Đây là một bài đăng trên blog của khách đồng viết với Minghui Yu và Jianzhe Xiao từ Bytedance.
ByteDance là một công ty công nghệ vận hành nhiều nền tảng nội dung để thông báo, giáo dục, giải trí và truyền cảm hứng cho mọi người trên khắp các ngôn ngữ, nền văn hóa và khu vực địa lý. Người dùng tin tưởng và tận hưởng nền tảng nội dung của chúng tôi vì trải nghiệm phong phú, trực quan và an toàn mà họ cung cấp. Những trải nghiệm này có thể thực hiện được nhờ công cụ phụ trợ học máy (ML) của chúng tôi, với các mô hình ML được xây dựng để kiểm duyệt nội dung, tìm kiếm, đề xuất, quảng cáo và hiệu ứng hình ảnh mới lạ.
Nhóm ByteDance AML (Học máy ứng dụng) cung cấp các hệ thống ML có hiệu suất cao, đáng tin cậy và có thể mở rộng cũng như các dịch vụ ML đầu cuối cho hoạt động kinh doanh của công ty. Chúng tôi đang nghiên cứu các cách tối ưu hóa hệ thống suy luận ML của mình để giảm chi phí mà không làm tăng thời gian phản hồi. Khi AWS ra mắt Suy luận AWS, chip suy luận ML hiệu suất cao do AWS xây dựng có mục đích, chúng tôi đã hợp tác với nhóm tài khoản AWS của mình để kiểm tra xem AWS Inferentia có thể giải quyết các mục tiêu tối ưu hóa của chúng tôi hay không. Chúng tôi đã chạy một số bằng chứng về khái niệm, dẫn đến chi phí suy luận thấp hơn tới 60% so với các phiên bản EC4 G2dn dựa trên GPU T4 và độ trễ suy luận thấp hơn tới 25%. Để hiện thực hóa những cải thiện về hiệu suất và tiết kiệm chi phí này, chúng tôi đã quyết định triển khai các mô hình trên nền tảng AWS Inferentia Đám mây điện toán đàn hồi Amazon (Amazon EC2) Phiên bản Inf1 trong sản xuất.
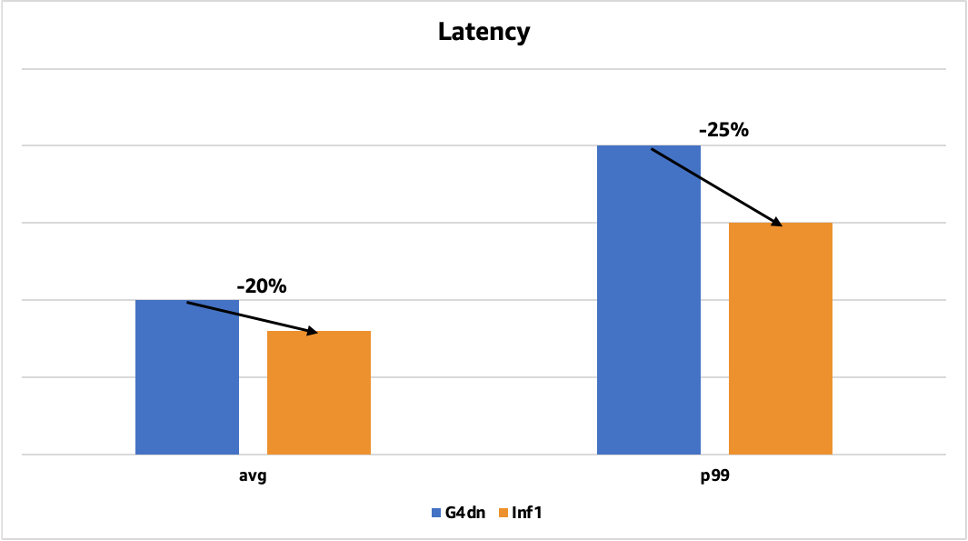
Biểu đồ sau đây cho thấy sự cải thiện độ trễ đối với một trong các mô hình nhận diện khuôn mặt của chúng tôi đã được triển khai trước đây trên GPU với Tensor RT. Độ trễ trung bình giảm 20% (từ 50 mili giây xuống 40 mili giây) và độ trễ p99 giảm 25% (từ 200 mili giây xuống 150 mili giây).
Trong bài đăng này, chúng tôi chia sẻ cách tiết kiệm chi phí suy luận đồng thời giảm độ trễ và tăng thông lượng bằng AWS Inferentia.
