Giới thiệu
Trong thị giác máy tính, tồn tại các kỹ thuật khác nhau để phát hiện đối tượng trực tiếp, bao gồm Faster R-CNN, SSDvà Yolo. Mỗi kỹ thuật đều có những hạn chế và ưu điểm của nó. Mặc dù Faster R-CNN có thể vượt trội về độ chính xác nhưng nó có thể không hoạt động tốt trong các tình huống thời gian thực, dẫn đến sự thay đổi theo hướng Thuật toán YOLO.
Phát hiện đối tượng là nền tảng trong thị giác máy tính, cho phép máy xác định và định vị các đối tượng trong khung hoặc màn hình. Trong những năm qua, nhiều thuật toán phát hiện đối tượng khác nhau đã được phát triển, trong đó YOLO nổi lên là một trong những thuật toán thành công nhất. Gần đây, YOLOv8 đã được giới thiệu, nâng cao hơn nữa khả năng của thuật toán.
Trong hướng dẫn toàn diện này, chúng tôi khám phá ba thuật toán phát hiện đối tượng nổi bật: R-CNN nhanh hơn, SSD (Single Shot MultiBox Detector) và YOLOv8. Chúng tôi thảo luận về các khía cạnh thực tế của việc triển khai các thuật toán này, bao gồm thiết lập môi trường ảo và phát triển ứng dụng Streamlit.
Mục tiêu học tập
- Hiểu Faster R-CNN, SSD và YOLO và phân tích sự khác biệt giữa chúng.
- Có được kinh nghiệm thực tế trong việc triển khai các hệ thống phát hiện đối tượng trực tiếp bằng OpenCV, Supervision và YOLOv8.
- Tìm hiểu mô hình phân đoạn hình ảnh bằng chú thích Roboflow.
- Tạo ứng dụng Streamlit để có giao diện người dùng dễ dàng.
Hãy cùng khám phá cách thực hiện phân đoạn hình ảnh với YOLOv8 nhé!
Mục lục
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
R-CNN nhanh hơn
Faster R-CNN (Mạng thần kinh chuyển đổi dựa trên khu vực nhanh hơn) là một thuật toán phát hiện đối tượng dựa trên deep learning. Nó được đánh giá bằng cách sử dụng khung R-CNN và Fast R-CNN và có thể được coi là phần mở rộng của Fast R-CNN.
Thuật toán này giới thiệu Mạng đề xuất khu vực (RPN) để tạo đề xuất khu vực, thay thế tìm kiếm chọn lọc được sử dụng trong R-CNN. RPN chia sẻ các lớp tích chập với mạng phát hiện, cho phép đào tạo đầu cuối hiệu quả.
Sau đó, các đề xuất vùng được tạo sẽ được đưa vào mạng Fast R-CNN để tinh chỉnh hộp giới hạn và phân loại đối tượng.
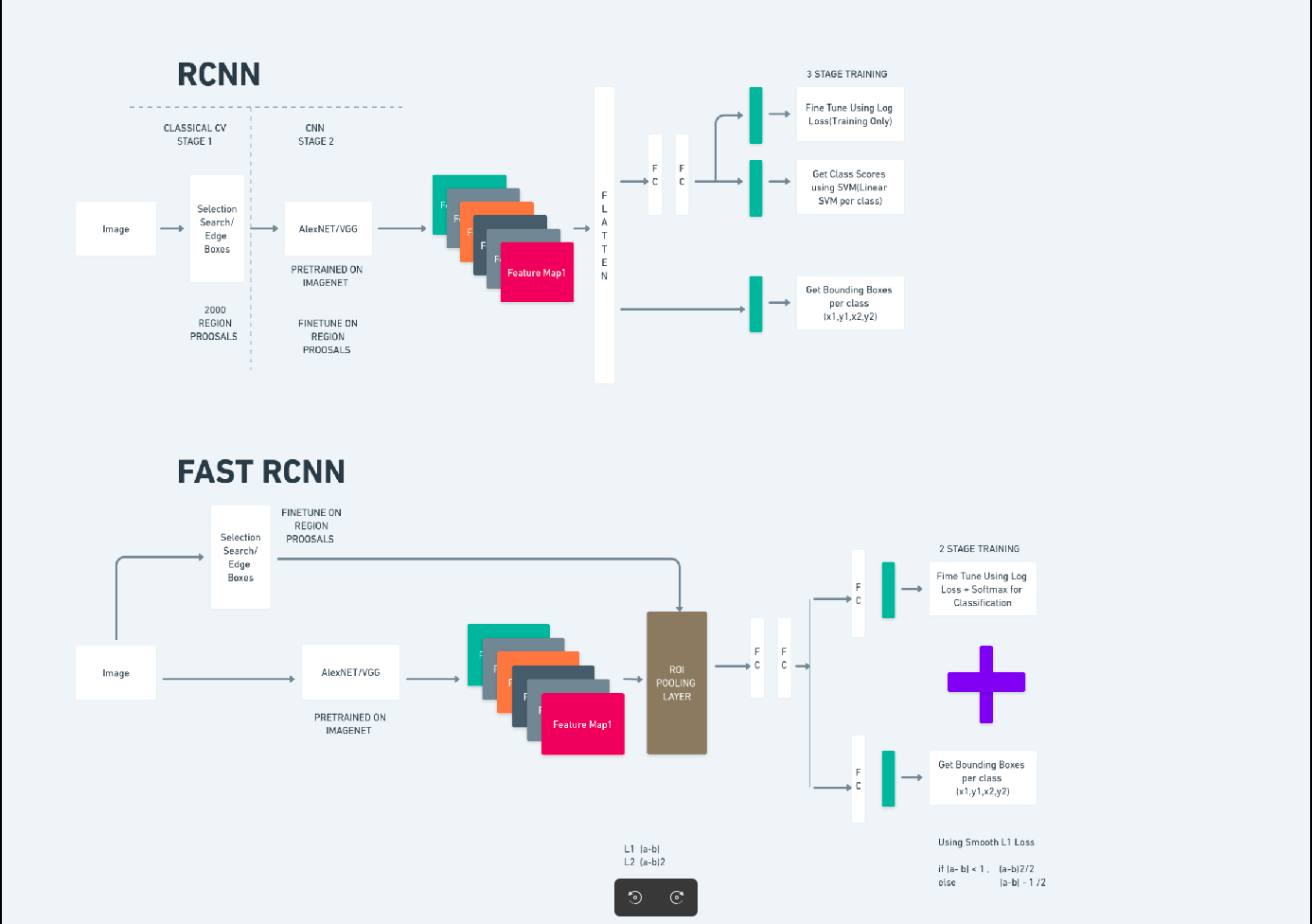
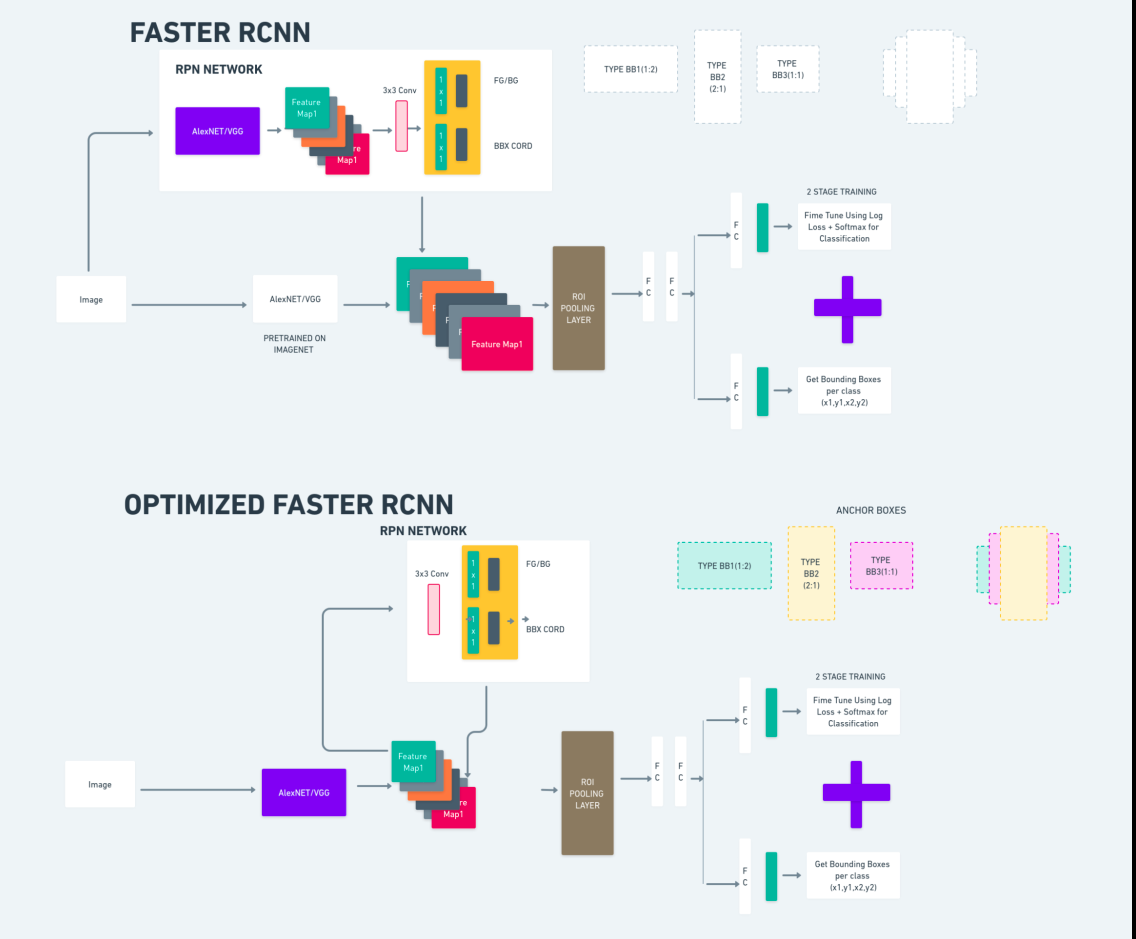
Sơ đồ trên minh họa họ Faster R-CNN một cách toàn diện và dễ hiểu để đánh giá từng thuật toán.
Máy dò MultiBox bắn một lần (SSD)
Sản phẩm Máy dò MultiBox bắn một lần (SSD) phổ biến trong phát hiện đối tượng và chủ yếu được sử dụng trong các tác vụ thị giác máy tính. Trong phương pháp trước đó, Faster R-CNN, chúng tôi đã làm theo hai bước: bước đầu tiên liên quan đến phần phát hiện và bước thứ hai liên quan đến hồi quy. Tuy nhiên, với SSD, chúng ta chỉ thực hiện một bước phát hiện duy nhất. SSD được giới thiệu vào năm 2016 nhằm giải quyết nhu cầu về mô hình phát hiện đối tượng nhanh và chính xác.

SSD có một số ưu điểm so với các phương pháp phát hiện đối tượng trước đây như Faster R-CNN:
- Hiệu quả: SSD là công cụ phát hiện một giai đoạn, nghĩa là nó dự đoán trực tiếp các hộp giới hạn và điểm lớp mà không yêu cầu bước tạo đề xuất riêng. Điều này làm cho nó nhanh hơn so với các máy dò hai giai đoạn như Faster R-CNN.
