Letzte Woche haben wir das angekündigt allgemeine Verfügbarkeit der Integration zwischen Amazon DataZone und AWS Lake-Formation Hybrider Zugriffsmodus. In diesem Beitrag teilen wir mit, wie diese neue Funktion Ihnen hilft, die Art und Weise, wie Sie Amazon DataZone nutzen, zu vereinfachen, um eine sichere und kontrollierte Freigabe Ihrer Daten in der zu ermöglichen AWS-Kleber Datenkatalog. Wir befassen uns auch damit, wie Datenproduzenten ihre AWS Glue-Tabellen über Amazon DataZone teilen können, ohne sie zuerst in Lake Formation registrieren zu müssen.
Überblick über die Amazon DataZone-Integration mit dem Hybridzugriffsmodus von Lake Formation
Amazon DataZone ist ein vollständig verwalteter Datenverwaltungsdienst zum Katalogisieren, Entdecken, Analysieren, Teilen und Verwalten von Daten zwischen Datenproduzenten und -konsumenten in Ihrem Unternehmen. Mit Amazon DataZone füllen Datenproduzenten den Geschäftsdatenkatalog mit Datenbeständen aus Datenquellen wie dem AWS Glue Data Catalog und Amazon RedShift. Sie reichern ihre Assets außerdem mit geschäftlichem Kontext an, um den Datenkonsumenten das Verständnis zu erleichtern. Sobald die Daten im Katalog verfügbar sind, können Datenkonsumenten wie Analysten und Datenwissenschaftler diese Daten suchen und darauf zugreifen, indem sie Abonnements anfordern. Wenn die Anfrage genehmigt wird, kann Amazon DataZone automatisch Zugriff auf die Daten bereitstellen, indem Berechtigungen in Lake Formation oder Amazon Redshift verwaltet werden, sodass der Datenkonsument mit Tools wie z. B. beginnen kann, die Daten abzufragen Amazonas Athena oder Amazon Redshift.
Um den Zugriff auf Daten im AWS Glue Data Catalog zu verwalten, verwendet Amazon DataZone Lake Formation. Wenn Sie bisher Amazon DataZone zum Verwalten des Zugriffs auf Ihre Daten im AWS Glue Data Catalog verwenden wollten, mussten Sie Ihre Daten zunächst in Lake Formation integrieren. Die Integration des Hybridzugriffsmodus von Amazon DataZone und Lake Formation vereinfacht nun den Einstieg in Ihre Amazon DataZone-Reise, da Sie Ihre Daten nicht mehr zuerst in Lake Formation einbinden müssen.
Seebildung Hybrider Zugriffsmodus ermöglicht es Ihnen, mit der Verwaltung von Berechtigungen für Ihre AWS Glue-Datenbanken und -Tabellen über Lake Formation zu beginnen und gleichzeitig alle vorhandenen Berechtigungen beizubehalten AWS Identity and Access Management and (IAM)-Berechtigungen für diese Tabellen und Datenbanken. Der hybride Zugriffsmodus von Lake Formation unterstützt zwei Berechtigungspfade zu denselben Data Catalog-Datenbanken und -Tabellen:
- Im ersten Weg ermöglicht Ihnen Lake Formation, bestimmte Prinzipale auszuwählen (Opt-In-Prinzipale) und ihnen durch Opt-In Lake Formation-Berechtigungen für den Zugriff auf Datenbanken und Tabellen zu erteilen
- Der zweite Weg ermöglicht allen anderen Prinzipalen (die nicht als Opt-in-Prinzipale hinzugefügt wurden) den Zugriff auf diese Ressourcen über die IAM-Prinzipalrichtlinien für Amazon Simple Storage-Service (Amazon S3) und AWS Glue-Aktionen
Mit der Integration zwischen Amazon DataZone und dem Hybridzugriffsmodus von Lake Formation können Sie, wenn Sie Tabellen im AWS Glue-Datenkatalog haben, die über IAM-basierte Richtlinien verwaltet werden, diese Tabellen direkt in Amazon DataZone veröffentlichen, ohne sie in Lake Formation zu registrieren. Amazon DataZone registriert den Standort dieser Tabellen in Lake Formation mithilfe des Hybridzugriffsmodus, der die Verwaltung von Berechtigungen für AWS Glue-Tabellen über Lake Formation ermöglicht und gleichzeitig alle vorhandenen IAM-Berechtigungen weiterhin beibehält.
Mit Amazon DataZone können Sie jede Art von Asset im Geschäftsdatenkatalog veröffentlichen. Für einige dieser Assets kann Amazon DataZone Zugriffsgewährungen automatisch verwalten. Diese Vermögenswerte werden aufgerufen verwaltetes Vermögenund umfassen von Lake Formation verwaltete Data Catalog-Tabellen sowie Amazon Redshift-Tabellen und -Ansichten. Vor dieser Integration mussten Sie die folgenden Schritte ausführen, bevor Amazon DataZone die veröffentlichte Data Catalog-Tabelle als verwaltetes Asset behandeln konnte:
- Identifizieren Sie den Amazon S3-Standort, der der Datenkatalogtabelle zugeordnet ist.
- Registrieren Sie den Amazon S3-Standort bei Lake Formation im Hybridzugriffsmodus mit a Rolle mit entsprechenden Berechtigungen.
- Veröffentlichen Sie die Tabellenmetadaten im Amazon DataZone-Geschäftsdatenkatalog.
Das folgende Diagramm veranschaulicht diesen Workflow.
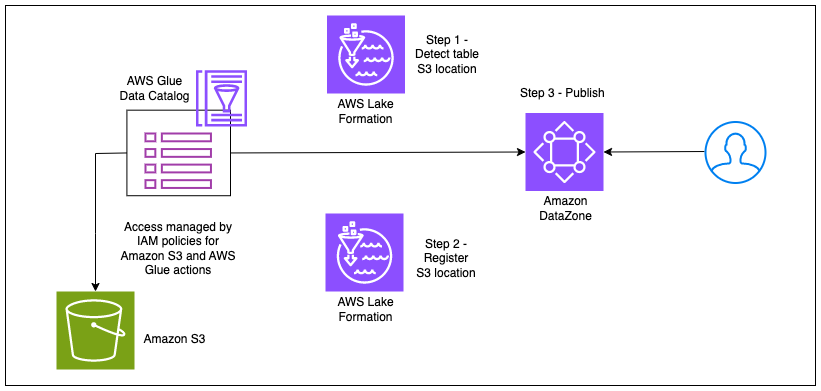
Mit der Integration von Amazon DataZone in den Hybridzugriffsmodus von Lake Formation können Sie Ihre AWS Glue-Tabellen einfach in Amazon DataZone veröffentlichen, ohne sich um die Registrierung des Amazon S3-Standorts oder das Hinzufügen eines Opt-In-Prinzipals in Lake Formation kümmern zu müssen, indem Sie diese Schritte an Amazon DataZone delegieren . Der Administrator eines AWS-Kontos kann die Einstellung zur Datenstandortregistrierung unter aktivieren DefaultDataLake Blaupause auf der Amazon DataZone-Konsole. Jetzt kann ein Dateneigentümer oder Herausgeber seine AWS Glue-Tabelle (verwaltet über IAM-Berechtigungen) ohne zusätzliche Einrichtungsschritte in Amazon DataZone veröffentlichen. Wenn ein Datenkonsument diese Tabelle abonniert, registriert Amazon DataZone die Amazon S3-Speicherorte der Tabelle im Hybridzugriffsmodus, fügt die IAM-Rolle des Datenkonsumenten als Opt-in-Prinzipal hinzu und gewährt Zugriff auf dieselbe IAM-Rolle durch die Verwaltung von Berechtigungen für Tisch durch die Lake Formation. Dadurch wird sichergestellt, dass IAM-Berechtigungen für die Tabelle mit neu erteilten Lake Formation-Berechtigungen koexistieren können, ohne dass bestehende Arbeitsabläufe unterbrochen werden. Das folgende Diagramm veranschaulicht diesen Arbeitsablauf.

