Các mô hình ngôn ngữ lớn (LLM) đang ngày càng trở nên phổ biến, với các trường hợp sử dụng mới liên tục được khám phá. Nói chung, bạn có thể xây dựng các ứng dụng được hỗ trợ bởi LLM bằng cách kết hợp kỹ thuật nhanh chóng vào mã của mình. Tuy nhiên, có những trường hợp việc nhắc LLM hiện tại không thành công. Đây là lúc việc tinh chỉnh mô hình có thể giúp ích. Kỹ thuật nhắc nhở là hướng dẫn đầu ra của mô hình bằng cách tạo ra các lời nhắc đầu vào, trong khi tinh chỉnh là đào tạo mô hình trên các tập dữ liệu tùy chỉnh để làm cho mô hình phù hợp hơn với các nhiệm vụ hoặc lĩnh vực cụ thể.
Trước khi có thể tinh chỉnh một mô hình, bạn cần tìm một tập dữ liệu dành riêng cho nhiệm vụ. Một tập dữ liệu thường được sử dụng là Tập dữ liệu thu thập thông tin chung. Kho dữ liệu Thu thập thông tin chung chứa hàng petabyte dữ liệu, được thu thập thường xuyên kể từ năm 2008 và chứa dữ liệu trang web thô, các trích xuất siêu dữ liệu và các trích xuất văn bản. Ngoài việc xác định tập dữ liệu nào sẽ được sử dụng, cần phải làm sạch và xử lý dữ liệu theo nhu cầu cụ thể của việc tinh chỉnh.
Gần đây, chúng tôi đã làm việc với một khách hàng muốn xử lý trước một tập hợp con của tập dữ liệu Thu thập thông tin chung mới nhất và sau đó tinh chỉnh LLM của họ bằng dữ liệu đã được làm sạch. Khách hàng đang tìm kiếm cách họ có thể đạt được điều này theo cách tiết kiệm chi phí nhất trên AWS. Sau khi thảo luận về các yêu cầu, chúng tôi khuyên bạn nên sử dụng Amazon EMR không có máy chủ làm nền tảng cho việc tiền xử lý dữ liệu. EMR Serverless rất phù hợp để xử lý dữ liệu quy mô lớn và loại bỏ nhu cầu bảo trì cơ sở hạ tầng. Về chi phí, nó chỉ tính phí dựa trên tài nguyên và thời gian sử dụng cho mỗi công việc. Khách hàng có thể xử lý trước hàng trăm TB dữ liệu trong vòng một tuần bằng cách sử dụng EMR Serverless. Sau khi xử lý trước dữ liệu, họ sử dụng Amazon SageMaker để tinh chỉnh LLM.
Trong bài đăng này, chúng tôi sẽ hướng dẫn bạn về trường hợp sử dụng và kiến trúc được sử dụng của khách hàng.
Trong các phần sau, trước tiên chúng tôi giới thiệu tập dữ liệu Thu thập thông tin chung cũng như cách khám phá và lọc dữ liệu chúng tôi cần. amazon Athena chỉ tính phí cho kích thước dữ liệu mà nó quét và được sử dụng để khám phá và lọc dữ liệu một cách nhanh chóng, đồng thời tiết kiệm chi phí. EMR Serverless cung cấp tùy chọn tiết kiệm chi phí và không cần bảo trì để xử lý dữ liệu Spark và được sử dụng để xử lý dữ liệu đã lọc. Tiếp theo, chúng tôi sử dụng Khởi động Amazon SageMaker để tinh chỉnh Mô hình Llama 2 với tập dữ liệu đã được xử lý trước. SageMaker JumpStart cung cấp một bộ giải pháp cho các trường hợp sử dụng phổ biến nhất có thể được triển khai chỉ bằng vài cú nhấp chuột. Bạn không cần phải viết bất kỳ mã nào để tinh chỉnh LLM như Llama 2. Cuối cùng, chúng tôi triển khai mô hình tinh chỉnh bằng cách sử dụng Amazon SageMaker và so sánh sự khác biệt trong kết quả đầu ra văn bản cho cùng một câu hỏi giữa mô hình Llama 2 ban đầu và mô hình đã được tinh chỉnh.
Sơ đồ sau đây minh họa kiến trúc của giải pháp này.
Trước khi bạn đi sâu vào chi tiết giải pháp, hãy hoàn thành các bước tiên quyết sau:
Thu thập thông tin chung là một tập dữ liệu mở có được bằng cách thu thập dữ liệu trên 50 tỷ trang web. Nó bao gồm một lượng lớn dữ liệu phi cấu trúc bằng nhiều ngôn ngữ, bắt đầu từ năm 2008 và đạt đến mức petabyte. Nó được cập nhật liên tục.
