Giới thiệu
Trong một thế giới tràn ngập thông tin, việc truy cập và trích xuất dữ liệu liên quan một cách hiệu quả là vô giá. ResearchBot là một dự án ứng dụng tiên tiến được hỗ trợ bởi LLM sử dụng các khả năng của LLM của OpenAI (Mô hình ngôn ngữ lớn) với Langchain để truy xuất thông tin. Bài viết này giống như hướng dẫn từng bước về cách tạo ResearchBot của riêng bạn và cách nó có thể hữu ích trong cuộc sống thực. Nó giống như có một trợ lý thông minh có thể tìm thấy thông tin bạn cần từ biển dữ liệu. Cho dù bạn yêu thích viết mã hay quan tâm đến AI, hướng dẫn này luôn sẵn sàng giúp bạn trao quyền cho nghiên cứu của mình với Trợ lý AI được hỗ trợ bởi LLM được tùy chỉnh. Đó là hành trình khám phá tiềm năng của LLM và cách mạng hóa cách bạn truy cập thông tin.

Mục tiêu học tập
- Hiểu các khái niệm sâu sắc hơn về LLM (Mô hình ngôn ngữ lớn), Langchain, Cơ sở dữ liệu vectơ và Nội dung nhúng.
- Khám phá các ứng dụng thực tế của LLM và ResearchBot trong các lĩnh vực như nghiên cứu, hỗ trợ khách hàng và tạo nội dung.
- Khám phá các phương pháp hay nhất để tích hợp ResearchBot vào các dự án hoặc quy trình công việc hiện có, cải thiện năng suất và ra quyết định.
- Xây dựng ResearchBot để hợp lý hóa quá trình trích xuất dữ liệu và trả lời các truy vấn.
- Luôn cập nhật các xu hướng trong công nghệ LLM và tiềm năng của nó trong việc cách mạng hóa cách chúng ta truy cập và sử dụng thông tin này.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
ResearchBot là gì?
ResearchBot là một trợ lý nghiên cứu được cung cấp bởi LLM. Đây là một công cụ cải tiến có thể truy cập và tóm tắt nội dung một cách nhanh chóng, khiến nó trở thành đối tác tuyệt vời cho các chuyên gia thuộc các ngành khác nhau.
Hãy tưởng tượng bạn có một trợ lý được cá nhân hóa có thể đọc và hiểu nhiều bài viết, tài liệu và trang web, đồng thời cung cấp cho bạn những bản tóm tắt ngắn và có liên quan. Mục đích ResearchBot của chúng tôi là giảm thời gian và công sức cần thiết cho mục đích nghiên cứu của bạn.
Các trường hợp sử dụng trong thế giới thực
- Phân tích tài chính: Luôn cập nhật những tin tức thị trường mới nhất và nhận được câu trả lời nhanh chóng cho các câu hỏi tài chính.
- Báo chí: Thu thập thông tin cơ bản, nguồn và tài liệu tham khảo cho bài viết một cách hiệu quả.
- Chăm sóc sức khỏe: Truy cập các tài liệu và tóm tắt nghiên cứu y học hiện tại cho mục đích nghiên cứu.
- Học tập: Tìm các tài liệu học thuật, tài liệu nghiên cứu có liên quan và câu trả lời cho các câu hỏi nghiên cứu.
- Nghiên cứu pháp lý: Truy xuất các tài liệu pháp lý, phán quyết và hiểu biết sâu sắc về các vấn đề pháp lý một cách nhanh chóng.
thuật ngữ kỹ thuật
Cơ sở dữ liệu véc tơ
Vùng chứa để lưu trữ các vectơ nhúng của dữ liệu văn bản là rất quan trọng để tìm kiếm dựa trên sự tương đồng hiệu quả.
Tìm kiếm ngữ nghĩa
Hiểu mục đích và ngữ cảnh truy vấn của người dùng để thực hiện tìm kiếm mà không phụ thuộc hoàn toàn vào việc kết hợp từ khóa hoàn hảo.
Nhúng
Một biểu diễn số của dữ liệu văn bản cho phép so sánh và tìm kiếm hiệu quả.
