Giới thiệu
Việc gắn nhãn cho hình ảnh hoặc chú thích cho bức ảnh trong bức tranh lớn về thị giác máy tính là một thách thức. Khám phá của chúng tôi đi sâu vào hoạt động làm việc nhóm của LabelImg và Detectron, một bộ đôi mạnh mẽ kết hợp chú thích chính xác với việc xây dựng mô hình hiệu quả. LabelImg, dễ sử dụng và chính xác, dẫn đến chú thích cẩn thận, đặt nền tảng vững chắc để phát hiện đối tượng rõ ràng.
Khi chúng tôi khám phá LabelImg và vẽ các hộp giới hạn tốt hơn, chúng tôi sẽ chuyển sang Detectron một cách liền mạch. Khung mạnh mẽ này sắp xếp dữ liệu đã đánh dấu của chúng tôi, giúp dữ liệu này hữu ích trong việc đào tạo các mô hình nâng cao. LabelImg và Detectron cùng nhau giúp mọi người dễ dàng phát hiện đối tượng, cho dù bạn là người mới bắt đầu hay chuyên gia. Hãy đến đây, nơi mỗi hình ảnh được đánh dấu giúp chúng ta khai phá toàn bộ sức mạnh của thông tin hình ảnh.
Mục tiêu học tập
- Bắt đầu với LabelImg.
- Thiết lập môi trường và cài đặt LabelImg.
- Hiểu LabelImg và chức năng của nó.
- Chuyển đổi dữ liệu VOC hoặc Pascal sang định dạng COCO để phát hiện đối tượng.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Sơ đồ

Thiết lập môi trường của bạn
1. Tạo môi trường ảo:
conda create -p ./venv python=3.8 -yLệnh này tạo một môi trường ảo có tên là “venv” bằng Python phiên bản 3.8.
2. Kích hoạt môi trường ảo:
conda activate venvKích hoạt môi trường ảo để cách ly cài đặt LabelImg.
Cài đặt và sử dụng LabelImg
1. Cài đặt LabelImg:
pip install labelImgCài đặt LabelImg trong môi trường ảo được kích hoạt.
2. Khởi chạy LabelImg:
labelImg
Xử lý sự cố: Nếu bạn gặp lỗi khi chạy tập lệnh
Nếu bạn gặp lỗi khi chạy tập lệnh, tôi đã chuẩn bị một kho lưu trữ zip chứa môi trường ảo (venv) để thuận tiện cho bạn.
1. Tải xuống Lưu trữ Zip:
- Tải xuống kho lưu trữ venv.zip từ liên kết
2. Tạo thư mục LabelImg:
- Tạo một thư mục mới có tên LabelImg trên máy cục bộ của bạn.
3. Giải nén thư mục venv:
- Trích xuất nội dung của kho lưu trữ venv.zip vào thư mục LabelImg.
4. Kích hoạt môi trường ảo:
- Mở dấu nhắc lệnh hoặc thiết bị đầu cuối của bạn.
- Điều hướng đến thư mục LabelImg.
- Chạy lệnh sau để kích hoạt môi trường ảo:
conda activate ./venvQuá trình này đảm bảo bạn có môi trường ảo được cấu hình sẵn sẵn sàng để sử dụng với LabelImg. Kho lưu trữ zip được cung cấp đóng gói các phần phụ thuộc cần thiết, cho phép trải nghiệm mượt mà hơn mà không phải lo lắng về khả năng cài đặt.
Bây giờ, hãy tiếp tục các bước trước đó để cài đặt và sử dụng LabelImg trong môi trường ảo được kích hoạt này.
Quy trình làm việc chú thích với LabelImg
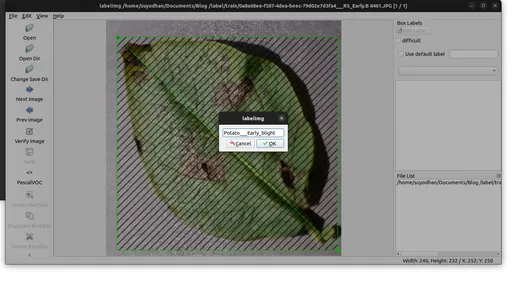
1. Chú thích hình ảnh ở định dạng PascalVOC:
- Xây dựng và khởi chạy LabelImg.
