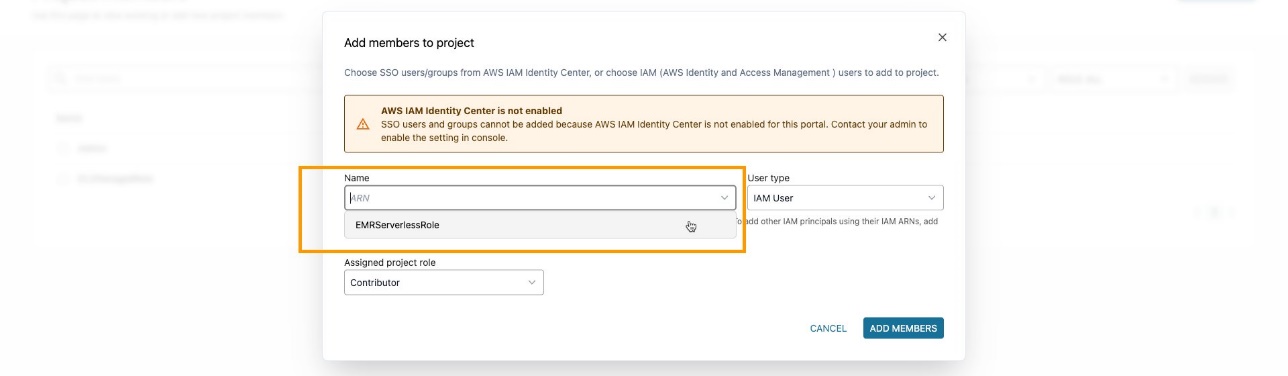
Stellen Sie sicher, dass Sie die EMR-Rolle als hinzugefügt haben Projektmitglied im Amazon DataZone-Projekt. Navigieren Sie in der Amazon DataZone-Konsole zu Projektmitglieder Seite und wählen Mitglieder hinzufügen.

Fügen Sie die EMR-Rolle als Mitwirkender hinzu.
Nehmen Sie PySpark-Code auf und analysieren Sie ihn
In diesem Abschnitt analysieren wir den PySpark-Code, den wir zur Durchführung von Datenqualitätsprüfungen verwenden, und senden die Ergebnisse an Amazon DataZone. Sie können das komplette herunterladen PySpark-Skript.
Um das Skript vollständig auszuführen, können Sie einen Job an EMR Serverless senden. Der Dienst kümmert sich um die Planung des Auftrags und die automatische Zuweisung der benötigten Ressourcen, sodass Sie den Auftrag nachverfolgen können Jobausführungsstatus während des gesamten Prozesses.
Du kannst dich Senden Sie einen Auftrag an EMR in der Amazon EMR-Konsole mit EMR Studio oder programmgesteuert mit dem AWS-CLI oder mit einem der AWS-SDKs.
In Apache Spark, a SparkSession ist der Einstiegspunkt für die Interaktion mit DataFrames und den integrierten Funktionen von Spark. Das Skript beginnt mit der Initialisierung von a SparkSession:
Wir lesen einen Datensatz von Amazon S3. Für eine erhöhte Modularität können Sie die Skripteingabe verwenden, um auf den S3-Pfad zu verweisen:
Als Nächstes richten wir ein Metrik-Repository ein. Dies kann hilfreich sein, um die Laufergebnisse in Amazon S3 beizubehalten.
Mit Pydeequ können Sie Datenqualitätsregeln mithilfe des Builder-Musters erstellen, einem bekannten Entwurfsmuster für die Softwareentwicklung, bei dem Anweisungen zum Instanziieren von a verkettet werden VerificationSuite Objekt:
Das Folgende ist die Ausgabe für die Datenvalidierungsregeln:
An dieser Stelle wollen wir diese Datenqualitätswerte in Amazon DataZone einfügen. Dazu nutzen wir die post_time_series_data_points Funktion im Boto3 Amazon DataZone-Client.
Das PostTimeSeriesDataPoints DataZone-API ermöglicht Ihnen das Einfügen neuer Zeitreihendatenpunkte für ein bestimmtes Asset oder eine bestimmte Auflistung, ohne eine neue Revision zu erstellen.
An dieser Stelle möchten Sie möglicherweise auch weitere Informationen darüber erhalten, welche Felder als Eingabe für die API gesendet werden. Du kannst den ... benutzen APIs um die Spezifikation für Amazon DataZone-Formulartypen zu erhalten; in unserem Fall ist es so amazon.datazone.DataQualityResultFormType.
