Giới thiệu
Dữ liệu là nhiên liệu cho ngành CNTT và Dự án khoa học dữ liệu trong thế giới trực tuyến ngày nay. Các ngành CNTT phụ thuộc rất nhiều vào những hiểu biết sâu sắc về thời gian thực từ truyền dữ liệu nguồn. Xử lý và xử lý dữ liệu phát trực tuyến là công việc khó khăn nhất đối với Phân tích dữ liệu. Chúng tôi biết rằng dữ liệu phát trực tuyến là dữ liệu được phát ra ở mức âm lượng lớn trong quá trình xử lý liên tục, điều đó có nghĩa là dữ liệu thay đổi mỗi giây. Để xử lý dữ liệu này chúng tôi đang sử dụng Nền tảng hợp lưu – Một bản phân phối cấp doanh nghiệp, tự quản lý của Kafka Apache.
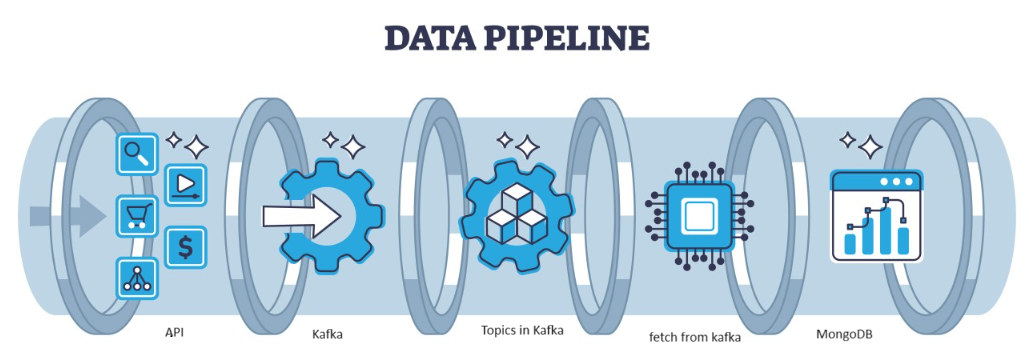
Kafka là một lỗi phân tán có thể được xử lý bằng kiến trúc, đóng vai trò là lựa chọn phổ biến để quản lý các luồng dữ liệu thông lượng cao. Dữ liệu sau đó từ Kafka được thu thập trong MongoDB dưới dạng sưu tập. Trong bài viết này, chúng tôi sẽ tạo đường dẫn từ đầu đến cuối trong đó dữ liệu được tìm nạp với sự trợ giúp của API trong Đường ống và sau đó được thu thập trong Kafka dưới dạng chủ đề và sau đó được lưu trữ trong MongoDB từ đó chúng ta có thể sử dụng nó trong dự án hoặc thực hiện kỹ thuật tính năng.
Mục tiêu học tập
- Tìm hiểu dữ liệu phát trực tuyến là gì và cách xử lý dữ liệu phát trực tuyến với sự trợ giúp của Kafka.
- Hiểu nền tảng hợp lưu – Một bản phân phối Apache Kafka cấp doanh nghiệp, tự quản lý.
- Lưu trữ dữ liệu được Kafka thu thập vào MongoDB, đây là cơ sở dữ liệu NoSQL lưu trữ dữ liệu phi cấu trúc.
- Tạo một đường dẫn hoàn chỉnh từ đầu đến cuối để tìm nạp và lưu trữ dữ liệu trong Cơ sở dữ liệu.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Xác định vấn đề
Để xử lý dữ liệu phát trực tuyến đến từ cảm biến, các phương tiện chứa dữ liệu cảm biến được tạo ra mỗi giây và rất khó xử lý cũng như xử lý trước dữ liệu để sử dụng trong Dự án khoa học dữ liệu. Vì vậy, để giải quyết vấn đề này, chúng tôi đang tạo đường dẫn từ đầu đến cuối để xử lý dữ liệu và lưu trữ dữ liệu.
Truyền dữ liệu là gì?