Lösungsüberblick
Um diese neue Funktion zu demonstrieren, verwenden wir ein Beispielkundenszenario, in dem das Finanzteam für Finanzanalysen und Berichte auf Daten zugreifen möchte, die dem Vertriebsteam gehören. Das Verkaufsteam verfügt über eine Pipeline, die einen Datensatz mit wertvollen Informationen über Ticketverkäufe, beliebte Veranstaltungen, Veranstaltungsorte und Saisons erstellt. Wir nennen es den Tickit-Datensatz. Das Vertriebsteam speichert diesen Datensatz in Amazon S3 und registriert ihn in einer Datenbank im Datenkatalog. Der Zugriff auf diese Tabelle wird derzeit über IAM-basierte Berechtigungen verwaltet. Das Vertriebsteam möchte diese Tabelle jedoch in Amazon DataZone veröffentlichen, um einen sicheren und kontrollierten Datenaustausch mit dem Finanzteam zu ermöglichen.
Die Schritte zum Konfigurieren dieser Lösung lauten wie folgt:
- Der Amazon DataZone-Administrator aktiviert die Data Lake-Standortregistrierungseinstellung in Amazon DataZone, um den Amazon S3-Standort der AWS Glue-Tabellen automatisch im Lake Formation-Hybridzugriffsmodus zu registrieren.
- Nachdem die Hybrid-Zugriffsmodus-Integration in Amazon DataZone aktiviert wurde, fordert das Finanzteam ein Abonnement für das Verkaufsdaten-Asset an. Das Asset wird als verwaltetes Asset angezeigt, was bedeutet, dass Amazon DataZone den Zugriff auf dieses Asset auch dann verwalten kann, wenn der Amazon S3-Standort dieses Assets nicht in Lake Formation registriert ist.
- Das Vertriebsteam wird über eine vom Finanzteam gestellte Abonnementanfrage benachrichtigt. Sie prüfen und genehmigen die Zugriffsanfrage. Nachdem die Anfrage genehmigt wurde, erfüllt Amazon DataZone die Abonnementanfrage, indem es die Berechtigungen in der Lake Formation verwaltet. Es registriert den Amazon S3-Standort der abonnierten Tabelle im Lake Formation-Hybridmodus.
- Das Finanzteam erhält Zugriff auf den für seine Finanzberichte erforderlichen Verkaufsdatensatz. Sie können in ihre DataZone-Umgebung gehen und mit Athena Abfragen für ihren abonnierten Datensatz ausführen.
Voraussetzungen:
Um die Schritte in diesem Beitrag ausführen zu können, benötigen Sie ein AWS-Konto. Wenn Sie kein Konto haben, können Sie dies tun erstelle einen. Darüber hinaus müssen in Ihrem Konto die folgenden Ressourcen konfiguriert sein:
- Ein S3-Eimer
- Eine AWS Glue-Datenbank und ein Crawler
- IAM-Rollen für verschiedene Personas und Dienste
- Eine Amazon DataZone-Domäne und ein Projekt
- Ein Amazon DataZone-Umgebungsprofil und eine Umgebung
- Eine Amazon DataZone-Datenquelle
Wenn Sie diese Ressourcen noch nicht konfiguriert haben, können Sie sie erstellen, indem Sie Folgendes bereitstellen AWS CloudFormation Stapel:
- Auswählen
Stack starten um eine CloudFormation-Vorlage bereitzustellen.

- Führen Sie die Schritte zum Bereitstellen der Vorlage aus und belassen Sie alle Einstellungen auf den Standardeinstellungen.
- Auswählen Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt, Dann wählen Absenden.
Nachdem die CloudFormation-Bereitstellung abgeschlossen ist, können Sie sich beim Amazon DataZone-Portal anmelden und manuell eine Datenquellenausführung auslösen. Dadurch werden alle neuen oder geänderten Metadaten aus der Quelle abgerufen und die zugehörigen Assets im Inventar aktualisiert. Diese Datenquelle wurde so konfiguriert, dass die Datenbestände automatisch im Katalog veröffentlicht werden.
- Wählen Sie in der Amazon DataZone-Konsole Domains ansehen.
Sie sollten mit derselben Rolle angemeldet sein, die für die Bereitstellung von CloudFormation verwendet wird, und sicherstellen, dass Sie sich in derselben AWS-Region befinden.
- Finden Sie die Domäne
blog_dz_domain, Dann wählen Offenes Datenportal. - Auswählen
Durchsuchen Sie alle Projekte und wählen Sie Vertriebsproduzentenprojekt.
- Auf dem Datum Tab, wählen Sie Datenquellen im Navigationsbereich.
- Suchen Sie die Datenquelle, die Sie ausführen möchten, und wählen Sie sie aus.
Dadurch wird die Seite mit den Datenquellendetails geöffnet.
- Wählen Sie das Optionsmenü (drei vertikale Punkte) daneben
tickit_datasourceund wählen Sie Führen Sie.
Der Status der Datenquelle ändert sich in „Wird ausgeführt“, während Amazon DataZone die Asset-Metadaten aktualisiert.
Aktivieren Sie die Integration im Hybridmodus in Amazon DataZone
In diesem Schritt durchläuft der Amazon DataZone-Administrator den Prozess der Aktivierung der Amazon DataZone-Integration mit dem Hybridzugriffsmodus von Lake Formation. Führen Sie die folgenden Schritte aus:
- Öffnen Sie auf einer separaten Browser-Registerkarte die Amazon DataZone-Konsole.
Stellen Sie sicher, dass Sie sich in derselben Region befinden, in der Sie die CloudFormation-Vorlage bereitgestellt haben.
- Auswählen Domains ansehen.
- Wählen Sie die von AWS CloudFormation erstellte Domäne aus.
blog_dz_domain. - Scrollen Sie auf der Seite mit den Domaindetails nach unten und wählen Sie die aus Blaupausen Tab.
A Entwurf definiert, welche AWS-Tools und -Dienste mit den in Amazon DataZone veröffentlichten Datenbeständen verwendet werden können. Der DefaultDataLake Blueprint wird als Teil der CloudFormation-Stack-Bereitstellung aktiviert. Mit diesem Blueprint können Sie AWS Glue-Tabellen mit Athena erstellen und abfragen. Die Schritte zum Aktivieren dieser Funktion in Ihren eigenen Bereitstellungen finden Sie unter Aktivieren Sie integrierte Blueprints im AWS-Konto, das die Amazon DataZone-Domäne besitzt.