- Đào tạo từ đầu đến cuối: SSD có thể được đào tạo từ đầu đến cuối, tối ưu hóa cả mạng cơ sở và đầu phát hiện, giúp đơn giản hóa quá trình đào tạo.
- Kết hợp tính năng đa tỷ lệ: SSD hoạt động trên các bản đồ tính năng ở nhiều tỷ lệ, cho phép phát hiện các vật thể có kích thước khác nhau một cách hiệu quả hơn.
SSD đạt được sự cân bằng tốt giữa tốc độ và độ chính xác, khiến ổ SSD này phù hợp với các ứng dụng thời gian thực trong đó cả hiệu suất và hiệu quả đều rất quan trọng.
Bạn Chỉ Nhìn Một Lần(YOLOv8)
Vào năm 2015, You Only Look Once (YOLO) đã được giới thiệu như một thuật toán phát hiện đối tượng trong một bài nghiên cứu của Joseph Redmon, Santosh Divvala, Ross Girshick và Ali Farhadi. YOLO là một thuật toán một lần phân loại trực tiếp một đối tượng trong một lần truyền bằng cách chỉ có một mạng thần kinh dự đoán các hộp giới hạn và xác suất của lớp bằng cách sử dụng hình ảnh đầy đủ làm đầu vào.
Bây giờ, hãy hiểu YOLOv8 là những tiến bộ tiên tiến trong việc phát hiện đối tượng theo thời gian thực với độ chính xác và tốc độ được cải thiện. YOLOv8 cho phép bạn tận dụng các mô hình được đào tạo trước, những mô hình đã được đào tạo trên tập dữ liệu khổng lồ như COCO (Đối tượng chung trong ngữ cảnh). Phân đoạn hình ảnh cung cấp thông tin ở cấp độ pixel về từng đối tượng, cho phép phân tích và hiểu chi tiết hơn về nội dung hình ảnh.
Mặc dù việc phân đoạn hình ảnh có thể tốn kém về mặt tính toán nhưng YOLOv8 tích hợp phương pháp này vào kiến trúc mạng thần kinh của nó, cho phép phân đoạn đối tượng hiệu quả và chính xác.
Nguyên lý hoạt động của YOLOv8
YOLOv8 đầu tiên hoạt động bằng cách chia hình ảnh đầu vào thành các ô lưới. Bằng cách sử dụng các ô lưới này, YOLOv8 dự đoán các hộp giới hạn (bbox) có xác suất thuộc lớp.
Sau đó, YOLOv8 sử dụng thuật toán NMS để giảm sự chồng chéo. Ví dụ: nếu có nhiều ô tô xuất hiện trong hình ảnh dẫn đến các hộp giới hạn chồng chéo, thuật toán NMS sẽ giúp giảm sự chồng chéo này.
Sự khác biệt giữa các biến thể của Yolo V8: YOLOv8 có sẵn ba biến thể: YOLOv8, YOLOv8-L và YOLOv8-X. Sự khác biệt chính giữa các biến thể là kích thước của mạng đường trục. YOLOv8 có mạng đường trục nhỏ nhất, trong khi YOLOv8-X có mạng đường trục lớn nhất.
Sự khác biệt giữa R-CNN nhanh hơn, SSD và YOLO
| Aspect | R-CNN nhanh hơn | SSD | Yolo |
|---|---|---|---|
| Kiến trúc | Máy dò hai giai đoạn với RPN và Fast R-CNN | Máy dò một tầng | Máy dò một tầng |
| Đề xuất khu vực | Có | Không | Không |
| Tốc độ phát hiện | Chậm hơn so với SSD và YOLO | Nhanh hơn so với Faster R-CNN, chậm hơn YOLO | Rất nhanh |
| tính chính xác | Nói chung độ chính xác cao hơn | Cân bằng độ chính xác và tốc độ | Độ chính xác khá cao, đặc biệt đối với các ứng dụng thời gian thực |
| Linh hoạt | Linh hoạt, có thể xử lý nhiều kích thước đối tượng và tỷ lệ khung hình khác nhau | Có thể xử lý nhiều quy mô của đối tượng | Có thể gặp khó khăn trong việc định vị chính xác các vật thể nhỏ |
| Phát hiện thống nhất | Không | Không | Có |
| Sự đánh đổi giữa tốc độ và độ chính xác | Nói chung hy sinh tốc độ cho độ chính xác | Cân bằng tốc độ và độ chính xác | Ưu tiên tốc độ trong khi vẫn duy trì độ chính xác khá |
Phân khúc là gì?
Như chúng ta đã biết, phân đoạn có nghĩa là chúng ta chia hình ảnh lớn thành các nhóm nhỏ hơn dựa trên các đặc điểm nhất định. Hãy hiểu phân đoạn hình ảnh là kỹ thuật thị giác máy tính được sử dụng để phân vùng hình ảnh thành nhiều phân đoạn hoặc vùng khác nhau. Vì hình ảnh được tạo từ các pixel và trong phân đoạn Hình ảnh, các pixel được nhóm lại với nhau theo sự giống nhau về màu sắc, cường độ, kết cấu hoặc các đặc tính hình ảnh khác.
Ví dụ: nếu một hình ảnh chứa cây cối, ô tô hoặc người thì phân đoạn hình ảnh sẽ chia hình ảnh thành các lớp khác nhau đại diện cho các đối tượng hoặc phần có ý nghĩa của hình ảnh. Phân đoạn hình ảnh được sử dụng rộng rãi trong các lĩnh vực khác nhau như hình ảnh y tế, phân tích hình ảnh vệ tinh, nhận dạng đối tượng trong thị giác máy tính, v.v.

Trong phần phân đoạn, ban đầu chúng tôi tạo mô hình phân đoạn YOLOv8 đầu tiên bằng Robflow. Sau đó, chúng tôi nhập mô hình phân đoạn để thực hiện nhiệm vụ phân đoạn. Câu hỏi đặt ra: tại sao chúng ta tạo mô hình phân đoạn khi nhiệm vụ có thể được hoàn thành chỉ bằng thuật toán phát hiện?
Phân đoạn cho phép chúng ta có được hình ảnh toàn thân của một lớp. Trong khi các thuật toán phát hiện tập trung vào việc phát hiện sự hiện diện của các đối tượng thì phân đoạn cung cấp sự hiểu biết chính xác hơn bằng cách phân định ranh giới chính xác của các đối tượng. Điều này dẫn đến việc định vị và hiểu chính xác hơn về các đối tượng có trong ảnh.
Tuy nhiên, phân đoạn thường có độ phức tạp về thời gian cao hơn so với các thuật toán phát hiện vì nó yêu cầu các bước bổ sung như tách chú thích và tạo mô hình. Bất chấp nhược điểm này, độ chính xác tăng lên do phân đoạn mang lại có thể lớn hơn chi phí tính toán trong các nhiệm vụ trong đó việc phân định đối tượng chính xác là rất quan trọng.
Phát hiện trực tiếp từng bước và phân đoạn hình ảnh với YOLOv8
Trong khái niệm này, chúng ta đang khám phá các bước tạo môi trường ảo bằng conda, kích hoạt venv và cài đặt các gói yêu cầu bằng pip. đầu tiên tạo tập lệnh python bình thường, sau đó chúng ta tạo ứng dụng hợp lý.
Bước 1: Tạo môi trường ảo bằng Conda
conda create -p ./venv python=3.8 -yBước 2: Kích hoạt môi trường ảo
conda activate ./venv
Bước 3: Tạo file require.txt
Mở terminal và dán đoạn script bên dưới:
touch requirements.txtBước 4: Sử dụng Lệnh Nano và Chỉnh sửa request.txt
Sau khi tạo tệp request.txt, hãy sử dụng lệnh sau để chỉnh sửa tệp request.txt
nano requirements.txtSau khi chạy đoạn script trên, bạn có thể thấy giao diện người dùng này.
Viết các gói cần thiết của cô ấy.
ultralytics==8.0.32
supervision==0.2.1
streamlitSau đó nhấn “ctrl+o”(lệnh này lưu phần chỉnh sửa) rồi nhấn nút "Đi vào"
Sau khi nhấn nút “Ctrl+x”. bạn có thể thoát khỏi tập tin. và đi đến con đường chính.
Bước 5: Cài đặt require.txt
pip install -r requirements.txtBước 6: Tạo tập lệnh Python
Trong terminal viết đoạn script sau hoặc chúng ta có thể nói lệnh.
touch main.pySau khi tạo main.py, hãy mở mã vs bạn sử dụng lệnh ghi trong terminal,
code Bước 7: Viết tập lệnh Python
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Sau khi chạy lệnh này, bạn có thể thấy camera đang mở và phát hiện một phần cơ thể của bạn. như giới tính và phần nền.
Bước 7: Tạo ứng dụng hợp lý
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
Trong tập lệnh này, chúng tôi đang tạo ứng dụng có đèn chiếu sáng đơn giản và tạo nút để sau khi nhấn nút, camera của thiết bị của bạn sẽ mở và phát hiện phần trong khung.
Chạy tập lệnh này bằng lệnh này.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Sau khi chạy lệnh trên, giả sử bạn gặp lỗi liên hệ như sau:
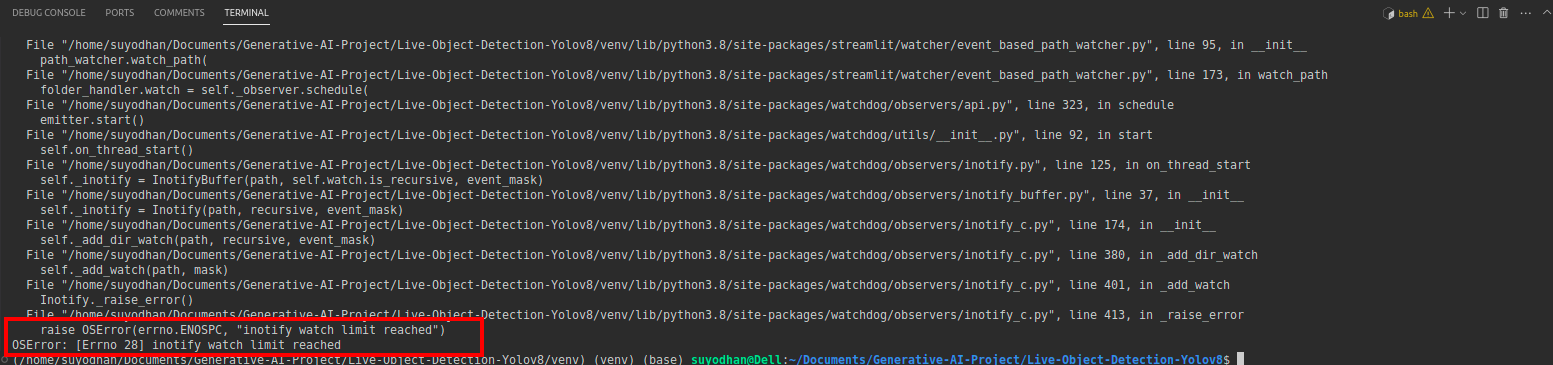
sau đó nhấn lệnh này,
sudo sysctl fs.inotify.max_user_watches=524288Sau khi nhấn lệnh bạn muốn viết mật khẩu của mình vì chúng tôi đang sử dụng lệnh sudo sudo là thần :)
Chạy lại tập lệnh. và bạn có thể thấy ứng dụng được chiếu sáng rõ ràng.
