Giới thiệu
Retrieval Augmented-Generation (RAG) đã được Storm chiếm lĩnh thế giới kể từ khi thành lập. RAG là những gì cần thiết để Mô hình ngôn ngữ lớn (LLM) cung cấp hoặc tạo ra các câu trả lời chính xác và thực tế. Chúng tôi giải quyết tính xác thực của LLM bằng RAG, trong đó chúng tôi cố gắng cung cấp cho LLM một ngữ cảnh tương tự về mặt ngữ cảnh với truy vấn của người dùng để LLM sẽ hoạt động với ngữ cảnh này và tạo ra phản hồi chính xác về mặt thực tế. Chúng tôi thực hiện điều này bằng cách biểu diễn dữ liệu và truy vấn của người dùng dưới dạng nhúng vectơ và thực hiện phép tương tự cosine. Nhưng vấn đề là tất cả các cách tiếp cận truyền thống đều thể hiện dữ liệu trong một lần nhúng duy nhất, điều này có thể không lý tưởng cho mục đích tốt. hệ thống truy xuất. Trong hướng dẫn này, chúng ta sẽ xem xét ColBERT thực hiện truy xuất với độ chính xác cao hơn các mô hình bộ mã hóa hai truyền thống.
Mục tiêu học tập
- Hiểu cách hoạt động truy xuất trong RAG ở mức cao.
- Hiểu các giới hạn nhúng đơn trong truy xuất.
- Cải thiện bối cảnh truy xuất bằng cách nhúng mã thông báo của ColBERT.
- Tìm hiểu cách tương tác muộn của ColBERT cải thiện khả năng truy xuất.
- Tìm hiểu cách làm việc với ColBERT để truy xuất chính xác.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
RAG là gì?
LLM, mặc dù có khả năng tạo ra văn bản vừa có ý nghĩa vừa đúng ngữ pháp, nhưng những LLM này lại gặp phải một vấn đề gọi là ảo giác. Ảo giác trong LLM là khái niệm mà LLM tự tin đưa ra các câu trả lời sai, tức là họ bịa ra các câu trả lời sai theo cách khiến chúng tôi tin rằng đó là sự thật. Đây là một vấn đề lớn kể từ khi LLM được giới thiệu. Những ảo giác này dẫn đến những câu trả lời sai và sai về mặt thực tế. Do đó Thế hệ tăng cường truy xuất đã được giới thiệu.
Trong RAG, chúng tôi lấy danh sách các tài liệu/khối tài liệu và mã hóa các tài liệu văn bản này thành một biểu diễn bằng số gọi là nhúng vectơ, trong đó một vectơ nhúng đại diện cho một đoạn tài liệu và lưu trữ chúng trong cơ sở dữ liệu có tên là cửa hàng vector. Các mô hình cần thiết để mã hóa các đoạn này thành các phần nhúng được gọi là mô hình mã hóa hoặc bộ mã hóa kép. Các bộ mã hóa này được đào tạo trên một kho dữ liệu lớn, do đó làm cho chúng đủ mạnh để mã hóa các khối tài liệu trong một biểu diễn nhúng vectơ duy nhất.
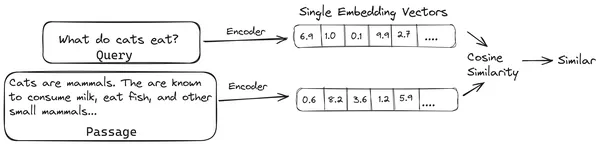
Bây giờ, khi người dùng yêu cầu một truy vấn tới LLM, thì chúng tôi sẽ cung cấp truy vấn này cho cùng một bộ mã hóa để tạo ra một vectơ nhúng duy nhất. Việc nhúng này sau đó được sử dụng để tính điểm tương tự với nhiều cách nhúng vectơ khác của các đoạn tài liệu để có được đoạn tài liệu phù hợp nhất. Đoạn phù hợp nhất hoặc danh sách các đoạn phù hợp nhất cùng với truy vấn của người dùng được cung cấp cho LLM. Sau đó, LLM sẽ nhận được thông tin ngữ cảnh bổ sung này và sau đó tạo ra câu trả lời phù hợp với ngữ cảnh nhận được từ truy vấn của người dùng. Điều này đảm bảo rằng nội dung do LLM tạo ra là thực tế và có thể truy nguyên nội dung đó nếu cần thiết.
