
Image by Author | Canva
DeepChecks is a Python package that provides a wide variety of built-in checks to test for issues with model performance, data distribution, data integrity, and more.
In this tutorial, we will learn about DeepChecks and use it to validate the dataset and test the trained machine learning model to generate a comprehensive report. We will also learn to test models on specific tests instead of generating full reports.
Why do we need Machine Learning Testing?
Machine learning testing is essential for ensuring the reliability, fairness, and security of AI models. It helps verify model performance, detect biases, enhance security against adversarial attacks especially in Large Language Models (LLMs), ensure regulatory compliance, and enable continuous improvement. Tools like Deepchecks provide a comprehensive testing solution that addresses all aspects of AI and ML validation from research to production, making them invaluable for developing robust, trustworthy AI systems.
Getting Started with DeepChecks
In this getting started guide, we will load the dataset and perform a data integrity test. This critical step ensures that our dataset is reliable and accurate, paving the way for successful model training.
- We will start by installing the DeepChecks Python package using the `pip` command.
!pip install deepchecks --upgrade
- Import essential Python packages.
- Load the dataset using the pandas library, which consists of 569 samples and 30 features. The Cancer classification dataset is derived from digitized images of fine needle aspirates (FNAs) of breast masses, where each feature represents a characteristic of the cell nuclei present in the image. These features enable us to predict whether the cancer is benign or malignant.
- Split the dataset into training and testing using the target column ‘benign_0__mal_1’.
import pandas as pd
from sklearn.model_selection import train_test_split
# Load Data
cancer_data = pd.read_csv("/kaggle/input/cancer-classification/cancer_classification.csv")
label_col = 'benign_0__mal_1'
df_train, df_test = train_test_split(cancer_data, stratify=cancer_data[label_col], random_state=0)
- Create the DeepChecks dataset by providing additional metadata. Since our dataset has no categorical features, we leave the argument empty.
from deepchecks.tabular import Dataset
ds_train = Dataset(df_train, label=label_col, cat_features=[])
ds_test = Dataset(df_test, label=label_col, cat_features=[])
- Run the data integrity test on the train dataset.
from deepchecks.tabular.suites import data_integrity
integ_suite = data_integrity()
integ_suite.run(ds_train)
It will take a few second to generate the report.