Truyền dữ liệu là dữ liệu được tạo liên tục bởi các nguồn khác nhau là dữ liệu phi cấu trúc. Nó đề cập đến luồng dữ liệu liên tục được tạo từ các nguồn khác nhau trong thời gian thực hoặc gần thời gian thực. Trong xử lý hàng loạt truyền thống, nơi dữ liệu được thu thập và dữ liệu phát trực tuyến này được xử lý ngay khi nó được tạo. Dữ liệu truyền trực tuyến có thể là dữ liệu IOT như cảm biến nhiệt độ và thiết bị theo dõi GPS hoặc Dữ liệu máy giống như dữ liệu được tạo bởi máy móc và thiết bị công nghiệp như dữ liệu đo từ xa từ phương tiện và máy móc sản xuất. Có các nền tảng xử lý dữ liệu phát trực tuyến như Apache-Kafka.
Kafka là gì?
Apache Kafka là một nền tảng được sử dụng để xây dựng các đường dẫn dữ liệu thời gian thực và các ứng dụng phát trực tuyến. API Kafka Streams là một thư viện mạnh mẽ cho phép xử lý nhanh chóng, cho phép bạn thu thập và tạo các tham số cửa sổ, thực hiện nối dữ liệu trong luồng, v.v. Apache Kafka bao gồm một lớp lưu trữ và một lớp điện toán kết hợp việc nhập dữ liệu theo thời gian thực, hiệu quả, truyền luồng dữ liệu và lưu trữ trên các hệ thống.
Cách tiếp cận sẽ là gì?
Đây là một quy trình học máy giúp chúng tôi biết cách xuất bản và xử lý dữ liệu đến và đi từ hợp lưu Kafka ở định dạng JSON. Có hai phần của người tiêu dùng và nhà sản xuất xử lý dữ liệu kafka. Để lưu trữ dữ liệu phát trực tuyến từ các nhà sản xuất khác nhau và lưu trữ nó trong hợp lưu, sau đó quá trình khử tuần tự trên dữ liệu được thực hiện và dữ liệu đó được lưu trữ trong Cơ sở dữ liệu.
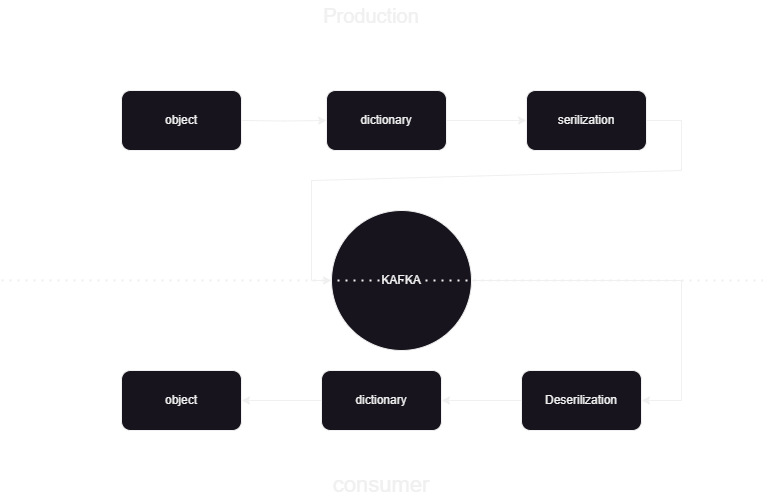
Tổng quan về kiến trúc hệ thống
Chúng tôi đang xử lý dữ liệu phát trực tuyến với sự trợ giúp của kafka hợp lưu và Kafka được chia thành hai phần:
- Nhà sản xuất Kafka: Nhà sản xuất Kafka chịu trách nhiệm sản xuất và gửi dữ liệu đến các chủ đề Kafka.
- Người tiêu dùng Kafka: Người tiêu dùng Kafka có nhiệm vụ đọc và xử lý dữ liệu từ các chủ đề Kafka.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
Thành phần là gì?
- Chủ đề: Chủ đề là các kênh hoặc danh mục hợp lý được nhà sản xuất xuất bản. Mỗi chủ đề được chia thành một hoặc nhiều phân vùng và mỗi chủ đề được sao chép trên nhiều nhà môi giới để có khả năng chịu lỗi. Nhà sản xuất xuất bản dữ liệu về các chủ đề cụ thể và người tiêu dùng đăng ký các chủ đề để sử dụng dữ liệu.