Vấn đề với bộ mã hóa hai truyền thống
Vấn đề với các mẫu Bộ mã hóa truyền thống như all-miniLM, OpenAI mô hình nhúng và các mô hình mã hóa khác là chúng nén toàn bộ văn bản thành một biểu diễn nhúng vectơ duy nhất. Các biểu diễn nhúng vectơ đơn này rất hữu ích vì chúng giúp truy xuất hiệu quả và nhanh chóng các tài liệu tương tự. Tuy nhiên, vấn đề nằm ở bối cảnh giữa truy vấn và tài liệu. Việc nhúng vectơ đơn lẻ có thể không đủ để lưu trữ thông tin theo ngữ cảnh của một đoạn tài liệu, do đó tạo ra nút thắt cổ chai thông tin.
Hãy tưởng tượng rằng 500 từ đang được nén thành một vectơ duy nhất có kích thước 782. Việc biểu diễn một đoạn như vậy bằng một vectơ nhúng duy nhất có thể là không đủ, do đó mang lại kết quả truy xuất dưới tiêu chuẩn trong hầu hết các trường hợp. Biểu diễn vectơ đơn cũng có thể không thành công trong trường hợp truy vấn hoặc tài liệu phức tạp. Một giải pháp như vậy là biểu diễn đoạn tài liệu hoặc một truy vấn dưới dạng danh sách các vectơ nhúng thay vì một vectơ nhúng duy nhất, đây là lúc ColBERT xuất hiện.
ColBERT là gì?
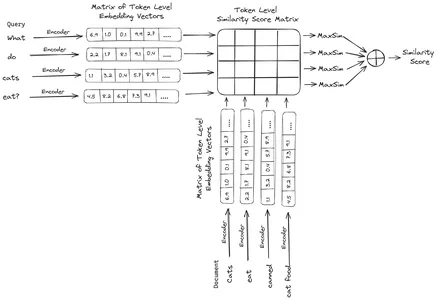
ColBERT (BERT tương tác muộn theo ngữ cảnh) là một bộ mã hóa hai chiều biểu thị văn bản dưới dạng biểu diễn nhúng nhiều vectơ. Nó nhận một Truy vấn hoặc một đoạn Tài liệu/một Tài liệu nhỏ và tạo các phần nhúng vectơ ở cấp mã thông báo. Nghĩa là mỗi mã thông báo có nhúng vectơ riêng và truy vấn/tài liệu được mã hóa thành danh sách nhúng vectơ cấp mã thông báo. Việc nhúng cấp độ mã thông báo được tạo từ một chương trình được đào tạo trước Chứng nhận mô hình do đó có tên BERT.
Sau đó chúng được lưu trữ trong cơ sở dữ liệu vector. Bây giờ, khi có một truy vấn xuất hiện, một danh sách nhúng cấp mã thông báo sẽ được tạo cho truy vấn đó và sau đó phép nhân ma trận được thực hiện giữa truy vấn của người dùng và từng tài liệu, do đó tạo ra một ma trận chứa điểm tương tự. Độ tương tự tổng thể đạt được bằng cách lấy tổng độ tương tự tối đa giữa các mã thông báo tài liệu cho mỗi mã thông báo truy vấn. Công thức cho điều này có thể được nhìn thấy trong hình dưới đây:
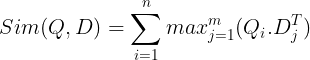
Ở đây trong phương trình trên, chúng ta thấy rằng chúng ta thực hiện tích số chấm giữa Ma trận mã thông báo truy vấn (chứa N phần nhúng vectơ cấp mã thông báo) và Ma trận chuyển đổi mã thông báo tài liệu (chứa phần nhúng vectơ cấp mã thông báo M), sau đó chúng tôi lấy độ tương tự tối đa vượt qua các mã thông báo tài liệu cho mỗi mã thông báo truy vấn. Sau đó, chúng tôi lấy tổng của tất cả những điểm tương đồng tối đa này để cho chúng tôi điểm tương đồng cuối cùng giữa tài liệu và truy vấn. Lý do tại sao điều này mang lại khả năng truy xuất hiệu quả và chính xác là ở đây chúng ta đang có sự tương tác ở cấp độ mã thông báo, mang lại không gian để hiểu rõ hơn về ngữ cảnh giữa truy vấn và tài liệu.
