Chúng ta đang sống trong thời đại mà mô hình học máy đang ở đỉnh cao. So với nhiều thập kỷ trước, hầu hết mọi người sẽ chưa bao giờ nghe nói về ChatGPT hoặc Trí tuệ nhân tạo. Tuy nhiên, đó là những chủ đề mà mọi người vẫn tiếp tục nói đến. Tại sao? Bởi những giá trị được trao rất có ý nghĩa so với công sức bỏ ra.
Sự đột phá của AI trong những năm gần đây có thể đến từ nhiều thứ, nhưng một trong số đó chính là mô hình ngôn ngữ lớn (LLM). Nhiều AI tạo văn bản mà mọi người sử dụng được hỗ trợ bởi mô hình LLM; Ví dụ: ChatGPT sử dụng mô hình GPT của họ. Vì LLM là một chủ đề quan trọng nên chúng ta nên tìm hiểu về nó.
Bài viết này sẽ thảo luận về Mô hình ngôn ngữ lớn ở 3 mức độ khó, nhưng chúng tôi sẽ chỉ đề cập đến một số khía cạnh của LLM. Chúng tôi sẽ chỉ khác nhau theo cách cho phép mọi người đọc hiểu LLM là gì. Với ý nghĩ đó, chúng ta hãy đi vào nó.
Ở cấp độ đầu tiên, chúng tôi cho rằng người đọc không biết về LLM và có thể biết một chút về lĩnh vực khoa học dữ liệu/học máy. Vì vậy, tôi sẽ giới thiệu ngắn gọn về AI và Machine Learning trước khi chuyển sang LLM.
Trí tuệ nhân tạo là khoa học phát triển các chương trình máy tính thông minh. Mục đích của chương trình là thực hiện các nhiệm vụ thông minh mà con người có thể làm nhưng không có giới hạn về nhu cầu sinh học của con người. học máy là một lĩnh vực trí tuệ nhân tạo tập trung vào nghiên cứu khái quát hóa dữ liệu bằng các thuật toán thống kê. Theo một cách nào đó, Machine Learning đang cố gắng đạt được Trí tuệ nhân tạo thông qua nghiên cứu dữ liệu để chương trình có thể thực hiện các nhiệm vụ trí tuệ mà không cần hướng dẫn.
Trong lịch sử, lĩnh vực giao thoa giữa khoa học máy tính và ngôn ngữ học được gọi là Khoa học tự nhiên. Xử lý ngôn ngữ cánh đồng. Lĩnh vực này chủ yếu liên quan đến bất kỳ hoạt động nào của máy xử lý văn bản của con người, chẳng hạn như tài liệu văn bản. Trước đây, lĩnh vực này chỉ giới hạn ở hệ thống dựa trên quy tắc nhưng nó đã trở nên phổ biến hơn với sự ra đời của các thuật toán bán giám sát và không giám sát tiên tiến cho phép mô hình học mà không cần bất kỳ hướng nào. Một trong những mô hình nâng cao để thực hiện điều này là Mô hình ngôn ngữ.
Ngôn ngữ kiểu mẫu là một mô hình NLP xác suất để thực hiện nhiều nhiệm vụ của con người như dịch thuật, sửa ngữ pháp và tạo văn bản. Dạng cũ của mô hình ngôn ngữ sử dụng các phương pháp thống kê thuần túy như phương pháp n-gram, trong đó giả định rằng xác suất của từ tiếp theo chỉ phụ thuộc vào dữ liệu có kích thước cố định của từ trước đó.
Tuy nhiên, việc đưa ra Mạng thần kinh đã loại bỏ cách tiếp cận trước đó. Mạng nơ-ron nhân tạo, hay NN, là một chương trình máy tính mô phỏng cấu trúc nơ-ron của não người. Cách tiếp cận Mạng nơ-ron rất tốt để sử dụng vì nó có thể xử lý nhận dạng mẫu phức tạp từ dữ liệu văn bản và xử lý dữ liệu tuần tự như văn bản. Đó là lý do tại sao Mô hình ngôn ngữ hiện tại thường dựa trên NN.
