amazon Athena là một dịch vụ phân tích tương tác, không có máy chủ, được xây dựng trên các khung nguồn mở, hỗ trợ các định dạng tệp bảng mở. Athena cung cấp một cách đơn giản, linh hoạt để phân tích hàng petabyte dữ liệu nơi nó tồn tại. Bạn có thể phân tích dữ liệu hoặc xây dựng ứng dụng từ một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) dữ liệu và 30 nguồn dữ liệu, bao gồm các nguồn dữ liệu tại chỗ hoặc các hệ thống đám mây khác sử dụng SQL hoặc Python. Athena được xây dựng trên các công cụ Trino và Presto mã nguồn mở cũng như các khung Apache Spark mà không cần nỗ lực cung cấp hoặc cấu hình.
Bắt đầu từ hôm nay, công cụ Athena SQL sử dụng trình tối ưu hóa dựa trên chi phí (CBO), một tính năng mới sử dụng số liệu thống kê bảng và cột được lưu trữ trong Keo AWS Danh mục dữ liệu như một phần siêu dữ liệu của bảng. Bằng cách sử dụng những số liệu thống kê này, CBO cải thiện kế hoạch chạy truy vấn và tăng hiệu suất của các truy vấn chạy trong Athena. Một số tối ưu hóa cụ thể mà CBO có thể sử dụng bao gồm sắp xếp lại thứ tự nối và đẩy các tập hợp xuống dựa trên số liệu thống kê có sẵn cho từng bảng và cột.
Điểm chuẩn TPC-DS Các điểm chuẩn này thể hiện sức mạnh của trình tối ưu hóa dựa trên chi phí—các truy vấn chạy nhanh hơn gấp 2 lần khi bật CBO so với việc chạy cùng các truy vấn TPC-DS không có CBO.
So sánh hiệu suất và chi phí trên điểm chuẩn TPC-DS
Chúng tôi đã sử dụng TPC-DS 3 TB tiêu chuẩn ngành để đáp ứng các trường hợp sử dụng khác nhau của khách hàng. Đây là đại diện cho khối lượng công việc có kích thước gấp 10 lần kích thước chuẩn đã nêu. Điều này có nghĩa là tập dữ liệu chuẩn 3 TB thể hiện chính xác khối lượng công việc của khách hàng trên tập dữ liệu 30–50 TB.
Trong thử nghiệm của chúng tôi, tập dữ liệu được lưu trữ trong Amazon S3 ở định dạng Parquet không nén và Danh mục dữ liệu AWS Glue được dùng để lưu trữ siêu dữ liệu cho cơ sở dữ liệu và bảng. Các bảng sự kiện được phân vùng trên cột ngày tháng được sử dụng cho các hoạt động nối và mỗi bảng sự kiện bao gồm 2,000 phân vùng. Để giúp minh họa hiệu suất của CBO, chúng tôi so sánh hành vi của các truy vấn khác nhau và nêu bật sự khác biệt về hiệu suất giữa việc chạy với CBO được bật và bị vô hiệu hóa.
Biểu đồ sau minh họa thời gian chạy của các truy vấn trên công cụ có và không có CBO.

Biểu đồ sau đây trình bày 10 truy vấn hàng đầu từ điểm chuẩn TPC-DS có mức cải thiện hiệu suất lớn nhất.