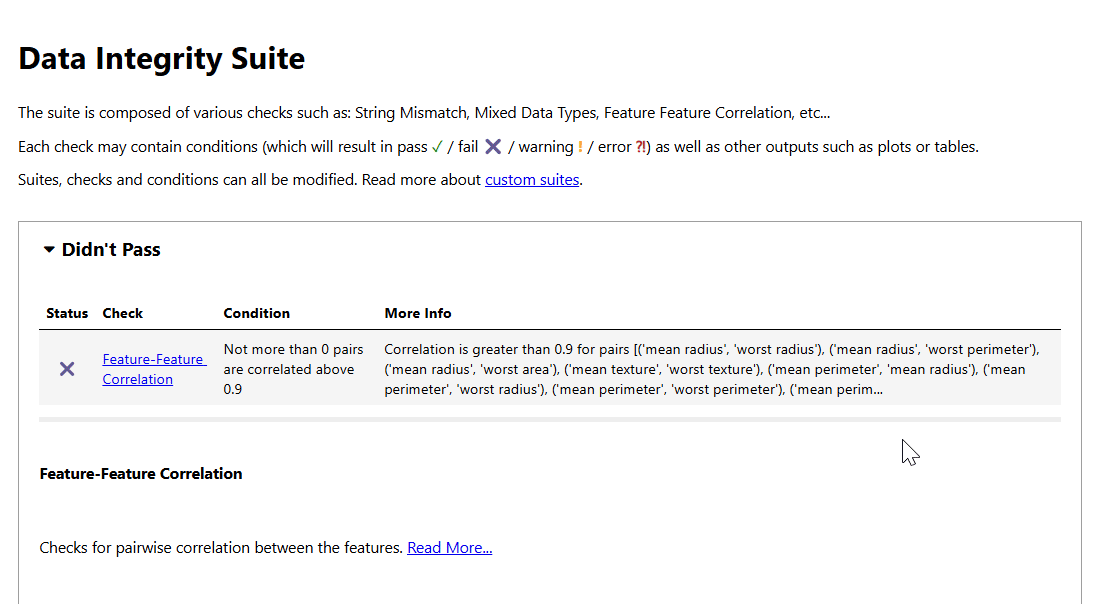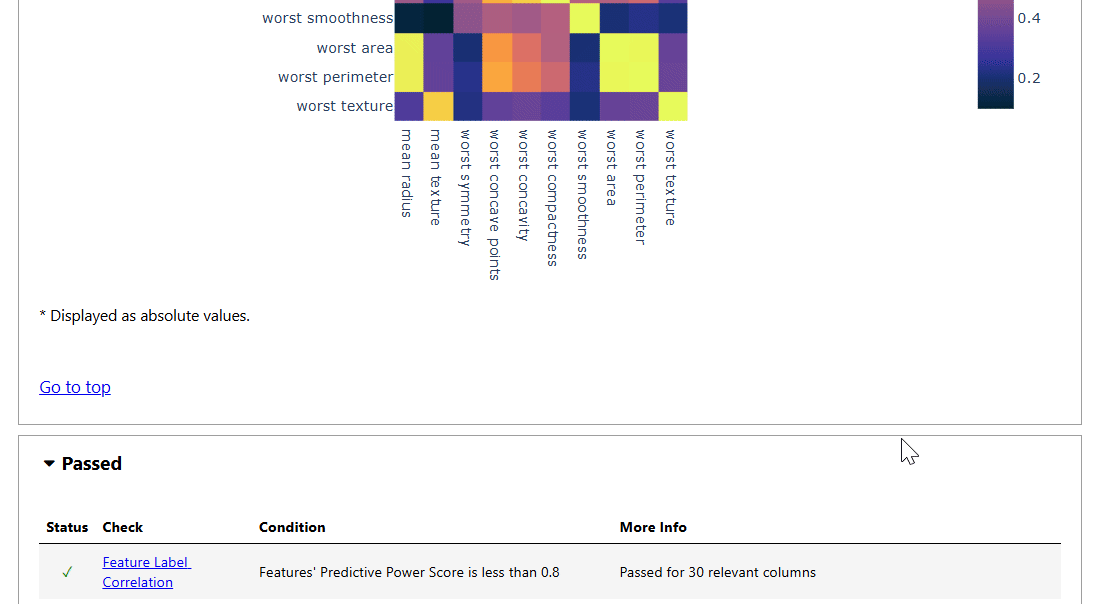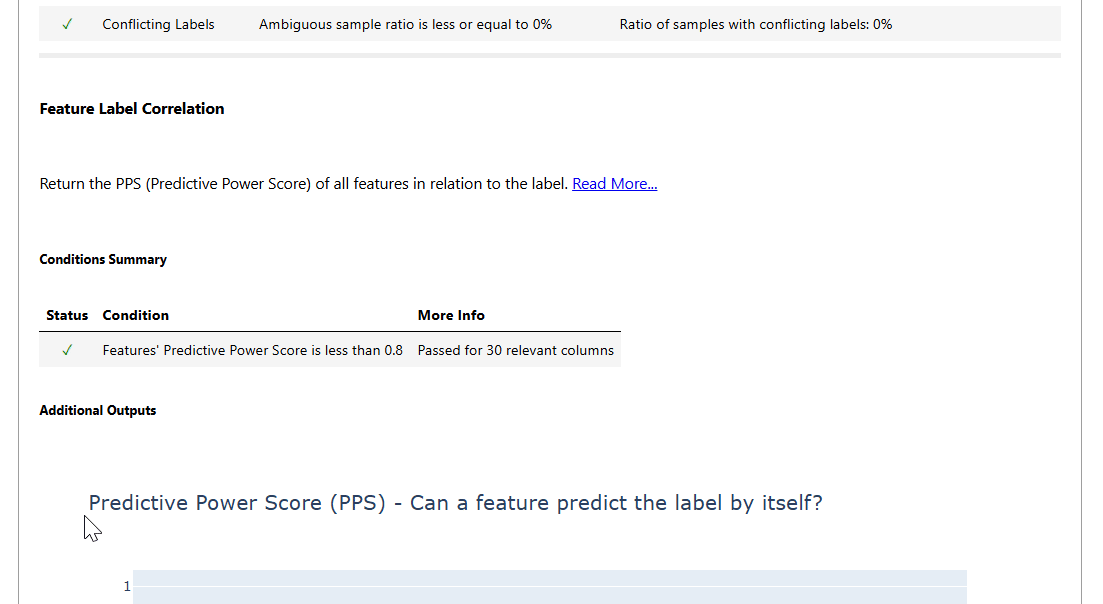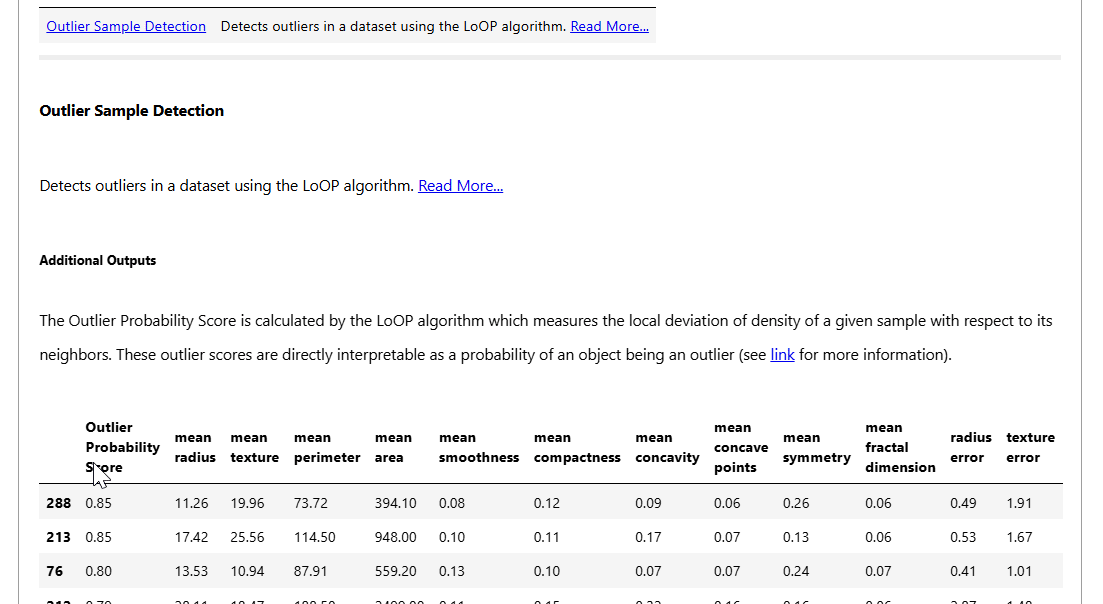
The data integrity report contains test results on:
- Feature-Feature Correlation
- Feature-Label Correlation
- Single Value in Column
- Special Characters
- Mixed Nulls
- Mixed Data Types
- String Mismatch
- Data Duplicates
- String Length Out Of Bounds
- Conflicting Labels
- Outlier Sample Detection
Machine Learning Model Testing
Let’s train our model and then run a model evaluation suite to learn more about model performance.
- Load the essential Python packages.
- Build three machine learning models (Logistic Regression, Random Forest Classifier, and Gaussian NB).
- Ensemble them using the voting classifier.
- Fit the ensemble model on the training dataset.
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
# Train Model
clf1 = LogisticRegression(random_state=1,max_iter=10000)
clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
clf3 = GaussianNB()
V_clf = VotingClassifier(
estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
voting='hard')
V_clf.fit(df_train.drop(label_col, axis=1), df_train[label_col]);
- Once the training phase is completed, run the DeepChecks model evaluation suite using the training and testing datasets and the model.