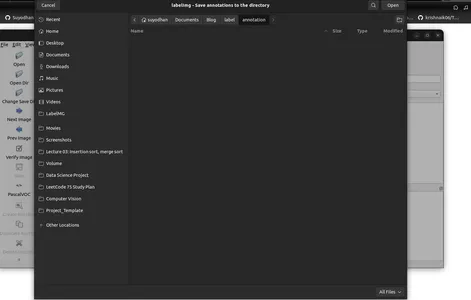
- Nhấp vào 'Thay đổi thư mục chú thích đã lưu mặc định' trong Menu/Tệp.
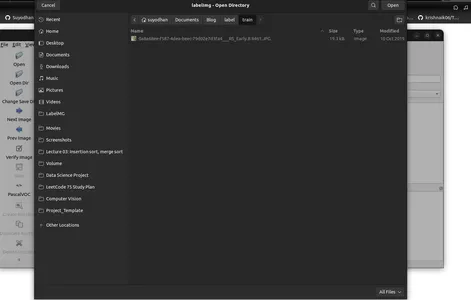
- Nhấp vào 'Open Dir' để chọn thư mục hình ảnh.
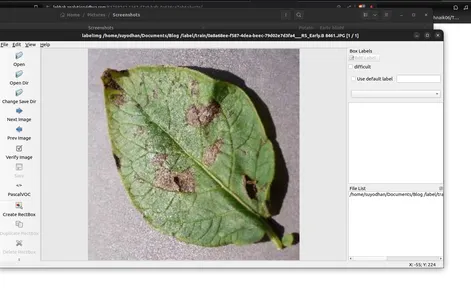
- Sử dụng “Create RectBox” để chú thích các đối tượng trong ảnh.
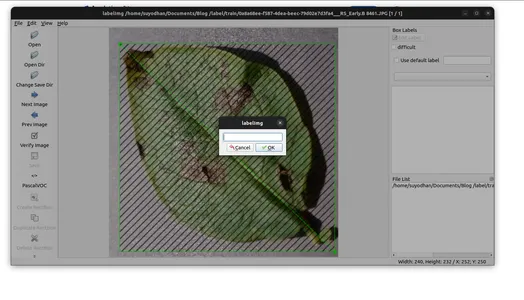
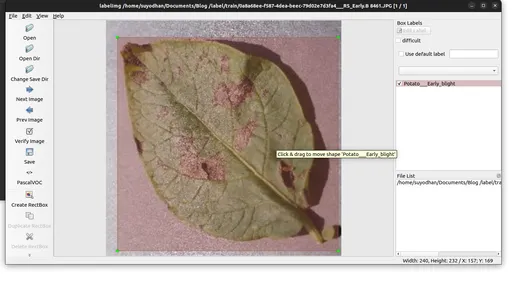
- Lưu các chú thích vào thư mục được chỉ định.
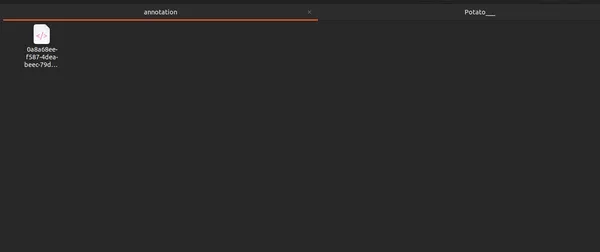
bên trong .xml
<annotation>
<folder>train</folder>
<filename>0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</filename>
<path>/home/suyodhan/Documents/Blog /label
/train/0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>256</width>
<height>256</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Potato___Early_blight</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>12</xmin>
<ymin>18</ymin>
<xmax>252</xmax>
<ymax>250</ymax>
</bndbox>
</object>
</annotation>Cấu trúc XML này tuân theo định dạng chú thích Pascal VOC, thường được sử dụng cho các bộ dữ liệu phát hiện đối tượng. Định dạng này cung cấp cách trình bày tiêu chuẩn hóa dữ liệu được chú thích để đào tạo các mô hình thị giác máy tính. Nếu bạn có thêm hình ảnh có chú thích, bạn có thể tiếp tục tạo các tệp XML tương tự cho từng đối tượng được chú thích trong các hình ảnh tương ứng.