Tại sao tên ColBERT?
Vì chúng tôi đang tính toán danh sách các vectơ nhúng trước chính nó và chỉ thực hiện thao tác MaxSim (độ tương tự tối đa) này trong quá trình suy luận mô hình, do đó gọi đó là bước tương tác muộn và vì chúng tôi đang nhận được nhiều thông tin theo ngữ cảnh hơn thông qua các tương tác ở cấp độ mã thông báo, nên nó được gọi là theo ngữ cảnh tương tác muộn. Do đó, tên Tương tác muộn theo ngữ cảnh Chứng nhận hoặc ColBERT. Những tính toán này có thể được thực hiện song song, do đó chúng có thể được tính toán một cách hiệu quả. Cuối cùng, một mối quan tâm là không gian, tức là cần nhiều không gian để lưu trữ danh sách nhúng vectơ cấp mã thông báo này. Vấn đề này đã được giải quyết trong ColBERTv2, trong đó các phần nhúng được nén thông qua kỹ thuật được gọi là nén dư, do đó tối ưu hóa không gian được sử dụng.
ColBERT thực hành với ví dụ
Trong phần này, chúng ta sẽ thực hành ColBERT và thậm chí kiểm tra xem nó hoạt động như thế nào so với mô hình nhúng thông thường.
Bước 1: Tải xuống thư viện
Chúng ta sẽ bắt đầu bằng cách tải xuống thư viện sau:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Thư viện này cho phép chúng tôi làm việc với các phương pháp truy xuất hiện đại (SOTA) như ColBERT theo cách dễ sử dụng. Nó cung cấp các tùy chọn để tạo chỉ mục trên các tập dữ liệu, truy vấn chúng và thậm chí cho phép chúng tôi đào tạo mô hình ColBERT trên dữ liệu của mình.
- LangChain: Thư viện này sẽ cho phép chúng tôi làm việc với các mô hình nhúng nguồn mở để chúng tôi có thể kiểm tra xem các mô hình nhúng khác hoạt động tốt như thế nào khi so sánh với ColBERT.
- langchain_openai: Cài đặt LangChain phụ thuộc cho OpenAI. Chúng tôi thậm chí sẽ làm việc với mô hình Nhúng OpenAI để kiểm tra hiệu suất của nó so với ColBERT.
- ChromaDB: Thư viện này sẽ cho phép chúng tôi tạo một kho lưu trữ vectơ trong môi trường của mình để chúng tôi có thể lưu các phần nhúng mà chúng tôi đã tạo trên dữ liệu của mình và sau đó thực hiện tìm kiếm ngữ nghĩa giữa truy vấn và các phần nhúng được lưu trữ.
- einops: Thư viện này cần thiết để nhân ma trận tensor hiệu quả.
- người biến câu và tikitoken thư viện là cần thiết để các mô hình nhúng nguồn mở hoạt động bình thường.
Bước 2: Tải xuống mô hình được đào tạo trước
Trong bước tiếp theo, chúng tôi sẽ tải xuống mô hình ColBERT đã được đào tạo trước. Đối với điều này, mã sẽ là
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Trước tiên, chúng tôi nhập lớp RAGPretrainModel từ thư viện RAGatouille.
- Sau đó, chúng tôi gọi .from_pretrain() và đặt tên mô hình, tức là “colbert-ir/colbertv2.0”.
Việc chạy mã ở trên sẽ khởi tạo mô hình ColBERT RAG. Bây giờ hãy tải xuống một trang Wikipedia và thực hiện truy xuất từ đó. Đối với điều này, mã sẽ là:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille đi kèm với một hàm tiện dụng được gọi là get_wikipedia_page, hàm này nhận vào một chuỗi và lấy trang Wikipedia tương ứng. Ở đây chúng tôi tải xuống nội dung Wikipedia về Elon Musk và lưu trữ nó trong tài liệu biến. Hãy in số từ có trong tài liệu và một vài dòng đầu tiên của tài liệu.
