Khi doanh nghiệp mở rộng, nhu cầu về địa chỉ IP trong mạng công ty thường vượt quá nguồn cung. Mạng của một tổ chức thường được thiết kế với một số yêu cầu dự kiến trong tương lai, nhưng khi doanh nghiệp phát triển, nhu cầu về công nghệ thông tin (CNTT) của họ sẽ vượt xa mạng được thiết kế trước đó. Các công ty có thể thấy mình gặp khó khăn trong việc quản lý nhóm địa chỉ IP hạn chế.
Đối với khối lượng công việc kỹ thuật dữ liệu khi Keo AWS được sử dụng trong cấu hình mạng hạn chế như vậy, nhóm của bạn đôi khi có thể gặp phải trở ngại khi thực hiện nhiều công việc cùng lúc. Điều này xảy ra vì bạn có thể không có đủ địa chỉ IP để hỗ trợ các kết nối cần thiết tới cơ sở dữ liệu. Để khắc phục tình trạng thiếu hụt này, nhóm có thể lấy thêm địa chỉ IP từ nhóm mạng công ty của bạn. Các địa chỉ IP thu được này có thể là duy nhất (không chồng chéo) hoặc chồng chéo khi địa chỉ IP được sử dụng lại trong mạng công ty của bạn.
Khi bạn sử dụng các địa chỉ IP chồng chéo, bạn cần có sự quản lý mạng bổ sung để thiết lập kết nối. Giải pháp mạng có thể bao gồm các tùy chọn như cổng dịch địa chỉ mạng riêng (NAT), Liên kết riêng AWShoặc các thiết bị NAT tự quản lý để dịch địa chỉ IP.
Trong bài đăng này, chúng ta sẽ thảo luận về hai chiến lược để mở rộng quy mô công việc AWS Glue:
- Tối ưu hóa mức tiêu thụ địa chỉ IP bằng cách định cỡ phù hợp cho Đơn vị xử lý dữ liệu (DPU), sử dụng tính năng Tự động chia tỷ lệ của AWS Glue và tinh chỉnh công việc.
- Mở rộng dung lượng mạng bằng cách sử dụng phạm vi Định tuyến liên miền không phân loại (CIDR) không thể định tuyến bổ sung với cổng NAT riêng.
Trước khi đi sâu vào các giải pháp này, hãy cùng chúng tôi tìm hiểu cách AWS Glue sử dụng Giao diện mạng đàn hồi (ENI) để thiết lập kết nối. Để cho phép truy cập vào kho lưu trữ dữ liệu bên trong VPC, bạn cần tạo kết nối AWS Glue được gắn vào VPC của bạn. Khi tác vụ AWS Glue chạy trong VPC của bạn, tác vụ đó sẽ tạo ENI bên trong VPC đã định cấu hình cho mỗi kết nối dữ liệu và ENI đó sử dụng địa chỉ IP trong VPC được chỉ định. Các ENI này tồn tại trong thời gian ngắn và hoạt động cho đến khi công việc hoàn tất.
Bây giờ chúng ta hãy xem giải pháp đầu tiên giải thích việc tối ưu hóa mức tiêu thụ địa chỉ IP AWS Glue.
Chiến lược sử dụng địa chỉ IP hiệu quả
Trong AWS Glue, số lượng công nhân mà một công việc sử dụng sẽ xác định số lượng địa chỉ IP được sử dụng từ mạng con VPC của bạn. Điều này là do mỗi nhân viên yêu cầu một địa chỉ IP ánh xạ tới một ENI. Khi không phân bổ đủ phạm vi CIDR cho mạng con AWS Glue, bạn có thể gặp lỗi cạn kiệt địa chỉ IP. Sau đây là một số phương pháp hay nhất để tối ưu hóa mức tiêu thụ địa chỉ IP AWS Glue:
- Định cỡ phù hợp DPU của công việc – AWS Glue là một công cụ xử lý phân tán. Nó hoạt động hiệu quả khi có thể chạy các tác vụ song song. Nếu một công việc có nhiều hơn số DPU cần thiết thì không phải lúc nào công việc cũng chạy nhanh hơn. Vì vậy, việc tìm đúng số lượng DPU sẽ đảm bảo bạn sử dụng địa chỉ IP một cách tối ưu. Bằng cách xây dựng khả năng quan sát trong hệ thống và phân tích hiệu suất công việc, bạn có thể hiểu rõ hơn về xu hướng tiêu thụ ENI và sau đó định cấu hình năng lực phù hợp cho công việc với quy mô phù hợp. Để biết thêm chi tiết, hãy tham khảo Giám sát lập kế hoạch năng lực DPU. Giao diện người dùng Spark là một công cụ hữu ích để giám sát việc sử dụng công việc của nhân viên AWS Glue. Để biết thêm chi tiết, hãy tham khảo Giám sát công việc bằng giao diện người dùng web Apache Spark.