Tìm kiếm máy tính hiệu suất cao, tiết kiệm chi phí
Nhóm ByteDance AML tập trung vào nghiên cứu và triển khai các hệ thống ML tiên tiến cũng như các tài nguyên điện toán không đồng nhất mà chúng yêu cầu. Chúng tôi tạo ra các hệ thống suy luận và đào tạo quy mô lớn cho nhiều mô hình đề xuất, xử lý ngôn ngữ tự nhiên (NLP) và thị giác máy tính (CV). Các mô hình này rất phức tạp và xử lý một lượng dữ liệu khổng lồ từ nhiều nền tảng nội dung mà ByteDance vận hành. Việc triển khai các mô hình này yêu cầu tài nguyên GPU đáng kể, cho dù trên đám mây hay tại cơ sở. Do đó, chi phí tính toán cho các hệ thống suy luận này khá cao.
Chúng tôi đang tìm cách giảm các chi phí này mà không ảnh hưởng đến thông lượng hoặc độ trễ. Chúng tôi muốn tính linh hoạt của đám mây và chu kỳ phân phối nhanh hơn, ngắn hơn nhiều so với chu kỳ cần thiết cho thiết lập tại chỗ. Và mặc dù chúng tôi sẵn sàng khám phá các tùy chọn mới cho ML tăng tốc, nhưng chúng tôi cũng muốn có trải nghiệm liền mạch dành cho nhà phát triển.
Chúng tôi đã học được từ nhóm AWS của mình rằng các phiên bản EC2 Inf1 dựa trên AWS Inferentia mang lại khả năng suy luận ML hiệu suất cao với chi phí mỗi lần suy luận thấp nhất trên đám mây. Chúng tôi tò mò khám phá chúng và nhận thấy chúng rất phù hợp với trường hợp sử dụng của chúng tôi, bởi vì chúng tôi chạy máy học đáng kể trên một lượng lớn dữ liệu hình ảnh, đối tượng, lời nói và văn bản. Chúng chắc chắn rất phù hợp với các mục tiêu của chúng tôi, bởi vì chúng tôi có thể tiết kiệm được rất nhiều chi phí do tính phức tạp của các mô hình và khối lượng dự đoán hàng ngày của chúng tôi. Hơn nữa, AWS Inferentia có một lượng lớn bộ nhớ trên chip, bạn có thể sử dụng bộ nhớ này để lưu vào bộ nhớ đệm các mô hình lớn thay vì lưu trữ chúng bên ngoài chip. Chúng tôi nhận thấy rằng điều này có thể có tác động đáng kể trong việc giảm độ trễ suy luận vì các lõi xử lý của AWS Inferentia, được gọi là NeuronCores, có quyền truy cập tốc độ cao vào các mô hình được lưu trữ trong bộ nhớ trên chip và không bị giới hạn bởi bộ nhớ ngoài chip băng thông.
Cuối cùng, sau khi đánh giá một số tùy chọn, chúng tôi đã chọn các phiên bản EC2 Inf1 vì tỷ lệ hiệu suất/giá tốt hơn so với các phiên bản G4dn và NVIDIA T4 tại cơ sở. Chúng tôi đã tham gia vào một chu kỳ lặp lại liên tục với nhóm AWS để khám phá các lợi ích về giá và hiệu suất của Inf1.
Triển khai khối lượng công việc suy luận trên AWS Inferentia
Bắt đầu với AWS Inferentia bằng SDK AWS Neuron bao gồm hai giai đoạn: biên dịch mã mô hình và triển khai trên các phiên bản Inf1. Như thường lệ khi chuyển các mô hình ML sang bất kỳ cơ sở hạ tầng mới nào, có một số thách thức mà chúng tôi gặp phải. Chúng tôi đã có thể vượt qua những thách thức này nhờ sự siêng năng và hỗ trợ từ nhóm AWS của chúng tôi. Trong các phần sau, chúng tôi chia sẻ một số mẹo và quan sát hữu ích dựa trên kinh nghiệm của chúng tôi khi triển khai khối lượng công việc suy luận trên AWS Inferentia.