Chuyển đổi chú thích Pascal VOC sang định dạng COCO: Tập lệnh Python
Các mô hình phát hiện đối tượng thường yêu cầu chú thích ở các định dạng cụ thể để huấn luyện và đánh giá hiệu quả. Mặc dù Pascal VOC là định dạng được sử dụng rộng rãi nhưng các khung cụ thể như Detectron lại thích chú thích COCO hơn. Để thu hẹp khoảng cách này, chúng tôi giới thiệu một giải pháp đa năng Python script, voc2coco.py, được thiết kế để chuyển đổi liền mạch các chú thích Pascal VOC sang định dạng COCO.
#!/usr/bin/python
# pip install lxml
import sys
import os
import json
import xml.etree.ElementTree as ET
import glob
START_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = None
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise ValueError("Can not find %s in %s." % (name, root.tag))
if length > 0 and len(vars) != length:
raise ValueError(
"The size of %s is supposed to be %d, but is %d."
% (name, length, len(vars))
)
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = filename.replace("", "/")
filename = os.path.splitext(os.path.basename(filename))[0]
return str(filename)
except:
raise ValueError("Filename %s is supposed to be an integer." % (filename))
def get_categories(xml_files):
"""Generate category name to id mapping from a list of xml files.
Arguments:
xml_files {list} -- A list of xml file paths.
Returns:
dict -- category name to id mapping.
"""
classes_names = []
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall("object"):
classes_names.append(member[0].text)
classes_names = list(set(classes_names))
classes_names.sort()
return {name: i for i, name in enumerate(classes_names)}
def convert(xml_files, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
if PRE_DEFINE_CATEGORIES is not None:
categories = PRE_DEFINE_CATEGORIES
else:
categories = get_categories(xml_files)
bnd_id = START_BOUNDING_BOX_ID
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
path = get(root, "path")
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, "filename", 1).text
else:
raise ValueError("%d paths found in %s" % (len(path), xml_file))
## The filename must be a number
image_id = get_filename_as_int(filename)
size = get_and_check(root, "size", 1)
width = int(get_and_check(size, "width", 1).text)
height = int(get_and_check(size, "height", 1).text)
image = {
"file_name": filename,
"height": height,
"width": width,
"id": image_id,
}
json_dict["images"].append(image)
## Currently we do not support segmentation.
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, "object"):
category = get_and_check(obj, "name", 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, "bndbox", 1)
xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1
ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1
xmax = int(get_and_check(bndbox, "xmax", 1).text)
ymax = int(get_and_check(bndbox, "ymax", 1).text)
assert xmax > xmin
assert ymax > ymin
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {
"area": o_width * o_height,
"iscrowd": 0,
"image_id": image_id,
"bbox": [xmin, ymin, o_width, o_height],
"category_id": category_id,
"id": bnd_id,
"ignore": 0,
"segmentation": [],
}
json_dict["annotations"].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {"supercategory": "none", "id": cid, "name": cate}
json_dict["categories"].append(cat)
#os.makedirs(os.path.dirname(json_file), exist_ok=True)
json_fp = open(json_file, "w")
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description="Convert Pascal VOC annotation to COCO format."