- Wähle die
DefaultDataLakeEntwurf.
- Auf dem Provisioning Tab, wählen Sie Bearbeiten.
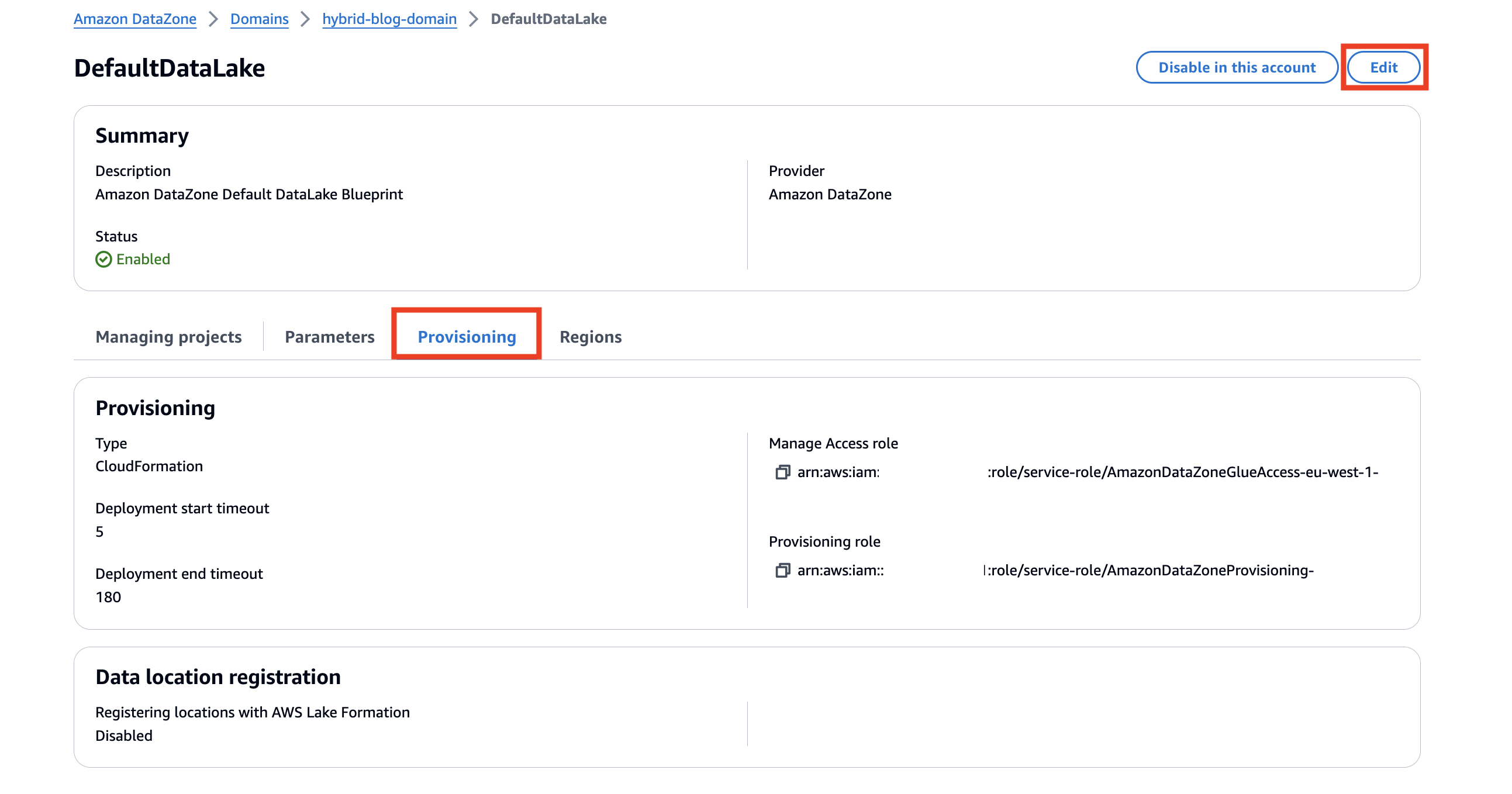
- Auswählen Aktivieren Sie Amazon DataZone, um S3-Standorte mithilfe des AWS Lake Formation-Hybridzugriffsmodus zu registrieren.
Sie haben die Möglichkeit, bestimmte Amazon S3-Standorte auszuschließen, wenn Sie nicht möchten, dass Amazon DataZone sie automatisch im Lake Formation-Hybrid-Zugriffsmodus registriert.
- Auswählen
Änderungen speichern.

Recht auf Zugriff
In diesem Schritt melden Sie sich als Finanzteam bei Amazon DataZone an, suchen nach dem Verkaufsdaten-Asset und abonnieren es. Führen Sie die folgenden Schritte aus:
- Kehren Sie zur Browser-Registerkarte Ihres Amazon DataZone-Datenportals zurück.
- Wechseln Sie zum Finanzkonsumentenprojekt, indem Sie das Dropdown-Menü neben dem Projektnamen auswählen und auswählen Verbraucherprojekt finanzieren.
Von diesem Schritt an schlüpfen Sie in die Rolle eines Finanzbenutzers, der ein im vorherigen Schritt veröffentlichtes Datenasset abonnieren möchte.