Mô hình ngôn ngữ lớn, hay LLM, là các mô hình học máy học từ một số lượng lớn tài liệu dữ liệu để thực hiện việc tạo ngôn ngữ cho mục đích chung. Chúng vẫn là một mô hình ngôn ngữ, nhưng số lượng lớn các tham số mà NN học được khiến chúng được coi là lớn. Theo thuật ngữ của giáo dân, mô hình có thể thực hiện cách con người viết bằng cách dự đoán rất tốt các từ tiếp theo từ các từ đầu vào đã cho.
Ví dụ về các nhiệm vụ LLM bao gồm dịch ngôn ngữ, chatbot máy, trả lời câu hỏi, v.v. Từ bất kỳ chuỗi dữ liệu đầu vào nào, mô hình có thể xác định mối quan hệ giữa các từ và tạo ra đầu ra phù hợp với lệnh.
Hầu như tất cả các sản phẩm Generative AI tự hào về thứ gì đó sử dụng tính năng tạo văn bản đều được cung cấp bởi LLM. Các sản phẩm lớn như ChatGPT, Bard của Google và nhiều sản phẩm khác đang sử dụng LLM làm nền tảng cho sản phẩm của họ.
Người đọc có kiến thức về khoa học dữ liệu nhưng cần tìm hiểu thêm về LLM ở cấp độ này. Ít nhất, người đọc có thể hiểu được các thuật ngữ được sử dụng trong trường dữ liệu. Ở cấp độ này, chúng tôi sẽ đi sâu hơn vào kiến trúc cơ sở.
Như đã giải thích trước đây, LLM là mô hình Mạng thần kinh được đào tạo trên lượng dữ liệu văn bản khổng lồ. Để hiểu sâu hơn về khái niệm này, sẽ rất hữu ích nếu hiểu cách mạng lưới thần kinh và học sâu hoạt động.
Ở cấp độ trước, chúng ta đã giải thích rằng nơ-ron thần kinh là mô hình mô phỏng cấu trúc thần kinh của não người. Thành phần chính của Mạng nơ-ron là các nơ-ron, thường được gọi là các nút. Để giải thích khái niệm này rõ hơn, hãy xem kiến trúc Mạng thần kinh điển hình trong hình bên dưới.
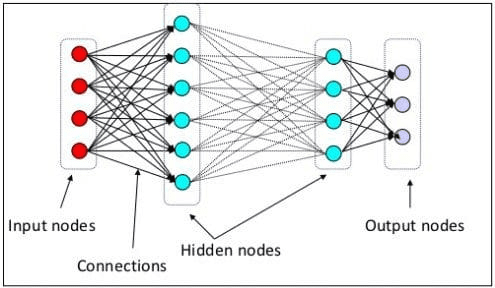
Kiến trúc mạng thần kinh(Nguồn hình ảnh: Xe đẩy)
Như chúng ta có thể thấy trong hình trên, Mạng nơ-ron bao gồm ba lớp:
- Lớp đầu vào nơi nó nhận thông tin và chuyển nó đến các nút khác trong lớp tiếp theo.
- Các lớp nút ẩn nơi tất cả các tính toán diễn ra.
- Lớp nút đầu ra nơi chứa các đầu ra tính toán.
Nó được gọi là học sâu khi chúng ta huấn luyện mô hình Mạng thần kinh của mình với hai hoặc nhiều lớp ẩn. Nó được gọi là sâu vì nó sử dụng nhiều lớp ở giữa. Ưu điểm của mô hình học sâu là chúng tự động học và trích xuất các tính năng từ dữ liệu mà các mô hình học máy truyền thống không có khả năng thực hiện được.
Trong Mô hình ngôn ngữ lớn, học sâu rất quan trọng vì mô hình được xây dựng dựa trên kiến trúc mạng lưới thần kinh sâu. Vậy tại sao nó được gọi là LLM? Đó là bởi vì hàng tỷ lớp được đào tạo dựa trên lượng dữ liệu văn bản khổng lồ. Các lớp sẽ tạo ra các tham số mô hình giúp mô hình tìm hiểu các mẫu phức tạp trong ngôn ngữ, bao gồm ngữ pháp, phong cách viết, v.v.
