Amazon SageMaker Stüdyosu Veri bilimcilerin makine öğrenimi (ML) modellerini etkileşimli olarak oluşturması, eğitmesi ve dağıtması için tam olarak yönetilen bir çözüm sağlar. Veri bilimcileri, makine öğrenimi görevleri üzerinde çalışma sürecinde genellikle ilgili veri kaynaklarını keşfederek ve bunlara bağlanarak iş akışlarına başlar. Daha sonra SQL'i makine öğrenimi eğitimlerinde ve çıkarımlarında kullanmadan önce çeşitli kaynaklardan gelen verileri keşfetmek, analiz etmek, görselleştirmek ve entegre etmek için kullanırlar. Daha önce, veri bilimcileri iş akışlarında SQL'i desteklemek için birden fazla araçla hokkabazlık yaparken buluyorlardı ve bu da üretkenliği engelliyordu.
SageMaker Studio'daki JupyterLab not defterlerinin artık yerleşik SQL desteğiyle geldiğini duyurmaktan heyecan duyuyoruz. Veri bilimcileri artık şunları yapabilir:
- Aşağıdakiler dahil popüler veri hizmetlerine bağlanın: Amazon Atina, Amazon Kırmızıya Kaydırma, Amazon Veri Bölgesive Snowflake'i doğrudan not defterlerinde
- Dizüstü bilgisayar arayüzünde veritabanlarına, şemalara, tablolara ve görünümlere göz atın ve bunları arayın ve verileri önizleyin
- Makine öğrenimi projelerinde kullanılmak üzere verilerin verimli bir şekilde araştırılması ve dönüştürülmesi için SQL ve Python kodunu aynı not defterinde karıştırın
- Kod geliştirmeyi hızlandırmaya ve genel geliştirici üretkenliğini artırmaya yardımcı olmak için SQL komut tamamlama, kod biçimlendirme yardımı ve sözdizimi vurgulama gibi geliştirici üretkenlik özelliklerini kullanın
Ayrıca yöneticiler bu veri hizmetlerine olan bağlantıları güvenli bir şekilde yönetebilir ve bu da veri bilimcilerinin kimlik bilgilerini manuel olarak yönetmeye gerek kalmadan yetkili verilere erişmesine olanak tanır.
Bu yazıda, SageMaker Studio'da bu özelliğin kurulumunda size rehberlik edeceğiz ve bu özelliğin çeşitli yetenekleri konusunda size yol göstereceğiz. Ardından, girdi olarak doğal dil metnini kullanarak karmaşık SQL sorguları yazmak için gelişmiş büyük dil modelleri (LLM'ler) tarafından sağlanan Metinden SQL'e özelliklerini kullanarak dizüstü bilgisayardaki SQL deneyimini nasıl geliştirebileceğinizi göstereceğiz. Son olarak, daha geniş bir kullanıcı kitlesinin not defterlerindeki doğal dil girişinden SQL sorguları oluşturmasını sağlamak için, size bu Metinden SQL'e modellerini kullanarak nasıl dağıtacağınızı gösteriyoruz. Amazon Adaçayı Yapıcı uç noktalar.
Çözüme genel bakış
SageMaker Studio JupyterLab dizüstü bilgisayarın SQL entegrasyonuyla artık Snowflake, Athena, Amazon Redshift ve Amazon DataZone gibi popüler veri kaynaklarına bağlanabilirsiniz. Bu yeni özellik çeşitli işlevleri gerçekleştirmenize olanak tanır.
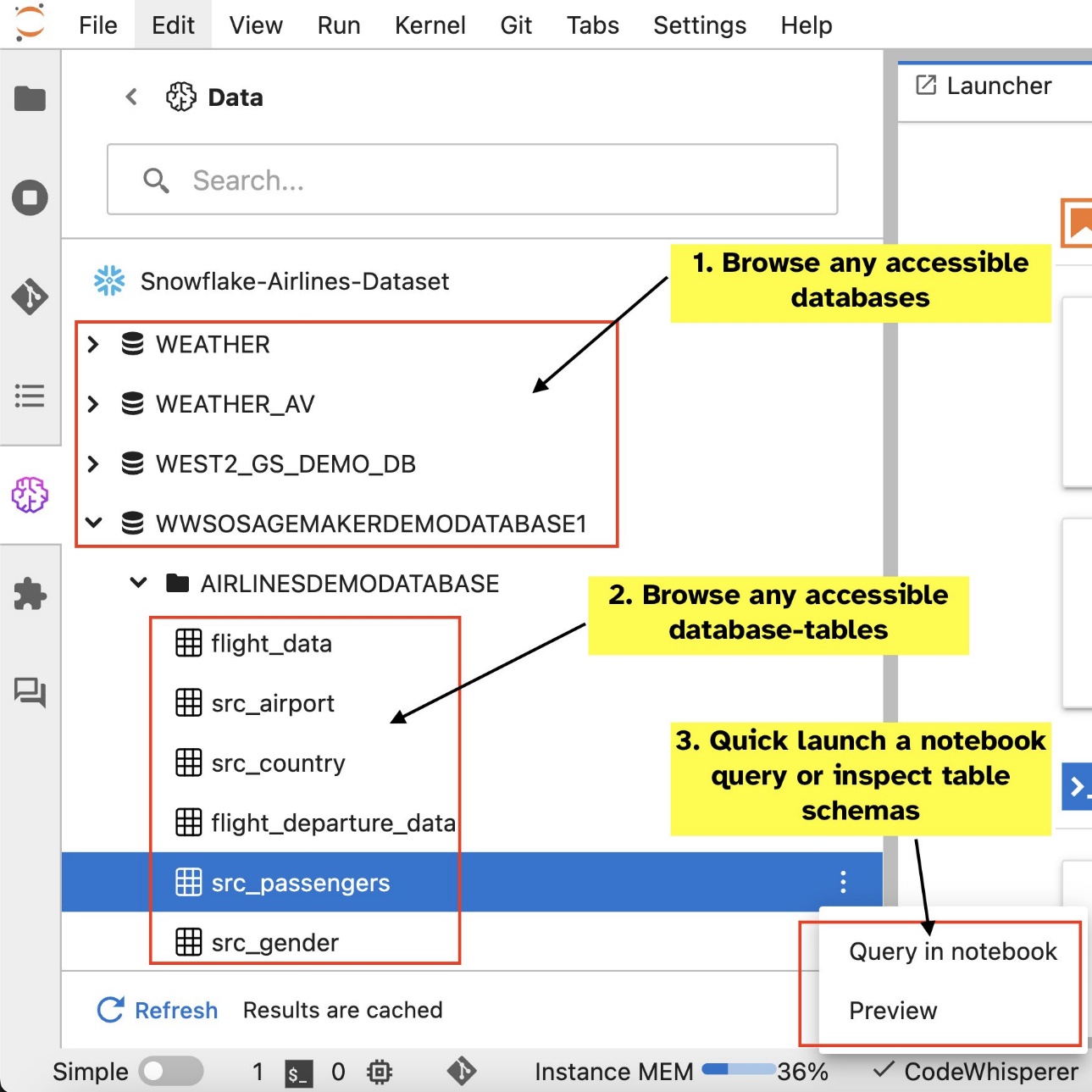
Örneğin veritabanları, tablolar ve şemalar gibi veri kaynaklarını doğrudan JupyterLab ekosisteminizden görsel olarak keşfedebilirsiniz. Dizüstü bilgisayar ortamlarınız SageMaker Dağıtım 1.6 veya üzeri sürümde çalışıyorsa JupyterLab arayüzünüzün sol tarafında yeni bir widget arayın. Bu ekleme, geliştirme ortamınızdaki veri erişilebilirliğini ve yönetimini geliştirir.
Şu anda önerilen SageMaker Dağıtımında (1.5 veya daha düşük) veya özel bir ortamda değilseniz daha fazla bilgi için eke bakın.
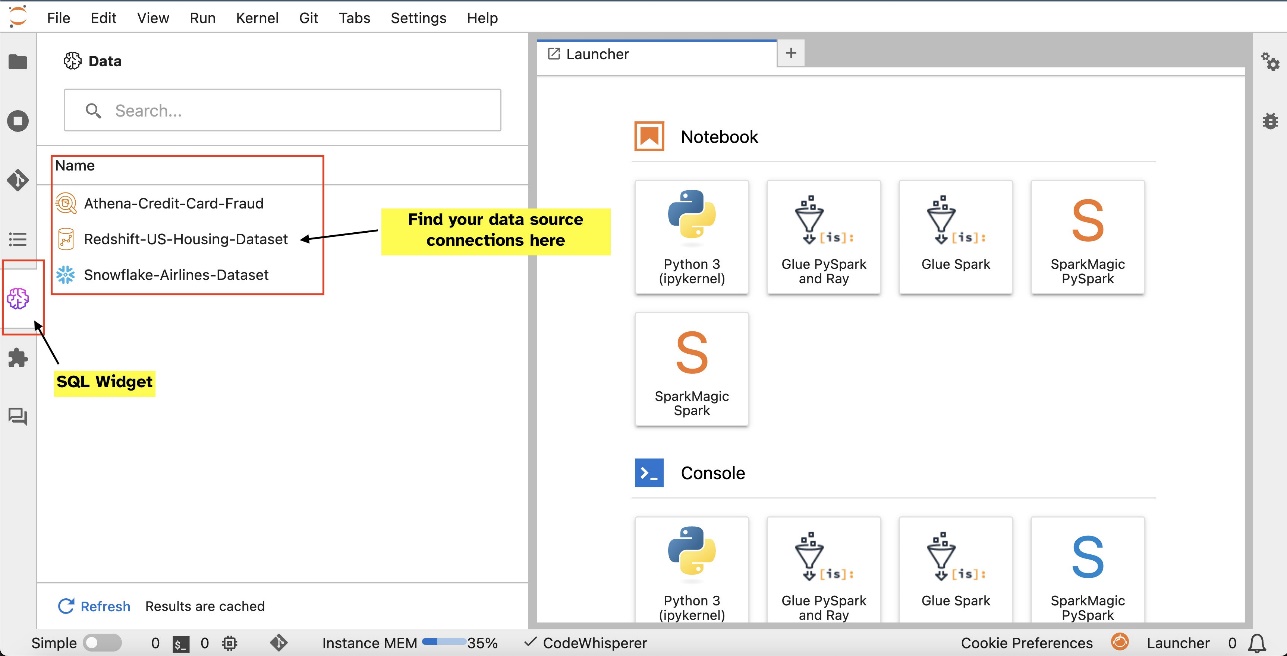
Bağlantıları kurduktan sonra (bir sonraki bölümde gösterilmiştir), veri bağlantılarını listeleyebilir, veritabanlarına ve tablolara göz atabilir ve şemaları inceleyebilirsiniz.