Kiến trúc kỹ thuật của dự án
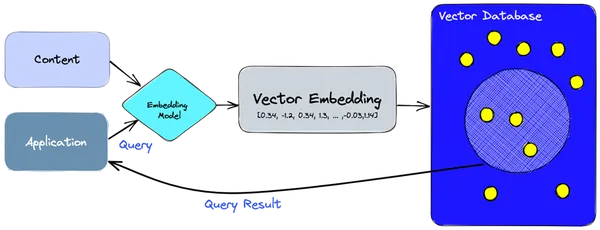
- Chúng tôi sử dụng mô hình nhúng để tạo các vectơ nhúng cho thông tin hoặc nội dung mà chúng tôi cần lập chỉ mục.
- Việc nhúng vectơ được chèn vào cơ sở dữ liệu vectơ, với một số tham chiếu đến nội dung gốc mà việc nhúng được tạo từ đó.
- Khi ứng dụng đưa ra một truy vấn, chúng tôi sử dụng cùng một mô hình nhúng để tạo các phần nhúng cho truy vấn và sử dụng các phần nhúng đó để truy vấn cơ sở dữ liệu về các phần nhúng vectơ tương tự.
- Những phần nhúng tương tự này được liên kết với nội dung gốc được sử dụng để tạo ra chúng.
ResearchBot hoạt động như thế nào?
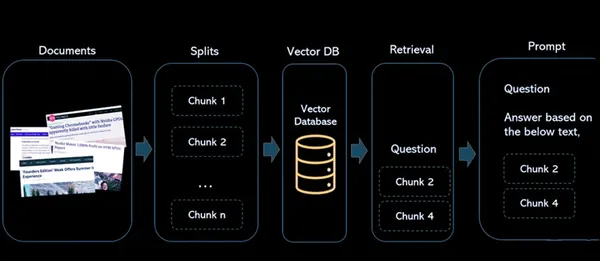
Kiến trúc này tạo điều kiện thuận lợi cho việc lưu trữ, truy xuất và tương tác với nội dung, làm cho ResearchBot của chúng tôi trở thành một công cụ mạnh mẽ để truy xuất và phân tích thông tin. Nó tận dụng khả năng nhúng vectơ và cơ sở dữ liệu vectơ để tạo điều kiện tìm kiếm nội dung nhanh chóng và chính xác.
Các thành phần
- Các tài liệu: Đây là những bài viết hoặc nội dung mà bạn muốn lập chỉ mục để tham khảo và truy xuất trong tương lai.
- Tách: Điều này xử lý quá trình chia nhỏ tài liệu thành các phần nhỏ hơn, dễ quản lý hơn. Điều này rất quan trọng khi làm việc với các tài liệu hoặc bài viết lớn, đảm bảo chúng hoàn toàn phù hợp với các ràng buộc của mô hình ngôn ngữ và để lập chỉ mục hiệu quả.
- Cơ sở dữ liệu vectơ: Cơ sở dữ liệu vector là một phần quan trọng của kiến trúc. Nó lưu trữ các phần nhúng vector được tạo từ nội dung. Mỗi vectơ được liên kết với nội dung gốc mà nó được tạo ra, tạo ra mối liên kết giữa biểu diễn số và tài liệu nguồn.
- Truy xuất: Khi người dùng truy vấn hệ thống, mô hình nhúng tương tự sẽ được sử dụng để tạo các phần nhúng cho truy vấn. Sau đó, các truy vấn nhúng này được sử dụng để tìm kiếm cơ sở dữ liệu vectơ để tìm các nhúng vectơ tương tự. Kết quả là một nhóm lớn các vectơ tương tự, mỗi vectơ được liên kết với nguồn nội dung gốc của nó.
- nhắc nhở: Nó được xác định nơi người dùng tương tác với hệ thống. Người dùng nhập truy vấn và hệ thống xử lý các truy vấn này để lấy thông tin liên quan từ cơ sở dữ liệu vectơ, cung cấp câu trả lời và tham chiếu đến nội dung nguồn.
Trình tải tài liệu trong LangChain
Sử dụng trình tải tài liệu để tải dữ liệu từ một nguồn dưới dạng tài liệu. Tài liệu là một đoạn văn bản và siêu dữ liệu liên quan. Ví dụ: có các trình tải tài liệu để tải một tệp .txt đơn giản, để tải nội dung văn bản của các bài báo hoặc blog hoặc thậm chí để tải bản ghi của video YouTube.