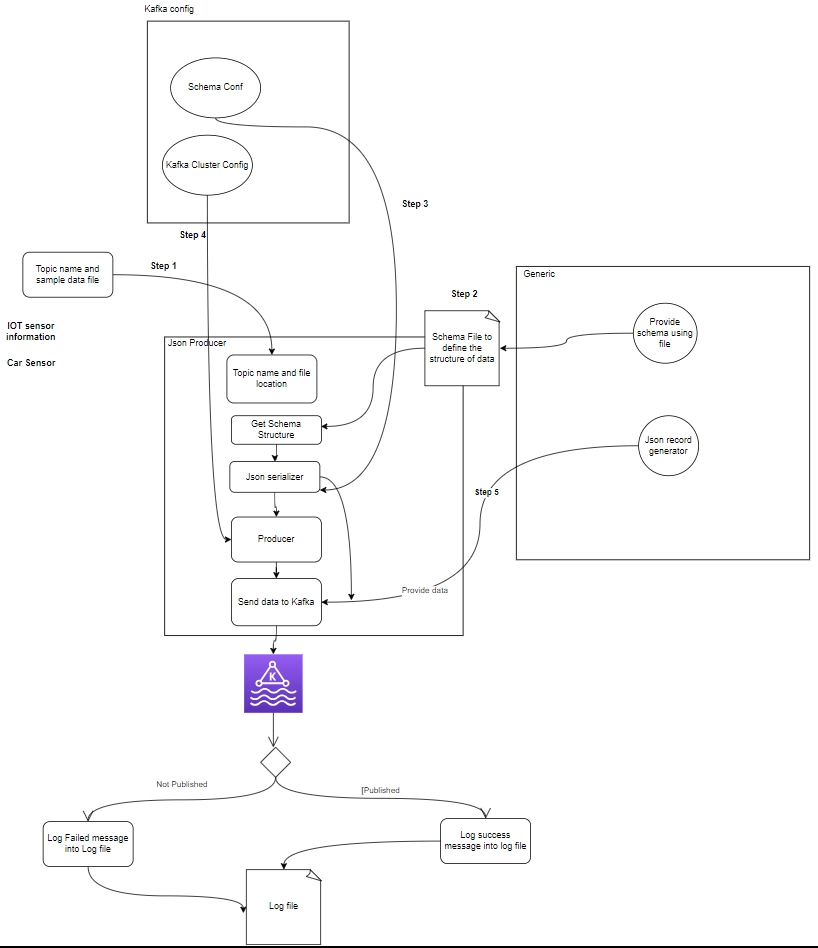
- Nhà sản xuất: Nhà sản xuất Apache Kafka là một ứng dụng khách xuất bản (ghi) các sự kiện vào cụm Kafka. Các ứng dụng gửi dữ liệu vào các chủ đề được gọi là nhà sản xuất Kafka. Phần này cung cấp cái nhìn tổng quan về nhà sản xuất Kafka.
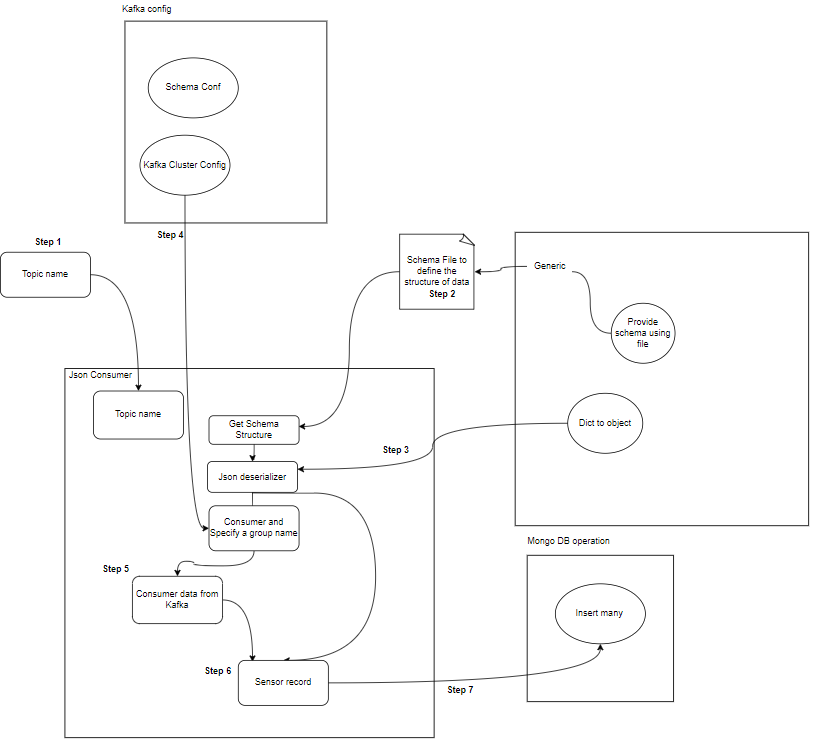
- Khách hàng: Người tiêu dùng Kafka chịu trách nhiệm đọc dữ liệu và xử lý từ các chủ đề Kafka và xử lý chúng. Người tiêu dùng có thể là một phần của bất kỳ ứng dụng nào cần sử dụng và phản ứng với dữ liệu từ Kafka. Họ đăng ký một hoặc nhiều chủ đề và dữ liệu từ các nhà môi giới Kafka. Người tiêu dùng có thể được tổ chức thành các nhóm người tiêu dùng, trong đó mỗi nhóm người tiêu dùng có một hoặc nhiều người tiêu dùng và mỗi chủ đề của một chủ đề chỉ được một người tiêu dùng trong nhóm sử dụng. Điều này cho phép xử lý song song và cân bằng tải mức tiêu thụ dữ liệu.
Cấu trúc dự án là gì?
Điều này hiển thị sơ đồ của dự án cách phân chia thư mục và tệp trong dự án:
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- Nhà sản xuất Kafka: Nhà sản xuất là phần chính tạo ra dữ liệu cảm biến (ví dụ: từ tệp CSV trong sample_data/) và xuất bản nó lên chủ đề Kafka. các điều kiện lỗi có thể xảy ra trong quá trình tạo hoặc xuất bản dữ liệu.
- (Các) nhà môi giới Kafka: Các nhà môi giới Kafka lưu trữ và sao chép dữ liệu trên cụm Kafka, xử lý việc phân vùng dữ liệu và đảm bảo khả năng chịu lỗi và tính sẵn sàng cao.