- AWS Glue Auto Scaling – Thường rất khó để dự đoán trước yêu cầu về năng lực của công việc. Việc kích hoạt tính năng Auto Scaling của AWS Glue sẽ chuyển một phần trách nhiệm này sang AWS. Trong thời gian chạy dựa trên yêu cầu khối lượng công việc, công việc sẽ tự động điều chỉnh quy mô các nút công nhân theo cấu hình tối đa đã xác định. Nếu không có nhu cầu bổ sung, AWS Glue sẽ không cung cấp thừa nhân công, từ đó tiết kiệm tài nguyên và giảm chi phí. Tính năng Auto Scaling có sẵn trong AWS Glue 3.0 trở lên. Để biết thêm thông tin, hãy tham khảo Giới thiệu AWS Glue Auto Scaling: Tự động thay đổi kích thước tài nguyên máy tính không máy chủ để có chi phí thấp hơn với Apache Spark được tối ưu hóa.
- Tối ưu hóa cấp độ công việc – Xác định tối ưu hóa cấp độ công việc bằng cách sử dụng Chỉ số công việc của AWS Glue và áp dụng các phương pháp hay nhất từ Các phương pháp hay nhất để điều chỉnh hiệu suất AWS Glue cho công việc Apache Spark.
Tiếp theo chúng ta hãy xem xét giải pháp thứ hai giúp nâng cao dung lượng mạng.
Giải pháp mở rộng quy mô mạng (địa chỉ IP)
Trong phần này, chúng ta sẽ thảo luận chi tiết hơn về hai giải pháp khả thi để mở rộng quy mô mạng.
Mở rộng phạm vi VPC CIDR bằng các địa chỉ có thể định tuyến
Một giải pháp là bổ sung thêm nhiều phạm vi CIDR IPv4 riêng tư từ RFC 1918 tới VPC của bạn. Về mặt lý thuyết, mỗi tài khoản AWS có thể được gán cho một số hoặc tất cả các CIDR địa chỉ IP này. Nhóm Quản lý địa chỉ IP (IPAM) của bạn thường quản lý việc phân bổ địa chỉ IP mà mỗi đơn vị kinh doanh có thể sử dụng từ RFC1918 để tránh trùng lặp địa chỉ IP trên nhiều tài khoản AWS hoặc đơn vị kinh doanh. Nếu hạn mức địa chỉ IP có thể định tuyến hiện tại do nhóm IPAM phân bổ không đủ thì bạn có thể yêu cầu thêm.
Nếu nhóm IPAM cấp cho bạn một phạm vi CIDR không chồng chéo bổ sung thì bạn có thể thêm phạm vi đó làm CIDR phụ cho VPC hiện tại của mình hoặc tạo một VPC mới với phạm vi đó. Nếu bạn dự định tạo một VPC mới thì bạn có thể kết nối các VPC với nhau thông qua VPC ngang hàng or Cổng chuyển tuyến AWS.
Nếu công suất bổ sung này đủ để thực hiện tất cả công việc của bạn trong khung thời gian xác định thì đó là một giải pháp đơn giản và tiết kiệm chi phí. Mặt khác, bạn có thể xem xét áp dụng các địa chỉ IP chồng chéo với cổng NAT riêng, như được mô tả trong phần sau. Với giải pháp sau, bạn phải sử dụng Transit Gateway để kết nối các VPC vì không thể kết nối VPC ngang hàng khi có phạm vi CIDR chồng chéo trong hai VPC đó.
Định cấu hình CIDR không thể định tuyến bằng cổng NAT riêng
Như được mô tả trong báo cáo nghiên cứu chuyên sâu của AWS Xây dựng cơ sở hạ tầng mạng AWS đa VPC an toàn và có thể mở rộng, bạn có thể mở rộng dung lượng mạng của mình bằng cách tạo mạng con địa chỉ IP không thể định tuyến và sử dụng cổng NAT riêng nằm trong không gian địa chỉ IP có thể định tuyến (không chồng chéo) để định tuyến lưu lượng. Cổng NAT riêng dịch và định tuyến lưu lượng giữa các địa chỉ IP không thể định tuyến và địa chỉ IP có thể định tuyến. Sơ đồ sau đây minh họa giải pháp có tham chiếu đến AWS Glue.