Có nhiều loại Trình tải tài liệu:
| Loader | Sử dụng |
|---|---|
| Trình tải văn bản | Tải tài liệu văn bản đơn giản để xử lý. |
| Trình tải CSV | Nhập dữ liệu từ tệp CSV. |
| Trình tải thư mục | Đọc và tải nội dung từ các thư mục. |
| Trình tải HTML không có cấu trúc | Tìm nạp và xử lý nội dung HTML phi cấu trúc. |
| Trình tải JSON | Tải dữ liệu từ các tệp JSON. |
| Trình tải Markdown không có cấu trúc | Xử lý và tải nội dung Markdown không có cấu trúc. |
| Trình tải PyPDF | Trích xuất nội dung văn bản từ tệp PDF để xử lý thêm. |
Ví dụ - Trình tải văn bản
Mã này hiển thị chức năng của TextLoader từ Langchain. Nó tải dữ liệu văn bản từ tệp hiện có, “Langchain.txt,” vào lớp TextLoader, chuẩn bị sẵn sàng để xử lý tiếp. Biến 'file_path' lưu trữ đường dẫn đến tệp đang được tải cho các mục đích sau này.
# Import the TextLoader class from the langchain.document_loaders module
from langchain.document_loaders import TextLoader # consider the TextLoader class by mentioning the file to load, Here "Langchain.txt"
loader = TextLoader("Langchain.txt") # Load the content from provided file ("Langchain.txt") into the TextLoader class
loader.load() # Check the type of the 'loader' instance, which should be 'TextLoader'
type(loader) # The file path associated with the TextLoader in the 'file_path' variable
loader.file_path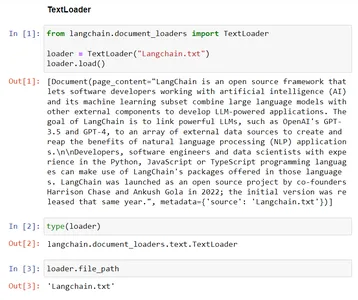
Bộ tách văn bản trong LangChain
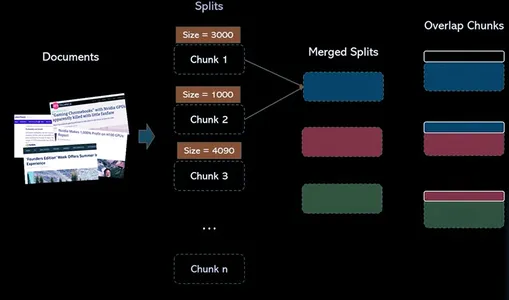
Bộ tách văn bản có trách nhiệm chia tài liệu thành các tài liệu nhỏ hơn. Các đơn vị nhỏ hơn này giúp làm việc và xử lý nội dung hiệu quả dễ dàng hơn. Trong bối cảnh dự án ResearchBot của chúng tôi, chúng tôi sử dụng bộ tách văn bản để chuẩn bị dữ liệu cho việc phân tích và truy xuất thêm.
Tại sao chúng ta cần bộ chia văn bản?
LLM có giới hạn mã thông báo. Do đó, chúng ta cần chia văn bản có thể lớn thành các phần nhỏ sao cho kích thước mỗi phần nằm dưới giới hạn mã thông báo.
Cách tiếp cận thủ công để chia văn bản thành nhiều phần
# Taking some random text from wikipedia
text # Say LLM token limit is 100, in our code we can do simple thing such as this text[:100]

Chà, nhưng chúng tôi muốn các từ hoàn chỉnh và muốn làm điều này cho toàn bộ văn bản, có thể chúng tôi có thể sử dụng chức năng phân tách của Python
words = text.split(" ")
len(words) chunks = [] s = ""
for word in words: s += word + " " if len(s)>200: chunks.append(s) s = "" chunks.append(s) chunks[:2]
Việc chia dữ liệu thành các phần có thể được thực hiện bằng python gốc nhưng đó là một quá trình đơn giản. Ngoài ra, nếu cần, bạn có thể cần thử nghiệm nhiều dấu phân cách theo cách liên tiếp để đảm bảo rằng mỗi đoạn không vượt quá giới hạn độ dài mã thông báo của LLM tương ứng.
Langchain cung cấp một cách tốt hơn thông qua các lớp phân tách văn bản. Có nhiều lớp phân tách văn bản trong langchain cho phép chúng ta thực hiện việc này.