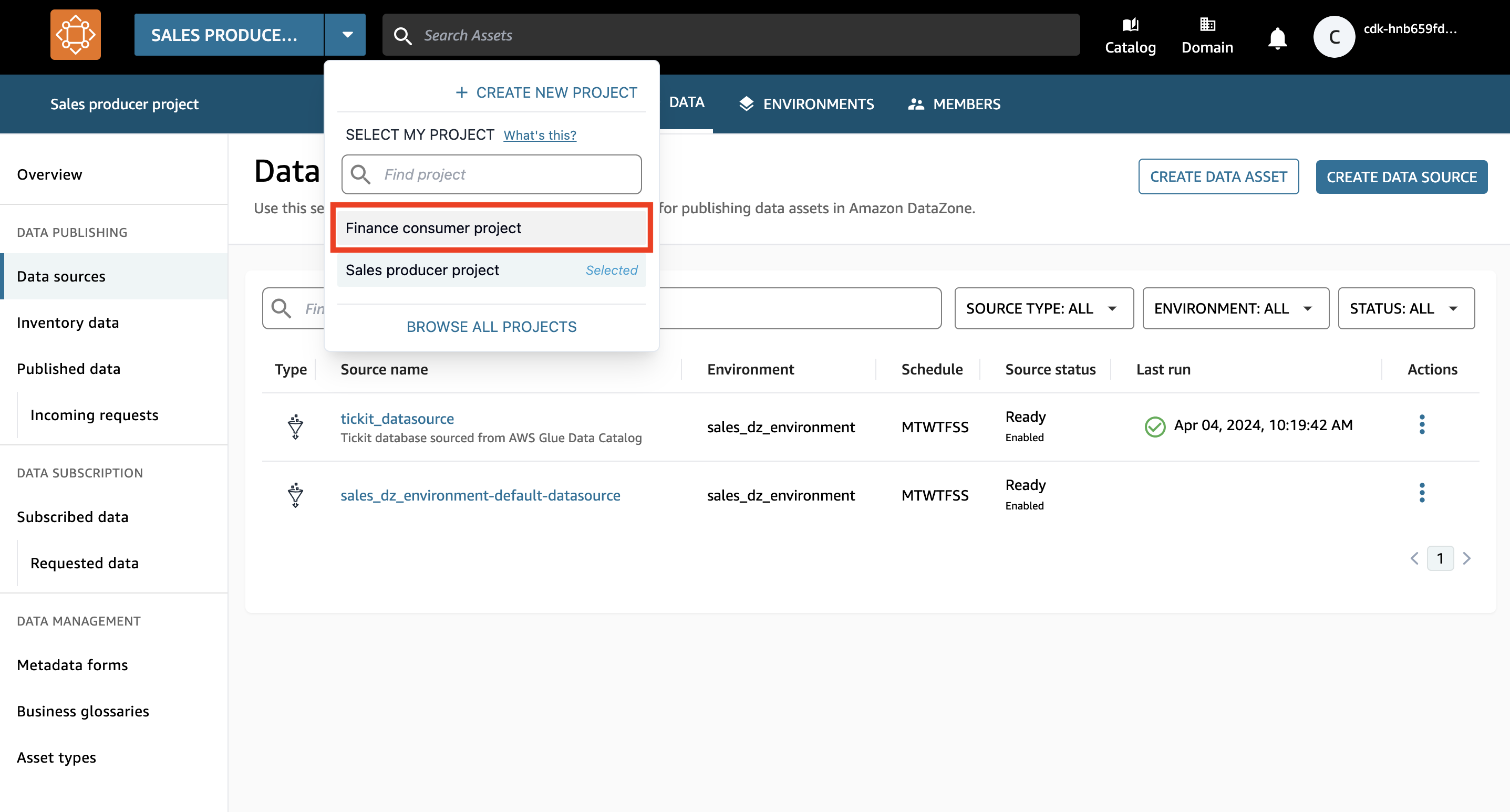
- Suchen Sie in der Suchleiste nach und wählen Sie aus
salesDatenbestand.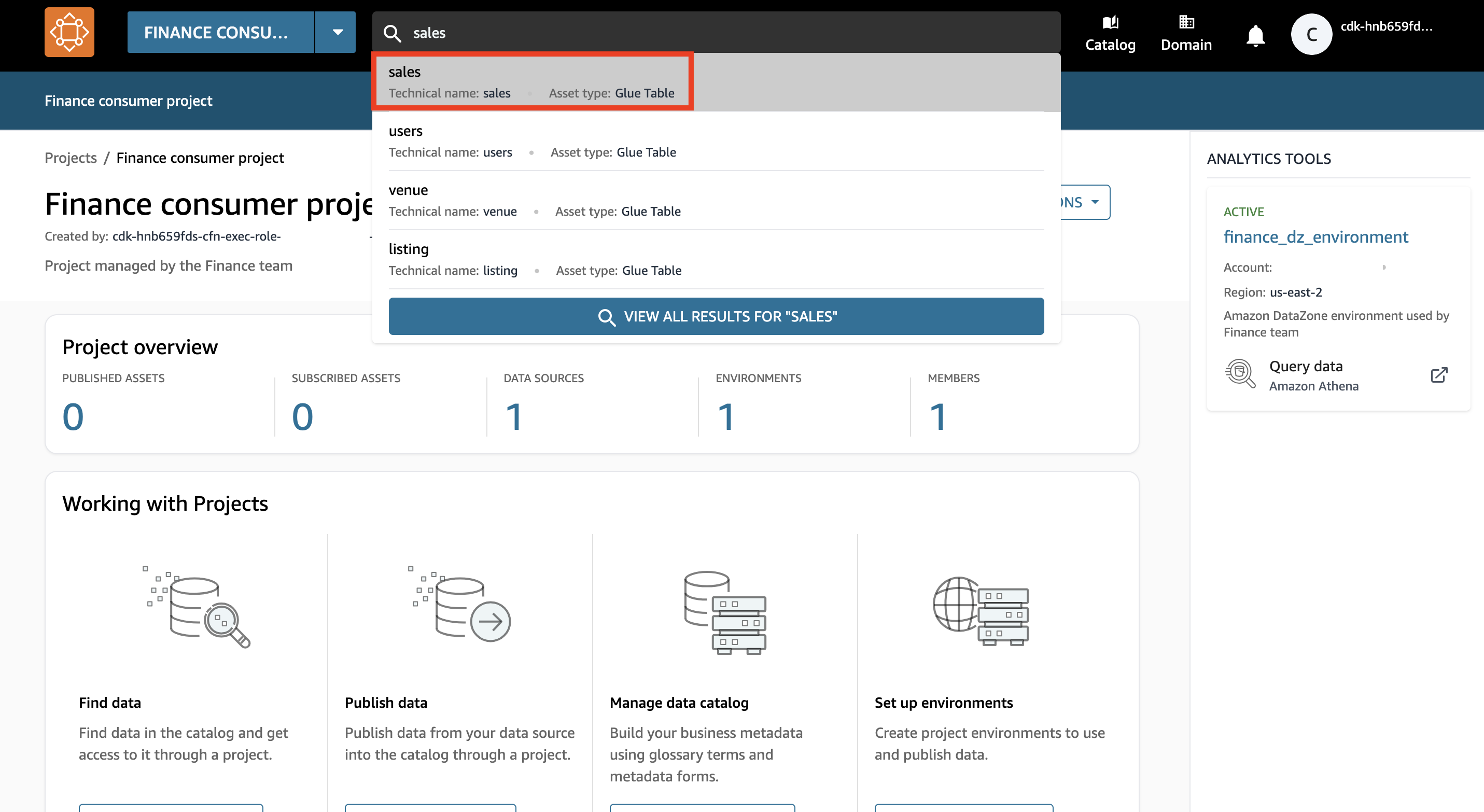
- Auswählen
Abonnieren.