from deepchecks.tabular.suites import model_evaluation
evaluation_suite = model_evaluation()
suite_result = evaluation_suite.run(ds_train, ds_test, V_clf)
suite_result.show()
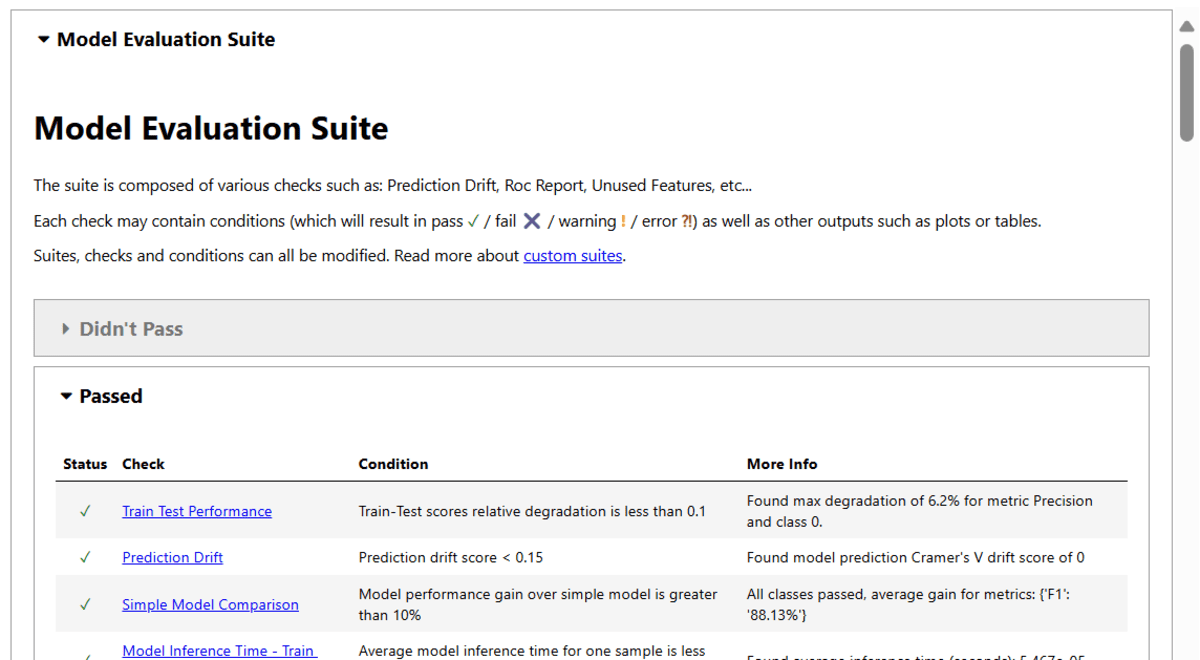
The model evaluation report contains the test results on:
- Unused Features – Train Dataset
- Unused Features – Test Dataset
- Train Test Performance
- Prediction Drift
- Simple Model Comparison
- Model Inference Time – Train Dataset
- Model Inference Time – Test Dataset
- Confusion Matrix Report – Train Dataset
- Confusion Matrix Report – Test Dataset
There are other tests available in the suite that didn’t run due to the ensemble type of model. If you ran a simple model like logistic regression, you might have gotten a full report.
- If you want to use a model evaluation report in a structured format, you can always use the `.to_json()` function to convert your report into the JSON format.
suite_result.to_json()

- Moreover, you can also save this interactive report as a web page using the
.save_as_html()function.
Running the Single Check
If you don’t want to run the entire suite of model evaluation tests, you can also test your model on a single check.
For example, you can check label drift by providing the training and testing dataset.
from deepchecks.tabular.checks import LabelDrift
check = LabelDrift()
result = check.run(ds_train, ds_test)
result
As a result, you will get a distribution plot and drift score.

You can even extract the value and methodology of the drift score.
result.value
{'Drift score': 0.0, 'Method': "Cramer's V"}
Conclusion
The next step in your learning journey is to automate the machine learning testing process and track performance. You can do that with GitHub Actions by following the Deepchecks In CI/CD guide.
In this beginner-friendly, we have learned to generate data validation and machine learning evaluation reports using DeepChecks. If you are having trouble running the code, I suggest you have a look at the Machine Learning Testing With DeepChecks Kaggle Notebook and run it yourself.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in technology management and a bachelor’s degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.kdnuggets.com/beginners-guide-to-machine-learning-testing-with-deepchecks?utm_source=rss&utm_medium=rss&utm_campaign=beginners-guide-to-machine-learning-testing-with-deepchecks