Trong quá trình đào tạo GPT-3, tập dữ liệu Common Crawl chiếm 60% dữ liệu huấn luyện của nó, như được hiển thị trong sơ đồ sau (nguồn: Mô hình ngôn ngữ ít người học).
Một tập dữ liệu quan trọng khác đáng được đề cập là tập dữ liệu C4. C4, viết tắt của Colossal Clean Crawled Corpus, là một tập dữ liệu có nguồn gốc từ quá trình xử lý hậu kỳ của tập dữ liệu Thu thập thông tin chung. Trong bài báo LLaMA của Meta, họ đã phác thảo các bộ dữ liệu được sử dụng, trong đó Common Crawl chiếm 67% (sử dụng 3.3 TB dữ liệu) và C4 chiếm 15% (sử dụng 783 GB dữ liệu). Bài viết nhấn mạnh tầm quan trọng của việc kết hợp các dữ liệu được xử lý trước khác nhau để nâng cao hiệu suất của mô hình. Mặc dù dữ liệu C4 ban đầu là một phần của Thu thập thông tin chung, Meta đã chọn phiên bản được xử lý lại của dữ liệu này.
Trong phần này, chúng tôi đề cập đến các cách phổ biến để tương tác, lọc và xử lý tập dữ liệu Thu thập thông tin chung.
Tập dữ liệu thô Common Crawl bao gồm ba loại tệp dữ liệu: dữ liệu trang web thô (WARC), siêu dữ liệu (WAT) và trích xuất văn bản (WET).
Dữ liệu được thu thập sau năm 2013 được lưu trữ ở định dạng WARC và bao gồm siêu dữ liệu tương ứng (WAT) và dữ liệu trích xuất văn bản (WET). Tập dữ liệu được đặt tại Amazon S3, được cập nhật hàng tháng và có thể được truy cập trực tiếp thông qua Thị trường AWS.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzTập dữ liệu Thu thập thông tin chung cũng cung cấp bảng chỉ mục để lọc dữ liệu, được gọi là bảng cc-index.
Bảng cc-index là chỉ mục của dữ liệu hiện có, cung cấp chỉ mục dựa trên bảng của các tệp WARC. Nó cho phép dễ dàng tra cứu thông tin, chẳng hạn như tệp WARC nào tương ứng với một URL cụ thể.
Ví dụ: bạn có thể tạo bảng Athena để ánh xạ dữ liệu chỉ mục cc bằng mã sau:
Các câu lệnh SQL trước đây minh họa cách tạo bảng Athena, thêm phân vùng và chạy truy vấn.
Lọc dữ liệu từ tập dữ liệu Thu thập thông tin chung
Như bạn có thể thấy từ câu lệnh SQL tạo bảng, có một số trường có thể giúp lọc dữ liệu. Ví dụ: nếu bạn muốn lấy số lượng tài liệu tiếng Trung trong một khoảng thời gian cụ thể thì câu lệnh SQL có thể như sau:
Nếu muốn xử lý thêm, bạn có thể lưu kết quả vào một bộ chứa S3 khác.
Phân tích dữ liệu đã lọc
Sản phẩm Kho lưu trữ GitHub thu thập thông tin chung cung cấp một số ví dụ PySpark để xử lý dữ liệu thô.
Hãy xem một ví dụ về việc chạy server_count.py (tập lệnh mẫu được cung cấp bởi kho lưu trữ Common Crawl GitHub) trên dữ liệu nằm trong s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Đầu tiên, bạn cần có môi trường Spark, chẳng hạn như EMR Spark. Ví dụ: bạn có thể khởi chạy Amazon EMR trên cụm EC2 trong us-east-1 (vì tập dữ liệu nằm trong us-east-1). Sử dụng EMR trên cụm EC2 có thể giúp bạn thực hiện các thử nghiệm trước khi gửi công việc đến môi trường sản xuất.
Sau khi khởi chạy EMR trên cụm EC2, bạn cần thực hiện đăng nhập SSH vào nút chính của cụm. Sau đó, đóng gói môi trường Python và gửi tập lệnh (tham khảo phần Tài liệu Conda để cài đặt Miniconda):
Có thể mất thời gian để xử lý tất cả các tham chiếu trong warc.path. Đối với mục đích demo, bạn có thể cải thiện thời gian xử lý bằng các chiến lược sau:
- Tải xuống tệp tin
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzvào máy cục bộ của bạn, giải nén nó rồi tải nó lên HDFS hoặc Amazon S3. Điều này là do tệp .gzip không thể chia tách được. Bạn cần giải nén nó để xử lý file này song song. - Sửa đổi
warc.pathtập tin, xóa hầu hết các dòng của nó và chỉ giữ lại hai dòng để công việc chạy nhanh hơn nhiều.