1. Bộ tách văn bản ký tự
Lớp này được thiết kế để chia văn bản thành các phần nhỏ hơn dựa trên các dấu phân cách cụ thể. Giống như đoạn văn, dấu chấm, dấu phẩy và ngắt dòng (n). Sẽ hữu ích hơn khi chia nhỏ văn bản thành nhiều phần để xử lý tiếp.
from langchain.text_splitter import CharacterTextSplitter splitter = CharacterTextSplitter( separator = "n", chunk_size=200, chunk_overlap=0
) chunks = splitter.split_text(text)
len(chunks) for chunk in chunks: print(len(chunk))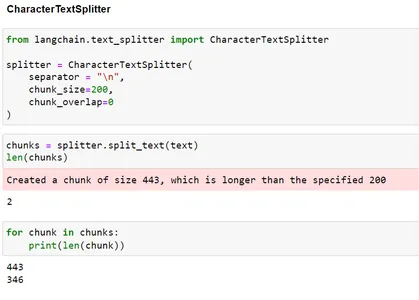
Như bạn có thể thấy, mặc dù chúng tôi đã đưa ra kích thước khối 200 vì việc phân tách dựa trên n nhưng cuối cùng nó lại tạo ra các khối lớn hơn kích thước 200.
Một lớp khác từ Langchain có thể được sử dụng để phân chia văn bản một cách đệ quy dựa trên danh sách các dấu phân cách. Lớp này là RecursiveTextSplitter. Hãy xem nó hoạt động như thế nào.
2. Bộ tách văn bản đệ quy
Đây là một loại bộ tách văn bản hoạt động bằng cách phân tích đệ quy các ký tự trong văn bản. Nó cố gắng phân tách văn bản theo các ký tự khác nhau, lặp đi lặp lại tìm các tổ hợp ký tự khác nhau cho đến khi xác định được phương pháp phân tách giúp phân chia văn bản và các loại shell khác nhau một cách hiệu quả.
from langchain.text_splitter import RecursiveCharacterTextSplitter r_splitter = RecursiveCharacterTextSplitter( separators = ["nn", "n", " "], # List of separators chunk_size = 200, # size of each chunk created chunk_overlap = 0, # size of overlap between chunks length_function = len # Function to calculate size,
) chunks = r_splitter.split_text(text) for chunk in chunks: print(len(chunk)) first_split = text.split("nn")[0]
first_split
len(first_split) second_split = first_split.split("n")
second_split
for split in second_split: print(len(split)) second_split[2]
second_split[2].split(" ")
Hãy hiểu cách chúng tôi hình thành các khối này:
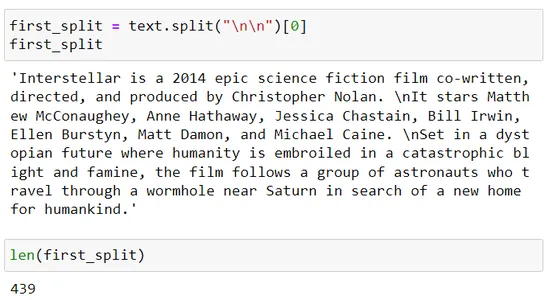
Bộ tách văn bản đệ quy sử dụng danh sách các dấu phân cách, tức là dấu phân cách = [“nn”, “n”, “.”]
Vì vậy, bây giờ, trước tiên nó sẽ phân tách bằng cách sử dụng nn và sau đó nếu kích thước khối kết quả lớn hơn tham số chunk_size là 200 trong cảnh này thì nó sẽ sử dụng dấu phân cách tiếp theo là n.
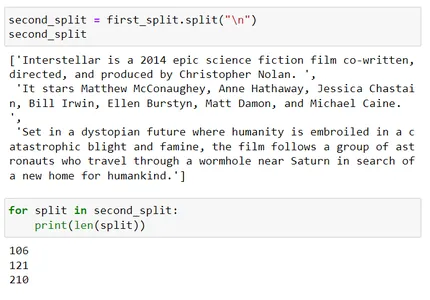
Phần phân chia thứ ba vượt quá kích thước khối 200. Bây giờ, nó sẽ cố gắng phân chia thêm bằng cách sử dụng dấu phân cách thứ ba là '' (dấu cách)
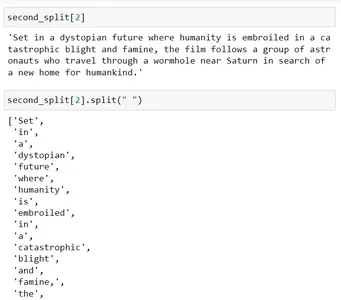
Khi bạn chia phần này bằng dấu cách (tức là giây_split[2].split(” “)), nó sẽ tách từng từ và sau đó nó sẽ hợp nhất các phần đó sao cho kích thước của chúng gần bằng 200.