Mô hình tuân thủ cho OCR
Mô hình tuân thủ nhận dạng ký tự quang học (OCR) của chúng tôi phát hiện và đọc văn bản trong hình ảnh. Chúng tôi đã làm việc trên một số phương pháp tối ưu hóa để có được hiệu suất cao (QPS) cho nhiều kích cỡ lô khác nhau, trong khi vẫn giữ độ trễ thấp. Một số tối ưu hóa quan trọng được lưu ý dưới đây:
- Tối ưu hóa trình biên dịch – Theo mặc định, Inferentia hoạt động tốt nhất trên các đầu vào có độ dài chuỗi cố định, điều này gây ra thách thức vì độ dài của dữ liệu văn bản không cố định. Để khắc phục điều này, chúng tôi chia mô hình của mình thành hai phần: bộ mã hóa và bộ giải mã. Chúng tôi đã biên dịch hai mô hình con này một cách riêng biệt và sau đó hợp nhất chúng thành một mô hình duy nhất thông qua TorchScript. Bằng cách chạy luồng điều khiển vòng lặp for trên CPU, phương pháp này cho phép hỗ trợ độ dài chuỗi thay đổi trên Inferentia.
- Hiệu suất tích chập theo chiều sâu – Chúng tôi đã gặp phải nút cổ chai DMA trong hoạt động tích chập theo chiều sâu, vốn được mô hình tuân thủ của chúng tôi sử dụng nhiều. Chúng tôi đã hợp tác chặt chẽ với nhóm AWS Neuron để xác định và giải quyết tắc nghẽn hiệu suất truy cập DMA, giúp cải thiện hiệu suất của hoạt động này và cải thiện hiệu suất tổng thể của mô hình OCR của chúng tôi.
Chúng tôi đã tạo hai biến thể mô hình mới để tối ưu hóa việc triển khai của mình trên Inferentia:
- Bộ mã hóa/giải mã kết hợp và không kiểm soát – Thay vì sử dụng bộ mã hóa và bộ giải mã được biên dịch độc lập, chúng tôi đã kết hợp bộ mã hóa và bộ giải mã không được kiểm soát hoàn toàn thành một mô hình duy nhất và biên dịch mô hình này thành một NEFF duy nhất. Bỏ điều khiển bộ giải mã giúp có thể chạy tất cả luồng điều khiển bộ giải mã trên Inferentia mà không cần sử dụng bất kỳ thao tác CPU nào. Với cách tiếp cận này, mỗi lần lặp lại của bộ giải mã sử dụng chính xác lượng tính toán cần thiết cho mã thông báo đó. Cách tiếp cận này cải thiện hiệu suất vì chúng tôi giảm đáng kể lượng tính toán dư thừa đã được giới thiệu trước đây bằng các đầu vào đệm. Hơn nữa, không cần truyền dữ liệu từ Inferentia sang CPU giữa các lần lặp bộ giải mã, giúp giảm đáng kể thời gian I/O. Phiên bản này của mô hình không hỗ trợ dừng sớm.
- Bộ giải mã không kiểm soát được phân vùng – Tương tự như mô hình không kiểm soát hoàn toàn được kết hợp, biến thể của mô hình này sẽ hủy kiểm soát nhiều lần lặp của bộ giải mã và biên dịch chúng dưới dạng một lần thực thi duy nhất (nhưng không bao gồm bộ mã hóa). Ví dụ: đối với độ dài chuỗi tối đa là 75, chúng tôi có thể hủy đăng ký bộ giải mã thành 3 phân vùng tính toán mã thông báo 1-25, 26-50 và 51-75. Về I/O, tốc độ này cũng nhanh hơn đáng kể vì chúng tôi không cần chuyển đầu ra bộ mã hóa một lần cho mỗi lần lặp lại. Thay vào đó, các đầu ra chỉ được truyền một lần cho mỗi phân vùng bộ giải mã. Phiên bản này của mô hình hỗ trợ dừng sớm, nhưng chỉ ở ranh giới phân vùng. Ranh giới phân vùng có thể được điều chỉnh cho từng ứng dụng cụ thể để đảm bảo rằng phần lớn các yêu cầu chỉ thực hiện trên một phân vùng.
Để cải thiện hơn nữa hiệu suất, chúng tôi đã thực hiện các tối ưu hóa sau để giảm mức sử dụng bộ nhớ hoặc cải thiện hiệu quả truy cập:
- Tensor deduplication và các bản sao giảm – Đây là một trình tối ưu hóa trình biên dịch giúp giảm đáng kể kích thước của các mô hình không được kiểm soát và số lượng lệnh/truy cập bộ nhớ bằng cách sử dụng lại các tenxơ để cải thiện hiệu quả sử dụng không gian.
- hướng dẫn giảm – Đây là một tối ưu hóa trình biên dịch được sử dụng với phiên bản không đệm của bộ giải mã để giảm đáng kể tổng số lệnh.
- Chống trùng lặp đa lõi – Đây là một tối ưu hóa thời gian chạy thay thế cho tính năng chống trùng lặp tensor. Với tùy chọn này, tất cả các mô hình đa lõi sẽ tiết kiệm không gian hơn đáng kể.