Quy trình đào tạo mô hình được đơn giản hóa được hiển thị trong hình ảnh bên dưới.
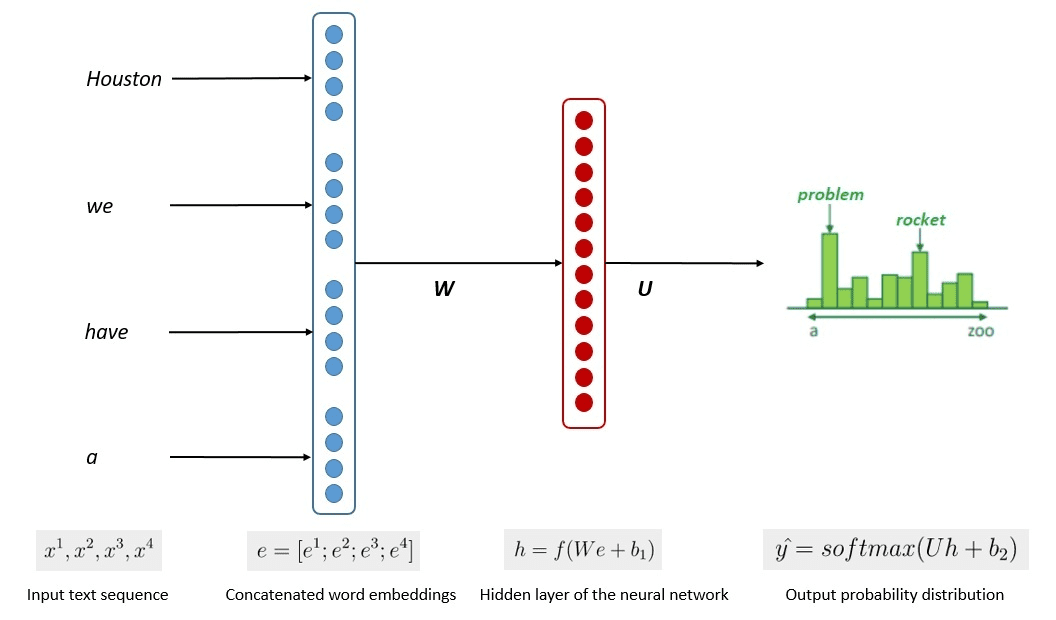
Hình ảnh của Kumar Chandrakant (Nguồn: Baeldung.com)
Quá trình này cho thấy các mô hình có thể tạo ra văn bản có liên quan dựa trên khả năng xảy ra của từng từ hoặc câu trong dữ liệu đầu vào. Trong LLM, phương pháp nâng cao sử dụng học tập tự giám sát và học bán giám sát để đạt được khả năng mục đích chung.
Học tự giám sát là một kỹ thuật mà chúng ta không có nhãn và thay vào đó, dữ liệu huấn luyện sẽ tự cung cấp phản hồi huấn luyện. Nó được sử dụng trong quá trình đào tạo LLM vì dữ liệu thường thiếu nhãn. Trong LLM, người ta có thể sử dụng bối cảnh xung quanh làm đầu mối để dự đoán các từ tiếp theo. Ngược lại, Học bán giám sát kết hợp các khái niệm học có giám sát và không giám sát với một lượng nhỏ dữ liệu được dán nhãn để tạo nhãn mới cho một lượng lớn dữ liệu không được gắn nhãn. Học bán giám sát thường được sử dụng cho LLM có nhu cầu về ngữ cảnh hoặc miền cụ thể.
Ở cấp độ thứ ba, chúng ta sẽ thảo luận sâu hơn về LLM, đặc biệt là giải quyết cấu trúc LLM và cách nó có thể đạt được khả năng tạo ra giống như con người.
Chúng ta đã thảo luận rằng LLM dựa trên mô hình Mạng thần kinh với các kỹ thuật Deep Learning. LLM thường được xây dựng dựa trên dựa trên máy biến áp kiến trúc trong những năm gần đây. Máy biến áp dựa trên cơ chế chú ý nhiều đầu được giới thiệu bởi Vaswani et al. (2017) và đã được sử dụng trong nhiều LLM.