Cơ sở dữ liệu véc tơ
Bây giờ, hãy xem xét một tình huống mà bạn cần lưu trữ hàng triệu hoặc thậm chí hàng tỷ từ nhúng, đó sẽ là cảnh quan trọng trong một ứng dụng trong thế giới thực. Cơ sở dữ liệu quan hệ, mặc dù có khả năng lưu trữ dữ liệu có cấu trúc, nhưng có thể không phù hợp do những hạn chế của chúng trong việc xử lý lượng dữ liệu lớn hơn như vậy.
Đây là lúc Cơ sở dữ liệu Vector phát huy tác dụng. Cơ sở dữ liệu vectơ được thiết kế để lưu trữ và truy xuất dữ liệu vectơ một cách hiệu quả, làm cho nó phù hợp cho việc nhúng từ.
Cơ sở dữ liệu Vector đang cách mạng hóa việc truy xuất thông tin bằng cách sử dụng tìm kiếm ngữ nghĩa. Họ tận dụng sức mạnh của việc nhúng từ và kỹ thuật lập chỉ mục thông minh để giúp tìm kiếm nhanh hơn và chính xác hơn.
Sự khác biệt giữa Chỉ mục Vector và Cơ sở dữ liệu Vector là gì?
Các chỉ số vectơ độc lập như THẤT BẠI (Tìm kiếm tương tự AI của Facebook) có thể cải thiện việc tìm kiếm và truy xuất các phần nhúng vectơ, nhưng chúng thiếu các khả năng tồn tại trong một trong các db (cơ sở dữ liệu). Mặt khác, cơ sở dữ liệu vectơ được xây dựng có mục đích để quản lý việc nhúng vectơ, cung cấp nhiều ưu điểm so với việc sử dụng các chỉ mục vectơ độc lập.
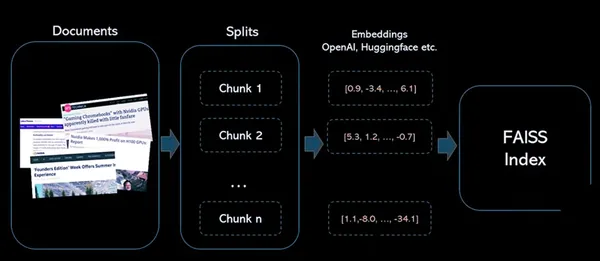
Bước sau:
1 : Tạo nhúng nguồn cho cột văn bản
2 : Xây dựng chỉ số FAISS cho vectơ
3 : Chuẩn hóa các vectơ nguồn và thêm vào chỉ mục
4 : Mã hóa văn bản tìm kiếm bằng cùng một bộ mã hóa và chuẩn hóa vectơ đầu ra
5: Tìm kiếm vectơ tương tự trong chỉ mục FAISS đã tạo
df = pd.read_csv("sample_text.csv")
df # Step 1 : Create source embeddings for the text column
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("all-mpnet-base-v2")
vectors = encoder.encode(df.text)
vectors # Step 2 : Build a FAISS Index for vectors
import faiss
index = faiss.IndexFlatL2(dim) # Step 3 : Normalize the source vectors and add to index
index.add(vectors)
index # Step 4 : Encode search text using same encoder
search_query = "looking for places to visit during the holidays"
vec = encoder.encode(search_query)
vec.shape
svec = np.array(vec).reshape(1,-1)
svec.shape # Step 5: Search for similar vector in the FAISS index
distances, I = index.search(svec, k=2)
distances
row_indices = I.tolist()[0]
row_indices
df.loc[row_indices]Nếu chúng ta kiểm tra tập dữ liệu này,