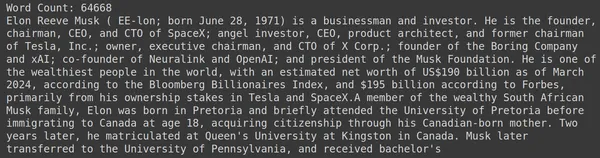
Ở đây chúng ta có thể thấy đầu ra trong hình. Chúng ta có thể thấy trang Wikipedia của Elon Musk có tổng cộng 64,668 từ.
Bước 3: Lập chỉ mục
Bây giờ chúng ta sẽ tạo một chỉ mục trên tài liệu này.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Ở đây chúng ta gọi .index() của RAG để lập chỉ mục cho tài liệu của mình. Về vấn đề này, chúng tôi chuyển như sau:
- bộ sưu tập: Đây là danh sách các tài liệu mà chúng tôi muốn lập chỉ mục. Ở đây chúng tôi chỉ có một tài liệu, do đó có một danh sách một tài liệu.
- tài liệu_ids: Mỗi tài liệu yêu cầu một ID tài liệu duy nhất. Ở đây chúng tôi đặt tên là elon_musk vì tài liệu nói về Elon Musk.
- tài liệu_siêu dữ liệu: Mỗi tài liệu đều có siêu dữ liệu của nó. Đây lại là danh sách các từ điển, trong đó mỗi từ điển chứa siêu dữ liệu cặp khóa-giá trị cho một tài liệu cụ thể.
- tên_chỉ mục: Tên của chỉ mục mà chúng tôi đang tạo. Hãy đặt tên nó là Elon2.
- max_document_size: Điều này tương tự như kích thước chunk. Chúng tôi chỉ định mỗi đoạn tài liệu nên có bao nhiêu. Ở đây chúng ta gán cho nó giá trị 256. Nếu chúng ta không chỉ định bất kỳ giá trị nào, 256 sẽ được lấy làm kích thước chunk mặc định.
- chia_tài liệu: Đó là một giá trị boolean, trong đó True biểu thị rằng chúng tôi muốn chia tài liệu của mình theo kích thước khối nhất định và Sai cho biết rằng chúng tôi muốn lưu trữ toàn bộ tài liệu dưới dạng một khối duy nhất.
Việc chạy mã ở trên sẽ chia tài liệu của chúng ta thành các kích thước 256 mỗi đoạn, sau đó nhúng chúng thông qua mô hình ColBERT, mô hình này sẽ tạo ra danh sách các vectơ nhúng cấp mã thông báo cho mỗi đoạn và cuối cùng lưu trữ chúng trong một chỉ mục. Bước này sẽ mất một chút thời gian để chạy và có thể được tăng tốc nếu có GPU. Cuối cùng, nó tạo một thư mục nơi lưu trữ chỉ mục của chúng tôi. Ở đây thư mục sẽ là “.ragatouille/colbert/indexes/Elon2”
Bước 4: Truy vấn chung
Bây giờ, chúng ta sẽ bắt đầu tìm kiếm. Đối với điều này, mã sẽ là
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Đầu tiên, ở đây chúng ta gọi phương thức .search() của đối tượng RAG
- Để làm điều này, chúng tôi đưa ra các biến bao gồm tên truy vấn, k (số lượng tài liệu cần truy xuất) và tên chỉ mục để tìm kiếm
- Ở đây chúng tôi cung cấp truy vấn “Elon Musk đã tìm thấy những công ty nào?”. Kết quả thu được sẽ ở dạng danh sách định dạng từ điển, trong đó chứa các khóa như nội dung, điểm, thứ hạng, document_id, pass_id và document_metadata
- Do đó, chúng tôi làm việc với mã bên dưới để in các tài liệu được truy xuất một cách gọn gàng
- Ở đây chúng ta đi qua danh sách từ điển và in nội dung của tài liệu
Chạy code sẽ cho kết quả như sau:
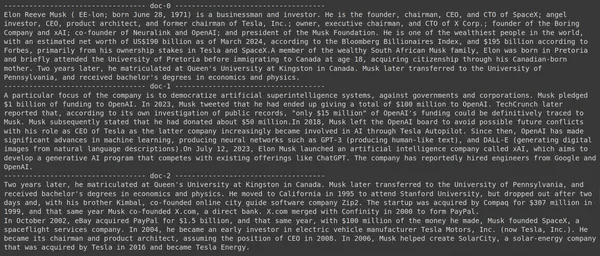
Trong ảnh, chúng ta có thể thấy rằng tài liệu đầu tiên và cuối cùng hoàn toàn đề cập đến các công ty khác nhau do Elon Musk thành lập. ColBERT có thể truy xuất chính xác các đoạn có liên quan cần thiết để trả lời truy vấn.