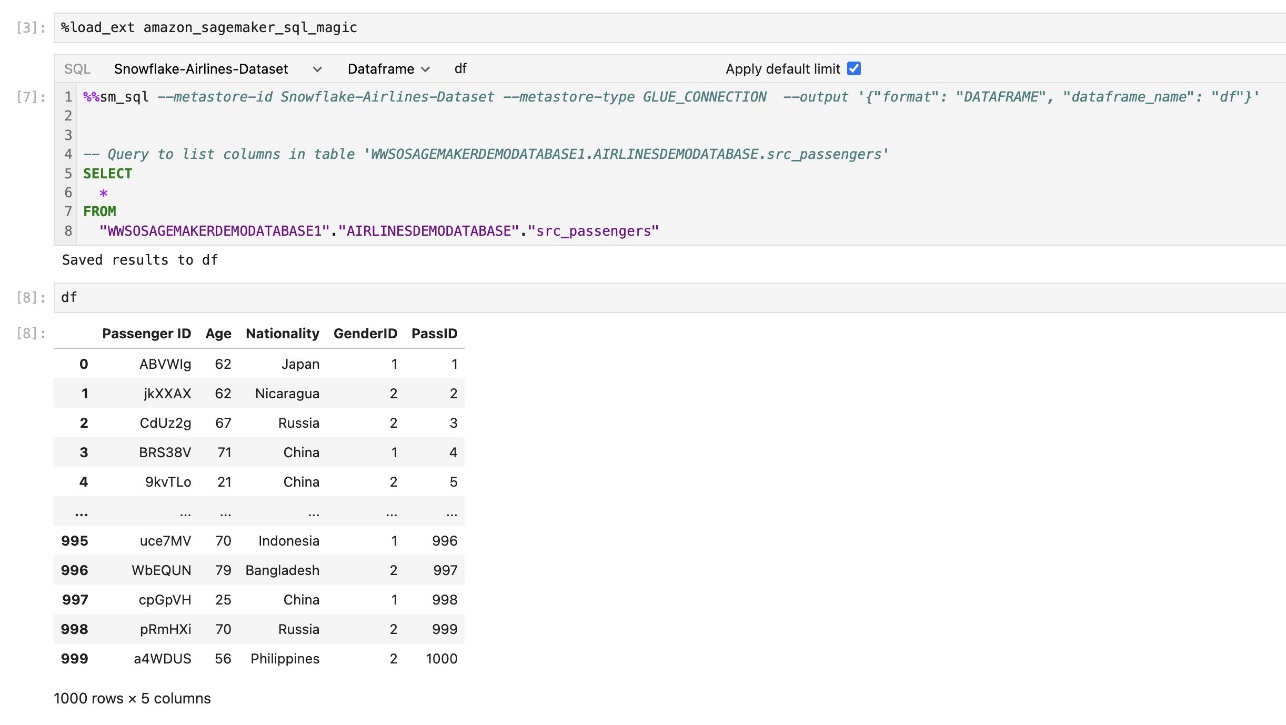
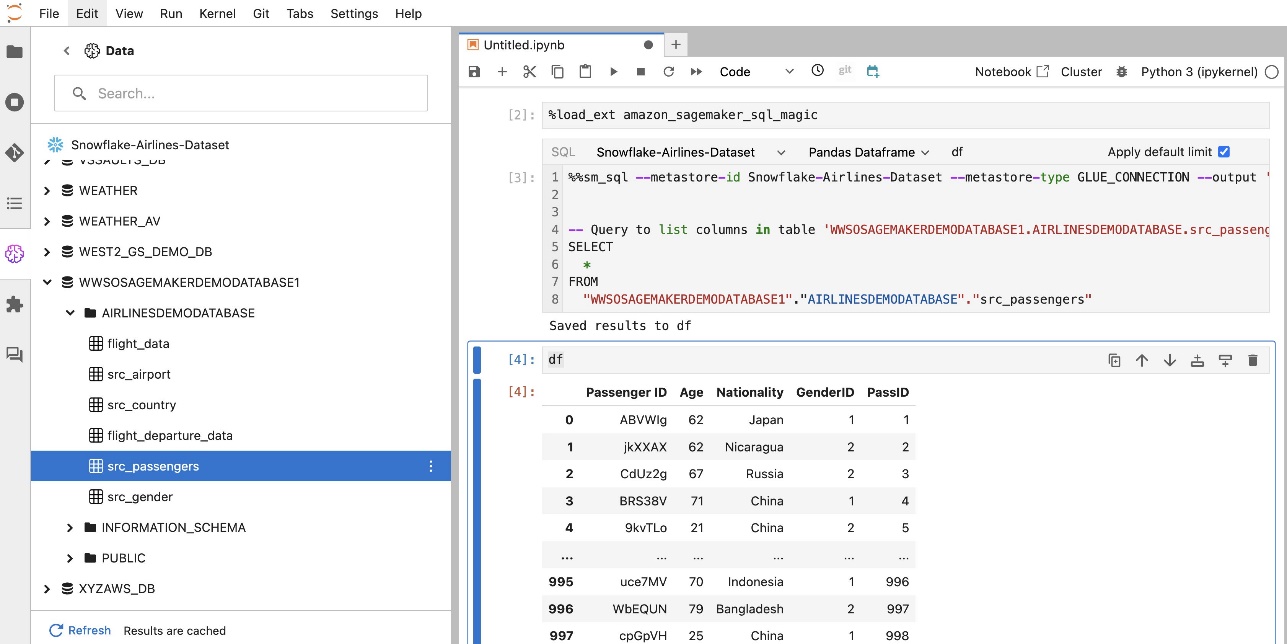
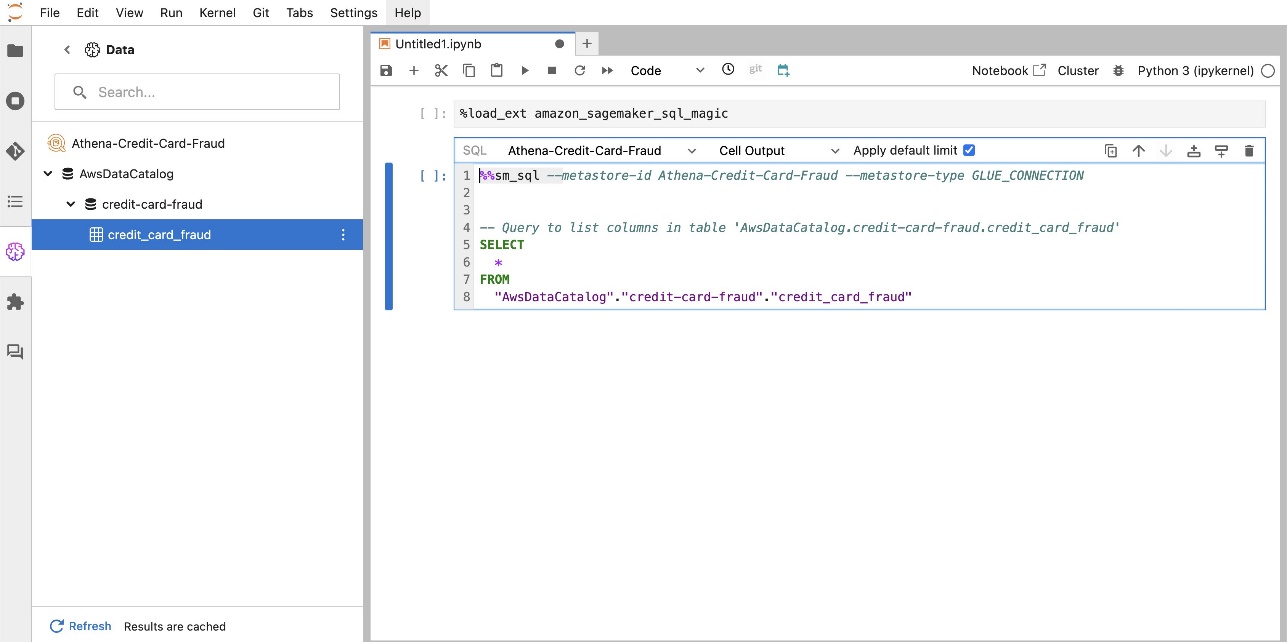
SageMaker Studio JupyterLab'ın yerleşik SQL uzantısı, SQL sorgularını doğrudan bir dizüstü bilgisayardan çalıştırmanıza da olanak tanır. Jupyter not defterleri SQL ve Python kodlarını aşağıdaki şekilde ayırt edebilir: %%sm_sql SQL kodunu içeren herhangi bir hücrenin üstüne yerleştirilmesi gereken sihirli komut. Bu komut JupyterLab'a aşağıdaki talimatların Python kodu yerine SQL komutları olduğunu bildirir. Bir sorgunun çıktısı doğrudan not defterinin içinde görüntülenebilir, bu da SQL ve Python iş akışlarının veri analizinize kusursuz entegrasyonunu kolaylaştırır.