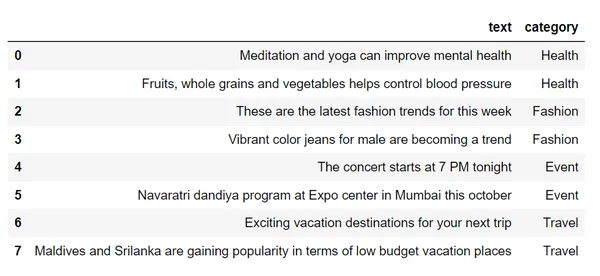
chúng tôi sẽ chuyển đổi những văn bản này thành vectơ bằng cách sử dụng tính năng nhúng từ
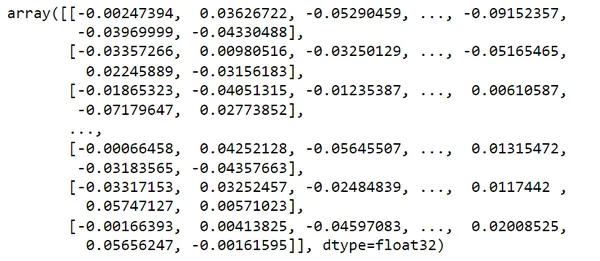
Xem xét search_query của tôi = “đang tìm kiếm địa điểm tham quan trong kỳ nghỉ lễ”

Nó cung cấp 2 kết quả tương tự nhất liên quan đến truy vấn của tôi bằng cách sử dụng tìm kiếm ngữ nghĩa của Danh mục Du lịch.
Khi bạn thực hiện truy vấn tìm kiếm, cơ sở dữ liệu sẽ sử dụng các kỹ thuật như Băm nhạy cảm cục bộ (LSH) để tăng tốc quá trình. LSH nhóm các vectơ tương tự vào các nhóm, cho phép tìm kiếm nhanh hơn và có mục tiêu hơn. Điều này có nghĩa là bạn không phải so sánh vectơ truy vấn của mình với mọi vectơ được lưu trữ.
Truy xuất
Khi người dùng truy vấn hệ thống, mô hình nhúng tương tự sẽ được sử dụng để tạo các phần nhúng cho truy vấn. Sau đó, các truy vấn nhúng này được sử dụng để tìm kiếm cơ sở dữ liệu vectơ để tìm các nhúng vectơ tương tự. Kết quả là một nhóm các vectơ tương tự, mỗi vectơ được liên kết với nguồn nội dung gốc của nó.
Những thách thức của việc thu hồi
Việc truy xuất trong tìm kiếm ngữ nghĩa cho thấy một số thách thức như giới hạn mã thông báo do các mô hình ngôn ngữ như GPT-3 áp đặt. khi xử lý nhiều khối dữ liệu có liên quan, việc vượt quá giới hạn phản hồi sẽ xảy ra.
Phương pháp thứ
Trong mô hình này, Nó liên quan đến việc thu thập tất cả các khối dữ liệu có liên quan từ cơ sở dữ liệu vectơ và kết hợp chúng thành một dấu nhắc (riêng lẻ). Nhược điểm chính của quá trình này là vượt quá giới hạn mã thông báo, do đó dẫn đến phản hồi không đầy đủ.
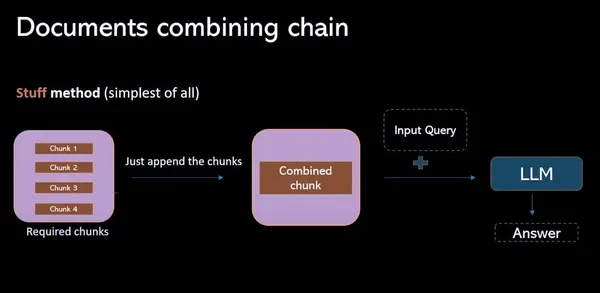
Phương pháp thu nhỏ bản đồ
Để vượt qua thách thức giới hạn mã thông báo và hợp lý hóa quy trình QA truy xuất, quy trình này cung cấp giải pháp thay vì kết hợp các phần có liên quan thành một dấu nhắc (riêng lẻ), nếu có 4 phần. Truyền tất cả thông qua các LLM riêng biệt. Những câu hỏi này cung cấp thông tin theo ngữ cảnh cho phép mô hình ngôn ngữ tập trung vào nội dung của từng đoạn một cách độc lập. Điều này dẫn đến một tập hợp các câu trả lời duy nhất cho mỗi đoạn. Cuối cùng, cuộc gọi LLM cuối cùng được thực hiện để kết hợp tất cả các câu trả lời riêng lẻ này nhằm tìm ra câu trả lời tốt nhất dựa trên những hiểu biết sâu sắc thu thập được từ mỗi đoạn.