Bước 5: Truy vấn cụ thể
Bây giờ chúng ta hãy tiến thêm một bước nữa và hỏi nó một câu hỏi cụ thể.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])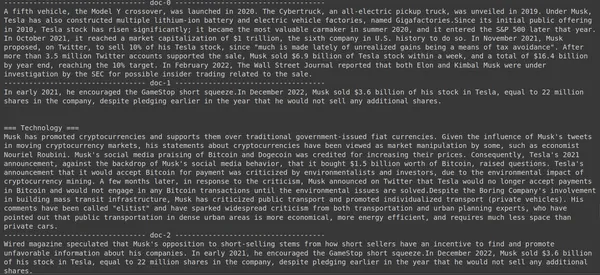
Ở đây, trong đoạn mã trên, chúng tôi đang đặt một câu hỏi rất cụ thể về số lượng cổ phiếu trị giá mà Tesla Elon đã bán được trong tháng 2022 năm 1. Chúng tôi có thể xem kết quả đầu ra ở đây. Tài liệu-3.6 chứa câu trả lời cho câu hỏi. Elon đã bán số cổ phiếu trị giá XNUMX tỷ USD của mình ở Tesla. Một lần nữa, ColBERT đã có thể truy xuất thành công đoạn có liên quan cho truy vấn đã cho.
Bước 6: Thử nghiệm các mô hình khác
Bây giờ chúng ta hãy thử câu hỏi tương tự với các mô hình nhúng khác cả nguồn mở và đóng tại đây:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Trước tiên, chúng tôi bắt đầu bằng cách tải xuống mô hình thông qua lớp AutoModel từ thư viện Transformers.
- Sau đó, chúng tôi lưu trữ model_name và model_kwargs trong các biến tương ứng của chúng.
- Bây giờ để làm việc với mô hình này trong LangChain, chúng tôi nhập HuggingFaceEmbeddings từ LangChain và đặt tên model và model_kwargs.
Chạy mã này sẽ tải xuống và tải mô hình nhúng Jina để chúng ta có thể làm việc với nó
Bước 7: Tạo phần nhúng
Bây giờ, chúng ta cần bắt đầu tách tài liệu của mình, sau đó tạo các phần nhúng từ đó và lưu trữ chúng trong kho vectơ Chroma. Đối với điều này, chúng tôi làm việc với đoạn mã sau:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Chúng tôi bắt đầu bằng cách nhập Chroma và RecursiveCharacterTextSplitter từ thư viện LangChain
- Sau đó, chúng tôi khởi tạo một text_splitter bằng cách gọi .from_tiktoken_encoding của RecursiveCharacterTextSplitter và chuyển nó chunk_size và chunk_overlap
- Ở đây chúng ta sẽ sử dụng cùng chunk_size mà chúng ta đã cung cấp cho ColBERT
- Sau đó, chúng tôi gọi phương thức .split_text() của text_splitter này và cung cấp cho nó tài liệu chứa thông tin Wikipedia về Elon Musk. Sau đó, nó phân chia tài liệu dựa trên kích thước khối nhất định và cuối cùng, danh sách các Khối tài liệu được lưu trữ trong các phần chia biến
- Cuối cùng, chúng ta gọi hàm .from_texts() của lớp Chroma để tạo một kho lưu trữ vectơ. Đối với chức năng này, chúng tôi cung cấp các phần tách, mô hình nhúng và tên_bộ sưu tập
- Bây giờ, chúng ta tạo một công cụ truy xuất từ nó bằng cách gọi hàm .as_retriever() của đối tượng lưu trữ vector. Chúng tôi đưa ra 3 cho giá trị k
Việc chạy mã này sẽ lấy tài liệu của chúng ta, chia nó thành các tài liệu nhỏ hơn có kích thước 256 mỗi đoạn, sau đó nhúng các đoạn nhỏ hơn này bằng mô hình nhúng Jina và lưu trữ các vectơ nhúng này trong kho vectơ sắc độ.