Bir sorgunun çıktısı, aşağıdaki ekran görüntüsünde gösterildiği gibi görsel olarak HTML tabloları halinde görüntülenebilir.

Ayrıca bir harfe de yazılabilirler. pandalar DataFrame.
Önkoşullar
SageMaker Studio dizüstü bilgisayar SQL deneyimini kullanmak için aşağıdaki önkoşulları karşıladığınızdan emin olun:
- SageMaker Stüdyo V2 – Bilgisayarınızın en güncel sürümünü çalıştırdığınızdan emin olun. SageMaker Studio alanı ve kullanıcı profilleri. Şu anda SageMaker Studio Classic'teyseniz, bkz. Amazon SageMaker Studio Classic'ten geçiş.
- IAM rolü – SageMaker gerektirir AWS Kimlik ve Erişim Yönetimi İzinleri etkili bir şekilde yönetmek için bir SageMaker Studio etki alanına veya kullanıcı profiline atanacak (IAM) rolü. Verilere göz atma ve SQL çalıştırma özelliğini getirmek için yürütme rolü güncellemesi gerekebilir. Aşağıdaki örnek politika, kullanıcıların yetki vermesini, listelemesini ve çalıştırmasını sağlar AWS TutkalAthena, Amazon Basit Depolama Hizmeti (Amazon S3), AWS Sırları Yöneticisive Amazon Redshift kaynakları:
- JupyterLab Alanı – Güncellenmiş SageMaker Studio ve JupyterLab Space'e şu şekilde erişmeniz gerekir: SageMaker Dağıtımı v1.6 veya sonraki görüntü sürümleri. JupyterLab Spaces veya SageMaker Dağıtımının eski sürümleri (v1.5 veya daha düşük) için özel görüntüler kullanıyorsanız, bu özelliği ortamlarınızda etkinleştirmek için gerekli paket ve modülleri yükleme talimatları için eke bakın. SageMaker Studio JupyterLab Spaces hakkında daha fazla bilgi edinmek için bkz. Amazon SageMaker Studio'da verimliliği artırın: JupyterLab Spaces ve üretken yapay zeka araçlarıyla tanışın.
- Veri kaynağı erişim kimlik bilgileri – Bu SageMaker Studio dizüstü bilgisayar özelliği, Snowflake ve Amazon Redshift gibi veri kaynaklarına kullanıcı adı ve parola erişimi gerektirir. Henüz bir hesabınız yoksa, bu veri kaynaklarına kullanıcı adı ve parola tabanlı erişim oluşturun. Snowflake'e OAuth tabanlı erişim, bu yazının yazıldığı an itibariyle desteklenen bir özellik değildir.
- SQL büyüsünü yükle – Bir Jupyter not defteri hücresinden SQL sorgularını çalıştırmadan önce SQL magics uzantısını yüklemeniz önemlidir. Komutu kullanın
%load_ext amazon_sagemaker_sql_magicBu özelliği etkinleştirmek için. Ek olarak, şunları çalıştırabilirsiniz:%sm_sql?SQL hücresinden sorgulamaya yönelik desteklenen seçeneklerin kapsamlı bir listesini görüntülemek için komut. Bu seçenekler arasında varsayılan sorgu sınırının 1,000 olarak ayarlanması, tam ayıklamanın çalıştırılması ve sorgu parametrelerinin eklenmesi yer alır. Bu kurulum, doğrudan dizüstü bilgisayar ortamınızda esnek ve etkili SQL veri manipülasyonuna olanak tanır.
Veritabanı bağlantıları oluşturun
SageMaker Studio'nun yerleşik SQL tarama ve yürütme yetenekleri, AWS Glue bağlantıları tarafından geliştirilmiştir. AWS Glue bağlantısı, belirli veri depoları için oturum açma kimlik bilgileri, URI dizeleri ve sanal özel bulut (VPC) bilgileri gibi temel verileri depolayan bir AWS Glue Veri Kataloğu nesnesidir. Bu bağlantılar, çeşitli veri deposu türlerine erişmek için AWS Glue tarayıcıları, işleri ve geliştirme uç noktaları tarafından kullanılır. Bu bağlantıları hem kaynak hem de hedef veriler için kullanabilir ve hatta aynı bağlantıyı birden fazla tarayıcıda veya ayıklama, dönüştürme ve yükleme (ETL) işlerinde yeniden kullanabilirsiniz.
SageMaker Studio'nun sol bölmesinde SQL veri kaynaklarını keşfetmek için öncelikle AWS Glue bağlantı nesneleri oluşturmanız gerekir. Bu bağlantılar farklı veri kaynaklarına erişimi kolaylaştırır ve bunların şematik veri öğelerini keşfetmenize olanak tanır.
Aşağıdaki bölümlerde SQL'e özgü AWS Glue bağlayıcıları oluşturma sürecini adım adım anlatacağız. Bu, çeşitli veri depolarındaki veri kümelerine erişmenizi, bunları görüntülemenizi ve keşfetmenizi sağlayacaktır. AWS Glue bağlantıları hakkında daha ayrıntılı bilgi için bkz. Verilere bağlanma.
AWS Glue bağlantısı oluşturun
Veri kaynaklarını SageMaker Studio'ya getirmenin tek yolu AWS Glue bağlantılarıdır. Belirli bağlantı türleriyle AWS Glue bağlantıları oluşturmanız gerekir. Bu yazının yazıldığı an itibariyle, bu bağlantıları oluşturmanın desteklenen tek mekanizması, AWS Komut Satırı Arayüzü (AWS CLI'si).
Bağlantı tanımı JSON dosyası
AWS Glue'da farklı veri kaynaklarına bağlanırken öncelikle bağlantı özelliklerini tanımlayan bir JSON dosyası oluşturmanız gerekir. bağlantı tanımlama dosyası. Bu dosya, bir AWS Glue bağlantısı kurmak için çok önemlidir ve veri kaynağına erişim için gerekli tüm yapılandırmaları ayrıntılı olarak içermelidir. En iyi güvenlik uygulamaları açısından, parolalar gibi hassas bilgileri güvenli bir şekilde saklamak üzere Secrets Manager'ın kullanılması önerilir. Bu arada diğer bağlantı özellikleri doğrudan AWS Glue bağlantıları aracılığıyla yönetilebilir. Bu yaklaşım, bağlantı yapılandırmasını erişilebilir ve yönetilebilir hale getirirken hassas kimlik bilgilerinin korunmasını sağlar.
Aşağıda JSON bağlantı tanımının bir örneği verilmiştir:
Veri kaynaklarınız için AWS Glue bağlantılarını kurarken hem işlevsellik hem de güvenlik sağlamak amacıyla takip etmeniz gereken birkaç önemli yönerge vardır:
- Özelliklerin dizilmesi - İçinde
PythonPropertiesanahtarı, tüm özelliklerin olduğundan emin olun dizili anahtar/değer çiftleri. Gerektiğinde ters eğik çizgi () karakterini kullanarak çift tırnak işaretlerinden düzgün bir şekilde kaçınmak çok önemlidir. Bu, doğru formatın korunmasına ve JSON'unuzdaki sözdizimi hatalarının önlenmesine yardımcı olur. - Hassas bilgilerin işlenmesi – Tüm bağlantı özelliklerini dahil etmek mümkün olmasına rağmen
PythonProperties, şifreler gibi hassas ayrıntıların doğrudan bu özelliklere dahil edilmemesi tavsiye edilir. Bunun yerine, hassas bilgileri işlemek için Secrets Manager'ı kullanın. Bu yaklaşım, hassas verilerinizi ana yapılandırma dosyalarından uzakta, kontrollü ve şifreli bir ortamda depolayarak güvence altına alır.
AWS CLI'yi kullanarak bir AWS Glue bağlantısı oluşturun
Bağlantı tanımı JSON dosyanıza gerekli tüm alanları ekledikten sonra AWS CLI'yi ve aşağıdaki komutu kullanarak veri kaynağınız için bir AWS Glue bağlantısı kurmaya hazırsınız:
Bu komut, JSON dosyanızda ayrıntıları verilen spesifikasyonlara göre yeni bir AWS Glue bağlantısı başlatır. Aşağıda komut bileşenlerinin hızlı bir dökümü verilmiştir:
- -bölge – Bu, AWS Glue bağlantınızın oluşturulacağı AWS Bölgesini belirtir. Gecikmeyi en aza indirmek ve veri yerleşimi gereksinimlerine uymak için veri kaynaklarınızın ve diğer hizmetlerinizin bulunduğu Bölgeyi seçmeniz çok önemlidir.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Bu parametre, AWS CLI'yi JSON formatında bağlantı tanımınızı içeren yerel bir dosyadan giriş yapılandırmasını okumaya yönlendirir.