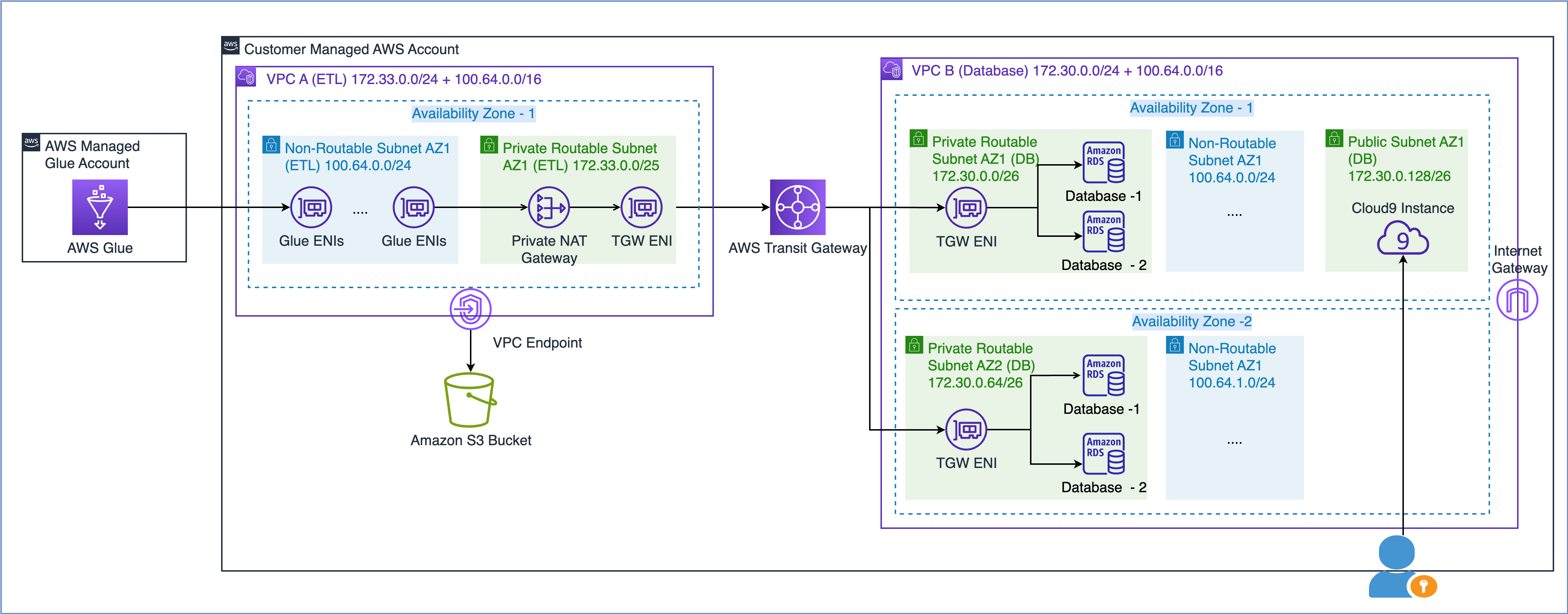
Như bạn có thể thấy trong sơ đồ trên, VPC A (ETL) có hai phạm vi CIDR được đính kèm. Phạm vi CIDR nhỏ hơn 172.33.0.0/24 có thể định tuyến được vì nó không được sử dụng lại ở bất kỳ đâu, trong khi phạm vi CIDR lớn hơn 100.64.0.0/16 không thể định tuyến được vì nó được sử dụng lại trong cơ sở dữ liệu VPC.
Trong VPC B (Cơ sở dữ liệu), chúng tôi đã lưu trữ hai cơ sở dữ liệu trong các mạng con có thể định tuyến 172.30.0.0/26 và 172.30.0.64/26. Hai mạng con này nằm trong hai Vùng sẵn sàng riêng biệt để có tính sẵn sàng cao. Chúng tôi cũng có thêm hai mạng con chưa sử dụng là 100.64.0.0/24 và 100.64.1.0/24 để mô phỏng thiết lập không thể định tuyến.
Bạn có thể chọn kích thước của phạm vi CIDR không thể định tuyến dựa trên yêu cầu về dung lượng của bạn. Vì bạn có thể sử dụng lại địa chỉ IP nên bạn có thể tạo một mạng con rất lớn nếu cần. Ví dụ: mặt nạ CIDR /16 sẽ cung cấp cho bạn khoảng 65,000 địa chỉ IPv4. Bạn có thể làm việc với nhóm kỹ thuật mạng của mình và xác định kích thước mạng con.
Nói tóm lại, bạn có thể định cấu hình các tác vụ AWS Glue để sử dụng cả mạng con có thể định tuyến và không thể định tuyến trong VPC của mình nhằm tối đa hóa nhóm địa chỉ IP có sẵn.
Bây giờ, hãy cùng chúng tôi tìm hiểu cách các ENI của Glue nằm trong mạng con không thể định tuyến giao tiếp với các nguồn dữ liệu trong một VPC khác.