Bước 8: Tạo một Retriever
Cuối cùng, chúng tôi tạo ra một chú chó tha mồi từ nó. Bây giờ chúng ta sẽ thực hiện tìm kiếm vector và kiểm tra kết quả.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)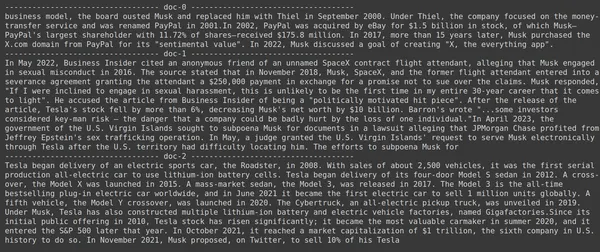
- Chúng tôi gọi hàm .get_relevent_documents() của đối tượng truy xuất và đưa ra truy vấn tương tự.
- Sau đó, chúng tôi in gọn gàng 3 tài liệu được truy xuất hàng đầu.
- Trong ảnh, chúng ta có thể thấy rằng Jina Embedder mặc dù là một mô hình nhúng phổ biến nhưng khả năng truy xuất truy vấn của chúng tôi rất kém. Nó đã không thành công trong việc lấy được các đoạn tài liệu chính xác.
Chúng ta có thể nhận thấy rõ sự khác biệt giữa Jina, mô hình nhúng biểu thị mỗi đoạn dưới dạng một vectơ nhúng duy nhất và mô hình ColBERT biểu thị mỗi đoạn dưới dạng danh sách các vectơ nhúng cấp mã thông báo. ColBERT rõ ràng hoạt động tốt hơn trong trường hợp này.
Bước 9: Kiểm tra mô hình nhúng của OpenAI
Bây giờ hãy thử sử dụng mô hình nhúng nguồn đóng như mô hình Nhúng OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Đoạn mã này rất giống với đoạn mã chúng ta vừa viết
- Sự khác biệt duy nhất là chúng tôi chuyển khóa API OpenAI để đặt biến môi trường.
- Sau đó, chúng tôi tạo một phiên bản của mô hình Nhúng OpenAI bằng cách nhập nó từ LangChain.
- Và trong khi tạo tên bộ sưu tập, chúng tôi đặt một tên bộ sưu tập khác để các phần nhúng từ mô hình Nhúng OpenAI được lưu trữ trong một bộ sưu tập khác.
Việc chạy mã này sẽ lấy lại các tài liệu của chúng ta, chia chúng thành các tài liệu nhỏ hơn có kích thước 256, sau đó nhúng chúng vào biểu diễn nhúng vectơ đơn bằng mô hình nhúng OpenAI và cuối cùng lưu trữ các phần nhúng này trong Cửa hàng Vector Chroma. Bây giờ hãy thử truy xuất các tài liệu liên quan đến câu hỏi khác.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)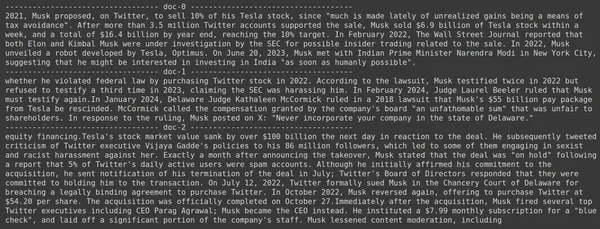
- Chúng tôi thấy rằng câu trả lời mà chúng tôi mong đợi không được tìm thấy trong các đoạn được truy xuất.
- Đoạn một chứa thông tin về cổ phiếu Tesla vào năm 2022 nhưng không nói về việc Elon bán chúng.
- Điều tương tự cũng có thể thấy với hai đoạn tài liệu còn lại, trong đó thông tin chứa về Tesla và cổ phiếu của nó nhưng đây không phải là thông tin mà chúng tôi mong đợi.