Studio JupyterLab terminalinizden önceki AWS CLI komutuyla AWS Glue bağlantıları oluşturabilmeniz gerekir. Üzerinde fileto menü seç yeni ve terminal.

Eğer create-connection Komut başarıyla çalıştığında, veri kaynağınızın SQL tarayıcı bölmesinde listelendiğini görmelisiniz. Veri kaynağınızı listede görmüyorsanız Yenile önbelleği güncellemek için.

Bir Kar Tanesi bağlantısı oluşturun
Bu bölümde Snowflake veri kaynağını SageMaker Studio ile entegre etmeye odaklanıyoruz. Snowflake hesapları, veritabanları ve depolar oluşturmak bu yazının kapsamı dışındadır. Snowflake'i kullanmaya başlamak için bkz. Kar tanesi kullanım kılavuzu. Bu yazıda Snowflake tanımı JSON dosyası oluşturmaya ve AWS Glue kullanarak Snowflake veri kaynağı bağlantısı kurmaya odaklanıyoruz.
Gizli Anahtar Yöneticisi sırrı oluşturma
Snowflake hesabınıza kullanıcı adı ve şifre kullanarak veya özel anahtarlar kullanarak bağlanabilirsiniz. Bir kullanıcı kimliği ve parolayla bağlanmak için kimlik bilgilerinizi Secrets Manager'da güvenli bir şekilde saklamanız gerekir. Daha önce de belirtildiği gibi, bu bilgilerin PythonProperties altına yerleştirilmesi mümkün olsa da, hassas bilgilerin düz metin biçiminde saklanması önerilmez. Potansiyel güvenlik risklerini önlemek için hassas verilerin güvenli bir şekilde işlendiğinden her zaman emin olun.
Bilgileri Secrets Manager'da depolamak için aşağıdaki adımları tamamlayın:
- Secrets Manager konsolunda, Yeni bir sır saklayın.
- İçin Gizli tip, seçmek Diğer tür sır.
- Anahtar/değer çifti için şunu seçin: plaintext ve şunu girin:
- Sırrınız için bir ad girin; örneğin
sm-sql-snowflake-secret. - Diğer ayarları varsayılan olarak bırakın veya gerekirse özelleştirin.
- Sırrı yarat.
Snowflake için AWS Glue bağlantısı oluşturun
Daha önce tartışıldığı gibi AWS Glue bağlantıları, SageMaker Studio'dan herhangi bir bağlantıya erişmek için gereklidir. Bir listesini bulabilirsiniz Snowflake için desteklenen tüm bağlantı özellikleri. Aşağıda Snowflake için örnek bir bağlantı tanımı JSON verilmiştir. Diske kaydetmeden önce yer tutucu değerlerini uygun değerlerle değiştirin:
Snowflake veri kaynağına yönelik bir AWS Glue bağlantı nesnesi oluşturmak için aşağıdaki komutu kullanın:
Bu komut, SQL tarayıcı bölmenizde göz atılabilir yeni bir Snowflake veri kaynağı bağlantısı oluşturur ve buna karşı JupyterLab not defteri hücrenizden SQL sorguları çalıştırabilirsiniz.
Amazon Redshift bağlantısı oluşturun
Amazon Redshift, tüm verilerinizi standart SQL kullanarak analiz etmeyi basitleştiren ve maliyetini azaltan, tam olarak yönetilen, petabayt ölçekli bir veri ambarı hizmetidir. Amazon Redshift bağlantısı oluşturma prosedürü, Snowflake bağlantısının prosedürünü yakından yansıtır.
Gizli Anahtar Yöneticisi sırrı oluşturma
Snowflake kurulumuna benzer şekilde, bir kullanıcı kimliği ve parola kullanarak Amazon Redshift'e bağlanmak için gizli dizi bilgilerini Secrets Manager'da güvenli bir şekilde saklamanız gerekir. Aşağıdaki adımları tamamlayın:
- Secrets Manager konsolunda, Yeni bir sır saklayın.
- İçin Gizli tip, seçmek Amazon Redshift kümesi için kimlik bilgileri.
- Amazon Redshift'e veri kaynağı olarak erişmek için oturum açmak için kullanılan kimlik bilgilerini girin.
- Gizli dizilerle ilişkili Redshift kümesini seçin.
- Gizli anahtar için bir ad girin; örneğin
sm-sql-redshift-secret. - Diğer ayarları varsayılan olarak bırakın veya gerekirse özelleştirin.
- Sırrı yarat.
Bu adımları izleyerek, hassas verileri etkili bir şekilde yönetmek için AWS'nin güçlü güvenlik özelliklerini kullanarak bağlantı kimlik bilgilerinizin güvenli bir şekilde kullanıldığından emin olursunuz.
Amazon Redshift için bir AWS Glue bağlantısı oluşturun
JSON tanımı kullanarak Amazon Redshift ile bağlantı kurmak için gerekli alanları doldurun ve aşağıdaki JSON yapılandırmasını diske kaydedin:
Redshift veri kaynağına yönelik bir AWS Glue bağlantı nesnesi oluşturmak için aşağıdaki AWS CLI komutunu kullanın:
Bu komut, AWS Glue'da Redshift veri kaynağınıza bağlı bir bağlantı oluşturur. Komut başarılı bir şekilde çalışırsa, Redshift veri kaynağınızı SageMaker Studio JupyterLab not defterinde SQL sorgularını çalıştırmaya ve veri analizi gerçekleştirmeye hazır olarak görebileceksiniz.

Athena bağlantısı oluşturun
Athena, Amazon S3'te depolanan verilerin standart SQL kullanılarak analiz edilmesini sağlayan, AWS'nin tam olarak yönetilen bir SQL sorgu hizmetidir. JupyterLab not defterinin SQL tarayıcısında veri kaynağı olarak bir Athena bağlantısı kurmak için bir Athena örnek bağlantı tanımı JSON oluşturmanız gerekir. Aşağıdaki JSON yapısı, veri kataloğunu, S3 hazırlama dizinini ve Bölgeyi belirterek Athena'ya bağlanmak için gerekli ayrıntıları yapılandırır:
Athena veri kaynağına yönelik bir AWS Glue bağlantı nesnesi oluşturmak için aşağıdaki AWS CLI komutunu kullanın:
Komut başarılı olursa Athena veri kataloğuna ve tablolarına SageMaker Studio JupyterLab not defterinizdeki SQL tarayıcısından doğrudan erişebileceksiniz.
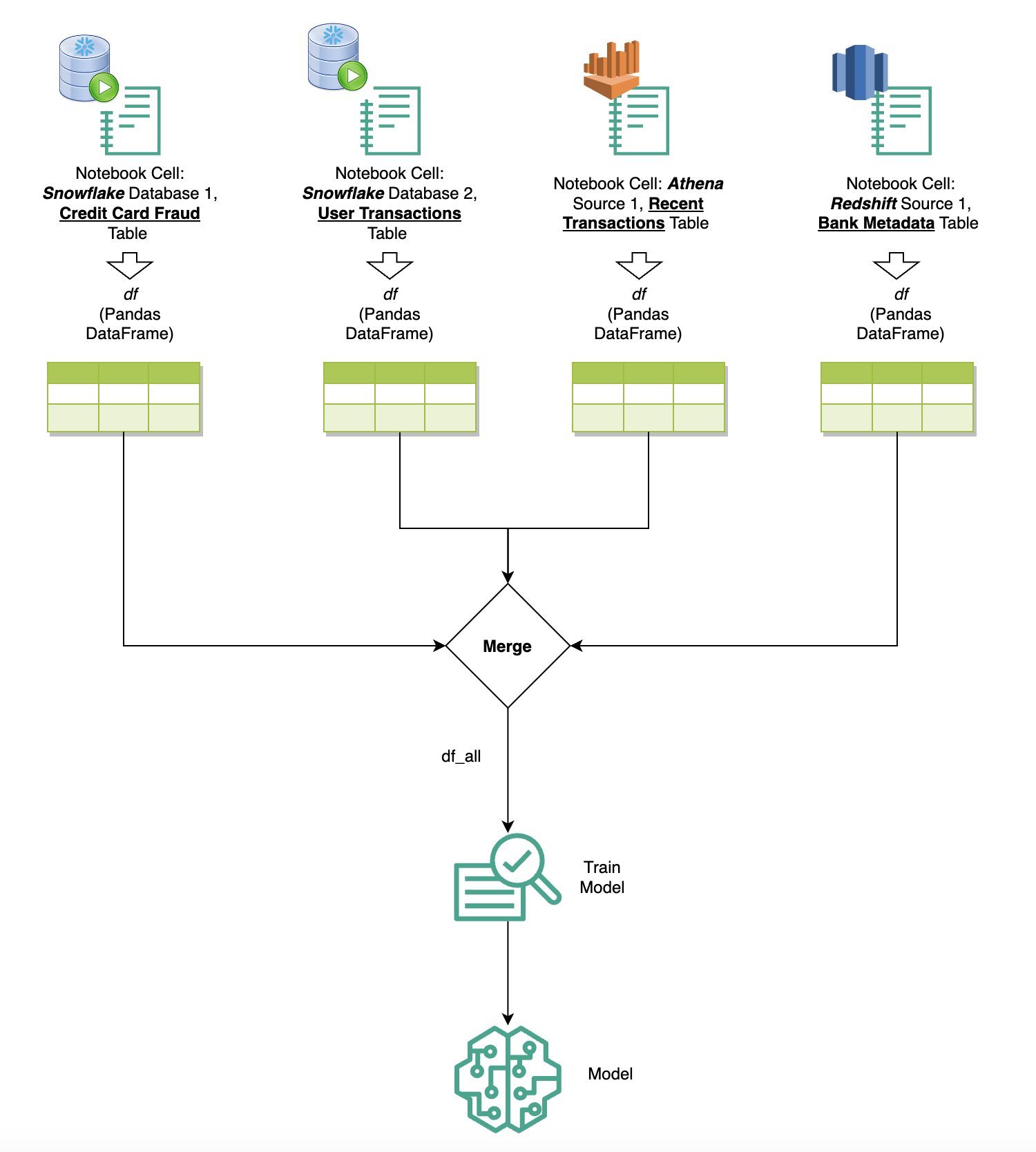
Birden fazla kaynaktan veri sorgulama
Yerleşik SQL tarayıcısı ve dizüstü bilgisayar SQL özelliği aracılığıyla SageMaker Studio'ya entegre edilmiş birden fazla veri kaynağınız varsa, sorguları hızlı bir şekilde çalıştırabilir ve bir dizüstü bilgisayardaki sonraki hücrelerde veri kaynağı arka uçları arasında zahmetsizce geçiş yapabilirsiniz. Bu özellik, analiz iş akışınız sırasında farklı veritabanları veya veri kaynakları arasında kesintisiz geçişlere olanak tanır.