Sau khi hoàn thành công việc, bạn có thể xem kết quả trong s3://xxxx-common-crawl/output/, ở định dạng Parquet.
Triển khai logic sở hữu tùy chỉnh
Kho lưu trữ Common Crawl GitHub cung cấp một cách tiếp cận chung để xử lý các tệp WARC. Nói chung, bạn có thể mở rộng CCSparkJob để ghi đè một phương thức duy nhất (process_record), điều này là đủ cho nhiều trường hợp.
Hãy xem một ví dụ để lấy các đánh giá IMDB về các bộ phim gần đây. Trước tiên, bạn cần lọc các tệp trên trang IMDB:
Sau đó, bạn có thể lấy danh sách tệp WARC chứa dữ liệu đánh giá IMDB và lưu tên tệp WARC dưới dạng danh sách trong tệp văn bản.
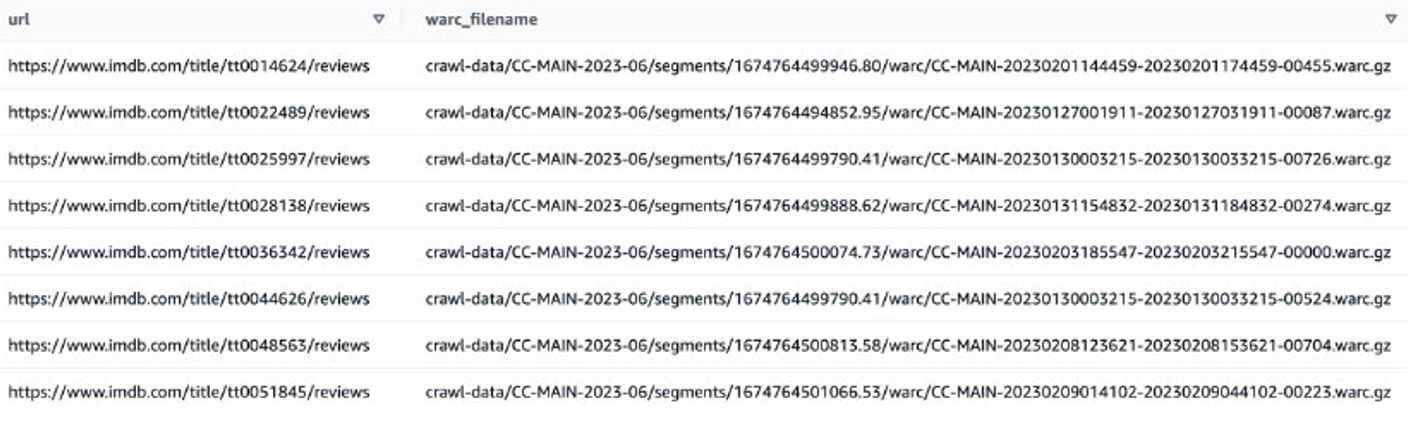
Ngoài ra, bạn có thể sử dụng EMR Spark lấy danh sách tệp WARC và lưu trữ nó trong Amazon S3. Ví dụ:
Tệp đầu ra sẽ trông giống như s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Bước tiếp theo là trích xuất đánh giá của người dùng từ các tệp WARC này. Bạn có thể mở rộng CCSparkJob ghi đè lên process_record() phương pháp:
Bạn có thể lưu tập lệnh trước dưới dạng imdb_extractor.py mà bạn sẽ sử dụng trong các bước sau. Sau khi đã chuẩn bị xong dữ liệu và tập lệnh, bạn có thể sử dụng EMR Serverless để xử lý dữ liệu đã được lọc.
EMR không có máy chủ
EMR Serverless là một tùy chọn triển khai không có máy chủ để chạy các ứng dụng phân tích dữ liệu lớn bằng cách sử dụng các khung nguồn mở như Apache Spark và Hive mà không cần định cấu hình, quản lý và mở rộng quy mô cụm hoặc máy chủ.
Với EMR Serverless, bạn có thể chạy khối lượng công việc phân tích ở mọi quy mô với tính năng tự động thay đổi quy mô giúp thay đổi kích thước tài nguyên trong vài giây để đáp ứng các yêu cầu xử lý và khối lượng dữ liệu luôn thay đổi. EMR Serverless tự động tăng giảm quy mô tài nguyên để cung cấp dung lượng phù hợp cho ứng dụng của bạn và bạn chỉ trả tiền cho những gì bạn sử dụng.
Việc xử lý tập dữ liệu Thu thập thông tin chung thường là tác vụ xử lý một lần, khiến nó phù hợp với khối lượng công việc EMR Serverless.
Tạo ứng dụng EMR Serverless
Bạn có thể tạo ứng dụng EMR Serverless trên bảng điều khiển EMR Studio. Hoàn thành các bước sau:
- Trên bảng điều khiển EMR Studio, chọn Ứng dụng Dưới Không có máy chủ trong khung điều hướng.