- Các đoạn được truy xuất ở trên sẽ không cung cấp ngữ cảnh để LLM trả lời truy vấn mà chúng tôi đã cung cấp.
Ngay cả ở đây, chúng ta có thể thấy sự khác biệt rõ ràng giữa biểu diễn nhúng một vectơ và biểu diễn nhúng nhiều vectơ. Các biểu diễn đa nhúng nắm bắt rõ ràng các truy vấn phức tạp mang lại kết quả truy xuất chính xác hơn.
Kết luận
Tóm lại, ColBERT thể hiện sự tiến bộ đáng kể về hiệu suất truy xuất so với các mô hình bộ mã hóa hai truyền thống bằng cách biểu diễn văn bản dưới dạng nhúng nhiều vectơ ở cấp mã thông báo. Cách tiếp cận này cho phép hiểu biết theo ngữ cảnh nhiều sắc thái hơn giữa các truy vấn và tài liệu, dẫn đến kết quả truy xuất chính xác hơn và giảm thiểu vấn đề ảo giác thường thấy trong LLM.
Chìa khóa chính
- RAG giải quyết vấn đề ảo giác trong LLM bằng cách cung cấp thông tin theo ngữ cảnh để tạo ra câu trả lời thực tế.
- Bộ mã hóa sinh học truyền thống gặp phải tình trạng tắc nghẽn thông tin do nén toàn bộ văn bản vào các phần nhúng vectơ duy nhất, dẫn đến độ chính xác truy xuất dưới mức trung bình.
- ColBERT, với cách trình bày nhúng ở cấp độ mã thông báo, tạo điều kiện hiểu biết ngữ cảnh tốt hơn giữa các truy vấn và tài liệu, dẫn đến hiệu suất truy xuất được cải thiện.
- Bước tương tác muộn trong ColBERT, kết hợp với các tương tác ở cấp độ mã thông báo, sẽ nâng cao độ chính xác của việc truy xuất bằng cách xem xét các sắc thái ngữ cảnh.
- ColBERTv2 tối ưu hóa không gian lưu trữ thông qua việc nén dư trong khi vẫn duy trì hiệu quả truy xuất.
- Các thử nghiệm thực hành chứng minh tính vượt trội của ColBERT về hiệu suất truy xuất so với các mô hình nhúng truyền thống và mã nguồn mở như Jina và OpenAI Embedding.
Những câu hỏi thường gặp
A. Bộ mã hóa sinh học truyền thống nén toàn bộ văn bản thành các phần nhúng vectơ duy nhất, có khả năng làm mất thông tin theo ngữ cảnh. Điều này hạn chế tính hiệu quả của chúng trong các tác vụ truy xuất, đặc biệt với các truy vấn hoặc tài liệu phức tạp.
A. ColBERT (BERT tương tác muộn theo ngữ cảnh) là mô hình mã hóa hai chiều thể hiện văn bản bằng cách sử dụng các phần nhúng vectơ cấp mã thông báo. Nó cho phép hiểu rõ hơn về ngữ cảnh giữa các truy vấn và tài liệu, cải thiện độ chính xác khi truy xuất.
A. ColBERT tạo các phần nhúng cấp mã thông báo cho các truy vấn và tài liệu, thực hiện phép nhân ma trận để tính điểm tương tự, sau đó chọn thông tin phù hợp nhất dựa trên độ tương tự tối đa giữa các mã thông báo. Điều này cho phép truy xuất hiệu quả với sự hiểu biết theo ngữ cảnh.
A. ColBERTv2 tối ưu hóa Không gian thông qua phương pháp nén dư, giảm yêu cầu lưu trữ cho các phần nhúng cấp mã thông báo trong khi vẫn duy trì độ chính xác khi truy xuất.
Đáp Bạn có thể sử dụng các thư viện như RAGatouille để làm việc với ColBERT một cách dễ dàng. Bằng cách lập chỉ mục các tài liệu và truy vấn, bạn có thể thực hiện các tác vụ truy xuất hiệu quả và tạo ra các câu trả lời chính xác phù hợp với ngữ cảnh.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

