
Image by Editor
Have you heard of Andrej Karpathy? He’s a renowned computer scientist and AI researcher known for his work on deep learning and neural networks. He played a key role in the development of ChatGPT at OpenAI and was previously the Sr. Director of AI at Tesla. Even before that, he designed and was the primary instructor for the first deep learning class Stanford – CS 231n: Convolutional Neural Networks for Visual Recognition. The class became one of the largest at Stanford and has grown from 150 enrolled in 2015 to 750 students in 2017. I highly recommend anyone interested in deep learning to watch this on YouTube. I will not go into more detail about him, and we will shift our focus toward one of his most popular talks on YouTube which crossed 1.4 million views “Introduction to Large Language Models.” This talk is a busy-person introduction to LLMs and is a must-watch for anyone interested in LLMs.
I have provided a concise summary of this talk. If this sparks your interest, then I will highly recommend you go over the slides and YouTube link that will be provided at the end of this article.
This talk provides a comprehensive introduction to LLMs, their capabilities, and the potential risks associated with their use. It has been divided into 3 major parts that are as follows:
Part 1: LLMs

Slides by Andrej Karpathy
LLMs are trained on a large corpus of text to generate human-like responses. In this part, Andrej discusses the Llama 2-70b model specifically. It is one of the largest LLMs with 70 billion parameters. The model consists of two main components: the parameters file and the run file. The parameters file is a large binary file that contains the weights and biases of the model. These weights and biases are essentially the “knowledge” that the model has learned during training. The run file is a piece of code that is used to load the parameters file and run the model. The training process of the model can be divided into the following two stages:
1. Pretraining
This involves collecting a large chunk of text, about 10 terabytes, from the internet, and then using a GPU cluster to train the model on this data. The result of the training process is a base model that is the lossy compression of the internet. It is capable of generating coherent and relevant text but not directly answering questions.
2. Finetuning
The pre-trained model is further trained on a high-quality dataset to make it more useful. This results in an assistant model. Andrej also mentions a third stage of fine-tuning, which involves using comparison labels. Instead of generating answers from scratch, the model is given multiple candidate answers and asked to choose the best one. This can be easier and more efficient than generating answers, and can further improve the model’s performance. This process is called reinforcement learning from human feedback (RLHF).
Part 2: Future of LLMs
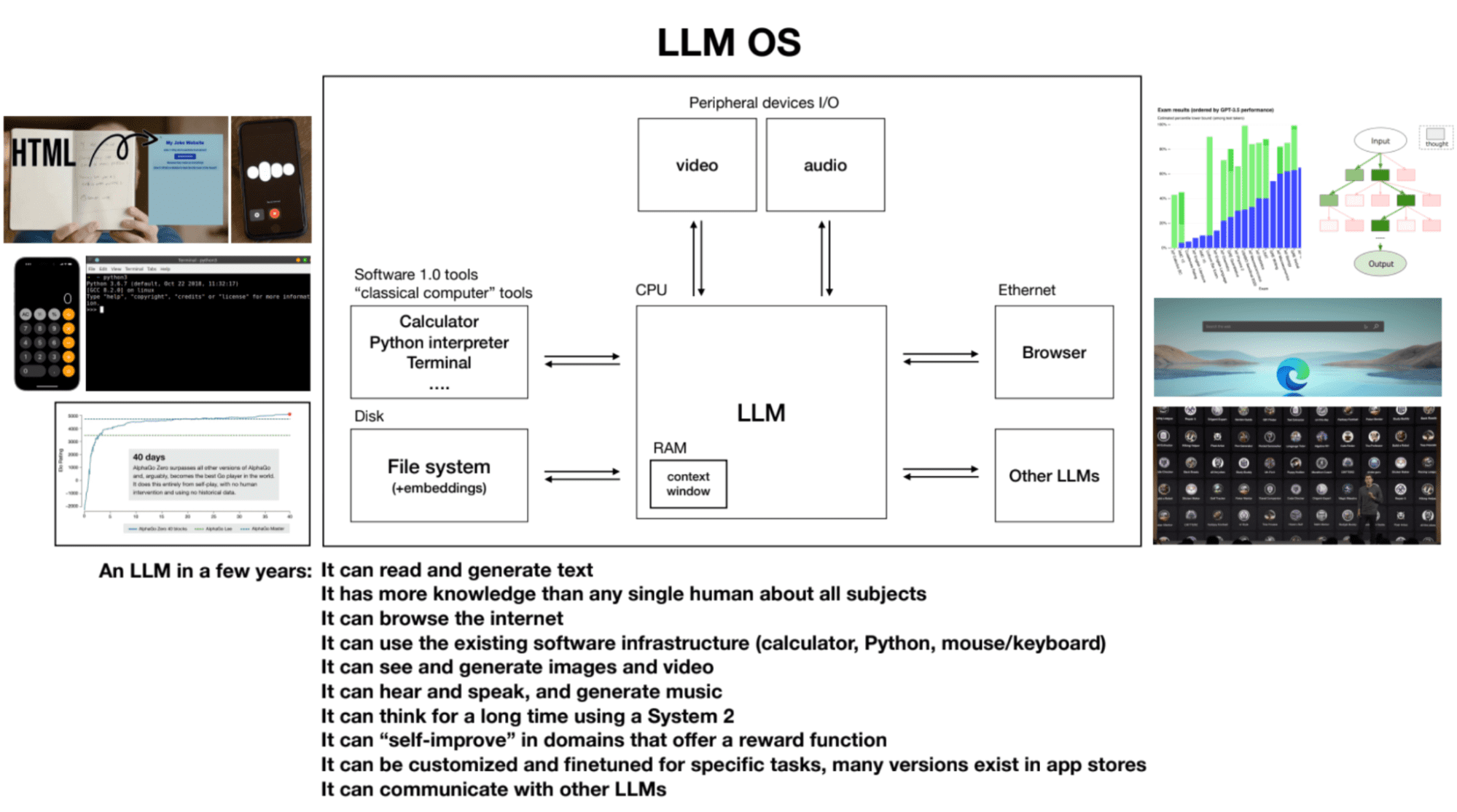
Slides by Andrej Karpathy
While discussing the future of large language models and their capabilities, the following key points are discussed:
1. Scaling Law
Model performance correlates with two variables—the number of parameters and the amount of training text. Larger models trained on more data tend to achieve better performance.
