Đã có những tiến bộ to lớn trong lĩnh vực học sâu phân tán cho các mô hình ngôn ngữ lớn (LLM), đặc biệt là sau khi phát hành ChatGPT vào tháng 2022 năm 5.32. LLM tiếp tục tăng quy mô với hàng tỷ, thậm chí hàng nghìn tỷ tham số và chúng thường không tăng phù hợp với một thiết bị tăng tốc duy nhất như GPU hoặc thậm chí một nút duy nhất như ml.p3xlarge do hạn chế về bộ nhớ. Khách hàng đào tạo LLM thường phải phân phối khối lượng công việc của họ trên hàng trăm hoặc thậm chí hàng nghìn GPU. Việc cho phép đào tạo ở quy mô như vậy vẫn là một thách thức trong đào tạo phân tán và đào tạo hiệu quả trong một hệ thống lớn như vậy là một vấn đề quan trọng không kém khác. Trong những năm qua, cộng đồng đào tạo phân tán đã giới thiệu song song XNUMXD (song song dữ liệu, song song đường ống và song song tensor) và các kỹ thuật khác (như song song trình tự và song song chuyên gia) để giải quyết những thách thức đó.
Vào tháng 2023 năm XNUMX, Amazon công bố phát hành Thư viện song song mô hình SageMaker 2.0 (SMP), đạt được hiệu quả tiên tiến trong đào tạo mô hình lớn, cùng với Thư viện song song dữ liệu phân tán SageMaker (SMDDP). Bản phát hành này là bản cập nhật quan trọng từ 1.x: SMP hiện được tích hợp với PyTorch mã nguồn mở Dữ liệu được chia sẻ hoàn toàn song song (FSDP), cho phép bạn sử dụng giao diện quen thuộc khi đào tạo các mô hình lớn và tương thích với Máy biến áp (TE), lần đầu tiên mở khóa các kỹ thuật song song tensor cùng với FSDP. Để tìm hiểu thêm về việc phát hành, hãy tham khảo Thư viện song song mô hình Amazon SageMaker hiện tăng tốc khối lượng công việc PyTorch FSDP lên tới 20%.
Trong bài đăng này, chúng tôi khám phá những lợi ích hiệu suất của Amazon SageMaker (bao gồm SMP và SMDDP) và cách bạn có thể sử dụng thư viện để đào tạo các mô hình lớn một cách hiệu quả trên SageMaker. Chúng tôi chứng minh hiệu suất của SageMaker bằng điểm chuẩn trên các cụm ml.p4d.24xlarge lên tới 128 phiên bản và độ chính xác hỗn hợp FSDP với bfloat16 cho mô hình Llama 2. Chúng tôi bắt đầu bằng việc minh họa hiệu quả mở rộng quy mô gần như tuyến tính cho SageMaker, sau đó là phân tích sự đóng góp từ từng tính năng để có thông lượng tối ưu và kết thúc bằng việc đào tạo hiệu quả với độ dài chuỗi khác nhau lên tới 32,768 thông qua tính song song tensor.
Chia tỷ lệ gần tuyến tính với SageMaker
Để giảm thời gian đào tạo tổng thể cho các mô hình LLM, việc duy trì thông lượng cao khi mở rộng sang các cụm lớn (hàng nghìn GPU) là rất quan trọng do chi phí liên lạc giữa các nút. Trong bài đăng này, chúng tôi chứng minh tính hiệu quả của việc mở rộng quy mô mạnh mẽ và gần như tuyến tính (bằng cách thay đổi số lượng GPU cho tổng kích thước vấn đề cố định) trên các phiên bản p4d gọi cả SMP và SMDDP.