Transformers là một kiến trúc mô hình cố gắng giải quyết các tác vụ tuần tự gặp phải trước đây trong RNN và LSTM. Cách cũ của Mô hình ngôn ngữ là sử dụng RNN và LSTM để xử lý dữ liệu một cách tuần tự, trong đó mô hình sẽ sử dụng mọi đầu ra từ và lặp lại chúng để mô hình không quên. Tuy nhiên, họ gặp vấn đề với dữ liệu chuỗi dài khi máy biến áp được đưa vào sử dụng.
Trước khi đi sâu hơn vào Transformers, tôi muốn giới thiệu khái niệm bộ mã hóa-giải mã đã được sử dụng trước đây trong RNN. Cấu trúc bộ mã hóa-giải mã cho phép văn bản đầu vào và đầu ra không có cùng độ dài. Trường hợp sử dụng ví dụ là bản dịch ngôn ngữ, thường có kích thước trình tự khác nhau.
Cấu trúc có thể được chia thành hai. Phần đầu tiên được gọi là Bộ mã hóa, là phần nhận chuỗi dữ liệu và tạo biểu diễn mới dựa trên chuỗi đó. Việc biểu diễn sẽ được sử dụng trong phần thứ hai của mô hình, đó là bộ giải mã.
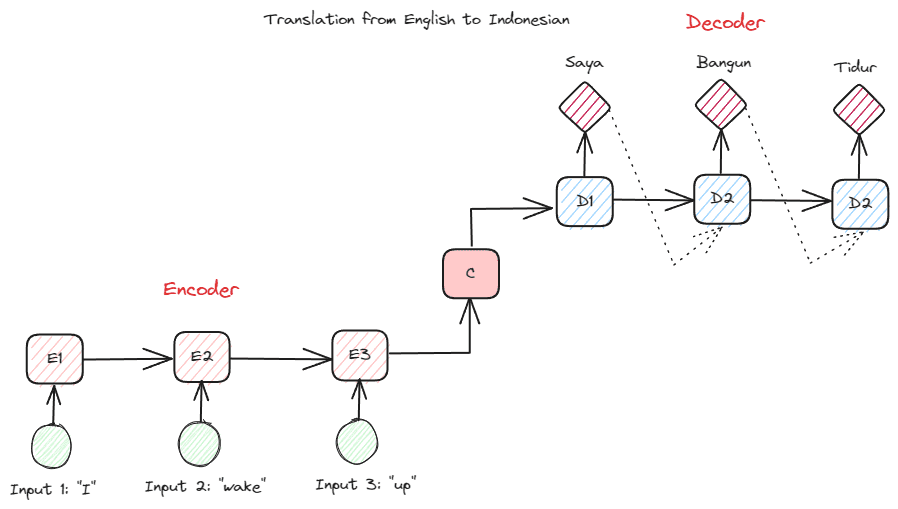
Hình ảnh của Tác giả
Vấn đề với RNN là mô hình có thể cần trợ giúp để ghi nhớ các chuỗi dài hơn, ngay cả với cấu trúc bộ mã hóa-giải mã ở trên. Đây là nơi cơ chế chú ý có thể giúp giải quyết vấn đề, một lớp có thể giải quyết các vấn đề đầu vào dài. Cơ chế chú ý được giới thiệu trong bài báo bởi Bahdanau et al. (2014) để giải quyết các RNN loại bộ mã hóa-giải mã bằng cách tập trung vào một phần quan trọng của đầu vào mô hình trong khi có dự đoán đầu ra.
Cấu trúc của máy biến áp được lấy cảm hứng từ loại bộ mã hóa-giải mã và được xây dựng bằng kỹ thuật cơ chế chú ý nên không cần xử lý dữ liệu theo thứ tự tuần tự. Mô hình máy biến áp tổng thể có cấu trúc như hình bên dưới.