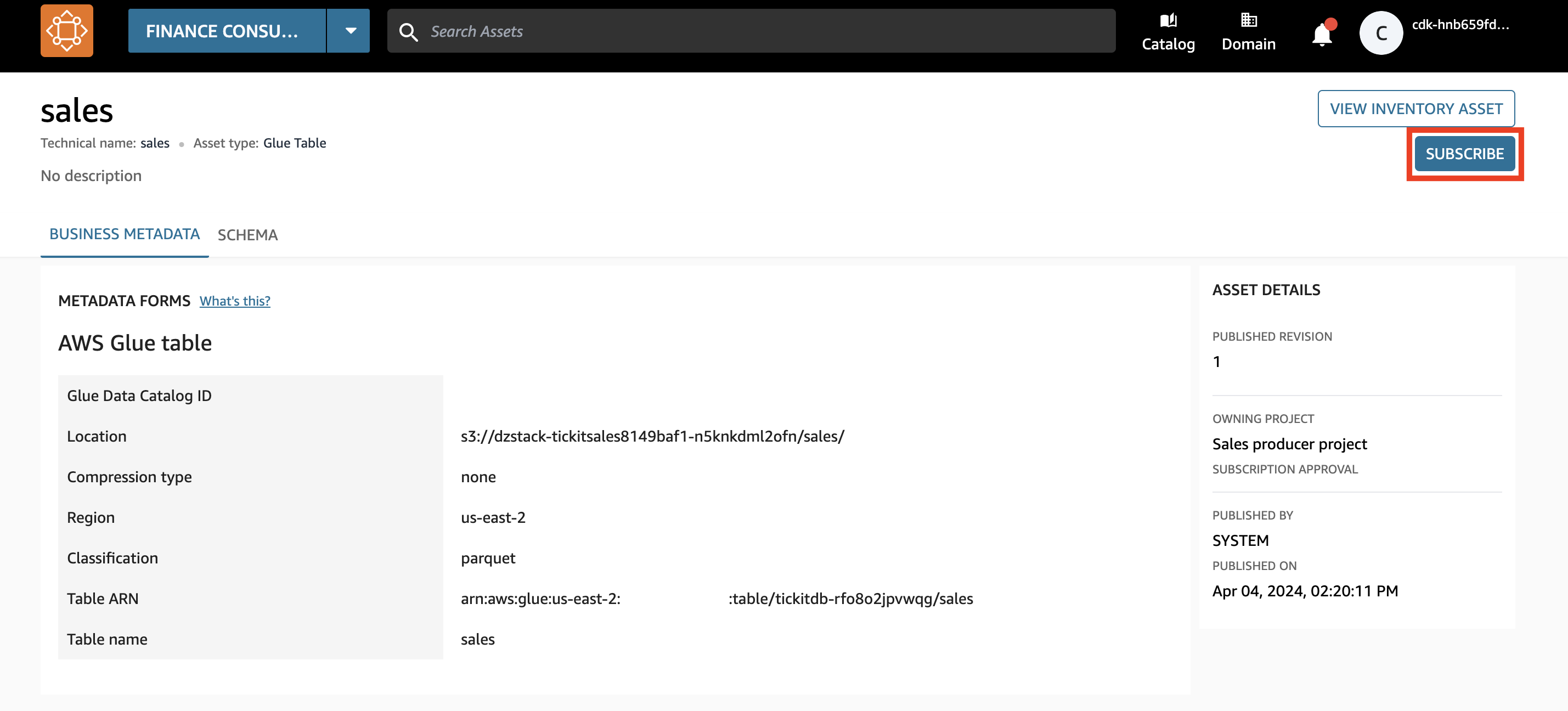
Das Asset wird als verwaltetes Asset angezeigt. Dies bedeutet, dass Amazon DataZone dem Projekt des Finanzteams Zugriff auf dieses Datenasset gewähren kann, indem die Berechtigungen in Lake Formation verwaltet werden.
- Geben Sie einen Grund für die Zugriffsanfrage ein und wählen Sie Abonnieren.
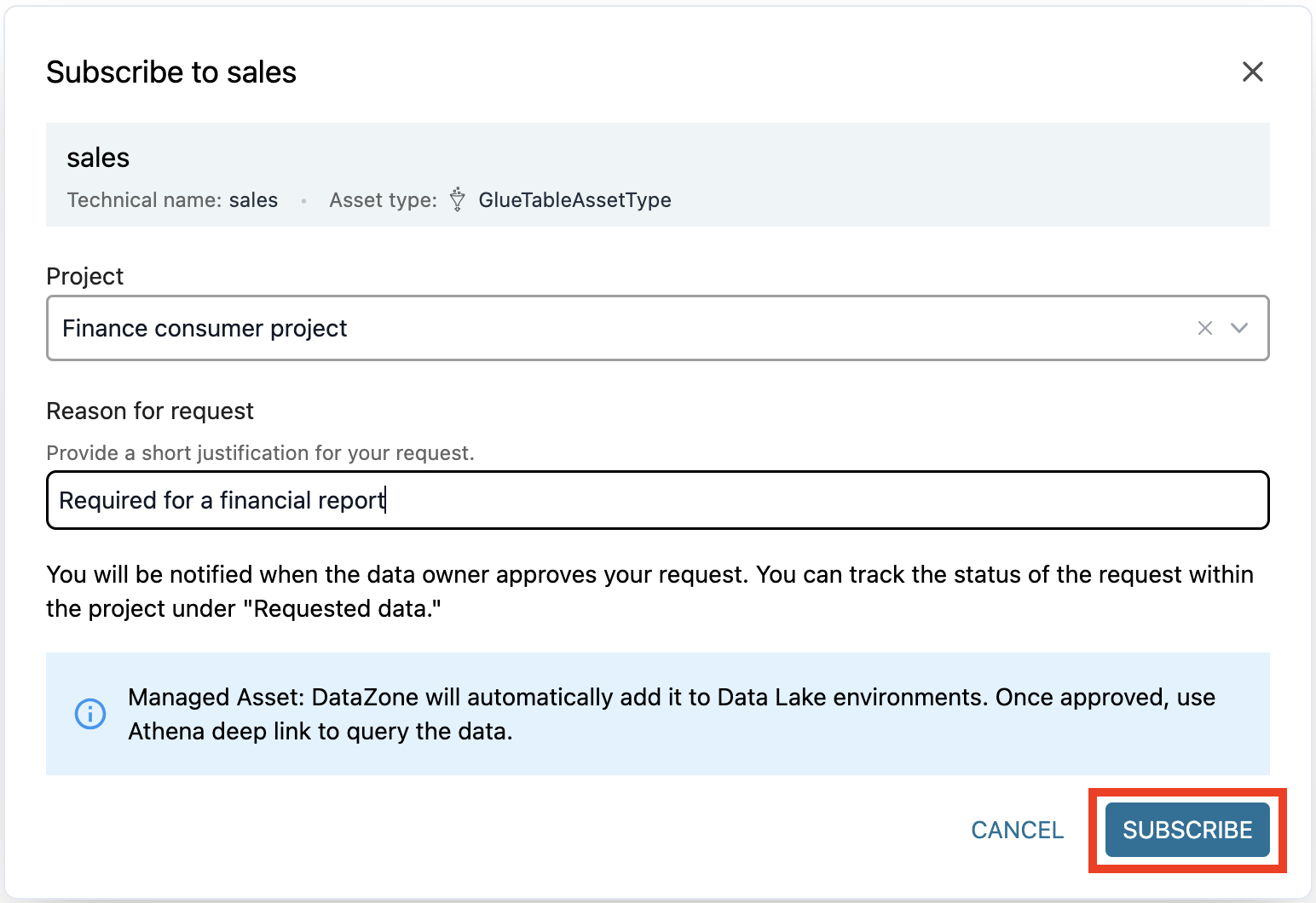
Zugriffsanfrage genehmigen
Das Vertriebsteam erhält eine Benachrichtigung, dass eine Zugriffsanfrage vom Finanzteam eingereicht wurde. Um die Anfrage zu genehmigen, führen Sie die folgenden Schritte aus:
- Wählen Sie das Dropdown-Menü neben dem Projektnamen und wählen Sie Vertriebsproduzentenprojekt.
Sie übernehmen nun die Rolle des Vertriebsteams, das Eigentümer und Verwalter der Vertriebsdatenbestände ist.
- Wählen Sie das Benachrichtigungssymbol in der oberen rechten Ecke des DataZone-Portals.
- Wähle die Abonnementanfrage erstellt Aufgabe.