Trong phần này, chúng tôi chứng minh hiệu suất mở rộng gần như tuyến tính của SMP. Ở đây, chúng tôi đào tạo các mô hình Llama 2 với nhiều kích cỡ khác nhau (tham số 7B, 13B và 70B) bằng cách sử dụng độ dài chuỗi cố định là 4,096, phần phụ trợ SMDDP để liên lạc tập thể, kích hoạt TE, kích thước lô toàn cầu là 4 triệu, với 16 đến 128 nút p4d . Bảng sau đây tóm tắt cấu hình và hiệu suất đào tạo tối ưu của chúng tôi (TFLOP mô hình mỗi giây).
| Kích thước mô hình | Số lượng nút | TFLOP* | sdp* | tp* | giảm tải* | Hiệu quả mở rộng quy mô |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Ở kích thước mô hình, độ dài chuỗi và số lượng nút nhất định, chúng tôi hiển thị thông lượng và cấu hình tối ưu toàn cầu sau khi khám phá các kết hợp giảm tải sdp, tp và kích hoạt khác nhau.
Bảng trước tóm tắt các số thông lượng tối ưu tùy theo mức độ song song dữ liệu (sdp) được phân chia (thường sử dụng phân chia kết hợp FSDP thay vì phân chia đầy đủ, với nhiều chi tiết hơn trong phần tiếp theo), mức độ song song tensor (tp) và các thay đổi giá trị giảm tải kích hoạt, thể hiện tỷ lệ gần như tuyến tính cho SMP cùng với SMDDP. Ví dụ: với mô hình Llama 2 có kích thước 7B và độ dài chuỗi 4,096, về tổng thể, nó đạt được hiệu suất mở rộng quy mô lần lượt là 97.0%, 91.6% và 84.1% (so với 16 nút) ở 32, 64 và 128 nút. Hiệu suất mở rộng ổn định trên các kích thước mô hình khác nhau và tăng nhẹ khi kích thước mô hình lớn hơn.
SMP và SMDDP cũng chứng minh hiệu quả mở rộng quy mô tương tự đối với các độ dài chuỗi khác như 2,048 và 8,192.
Hiệu suất thư viện song song mô hình SageMaker 2.0: Llama 2 70B
Quy mô mô hình đã tiếp tục phát triển trong những năm qua, cùng với các cập nhật hiệu suất tiên tiến thường xuyên trong cộng đồng LLM. Trong phần này, chúng tôi minh họa hiệu suất trong SageMaker cho mô hình Llama 2 bằng cách sử dụng kích thước mô hình cố định 70B, độ dài chuỗi là 4,096 và kích thước lô toàn cầu là 4 triệu. Để so sánh với thông lượng và cấu hình tối ưu toàn cầu của bảng trước (với phần phụ trợ SMDDP, điển hình là phân đoạn lai FSDP và TE), bảng sau đây mở rộng sang các thông lượng tối ưu khác (có thể có tính song song tensor) với các thông số kỹ thuật bổ sung trên phần phụ trợ phân tán (NCCL và SMDDP) , Chiến lược phân mảnh FSDP (phân mảnh đầy đủ và phân mảnh kết hợp) và có bật TE hay không (mặc định).
| Kích thước mô hình | Số lượng nút | TFLOPS | Cấu hình TFLOPs #3 | Cải thiện TFLOP so với mức cơ bản | ||||||||
| . | . | Phân mảnh đầy đủ NCCL: #0 | Phân mảnh đầy đủ SMDDP: #1 | Phân mảnh lai SMDDP: #2 | Phân mảnh lai SMDDP với TE: #3 | sdp* | tp* | giảm tải* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Ở kích thước mô hình, độ dài chuỗi và số lượng nút nhất định, chúng tôi hiển thị thông lượng và cấu hình tối ưu toàn cầu sau khi khám phá các kết hợp giảm tải sdp, tp và kích hoạt khác nhau.