- Người tiêu dùng Kafka: Người tiêu dùng đọc dữ liệu từ các chủ đề Kafka, xử lý dữ liệu đó (ví dụ: chuyển đổi, tổng hợp) và lưu trữ dữ liệu đó trong MongoDB. Họ cũng giám sát các tình trạng lỗi có thể xảy ra trong quá trình xử lý dữ liệu.
- MongoDB: MongoDB lưu trữ dữ liệu cảm biến nhận được từ người tiêu dùng Kafka. Nó cung cấp một truy vấn để truy xuất dữ liệu và đảm bảo độ bền của dữ liệu thông qua cơ chế sao chép và chịu lỗi.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
Điều kiện tiên quyết để lưu trữ dữ liệu
Kafka hợp lưu
- Tạo tài khoản: Để hiểu Kafka, bạn cần Confluent Bạn yêu thích Apache Kafka® nhưng không quản lý nó. Dịch vụ gốc đám mây, hoàn chỉnh và được quản lý hoàn toàn vượt trội hơn Kafka để những người giỏi nhất của bạn có thể tập trung vào việc mang lại giá trị cho doanh nghiệp của bạn.
- Tạo chủ đề:
- Đi tới Trang chủ và trên thanh bên
- Chuyển đến Môi trường sau đó nhấp vào Mặc định
- Đi đến các chủ đề

- chọn chủ đề mới đặt tên chủ đề

MongoDB
Tạo đăng ký và sau đó đăng nhập vào MongoDB Atlas và lưu liên kết kết nối của Mongodb Atlas để sử dụng tiếp.
Hướng dẫn từng bước để thiết lập dự án
- Cài đặt Python: Đảm bảo Python được cài đặt trên máy của bạn. Bạn có thể tải về và cài đặt Python từ trang web chính thức.
- Phiên bản conda: Kiểm tra phiên bản conda trong terminal.