Sorguları çeşitli veri kaynağı arka uçları koleksiyonuna karşı çalıştırabilir ve sonuçları daha fazla analiz veya görselleştirme için doğrudan Python alanına getirebilirsiniz. Bu, aşağıdakiler tarafından kolaylaştırılmıştır: %%sm_sql SageMaker Studio not defterlerinde sihirli komut mevcuttur. SQL sorgunuzun sonuçlarını bir pandas DataFrame'e çıkarmak için iki seçenek vardır:
- Dizüstü bilgisayarınızın hücre araç çubuğundan çıktı türünü seçin Veri çerçevesi ve DataFrame değişkeninizi adlandırın
- Aşağıdaki parametreyi dosyanıza ekleyin
%%sm_sqlkomut:
Aşağıdaki şema bu iş akışını göstermekte ve sonraki dizüstü bilgisayar hücrelerinde çeşitli kaynaklar arasında sorguları nasıl zahmetsizce çalıştırabileceğinizi, ayrıca eğitim işlerini kullanarak bir SageMaker modelini veya yerel hesaplamayı kullanarak doğrudan dizüstü bilgisayar içinde nasıl eğitebileceğinizi göstermektedir. Ek olarak şema, SageMaker Studio'nun yerleşik SQL entegrasyonunun, doğrudan bir JupyterLab dizüstü bilgisayar hücresinin tanıdık ortamında çıkarma ve oluşturma süreçlerini nasıl basitleştirdiğini vurgulamaktadır.
Text to SQL: Sorgu yazmayı geliştirmek için doğal dili kullanma
SQL, veritabanlarının, tabloların, söz dizimlerinin ve meta verilerin anlaşılmasını gerektiren karmaşık bir dildir. Günümüzde üretken yapay zeka (AI), derinlemesine SQL deneyimi gerektirmeden karmaşık SQL sorguları yazmanıza olanak sağlayabilir. LLM'lerin ilerlemesi, doğal dil işleme (NLP) tabanlı SQL üretimini önemli ölçüde etkileyerek, doğal dil açıklamalarından hassas SQL sorgularının oluşturulmasına olanak tanıdı; bu teknik, Metinden SQL'e olarak anılır. Ancak insan dili ile SQL arasındaki doğal farklılıkları kabul etmek önemlidir. İnsan dili bazen belirsiz veya kesin olmayabilirken SQL yapılandırılmış, açık ve nettir. Bu boşluğu kapatmak ve doğal dili doğru bir şekilde SQL sorgularına dönüştürmek zorlu bir zorluk teşkil edebilir. Uygun istemler sağlandığında, Yüksek Lisans'lar insan dilinin ardındaki amacı anlayarak ve buna göre doğru SQL sorguları oluşturarak bu boşluğu doldurmaya yardımcı olabilir.
SageMaker Studio'nun dizüstü bilgisayar içi SQL sorgulama özelliğinin piyasaya sürülmesiyle SageMaker Studio, Jupyter not defteri IDE'sinden hiç ayrılmadan veritabanlarını ve şemaları incelemeyi ve SQL sorguları yazmayı, çalıştırmayı ve hata ayıklamayı kolaylaştırır. Bu bölümde, gelişmiş LLM'lerin Metinden SQL'e yeteneklerinin, Jupyter not defterlerinde doğal dili kullanarak SQL sorgularının oluşturulmasını nasıl kolaylaştırabileceği araştırılmaktadır. En son Text-to-SQL modelini kullanıyoruz defog/sqlcoder-7b-2 Doğal dilden karmaşık SQL sorguları oluşturmak için özel olarak Jupyter not defterleri için tasarlanmış üretken bir yapay zeka asistanı olan Jupyter AI ile birlikte. Bu gelişmiş modeli kullanarak, doğal dili kullanarak karmaşık SQL sorgularını zahmetsizce ve verimli bir şekilde oluşturabilir, böylece dizüstü bilgisayarlardaki SQL deneyimimizi geliştirebiliriz.
Hugging Face Hub'ı kullanarak dizüstü bilgisayar prototipi oluşturma
Prototip oluşturmaya başlamak için aşağıdakilere ihtiyacınız vardır:
- GitHub kodu – Bu bölümde sunulan kod aşağıda mevcuttur GitHub repo ve referans vererek örnek not defteri.
- JupyterLab Alanı – GPU tabanlı örneklerle desteklenen SageMaker Studio JupyterLab Space'e erişim önemlidir. İçin
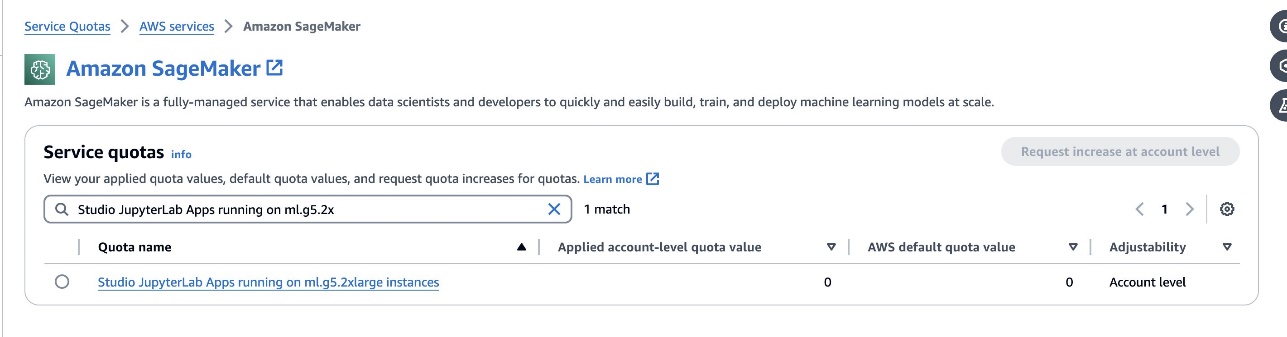
defog/sqlcoder-7b-2modelde, ml.g7xlarge örneğinin kullanıldığı bir 5.2B parametre modeli önerilir. Gibi alternatiflerdefog/sqlcoder-70b-alpha veyadefog/sqlcoder-34b-alphadoğal dilden SQL'e dönüştürme için de uygundur, ancak prototip oluşturma için daha büyük örnek türleri gerekebilir. Hizmet Kotaları konsoluna gidip SageMaker'ı arayarak veStudio JupyterLab Apps running on <instance type>.
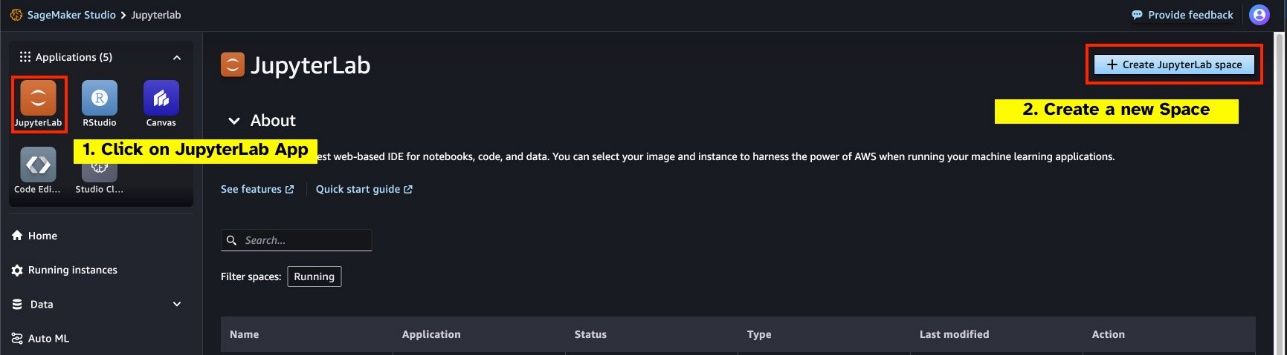
SageMaker Studio'nuzdan GPU destekli yeni bir JupyterLab Space başlatın. En az 75 GB alana sahip yeni bir JupyterLab Alanı oluşturmanız önerilir. Amazon Elastik Blok Mağazası 7B parametre modeli için (Amazon EBS) depolama.