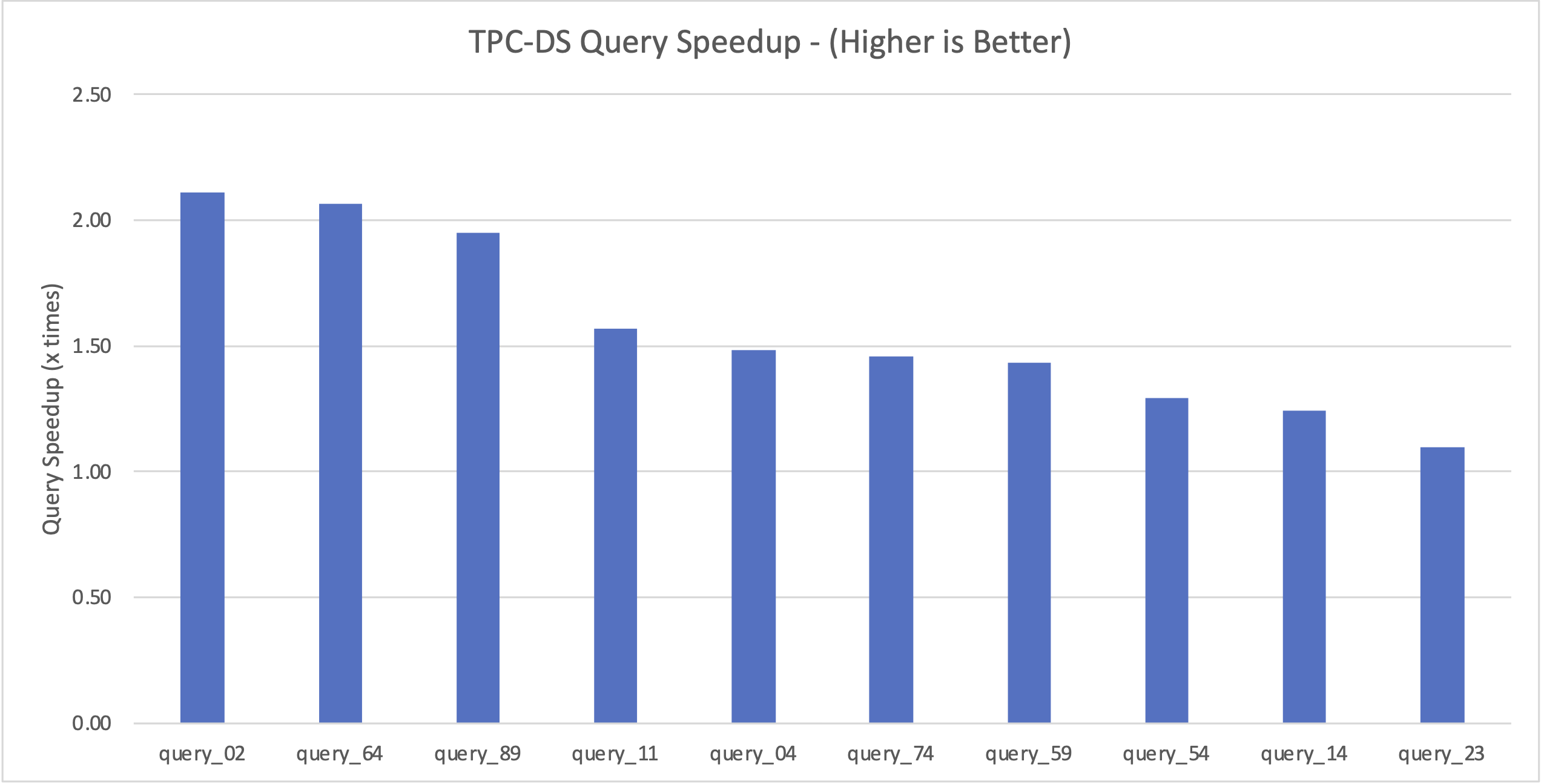
Hãy thảo luận về một số kỹ thuật tối ưu hóa dựa trên chi phí đã góp phần cải thiện hiệu suất truy vấn.
Sắp xếp lại tham gia dựa trên chi phí
Sắp xếp lại tham gia, một kỹ thuật tối ưu hóa được sử dụng bởi các trình tối ưu hóa SQL dựa trên chi phí, phân tích các trình tự tham gia khác nhau để chọn thứ tự giúp giảm thiểu thời gian chạy truy vấn bằng cách giảm dữ liệu trung gian được xử lý ở mỗi bước, giảm yêu cầu về bộ nhớ và CPU.
Hãy nói về truy vấn 82 của bộ dữ liệu TPC-DS 3TB. Truy vấn thực hiện các phép nối bên trong trên bốn bảng: item, inventory, date_dimvà store_sales. Các store_sales bảng có 8.6 tỷ hàng và được phân vùng theo ngày. Các inventory bảng có 1 tỷ hàng và cũng được phân vùng theo ngày. Các item bảng chứa 360,000 hàng và date_dim bảng chứa 73,000 hàng.
Truy vấn 82
Không có CBO
Nếu không sử dụng CBO, công cụ sẽ xác định thứ tự nối dựa trên trình tự các bảng được xác định trong truy vấn đầu vào bằng phương pháp phỏng đoán nội bộ. Mệnh đề FROM của truy vấn đầu vào là "from item, inventory, date_dim, store_sales" (tất cả các phép nối bên trong). Sau khi vượt qua các phương pháp phỏng đoán nội bộ, Athena đã chọn thứ tự nối là ((item ⋈ (inventory ⋈ date_dim)) ⋈ store_sales). Cho dù store_sales là bảng dữ kiện lớn nhất, nó được xác định cuối cùng trong mệnh đề FROM và do đó được nối cuối cùng. Kế hoạch này không thể giảm kích thước kết nối trung gian càng sớm càng tốt, dẫn đến thời gian chạy truy vấn tăng lên. Sơ đồ sau đây hiển thị thứ tự nối không có CBO và số lượng hàng trải qua các giai đoạn khác nhau.