- Tạo môi trường ảo: Tạo môi trường ảo bằng venv.
conda create -p venv python==3.10 -y- Kích hoạt môi trường ảo: Kích hoạt môi trường ảo:
conda activate venv/- Cài đặt các gói cần thiết: Sử dụng pip để cài đặt các phần phụ thuộc cần thiết được liệt kê trong tệp require.txt:
pip install -r requirements.txt- chúng ta phải đặt một số biến môi trường trong hệ thống cục bộ. Đây là Biến môi trường cụm đám mây hợp lưu
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
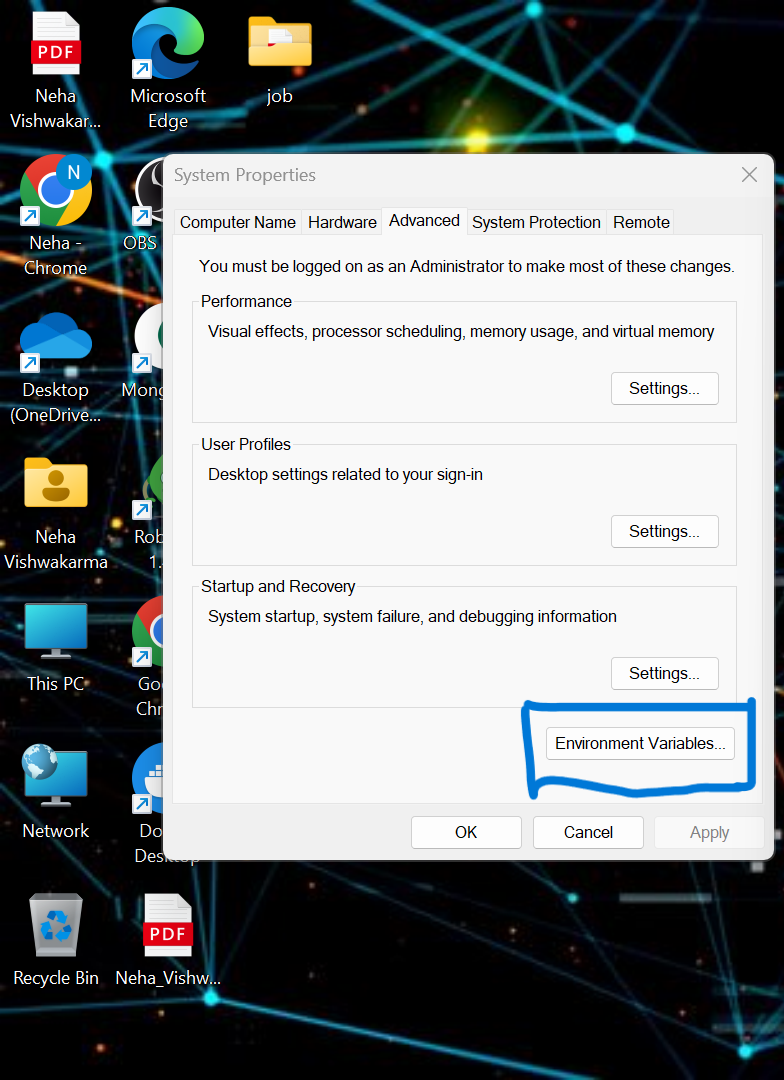
Cập nhật thông tin xác thực trong tệp .env và chạy lệnh bên dưới để chạy ứng dụng của bạn trong docker.
- Tạo tệp .env trong thư mục gốc của dự án của bạn nếu không có sẵn, dán nội dung bên dưới và cập nhật thông tin đăng nhập
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- Chạy tệp Nhà sản xuất và người tiêu dùng:
python producer_main.py
python consumer_main.pyLàm thế nào để triển khai mã?
- src/: Thư mục này là thư mục chính cho tất cả các tệp mã nguồn. Trong thư mục này, chúng ta có các thư mục con sau:
Consumer/: Thư mục này chứa mã cho Kafka_consumer, chịu trách nhiệm đọc dữ liệu từ các chủ đề Kafka và xử lý nó.
nhà sản xuất/: Thư mục này chứa mã cho Kafka_producer, chịu trách nhiệm tạo và gửi dữ liệu cảm biến đến các chủ đề Kafka. - README.md: Tệp Markdown này chứa tài liệu và hướng dẫn cho dự án, bao gồm tổng quan về mục đích của dự án, hướng dẫn, nguyên tắc sử dụng và bất kỳ thông tin nào.