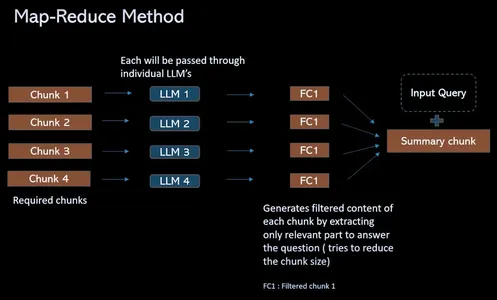
Quy trình làm việc của ResearchBot
(1) Tải dữ liệu
Ở bước này, dữ liệu, như văn bản hoặc tài liệu, được nhập và sẵn sàng để xử lý thêm, sẵn sàng cho việc phân tích.
#provide urls to scrape the data loaders = UnstructuredURLLoader(urls=[ "", ""
])
data = loaders.load() len(data)(2) Chia dữ liệu để tạo các khối
Dữ liệu được chia thành các phần hoặc khối nhỏ hơn, dễ quản lý hơn, tạo điều kiện thuận lợi cho việc xử lý và xử lý văn bản hoặc tài liệu lớn một cách hiệu quả.
text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200
) # use split_documents over split_text in order to get the chunks.
docs = text_splitter.split_documents(data)
len(docs)
docs[0](3) Tạo phần nhúng cho các Chunks này và lưu chúng vào chỉ mục FAISS
Các đoạn văn bản được chuyển đổi thành biểu diễn vectơ số (phần nhúng) và được lưu trữ trong chỉ mục Faiss, tối ưu hóa việc truy xuất các vectơ tương tự.
# Create the embeddings of the chunks using openAIEmbeddings
embeddings = OpenAIEmbeddings() # Pass the documents and embeddings inorder to create FAISS vector index
vectorindex_openai = FAISS.from_documents(docs, embeddings) # Storing vector index create in local
file_path="vector_index.pkl"
with open(file_path, "wb") as f: pickle.dump(vectorindex_openai, f) if os.path.exists(file_path): with open(file_path, "rb") as f: vectorIndex = pickle.load(f)(4) Truy xuất các phần nhúng tương tự cho một câu hỏi nhất định và gọi LLM để lấy câu trả lời cuối cùng
Đối với một truy vấn nhất định, chúng tôi truy xuất các phần nhúng tương tự và sử dụng các vectơ này để tương tác với mô hình ngôn ngữ (LLM) nhằm hợp lý hóa việc truy xuất thông tin và cung cấp câu trả lời cuối cùng cho câu hỏi của người dùng.
# Initialise LLM with the necessary parameters
llm = OpenAI(temperature=0.9, max_tokens=500) chain = RetrievalQAWithSourcesChain.from_llm( llm=llm, retriever=vectorIndex.as_retriever()
)
chain query = "" #ask your query langchain.debug=True chain({"question": query}, return_only_outputs=True)ứng dụng cuối cùng
Sau khi sử dụng tất cả các giai đoạn này (Trình tải tài liệu, Bộ tách văn bản, Vector DB, Truy xuất, Nhắc) và xây dựng một ứng dụng với sự trợ giúp của Streamlit. Chúng tôi đã hoàn thành việc xây dựng ResearchBot của mình.