Với CBO
Khi sử dụng CBO, trình tối ưu hóa sẽ xác định thứ tự liên kết tốt nhất bằng cách sử dụng nhiều dữ liệu khác nhau, bao gồm số liệu thống kê cũng như ước tính kích thước liên kết, phía xây dựng liên kết và loại liên kết. Trong trường hợp này, thứ tự tham gia được chọn của Athena là ((store_sales ⋈ item) ⋈ (inventory ⋈ date_dim)). Bảng sự kiện lớn nhất store_sales, không bị xáo trộn, được nối đầu tiên với item bảng chiều. Bảng được phân vùng khác, inventory, cũng lần đầu tiên được nối tại chỗ với date_dim bảng chiều. Phép nối với bảng thứ nguyên đóng vai trò như một bộ lọc trên bảng dữ kiện, giúp giảm đáng kể kích thước dữ liệu đầu vào của phép nối sau đó. Lưu ý rằng phía nào của bảng nằm trong một phép nối có ý nghĩa quan trọng trong Athena, vì chính bảng ở bên phải sẽ được tích hợp vào bộ nhớ cho thao tác nối. Vì vậy, chúng ta luôn muốn giữ bảng lớn hơn ở bên trái và bảng nhỏ hơn ở bên phải. CBO chọn phương án mà trước đây bên trái là 8.6 tỷ, nay là 13.6 triệu.

Với CBO, thời gian chạy truy vấn được cải thiện 25% (từ 15 giây xuống còn 11 giây) bằng cách chọn thứ tự nối tối ưu.
Tiếp theo, hãy thảo luận về một kỹ thuật CBO khác.
Đẩy xuống tổng hợp dựa trên chi phí
Đẩy xuống tổng hợp là một kỹ thuật tối ưu hóa được sử dụng bởi các trình tối ưu hóa truy vấn để cải thiện hiệu suất. Nó liên quan đến việc đẩy các hoạt động tổng hợp như SUM, COUNT và AVG vào giai đoạn trước đó trong kế hoạch truy vấn, trong khi vẫn duy trì cùng một ngữ nghĩa truy vấn. Điều này làm giảm lượng dữ liệu được truyền giữa các giai đoạn. Bằng cách giảm thiểu việc xử lý dữ liệu, việc đẩy xuống tổng hợp sẽ giảm mức sử dụng bộ nhớ, chi phí I/O và lưu lượng mạng.
Tuy nhiên, việc giảm tổng hợp không phải lúc nào cũng có lợi. Nó phụ thuộc vào việc phân phối dữ liệu. Ví dụ: nhóm trên một cột có nhiều hàng nhưng có ít giá trị riêng biệt (như giới tính) trước khi nối sẽ hoạt động tốt hơn. Nhóm đầu tiên có nghĩa là tổng hợp một số lượng lớn các bản ghi thành ít bản ghi hơn (ví dụ: chỉ nam, nữ). Nhóm sau khi nối có nghĩa là một số lượng lớn các bản ghi phải tham gia nối trước khi được tổng hợp. Mặt khác, việc nhóm trên cột có lượng số cao sẽ được thực hiện tốt hơn sau khi nối. Làm điều đó trước khi gặp rủi ro về chi phí tổng hợp không cần thiết vì dù sao thì mỗi giá trị có thể là duy nhất và bước đó sẽ không dẫn đến việc giảm lượng dữ liệu được truyền giữa các giai đoạn trung gian sớm hơn.
Do đó, việc có nên giảm tổng hợp hay không sẽ là một quyết định dựa trên chi phí. Hãy lấy ví dụ về truy vấn 2 chạy trên tập dữ liệu TPC-DS 3TB, cho thấy giá trị của việc đẩy xuống tổng hợp phụ thuộc như thế nào vào phân phối dữ liệu. Các web_sales bảng có 2.1 tỷ hàng và catalog_sales bảng có 4.23 tỷ hàng. Cả hai bảng đều được phân vùng trên cột ngày.
Truy vấn 2
Không có CBO
Athena lần đầu tiên tham gia kết quả của hoạt động liên minh trên web_sales cái bàn và cái catalog_sales bàn với một bàn khác. Chỉ khi đó nó mới thực hiện tổng hợp các kết quả đã nối. Trong ví dụ này, lượng dữ liệu cần được nối là rất lớn, dẫn đến thời gian chạy truy vấn dài hơn.