- sarılma yüz hub – SageMaker Studio alan adınızın model indirmeye erişimi varsa sarılma yüz hubkullanabilir,
AutoModelForCausalLMsınıftan kucaklayan yüz/transformatörler modelleri otomatik olarak indirmek ve bunları yerel GPU'larınıza sabitlemek için. Model ağırlıkları yerel makinenizin önbelleğinde saklanacaktır. Aşağıdaki koda bakın:
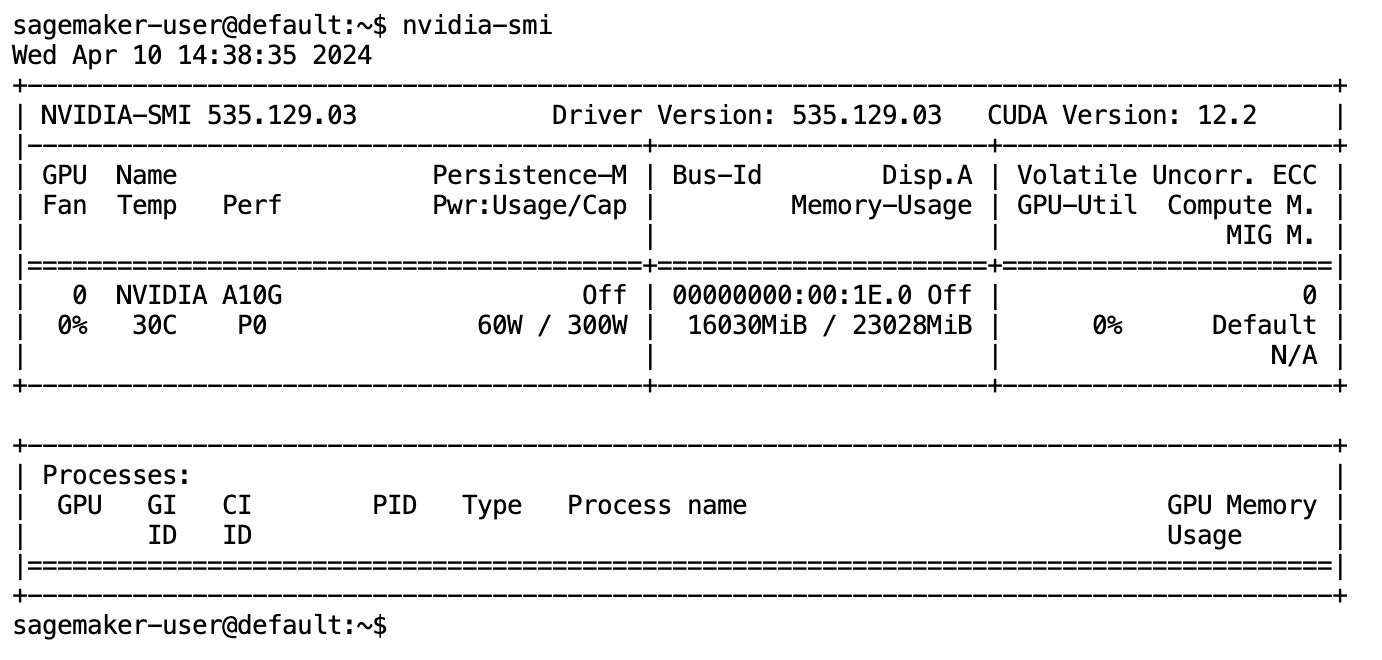
Model tamamen indirilip belleğe yüklendikten sonra yerel makinenizde GPU kullanımında bir artış gözlemlemelisiniz. Bu, modelin hesaplama görevleri için GPU kaynaklarını aktif olarak kullandığını gösterir. Bunu kendi JupyterLab alanınızda çalıştırarak doğrulayabilirsiniz. nvidia-smi (tek seferlik gösterim için) veya nvidia-smi —loop=1 (her saniyede bir tekrarlamak için) JupyterLab terminalinizden.
Metinden SQL'e modeller, kullanılan dil konuşma amaçlı veya belirsiz olsa bile, kullanıcının isteğinin amacını ve bağlamını anlama konusunda mükemmeldir. Süreç, doğal dil girdilerinin tablo adları, sütun adları ve koşullar gibi doğru veritabanı şeması öğelerine çevrilmesini içerir. Ancak kullanıma hazır bir Metinden SQL'e modeli, doğası gereği veri ambarınızın yapısını, belirli veritabanı şemalarını bilemez veya yalnızca sütun adlarına dayalı olarak bir tablonun içeriğini doğru bir şekilde yorumlayamaz. Doğal dilden pratik ve verimli SQL sorguları oluşturmak amacıyla bu modelleri etkili bir şekilde kullanmak için, SQL metin oluşturma modelini özel depo veritabanı şemanıza uyarlamanız gerekir. Bu adaptasyon aşağıdakilerin kullanılmasıyla kolaylaştırılır: Yüksek Lisans istemleri. Aşağıda, defog/sqlcoder-7b-2 Text-to-SQL modeli için dört bölüme ayrılmış, önerilen bir bilgi istemi şablonu yer almaktadır:
- Görev – Bu bölüm, model tarafından gerçekleştirilecek üst düzey bir görevi belirtmelidir. Modelin son SQL sorgusunun oluşturulmasını etkileyebilecek incelikli sözdizimsel farklılıklardan haberdar olmasını sağlamak için veritabanı arka ucu türünü (Amazon RDS, PostgreSQL veya Amazon Redshift gibi) içermelidir.
- talimatlar – Bu bölüm, model için görev sınırlarını ve etki alanı farkındalığını tanımlamalıdır ve modele ince ayarlı SQL sorguları oluşturmada rehberlik edecek birkaç örnek örnek içerebilir.
- Veritabanı Şeması – Bu bölüm, modelin veritabanı yapısını anlamasına yardımcı olmak için tablolar ve sütunlar arasındaki ilişkilerin ana hatlarını çizerek ambar veritabanı şemalarınızı detaylandırmalıdır.
- Cevap – Bu bölüm, modelin doğal dil girişine SQL sorgu yanıtının çıktısını vermesi için ayrılmıştır.
Bu bölümde kullanılan veritabanı şeması ve bilgi isteminin bir örneği şurada mevcuttur: GitHub Deposu.
Hızlı mühendislik yalnızca sorular veya ifadeler oluşturmakla ilgili değildir; bir yapay zeka modeliyle etkileşimlerin kalitesini önemli ölçüde etkileyen incelikli bir sanat ve bilimdir. Bir istemi oluşturma şekliniz, yapay zekanın yanıtının doğasını ve kullanışlılığını derinden etkileyebilir. Bu beceri, özellikle özel anlayış ve ayrıntılı yanıtlar gerektiren karmaşık görevlerde, yapay zeka etkileşimlerinin potansiyelini en üst düzeye çıkarmada çok önemlidir.
Belirli bir bilgi istemi için bir modelin yanıtını hızlı bir şekilde oluşturup test etme ve yanıta göre bilgi istemini optimize etme seçeneğine sahip olmak önemlidir. JupyterLab dizüstü bilgisayarlar, yerel bilgi işlem üzerinde çalışan bir modelden anında model geri bildirimi alma ve istemi optimize etme ve bir modelin yanıtını daha da ayarlama veya bir modeli tamamen değiştirme olanağı sağlar. Bu yazıda, dizüstü bilgisayarda Metinden SQL'e model çıkarımını çalıştırmak için ml.g5.2xlarge'nin NVIDIA A10G 24 GB GPU'su tarafından desteklenen bir SageMaker Studio JupyterLab dizüstü bilgisayar kullanıyoruz ve modelin yanıtı, sağlamak için yeterince ayarlanana kadar etkileşimli olarak model istemimizi oluşturuyoruz. JupyterLab'ın SQL hücrelerinde doğrudan yürütülebilen yanıtlar. Model çıkarımını çalıştırmak ve aynı anda model yanıtlarını yayınlamak için aşağıdakilerin bir kombinasyonunu kullanırız: model.generate ve TextIteratorStreamer aşağıdaki kodda tanımlandığı gibi:
Modelin çıktısı SageMaker SQL büyüsü ile dekore edilebilir %%sm_sql ...JupyterLab not defterinin hücreyi bir SQL hücresi olarak tanımlamasına olanak tanır.
Metinden SQL'e modellerini SageMaker uç noktaları olarak barındırın
Prototip oluşturma aşamasının sonunda, tercih ettiğimiz Text-to-SQL LLM'yi, etkili bir bilgi istemi formatını ve modeli barındırmak için uygun bir örnek tipini (tek GPU veya çoklu GPU) seçtik. SageMaker, SageMaker uç noktalarının kullanımı yoluyla özel modellerin ölçeklenebilir şekilde barındırılmasını kolaylaştırır. Bu uç noktalar, LLM'lerin uç noktalar olarak konuşlandırılmasına izin verecek şekilde belirli kriterlere göre tanımlanabilir. Bu özellik, çözümü daha geniş bir hedef kitleye ölçeklendirmenize olanak tanıyarak kullanıcıların, özel olarak barındırılan LLM'leri kullanarak doğal dil girişlerinden SQL sorguları oluşturmasına olanak tanır. Aşağıdaki diyagram bu mimariyi göstermektedir.