- Chọn Tạo ứng dụng.

- Cung cấp tên cho ứng dụng và chọn phiên bản Amazon EMR.
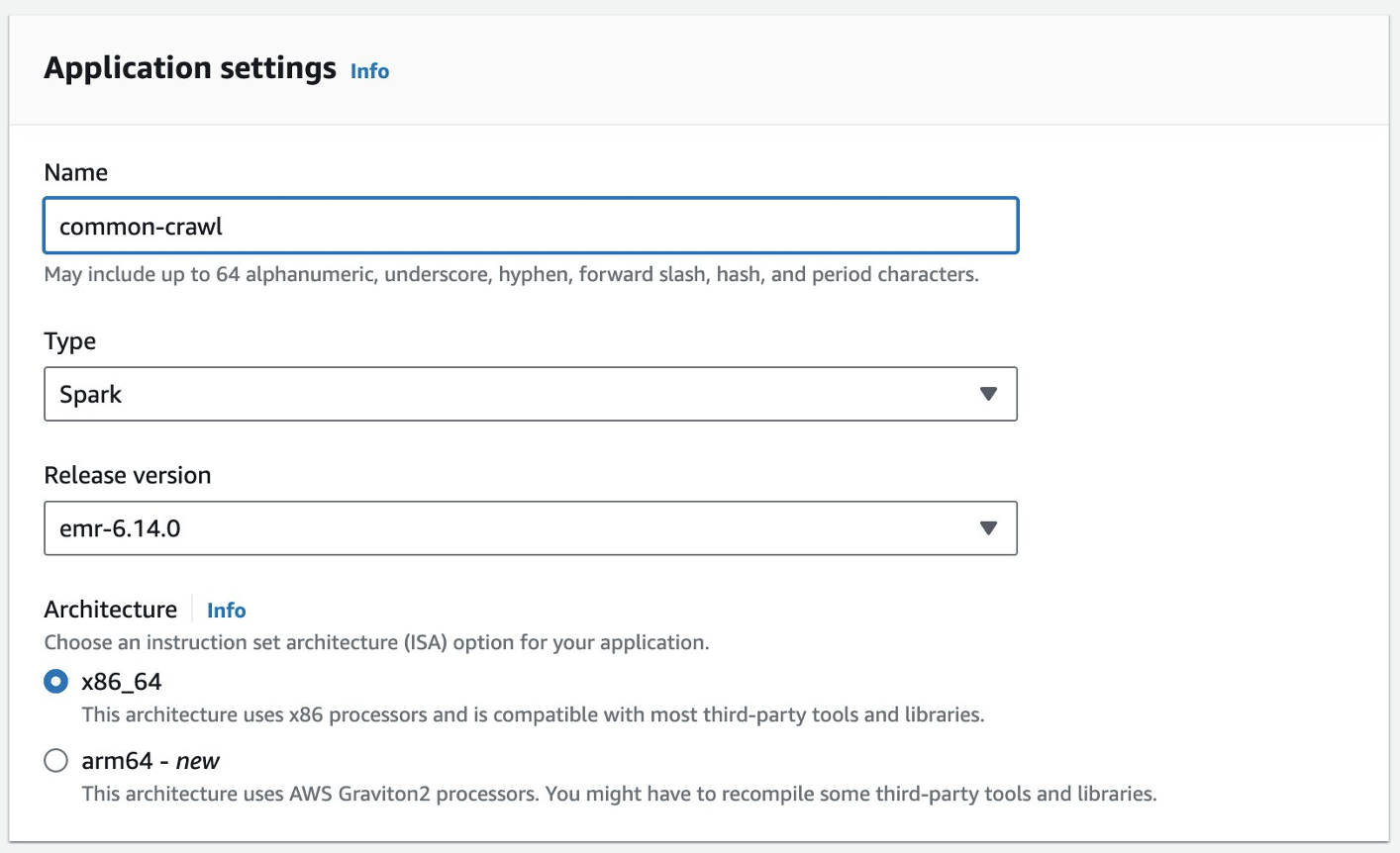
- Nếu cần có quyền truy cập vào tài nguyên VPC, hãy thêm cài đặt mạng tùy chỉnh.

- Chọn Tạo ứng dụng.
Môi trường không có máy chủ Spark của bạn sau đó sẽ sẵn sàng.
Trước khi có thể gửi công việc tới EMR Spark Serverless, bạn vẫn cần tạo vai trò thực thi. tham khảo Bắt đầu với Amazon EMR Serverless để biết thêm chi tiết.