Sie können auch die AWS CLI verwenden, um die API aufzurufen und die Formularstruktur anzuzeigen:
Diese Ausgabe hilft bei der Identifizierung der erforderlichen API-Parameter, einschließlich Feldern und Wertgrenzen:
Um die entsprechenden Formulardaten zu senden, müssen wir die Pydeequ-Ausgabe so konvertieren, dass sie mit der übereinstimmt DataQualityResultsFormType Vertrag. Dies kann mit einer Python-Funktion erreicht werden, die die Ergebnisse verarbeitet.
Für jede DataFrame-Zeile extrahieren wir Informationen aus der Einschränkungsspalte. Nehmen Sie zum Beispiel den folgenden Code:
Wir konvertieren es wie folgt:
Stellen Sie sicher, dass Sie eine Ausgabe senden, die den KPIs entspricht, die Sie verfolgen möchten. In unserem Fall hängen wir an _custom zum Statistiknamen hinzugefügt, was zu folgendem Format für KPIs führt:
Completeness_customUniqueness_custom
In einem realen Szenario möchten Sie möglicherweise einen Wert festlegen, der mit Ihrem Datenqualitäts-Framework in Bezug auf die KPIs übereinstimmt, die Sie in Amazon DataZone verfolgen möchten.
Nach der Anwendung einer Transformationsfunktion haben wir für jede Regelauswertung ein Python-Objekt:
Wir verwenden auch die constraint_status Spalte zur Berechnung der Gesamtpunktzahl:
In unserem Beispiel ergibt dies eine Erfolgsquote von 85.71 %.
Diesen Wert legen wir im fest passingPercentage Eingabefeld zusammen mit den anderen Informationen zu den Auswertungen in der Eingabe der Boto3-Methode post_time_series_data_points:
Boto3 ruft die auf Amazon DataZone-APIs. In diesen Beispielen haben wir Boto3 und Python verwendet, Sie können jedoch eines davon auswählen AWS-SDKs in der von Ihnen bevorzugten Sprache entwickelt.
Nachdem wir die entsprechende Domäne und Asset-ID festgelegt und die Methode ausgeführt haben, können wir in der Amazon DataZone-Konsole überprüfen, ob die Asset-Datenqualität jetzt auf der Asset-Seite sichtbar ist.
Wir können beobachten, dass die Gesamtpunktzahl mit dem API-Eingabewert übereinstimmt. Wir können auch sehen, dass wir durch benutzerdefinierte Parameterwerte benutzerdefinierte KPIs auf der Registerkarte „Übersicht“ hinzufügen konnten.
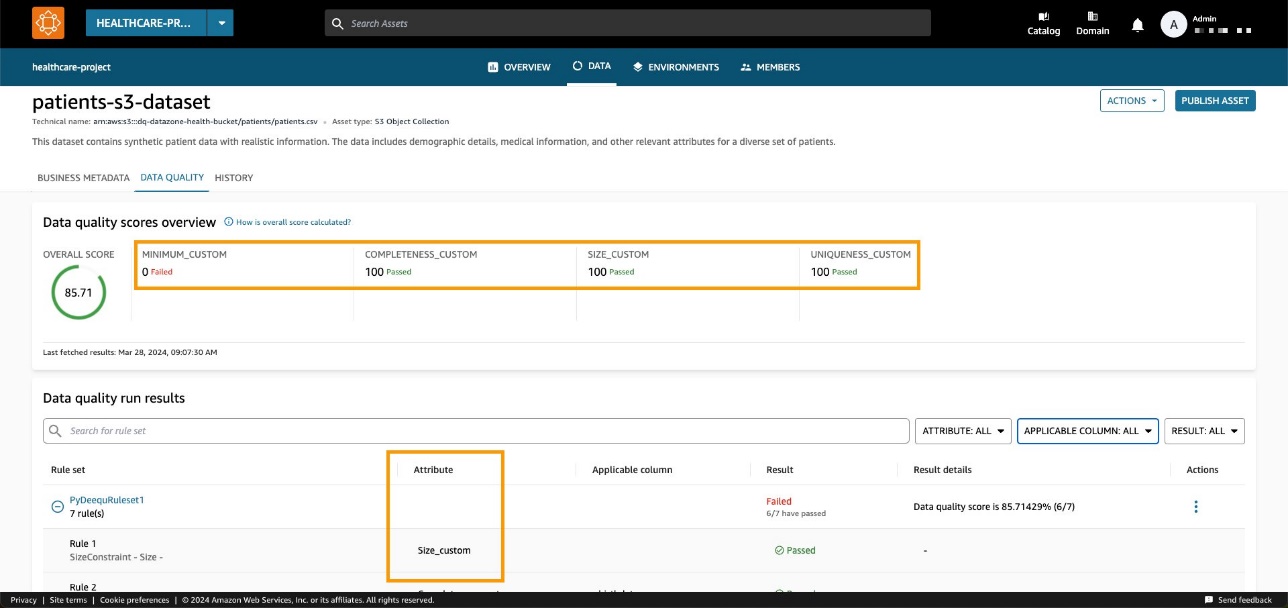
Mit den neuen Amazon DataZone-APIs können Sie Datenqualitätsregeln aus Drittsystemen in ein bestimmtes Datenasset laden. Mit dieser Funktion können Sie mit Amazon DataZone die in AWS Glue Data Quality vorhandenen Indikatorentypen (z. B. Vollständigkeit, Minimum und Eindeutigkeit) um benutzerdefinierte Indikatoren erweitern.