Mô hình ResNet50 để phân loại hình ảnh
ResNet-50 là một mô hình học sâu được đào tạo trước để phân loại hình ảnh. Đó là Mạng thần kinh chuyển đổi (CNN hoặc ConvNet) được áp dụng phổ biến nhất để phân tích hình ảnh trực quan. Chúng tôi đã sử dụng các kỹ thuật sau để cải thiện hiệu suất của mô hình này trên Inferentia:
- chuyển đổi mô hình – Nhiều mô hình của ByteDance được xuất ở định dạng ONNX, định dạng mà Inferentia hiện không hỗ trợ. Để xử lý các mô hình ONNX này, nhóm AWS Neuron đã cung cấp các tập lệnh để chuyển đổi các mô hình của chúng tôi từ định dạng ONNX sang các mô hình PyTorch, có thể được biên dịch trực tiếp cho Inferentia bằng torch-neuron.
- Tối ưu hóa hiệu suất – Chúng tôi đã làm việc chặt chẽ với Tế bào thần kinh AWS nhóm để điều chỉnh phỏng đoán lập lịch trình trong trình biên dịch để tối ưu hóa hiệu suất của các mô hình ResNet-50 của chúng tôi.
Mô hình đa phương thức để kiểm duyệt nội dung
Mô hình deep learning đa phương thức của chúng tôi là sự kết hợp của nhiều mô hình riêng biệt. Kích thước của mô hình này tương đối lớn, điều này gây ra lỗi tải mô hình trên Inferentia. Nhóm AWS Neuron đã giải quyết thành công vấn đề này bằng cách sử dụng tính năng chia sẻ trọng lượng để giảm mức sử dụng bộ nhớ của thiết bị. Nhóm Neuron đã phát hành tính năng loại bỏ trùng lặp trọng số này trong thư viện Neuron libnrt và cũng cải tiến Công cụ Neuron để có các số liệu chính xác hơn. Có thể bật tính năng khử trùng lặp trọng số thời gian chạy bằng cách đặt biến môi trường sau trước khi chạy suy luận:
NEURON_RT_MULTI_INSTANCE_SHARED_WEIGHTS=1
SDK Neuron được cập nhật đã giảm mức tiêu thụ bộ nhớ tổng thể của các mô hình trùng lặp của chúng tôi, điều này cho phép chúng tôi triển khai mô hình đa phương thức của mình để suy luận đa lõi.
Di chuyển nhiều mô hình hơn sang AWS Inferentia
Tại ByteDance, chúng tôi tiếp tục triển khai các mô hình học sâu sáng tạo để mang lại trải nghiệm thú vị cho người dùng cho gần 2 tỷ người dùng hoạt động hàng tháng. Với quy mô lớn mà chúng tôi hoạt động, chúng tôi không ngừng tìm cách tiết kiệm chi phí và tối ưu hóa hiệu suất. Chúng tôi sẽ tiếp tục di chuyển các mô hình sang AWS Inferentia để hưởng lợi từ hiệu suất cao và tiết kiệm chi phí. Chúng tôi cũng muốn AWS khởi chạy nhiều loại phiên bản dựa trên AWS Inferentia hơn, chẳng hạn như những loại có nhiều vCPU hơn cho các tác vụ tiền xử lý. Trong tương lai, ByteDance hy vọng sẽ thấy nhiều cải tiến silicon hơn từ AWS để mang lại hiệu suất giá tốt nhất cho các ứng dụng ML.
Nếu bạn muốn tìm hiểu thêm về cách AWS Inferentia có thể giúp bạn tiết kiệm chi phí trong khi tối ưu hóa hiệu suất cho các ứng dụng suy luận của mình, hãy truy cập Phiên bản Amazon EC2 Inf1 trang sản phẩm.
Về các tác giả
 Minh Huệ là Trưởng nhóm học máy cao cấp về suy luận tại ByteDance. Lĩnh vực trọng tâm của anh ấy là Tăng tốc điện toán AI và Hệ thống máy học. Anh ấy rất quan tâm đến điện toán không đồng nhất và kiến trúc máy tính trong thời kỳ hậu Moore. Khi rảnh rỗi, anh ấy thích bóng rổ và bắn cung.
Minh Huệ là Trưởng nhóm học máy cao cấp về suy luận tại ByteDance. Lĩnh vực trọng tâm của anh ấy là Tăng tốc điện toán AI và Hệ thống máy học. Anh ấy rất quan tâm đến điện toán không đồng nhất và kiến trúc máy tính trong thời kỳ hậu Moore. Khi rảnh rỗi, anh ấy thích bóng rổ và bắn cung.