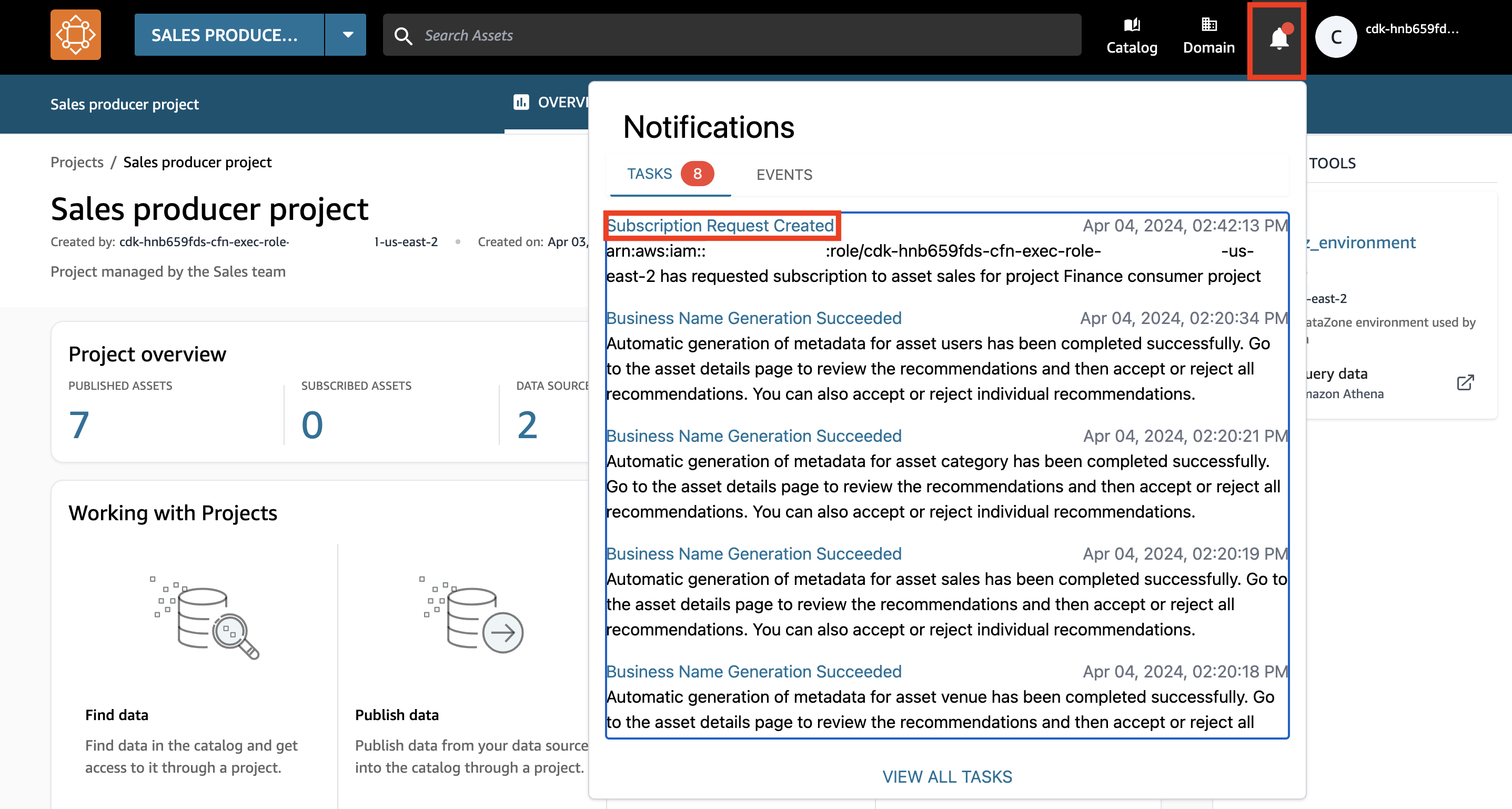
- Gewähren Sie dem Finanzteam Zugriff auf das Verkaufsdaten-Asset und wählen Sie aus genehmigen.

Analysieren Sie die Daten
Dem Finanzteam wurde nun Zugriff auf die Verkaufsdaten gewährt, und dieser Datensatz wurde in seiner Amazon DataZone-Umgebung gespeichert. Sie können auf die Umgebung zugreifen und den Verkaufsdatensatz mit Athena abfragen, zusammen mit allen anderen Datensätzen, die sie derzeit besitzen. Führen Sie die folgenden Schritte aus:
- Wählen Sie im Dropdown-Menü die Option aus Verbraucherprojekt finanzieren.
Im rechten Bereich des Projektübersichtsbildschirms finden Sie eine Liste der aktiven Umgebungen, die zur Verwendung verfügbar sind.
- Wählen Sie die Amazon DataZone-Umgebung
finance_dz_environment.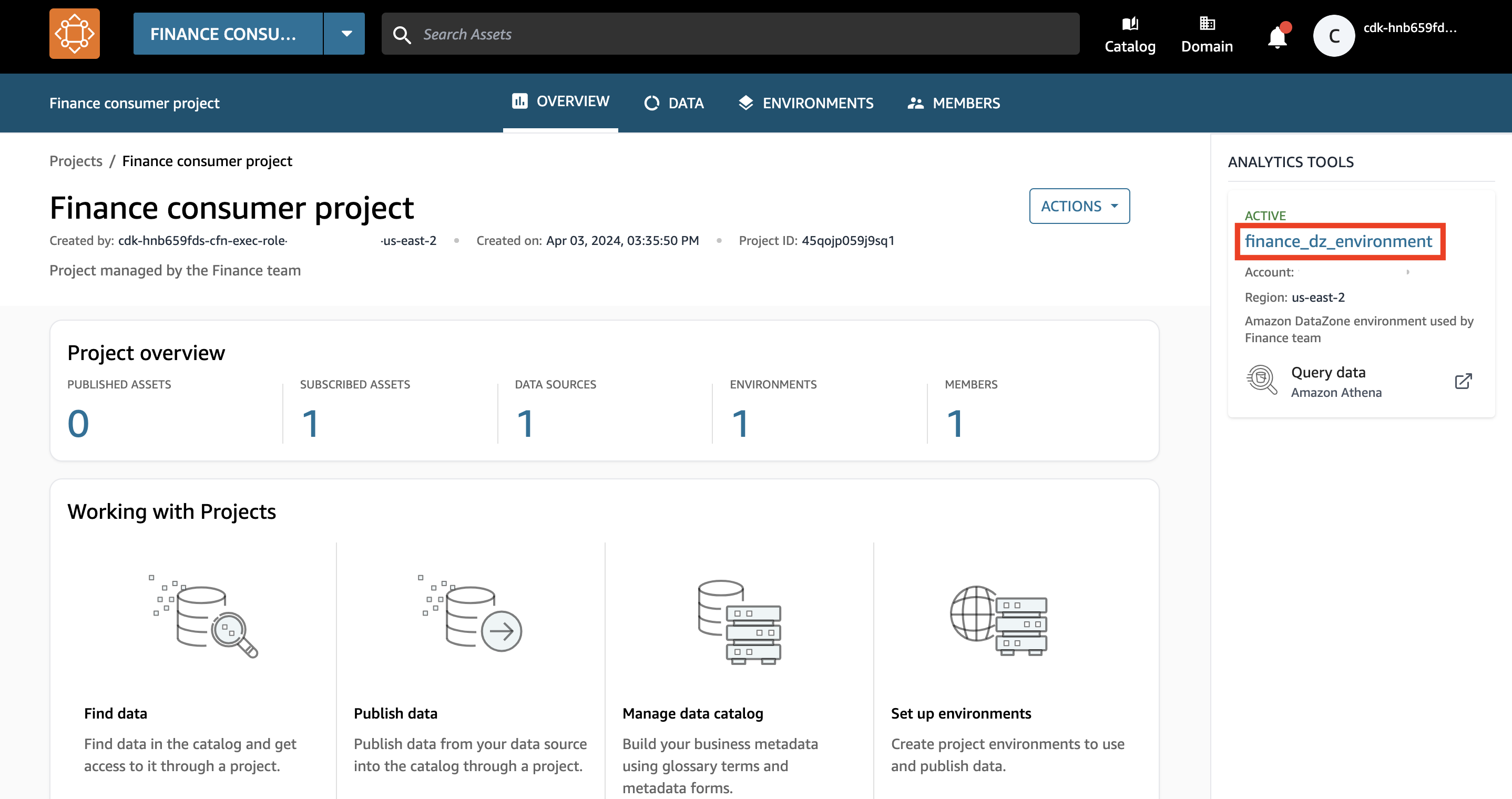
- Im Navigationsbereich unter Datenbestände, wählen Gezeichnet.