Aufräumen
Wir empfehlen, alle potenziell ungenutzten Ressourcen zu löschen, um unerwartete Kosten zu vermeiden. Das können Sie zum Beispiel Löschen Sie die Amazon DataZone-Domäne und für EMR-Anwendung Sie haben während dieses Prozesses erstellt.
Zusammenfassung
In diesem Beitrag haben wir die neuesten Funktionen von Amazon DataZone für die Datenqualität hervorgehoben, die Endbenutzern einen verbesserten Kontext und Einblick in ihre Datenbestände ermöglichen. Darüber hinaus haben wir uns mit der nahtlosen Integration zwischen Amazon DataZone und AWS Glue Data Quality befasst. Sie können die Amazon DataZone-APIs auch zur Integration mit externen Datenqualitätsanbietern verwenden und so eine umfassende und robuste Datenstrategie in Ihrer AWS-Umgebung beibehalten.
Weitere Informationen zu Amazon DataZone finden Sie im Amazon DataZone-Benutzerhandbuch.
Über die Autoren
 Andrea Filippo ist Partner Solutions Architect bei AWS und unterstützt Partner und Kunden des öffentlichen Sektors in Italien. Sein Schwerpunkt liegt auf modernen Datenarchitekturen und der Unterstützung von Kunden bei der Beschleunigung ihrer Cloud-Reise mit serverlosen Technologien.
Andrea Filippo ist Partner Solutions Architect bei AWS und unterstützt Partner und Kunden des öffentlichen Sektors in Italien. Sein Schwerpunkt liegt auf modernen Datenarchitekturen und der Unterstützung von Kunden bei der Beschleunigung ihrer Cloud-Reise mit serverlosen Technologien.
 Emanuele ist Lösungsarchitekt bei AWS mit Sitz in Italien, nachdem er mehr als fünf Jahre in Spanien gelebt und gearbeitet hat. Er unterstützt gerne große Unternehmen bei der Einführung von Cloud-Technologien und sein Fachgebiet konzentriert sich hauptsächlich auf Datenanalyse und Datenmanagement. Außerhalb der Arbeit reist er gerne und sammelt Actionfiguren.
Emanuele ist Lösungsarchitekt bei AWS mit Sitz in Italien, nachdem er mehr als fünf Jahre in Spanien gelebt und gearbeitet hat. Er unterstützt gerne große Unternehmen bei der Einführung von Cloud-Technologien und sein Fachgebiet konzentriert sich hauptsächlich auf Datenanalyse und Datenmanagement. Außerhalb der Arbeit reist er gerne und sammelt Actionfiguren.
 Varsha Velagapudi ist Senior Technical Product Manager bei Amazon DataZone bei AWS. Ihr Schwerpunkt liegt auf der Verbesserung der für die Datenanalyse erforderlichen Datenermittlung und -kuratierung. Ihre Leidenschaft liegt darin, die KI/ML- und Analytics-Reise ihrer Kunden zu vereinfachen, um ihnen bei der Bewältigung ihrer täglichen Aufgaben zu helfen. Außerhalb der Arbeit genießt sie die Natur und Outdoor-Aktivitäten, liest und reist gerne.
Varsha Velagapudi ist Senior Technical Product Manager bei Amazon DataZone bei AWS. Ihr Schwerpunkt liegt auf der Verbesserung der für die Datenanalyse erforderlichen Datenermittlung und -kuratierung. Ihre Leidenschaft liegt darin, die KI/ML- und Analytics-Reise ihrer Kunden zu vereinfachen, um ihnen bei der Bewältigung ihrer täglichen Aufgaben zu helfen. Außerhalb der Arbeit genießt sie die Natur und Outdoor-Aktivitäten, liest und reist gerne.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/amazon-datazone-now-integrates-with-aws-glue-data-quality-and-external-data-quality-solutions/