LLM'nizi bir SageMaker uç noktası olarak barındırmak için çeşitli yapılar oluşturursunuz.
İlk eser model ağırlıklarıdır. SageMaker Deep Java Kütüphanesi (DJL) Sunumu kapsayıcılar, bir meta aracılığıyla yapılandırmaları ayarlamanıza olanak tanır porsiyon.özellikleri Bu dosya, modellerin nasıl elde edildiğini doğrudan Hugging Face Hub'dan veya Amazon S3'ten model yapıtlarını indirerek yönlendirmenizi sağlar. Eğer belirtirseniz model_id=defog/sqlcoder-7b-2, DJL Serving bu modeli doğrudan Hugging Face Hub'dan indirmeye çalışacaktır. Ancak uç noktanın her dağıtılmasında veya esnek olarak ölçeklendirilmesinde ağ giriş/çıkış ücretlerine tabi olabilirsiniz. Bu ücretlendirmelerden kaçınmak ve model yapıtlarının indirilmesini potansiyel olarak hızlandırmak için, bu kullanımın atlanması önerilir. model_id in serving.properties ve model ağırlıklarını S3 yapıları olarak kaydedin ve bunları yalnızca s3url=s3://path/to/model/bin.
Bir modeli (belirteçleyicisiyle birlikte) diske kaydetmek ve Amazon S3'e yüklemek yalnızca birkaç satır kodla gerçekleştirilebilir:
Ayrıca bir veritabanı bilgi istemi dosyası kullanırsınız. Bu kurulumda, veritabanı istemi şunlardan oluşur: Task, Instructions, Database Schema, ve Answer sections. Mevcut mimaride her veritabanı şeması için ayrı bir istem dosyası ayırıyoruz. Ancak bu kurulumu, bilgi istemi dosyası başına birden çok veritabanı içerecek şekilde genişletme esnekliği vardır; bu, modelin aynı sunucudaki veritabanları arasında bileşik birleştirmeler çalıştırmasına olanak tanır. Prototip oluşturma aşamasında veritabanı istemini isimli bir metin dosyası olarak kaydediyoruz. <Database-Glue-Connection-Name>.prompt, Burada Database-Glue-Connection-Name JupyterLab ortamınızda görünen bağlantı adına karşılık gelir. Örneğin, bu yazı adlı bir Snowflake bağlantısına atıfta bulunuyor. Airlines_Dataset, böylece veritabanı bilgi istemi dosyası adlandırılır Airlines_Dataset.prompt. Bu dosya daha sonra Amazon S3'te depolanır ve ardından model sunma mantığımız tarafından okunup önbelleğe alınır.
Ayrıca bu mimari, bu uç noktanın yetkili kullanıcılarının, modelin birden fazla yeniden konuşlandırılmasına gerek kalmadan SQL sorgularına yönelik doğal dil tanımlamasına, depolamasına ve oluşturmasına olanak tanır. Aşağıdakileri kullanıyoruz veritabanı istemi örneği Metinden SQL'e işlevselliğini göstermek için.
Daha sonra özel model hizmet mantığını oluşturursunuz. Bu bölümde, adında özel bir çıkarım mantığının ana hatlarını çizeceksiniz. model.py. Bu komut dosyası, Metinden SQL'e hizmetlerimizin performansını ve entegrasyonunu optimize etmek için tasarlanmıştır:
- Veritabanı bilgi istemi dosyasını önbelleğe alma mantığını tanımlama – Gecikmeyi en aza indirmek için, veritabanı bilgi istemi dosyalarının indirilmesi ve önbelleğe alınması için özel bir mantık uyguluyoruz. Bu mekanizma, istemlerin hazır olmasını sağlayarak sık sık yapılan indirmelerden kaynaklanan yükü azaltır.
- Özel model çıkarım mantığını tanımlayın – Çıkarım hızını artırmak için metinden SQL'e modelimiz float16 hassas formatında yüklenir ve ardından DeepSpeed modeline dönüştürülür. Bu adım daha verimli hesaplamaya olanak tanır. Ek olarak, bu mantık dahilinde, kullanıcıların çıkarım çağrıları sırasında işlevselliği kendi ihtiyaçlarına göre uyarlamak için hangi parametreleri ayarlayabileceklerini belirlersiniz.
- Özel giriş ve çıkış mantığını tanımlayın – Açık ve özelleştirilmiş giriş/çıkış formatlarının oluşturulması, sonraki uygulamalarla sorunsuz entegrasyon için çok önemlidir. Böyle bir uygulama, sonraki bölümde tartışacağımız JupyterAI'dir.
Ek olarak şunları da dahil ediyoruz: serving.properties DJL sunumu kullanılarak barındırılan modeller için genel bir yapılandırma dosyası görevi gören dosya. Daha fazla bilgi için bkz. Yapılandırmalar ve ayarlar.
Son olarak şunları da ekleyebilirsiniz: requirements.txt Çıkarım için gereken ek modülleri tanımlamak ve dağıtım için her şeyi bir tarball'a paketlemek için dosya.
Aşağıdaki koda bakın:
Uç noktanızı SageMaker Studio Jupyter AI asistanıyla entegre edin
Jüpiter AI üretken yapay zeka modellerini keşfetmek için sağlam ve kullanıcı dostu bir platform sunan, üretken yapay zekayı Jupyter dizüstü bilgisayarlara getiren açık kaynaklı bir araçtır. Dizüstü bilgisayarların içinde üretken bir yapay zeka oyun alanı oluşturmak için %%ai büyüsü, bir konuşma asistanı olarak yapay zeka ile etkileşime geçmek için JupyterLab'da yerel bir sohbet kullanıcı arayüzü ve çok çeşitli Yüksek Lisans Diplomaları için destek gibi özellikler sağlayarak JupyterLab ve Jupyter dizüstü bilgisayarlarda üretkenliği artırır. gibi sağlayıcılar Amazon Titanı, AI21, Anthropic, Cohere ve Hugging Face veya yönetilen hizmetler Amazon Ana Kayası ve SageMaker uç noktaları. Bu yazı için, Metinden SQL'e özelliğini JupyterLab not defterlerine getirmek için Jupyter AI'nin SageMaker uç noktalarıyla kullanıma hazır entegrasyonunu kullanıyoruz. Jupyter AI aracı, aşağıdakiler tarafından desteklenen tüm SageMaker Studio JupyterLab Spaces'a önceden yüklenmiş olarak gelir: SageMaker Dağıtım görselleri; Son kullanıcıların, SageMaker tarafından barındırılan bir uç noktayla entegrasyon amacıyla Jupyter AI uzantısını kullanmaya başlamak için herhangi bir ek yapılandırma yapmasına gerek yoktur. Bu bölümde entegre Jupyter AI aracını kullanmanın iki yolunu tartışıyoruz.
Sihir kullanan bir not defterinin içindeki Jupyter AI
Jüpyter yapay zekası %%ai magic komutu, SageMaker Studio JupyterLab not defterlerinizi tekrarlanabilir, üretken bir yapay zeka ortamına dönüştürmenize olanak tanır. Yapay zeka büyülerini kullanmaya başlamak için jupyter_ai_magics uzantısını yüklediğinizden emin olun. %%ai sihir ve ayrıca yükleme amazon_sagemaker_sql_magic kullanmak %%sm_sql büyü:
Not defterinizi kullanarak SageMaker uç noktanıza çağrı yapmak için %%ai magic komutunu kullanarak aşağıdaki parametreleri sağlayın ve komutu şu şekilde yapılandırın:
- –bölge adı – Uç noktanızın dağıtıldığı Bölgeyi belirtin. Bu, isteğin doğru coğrafi konuma yönlendirilmesini sağlar.
- –istek şeması – Giriş verilerinin şemasını ekleyin. Bu şema, modelinizin isteği işlemek için ihtiyaç duyduğu giriş verilerinin beklenen biçimini ve türlerini özetlemektedir.
- –yanıt-yolu – Modelinizin çıktısının bulunduğu yanıt nesnesi içindeki yolu tanımlayın. Bu yol, modelinizin döndürdüğü yanıttan ilgili verileri çıkarmak için kullanılır.
- -f (isteğe bağlı) - Bu bir çıktı biçimlendirici model tarafından döndürülen çıktının türünü belirten bayrak. Bir Jupyter not defteri bağlamında, çıktı kod ise, bu bayrak, çıktıyı bir Jupyter not defteri hücresinin üst kısmında çalıştırılabilir kod olarak biçimlendirecek şekilde ayarlanmalı ve ardından kullanıcı etkileşimi için bir serbest metin giriş alanı gelmelidir.