2. Usage of Tools
LLMs like ChatGPT can utilize tools such as a browser, calculator, and Python libraries to perform tasks that would otherwise be challenging or impossible for the model alone.
3. System One and System Two Thinking in LLMs
Currently, LLMs predominantly employ system one thinking—fast, instinctive, and pattern-based. However, there is interest in developing LLMs capable of engaging in system two thinking—slower, rational, and requiring conscious effort.
4. LLM OS
LLMs can be thought of as the kernel process of an emerging operating system. They can read and generate text, have extensive knowledge on various subjects, browse the internet or reference local files, use existing software infrastructure, generate images and videos, hear and speak, and think for extended periods using system 2. The context window of an LLM is analogous to RAM in a computer, and the kernel process tries to page relevant information in and out of its context window to perform tasks.
Part 3: LLMs Security

Slides by Andrej Karpathy
Andrej highlights ongoing research efforts in addressing security challenges associated with LLMs. The following attacks are discussed:
1. Jailbreak
Attempts to bypass safety measures in LLMs to extract harmful or inappropriate information. Examples include role-playing to deceive the model and manipulating responses using optimized sequences of words or images.
2. Prompt Injection
Involves injecting new instructions or prompts into an LLM to manipulate its responses. Attackers can hide instructions within images or web pages, leading to the inclusion of unrelated or harmful content in the model’s answers.
3. Data Poisoning /Backdoor Attack/Sleeper Agent Attack
Involves training a large language model on malicious or manipulated data containing trigger phrases. When the model encounters the trigger phrase, it can be manipulated to perform undesirable actions or provide incorrect predictions.
You can watch the comprehensive video on YouTube by clicking below:
[embedded content][embedded content]
Slides: Click here
If you’re new to LLMs and looking for resources to kickstart your journey, then this comprehensive list is a great place to start! It contains both foundational and LLM-specific courses that will help you build a solid foundation. Additionally, if you’re interested in a more structured learning experience, Maxime Labonne recently launched his LLM course with three different tracks to choose from based on your needs and experience level. Here are the links to both resources for your convenience:
- A Comprehensive List of Resources to Master Large Language Models by Kanwal Mehreen
- Large Language Model Course by Maxime Labonne
Kanwal Mehreen is an aspiring software developer with a keen interest in data science and applications of AI in medicine. Kanwal was selected as the Google Generation Scholar 2022 for the APAC region. Kanwal loves to share technical knowledge by writing articles on trending topics, and is passionate about improving the representation of women in tech industry.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.kdnuggets.com/unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy?utm_source=rss&utm_medium=rss&utm_campaign=unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy