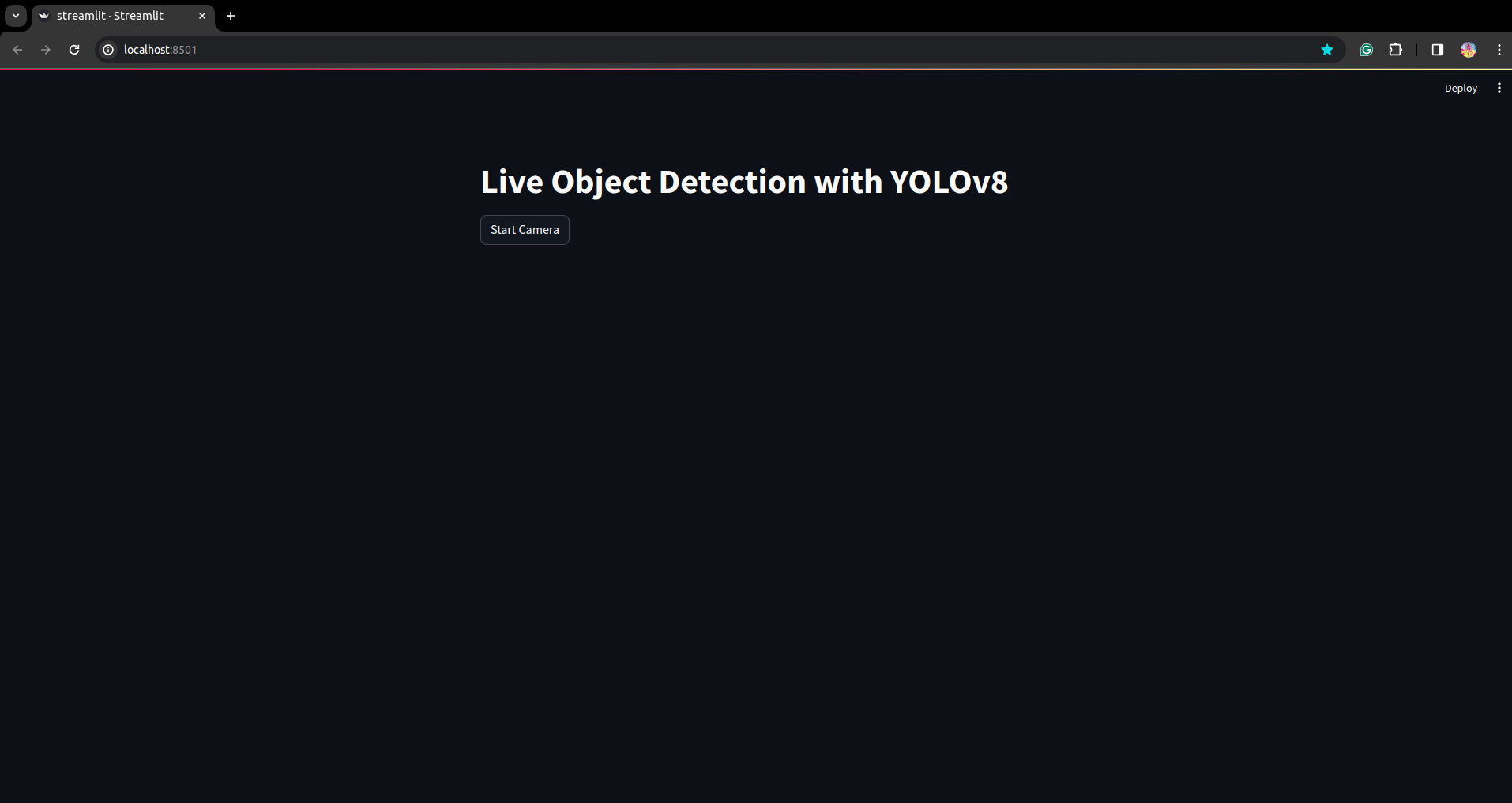
Ở đây chúng ta có thể tạo một ứng dụng phát hiện trực tiếp thành công. Phần tiếp theo chúng ta sẽ xem phần phân đoạn.
Các bước chú thích
Bước 1: Thiết lập Roboflow
Sau khi ký “Tạo dự án”. tại đây bạn có thể tạo dự án và nhóm chú thích.

Bước 2: Tải xuống tập dữ liệu
Ở đây chúng tôi xem xét ví dụ đơn giản nhưng bạn muốn sử dụng nó trong báo cáo vấn đề của mình nên tôi đang sử dụng tập dữ liệu vịt ở đây.
Đi cái này Link và tải xuống tập dữ liệu vịt.

Giải nén thư mục ở đó bạn có thể thấy ba thư mục: đào tạo, kiểm tra và val.
Bước 3: Tải Tập dữ liệu lên roboflow
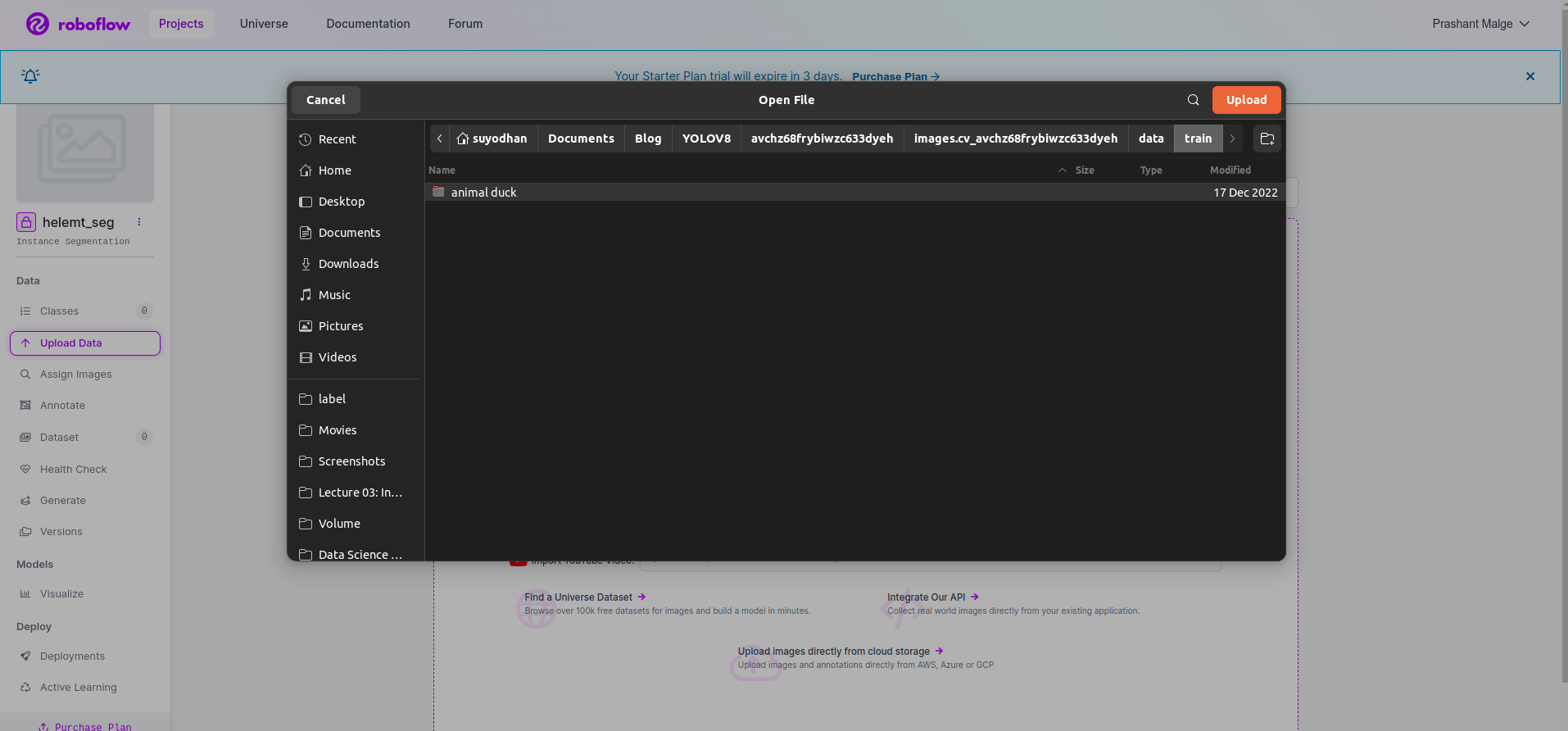
Sau khi tạo dự án trong roboflow, bạn có thể thấy giao diện người dùng này tại đây. Bạn có thể tải tập dữ liệu của mình lên, vì vậy, chỉ tải lên các hình ảnh bộ phận đào tạo, hãy chọn “chọn thư mục" tùy chọn.