Bản phát hành mới nhất của SMP và SMDDP hỗ trợ nhiều tính năng bao gồm PyTorch FSDP nguyên bản, phân mảnh lai mở rộng và linh hoạt hơn, tích hợp động cơ biến áp, song song tensor và tối ưu hóa tất cả hoạt động tập hợp. Để hiểu rõ hơn về cách SageMaker đạt được hoạt động đào tạo phân tán hiệu quả cho LLM, chúng tôi khám phá những đóng góp gia tăng từ SMDDP và SMP sau đây tính năng cốt lõi:
- Cải tiến SMDDP so với NCCL với phân đoạn đầy đủ FSDP
- Thay thế phân mảnh toàn diện FSDP bằng phân mảnh lai, giúp giảm chi phí liên lạc để cải thiện thông lượng
- Tăng thêm thông lượng với TE, ngay cả khi tính năng song song tensor bị vô hiệu hóa
- Ở cài đặt tài nguyên thấp hơn, việc giảm tải kích hoạt có thể cho phép đào tạo vốn không khả thi hoặc rất chậm do áp lực bộ nhớ cao
Phân đoạn đầy đủ FSDP: Cải tiến SMDDP so với NCCL
Như được hiển thị trong bảng trước, khi các mô hình được phân chia hoàn toàn bằng FSDP, mặc dù thông lượng NCCL (TFLOPs #0) và SMDDP (TFLOPs #1) tương đương nhau ở 32 hoặc 64 nút, nhưng có sự cải thiện rất lớn 50.4% từ NCCL đến SMDDP tại 128 nút.
Ở kích thước mô hình nhỏ hơn, chúng tôi quan sát thấy những cải tiến nhất quán và đáng kể của SMDDP so với NCCL, bắt đầu từ các kích thước cụm nhỏ hơn, vì SMDDP có thể giảm thiểu tắc nghẽn truyền thông một cách hiệu quả.
Phân mảnh lai FSDP để giảm chi phí truyền thông
Trong SMP 1.0, chúng tôi đã khởi chạy song song dữ liệu sharded, một kỹ thuật đào tạo phân tán được hỗ trợ bởi Amazon nội bộ MiCS công nghệ. Trong SMP 2.0, chúng tôi giới thiệu phân mảnh lai SMP, một kỹ thuật phân mảnh lai có khả năng mở rộng và linh hoạt hơn cho phép các mô hình được phân chia trong một tập hợp con GPU, thay vì tất cả các GPU đào tạo, đó là trường hợp phân mảnh toàn bộ FSDP. Tính năng này hữu ích cho các mô hình cỡ trung bình không cần phân chia trên toàn bộ cụm để đáp ứng các ràng buộc về bộ nhớ trên mỗi GPU. Điều này dẫn đến các cụm có nhiều bản sao mô hình và mỗi GPU giao tiếp với ít đồng nghiệp hơn trong thời gian chạy.
Phân mảnh kết hợp của SMP cho phép phân mảnh mô hình hiệu quả trên phạm vi rộng hơn, từ mức độ phân mảnh nhỏ nhất không có vấn đề về bộ nhớ cho đến toàn bộ kích thước cụm (tương đương với phân mảnh toàn bộ).
Hình dưới đây minh họa sự phụ thuộc thông lượng vào sdp tại tp = 1 để đơn giản. Mặc dù nó không nhất thiết phải giống với giá trị tp tối ưu cho phân mảnh toàn bộ NCCL hoặc SMDDP trong bảng trước, nhưng các con số này khá gần nhau. Nó xác nhận rõ ràng giá trị của việc chuyển từ phân đoạn hoàn toàn sang phân đoạn lai ở kích thước cụm lớn gồm 128 nút, có thể áp dụng cho cả NCCL và SMDDP. Đối với kích thước mô hình nhỏ hơn, những cải tiến đáng kể với phân đoạn kết hợp bắt đầu ở kích thước cụm nhỏ hơn và sự khác biệt tiếp tục tăng theo kích thước cụm.