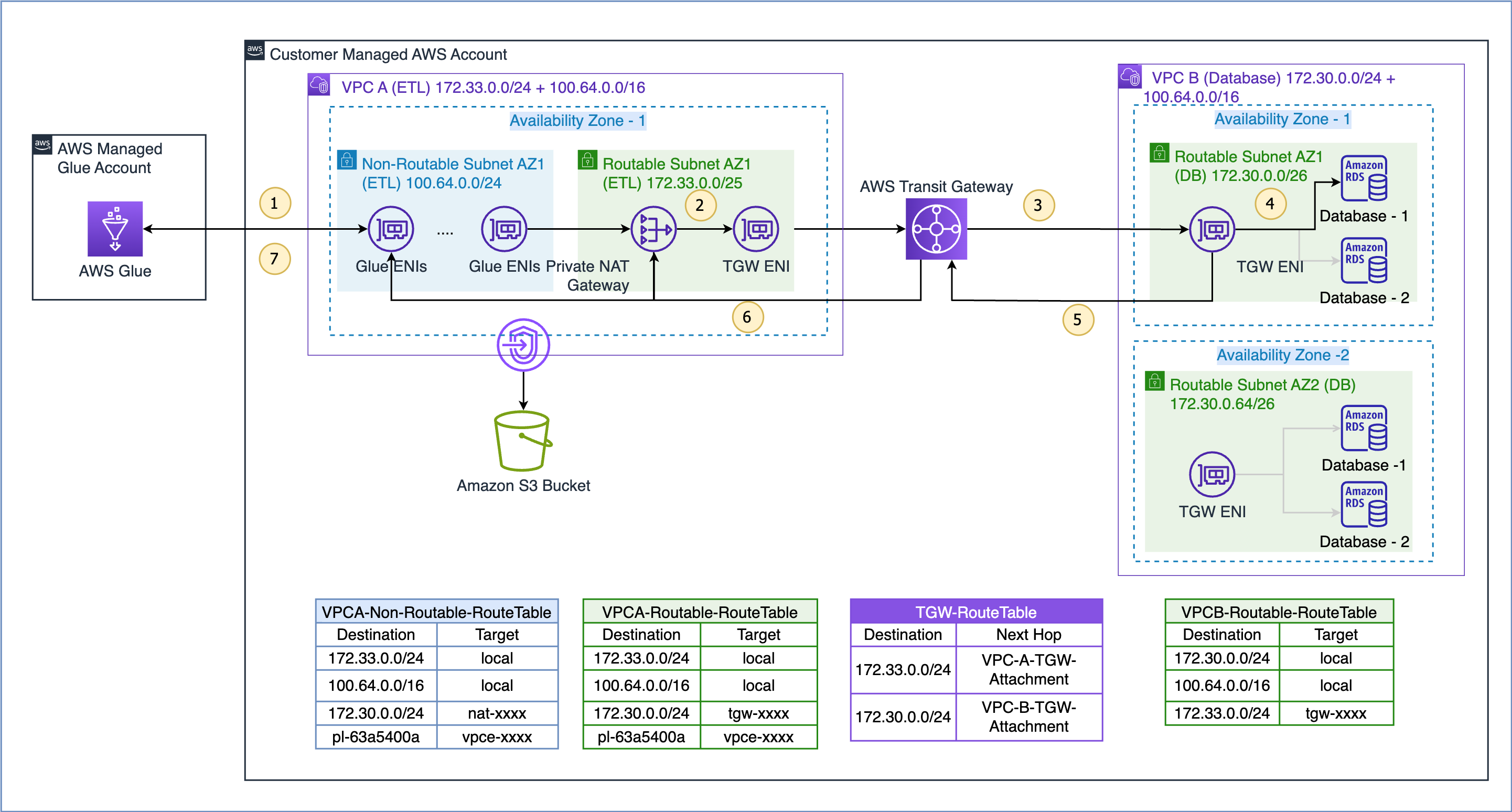
Luồng dữ liệu cho trường hợp sử dụng được trình bày ở đây như sau (tham khảo các bước được đánh số trong hình trên):
- Khi một tác vụ AWS Glue cần truy cập vào nguồn dữ liệu, trước tiên tác vụ đó sẽ sử dụng kết nối AWS Glue trong tác vụ đó và tạo ENI trong mạng con không thể định tuyến 100.64.0.0/24 trong VPC A. Sau đó, AWS Glue sử dụng cấu hình kết nối cơ sở dữ liệu và cố gắng kết nối với cơ sở dữ liệu trong VPC B 172.30.0.0/24.
- Theo bảng lộ trình
VPCA-Non-Routable-RouteTableđích 172.30.0.0/24 được định cấu hình cho cổng NAT riêng. Yêu cầu được gửi đến cổng NAT, sau đó chuyển địa chỉ IP nguồn từ địa chỉ IP không thể định tuyến sang địa chỉ IP có thể định tuyến. Sau đó, lưu lượng được gửi đến phần đính kèm cổng chuyển tuyến trong VPC A vì nó được liên kết vớiVPCA-Routable-RouteTablebảng định tuyến trong VPC A. - Transit Gateway sử dụng tuyến 172.30.0.0/24 và gửi lưu lượng đến phần đính kèm cổng chuyển tiếp VPC B.
- Cổng chuyển tiếp ENI trong VPC B sử dụng tuyến cục bộ của VPC B để kết nối với điểm cuối cơ sở dữ liệu và truy vấn dữ liệu.
- Khi truy vấn hoàn tất, phản hồi sẽ được gửi trở lại VPC A. Lưu lượng phản hồi được định tuyến đến phần đính kèm cổng chuyển tiếp trong VPC B, sau đó Transit Gateway sử dụng tuyến 172.33.0.0/24 và gửi lưu lượng truy cập đến phần đính kèm cổng chuyển tiếp VPC A .
- Cổng chuyển tuyến ENI trong VPC A sử dụng tuyến cục bộ để chuyển tiếp lưu lượng đến cổng NAT riêng, cổng này chuyển địa chỉ IP đích sang địa chỉ ENI trong mạng con không thể định tuyến.
- Cuối cùng, tác vụ AWS Glue nhận dữ liệu và tiếp tục xử lý.