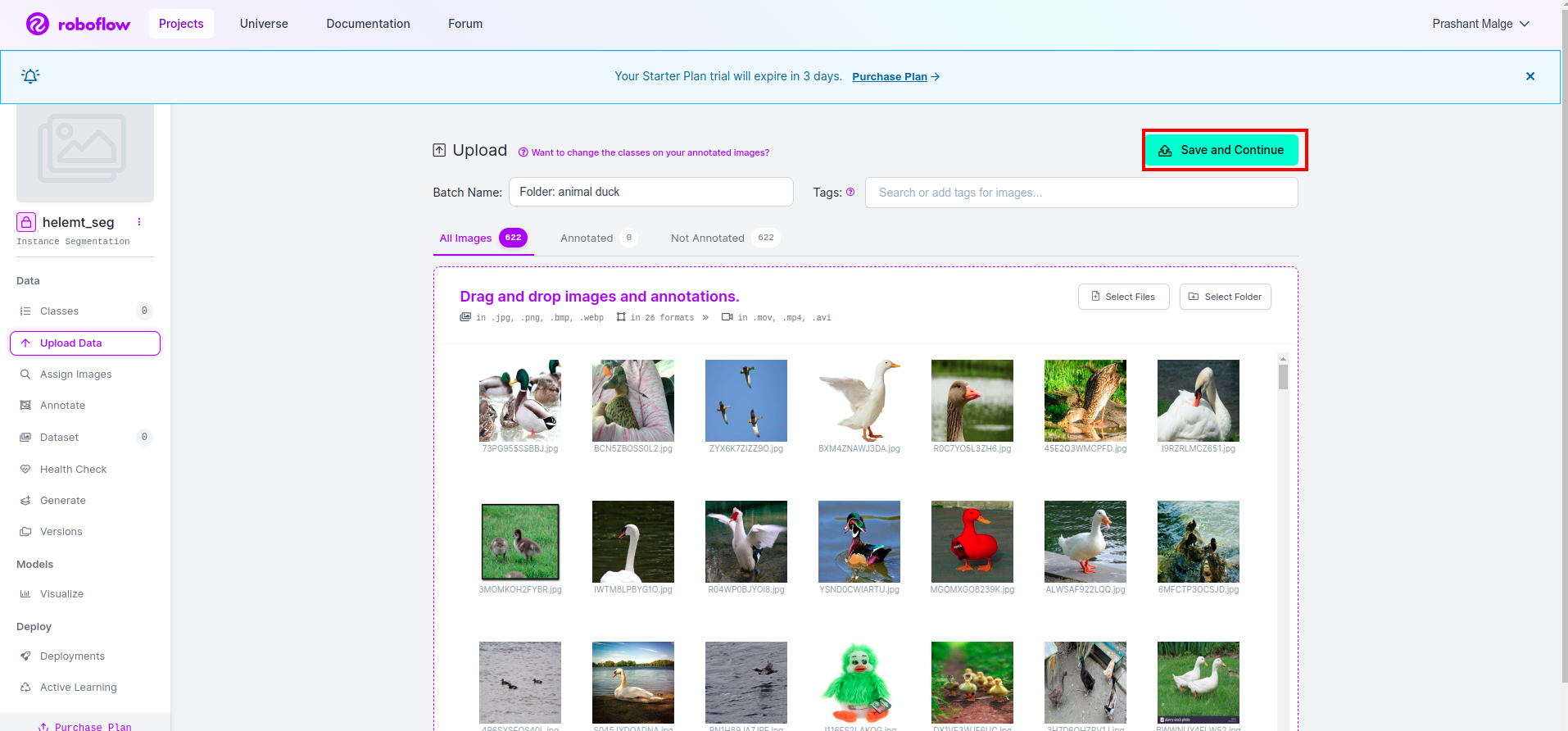
Sau đó nhấp vào nút “lưu lại và tiếp tục" tùy chọn khi tôi đánh dấu vào hộp hình chữ nhật màu đỏ
Bước 4: Thêm tên lớp
Sau đó đi đến phần lớp ở bên trái đánh dấu vào ô màu đỏ. và viết tên lớp là con vịt, sau khi nhấp vào hộp màu xanh lá cây.
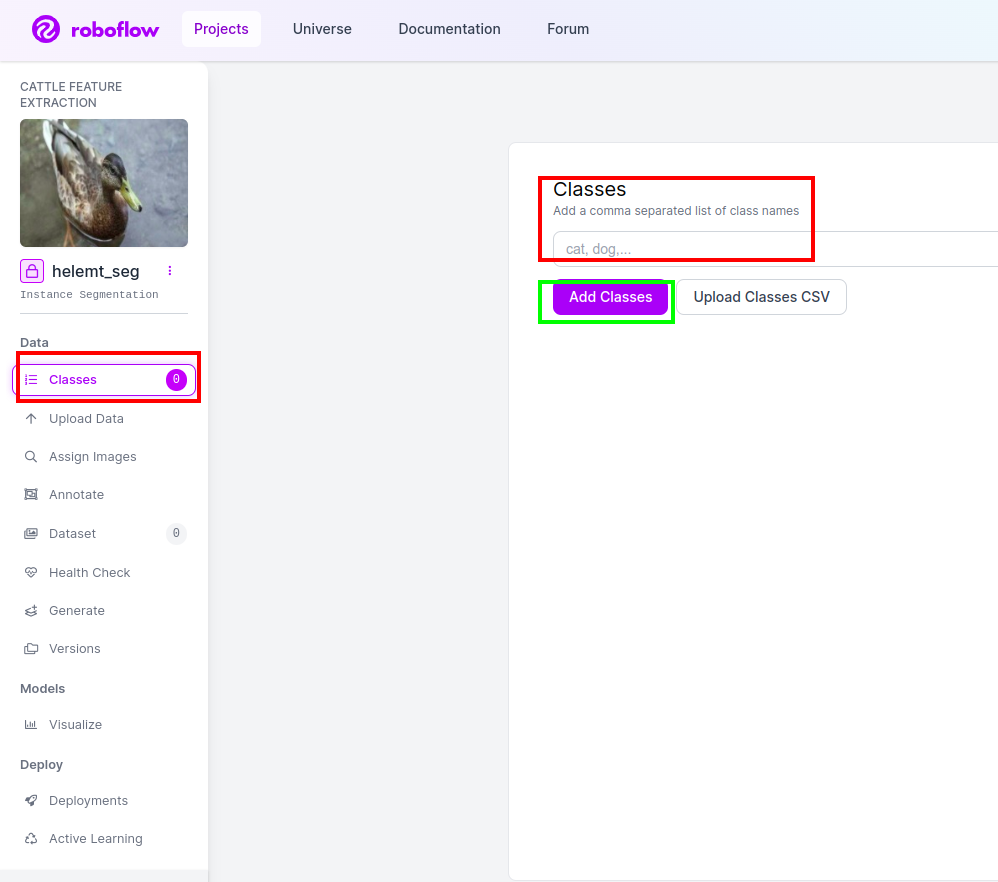
Bây giờ chúng ta đã thiết lập xong và phần tiếp theo như phần chú thích cũng đơn giản.