Örneğin, Jupyter not defteri hücresindeki komut aşağıdaki koda benzeyebilir:
Jupyter AI sohbet penceresi
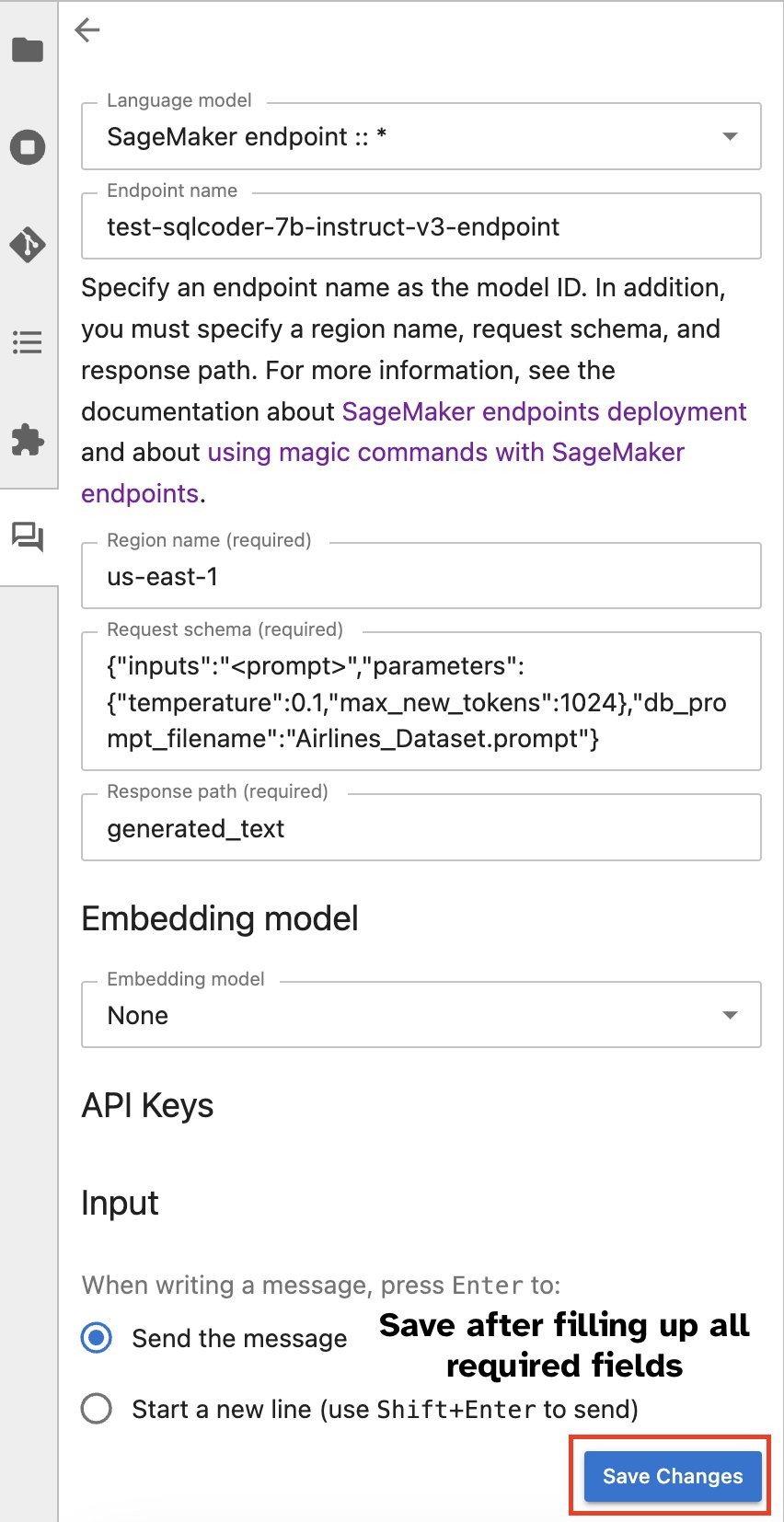
Alternatif olarak, yerleşik bir kullanıcı arayüzü aracılığıyla SageMaker uç noktalarıyla etkileşim kurarak sorgu oluşturma veya diyalog kurma sürecini basitleştirebilirsiniz. SageMaker uç noktanızla sohbet etmeye başlamadan önce, aşağıdaki ekran görüntüsünde gösterildiği gibi SageMaker uç noktası için Jupyter AI'deki ilgili ayarları yapılandırın.
 |
 |
Sonuç
SageMaker Studio artık SQL desteğini JupyterLab not defterlerine entegre ederek veri bilimci iş akışını basitleştiriyor ve kolaylaştırıyor. Bu, veri bilimcilerinin birden fazla aracı yönetmeye gerek kalmadan görevlerine odaklanmasına olanak tanır. Ayrıca, SageMaker Studio'daki yeni yerleşik SQL entegrasyonu, veri personelinin doğal dil metnini girdi olarak kullanarak zahmetsizce SQL sorguları oluşturmasına olanak tanır ve böylece iş akışlarını hızlandırır.
SageMaker Studio'daki bu özellikleri keşfetmenizi öneririz. Daha fazla bilgi için bkz. Studio'da SQL ile veri hazırlama.
Ek
Özel ortamlarda SQL tarayıcısını ve not defteri SQL hücresini etkinleştirin
Bir SageMaker Dağıtım görüntüsü kullanmıyorsanız veya Dağıtım görüntüleri 1.5 veya daha düşük bir sürümü kullanmıyorsanız, JupyterLab ortamınızda SQL tarama özelliğini etkinleştirmek için aşağıdaki komutları çalıştırın:
SQL tarayıcı widget'ının yerini değiştirin
JupyterLab widget'ları yer değiştirmeye izin verir. Tercihinize bağlı olarak widget'ları JupyterLab widget'lar bölmesinin her iki tarafına da taşıyabilirsiniz. İsterseniz, SQL widget'ının yönünü, widget simgesini sağ tıklayıp seçerek kenar çubuğunun karşı tarafına (sağdan sola) taşıyabilirsiniz. Kenar Çubuğu Tarafını Değiştir.
 |
 |
yazarlar hakkında
 Pranav Murthy AWS'de AI/ML Uzman Çözüm Mimarıdır. Müşterilerin makine öğrenimi (ML) iş yüklerini oluşturmasına, eğitmesine, dağıtmasına ve SageMaker'a taşımasına yardımcı olmaya odaklanıyor. Daha önce yarı iletken endüstrisinde, en gelişmiş makine öğrenimi tekniklerini kullanarak yarı iletken süreçlerini iyileştirmek için büyük bilgisayarlı görüntü (CV) ve doğal dil işleme (NLP) modelleri geliştirerek çalıştı. Boş zamanlarında satranç oynamaktan ve seyahat etmekten hoşlanıyor. Pranav'ı şurada bulabilirsiniz: LinkedIn.
Pranav Murthy AWS'de AI/ML Uzman Çözüm Mimarıdır. Müşterilerin makine öğrenimi (ML) iş yüklerini oluşturmasına, eğitmesine, dağıtmasına ve SageMaker'a taşımasına yardımcı olmaya odaklanıyor. Daha önce yarı iletken endüstrisinde, en gelişmiş makine öğrenimi tekniklerini kullanarak yarı iletken süreçlerini iyileştirmek için büyük bilgisayarlı görüntü (CV) ve doğal dil işleme (NLP) modelleri geliştirerek çalıştı. Boş zamanlarında satranç oynamaktan ve seyahat etmekten hoşlanıyor. Pranav'ı şurada bulabilirsiniz: LinkedIn.
 Varun Şah Amazon Web Services'te Amazon SageMaker Studio'da çalışan bir Yazılım Mühendisidir. Veri işleme ve veri hazırlama yolculuklarını basitleştiren etkileşimli makine öğrenimi çözümleri oluşturmaya odaklanmıştır. Varun, boş zamanlarında yürüyüş ve kayak gibi açık hava aktivitelerinden hoşlanıyor ve her zaman yeni, heyecan verici yerler keşfetmeye hazır.
Varun Şah Amazon Web Services'te Amazon SageMaker Studio'da çalışan bir Yazılım Mühendisidir. Veri işleme ve veri hazırlama yolculuklarını basitleştiren etkileşimli makine öğrenimi çözümleri oluşturmaya odaklanmıştır. Varun, boş zamanlarında yürüyüş ve kayak gibi açık hava aktivitelerinden hoşlanıyor ve her zaman yeni, heyecan verici yerler keşfetmeye hazır.
 Sümeyye Swamy Amazon Web Services'te Baş Ürün Yöneticisi olarak görev yapmaktadır ve burada veri bilimi ve makine öğrenimi için tercih edilen IDE'yi geliştirme misyonunda SageMaker Studio ekibine liderlik etmektedir. Son 15 yılını Makine Öğrenimi tabanlı tüketici ve kurumsal ürünler geliştirmeye adadı.
Sümeyye Swamy Amazon Web Services'te Baş Ürün Yöneticisi olarak görev yapmaktadır ve burada veri bilimi ve makine öğrenimi için tercih edilen IDE'yi geliştirme misyonunda SageMaker Studio ekibine liderlik etmektedir. Son 15 yılını Makine Öğrenimi tabanlı tüketici ve kurumsal ürünler geliştirmeye adadı.
 bosco albuquerque AWS'de Kıdemli İş Ortağı Çözümleri Mimarıdır ve kurumsal veritabanı satıcıları ve bulut sağlayıcılarının veritabanı ve analitik ürünleriyle çalışma konusunda 20 yılı aşkın deneyime sahiptir. Teknoloji şirketlerinin veri analitiği çözümleri ve ürünleri tasarlamasına ve uygulamasına yardımcı oldu.
bosco albuquerque AWS'de Kıdemli İş Ortağı Çözümleri Mimarıdır ve kurumsal veritabanı satıcıları ve bulut sağlayıcılarının veritabanı ve analitik ürünleriyle çalışma konusunda 20 yılı aşkın deneyime sahiptir. Teknoloji şirketlerinin veri analitiği çözümleri ve ürünleri tasarlamasına ve uygulamasına yardımcı oldu.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