- yêu cầu.txt: Tệp này liệt kê thư viện Python cần thiết cho dự án. Mỗi phần phụ thuộc được liệt kê cùng với số phiên bản của nó. Các công cụ như pip có thể sử dụng tệp này để tự động cài đặt các phụ thuộc cần thiết.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: Để kết nối MongoDB Altas thông qua liên kết, chúng tôi đang viết tập lệnh python
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
nhập URL của bạn được sao chép từ MongoDb Altas
Đầu ra:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
Tập tin này chạy sau đó chúng tôi gọi python nhà sản xuất_main.py và điều này sẽ gọi tập tin bên dưới:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
Đầu ra:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
Tập tin này chạy sau đó chúng tôi gọi python Consumer_main.py và điều này sẽ gọi tập tin bên dưới:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()Đầu ra:

Khi chúng tôi chạy cả người tiêu dùng và nhà sản xuất thì hệ thống sẽ chạy trên kafka và thông tin/dữ liệu được thu thập nhanh hơn

Đầu ra:
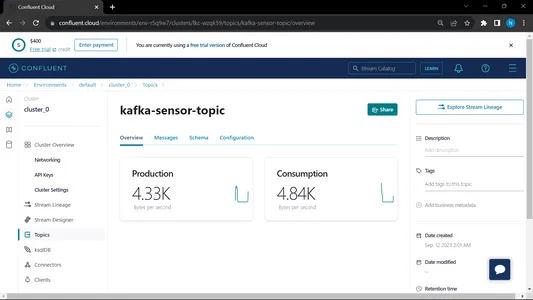
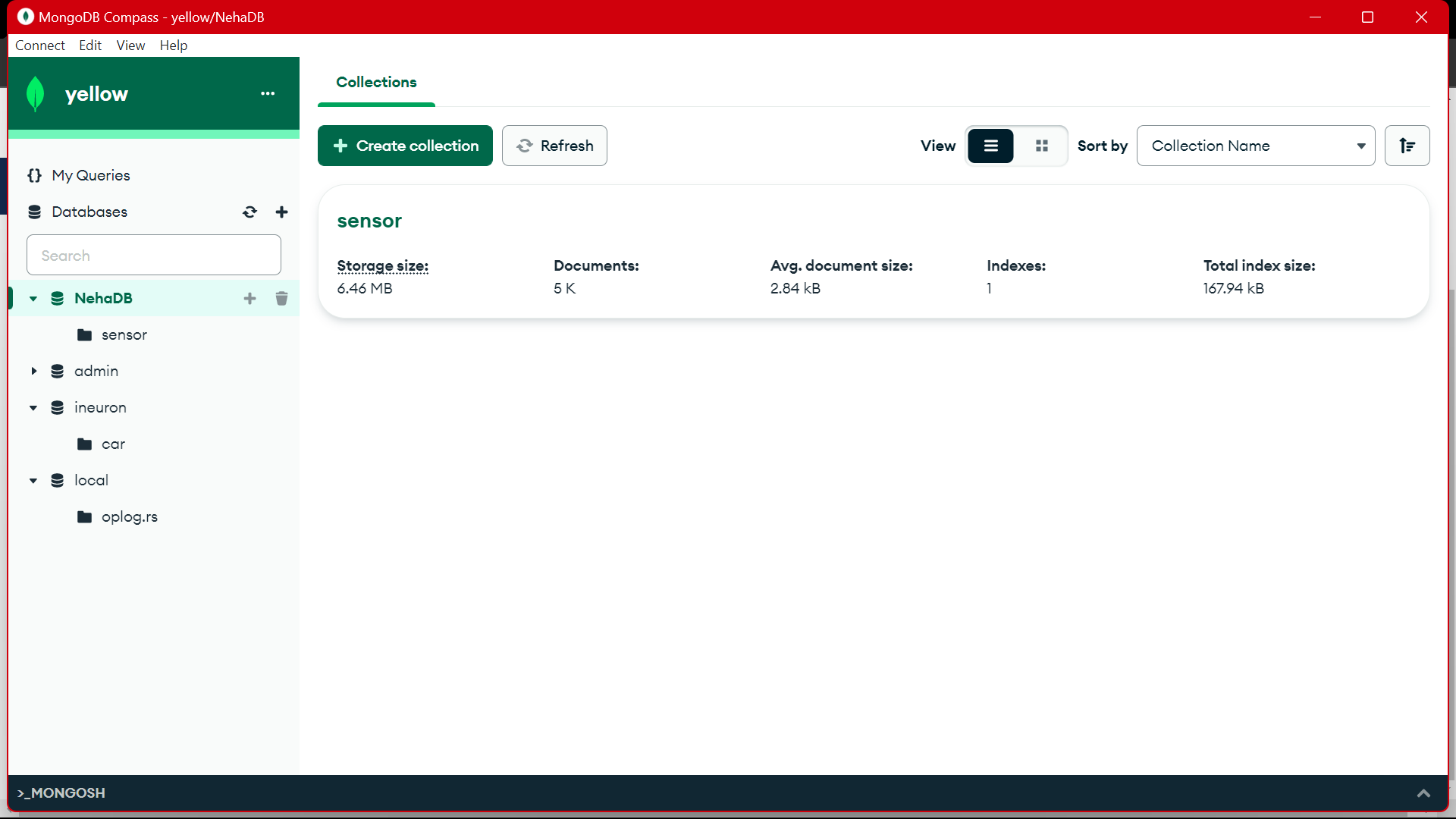
Từ MongoDB, chúng tôi đang sử dụng dữ liệu này để xử lý trước trong EDA, công việc kỹ thuật tính năng và phân tích dữ liệu được thực hiện trên dữ liệu này.
[Nhúng nội dung]
Kết luận
Trong bài viết này, chúng tôi hiểu cách chúng tôi lưu trữ và xử lý dữ liệu truyền phát từ cảm biến đến Kafka dưới dạng định dạng JSON, sau đó chúng tôi lưu trữ dữ liệu vào MongoDB. Chúng tôi biết rằng dữ liệu phát trực tuyến là dữ liệu được phát ra ở mức âm lượng lớn trong quá trình xử lý liên tục, điều đó có