- Stellen Sie sicher, dass Ihre Umgebung jetzt Zugriff auf die Verkaufsdaten hat.
Es kann einige Minuten dauern, bis das Datenasset automatisch zu Ihrer Umgebung hinzugefügt wird.
- Wählen Sie das neue Tab-Symbol für Daten abfragen.
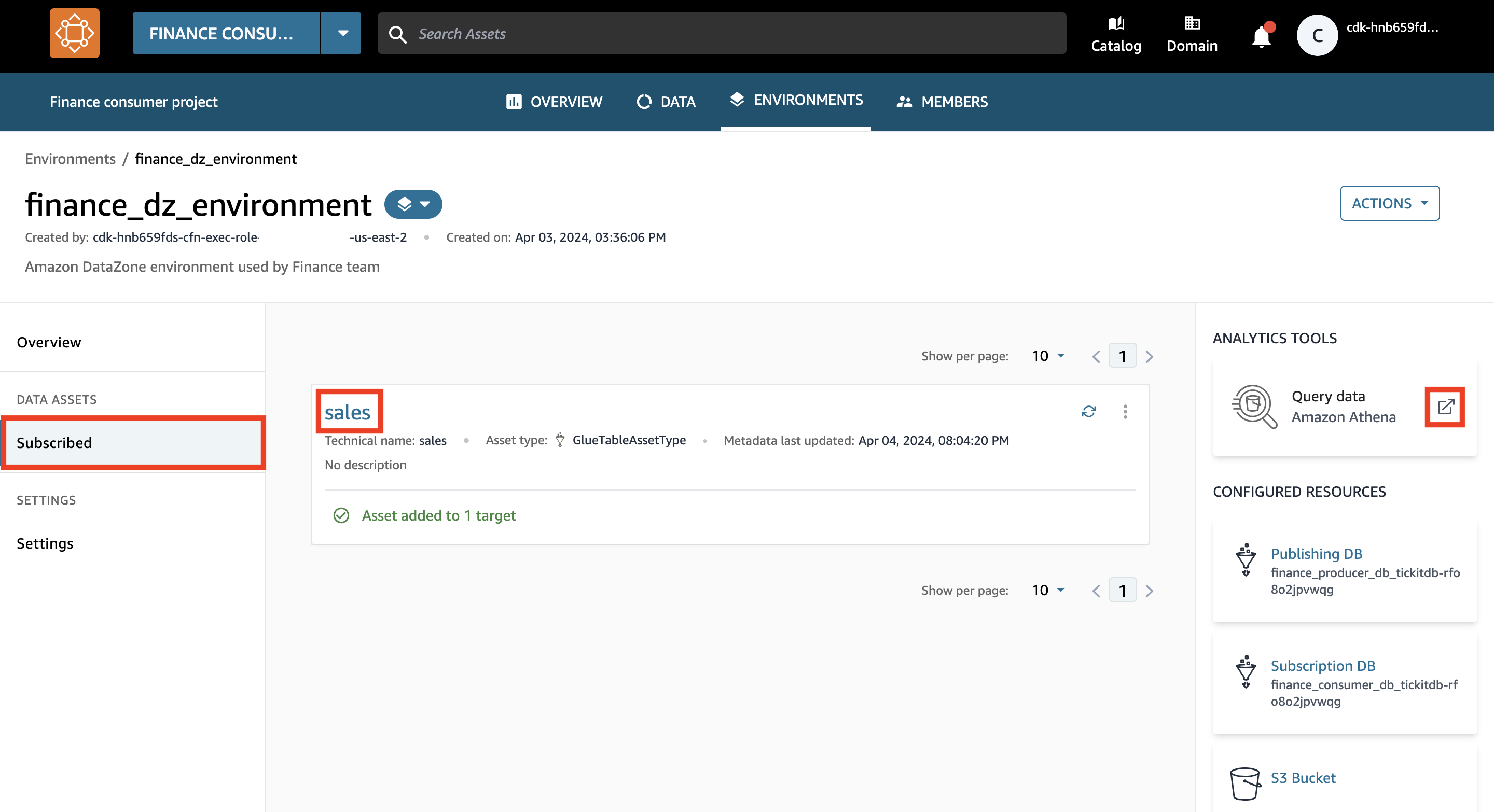
Es öffnet sich eine neue Registerkarte mit dem Athena-Abfrageeditor.
- Aussichten für Datenbase, wählen
finance_consumer_db_tickitdb-<suffix>.
Diese Datenbank enthält Ihre abonnierten Datenbestände.

- Erstellen Sie eine Vorschau der Verkaufstabelle, indem Sie das Optionsmenü (drei vertikale Punkte) auswählen und auswählen Vorschautabelle.