Bước 5: Bắt đầu phần chú thích
Tới tùy chọn chú thích Tôi đã đánh dấu vào ô màu đỏ rồi nhấp vào phần bắt đầu chú thích như tôi đã đánh dấu ở ô màu xanh lá cây.
Nhấp vào hình ảnh đầu tiên bạn có thể thấy giao diện người dùng này. Sau khi nhìn thấy điều này, hãy nhấp vào tùy chọn chú thích thủ công.
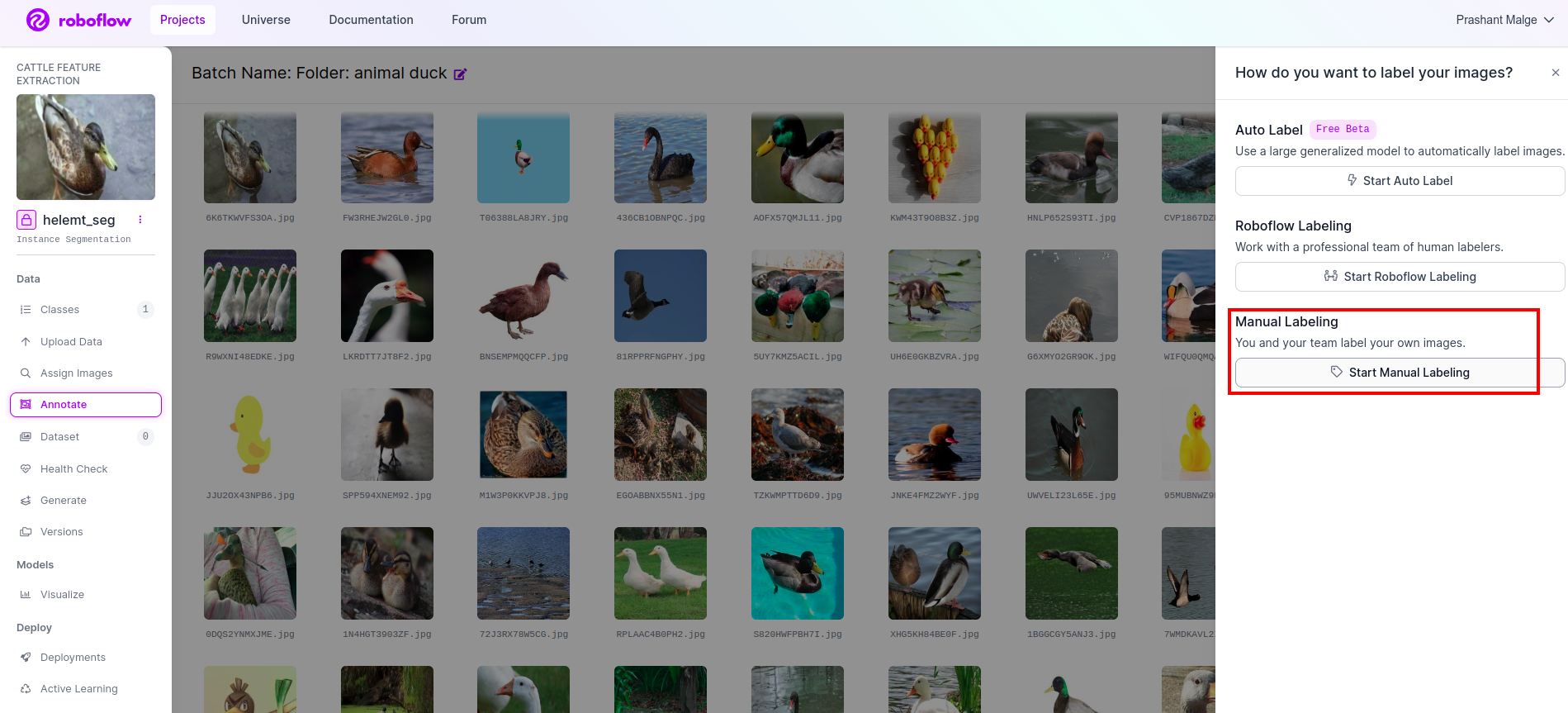
Sau đó thêm id email của bạn hoặc tên đồng đội của bạn để bạn có thể giao nhiệm vụ.
Nhấp vào hình ảnh đầu tiên bạn có thể thấy giao diện người dùng này. Ở đây bấm vào ô màu đỏ để bạn có thể chọn mô hình đa đa thức.
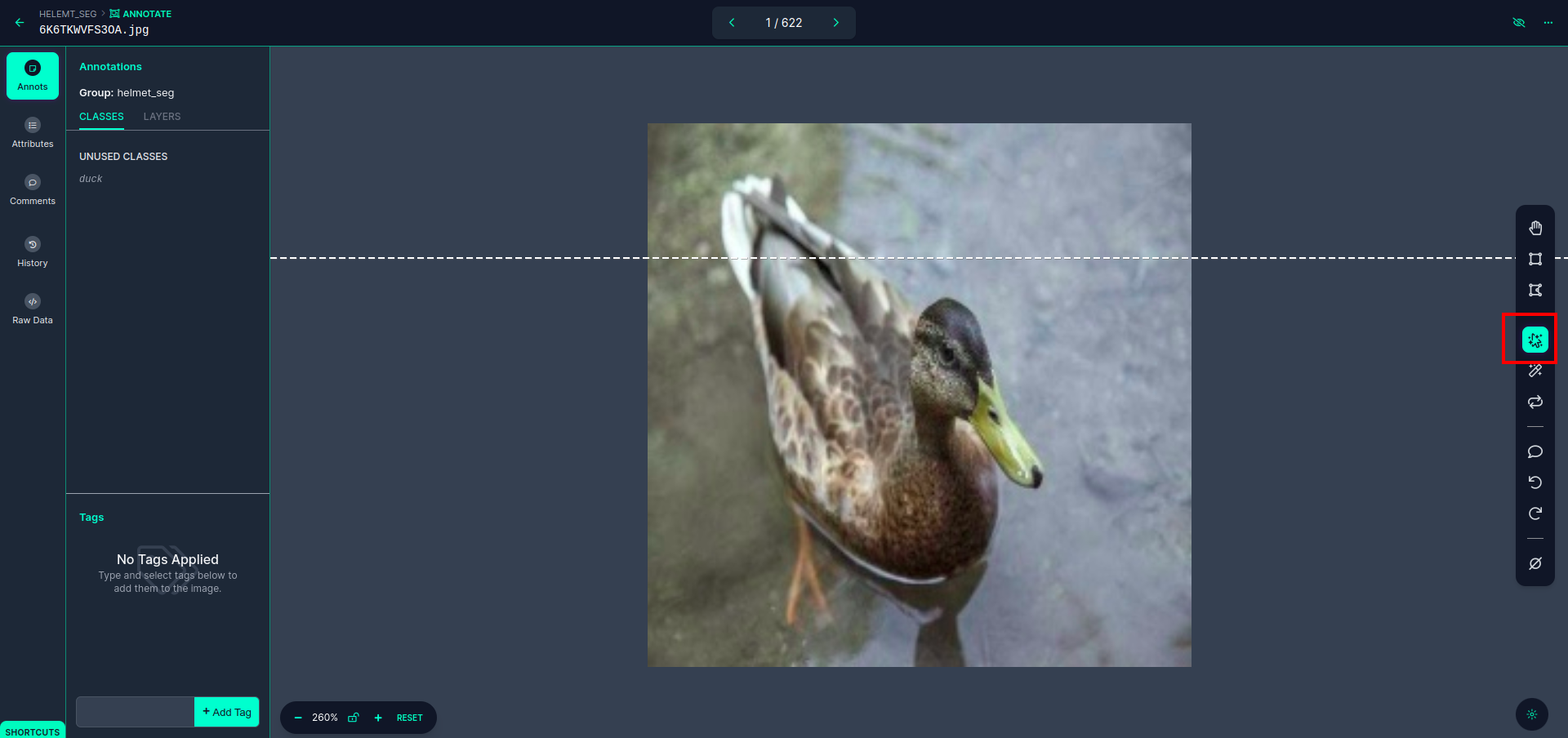
Sau khi nhấn vào ô màu đỏ, chọn mô hình mặc định và nhấn vào đối tượng con vịt. Điều này sẽ tự động phân đoạn hình ảnh. Sau đó, nhấp vào phần tiếp theo và lưu nó. Sau đó, bạn sẽ thấy phía bên trái được đánh dấu trong hộp màu đỏ, nơi bạn có thể thấy tên lớp.