Xử lý dữ liệu thu thập thông tin phổ biến với EMR Serverless
Sau khi ứng dụng EMR Spark Serverless của bạn sẵn sàng, hãy hoàn thành các bước sau để xử lý dữ liệu:
- Chuẩn bị môi trường Conda và tải nó lên Amazon S3. Môi trường này sẽ được sử dụng làm môi trường trong EMR Spark Serverless.
- Tải tập lệnh lên để chạy vào vùng lưu trữ S3. Trong ví dụ sau, có hai tập lệnh:
- imbd_extractor.py – Logic tùy chỉnh để trích xuất nội dung từ tập dữ liệu. Nội dung có thể được tìm thấy trước đó trong bài viết này.
- cc-pyspark/sparkcc.py – Ví dụ khung PySpark từ Kho GitHub thu thập thông tin chung, điều cần thiết phải được đưa vào.
- Gửi công việc PySpark tới EMR Serverless Spark. Xác định các tham số sau để chạy ví dụ này trong môi trường của bạn:
- id ứng dụng – ID ứng dụng của ứng dụng EMR Serverless của bạn.
- vai trò thực thi-arn – Vai trò thực thi EMR Serverless của bạn. Để tạo nó, hãy tham khảo Tạo vai trò thời gian chạy công việc.
- Vị trí tệp WARC – Vị trí tệp WARC của bạn.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtchứa danh sách tệp WARC đã lọc mà bạn đã lấy được trước đó trong bài đăng này. - spark.sql.warehouse.dir – Vị trí kho mặc định (sử dụng thư mục S3 của bạn).
- spark.archives – Vị trí S3 của môi trường Conda đã chuẩn bị.
- spark.submit.pyFiles – Tập lệnh PySpark đã được chuẩn bị sẵn sparkcc.py.
Xem mã sau đây:
Sau khi công việc hoàn tất, các đánh giá được trích xuất sẽ được lưu trữ trong Amazon S3. Để kiểm tra nội dung, bạn có thể sử dụng Amazon S3 Select, như trong ảnh chụp màn hình sau.
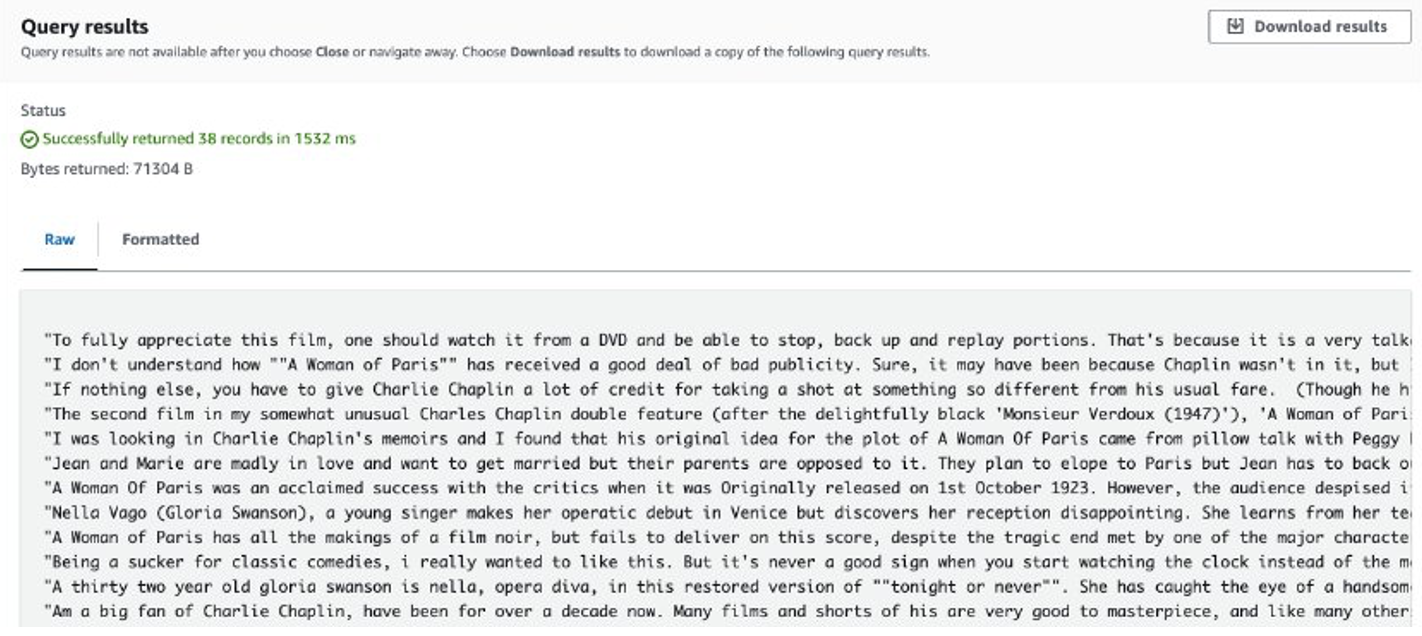
Những cân nhắc
Sau đây là những điểm cần cân nhắc khi xử lý lượng dữ liệu khổng lồ bằng mã tùy chỉnh:
- Một số thư viện Python của bên thứ ba có thể không có sẵn trong Conda. Trong những trường hợp như vậy, bạn có thể chuyển sang môi trường ảo Python để xây dựng môi trường thời gian chạy PySpark.