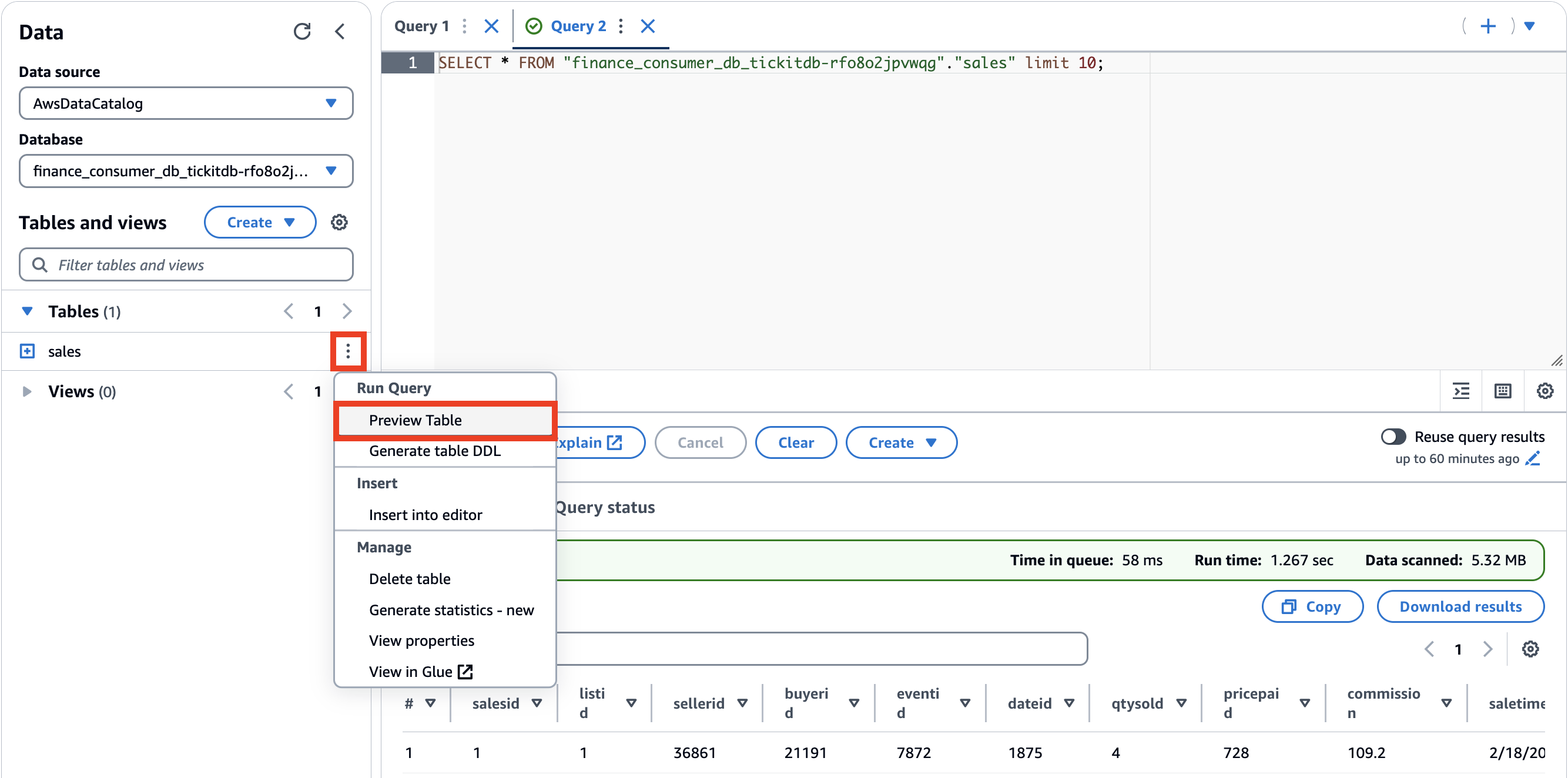
Aufräumen
Führen Sie die folgenden Schritte aus, um Ihre Ressourcen zu bereinigen:
- Wechseln Sie zurück zu der Administratorrolle, die Sie zum Bereitstellen des CloudFormation-Stacks verwendet haben.
- Auf der Amazon DataZone-Konsole: Löschen Sie die Projekte in diesem Beitrag verwendet. Dadurch werden die meisten projektbezogenen Objekte wie Datenbestände und Umgebungen gelöscht.
- Löschen Sie in der AWS CloudFormation-Konsole den Stack, den Sie am Anfang dieses Beitrags bereitgestellt haben.
- Löschen Sie auf der Amazon S3-Konsole die S3-Buckets, die den Tickit-Datensatz enthalten.
- Löschen Sie auf der Lake Formation-Konsole die von Amazon DataZone registrierten Lake Formation-Administratoren.
- Löschen Sie auf der Lake Formation-Konsole die von Amazon DataZone erstellten Tabellen und Datenbanken.
Zusammenfassung
In diesem Beitrag haben wir besprochen, wie die Integration zwischen Amazon DataZone und dem Hybridzugriffsmodus von Lake Formation den Prozess vereinfacht, Amazon DataZone für die End-to-End-Governance Ihrer Daten im AWS Glue Data Catalog zu verwenden. Diese Integration hilft Ihnen, die manuellen Schritte des Onboardings bei Lake Formation zu umgehen, bevor Sie Amazon DataZone verwenden können.
Weitere Informationen zu den ersten Schritten mit Amazon DataZone finden Sie im Erste Schritte. . Check out the Schauen Sie sich die YouTube Playlist Hier finden Sie einige der neuesten Demos von Amazon DataZone und kurze Beschreibungen der verfügbaren Funktionen. Weitere Informationen zu Amazon DataZone finden Sie unter Wie Amazon DataZone Kunden dabei hilft, in den Ozeanen von Daten einen Mehrwert zu finden.
Über die Autoren
 Utkarsh Mittal ist Senior Technical Product Manager für Amazon DataZone bei AWS. Seine Leidenschaft gilt der Entwicklung innovativer Produkte, die die End-to-End-Analytics-Journeys der Kunden vereinfachen. Außerhalb der Tech-Welt liebt Utkarsh die Musik, wobei Schlagzeug sein neuestes Unterfangen ist.
Utkarsh Mittal ist Senior Technical Product Manager für Amazon DataZone bei AWS. Seine Leidenschaft gilt der Entwicklung innovativer Produkte, die die End-to-End-Analytics-Journeys der Kunden vereinfachen. Außerhalb der Tech-Welt liebt Utkarsh die Musik, wobei Schlagzeug sein neuestes Unterfangen ist.
 Praveen Kumar ist Principal Analytics Solution Architect bei AWS mit Fachkenntnissen im Entwerfen, Erstellen und Implementieren moderner Daten- und Analyseplattformen mithilfe cloudbasierter Dienste. Seine Interessengebiete sind serverlose Technologie, moderne Cloud-Data-Warehouses, Streaming und generative KI-Anwendungen.
Praveen Kumar ist Principal Analytics Solution Architect bei AWS mit Fachkenntnissen im Entwerfen, Erstellen und Implementieren moderner Daten- und Analyseplattformen mithilfe cloudbasierter Dienste. Seine Interessengebiete sind serverlose Technologie, moderne Cloud-Data-Warehouses, Streaming und generative KI-Anwendungen.
 Paul Villena ist Senior Analytics Solutions Architect bei AWS mit Fachwissen im Aufbau moderner Daten- und Analyselösungen zur Steigerung des Geschäftswerts. Er arbeitet mit Kunden zusammen, um ihnen zu helfen, die Leistungsfähigkeit der Cloud zu nutzen. Seine Interessengebiete sind Infrastruktur als Code, serverlose Technologien und Codierung in Python
Paul Villena ist Senior Analytics Solutions Architect bei AWS mit Fachwissen im Aufbau moderner Daten- und Analyselösungen zur Steigerung des Geschäftswerts. Er arbeitet mit Kunden zusammen, um ihnen zu helfen, die Leistungsfähigkeit der Cloud zu nutzen. Seine Interessengebiete sind Infrastruktur als Code, serverlose Technologien und Codierung in Python
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/amazon-datazone-announces-integration-with-aws-lake-formation-hybrid-access-mode-for-the-aws-glue-data-catalog/