nghĩa là dữ liệu thay đổi mỗi giây. Chúng tôi đã tạo đường dẫn từ đầu đến cuối trong đó dữ liệu được tìm nạp với sự trợ giúp của API trong Đường ống và sau đó được thu thập trong Kafka dưới dạng chủ đề và sau đó được lưu trữ trong MongoDB từ đó chúng tôi có thể sử dụng nó trong dự án hoặc thực hiện kỹ thuật tính năng.
Chìa khóa chính
- Tìm hiểu dữ liệu phát trực tuyến là gì và cách xử lý dữ liệu phát trực tuyến với sự trợ giúp của Kafka.
- hiểu Nền tảng hợp lưu – Một bản phân phối Apache Kafka cấp doanh nghiệp, tự quản lý.
- lưu trữ dữ liệu được Kafka thu thập vào MongoDB, đây là cơ sở dữ liệu NoSQL lưu trữ dữ liệu phi cấu trúc.
- Tạo một đường dẫn hoàn chỉnh từ đầu đến cuối để tìm nạp và lưu trữ dữ liệu trong Cơ sở dữ liệu.
- hiểu chức năng của từng thành phần của dự án, triển khai nó trên docker và triển khai nó trên đám mây để sử dụng bất cứ lúc nào.
Thông tin
Những câu hỏi thường gặp
A. MongoDB lưu trữ dữ liệu ở dạng dữ liệu phi cấu trúc. dữ liệu phát trực tuyến là dạng dữ liệu phi cấu trúc để sử dụng bộ nhớ, chúng tôi đang sử dụng MongoDB làm cơ sở dữ liệu.
A. Mục đích là tạo ra một quy trình xử lý dữ liệu theo thời gian thực trong đó dữ liệu được nhập vào các chủ đề Kafka có thể được sử dụng, xử lý và lưu trữ trong MongoDB để phân tích, báo cáo hoặc sử dụng ứng dụng thêm.
A. Các trường hợp sử dụng bao gồm phân tích thời gian thực, xử lý dữ liệu IoT, tổng hợp nhật ký, giám sát phương tiện truyền thông xã hội và hệ thống đề xuất, trong đó dữ liệu truyền trực tuyến cần được xử lý và lưu trữ để phân tích thêm hoặc sử dụng ứng dụng.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