Giải pháp cổng NAT riêng là một tùy chọn nếu bạn cần thêm địa chỉ IP khi không thể lấy chúng từ mạng có thể định tuyến trong tổ chức của mình. Đôi khi, mỗi dịch vụ bổ sung sẽ phát sinh thêm chi phí và sự đánh đổi này là cần thiết để đáp ứng mục tiêu của bạn. Tham khảo phần giá NAT Gateway trên Trang định giá Amazon VPC để biết thêm thông tin chi tiết.
Điều kiện tiên quyết
Để hoàn tất quá trình hướng dẫn giải pháp cổng NAT riêng, bạn cần có những điều sau:
Triển khai giải pháp
Để thực hiện giải pháp, hãy hoàn thành các bước sau:
- Đăng nhập vào bảng điều khiển quản lý AWS của bạn.
- Triển khai giải pháp bằng cách nhấp vào
 . Ngăn xếp này mặc định là
. Ngăn xếp này mặc định là us-east-1, bạn có thể chọn Khu vực mong muốn của mình. - Nhấp chuột tiếp theo và sau đó chỉ định chi tiết ngăn xếp. Bạn có thể giữ lại các tham số đầu vào về giá trị mặc định được điền trước hoặc thay đổi chúng nếu cần.
- Trong
DatabaseUserPassword, nhập mật khẩu chữ và số mà bạn chọn và đảm bảo ghi lại mật khẩu đó để sử dụng tiếp. - Trong
S3BucketName, nhập một giá trị duy nhất Dịch vụ lưu trữ đơn giản của Amazon Tên nhóm (Amazon S3). Nhóm này lưu trữ tập lệnh công việc AWS Glue sẽ được sao chép từ kho lưu trữ mã công khai AWS.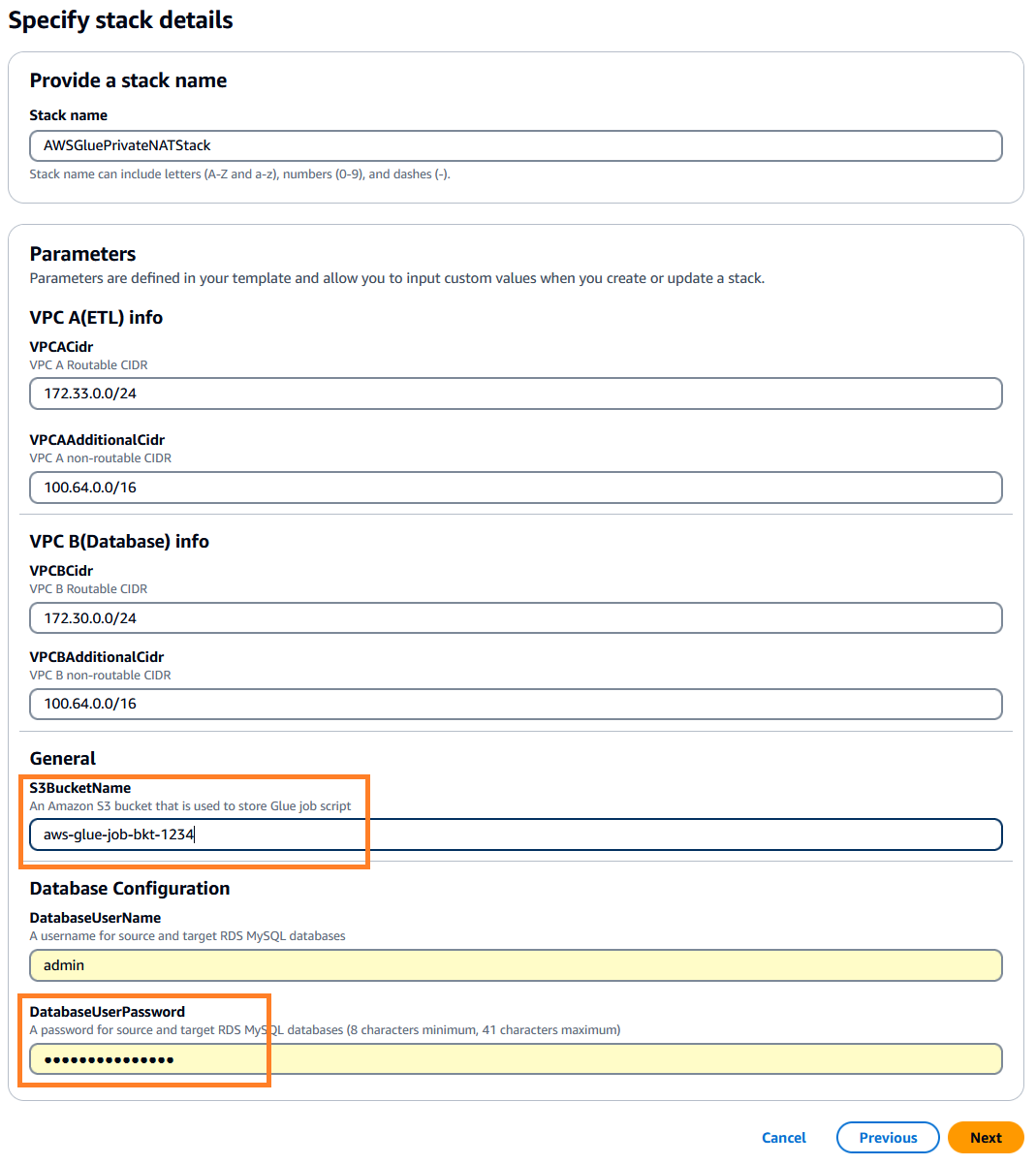
- Nhấp chuột tiếp theo.