 Kiến Triết Tiêu là Trưởng nhóm kỹ sư phần mềm cao cấp trong Nhóm AML tại ByteDance. Công việc hiện tại của anh ấy tập trung vào việc giúp nhóm kinh doanh đẩy nhanh quá trình triển khai mô hình và cải thiện hiệu suất suy luận của mô hình. Ngoài công việc, anh ấy thích chơi piano.
Kiến Triết Tiêu là Trưởng nhóm kỹ sư phần mềm cao cấp trong Nhóm AML tại ByteDance. Công việc hiện tại của anh ấy tập trung vào việc giúp nhóm kinh doanh đẩy nhanh quá trình triển khai mô hình và cải thiện hiệu suất suy luận của mô hình. Ngoài công việc, anh ấy thích chơi piano.
 thiên sư là Kiến trúc sư giải pháp cấp cao tại AWS. Lĩnh vực trọng tâm của anh ấy là phân tích dữ liệu, máy học và serverless. Anh ấy đam mê giúp khách hàng thiết kế và xây dựng các giải pháp đáng tin cậy và có thể mở rộng trên đám mây. Trong thời gian rảnh rỗi, anh ấy thích bơi lội và đọc sách.
thiên sư là Kiến trúc sư giải pháp cấp cao tại AWS. Lĩnh vực trọng tâm của anh ấy là phân tích dữ liệu, máy học và serverless. Anh ấy đam mê giúp khách hàng thiết kế và xây dựng các giải pháp đáng tin cậy và có thể mở rộng trên đám mây. Trong thời gian rảnh rỗi, anh ấy thích bơi lội và đọc sách.
 Giả Đông là Giám đốc giải pháp khách hàng tại AWS. Cô thích tìm hiểu về các dịch vụ AI/ML của AWS và giúp khách hàng đạt được kết quả kinh doanh bằng cách xây dựng các giải pháp cho họ. Ngoài công việc, Jia thích đi du lịch, tập Yoga và xem phim.
Giả Đông là Giám đốc giải pháp khách hàng tại AWS. Cô thích tìm hiểu về các dịch vụ AI/ML của AWS và giúp khách hàng đạt được kết quả kinh doanh bằng cách xây dựng các giải pháp cho họ. Ngoài công việc, Jia thích đi du lịch, tập Yoga và xem phim.
 Jonathan Lunt là một kỹ sư phần mềm tại Amazon, tập trung vào phát triển khung ML. Trong sự nghiệp của mình, anh ấy đã làm việc với đầy đủ các vai trò khoa học dữ liệu bao gồm phát triển mô hình, triển khai cơ sở hạ tầng và tối ưu hóa dành riêng cho phần cứng.
Jonathan Lunt là một kỹ sư phần mềm tại Amazon, tập trung vào phát triển khung ML. Trong sự nghiệp của mình, anh ấy đã làm việc với đầy đủ các vai trò khoa học dữ liệu bao gồm phát triển mô hình, triển khai cơ sở hạ tầng và tối ưu hóa dành riêng cho phần cứng.
 Joshua Hannan là một kỹ sư máy học tại Amazon. Anh làm việc về việc tối ưu hóa các mô hình học sâu cho các ứng dụng xử lý ngôn ngữ tự nhiên và thị giác máy tính quy mô lớn.
Joshua Hannan là một kỹ sư máy học tại Amazon. Anh làm việc về việc tối ưu hóa các mô hình học sâu cho các ứng dụng xử lý ngôn ngữ tự nhiên và thị giác máy tính quy mô lớn.
 Shruti Koparkar là Giám đốc Tiếp thị Sản phẩm Cấp cao tại AWS. Cô ấy giúp khách hàng khám phá, đánh giá và áp dụng cơ sở hạ tầng điện toán tăng tốc EC2 cho nhu cầu học máy của họ.
Shruti Koparkar là Giám đốc Tiếp thị Sản phẩm Cấp cao tại AWS. Cô ấy giúp khách hàng khám phá, đánh giá và áp dụng cơ sở hạ tầng điện toán tăng tốc EC2 cho nhu cầu học máy của họ.
- Coinsmart. Sàn giao dịch Bitcoin và tiền điện tử tốt nhất Châu Âu.Bấm vào đây
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/bytedance-saves-up-to-60-on-inference-costs-while-reducing-latency-and-increasing-throughput-using-aws-inferentia/