Với CBO
Athena sử dụng một trong các giá trị thống kê, số lượng giá trị riêng biệt, để đánh giá tác động chi phí của việc giảm tổng hợp so với không làm như vậy. Khi một cột có nhiều hàng nhưng có ít giá trị riêng biệt, CBO có nhiều khả năng đẩy tổng hợp xuống. Điều này đã thu hẹp các hàng đủ điều kiện từ web_sales và catalog_sales bảng lần lượt là 2,590 và 3,590 hàng. Những bản ghi tổng hợp này sau đó được hợp nhất và sử dụng để nối với các bảng. So với kế hoạch không có CBO, số bản ghi tham gia join từ hai bảng lớn đã giảm từ 6.33 tỷ hàng (2.1 tỷ + 4.23 tỷ) xuống chỉ còn 6,180 hàng (2,590 + 3,590). Điều này làm giảm đáng kể thời gian chạy truy vấn.

Với CBO, thời gian chạy truy vấn được cải thiện 50% (từ 37 giây xuống còn 18 giây). Tóm lại, CBO đã giúp Athena lựa chọn phương án đẩy xuống tổng hợp tối ưu, giảm thời gian truy vấn xuống một nửa so với việc không sử dụng tối ưu hóa dựa trên chi phí.
Kết luận
Trong bài đăng này, chúng tôi đã thảo luận về cách Athena sử dụng trình tối ưu hóa dựa trên chi phí (CBO) trong công cụ v3 của mình để sử dụng số liệu thống kê bảng nhằm tạo kế hoạch chạy truy vấn hiệu quả hơn. Thử nghiệm trên điểm chuẩn TPC-DS cho thấy hiệu suất truy vấn tổng thể được cải thiện 11% khi sử dụng CBO so với khi không sử dụng nó.
Hai tối ưu hóa chính được CBO sử dụng là sắp xếp lại liên kết và đẩy xuống tổng hợp. Việc sắp xếp lại tham gia giúp giảm dữ liệu trung gian bằng cách chọn thứ tự tham gia các bảng một cách thông minh dựa trên số liệu thống kê. Đẩy xuống tổng hợp làm giảm dữ liệu trung gian bằng cách đẩy các tổng hợp sớm hơn trong kế hoạch khi có lợi.
Tóm lại, trình tối ưu hóa dựa trên chi phí mới của Athena tăng tốc đáng kể các truy vấn bằng cách chọn các kế hoạch chạy ưu việt. CBO tối ưu hóa dựa trên số liệu thống kê dạng bảng được lưu trữ trong Danh mục dữ liệu AWS Glue. Việc tối ưu hóa tự động này giúp cải thiện năng suất cho người dùng Athena thông qua hiệu suất truy vấn phản hồi nhanh hơn. Để tận dụng các kỹ thuật tối ưu hóa của CBO, hãy tham khảo làm việc với số liệu thống kê cột để tạo số liệu thống kê trên các bảng và cột trong Danh mục dữ liệu AWS Glue.
Về các tác giả
 Darshit Thakkar là Giám đốc sản phẩm kỹ thuật của AWS và làm việc với nhóm Amazon Athena có trụ sở tại Boston, Massachusetts.
Darshit Thakkar là Giám đốc sản phẩm kỹ thuật của AWS và làm việc với nhóm Amazon Athena có trụ sở tại Boston, Massachusetts.
 Ngụy Tranh là Kỹ sư phát triển phần mềm cấp cao của Amazon Athena. Anh gia nhập AWS vào năm 2021 và đang nghiên cứu nhiều cải tiến hiệu suất trên Athena.
Ngụy Tranh là Kỹ sư phát triển phần mềm cấp cao của Amazon Athena. Anh gia nhập AWS vào năm 2021 và đang nghiên cứu nhiều cải tiến hiệu suất trên Athena.
 Chuho Chang là Kỹ sư phát triển phần mềm của Amazon Athena. Anh ấy đã làm việc về các trình tối ưu hóa truy vấn trong hơn một thập kỷ.
Chuho Chang là Kỹ sư phát triển phần mềm của Amazon Athena. Anh ấy đã làm việc về các trình tối ưu hóa truy vấn trong hơn một thập kỷ.
 Pathik Shah là Kiến trúc sư phân tích cấp cao trên Amazon Athena. Anh gia nhập AWS vào năm 2015 và kể từ đó tập trung vào lĩnh vực phân tích dữ liệu lớn, giúp khách hàng xây dựng các giải pháp mạnh mẽ và có thể mở rộng bằng dịch vụ phân tích AWS.
Pathik Shah là Kiến trúc sư phân tích cấp cao trên Amazon Athena. Anh gia nhập AWS vào năm 2015 và kể từ đó tập trung vào lĩnh vực phân tích dữ liệu lớn, giúp khách hàng xây dựng các giải pháp mạnh mẽ và có thể mở rộng bằng dịch vụ phân tích AWS.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/speed-up-queries-with-cost-based-optimizer-in-amazon-athena/