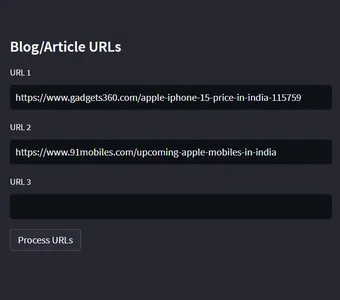
Đây là một phần trong trang, nơi chèn url của blog hoặc bài viết vào đó. Tôi đã đưa ra các liên kết của điện thoại di động Iphone mới nhất được phát hành vào năm 2023. Trước khi bắt đầu xây dựng ứng dụng ResearchBot này, mọi người sẽ có một câu hỏi rằng chúng ta đã có ChatGPT rồi thì tại sao chúng ta lại xây dựng ResearchBot này. Đây là câu trả lời:
Câu trả lời của ChatGPT:

Câu trả lời của ResearchBot:
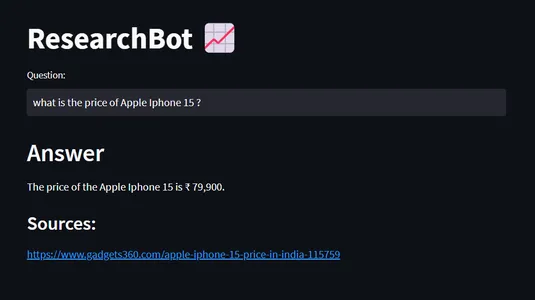
Đây, truy vấn của tôi là “Giá iPhone 15 của Apple là bao nhiêu?”
Dữ liệu này có từ năm 2023 và dữ liệu này không có sẵn với ChatGPT 3.5 nhưng chúng tôi đã đào tạo ResearchBot của mình bằng những thông tin mới nhất về Iphone. Vì vậy, chúng tôi đã nhận được câu trả lời cần thiết bởi ResearchBot.
Đây là 3 vấn đề khi sử dụng ChatGPT:
- Sao chép Dán nội dung bài viết là một công việc tẻ nhạt.
- Chúng ta cần một Cơ sở Kiến thức Tổng hợp.
- Giới hạn từ - 3000 từ
Kết luận
Chúng ta đã chứng kiến các khái niệm về tìm kiếm ngữ nghĩa và cơ sở dữ liệu vectơ trong bối cảnh thế giới thực. Khả năng ResearchBot của chúng tôi truy xuất hiệu quả các câu trả lời từ Cơ sở dữ liệu vectơ bằng cách sử dụng Tìm kiếm ngữ nghĩa, ResearchBot cho thấy tiềm năng to lớn của LLM (adv) sâu trong lĩnh vực truy xuất thông tin và hệ thống trả lời câu hỏi. Chúng tôi đã tạo ra một công cụ có nhu cầu cao giúp bạn dễ dàng tìm kiếm và tóm tắt thông tin quan trọng với khả năng và tính năng tìm kiếm cao. Đó là một giải pháp mạnh mẽ cho những người tìm kiếm kiến thức. Công nghệ này mở ra những chân trời mới cho các hệ thống truy xuất thông tin và trả lời câu hỏi, khiến nó trở thành công cụ thay đổi cuộc chơi cho bất kỳ ai đang tìm kiếm những hiểu biết sâu sắc dựa trên dữ liệu.
Những câu hỏi thường gặp
A. Nó là xương sống của các công cụ tìm kiếm ngữ nghĩa hiện đại. Cơ sở dữ liệu vectơ là cơ sở dữ liệu chuyên biệt được thiết kế để xử lý dữ liệu vectơ nhiều chiều. Chúng cung cấp những cách hiệu quả để lưu trữ và tìm kiếm dữ liệu nhiều chiều như vectơ đại diện cho văn bản hoặc các loại khác tùy thuộc vào độ phức tạp và mức độ chi tiết của dữ liệu.
A. Công cụ tìm kiếm ngữ nghĩa sẽ giải thích nghĩa của một từ tốt hơn. Nó có thể hiểu rõ hơn mục đích truy vấn, nó có thể tạo ra kết quả tìm kiếm phù hợp hơn với người tìm kiếm so với những gì công cụ tìm kiếm truyền thống có thể hiển thị.
A. FAISS bản thân nó không phải là cơ sở dữ liệu vectơ mà là thư viện tìm kiếm vectơ. Nó là một thư viện tìm kiếm vectơ và một thư viện độc lập được sử dụng để thực hiện tìm kiếm tương tự vectơ. Một số ví dụ phổ biến bao gồm FAISS, HNSW và Annoy.
Đáp. Mô hình ngôn ngữ lớn (LLM) là một loại thuật toán trí tuệ nhân tạo (AI) sử dụng các kỹ thuật học sâu và tập dữ liệu lớn để hiểu, tóm tắt, tạo và dự đoán nội dung mới. Những chatbot này có nhiều kỹ năng hiểu và trò chuyện bằng ngôn ngữ tự nhiên.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/10/empower-your-research-with-a-tailored-llm-powered-ai-assistant/