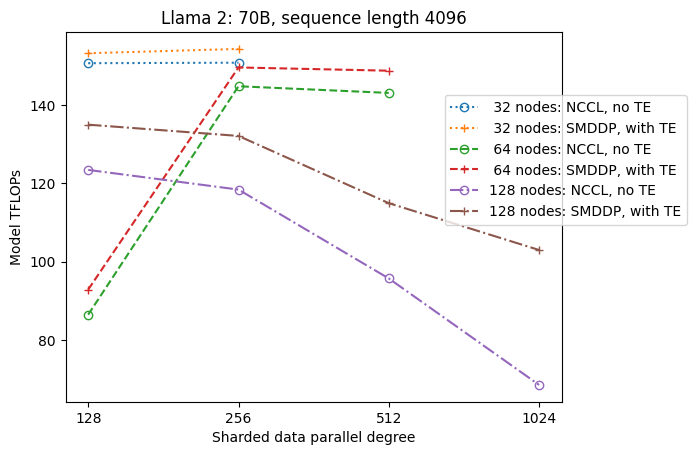
Cải tiến với TE
TE được thiết kế để đẩy nhanh quá trình đào tạo LLM trên GPU NVIDIA. Mặc dù không sử dụng FP8 vì nó không được hỗ trợ trên các phiên bản p4d, chúng tôi vẫn thấy tốc độ tăng tốc đáng kể với TE trên p4d.
Ngoài MiCS được đào tạo với chương trình phụ trợ SMDDP, TE giới thiệu khả năng tăng thông lượng nhất quán trên tất cả các kích thước cụm (ngoại lệ duy nhất là phân chia hoàn toàn ở 128 nút), ngay cả khi tính năng song song tensor bị vô hiệu hóa (mức độ song song của tensor là 1).
Đối với kích thước mô hình nhỏ hơn hoặc độ dài chuỗi khác nhau, mức tăng TE ổn định và không tầm thường, trong khoảng khoảng 3–7.6%.
Giảm tải kích hoạt ở cài đặt tài nguyên thấp
Ở cài đặt tài nguyên thấp (với số lượng nút nhỏ), FSDP có thể gặp áp lực bộ nhớ cao (hoặc thậm chí hết bộ nhớ trong trường hợp xấu nhất) khi bật điểm kiểm tra kích hoạt. Đối với những trường hợp bị tắc nghẽn do bộ nhớ như vậy, việc bật giảm tải kích hoạt có thể là một tùy chọn để cải thiện hiệu suất.
Ví dụ: như chúng ta đã thấy trước đây, mặc dù Llama 2 ở kích thước mô hình 13B và độ dài chuỗi 4,096 có thể huấn luyện tối ưu với ít nhất 32 nút có điểm kiểm tra kích hoạt và không giảm tải kích hoạt, nhưng nó vẫn đạt được thông lượng tốt nhất với giảm tải kích hoạt khi bị giới hạn ở 16 nút điểm giao.
Cho phép đào tạo với chuỗi dài: song song tensor SMP
Độ dài chuỗi dài hơn được mong muốn cho các cuộc hội thoại và bối cảnh dài hơn và đang nhận được nhiều sự chú ý hơn trong cộng đồng LLM. Do đó, chúng tôi báo cáo các thông lượng chuỗi dài khác nhau trong bảng sau. Bảng hiển thị thông lượng tối ưu cho quá trình đào tạo Llama 2 trên SageMaker, với độ dài chuỗi khác nhau từ 2,048 đến 32,768. Với độ dài chuỗi 32,768, việc đào tạo FSDP gốc là không khả thi với 32 nút ở quy mô lô toàn cầu là 4 triệu.