- Nếu có một lượng lớn dữ liệu cần xử lý, hãy thử tạo và sử dụng nhiều ứng dụng EMR Serverless Spark để song song hóa nó. Mỗi ứng dụng xử lý một tập hợp con các danh sách tập tin.
- Bạn có thể gặp phải sự cố làm chậm với Amazon S3 khi lọc hoặc xử lý dữ liệu Thu thập thông tin chung. Điều này là do bộ chứa S3 lưu trữ dữ liệu có thể truy cập công khai và những người dùng khác có thể truy cập dữ liệu cùng lúc. Để giảm thiểu sự cố này, bạn có thể thêm cơ chế thử lại hoặc đồng bộ hóa dữ liệu cụ thể từ vùng lưu trữ Common Crawl S3 sang vùng lưu trữ của riêng bạn.
Tinh chỉnh Llama 2 bằng SageMaker
Sau khi dữ liệu được chuẩn bị, bạn có thể tinh chỉnh mô hình Llama 2 bằng dữ liệu đó. Bạn có thể làm như vậy bằng SageMaker JumpStart mà không cần viết bất kỳ mã nào. Để biết thêm thông tin, hãy tham khảo Tinh chỉnh Llama 2 để tạo văn bản trên Amazon SageMaker JumpStart.
Trong trường hợp này, bạn thực hiện tinh chỉnh thích ứng miền. Với tập dữ liệu này, đầu vào bao gồm tệp CSV, JSON hoặc TXT. Bạn cần đặt tất cả dữ liệu đánh giá vào một tệp TXT. Để làm như vậy, bạn có thể gửi công việc Spark đơn giản tới EMR Spark Serverless. Xem đoạn mã mẫu sau:
Sau khi bạn chuẩn bị dữ liệu huấn luyện, hãy nhập vị trí dữ liệu cho Tập dữ liệu huấn luyện, sau đó chọn Train.
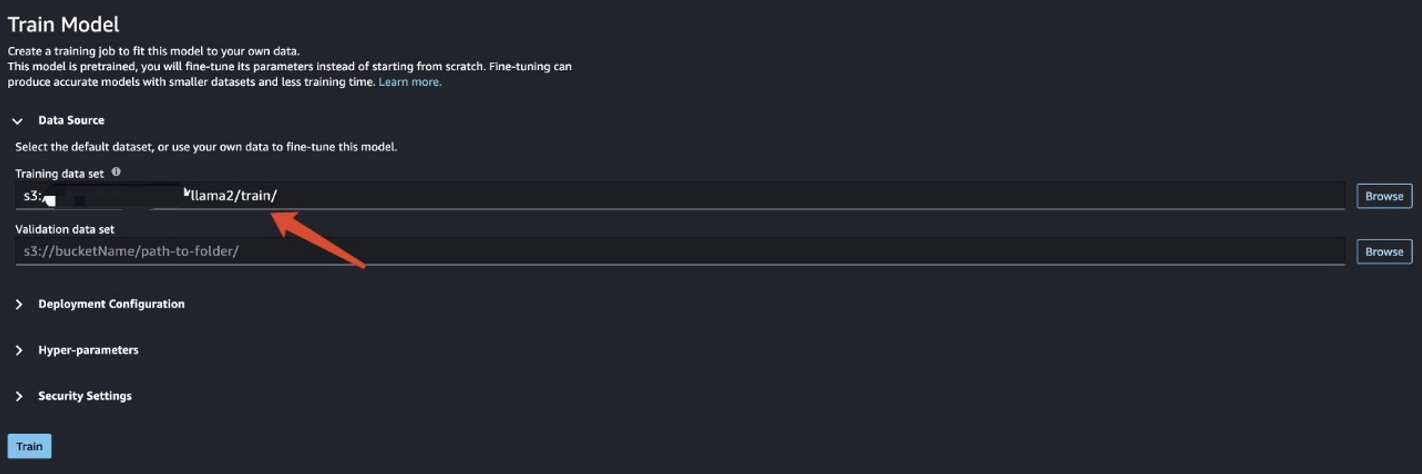
Bạn có thể theo dõi tình trạng công việc đào tạo.