Kiến trúc máy biến áp (Vaswani et al. (2017))
Trong cấu trúc trên, các bộ chuyển đổi mã hóa chuỗi vectơ dữ liệu thành từ nhúng đồng thời sử dụng bộ giải mã để chuyển đổi dữ liệu về dạng ban đầu. Việc mã hóa có thể ấn định tầm quan trọng nhất định cho đầu vào bằng cơ chế chú ý.
Chúng ta đã nói một chút về máy biến áp mã hóa vectơ dữ liệu, nhưng vectơ dữ liệu là gì? Hãy thảo luận về nó. Trong mô hình học máy, chúng ta không thể nhập dữ liệu ngôn ngữ tự nhiên thô vào mô hình, vì vậy chúng ta cần chuyển đổi chúng thành dạng số. Quá trình chuyển đổi được gọi là nhúng từ, trong đó mỗi từ đầu vào được xử lý thông qua mô hình nhúng từ để lấy vectơ dữ liệu. Chúng ta có thể sử dụng nhiều cách nhúng từ ban đầu, chẳng hạn như Word2vec or Găng tay, nhưng nhiều người dùng nâng cao cố gắng trau chuốt chúng bằng cách sử dụng từ vựng của họ. Ở dạng cơ bản, quá trình nhúng từ có thể được hiển thị trong hình ảnh bên dưới.
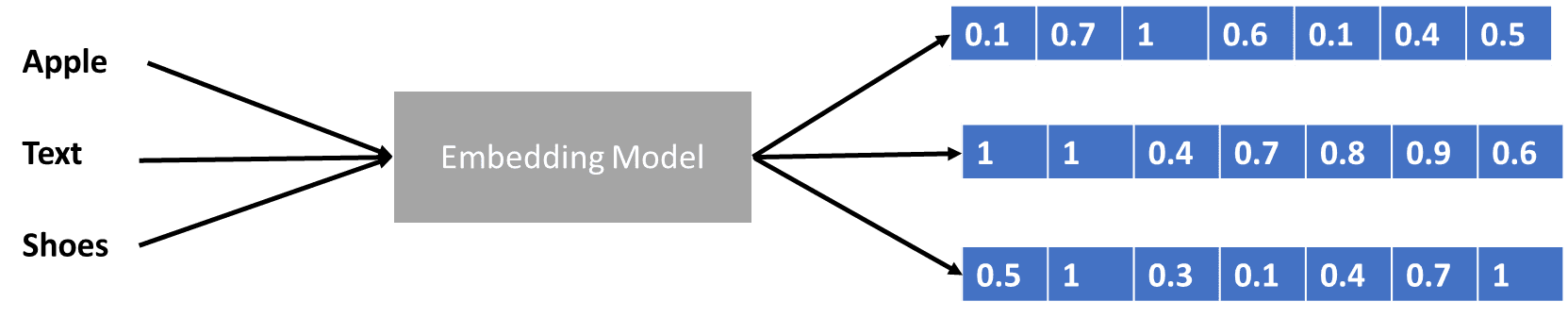
Hình ảnh của Tác giả
Máy biến áp có thể chấp nhận đầu vào và cung cấp ngữ cảnh phù hợp hơn bằng cách trình bày các từ ở dạng số như vectơ dữ liệu ở trên. Trong LLM, việc nhúng từ thường phụ thuộc vào ngữ cảnh, thường được tinh chỉnh dựa trên các trường hợp sử dụng và đầu ra dự kiến.
Chúng tôi đã thảo luận về Mô hình ngôn ngữ lớn ở ba cấp độ khó, từ sơ cấp đến nâng cao. Từ cách sử dụng chung của LLM cho đến cách cấu trúc của nó, bạn có thể tìm thấy lời giải thích chi tiết hơn về khái niệm này.
Cornellius Yudha Wijaya là trợ lý quản lý khoa học dữ liệu và người viết dữ liệu. Trong khi làm việc toàn thời gian tại Allianz Indonesia, anh ấy thích chia sẻ các mẹo về Python và Dữ liệu qua mạng xã hội và phương tiện viết lách.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/large-language-models-explained-in-3-levels-of-difficulty?utm_source=rss&utm_medium=rss&utm_campaign=large-language-models-explained-in-3-levels-of-difficulty