- Để lại các giá trị mặc định và nhấp vào tiếp theo một lần nữa.
- Xem lại chi tiết, xác nhận việc tạo tài nguyên IAM và nhấp vào trình để bắt đầu triển khai.
Bạn có thể theo dõi các sự kiện để xem tài nguyên được tạo trên bảng điều khiển AWS CloudFormation. Có thể mất khoảng 20 phút để tạo tài nguyên ngăn xếp.
Sau khi quá trình tạo ngăn xếp hoàn tất, hãy chuyển đến tab Đầu ra trên bảng điều khiển AWS CloudFormation và lưu ý các giá trị sau để sử dụng sau:
DBSourceDBTargetSourceCrawlerTargetCrawler
Kết nối với phiên bản AWS Cloud9
Tiếp theo, chúng ta cần chuẩn bị bảng Amazon RDS for MySQL nguồn và đích bằng cách sử dụng một Đám mây AWS9 ví dụ. Hoàn thành các bước sau:
- Trên trang bảng điều khiển AWS Cloud9, tìm vị trí
aws-glue-cloud9môi trường. - Trong cột Cloud9 IDE, nhấp vào Mở để khởi chạy phiên bản AWS Cloud9 của bạn trong trình duyệt web mới.
Chuẩn bị bảng MySQL nguồn
Hoàn thành các bước sau để chuẩn bị bảng nguồn của bạn:
- Từ thiết bị đầu cuối AWS Cloud9, cài đặt máy khách MySQL bằng lệnh sau:
sudo yum update -y && sudo yum install -y mysql - Kết nối với cơ sở dữ liệu nguồn bằng lệnh sau. Thay thế tên máy chủ nguồn bằng giá trị DBSource mà bạn đã chụp trước đó. Khi được nhắc, hãy nhập mật khẩu cơ sở dữ liệu mà bạn đã chỉ định trong quá trình tạo ngăn xếp.
mysql -h <Source Hostname> -P 3306 -u admin -p - Chạy các đoạn script sau để tạo nguồn
empbảng và tải dữ liệu thử nghiệm:-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - Kiểm tra nguồn
empsố lượng bảng bằng cách sử dụng truy vấn SQL bên dưới (bạn cần điều này ở bước sau để xác minh).select count(*) from emp; - Chạy lệnh sau để thoát khỏi tiện ích máy khách MySQL và quay lại thiết bị đầu cuối của phiên bản AWS Cloud9:
quit;
Chuẩn bị bảng MySQL mục tiêu
Hoàn thành các bước sau để chuẩn bị bảng mục tiêu:
- Kết nối với cơ sở dữ liệu đích bằng lệnh sau. Thay thế tên máy chủ đích bằng giá trị DTarget mà bạn đã chụp trước đó. Khi được nhắc, hãy nhập mật khẩu cơ sở dữ liệu mà bạn đã chỉ định trong quá trình tạo ngăn xếp.
mysql -h <Target Hostname> -P 3306 -u admin -p - Chạy các đoạn script sau để tạo mục tiêu
empbàn. Bảng này sẽ được tác vụ AWS Glue tải ở bước tiếp theo.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
Xác minh thiết lập mạng (Tùy chọn)
Các bước sau đây rất hữu ích để hiểu cổng NAT, bảng lộ trình và cấu hình cổng chuyển tuyến của giải pháp cổng NAT riêng. Các thành phần này được tạo trong quá trình tạo ngăn xếp CloudFormation.
- Trên trang bảng điều khiển Amazon VPC, điều hướng đến phần Đám mây riêng ảo và tìm cổng NAT.
- Tìm kiếm NAT Gateway có tên
Glue-OverlappingCIDR-NATGWvà khám phá nó sâu hơn. Như bạn có thể thấy trong ảnh chụp màn hình sau, cổng NAT đã được tạo trong VPC A (ETL) trên mạng con có thể định tuyến.
- Trong ngăn điều hướng bên trái, điều hướng đến Định tuyến bảng trong phần Đám mây riêng ảo.