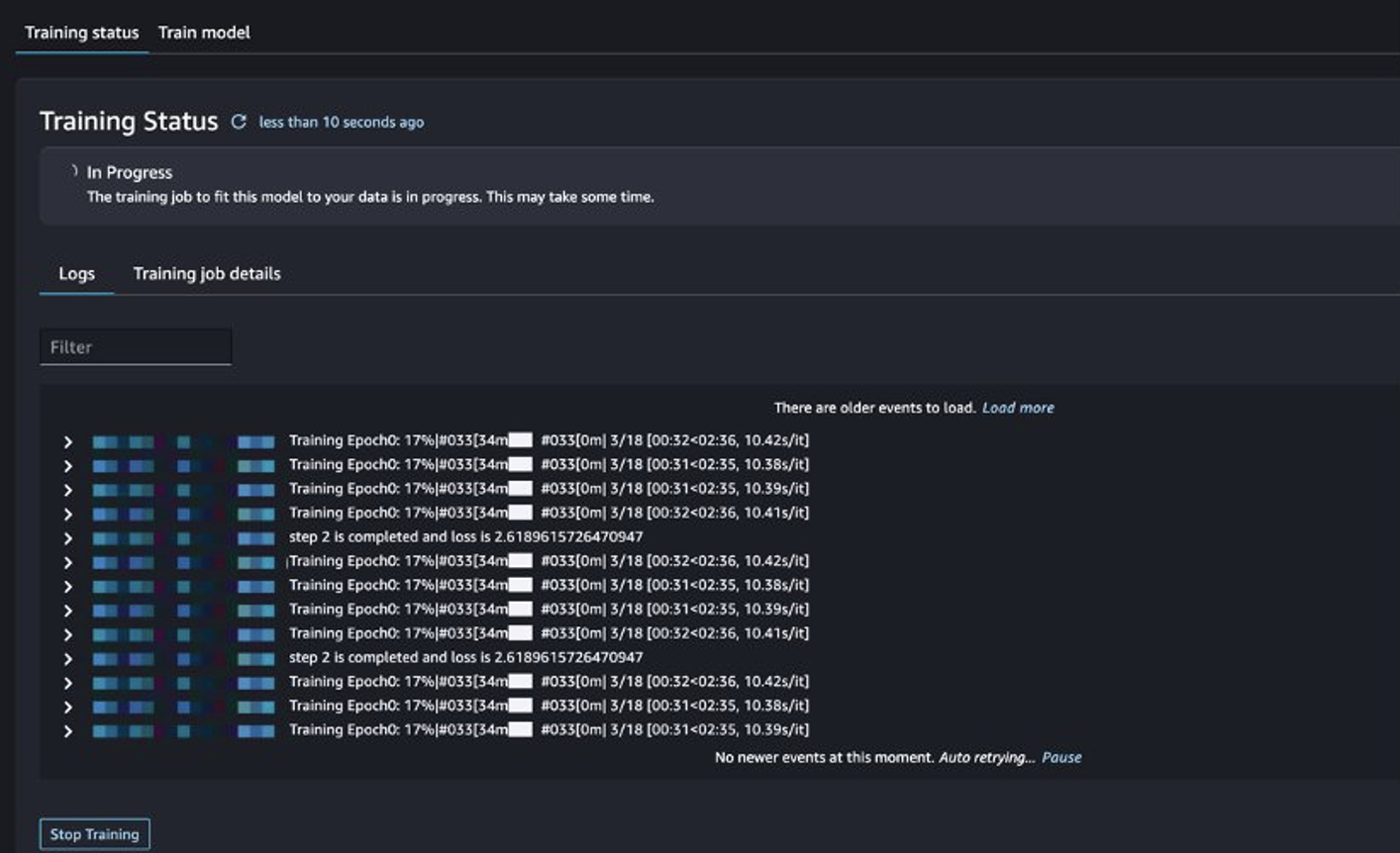
Đánh giá mô hình hiệu chỉnh
Sau khi đào tạo xong, chọn Triển khai trong SageMaker JumpStart để triển khai mô hình tinh chỉnh của bạn.

Sau khi mô hình được triển khai thành công, chọn Mở Notebook, chuyển hướng bạn đến sổ ghi chép Jupyter đã chuẩn bị sẵn nơi bạn có thể chạy mã Python của mình.

Bạn có thể sử dụng hình ảnh Data Science 2.0 và hạt nhân Python 3 cho sổ ghi chép.

Sau đó, bạn có thể đánh giá mô hình đã tinh chỉnh và mô hình gốc trong sổ ghi chép này.
Sau đây là hai câu trả lời do mô hình ban đầu và mô hình tinh chỉnh trả về cho cùng một câu hỏi.
Chúng tôi cung cấp cho cả hai người mẫu một câu giống nhau: “Bài đánh giá về phim 'A Woman of Paris: A Drama of Fate' là” và để họ hoàn thành câu.