)
parser.add_argument("xml_dir", help="Directory path to xml files.", type=str)
parser.add_argument("json_file", help="Output COCO format json file.", type=str)
args = parser.parse_args()
xml_files = glob.glob(os.path.join(args.xml_dir, "*.xml"))
# If you want to do train/test split, you can pass a subset of xml files to convert function.
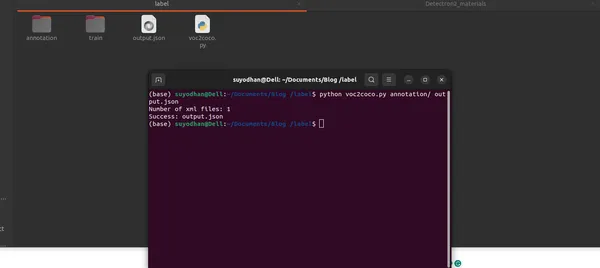
print("Number of xml files: {}".format(len(xml_files)))
convert(xml_files, args.json_file)
print("Success: {}".format(args.json_file))Tổng quan về kịch bản
Tập lệnh voc2coco.py đơn giản hóa quá trình chuyển đổi bằng cách tận dụng thư viện lxml. Trước khi đi sâu vào cách sử dụng, hãy khám phá các thành phần chính của nó:
1. Sự phụ thuộc:
- Đảm bảo thư viện lxml được cài đặt bằng pip install lxml.
2. Cấu hình:
- Tùy chọn xác định trước các danh mục bằng biến PRE_DEFINE_CATEGORIES. Bỏ ghi chú và sửa đổi phần này theo tập dữ liệu của bạn.
3. Chức năngNhận
- get, get_and_check, get_filename_as_int: Các hàm trợ giúp để phân tích cú pháp XML.
- get_categories: Tạo tên danh mục để ánh xạ ID từ danh sách các tệp XML.
- chuyển đổi: Chức năng chuyển đổi chính xử lý các tệp XML và tạo JSON định dạng COCO.
Cách Sử dụng
Việc thực thi tập lệnh rất đơn giản, chạy nó từ dòng lệnh, cung cấp đường dẫn đến tệp XML Pascal VOC của bạn và chỉ định đường dẫn đầu ra mong muốn cho tệp JSON định dạng COCO. Đây là một ví dụ:
python voc2coco.py /path/to/xml/files /path/to/output/output.jsonĐầu ra:
Tập lệnh xuất ra tệp JSON định dạng COCO có cấu trúc tốt chứa thông tin cần thiết về hình ảnh, chú thích và danh mục.
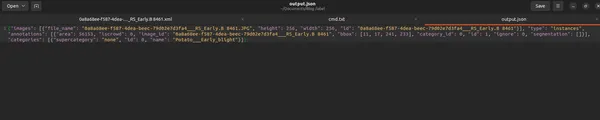
Kết luận
Tóm lại, Kết thúc hành trình phát hiện đối tượng của chúng tôi bằng LabelImg và Detectron, điều quan trọng là phải nhận ra sự đa dạng của các công cụ chú thích phục vụ cho những người đam mê và chuyên gia. LabelImg, như một viên ngọc nguồn mở, mang lại tính linh hoạt và khả năng truy cập, khiến nó trở thành lựa chọn hàng đầu.
Ngoài các công cụ miễn phí, các giải pháp trả phí như VGG Image Annotator (VIA), RectLabel và Labelbox cũng hỗ trợ các nhiệm vụ phức tạp và dự án lớn. Các nền tảng này mang lại các tính năng nâng cao và khả năng mở rộng, mặc dù có đầu tư tài chính, đảm bảo hiệu quả trong các nỗ lực đặt cược cao.
Việc khám phá của chúng tôi nhấn mạnh việc chọn công cụ chú thích phù hợp dựa trên chi tiết cụ thể của dự án, ngân sách và mức độ phức tạp. Cho dù bám sát tính mở của LabelImg hay đầu tư vào các công cụ trả phí, điều quan trọng là sự phù hợp với quy mô và mục tiêu dự án của bạn. Trong lĩnh vực thị giác máy tính đang phát triển, các công cụ chú thích tiếp tục đa dạng hóa, cung cấp các tùy chọn cho các dự án thuộc mọi quy mô và độ phức tạp.
Chìa khóa chính
- Giao diện trực quan và các tính năng nâng cao của LabelImg làm cho nó trở thành một công cụ nguồn mở linh hoạt để chú thích hình ảnh chính xác, lý tưởng cho những người muốn phát hiện đối tượng.