- Tìm kiếm
VPCA-Non-Routable-RouteTablevà khám phá nó sâu hơn. Bạn có thể thấy rằng bảng định tuyến được định cấu hình để dịch lưu lượng truy cập từ CIDR chồng chéo bằng cổng NAT.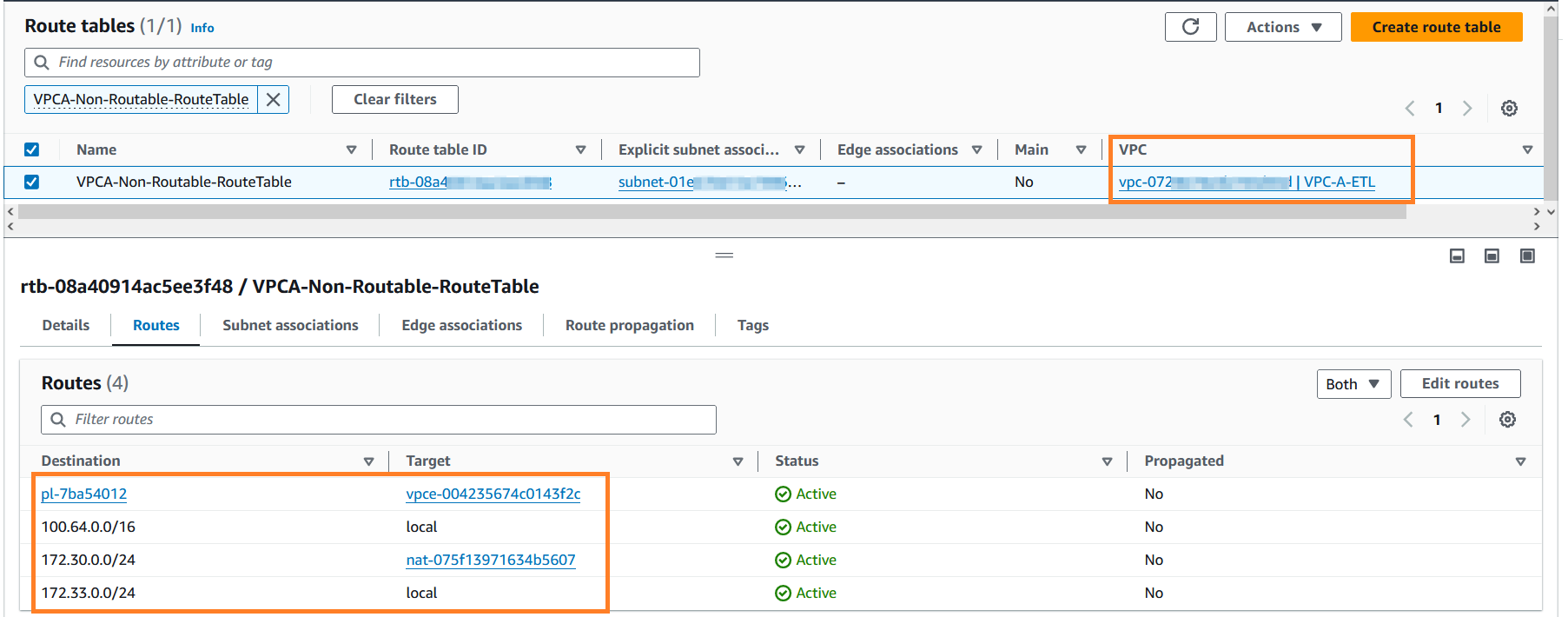
- Trong ngăn điều hướng bên trái, điều hướng đến phần Cổng chuyển tuyến và nhấp vào Tệp đính kèm cổng chuyển tuyến. Đi vào
VPC-vào hộp tìm kiếm và định vị hai tệp đính kèm cổng chuyển tuyến mới được tạo. - Bạn có thể khám phá thêm các tệp đính kèm này để tìm hiểu cấu hình của chúng.
Chạy trình thu thập thông tin AWS Glue
Hoàn thành các bước sau để chạy trình thu thập thông tin AWS Glue cần thiết để lập danh mục nguồn và đích emp những cái bàn. Đây là bước tiên quyết để chạy tác vụ AWS Glue.
- Trên trang Bảng điều khiển AWS Glue, trong phần Danh mục dữ liệu trong ngăn điều hướng, nhấp vào Trình thu thập thông tin.
- Xác định vị trí các trình thu thập thông tin nguồn và đích mà bạn đã lưu ý trước đó.
- Chọn các trình thu thập thông tin này và nhấp vào chạy để tạo các bảng Danh mục dữ liệu AWS Glue tương ứng.
- Bạn có thể giám sát trình thu thập thông tin của AWS Glue để hoàn thành thành công. Có thể mất khoảng 3–4 phút để cả hai trình thu thập thông tin hoàn tất. Khi hoàn tất, trạng thái lần chạy cuối cùng của công việc sẽ chuyển thành Thành công và bạn cũng có thể thấy có hai bảng danh mục AWS Glue được tạo từ lần chạy này.

Chạy tác vụ AWS Glue ETL
Sau khi thiết lập các bảng và hoàn thành các bước tiên quyết, giờ đây bạn đã sẵn sàng chạy tác vụ AWS Glue mà bạn đã tạo bằng mẫu CloudFormation. Công việc này kết nối với RDS nguồn cho cơ sở dữ liệu MySQL, trích xuất dữ liệu và tải dữ liệu vào cơ sở dữ liệu RDS cho MySQL đích. Công việc này đọc dữ liệu từ bảng MySQL nguồn và tải nó vào bảng MySQL đích bằng giải pháp cổng NAT riêng. Để chạy tác vụ AWS Glue, hãy hoàn thành các bước sau:
- Trên bảng điều khiển AWS Glue, nhấp vào công việc ETL trong khung điều hướng.