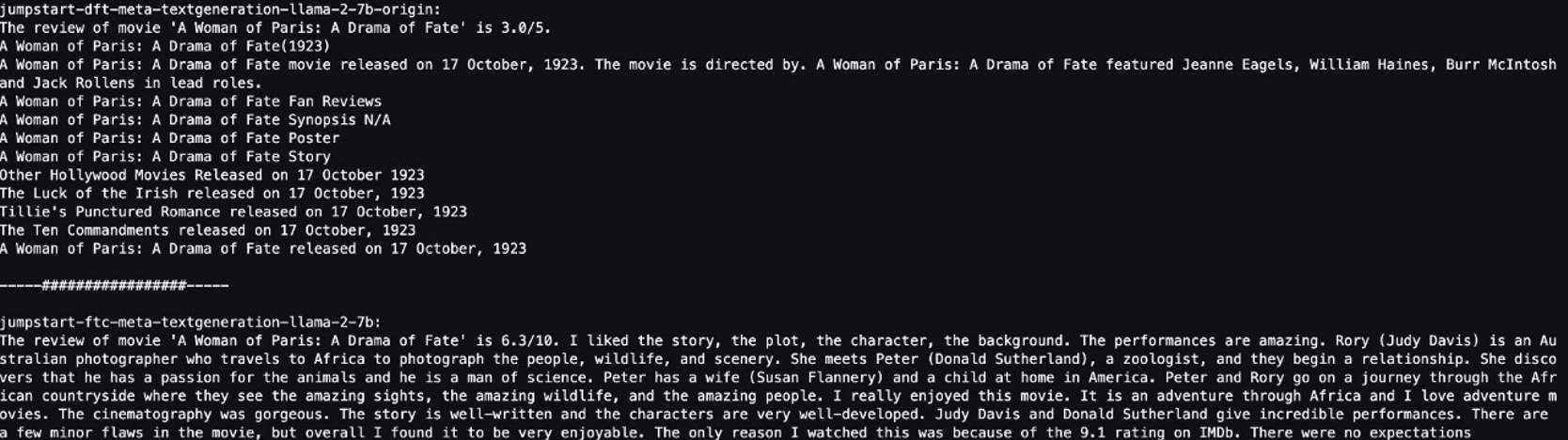
Mô hình ban đầu đưa ra những câu vô nghĩa:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
Ngược lại, kết quả đầu ra của mô hình tinh chỉnh giống như một bản đánh giá phim hơn:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Rõ ràng, mô hình được tinh chỉnh sẽ hoạt động tốt hơn trong trường hợp cụ thể này.
Làm sạch
Sau khi bạn hoàn thành bài tập này, hãy hoàn thành các bước sau để dọn dẹp tài nguyên của bạn:
- Xóa bộ chứa S3 lưu trữ tập dữ liệu đã được làm sạch.
- Dừng môi trường EMR Serverless.
- Xóa điểm cuối SageMaker lưu trữ mô hình LLM.
- Xóa miền SageMaker chạy sổ ghi chép của bạn.
Theo mặc định, ứng dụng bạn đã tạo sẽ tự động dừng sau 15 phút không hoạt động.
Nói chung, bạn không cần phải dọn dẹp môi trường Athena vì bạn không phải trả phí khi không sử dụng.
Kết luận
Trong bài đăng này, chúng tôi đã giới thiệu bộ dữ liệu Thu thập thông tin chung và cách sử dụng EMR Serverless để xử lý dữ liệu nhằm tinh chỉnh LLM. Sau đó, chúng tôi đã trình bày cách sử dụng SageMaker JumpStart để tinh chỉnh LLM và triển khai nó mà không cần bất kỳ mã nào. Để biết thêm các trường hợp sử dụng EMR Serverless, hãy tham khảo Amazon EMR không có máy chủ. Để biết thêm thông tin về mô hình lưu trữ và tinh chỉnh trên Amazon SageMaker JumpStart, hãy tham khảo Tài liệu Sagemaker JumpStart.
Về các tác giả
 Đường Thạch Kiến là Kiến trúc sư giải pháp chuyên gia phân tích tại Amazon Web Services.
Đường Thạch Kiến là Kiến trúc sư giải pháp chuyên gia phân tích tại Amazon Web Services.
 Matthêu Liêm là Giám đốc kiến trúc giải pháp cấp cao tại Amazon Web Services.
Matthêu Liêm là Giám đốc kiến trúc giải pháp cấp cao tại Amazon Web Services.
 Dalei Xu là Kiến trúc sư giải pháp chuyên gia phân tích tại Amazon Web Services.
Dalei Xu là Kiến trúc sư giải pháp chuyên gia phân tích tại Amazon Web Services.
 Nguyên Quân Tiêu là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services.
Nguyên Quân Tiêu là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/