- Các công cụ trả phí như VIA, RectLabel và Labelbox phục vụ cho các tác vụ chú thích phức tạp và các dự án quy mô lớn, cung cấp các tính năng nâng cao và khả năng mở rộng.
- Bài học quan trọng là chọn công cụ chú thích phù hợp dựa trên nhu cầu, ngân sách và độ phức tạp mong muốn của dự án, đảm bảo hiệu quả và thành công trong nỗ lực phát hiện đối tượng.
Tài nguyên để học thêm:
1. Tài liệu LabelImg:
- Khám phá tài liệu chính thức về LabelImg để hiểu rõ hơn về các tính năng và chức năng của nó.
- Tài liệu LabelImg
2. Tài liệu về khung Detectron:
- Đi sâu vào tài liệu về Detectron, khung phát hiện đối tượng mạnh mẽ, để hiểu các khả năng và cách sử dụng của nó.
- Tài liệu về máy dò
3. Hướng dẫn sử dụng Công cụ chú thích hình ảnh VGG (VIA):
- Nếu bạn muốn khám phá VIA, Công cụ chú thích hình ảnh VGG, hãy tham khảo hướng dẫn toàn diện để biết hướng dẫn chi tiết.
- Hướng dẫn sử dụng VIA
4.RectLabel Tài liệu:
- Tìm hiểu thêm về RectLabel, một công cụ chú thích trả phí, bằng cách tham khảo tài liệu chính thức của công cụ này để biết hướng dẫn về cách sử dụng và các tính năng.
- Tài liệu RectLabel
5.Trung tâm học tập Labelbox:
- Khám phá các tài nguyên giáo dục và hướng dẫn trong Trung tâm Kiến thức Labelbox để nâng cao hiểu biết của bạn về nền tảng chú thích này.
- Trung tâm học tập Labelbox
Những câu hỏi thường gặp
Trả lời: LabelImg là một công cụ chú thích hình ảnh nguồn mở dành cho các tác vụ phát hiện đối tượng. Giao diện thân thiện với người dùng và tính linh hoạt của nó làm cho nó trở nên khác biệt. Không giống như một số công cụ, LabelImg cho phép chú thích hộp giới hạn chính xác, khiến nó trở thành lựa chọn ưu tiên cho những người mới làm quen với việc phát hiện đối tượng.
Đáp: Có, một số công cụ chú thích trả phí, chẳng hạn như VGG Image Annotator (VIA), RectLabel và Labelbox, cung cấp các tính năng nâng cao và khả năng mở rộng. Trong khi các công cụ miễn phí như LabelImg rất tuyệt vời cho các tác vụ cơ bản thì các giải pháp trả phí lại được điều chỉnh cho các dự án phức tạp hơn, cung cấp các tính năng cộng tác và nâng cao hiệu quả.
Trả lời: Việc chuyển đổi chú thích sang định dạng Pascal VOC là rất quan trọng để tương thích với các khung như Detectron. Nó đảm bảo ghi nhãn lớp nhất quán và tích hợp liền mạch vào quy trình đào tạo, tạo điều kiện thuận lợi cho việc tạo ra các mô hình phát hiện đối tượng chính xác.
Trả lời: Detectron là một khung phát hiện đối tượng mạnh mẽ giúp đơn giản hóa quá trình đào tạo mô hình. Nó đóng một vai trò quan trọng trong việc xử lý dữ liệu chú thích, chuẩn bị cho việc đào tạo và tối ưu hóa hiệu quả tổng thể của các mô hình phát hiện đối tượng.
Đáp: Mặc dù các công cụ chú thích trả phí thường được liên kết với các nhiệm vụ cấp doanh nghiệp nhưng chúng cũng có thể mang lại lợi ích cho các dự án quy mô nhỏ. Quyết định phụ thuộc vào các yêu cầu cụ thể, hạn chế về ngân sách và mức độ phức tạp mong muốn đối với các nhiệm vụ chú thích.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/11/detectron-integration-with-labelimg/