| . | . | . | TFLOPS | ||
| Kích thước mô hình | Độ dài trình tự | Số lượng nút | FSDP và NCCL bản địa | SMP và SMDDP | cải tiến SMP |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: tối đa | . | . | . | . | 8.3% |
| *: Trung bình | . | . | . | . | 5.8% |
Khi kích thước cụm lớn và có kích thước lô toàn cầu cố định, một số hoạt động đào tạo mô hình có thể không khả thi với PyTorch FSDP gốc, thiếu đường dẫn tích hợp sẵn hoặc hỗ trợ song song tensor. Trong bảng trước, với kích thước lô toàn cầu là 4 triệu, 32 nút và độ dài chuỗi 32,768, kích thước lô hiệu quả trên mỗi GPU là 0.5 (ví dụ: tp = 2 với kích thước lô 1), nếu không thì sẽ không khả thi nếu không giới thiệu sự song song tensor.
Kết luận
Trong bài đăng này, chúng tôi đã trình diễn hoạt động đào tạo LLM hiệu quả với SMP và SMDDP trên các phiên bản p4d, ghi nhận sự đóng góp cho nhiều tính năng chính, chẳng hạn như cải tiến SMDDP so với NCCL, phân mảnh kết hợp FSDP linh hoạt thay vì phân mảnh hoàn toàn, tích hợp TE và hỗ trợ tính năng song song tensor có lợi cho độ dài chuỗi dài. Sau khi được thử nghiệm trên nhiều cài đặt với nhiều mô hình, kích thước mô hình và độ dài chuỗi khác nhau, nó cho thấy hiệu quả mở rộng quy mô gần như tuyến tính mạnh mẽ, lên tới 128 phiên bản p4d trên SageMaker. Tóm lại, SageMaker tiếp tục là một công cụ mạnh mẽ dành cho các nhà nghiên cứu và thực hành LLM.
Để tìm hiểu thêm, hãy tham khảo Thư viện song song mô hình SageMaker v2, hoặc liên hệ với nhóm SMP tại sm-model-parallel-feedback@amazon.com.
Lời cảm ơn
Chúng tôi muốn cảm ơn Robert Van Dusen, Ben Snyder, Gautam Kumar và Luis Quintela vì những phản hồi và thảo luận mang tính xây dựng của họ.
Về các tác giả

Xinle Sheila Liu là SDE trong Amazon SageMaker. Trong thời gian rảnh rỗi, cô thích đọc sách và chơi thể thao ngoài trời.
 Suhit Kodgule là Kỹ sư phát triển phần mềm thuộc nhóm Trí tuệ nhân tạo AWS làm việc về các khuôn khổ học sâu. Khi rảnh rỗi, anh thích đi bộ đường dài, du lịch và nấu ăn.
Suhit Kodgule là Kỹ sư phát triển phần mềm thuộc nhóm Trí tuệ nhân tạo AWS làm việc về các khuôn khổ học sâu. Khi rảnh rỗi, anh thích đi bộ đường dài, du lịch và nấu ăn.
 Victor Zhu là Kỹ sư phần mềm về Học sâu phân tán tại Amazon Web Services. Người ta có thể thấy anh ấy đang thích đi bộ đường dài và chơi trò chơi board quanh Khu vực Vịnh SF.
Victor Zhu là Kỹ sư phần mềm về Học sâu phân tán tại Amazon Web Services. Người ta có thể thấy anh ấy đang thích đi bộ đường dài và chơi trò chơi board quanh Khu vực Vịnh SF.
 Derya Cavdar làm kỹ sư phần mềm tại AWS. Mối quan tâm của cô bao gồm học sâu và tối ưu hóa đào tạo phân tán.
Derya Cavdar làm kỹ sư phần mềm tại AWS. Mối quan tâm của cô bao gồm học sâu và tối ưu hóa đào tạo phân tán.
 Đằng Húc là Kỹ sư phát triển phần mềm trong nhóm Đào tạo phân tán trong AWS AI. Anh ấy thích đọc sách.
Đằng Húc là Kỹ sư phát triển phần mềm trong nhóm Đào tạo phân tán trong AWS AI. Anh ấy thích đọc sách.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