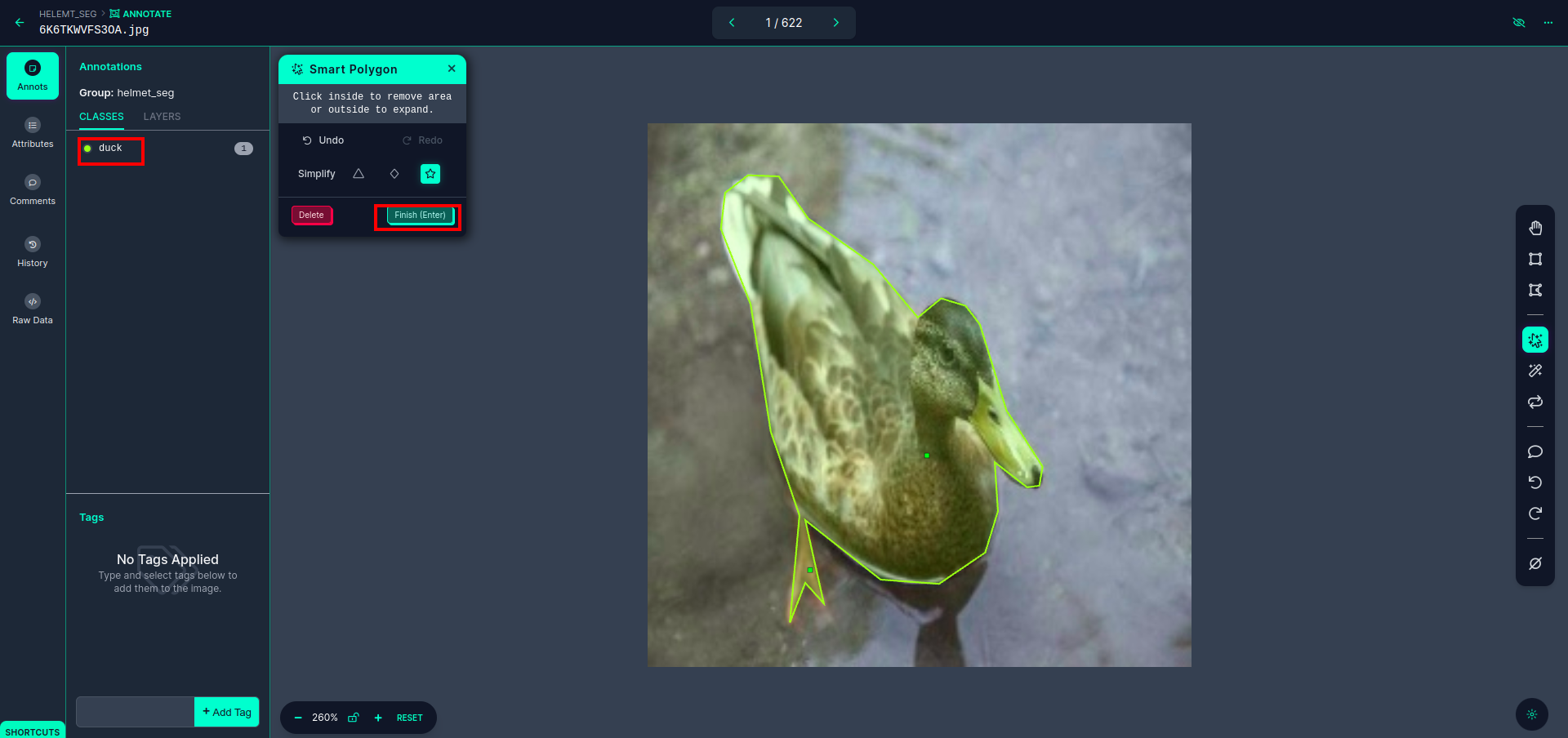
Nhấn vào lưu và nhập lựa chọn. chú thích tất cả các hình ảnh.
Thêm hình ảnh cho định dạng YOLOv8. Ở bên phải bạn sẽ thấy tùy chọn thêm hình ảnh vào phần chú thích. Ở đây, hai phần được tạo: một phần dành cho hình ảnh có chú thích và một phần dành cho hình ảnh không có chú thích.
- Đầu tiên, nhấp vào bên trái “chú thích” tùy chọn sau đó thêm vào những hình ảnh vào tập dữ liệu.
- Sau đó nhấp vào tiếp theo “Thêm hình ảnh".
Cuối cùng, chúng ta tạo tập dữ liệu, vì vậy hãy nhấp vào tùy chọn “Tạo” ở phía bên trái, sau đó chọn tùy chọn và nhấn tùy chọn conitune.