- Bấm vào công việc
glue-private-nat-job. - Nhấp chuột chạy để bắt đầu nó.
Sau đây là tập lệnh PySpark cho công việc ETL này:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
Dựa trên cấu hình DPU của công việc, AWS Glue tạo một tập hợp ENI trong mạng con không thể định tuyến được định cấu hình trên kết nối AWS Glue. Bạn có thể giám sát các ENI này trên trang Giao diện Mạng của Đám mây điện toán đàn hồi Amazon (Amazon EC2) bảng điều khiển.
Ảnh chụp màn hình bên dưới hiển thị 10 ENI đã được tạo để chạy công việc để khớp với số lượng công nhân được yêu cầu được định cấu hình trên các tham số công việc. Đúng như dự đoán, ENI đã được tạo trong mạng con không thể định tuyến của VPC A, cho phép mở rộng địa chỉ IP. Sau khi công việc hoàn tất, các ENI này sẽ được AWS Glue tự động giải phóng.
Khi tác vụ AWS Glue đang chạy, bạn có thể theo dõi trạng thái của tác vụ đó. Sau khi hoàn thành thành công, trạng thái của công việc sẽ thay đổi thành Kế nhiệm.
Xác minh kết quả
Sau khi công việc AWS Glue hoàn tất, hãy kết nối với cơ sở dữ liệu MySQL mục tiêu. Xác minh xem số lượng bản ghi mục tiêu có khớp với nguồn hay không. Bạn có thể sử dụng truy vấn SQL bên dưới trong thiết bị đầu cuối AWS Cloud9.
USE targetdb;
SELECT count(*) from emp;Cuối cùng, thoát khỏi tiện ích máy khách MySQL bằng lệnh sau và quay lại thiết bị đầu cuối AWS Cloud9: quit;
Giờ đây, bạn có thể xác nhận rằng AWS Glue đã hoàn thành thành công công việc tải dữ liệu vào cơ sở dữ liệu đích bằng cách sử dụng địa chỉ IP từ mạng con không thể định tuyến. Điều này kết thúc việc thử nghiệm từ đầu đến cuối giải pháp cổng NAT riêng.
Làm sạch
Để tránh phát sinh phí trong tương lai, hãy xóa tài nguyên được tạo qua ngăn xếp CloudFormation bằng cách hoàn thành các bước sau:
- Trên bảng điều khiển AWS CloudFormation, nhấp vào Ngăn xếp trong ngăn điều hướng.
- Chọn ngăn xếp
AWSGluePrivateNATStack. - Bấm vào Xóa để xóa ngăn xếp. Khi được nhắc xác nhận việc xóa ngăn xếp.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách bạn có thể mở rộng quy mô công việc AWS Glue bằng cách tối ưu hóa mức tiêu thụ địa chỉ IP và mở rộng dung lượng mạng bằng giải pháp cổng NAT riêng. Cách tiếp cận hai mặt này giúp bạn được bỏ chặn trong môi trường có hạn chế về dung lượng địa chỉ IP. Các tùy chọn được thảo luận trong phần tối ưu hóa địa chỉ IP của AWS Glue là bổ sung cho các giải pháp mở rộng địa chỉ IP và bạn có thể xây dựng lặp lại để hoàn thiện nền tảng dữ liệu của mình.
Tìm hiểu thêm về các kỹ thuật tối ưu hóa công việc của AWS Glue từ Theo dõi và tối ưu hóa chi phí trên AWS Glue cho Apache Spark và Các phương pháp hay nhất để thay đổi quy mô công việc Apache Spark và phân vùng dữ liệu bằng AWS Glue.
Giới thiệu về tác giả
 Sushanth Kothapally là Kiến trúc sư giải pháp tại Amazon Web Services hỗ trợ khách hàng Sản xuất và Ô tô. Anh đam mê thiết kế các giải pháp công nghệ để đáp ứng các mục tiêu kinh doanh và đặc biệt quan tâm đến kiến trúc serverless và hướng sự kiện.
Sushanth Kothapally là Kiến trúc sư giải pháp tại Amazon Web Services hỗ trợ khách hàng Sản xuất và Ô tô. Anh đam mê thiết kế các giải pháp công nghệ để đáp ứng các mục tiêu kinh doanh và đặc biệt quan tâm đến kiến trúc serverless và hướng sự kiện.
 Senthil Kamala Rathinam là Kiến trúc sư giải pháp tại Amazon Web Services chuyên về Dữ liệu và Phân tích. Anh đam mê giúp đỡ khách hàng thiết kế và xây dựng nền tảng dữ liệu hiện đại. Khi rảnh rỗi, Senthil thích dành thời gian cho gia đình và chơi cầu lông.
Senthil Kamala Rathinam là Kiến trúc sư giải pháp tại Amazon Web Services chuyên về Dữ liệu và Phân tích. Anh đam mê giúp đỡ khách hàng thiết kế và xây dựng nền tảng dữ liệu hiện đại. Khi rảnh rỗi, Senthil thích dành thời gian cho gia đình và chơi cầu lông.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