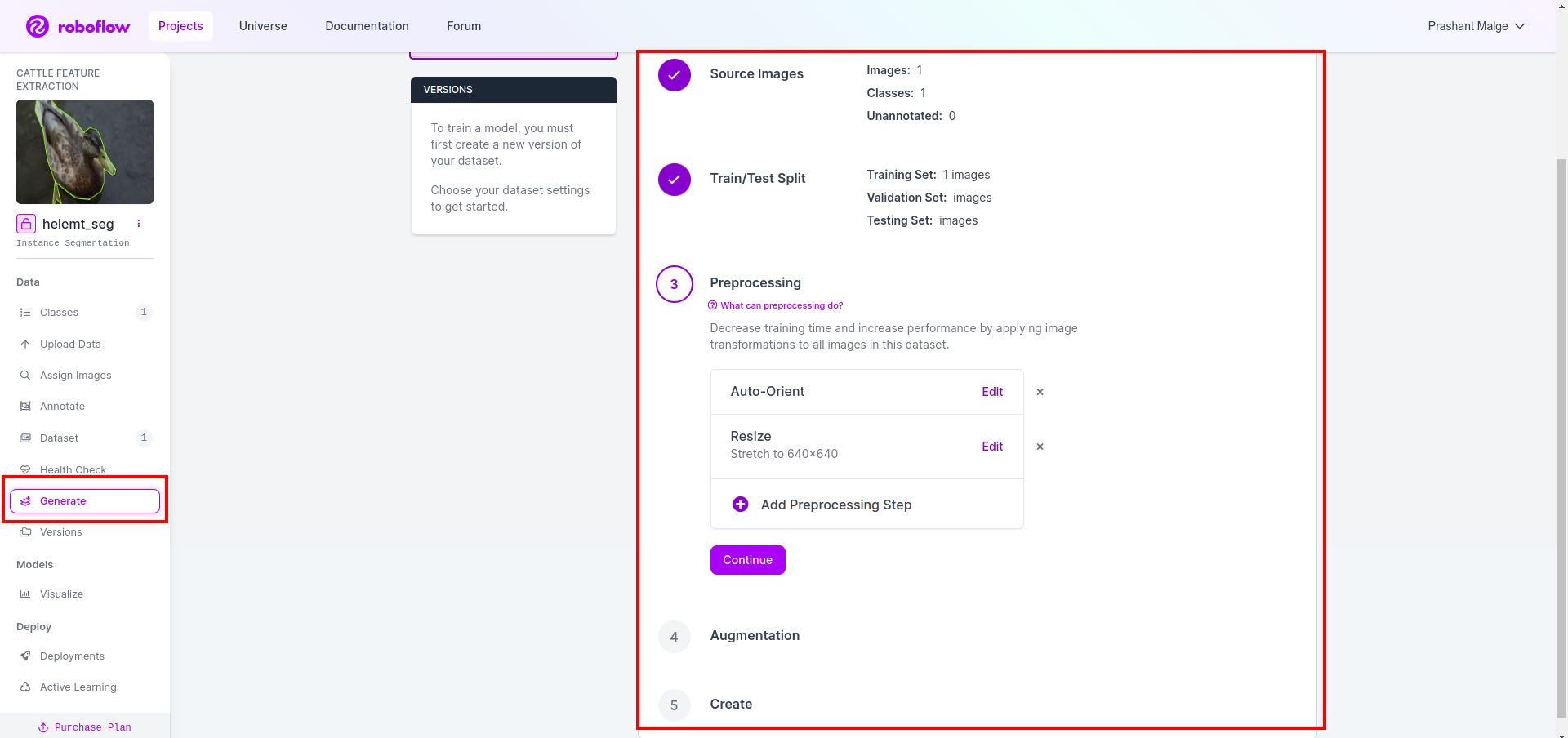
Sau đó, bạn nhận được giao diện người dùng của tùy chọn phân chia tập dữ liệu tại đây, bạn có thể kiểm tra các thư mục huấn luyện, kiểm tra và val mà hình ảnh của chúng tự động phân chia. và bấm vào ô màu đỏ ở trên Tùy chọn xuất tập dữ liệu và tải xuống tệp zip. cấu trúc thư mục tệp zip giống như…
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Bước 6: Viết script huấn luyện mô hình phân đoạn ảnh
Trong phần này trước tiên, bạn tạo tệp Google Collab bằng Drive, sau đó tải tập dữ liệu của mình lên. và điều hướng Google Drive bằng Google Collab.
1. Sử dụng lệnh này cho Gắn Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Xác định thư mục dữ liệu Sử dụng biến Hằng.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Cài đặt gói cần thiết, Cài đặt siêu phân tích
!pip install ultralytics4. Nhập thư viện
import os
from ultralytics import YOLO5. Tải YOLOv8 được đào tạo trước mô hình (ở đây chúng tôi có mô hình khác, đồng thời kiểm tra tài liệu chính thức ở đó bạn có thể thấy mô hình khác)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Đào tạo người mẫu
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Không kiểm tra ổ đĩa của bạn Thư mục tên mô hình được tạo và mô hình đó được lưu để dự đoán mà chúng tôi muốn mô hình này.
7. Dự đoán mô hình
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Tại đây bạn có thể thấy hình ảnh phân đoạn đã được lưu.

Bây giờ cuối cùng chúng ta có thể xây dựng cả mô hình phát hiện trực tiếp và phân đoạn hình ảnh.
Kết luận
Trong blog này, chúng tôi khám phá tính năng phát hiện đối tượng trực tiếp và phân đoạn hình ảnh bằng YOLOv8. Để phát hiện trực tiếp, chúng tôi nhập mô hình YOLOv8 được đào tạo trước và sử dụng thư viện thị giác máy tính, OpenCV, để mở camera và phát hiện vật thể. Ngoài ra, chúng tôi tạo ứng dụng Streamlit để có giao diện người dùng hấp dẫn.
Tiếp theo, chúng ta đi sâu vào phân đoạn hình ảnh bằng YOLOv8. Chúng tôi nhập mô hình được đào tạo trước và thực hiện học chuyển giao trên tập dữ liệu tùy chỉnh. Trước đó, chúng tôi đã khám phá Roboflow để chú thích tập dữ liệu, cung cấp giải pháp thay thế dễ sử dụng cho các công cụ như NhãnImg.
Cuối cùng, chúng ta dự đoán một hình ảnh có con vịt. Mặc dù đối tượng trong ảnh có vẻ là một con chim nhưng chúng tôi chỉ định tên lớp là “đẩy xuống nước” nhằm mục đích trình diễn.
Chìa khóa chính
- Tìm hiểu về các mô hình phát hiện đối tượng như Faster R-CNN, SSD và YOLOv8 mới nhất.
- Tìm hiểu công cụ chú thích Roboflow và vai trò của nó trong việc tạo bộ dữ liệu cho các mô hình phân đoạn YOLOv8.
- Khám phá tính năng phát hiện đối tượng trực tiếp bằng OpenCV (cv2) và Giám sát, nâng cao kỹ năng thực tế.
- Đào tạo và triển khai mô hình phân khúc sử dụng YOLOv8, tích lũy kinh nghiệm thực tế.
Những câu hỏi thường gặp
A. Phát hiện đối tượng liên quan đến việc xác định và định vị nhiều đối tượng trong một hình ảnh, thường bằng cách vẽ các hộp giới hạn xung quanh chúng. Mặt khác, phân đoạn hình ảnh sẽ chia hình ảnh thành các phân đoạn hoặc vùng dựa trên độ tương tự của pixel, cung cấp hiểu biết chi tiết hơn về ranh giới đối tượng.
A. YOLOv8 cải tiến so với các phiên bản trước bằng cách kết hợp những tiến bộ trong kiến trúc mạng, kỹ thuật đào tạo và tối ưu hóa. Nó có thể mang lại độ chính xác, tốc độ và hiệu quả tốt hơn so với YOLOv3.
A. YOLOv8 có thể được sử dụng để phát hiện đối tượng theo thời gian thực trên các thiết bị nhúng, tùy thuộc vào khả năng phần cứng và tối ưu hóa mô hình. Tuy nhiên, nó có thể yêu cầu tối ưu hóa như cắt bớt mô hình hoặc lượng tử hóa để đạt được hiệu suất thời gian thực trên các thiết bị bị hạn chế về tài nguyên.
Đáp: Roboflow cung cấp các công cụ chú thích trực quan, tính năng quản lý tập dữ liệu và hỗ trợ nhiều định dạng chú thích khác nhau. Nó hợp lý hóa quy trình chú thích, cho phép cộng tác và cung cấp khả năng kiểm soát phiên bản, giúp tạo và quản lý bộ dữ liệu cho các dự án thị giác máy tính dễ dàng hơn.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

